

文章目录
- 发现宝藏
- 一、 目标
- 二、简单分析网页
-
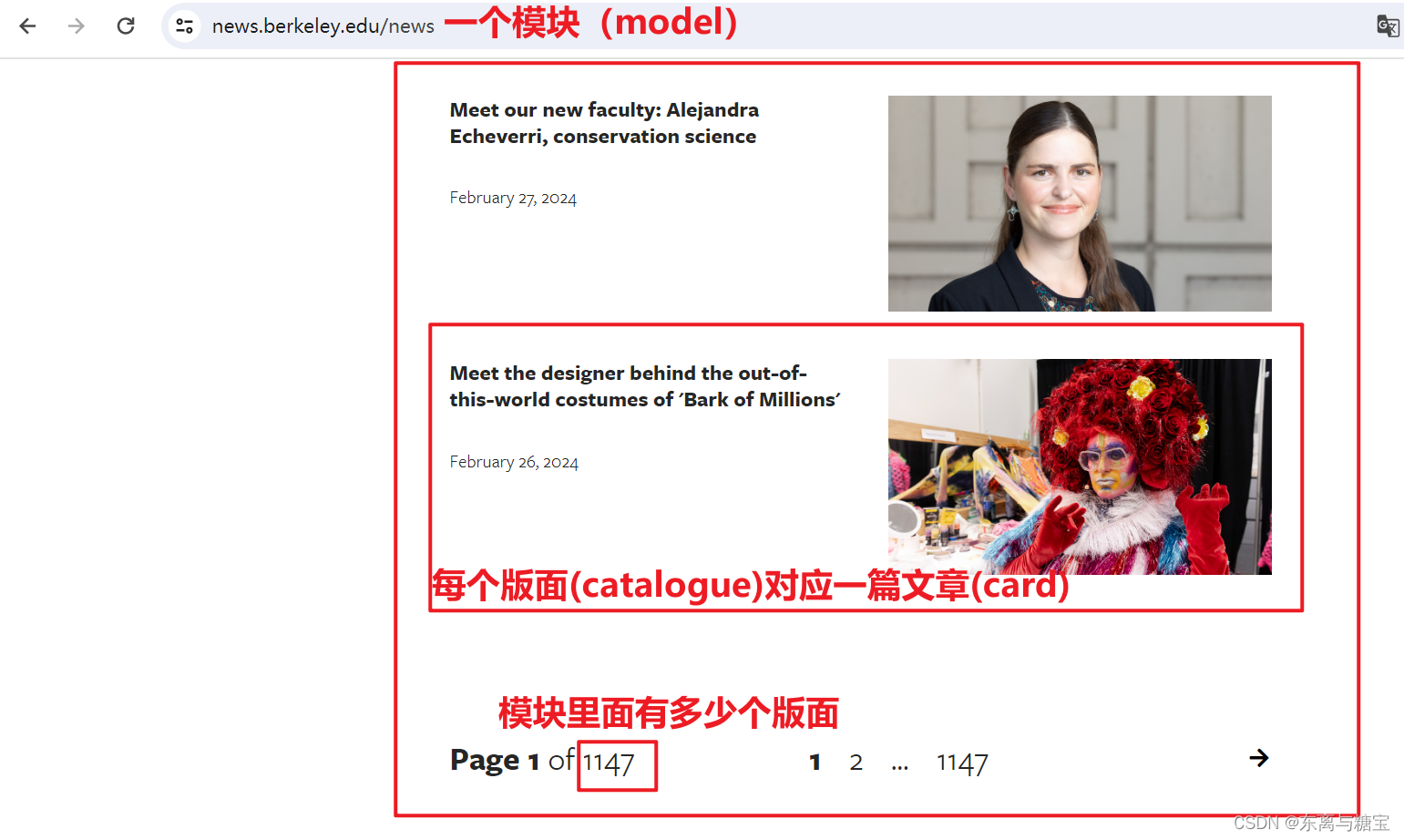
- 1. 寻找所有新闻
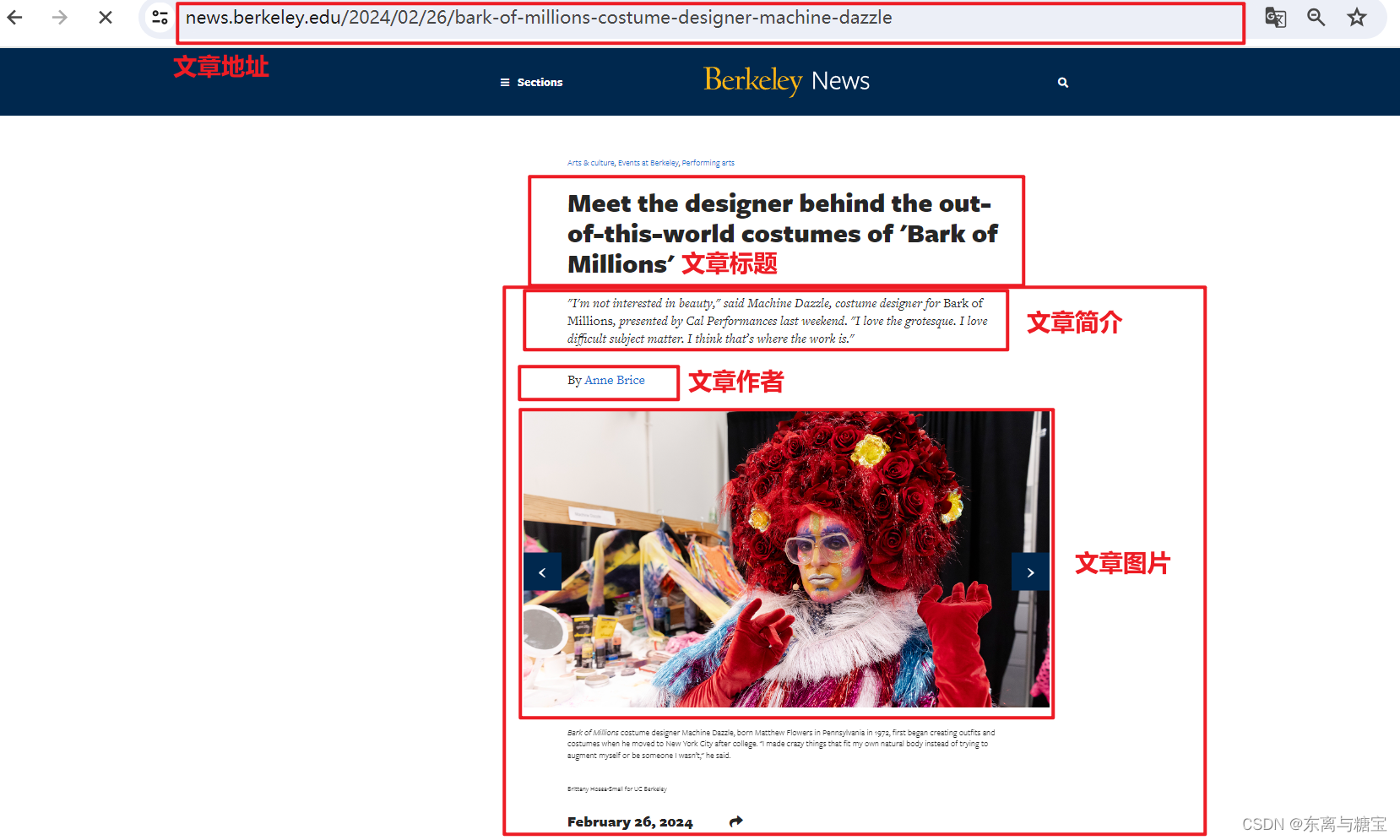
- 2. 分析模块、版面和文章
- 三、爬取新闻
-
- 1. 爬取模块
- 2. 爬取版面
- 3. 爬取文章
- 四、完整代码
- 五、效果展示
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。
一、 目标
爬取https://news.berkeley.edu/的字段,包含标题、内容,作者,发布时间,链接地址,文章快照 (可能需要翻墙才能访问)
二、简单分析网页
1. 寻找所有新闻

2. 分析模块、版面和文章
我们可以按照新闻模块、版面、和文章对网页信息进行拆分,分别按照步骤进行爬取
三、爬取新闻
1. 爬取模块
由于该新闻只有一个模块,所以直接请求该模块地址即可获取该模块的所有信息,但是为了兼容多模块的新闻,我们还是定义一个数组存储模块地址
class MitnewsScraper:
def __init__(self, root_url, model_url, img_output_dir):
self.root_url = root_url
self.model_url = model_url
self.img_output_dir = img_output_dir
self.headers = {
'Referer': 'https://news.berkeley.edu/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/122.0.0.0 Safari/537.36',
'Cookie': '替换成你自己的',
}
...
