

文章目录
- 发现宝藏
- 一、 目标
- 二、简单分析网页
-
- 1. 寻找所有新闻
- 2. 分析模块、版面和文章
- 三、爬取新闻
-
- 1. 爬取模块
- 2. 爬取版面
- 3. 爬取文章
- 四、完整代码
- 五、效果展示
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。

一、 目标
爬取news.columbia.edu的字段,包含标题、内容,作者,发布时间,链接地址,文章快照 (可能需要翻墙才能访问)
二、简单分析网页
1. 寻找所有新闻
- 按照如下步骤,找到全部新闻



2. 分析模块、版面和文章
-
为了规范爬取的命名与逻辑,我们分别用模块、版面、文章三部分来进行爬取,具体如下
-
一个网站的全部新闻由数个模块组成,只要我们遍历爬取了所有模块就获得的该网站的所有新闻,由于该网站所有新闻都在该路径下,所有该路径就是唯一的模块

- 一个模块由数页版面组成,只要遍历了所有版面,我们就爬取了一个模块

- 一个版面里有数页文章,由于该网站模块下的列表同时也是一篇文章,所以一个版面里只有一篇文章

- 一篇文章有标题、出版时间和作者信息、文章正文和文章图片等信息

三、爬取新闻
1. 爬取模块
- 由于该新闻只有一个模块,所以直接请求该模块地址即可获取该模块的所有信息,但是为了兼容多模块的新闻,我们还是定义一个数组存储模块地址
class ColumbianewsScraper::
def __init__(self, root_url, model_url, img_output_dir):
self.root_url = root_url
self.model_url = model_url
self.img_output_dir = img_output_dir
self.headers = {
'Referer': 'https://news.columbia.edu/news/other?page=194',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/122.0.0.0 Safari/537.36',
'Cookie': ''
}
def run():
# 网站根路径
root_url = 'https://news.columbia.edu/'
# 文章图片保存路径
output_dir = 'D://imgs//columbia-news'
# 模块地址数组
model_urls = ['https://news.columbia.edu/news/other']
for model_url in model_urls:
# 初始化类
scraper = ColumbianewsScraper(root_url, model_url, output_dir)
# 遍历版面
scraper.catalogue_all_pages()
if __name__ == "__main__":
run()
2. 爬取版面
- 首先我们确认模块下版面切页相关的参数传递,通过切换页面我们不难发现切换页面是通过传递参数 page 来实现的

- 于是我们接着寻找模块下有多少页版面,通过观察控制台我们发现最后一页是在 类名为 的 ul 标签里的最后一个 a 标签文本里

# 获取一个模块有多少版面
def catalogue_all_pages(self):
response = requests.get(self.model_url, headers=self.headers)
soup = BeautifulSoup(response.text, 'html.parser')
try:
num_page_str=soup.find('ul', 'pagination js-pager__items').find('a', title='Go to last page').get('href')
# 使用正则表达式匹配数字
match = re.search(r'd+', num_page_str)
num_pages = int(match.group()) + 1
print(self.model_url + ' 模块一共有' + str(num_pages) + '页版面')
for page in range(0, num_pages):
print(f"========start catalogues page {page+1}" + "/" + str(num_pages) + "========")
self.parse_catalogues(page)
print(f"========Finished catalogues page {page+1}" + "/" + str(num_pages) + "========")
except Exception as e:
print(f'Error: {e}')
traceback.print_exc()

- 根据模块地址和page参数传递完整版面地址,访问并解析找到对应的版面列表

# 解析版面列表里的版面
def parse_catalogues(self, page):
params = {'page': page}
response = requests.get(self.model_url, headers=self.headers, params=params)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
catalogue_list = soup.find('div', 'col-md-8')
catalogues_list = catalogue_list.find_all('div', 'views-row')
for index, catalogue in enumerate(catalogues_list):

- 遍历版面列表,获取版面标题

catalogue_title = catalogue.find('div', 'views-field views-field-title').find('a').get_text(strip=True)

- 获取出版时间和操作时间

date = datetime.now()
# 更新时间
publish_time = catalogue.find('div', 'views-field views-field-field-cu-date').find('time').get('datetime')
# 将日期字符串转换为datetime对象
# 去除时区信息,得到不带时区的时间字符串
date_string_no_tz = publish_time.replace('Z', '')
# 使用 strptime 函数将字符串转换为时间对象
updatetime = datetime.strptime(date_string_no_tz, '%Y-%m-%dT%H:%M:%S')

- 保存版面url和版面id, 由于该新闻是一个版面对应一篇文章,所以版面url和文章url是一样的,而且文章没有明显的标识,我们把地址后缀作为文章id,版面id则是文章id后面加上个01


# 版面url
catalogue_href = catalogue.find('div', 'views-field views-field-title').find('a').get('href')
catalogue_url = self.root_url + catalogue_href
# 使用正则表达式提取最后一个斜杠后的路径部分
match = re.search(r'/([^/]+)/?$', catalogue_url)
# 版面id
catalogue_id = str(match.group(1))

