


引言
Stable Diffusion 是一个开源的深度学习模型,主要利用文本描述生成高质量的图像,还可以图生图、模型合并、模型训练等。Stable Diffusion 的操作界面如下图所示:
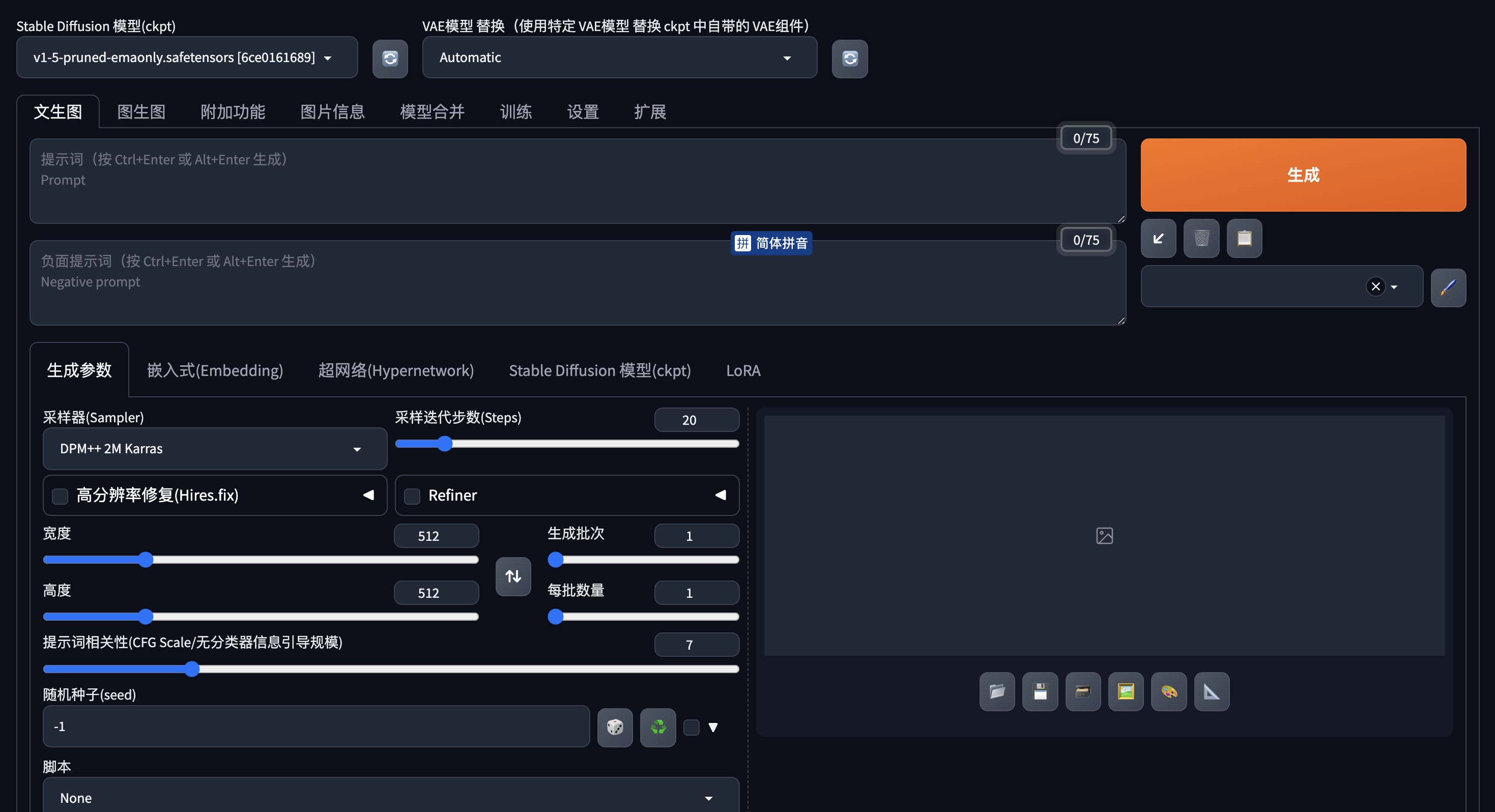
如何生图
下面介绍一下小鹿喝水的生图过程,生成图的时候分为提示词和负面提示词,输入提示词的时候要明确描述,尽量具体描述你想要的场景、对象、风格和颜色。例如,不仅仅说“小鹿喝水”,而是说“一条小溪,旁边是茂密的树,小溪旁有小鹿在喝水”,负面提示词是反方向的例如:无建筑物、无人物、无桥梁、无围栏,而过于模糊的描述可能导致结果不符合预期。

Stable Diffusion的核心优势
优势
对于AI绘画类的应用现在有很多,那么Stable Diffusion的核心优势是什么?