def run():
# 根路径
root_url = 'https://news.berkeley.edu/'
# 模块地址数组
model_urls = ['https://news.berkeley.edu/news']
# 文章图片保存路径
output_dir = 'D://imgs//berkeley-news'
for model_url in model_urls:
scraper = MitnewsScraper(root_url, model_url, output_dir)
scraper.catalogue_all_pages()
if __name__ == "__main__":
run()
多模块的新闻网站例子如下(4个模块)
2. 爬取版面
- f12打开控制台,点击网络(network),通过切换页面观察接口的参数传递,发现只有一个page参数
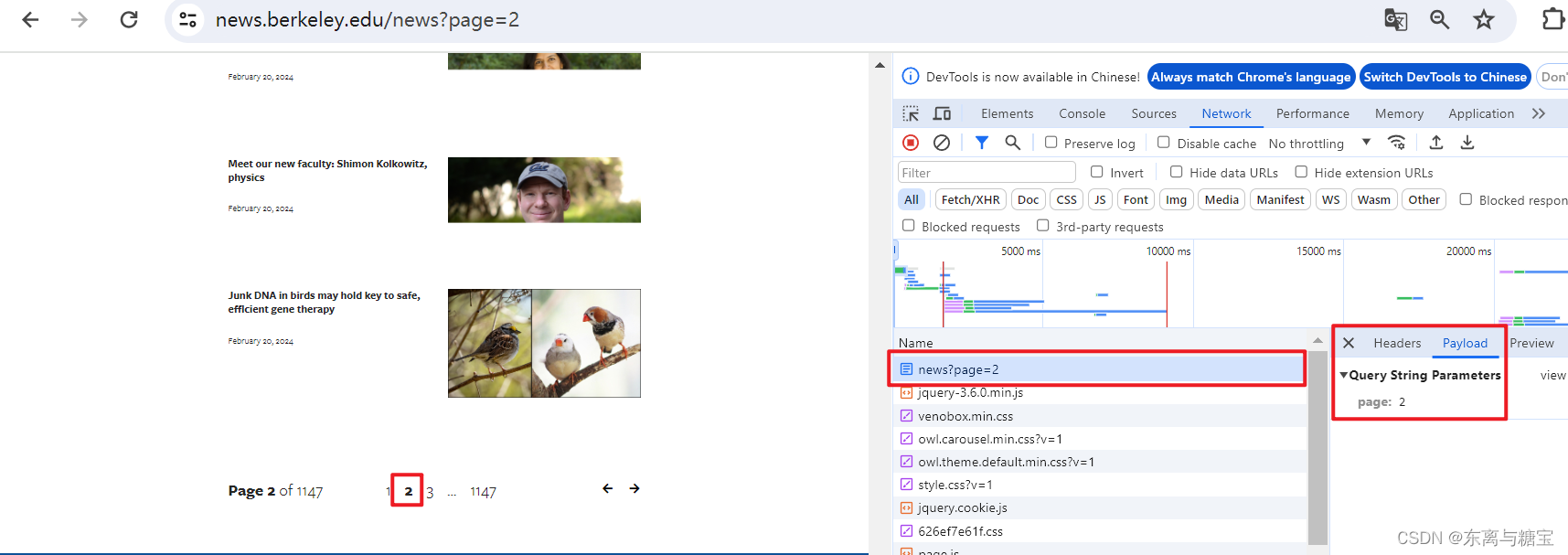
- 于是我们可以获取页面下面的页数(page x of xxxx), 然后进行遍历传参,也就遍历获取了所有版面

# 获取一个模块有多少版面
def catalogue_all_pages(self):
response = requests.get(self.model_url, headers=self.headers)
soup = BeautifulSoup(response.text, 'html.parser')
try:
match = re.search(r'of (d+)', soup.text)
num_pages = int(match.group(1))
print('模块一共有' + str(num_pages) + '页版面,')
for page in range(1, num_pages + 1):
self.parse_catalogues(page)
print(f"========Finished modeles page {page}========")
except:
return False
- F12打开控制台后按照如下步骤获取版面列表对应的dom结构
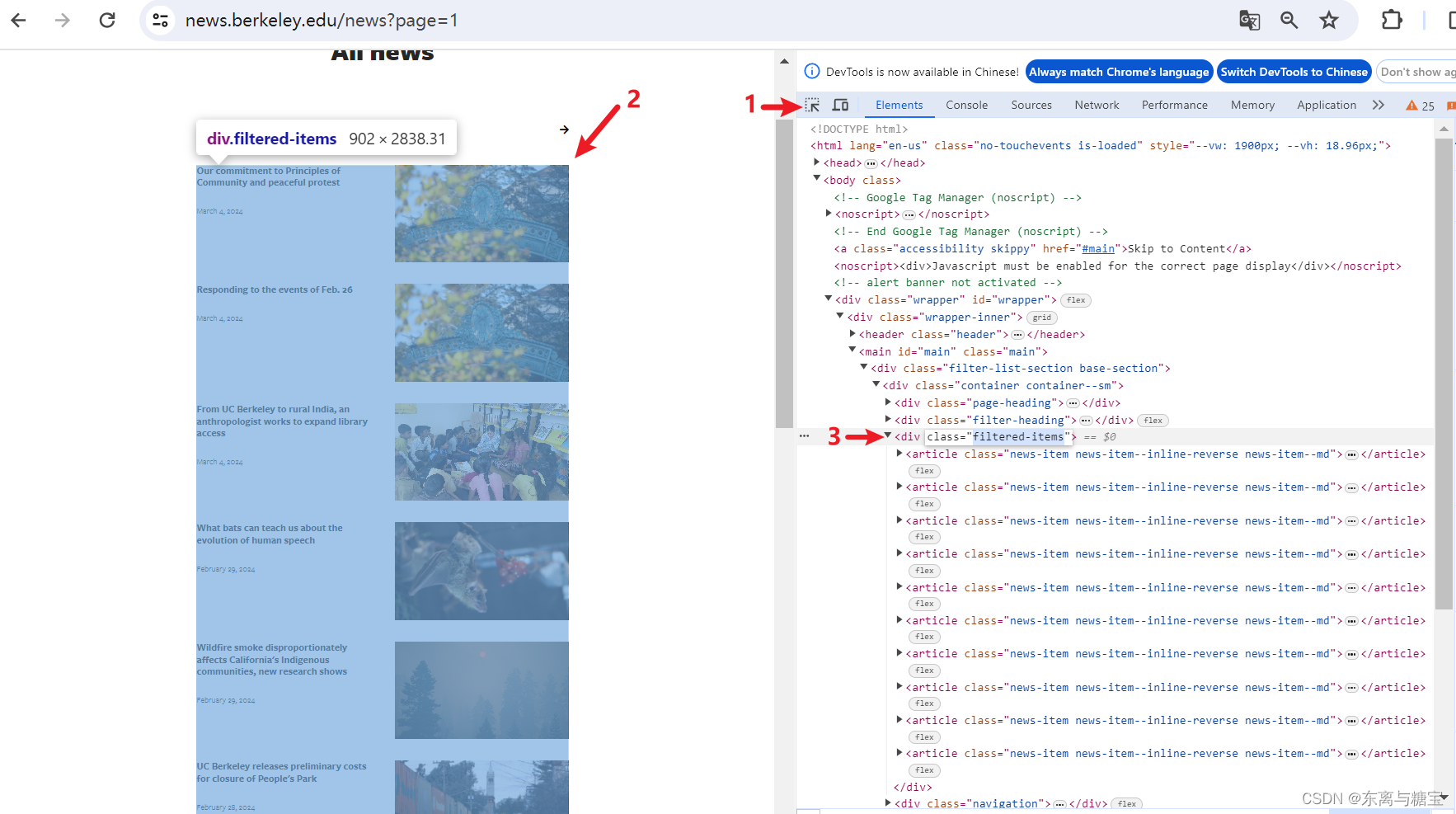
catalogue_list = soup.find('div', 'filtered-items')
catalogues_list = catalogue_list.find_all('article')
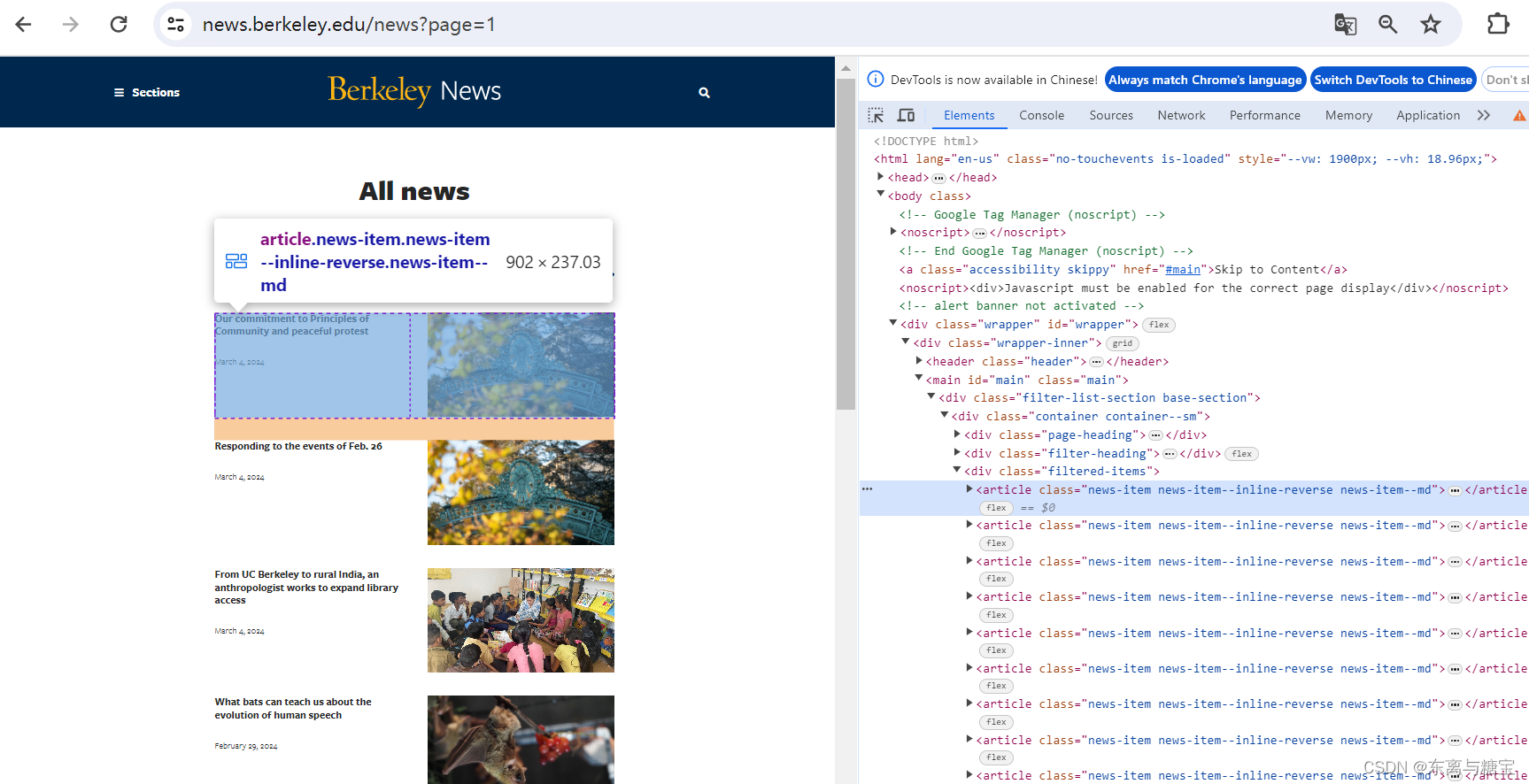
- 遍历版面列表,获取版面标题
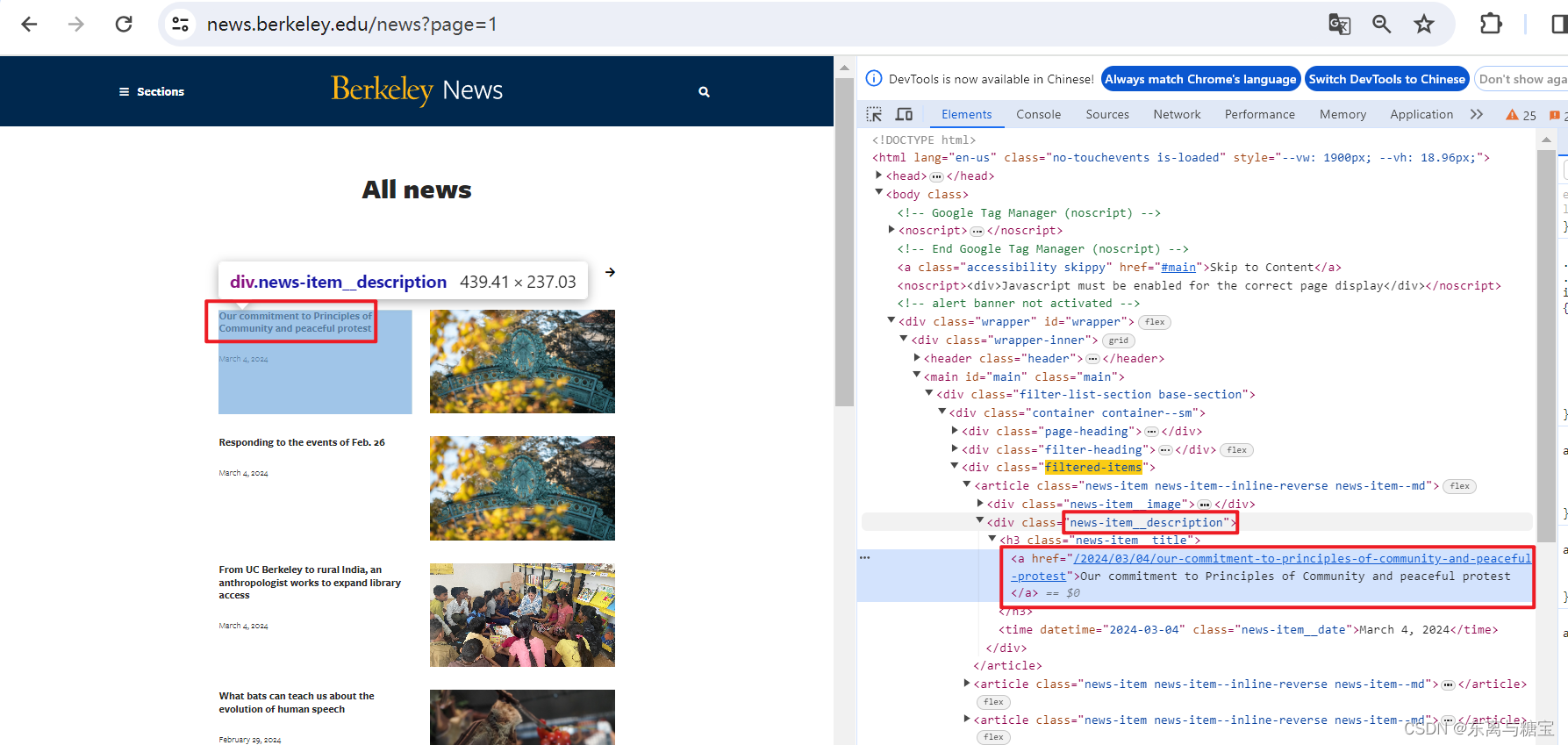
for index, catalogue in enumerate(catalogues_list):
# 版面标题
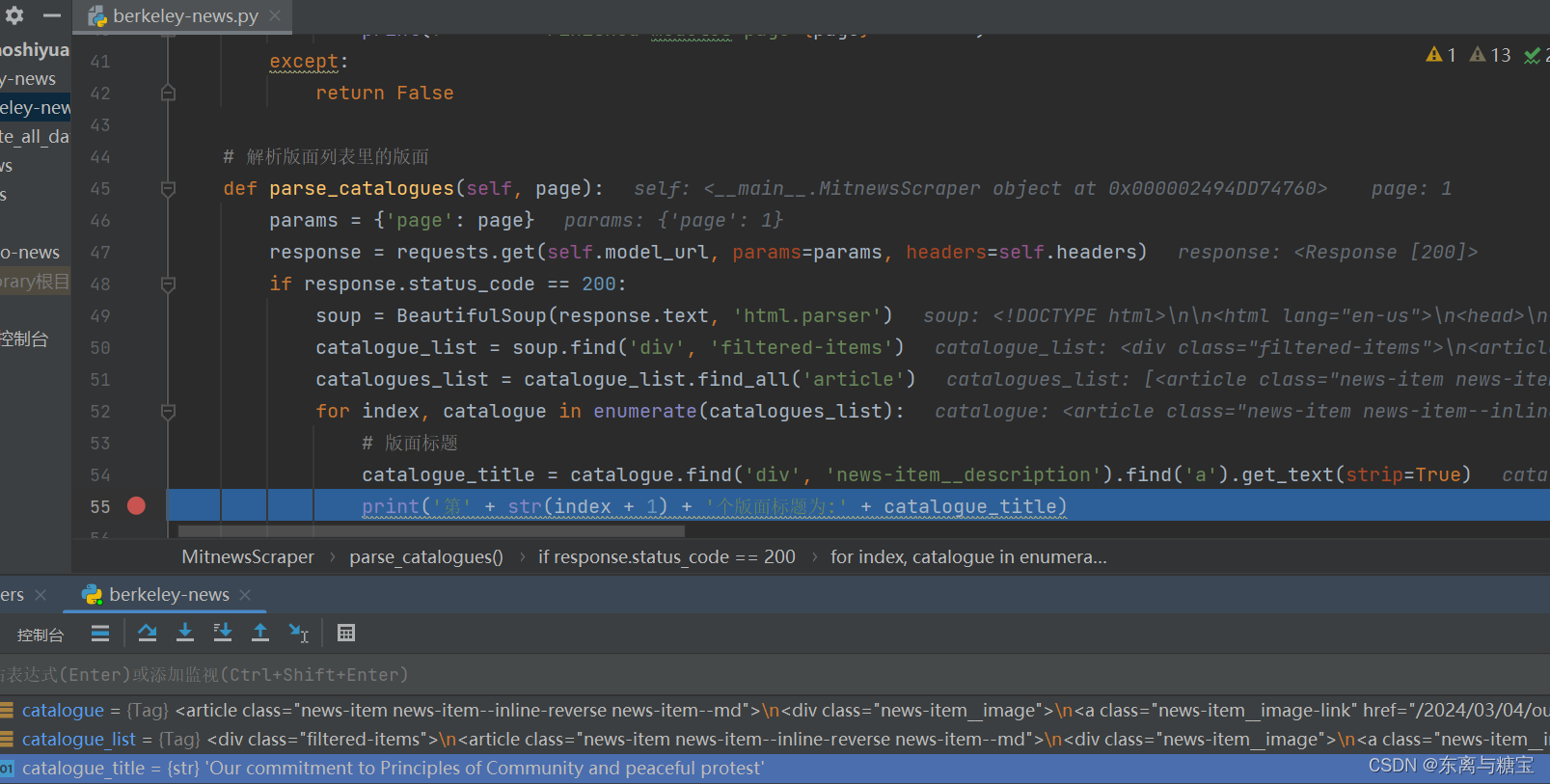
catalogue_title = catalogue.find('div', 'news-item__description').find('a').get_text(strip=True)