- 保存版面信息到mogodb数据库(由于每个版面只有一篇文章,所以版面文章数量cardsize的值赋为1)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['columbia-news']
# 创建或选择集合
catalogues_collection = db['catalogues']
# 插入示例数据到 catalogues 集合
catalogue_data = {
'id': catalogue_id,
'date': date,
'title': catalogue_title,
'url': catalogue_url,
'cardSize': 1,
'updatetime': updatetime
}
# 在插入前检查是否存在相同id的文档
existing_document = catalogues_collection.find_one({'id': catalogue_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
catalogues_collection.insert_one(catalogue_data)
print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")
else:
print("[爬取版面]版面 " + catalogue_url + " 已存在!")
print(f"========finsh catalogue {index+1}" + "/" + "15========")
3. 爬取文章
-
由于一个版面对应一篇文章,所以版面url 、更新时间、标题和文章是一样的,并且按照设计版面id和文章id的区别只是差了个01,所以可以传递版面url、版面id、更新时间和标题四个参数到解析文章的函数里面
-
获取文章id,文章url,文章更新时间和当下操作时间
# 解析版面列表里的版面
def parse_catalogues(self, page):
...
self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)
...
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
card_response = requests.get(url, headers=self.headers)
soup = BeautifulSoup(card_response.text, 'html.parser')
# 对应的版面id
card_id = catalogue_id
# 文章标题
card_title = cardtitle
# 文章更新时间
updateTime = cardupdatetime
# 操作时间
date = datetime.now()

- 获取文章作者

# 文章作者
author = soup.find('article', id='main-article').find('div', 'authors').get_text().replace('n', '').replace('By', '')

- 获取文章原始htmldom结构,并删除无用的部分(以下仅是部分举例),用html_content字段保留原始dom结构



# 原始htmldom结构
html_dom = soup.find('article', id='main-article')
html_cut1 = html_dom.find('div', 'news-topic')
html_cut2 = html_dom.find('div', id='cu_related_block-19355')
html_cut3 = html_dom.find('div', id='sub-frame-error')
# 移除元素
if html_cut1:
html_cut1.extract()
if html_cut2:
html_cut2.extract()
if html_cut3:
html_cut3.extract()
- 进行文章清洗,保留文本,去除标签,用content保留清洗后的文本
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
...
# 增加保留html样式的源文本
origin_html = html_dom.prettify() # String
# 转义网页中的图片标签
str_html = self.transcoding_tags(origin_html)
# 再包装成
temp_soup = BeautifulSoup(str_html, 'html.parser')
# 反转译文件中的插图
str_html = self.translate_tags(temp_soup.text)
# 绑定更新内容
content = self.clean_content(str_html)
...
# 工具 转义标签
def transcoding_tags(self, htmlstr):
re_img = re.compile(r's*s*', re.M)
s = re_img.sub(r'n @@##1##@@ n', htmlstr) # IMG 转义
return s
# 工具 转义标签
def translate_tags(self, htmlstr):
re_img = re.compile(r'@@##(img.*?)##@@', re.M)
s = re_img.sub(r'', htmlstr) # IMG 转义
return s
# 清洗文章
def clean_content(self, content):
if content is not None:
content = re.sub(r'r', r'n', content)
content = re.sub(r'n{2,}', '', content)
content = re.sub(r' {6,}', '', content)
content = re.sub(r' {3,}n', '', content)
content = re.sub(r' ', '', content)
content = content.replace(
'
', '', content)
content = content.replace(
' ', '')
content = content.replace(
''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="SourcePh " style="display:none">''',
'')
.replace(' <!--enpcontent', '').replace('
', '')
content = content.replace(
''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="SourcePh " style="display:none">''',
'')
.replace(' <!--enpcontent', '').replace('', '')
content = content.replace(''
, '').replace(''
, '').replace(' ', ' ')
return content
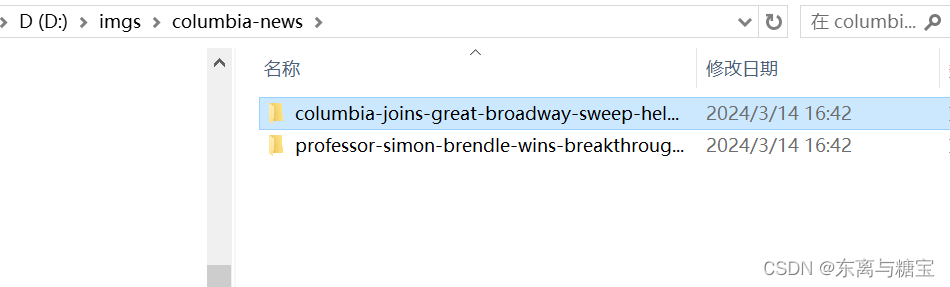
- 下载保存文章图片,保存到d盘目录下的imgs/nd-news文件夹下,每篇文章图片用一个命名为文章id的文件夹命名,并用字段illustrations保存图片的绝对路径和相对路径
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
...
# 下载图片
imgs = []
img_array = soup.find('div', id='featured-content').find_all('img')
if len(img_array) is not None:
for item in img_array:
img_url = self.root_url + item.get('src')
imgs.append(img_url)
if len(imgs) != 0:
# 下载图片
illustrations = self.download_images(imgs, card_id)
# 下载图片
def download_images(self, img_urls, card_id):
result = re.search(r'[^/]+$', card_id)
last_word = result.group(0)
# 根据card_id创建一个新的子目录
images_dir = os.path.join(self.img_output_dir, str(last_word)) if not os.path.exists(images_dir):
os.makedirs(images_dir)
downloaded_images = []
for index, img_url in enumerate(img_urls):
try:
response = requests.get(img_url, stream=True, headers=self.headers)
if response.status_code == 200:
# 从URL中提取图片文件名
img_name_with_extension = img_url.split('/')[-1]
pattern = r'^[^?]*'
match = re.search(pattern, img_name_with_extension)
img_name = match.group(0)
# 保存图片
with open(os.path.join(images_dir, img_name), 'wb') as f:
f.write(response.content)
downloaded_images.append([img_url, os.path.join(images_dir, img_name)])
print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')
except requests.exceptions.RequestException as e:
print(f'请求图片时发生错误:{e}')
except Exception as e:
print(f'保存图片时发生错误:{e}')
return downloaded_images
# 如果文件夹存在则跳过
else:
print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')
return []