与其他许多AI绘画工具相比,Stable Diffusion 是完全开源的,这意味着任何人都可以免费使用、修改和分发它,可自己训练模型。有多种风格绘画,并且在 civitai(国外) 和 哩布哩布 AI (国内)有很多种风格的模型,动漫游戏、建筑空间设计、二次元、3D立体、Logo图标等等。。。
之前看到一篇文章说,付费是自动档,Stable Diffusion 相当于手动档。
那么 Stable Diffusion 在众多AI绘画类应用中脱颖而出,主要得益于以下几个核心优势:
-
与其他许多AI绘画工具相比,Stable Diffusion是完全开源的,这意味着任何人都可以免费使用,并且可以在原有的基础上去开发让用户去注册。
-
Stable Diffusion支持高度的自定义,用户可以调整模型参数以生成符合特定风格或需求的图像。有能力的用户甚至可以对训练模型。
-
Stable Diffusion能够生成高分辨率、视觉上令人印象深刻的图像。它利用先进的深度学习技术,能够根据文本描述生成细腻、复杂的图像。
-
Stable Diffusion特别擅长根据文本提示生成图像,可以用简单的描述来创造出自己想要的图。
-
Stable Diffusion在艺术创作、娱乐产业、广告、教育、以及自己搞副业很多领域都有涉及。
使用场景
可以通过某音、某手和某书发布一些作品,AI绘画这个东西在自媒体上目前还不是很普遍,流量也是蛮不错的。想在在这些平台上变现,关键在于持续地产生高质量、吸引人的内容,要积极与粉丝互动,建立粉丝群体。
分享一个我一直在做的事,通过GPT帮我生成文案在(某音)做图文的视频,通过文案来生成图片,多张图片组合成一个视频,流量的高低主要还是来源图片的质量。
在某音还有很多图片工具(我用的是蓝猫壁纸),这种图片工具是让粉丝去这里下载图片,下载之前必须要先看广告,可以把生成的高质量头像、壁纸、logo放入工具里面,来赚取广告收益。