print('第' + str(index + 1) + '个版面标题为:' + catalogue_title)
- 获取版面更新时间和当下的操作时间

# 操作时间
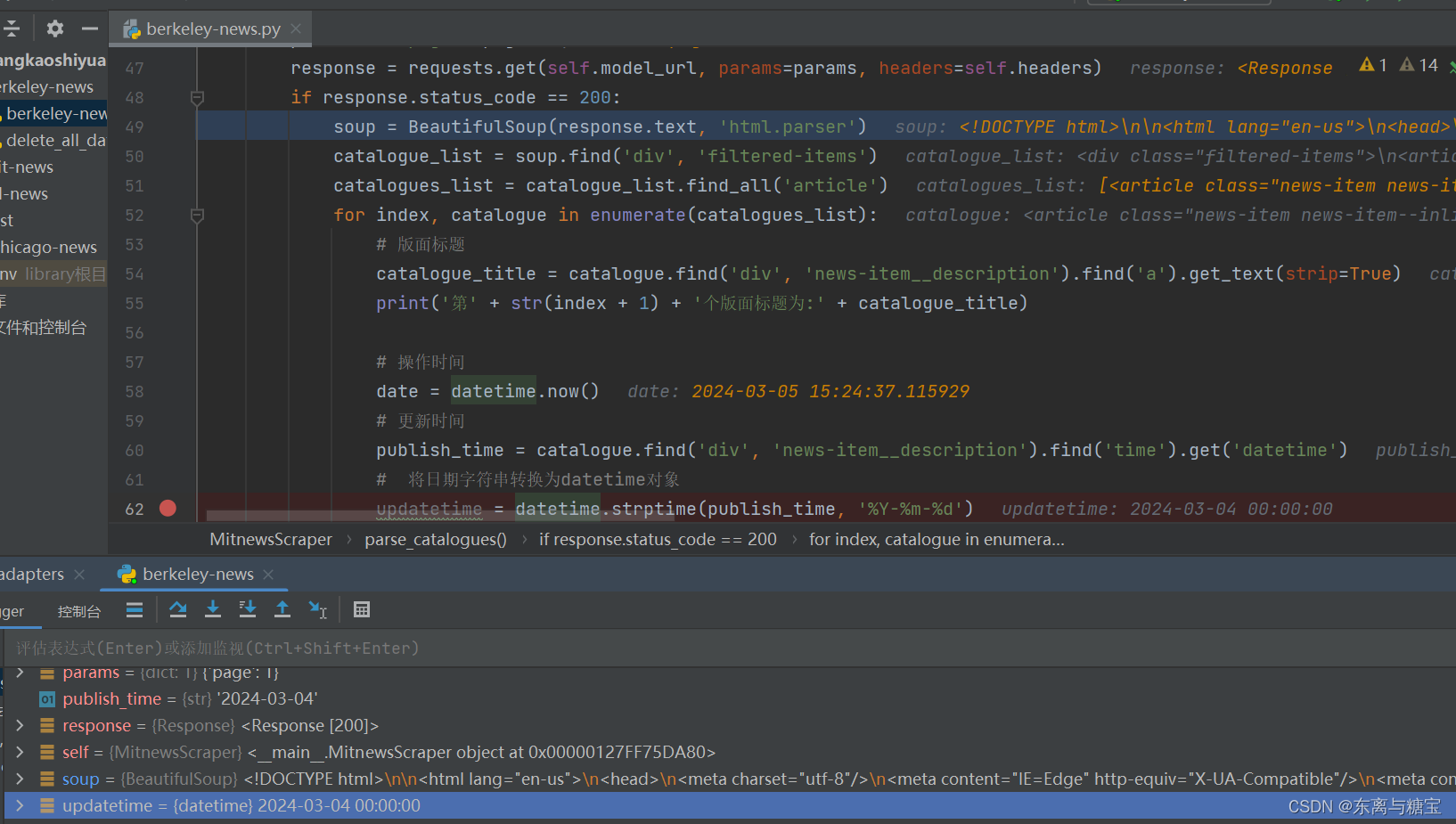
date = datetime.now()
# 更新时间
publish_time = catalogue.find('div', 'news-item__description').find('time').get('datetime')
# 将日期字符串转换为datetime对象
updatetime = datetime.strptime(publish_time, '%Y-%m-%d')
- 保存版面url和版面id, 由于该新闻是一个版面对应一篇文章,所以版面url和文章url是一样的,而且文章没有明显的标识,我们把地址后缀作为文章id,版面id则是文章id后面加上个01, 为了避免标题重复也可以把日期前缀也加上去
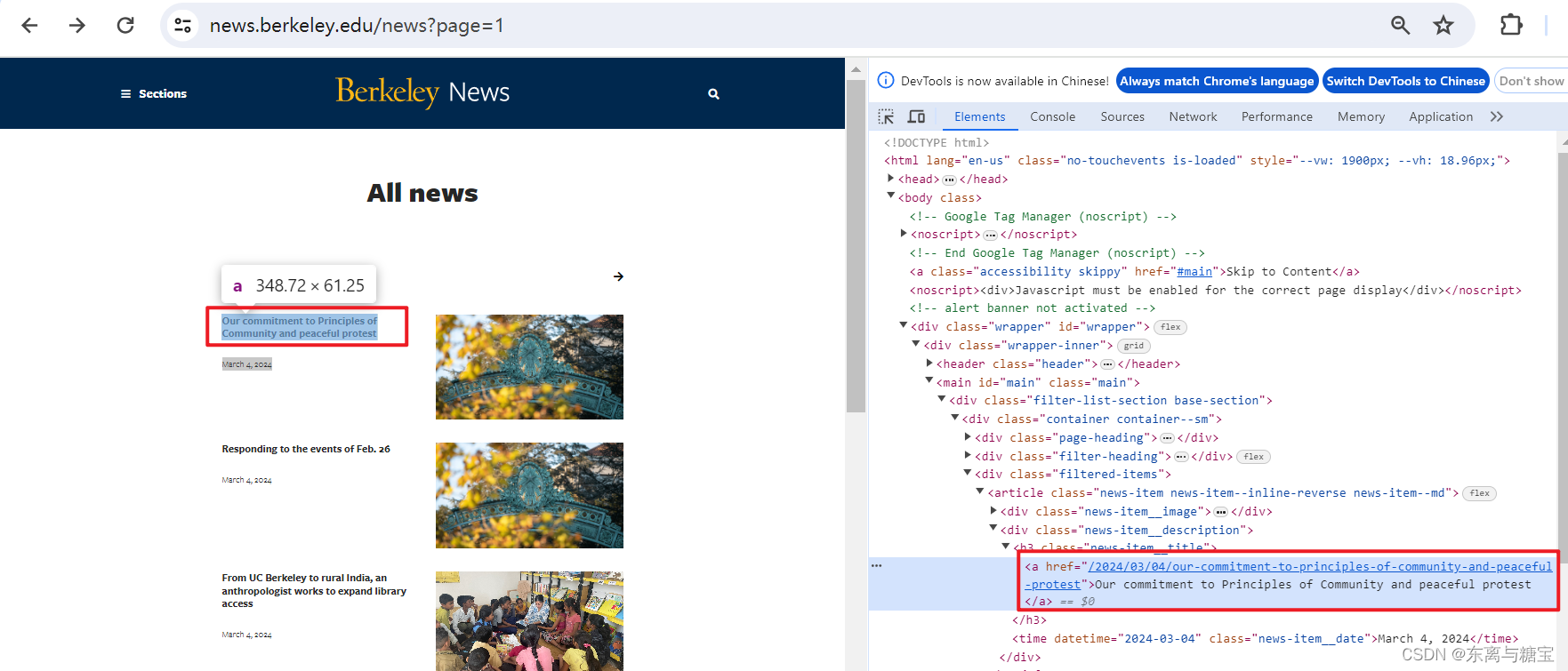

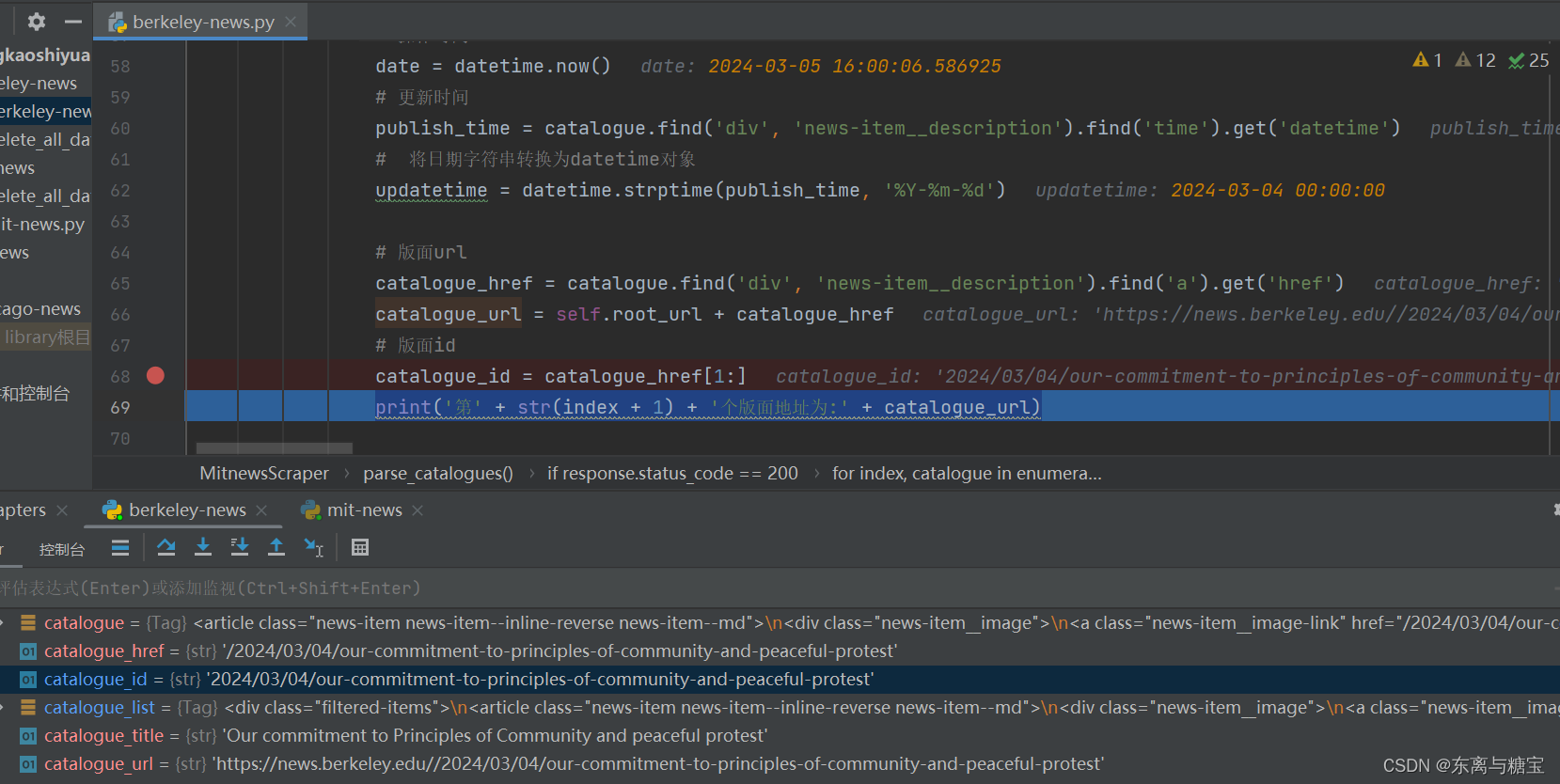
# 版面url
catalogue_href = catalogue.find('div', 'news-item__description').find('a').get('href')
catalogue_url = self.root_url + catalogue_href
# 版面id
catalogue_id = catalogue_href[1:]
print('第' + str(index + 1) + '个版面地址为:' + catalogue_url)
- 保存版面信息到mogodb数据库(由于每个版面只有一篇文章,所以版面文章数量cardsize的值赋为1)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['berkeley-news']
# 创建或选择集合
catalogues_collection = db['catalogues']
# 插入示例数据到 catalogues 集合
catalogue_data = {
'id': catalogue_id + '01',
'date': date,
'title': catalogue_title,
'url': catalogue_url,
'cardSize': 1,
'updatetime': updatetime
}
3. 爬取文章
-
由于一个版面对应一篇文章,所以版面url 、更新时间、标题和文章是一样的,并且按照设计版面id和文章id的区别只是差了个01,所以可以传递版面url、版面id、更新时间和标题四个参数到解析文章的函数里面
-
获取文章id,文章url,文章更新时间和当下操作时间
# 解析版面
def parse_catalogues(self, page):
...