- 保存文章数据到数据库
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['nd-news']
# 创建或选择集合
cards_collection = db['cards']
# 插入示例数据到 cards 集合
card_data = {
'id': card_id,
'catalogueId': catalogue_id,
'type': 'nd-news',
'date': date,
'title': card_title,
'author': author,
'updatetime': updateTime,
'url': url,
'html_content': str(html_content),
'content': content,
'illustrations': illustrations,
}
# 在插入前检查是否存在相同id的文档
existing_document = cards_collection.find_one({'id': card_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
cards_collection.insert_one(card_data)
print("[爬取文章]文章 " + url + " 已成功插入!")
else:
print("[爬取文章]文章 " + url + " 已存在!")
四、完整代码
import os
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import re
import traceback
class ColumbianewsScraper:
def __init__(self, root_url, model_url, img_output_dir):
self.root_url = root_url
self.model_url = model_url
self.img_output_dir = img_output_dir
self.headers = {
'Referer': 'https://news.columbia.edu/news/other?page=194',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/122.0.0.0 Safari/537.36',
'Cookie': '__cf_bm=_takFcwXmltRp7BQJYSUHhfc9SXRPZdt1QnDSdY3Og8-1710139489-1.0.1.1'
'-wX_2br0GXQiqc5vxjaOTTg34kdk.o9tCITBFF5O6X1Q9WY_2nvwFju21xbXXvSemuQmqWnyoUko6kKS23kRidg; '
'_gid=GA1.2.1882013722.1710139491; cuPivacyNotice=1; _ga=GA1.1.1680128029.1708481980; '
'BIGipServer~CUIT~drupaldistprod.cc.columbia.edu-443-pool=!omWlyZA9uxfUxy0HrSyr'
'/NyatqktDOUd6d8QEy32oKHvcMAczidbyADWBSz0qWS+aS7plRl8MVECTKw=; '
'_gcl_au=1.1.1784812938.1710140087; _ga_E1ZMHWNYYH=GS1.1.1710139491.3.1.1710140162.60.0.0 '
}
# 获取一个模块有多少版面
def catalogue_all_pages(self):
response = requests.get(self.model_url, headers=self.headers)
soup = BeautifulSoup(response.text, 'html.parser')
try:
num_page_str = soup.find('ul', 'pagination js-pager__items').find('a', title='Go to last page').get('href')
# 使用正则表达式匹配数字
match = re.search(r'd+', num_page_str)
num_pages = int(match.group()) + 1
print(self.model_url + ' 模块一共有' + str(num_pages) + '页版面')
for page in range(0, num_pages):
print(f"========start catalogues page {page + 1}" + "/" + str(num_pages) + "========")
self.parse_catalogues(page)