还可以:
-
有流量之后可以做定制,根据客户的需求来定制独一无二的画作,对于宝妈们定制宝宝头像之类。
-
在线下可以做AI绘画摆摊,需要笔记本电脑和打印机就可以支撑起来一个摊位,比如在大学城或者夜市人流量比较多的地方。
-
可以根据图生图的能力来画肖像画,再通过售卖的方式进行变现。
安装部署
前提条件
-
需要安装 Rainbond,Rainbond 是一个不需要懂 Kubernetes 的云原生应用管理平台,部署应用不需要复杂的配置。
-
部署 Stable Diffusion 机器配置不少于CPU:8核,内存:16GB。
步骤
-
进入 Rainbond 平台管理,侧边栏选择项目团队,创建你的第一个团队。
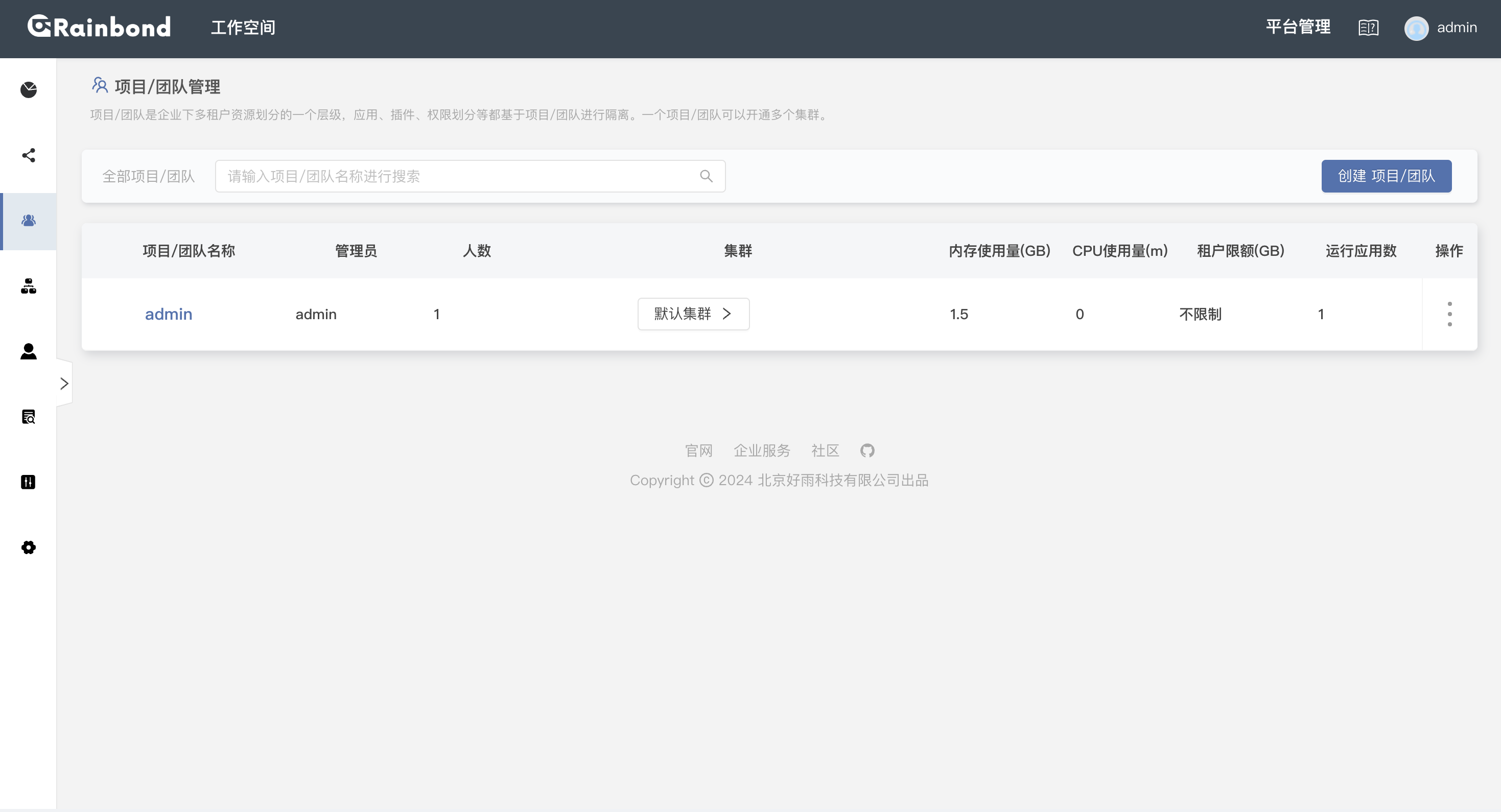
-
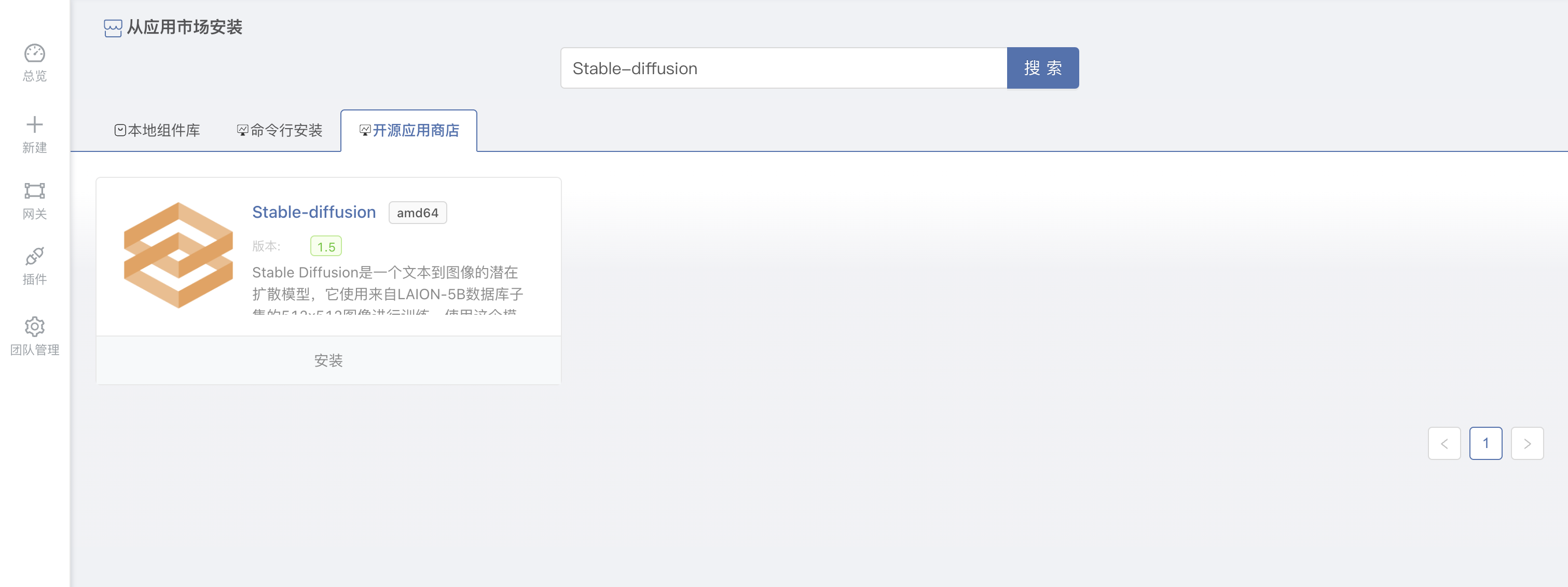
点击进入团队后 – 新建应用 – 外部应用市场 – 选择开源应用商店 – 搜索 Stable-diffusion。
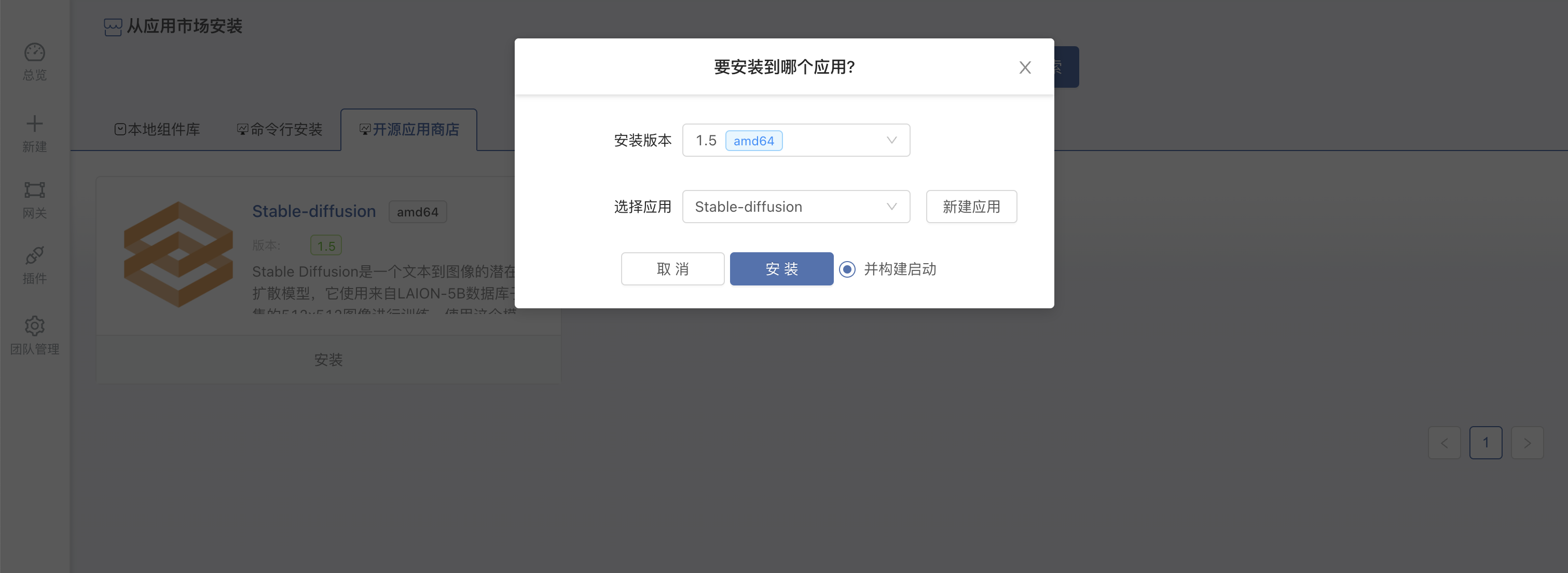