self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)
...
# 解析文章
def parse_cards_list(self, url, catalogue_id, updatetime, cardtitle):
card_response = requests.get(url, headers=self.headers)
soup = BeautifulSoup(card_response.text, 'html.parser')
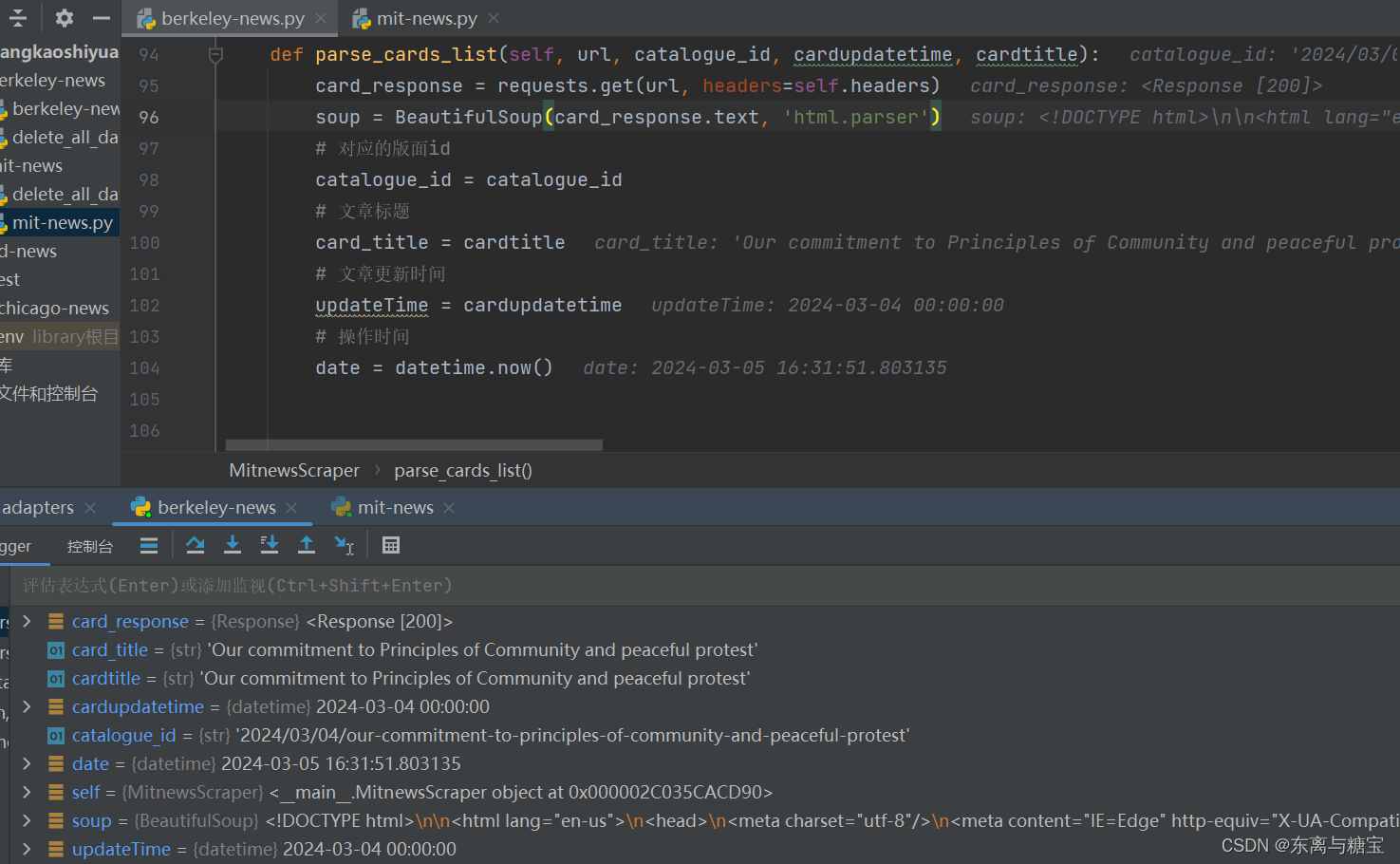
- 获取文章作者
# 文章作者
author = soup.find('a', href='/author/news').get_text()
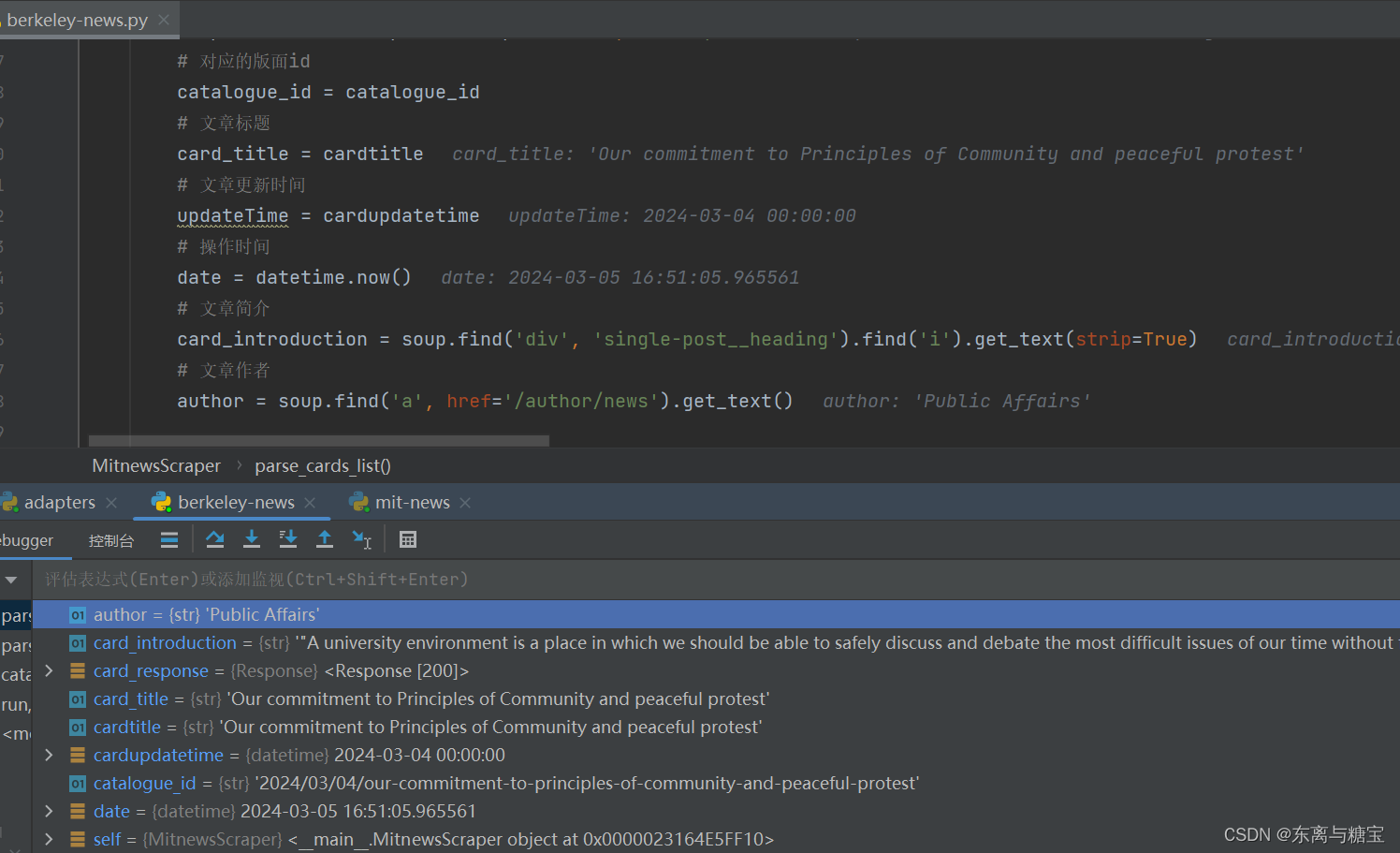
- 获取文章原始htmldom结构,并删除无用的部分(以下仅是部分举例),用html_content字段保留原始dom结构
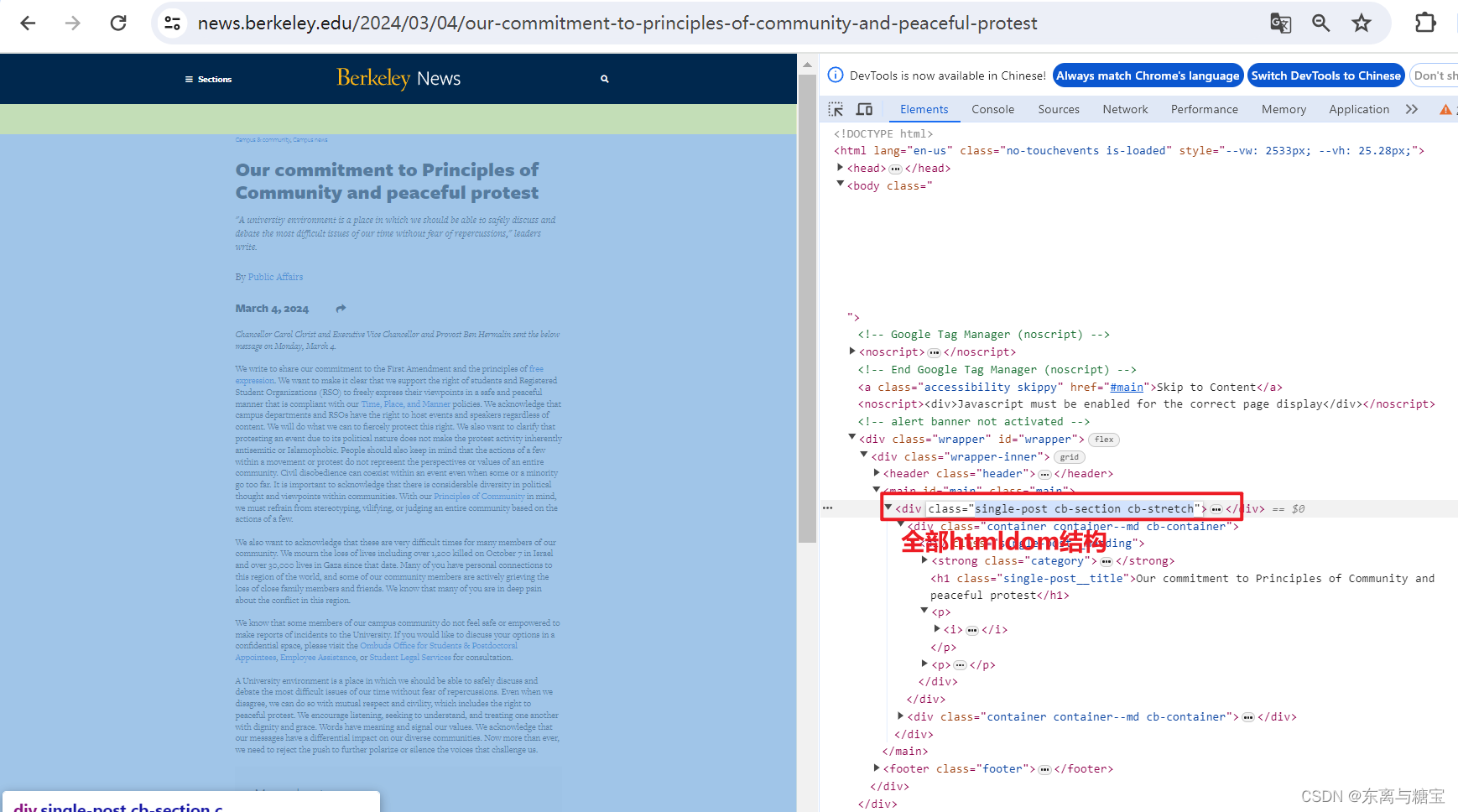