print(f"========Finished catalogues page {page + 1}" + "/" + str(num_pages) + "========")
except Exception as e:
print(f'Error: {e}')
traceback.print_exc()
# 解析版面列表里的版面
def parse_catalogues(self, page):
params = {'page': page}
response = requests.get(self.model_url, headers=self.headers, params=params)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
catalogue_list = soup.find('div', 'col-md-8')
catalogues_list = catalogue_list.find_all('div', 'views-row')
for index, catalogue in enumerate(catalogues_list):
print(f"========start catalogue {index + 1}" + "/" + "15========")
# 版面标题
catalogue_title = catalogue.find('div', 'views-field views-field-title').find('a').get_text(strip=True)
# 操作时间
date = datetime.now()
# 更新时间
publish_time = catalogue.find('div', 'views-field views-field-field-cu-date').find('time').get(
'datetime')
# 将日期字符串转换为datetime对象
# 去除时区信息,得到不带时区的时间字符串
date_string_no_tz = publish_time.replace('Z', '')
# 使用 strptime 函数将字符串转换为时间对象
updatetime = datetime.strptime(date_string_no_tz, '%Y-%m-%dT%H:%M:%S')
# 版面url
catalogue_href = catalogue.find('div', 'views-field views-field-title').find('a').get('href')
catalogue_url = self.root_url + catalogue_href
# 使用正则表达式提取最后一个斜杠后的路径部分
match = re.search(r'/([^/]+)/?$', catalogue_url)
# 版面id
catalogue_id = str(match.group(1))
self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['columbia-news']
# 创建或选择集合
catalogues_collection = db['catalogues']
# 插入示例数据到 catalogues 集合
catalogue_data = {
'id': catalogue_id,
'date': date,
'title': catalogue_title,
'url': catalogue_url,
'cardSize': 1,
'updatetime': updatetime
}
# 在插入前检查是否存在相同id的文档
existing_document = catalogues_collection.find_one({'id': catalogue_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
catalogues_collection.insert_one(catalogue_data)
print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")
else:
print("[爬取版面]版面 " + catalogue_url + " 已存在!")
print(f"========finsh catalogue {index + 1}" + "/" + "15========")
return True
else:
raise Exception(f"Failed to fetch page {page}. Status code: {response.status_code}")
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