可以选择应用版本安装 Stable-diffusion 应用。
-
创建成功之后在应用视图的拓扑图中可以看到 Stable-diffusion 应用。
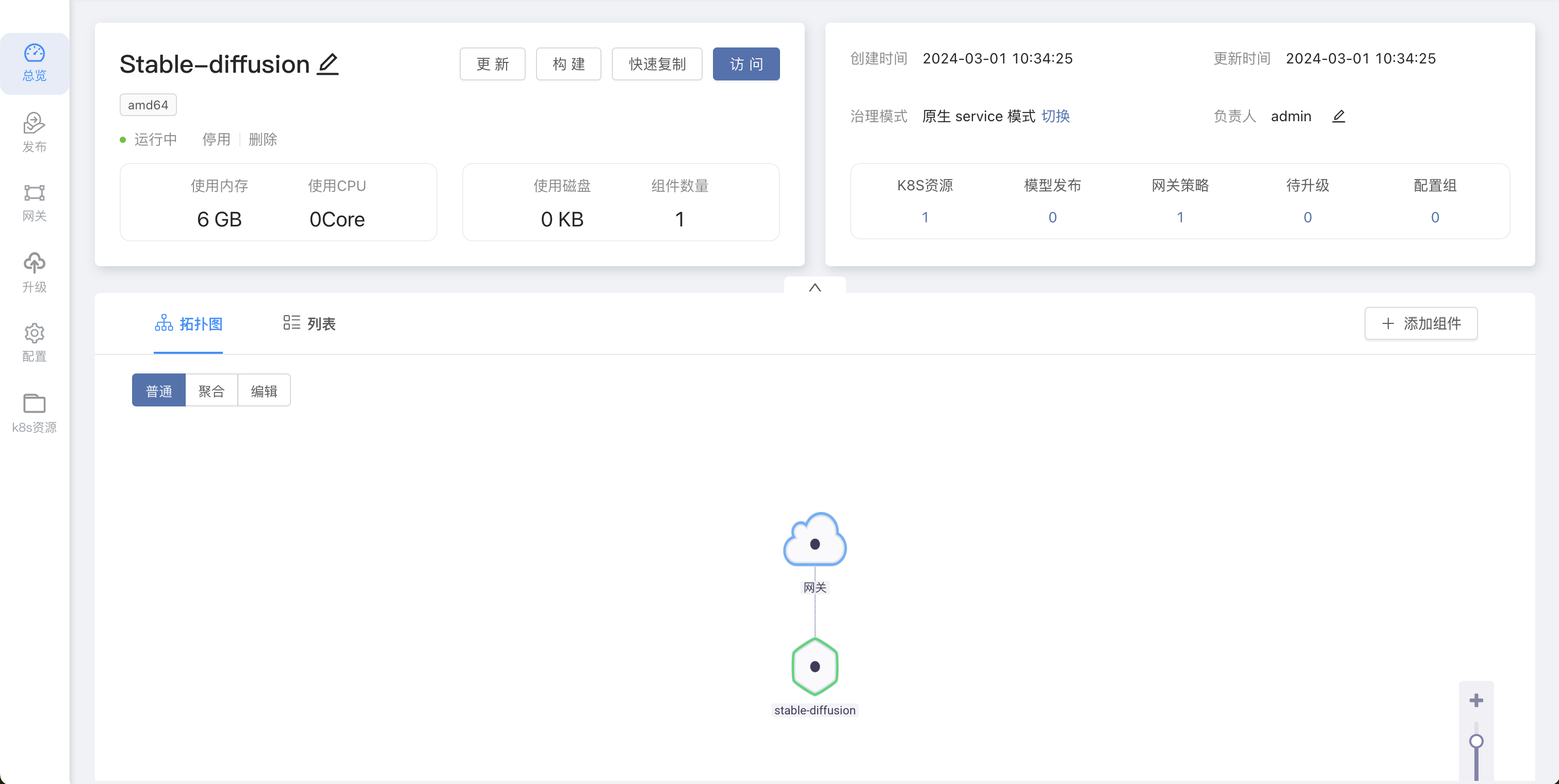
-
点击左侧网关 – 点击当前组件网关 – 编辑 – 开启 WebSocket支持。
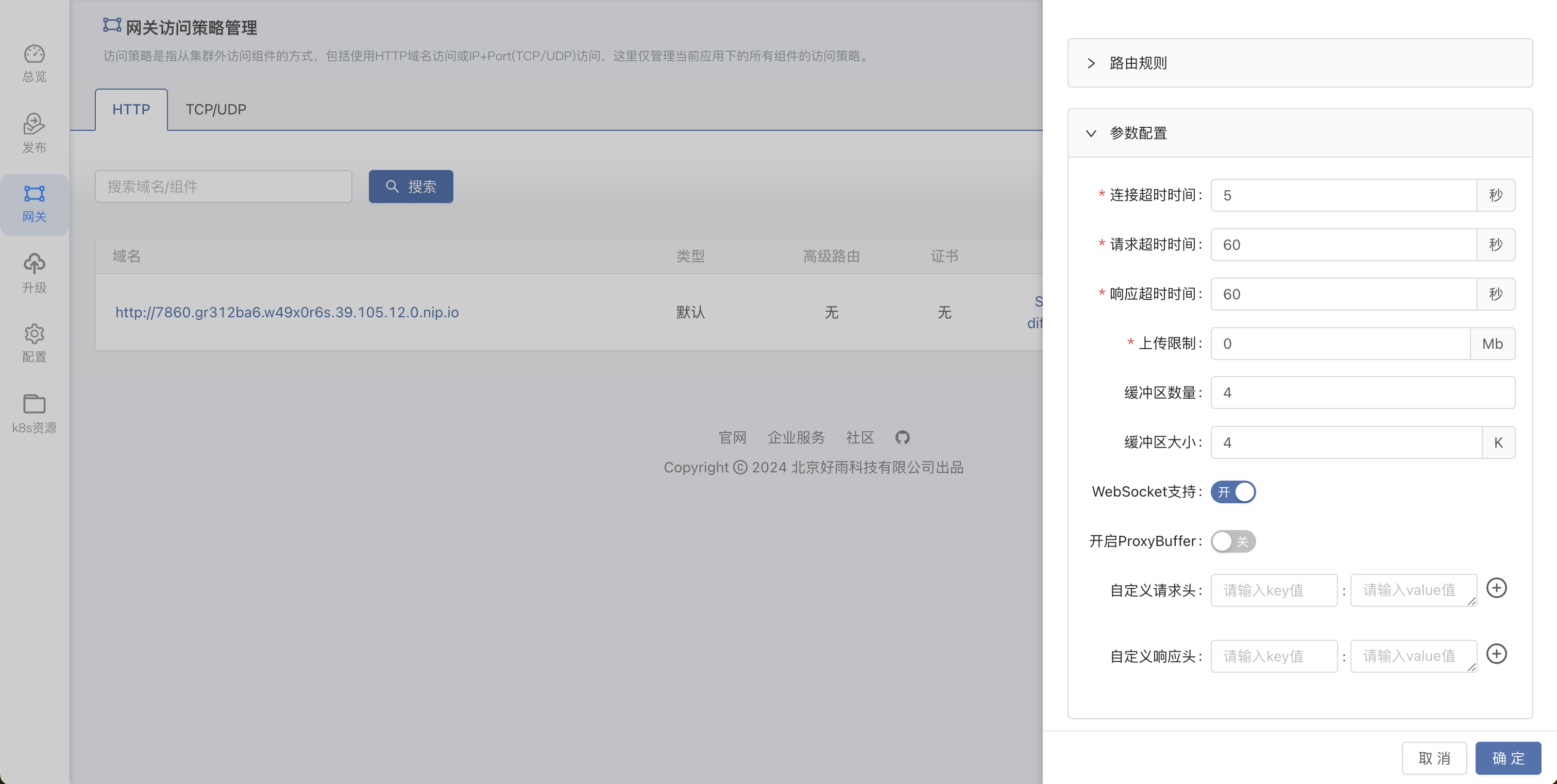
-
进入组件等待初始化文件 – 查看日志(解压过程较慢请稍等)。
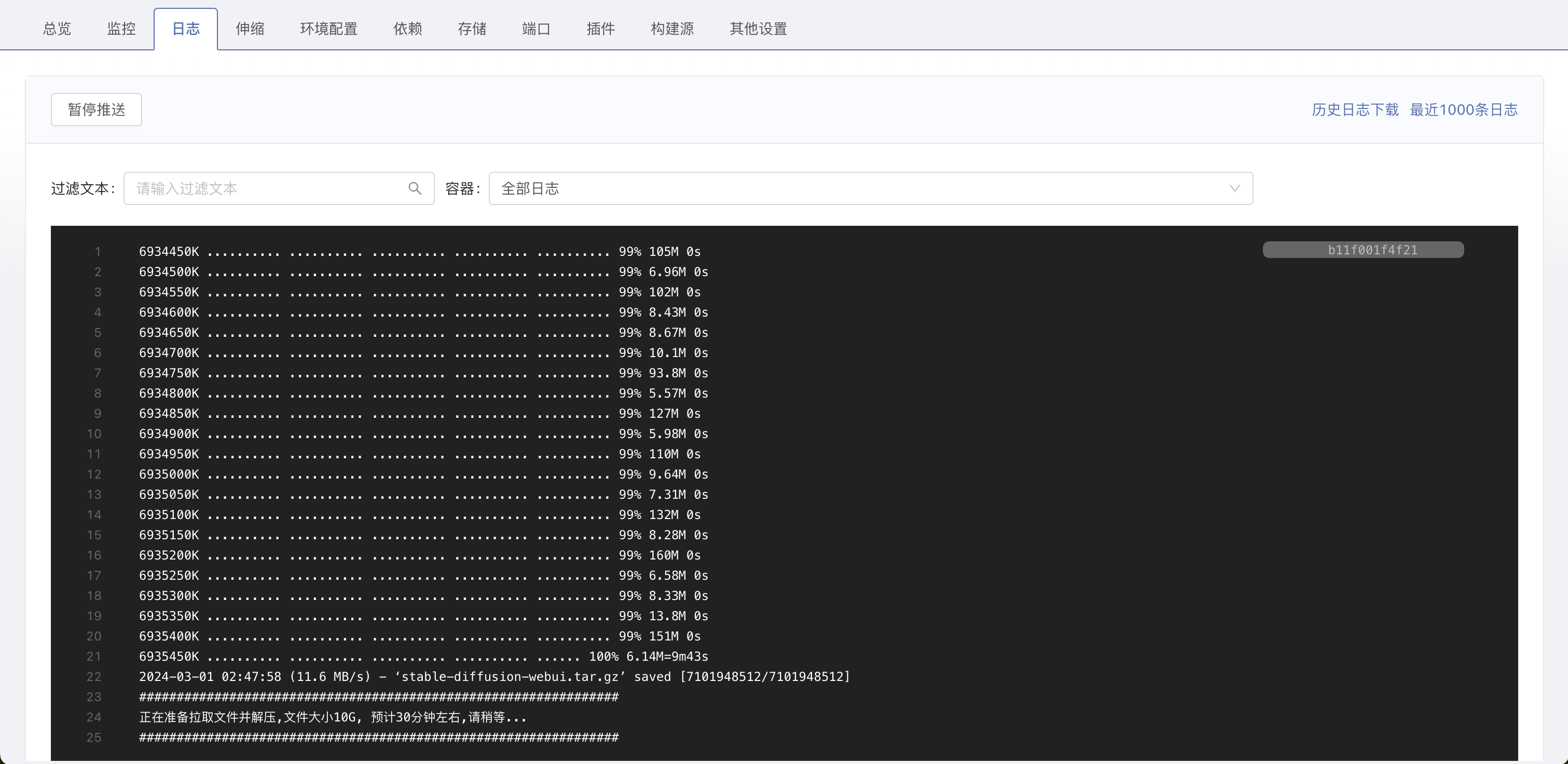