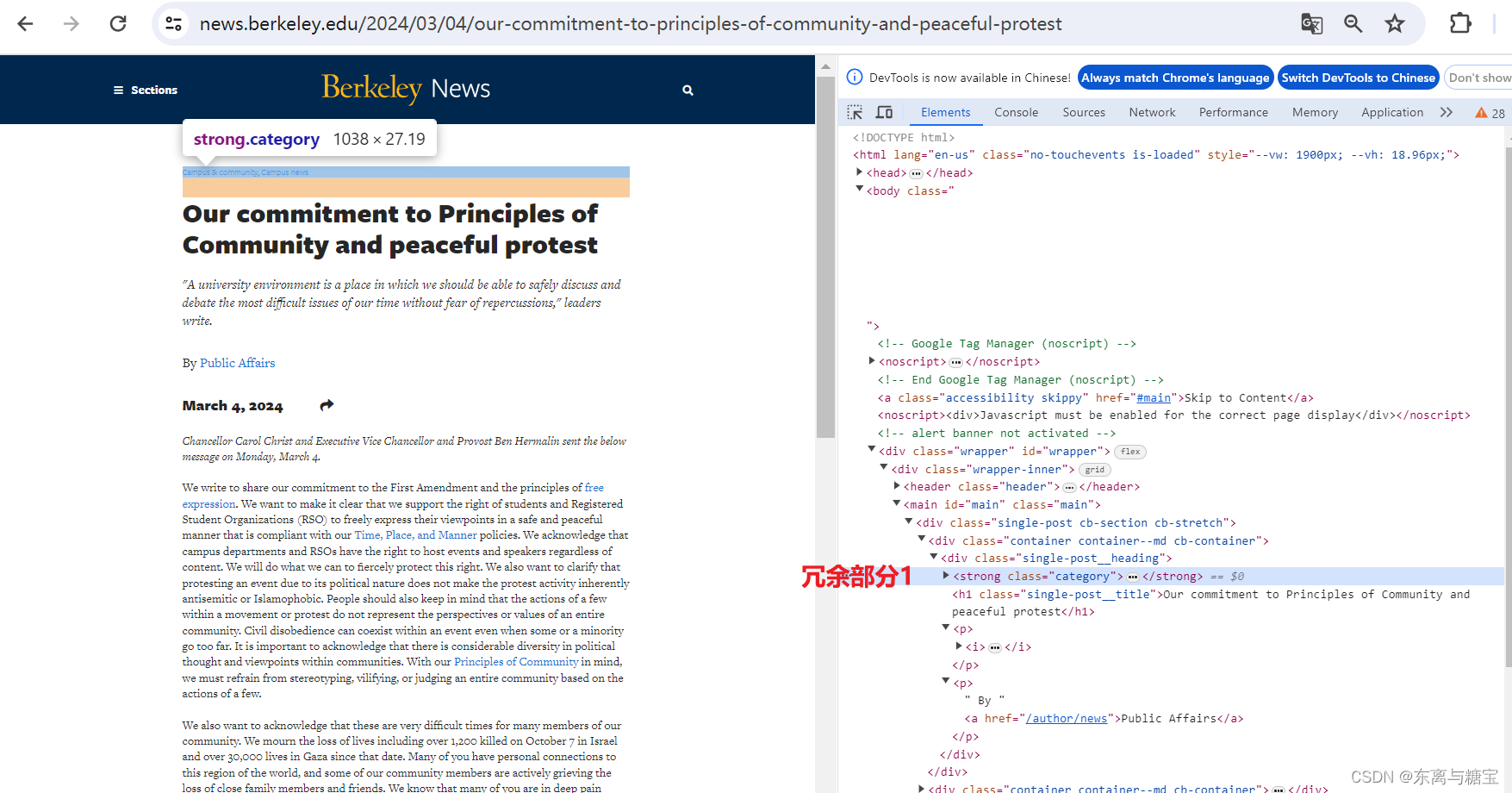


# 原始htmldom结构
html_dom = soup.find('div', 'single-post cb-section cb-stretch')
# 标题上方的冗余
html_cut1 = html_dom.find('div', 'single-post__heading').find('strong')
# 链接冗余
html_cut2 = html_dom.find_all('a', 'a2a_dd share-link')
# 移除元素
if html_cut1:
html_cut1.extract()
if html_cut2:
for item in html_cut2:
item.extract()
html_content = html_dom


- 进行文章清洗,保留文本,去除标签,用content保留清洗后的文本
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
...