card_response = requests.get(url, headers=self.headers)
soup = BeautifulSoup(card_response.text, 'html.parser')
# 对应的版面id
card_id = catalogue_id
# 文章标题
card_title = cardtitle
# 文章更新时间
updateTime = cardupdatetime
# 操作时间
date = datetime.now()
try:
# 文章作者
author = soup.find('article', id='main-article').find('div', 'authors').get_text().replace('n', '')
except:
author = None
# 原始htmldom结构
html_dom = soup.find('article', id='main-article')
html_cut1 = html_dom.find('div', 'news-topic')
html_cut2 = html_dom.find('div', id='cu_related_block-19355')
html_cut3 = html_dom.find('div', id='sub-frame-error')
# 移除元素
if html_cut1:
html_cut1.extract()
if html_cut2:
html_cut2.extract()
if html_cut3:
html_cut3.extract()
html_content = html_dom
# 增加保留html样式的源文本
origin_html = html_dom.prettify() # String
# 转义网页中的图片标签
str_html = self.transcoding_tags(origin_html)
# 再包装成
temp_soup = BeautifulSoup(str_html, 'html.parser')
# 反转译文件中的插图
str_html = self.translate_tags(temp_soup.text)
# 绑定更新内容
content = self.clean_content(str_html)
# 下载图片
imgs = []
img_array = soup.find('div', id='featured-content').find_all('img')
if len(img_array) is not None:
for item in img_array:
img_url = self.root_url + item.get('src')
imgs.append(img_url)
if len(imgs) != 0:
# 下载图片
illustrations = self.download_images(imgs, card_id)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['columbia-news']
# 创建或选择集合
cards_collection = db['cards']
# 插入示例数据到 cards 集合
card_data = {
'id': card_id,
'catalogueId': catalogue_id,
'type': 'nd-news',
'date': date,
'title': card_title,
'author': author,
'updatetime': updateTime,
'url': url,
'html_content': str(html_content),
'content': content,
'illustrations': illustrations,
}
# 在插入前检查是否存在相同id的文档
existing_document = cards_collection.find_one({'id': card_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
cards_collection.insert_one(card_data)
print("[爬取文章]文章 " + url + " 已成功插入!")
else:
print("[爬取文章]文章 " + url + " 已存在!")
# 下载图片
def download_images(self, img_urls, card_id):
result = re.search(r'[^/]+$', card_id)
last_word = result.group(0)
# 根据card_id创建一个新的子目录
images_dir = os.path.join(self.img_output_dir, str(last_word))
if not os.path.exists(images_dir):