-
看到此日志代表启动成功可以访问。
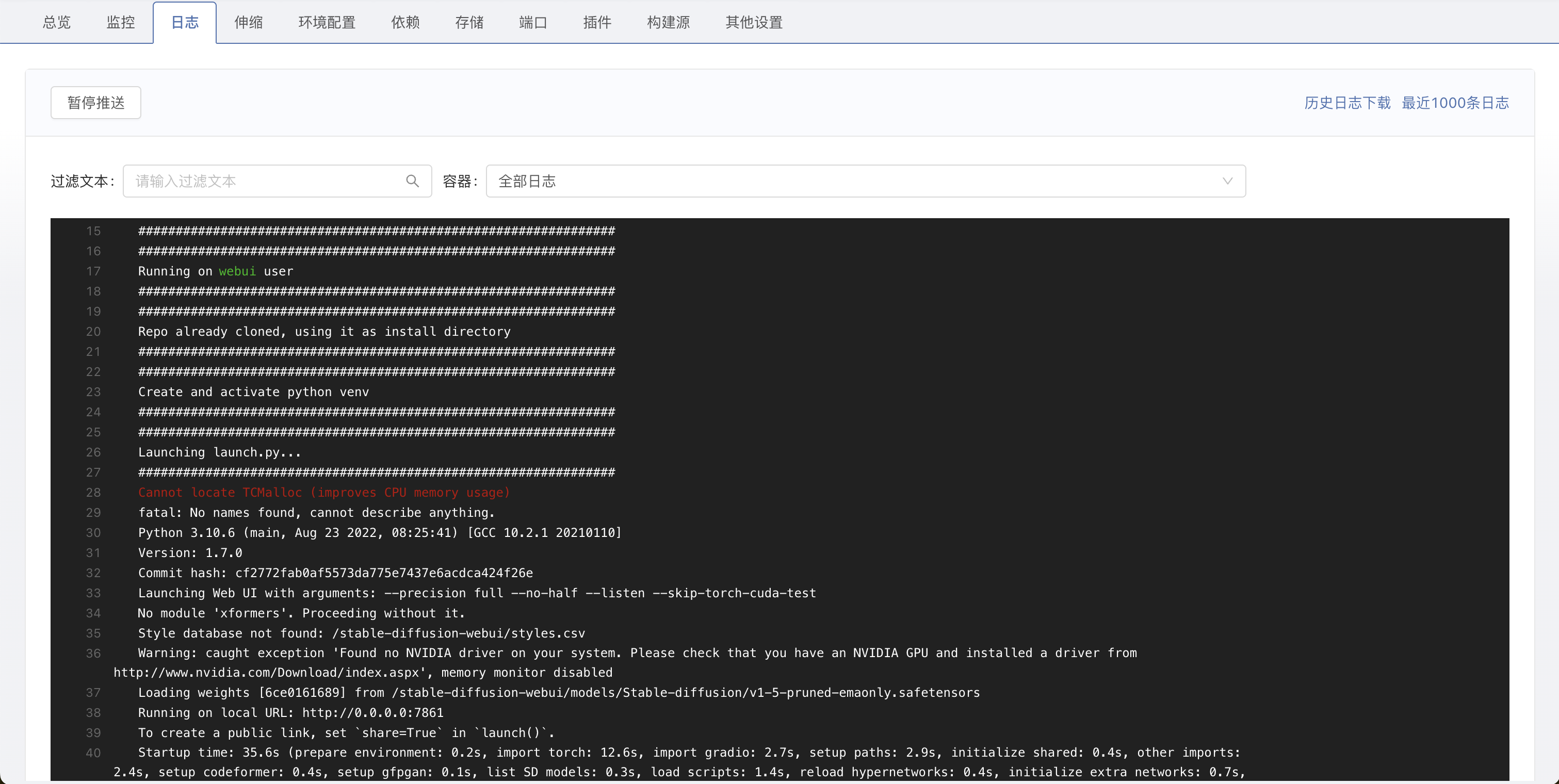
-
点击右上角的访问按钮就可以访问 Stable-diffusion 了。
-
Stable-diffusion 界面,在制作这个应用的时候还加入了中文语言包。
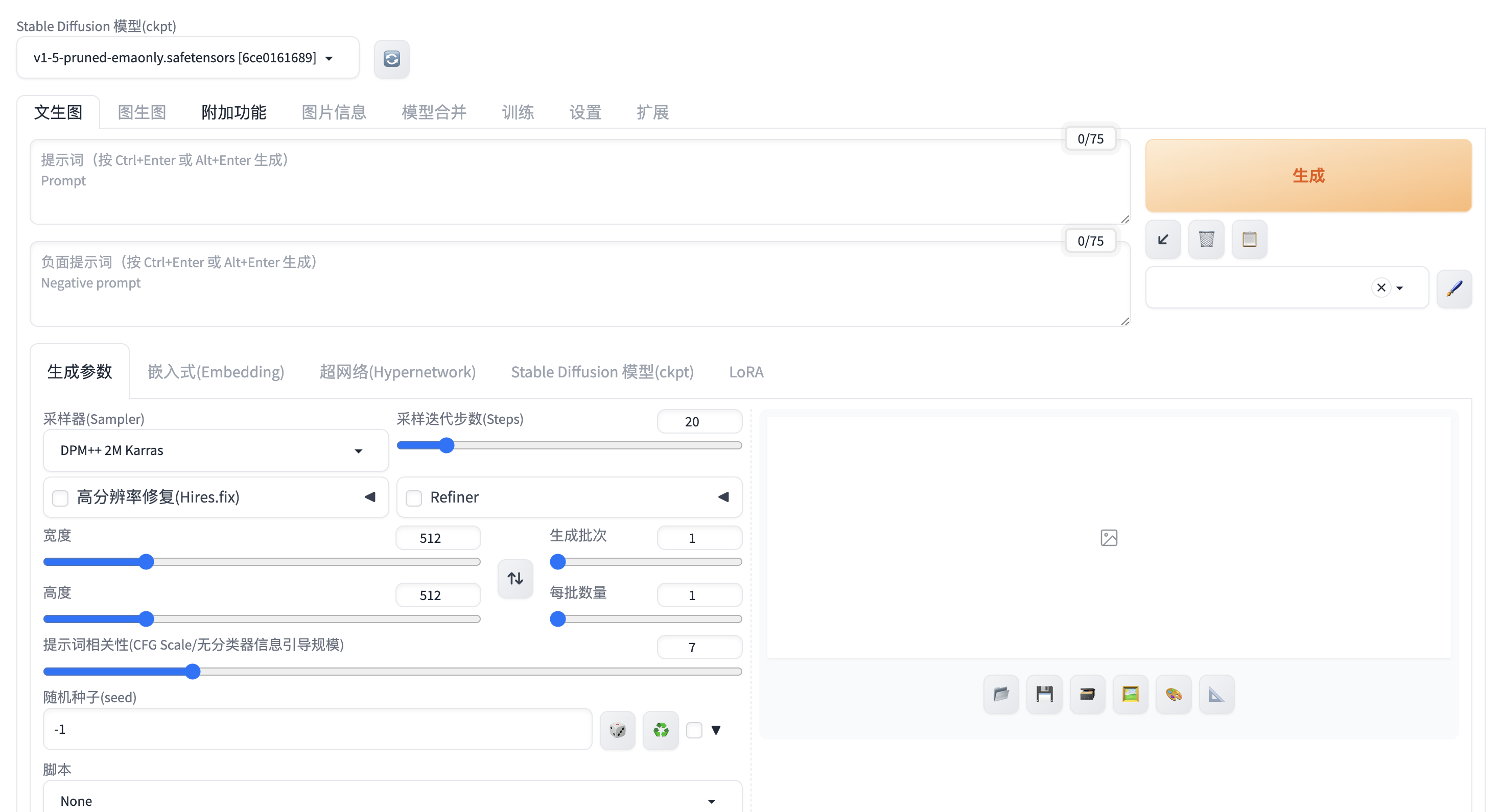
-
到这里就已经完成安装了,可以尝试去生成想要的图了。

关注我后续还会发布一篇文章告诉大家怎么上传多个模型以及提示词的详细使用教程。