os.makedirs(images_dir)
downloaded_images = []
for index, img_url in enumerate(img_urls):
try:
response = requests.get(img_url, stream=True, headers=self.headers)
if response.status_code == 200:
# 从URL中提取图片文件名
img_name_with_extension = img_url.split('/')[-1]
pattern = r'^[^?]*'
match = re.search(pattern, img_name_with_extension)
img_name = match.group(0)
# 保存图片
with open(os.path.join(images_dir, img_name), 'wb') as f:
f.write(response.content)
downloaded_images.append([img_url, os.path.join(images_dir, img_name)])
print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')
except requests.exceptions.RequestException as e:
print(f'请求图片时发生错误:{e}')
except Exception as e:
print(f'保存图片时发生错误:{e}')
return downloaded_images
# 如果文件夹存在则跳过
else:
print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')
return []
# 工具 转义标签
def transcoding_tags(self, htmlstr):
re_img = re.compile(r's*s*', re.M)
s = re_img.sub(r'n @@##1##@@ n', htmlstr) # IMG 转义
return s
# 工具 转义标签
def translate_tags(self, htmlstr):
re_img = re.compile(r'@@##(img.*?)##@@', re.M)
s = re_img.sub(r'', htmlstr) # IMG 转义
return s
# 清洗文章
def clean_content(self, content):
if content is not None:
content = re.sub(r'r', r'n', content)
content = re.sub(r'n{2,}', '', content)
content = re.sub(r' {6,}', '', content)
content = re.sub(r' {3,}n', '', content)
content = re.sub(r'', '', content)
content = content.replace(
' ', '')
content = content.replace(
''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="SourcePh " style="display:none">''',
'')
.replace(' <!--enpcontent', '').replace('', '')
content = content.replace(''
, '').replace(''
, '').replace(' ', ' ')
return content
def run():
# 网站根路径
root_url = 'https://news.columbia.edu/'
# 文章图片保存路径
output_dir = 'D://imgs//columbia-news'
# 模块地址数组
model_urls = ['https://news.columbia.edu/news/other']
for model_url in model_urls:
# 初始化类
scraper = ColumbianewsScraper(root_url, model_url, output_dir)
# 遍历版面
scraper.catalogue_all_pages()
if __name__ == "__main__":
run()
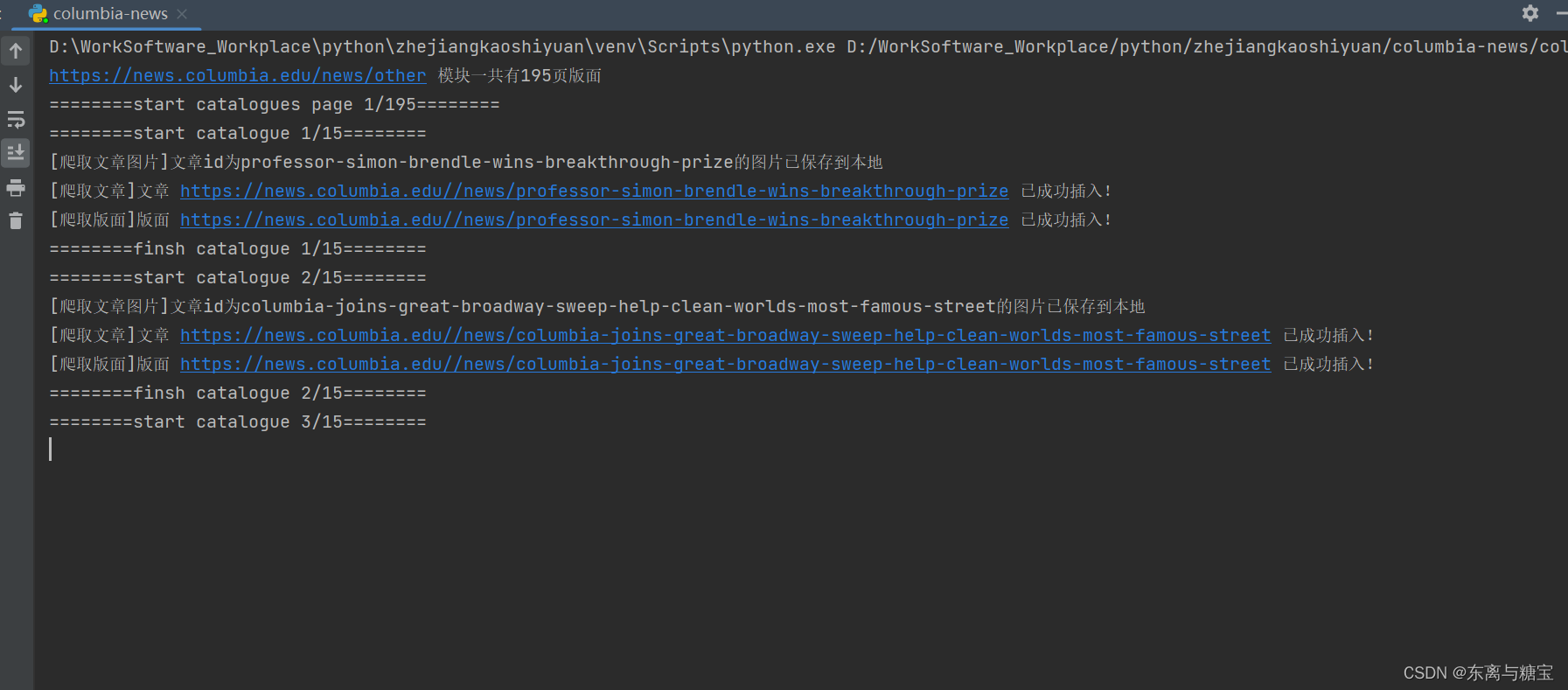
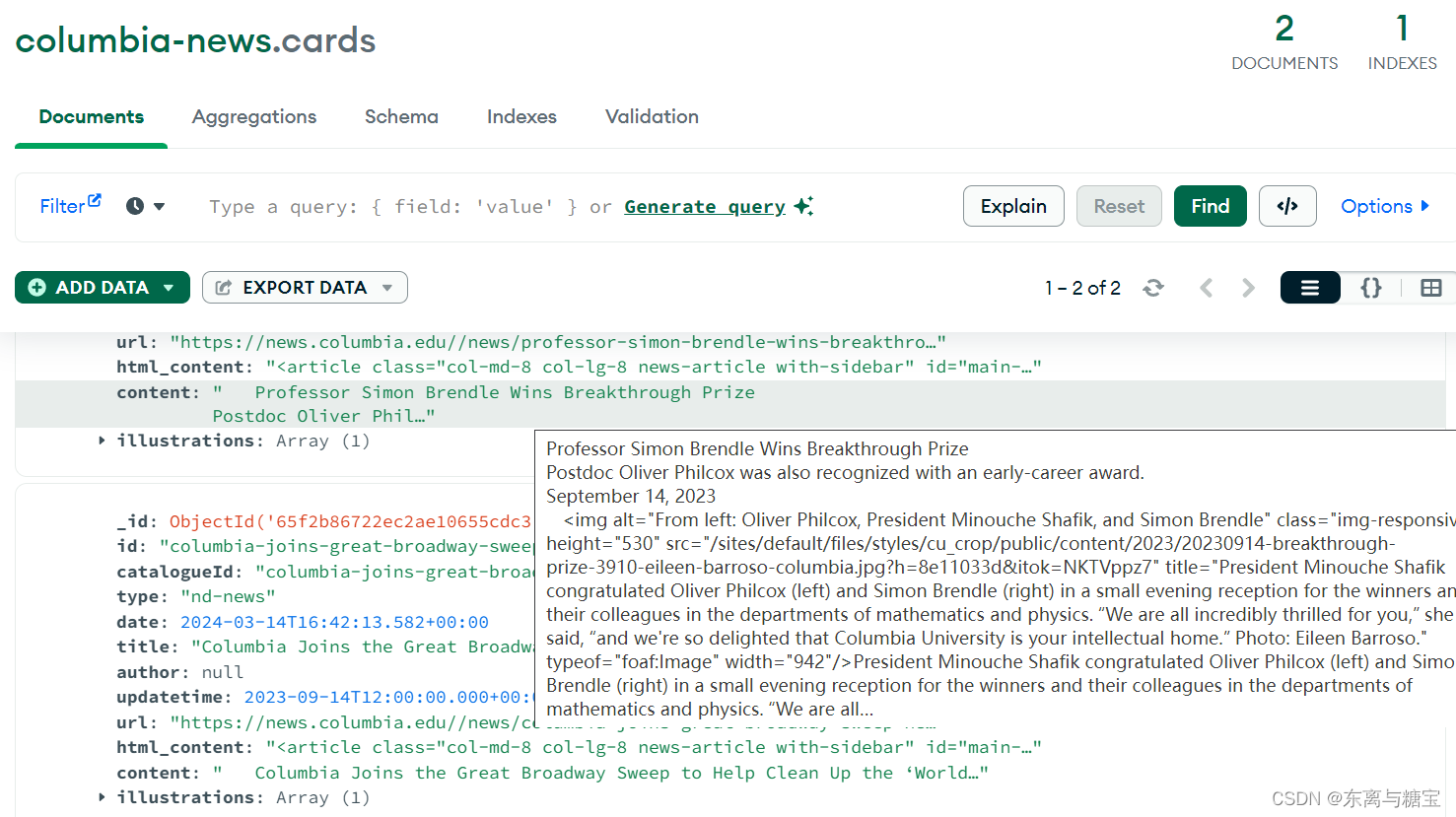
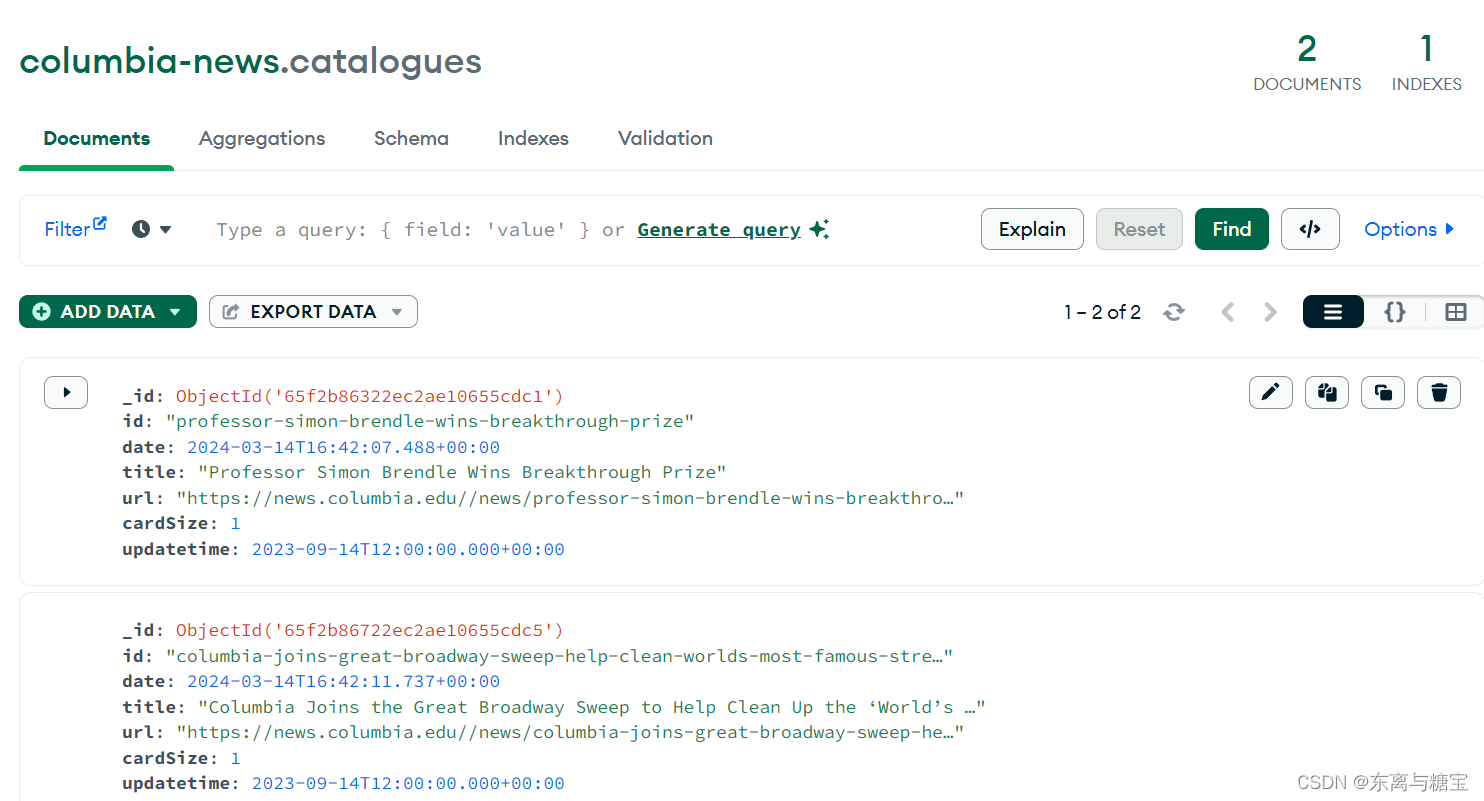
五、效果展示

$(function() {
setTimeout(function () {
var mathcodeList = document.querySelectorAll(‘.htmledit_views img.mathcode’);
if (mathcodeList.length > 0) {
for (let i = 0; i < mathcodeList.length; i++) {
if (mathcodeList[i].naturalWidth === 0 || mathcodeList[i].naturalHeight === 0) {
var alt = mathcodeList[i].alt;
alt = '\(' + alt + '\)';
var curSpan = $('‘);
curSpan.text(alt);
$(mathcodeList[i]).before(curSpan);
$(mathcodeList[i]).remove();
}
}
MathJax.Hub.Queue([“Typeset”,MathJax.Hub]);
}
}, 1000)
});

优惠劵

东离与糖宝
关注
关注
-



74
点赞
-


踩
-



44
收藏
觉得还不错?
一键收藏

-

打赏
-


34
评论
-

复制链接
信息检索 哥伦比亚大学
04-23
这个是哥伦比亚大学信息检索课的课件。很流行很受欢迎的资料呀。
哥伦比亚大学-Large Scale Machine Learning
12-10
哥伦比亚大学 Large Scale Machine Learning pdf文档
34 条评论
您还未登录,请先
登录
后发表或查看评论
机器学习(Machine Learning)&深度学习(Deep Learning)资料
weixin_33980459的博客
09-07

3127
机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 1)
《Brief History of Machine Learning》
介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机、神经网络、决策树、SVM、Adaboost到随机森林、Deep Learning.
《Deep Learning in Ne…
美国哥伦比亚大学教学和学习中心的特征及启示
06-11
大学教师的发展是高等教育质量建设的基础。我国大学教师发展机构尚处于起步阶段,本文通过对哥伦比亚大学教学和学习中心进行案例研究,从理念的传播、教师培训、研究生培训、资助和教育技术五个方面剖析其特征,以期对我国大学教师发展机构的建设提供有益的启示。
信息时代大学教学支持服务体系建设及其经验解读——美国哥伦比亚大学“新媒体教学与学习中心”透析.pdf
10-10
信息时代大学教学支持服务体系建设及其经验解读——美国哥伦比亚大学“新媒体教学与学习中心”透析.pdf
巴菲特在哥伦比亚大学的演讲中文版.doc
01-04
巴菲特在哥伦比亚大学的演讲中文版.doc
python 数据分析与挖局书籍
guangyinglanshan的博客
09-01
7931
之前一直有朋友叫我列一个数据科学的书单,说实话这件事情我是犹豫了很久的。有两个原因,其一是因为自己读书太少才疏学浅,其二我觉得基于我个人观点认为“好”的书其实可能对于很多人是不一定合适的。
不过,明天正好是世界读书日,所以这里从一个(在读的统计PhD学生➕即将去旧金山的某Startup进行Data Science暑期实习的准数据科学家)的角度,给大家列一个书单吧,里面有我读过的书,也有我想读的书
机器学习,深度学习的资料和工具库大全
AITBOOK
08-28
8762
https://github.com/maismall
《Brief History of Machine Learning》
介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机、神经网络、决策树、SVM、Adaboost到随机森林、Deep Learning.
《Deep Learning in Neural Networks: An Overview》
介绍:这是瑞士人工
Python爬虫如何快速入门
学而思(xiejava的blog)
03-27
1375
写了几篇网络爬虫的博文后,有网友留言问Python爬虫如何入门?今天就来了解一下什么是爬虫,如何快速的上手Python爬虫。
国内IP代理软件电脑版:深入解析与应用指南
hgdlip的博客
03-29
1016
随着互联网技术的快速发展,网络活动日益丰富多样,IP代理软件也因其独特的功能和优势,成为许多电脑用户不可或缺的工具。在国内,由于网络环境的复杂性和特殊性,选择一款稳定、高效的IP代理软件电脑版尤为重要。虎观代理将深入解析国内IP代理软件电脑版的功能、优势以及应用场景,并为大家提供一些实用的选择和使用建议。
Go语言爬虫实战(线程池)
最新发布
JUIU9527的博客
03-29
1370
可以通过对网站的观察我们可以发现网站各个页面之间微小的变化,然后将需要爬取的网页存储在一个切片当中,之后重复第一步即可。通过观察Html文本中图片的地址,并写出对应的正则表达式,匹配所有符合的图片信息。保存正则表达式的匹配结果,并对其发起GET请求获取图片资源信息。在存储图片的时候,获取图片的后缀以及获取图片原名称来命名图片。细节:通过浏览器的开发者模式,可以更快找到图片的地址。对指定URL发去GET请求,获取对应的响应。通过返回的响应获取网站的Html文本内容。// HandleError 错误。
js逆向之实例某宝热卖(MD5)&爬虫
金灰的博客
03-27
901
page_url:https%3A%2F%2Fuland.taobao.com%2Fsem%2Ftbsearch%3Frefpid%3Dmm_26632258_3504122_32538762%26keyword%3D%25e5%25a5%25b3%25e8%25a3%2585%26clk1%3Da8eba43425e1e5ec18b3b33d575a5619%26upsId%3Da8eba43425e1e5ec18b3b33d575a5619″}’一个断点,果然,停住了,说明调用了. 接着分析.
Python爬虫之XPath和Beautiful Soup的使用
小李学不完的博客
03-26
839
Beautiful Soup是Python的一个HTML或XML的解析库。Beautiful Soup用Python式的函数来处理导航、搜索、修改分析树等功能Beautiful Soup自动将输出文档转化为Unicode编码,将输出文档转化为utf-8编码。
Python爬虫:爬虫常用伪装手段
wq10_12的博客
03-28
975
随着互联网的快速发展,爬虫技术在网络数据采集方面发挥着重要的作用。然而,由于爬虫的使用可能会对被爬取的网站造成一定的压力,因此,很多网站会对爬虫进行限制或封禁。为了规避这些限制,爬虫需要使用一些伪装手段,使自己看起来更像是真实用户。本文将介绍一些常用的爬虫伪装手段,并提供相应的Python代码示例。本文介绍了一些常用的爬虫伪装手段,包括设置User-Agent、设置Referer、使用代理IP以及限制请求频率等。通过使用这些手段,可以让爬虫更好地伪装成真实用户,降低被检测到的概率。
python(一)网络爬取
weixin_51722520的博客
03-28
1564
python(一)网络爬虫
【爬虫开发】爬虫从0到1全知识md笔记第2篇:requests模块,知识点:【附代码文档】
一诺的博客
03-26
1353
爬虫开发从0到1全知识教程完整教程(附代码资料)主要内容讲述:爬虫课程概要,爬虫基础爬虫概述,,http协议复习。requests模块,requests模块1. requests模块介绍,2. response响应对象,3. requests模块发送请求,4. requests模块发送post请求,5. 利用requests.session进行状态保持。数据提取概要,数据提取概述1. 响应内容的分类,2. 认识xml以及和html的区别,1. jsonpat
爬虫实践(1)
qq_43259305的博客
03-26
423
以migu登录为例,分析其登录过程,之后可以使用任意语言模拟登录,获取登录token。
爬虫requests.get中的参数
m0_74455866的博客
03-27
510
爬虫requests.get中的参数
2022年由U.S.news指出的美国大学ims专业排名是什么样的
02-18
2022年,根据U.S.News的报告,美国排名最高的IMS专业大学包括:哈佛大学,斯坦福大学,加州大学伯克利分校,宾夕法尼亚大学,芝加哥大学,卡耐基梅隆大学,约翰霍普金斯大学,康奈尔大学,杜克大学,加州大学洛杉矶分校,罗格斯大学新伯朗士威校区,乔治城大学,威斯康星大学麦迪逊分校,哥伦比亚大学,乔治华盛顿大学,爱荷华州立大学,圣母大学和维克森林大学。
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助
-

 没帮助
没帮助
-

 一般
一般
-

 有帮助
有帮助
-

 非常有帮助
非常有帮助
提交
window.csdn.csdnFooter.options = {
el: ‘.blog-footer-bottom’,
type: 2
}
东离与糖宝

CSDN认证博客专家
CSDN认证企业博客
码龄3年

Java领域优质创作者
- 111
- 原创
- 72
- 周排名
- 280
- 总排名
- 39万+
- 访问
-

- 等级
- 3万+
- 积分
- 1万+
- 粉丝
- 1万+
- 获赞
- 1万+
- 评论
- 1万+
- 收藏
















 私信
关注
私信
关注
![]()


热门文章
-
python超详细基础文件操作【建议收藏】
28645
-
Mybatis-Plus 实现增删改查 — Mybatis-Plus 快速入门保姆级教程(一)
23736
-
初级爬虫实战——人民网
22342
-
一文带你深入浅出Web的自动化测试工具Selenium 4.xx【建议收藏】
17507
-
Spring概述与核心概念学习 — Spring入门(一)
16266
分类专栏
-

蓝桥杯省赛Java历年真题及解析
8篇
-

合作推广
19篇
-

python爬虫理论与实战
11篇
-

MongoDB
8篇
-

从全栈开发到前后端部署项目实例
-

资源分享
-

代码随想录算法训练营
-

mysql
3篇
-
vue
6篇
-

mybatis
3篇
-

SSM项目实例
12篇
-

SpringMVC
5篇
-

前后端软件安装与环境配置
2篇
-

纪念日
1篇
-

JAVA基础
4篇
-

Spring入门
8篇
-

mybatis-plus入门
2篇
-

操作系统
4篇
-

SpringBoot
3篇
-

Git
1篇
-

Redis
3篇
-

Nginx
1篇
-

HTTP
1篇
-

JS
1篇

最新评论
您愿意向朋友推荐“博客详情页”吗?
-
强烈不推荐
-
不推荐
-
一般般
-
推荐
-
强烈推荐
提交
最新文章
-
第十三届蓝桥杯国赛真题 Java C 组【原卷】
-
第十三届蓝桥杯省赛真题 Java 研究生 组【原卷】
-
第十三届蓝桥杯省赛真题 Java A 组【原卷】
2024年27篇
2023年84篇
目录
$(“a.flexible-btn”).click(function(){
$(this).parents(‘div.aside-box’).removeClass(‘flexible-box’);
$(this).parents(“p.text-center”).remove();
})
服务器托管,北京服务器托管,服务器租用,机房机柜带宽租用

咨询:董先生
电话13051898268 QQ/微信93663045!
上一篇: mysql的日志文件在哪?
下一篇: 30天拿下Rust之命令行参数

GUNDAM.:
这篇博客写得真是太棒了!作者的语言流畅、清晰,让我一下子就被吸引住了,文章结构紧凑,逻辑清晰,让我能够轻松地跟随作者的思路。此外,作者运用了丰富的例子和引用,为观点提供了很好的支持和证明。
Seal^_^:

第十三届蓝桥杯国赛真题 Java C 组【原卷】
愚润求学:
感谢博主分享,期待博主下一篇优质好文
东离与糖宝:
感谢GOTXX大佬支持!
东离与糖宝:
感谢悦心无谓大佬支持!