# 增加保留html样式的源文本
origin_html = html_dom.prettify() # String
# 转义网页中的图片标签
str_html = self.transcoding_tags(origin_html)
# 再包装成
temp_soup = BeautifulSoup(str_html, 'html.parser')
# 反转译文件中的插图
str_html = self.translate_tags(temp_soup.text)
# 绑定更新内容
content = self.clean_content(str_html)
# 工具 转义标签
def transcoding_tags(self, htmlstr):
re_img = re.compile(r's*s*', re.M)
s = re_img.sub(r'n @@##1##@@ n', htmlstr) # IMG 转义
return s
# 工具 转义标签
def translate_tags(self, htmlstr):
re_img = re.compile(r'@@##(img.*?)##@@', re.M)
s = re_img.sub(r'', htmlstr) # IMG 转义
return s
# 清洗文章
def clean_content(self, content):
if content is not None:
content = re.sub(r'r', r'n', content)
content = re.sub(r'n{2,}', '', content)
content = re.sub(r' {6,}', '', content)
content = re.sub(r' {3,}n', '', content)
content = re.sub(r' ', '', content)
content = content.replace(
'
', '', content)
content = content.replace(
' ', '')
content = content.replace(
''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="SourcePh " style="display:none">''',
'')
.replace(' <!--enpcontent', '').replace('
', '')
content = content.replace(
''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="SourcePh " style="display:none">''',
'')
.replace(' <!--enpcontent', '').replace('', '')
content = content.replace(''
, '').replace(''
, '').replace(' ', ' ')
return content
- 下载保存图片
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
...
imgs = []
img_array = soup.find('figure', 'cb-image cb-float--none cb-float--none--md cb-float--none--lg cb-100w cb-100w--md cb-100w--lg new-figure').find_all('img')
for item in img_array:
img_url = item.get('src')
imgs.append(img_url)
if len(imgs) != 0:
# 下载图片
illustrations = self.download_images(imgs, card_id)
# 下载图片
def download_images(self, img_urls, card_id):
result = re.search(r'[^/]+$', card_id)
last_word = result.group(0)
# 根据card_id创建一个新的子目录
images_dir = os.path.join(self.img_output_dir, str(last_word))
if not os.path.exists(images_dir):
os.makedirs(images_dir)
downloaded_images = []
for index, img_url in enumerate(img_urls):
try:
response = requests.get(img_url, stream=True, headers=self.headers)
if response.status_code == 200:
# 从URL中提取图片文件名
img_name_with_extension = img_url.split('/')[-1]
pattern = r'^[^?]*'
match = re.search(pattern, img_name_with_extension)
img_name = match.group(0)
# 保存图片
with open(os.path.join(images_dir, img_name), 'wb') as f:
f.write(response.content)
downloaded_images.append([img_url, os.path.join(images_dir, img_name)])
except requests.exceptions.RequestException as e:
print(f'请求图片时发生错误:{e}')
except Exception as e:
print(f'保存图片时发生错误:{e}')
return downloaded_images
# 如果文件夹存在则跳过
else:
print(f'文章id为{card_id}的图片文件夹已经存在')
return []
- 保存文章数据
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['berkeley-news']
# 创建或选择集合
cards_collection = db['cards']
# 插入示例数据到 catalogues 集合
card_data = {
'id': card_id,
'catalogueId': catalogue_id,
'type': 'berkeley-news',
'date': date,
'title': card_title,
'author': author,
'updatetime': updateTime,
'url': url,
'html_content': str(html_content),
'content': content,
'illustrations': illustrations,
}
cards_collection.insert_one(card_data)
四、完整代码
import os
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import re
import traceback
class MitnewsScraper:
def __init__(self, root_url, model_url, img_output_dir):
self.root_url = root_url
self.model_url = model_url
self.img_output_dir = img_output_dir
self.headers = {
'Referer': 'https://news.berkeley.edu/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/122.0.0.0 Safari/537.36',
'Cookie': '替换成你自己的',
}
# 获取一个模块有多少版面
def catalogue_all_pages(self):
response = requests.get(self.model_url, headers=self.headers)
soup = BeautifulSoup(response.text, 'html.parser')
try:
match = re.search(r'of (d+)', soup.text)
num_pages = int(match.group(1))
print('模块一共有' + str(num_pages) + '页版面')
for page in range(1, num_pages + 1):
print(f"========start catalogues page {page}" + "/" + str(num_pages) + "========")
self.parse_catalogues(page)
print(f"========Finished catalogues page {page}" + "/" + str(num_pages) + "========")
except Exception as e:
print(f'Error: {e}')
traceback.print_exc()
# 解析版面列表里的版面
def parse_catalogues(self, page):
params = {'page': page}
response = requests.get(self.model_url, params=params, headers=self.headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
catalogue_list = soup.find('div', 'filtered-items')
catalogues_list = catalogue_list.find_all('article')
for index, catalogue in enumerate(catalogues_list):
print(f"========start catalogue {index+1}" + "/" + "10========")
# 版面标题
catalogue_title = catalogue.find('div', 'news-item__description').find('a').get_text(strip=True)
# 操作时间
date = datetime.now()
# 更新时间
publish_time = catalogue.find('div', 'news-item__description').find('time').get('datetime')
# 将日期字符串转换为datetime对象
updatetime = datetime.strptime(publish_time, '%Y-%m-%d')
# 版面url
catalogue_href = catalogue.find('div', 'news-item__description').find('a').get('href')
catalogue_url = self.root_url + catalogue_href
# 版面id
catalogue_id = catalogue_href[1:]
self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['berkeley-news']
# 创建或选择集合
catalogues_collection = db['catalogues']
# 插入示例数据到 catalogues 集合
catalogue_data = {
'id': catalogue_id,
'date': date,
'title': catalogue_title,
'url': catalogue_url,
'cardSize': 1,
'updatetime': updatetime
}
# 在插入前检查是否存在相同id的文档
existing_document = catalogues_collection.find_one({'id': catalogue_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
catalogues_collection.insert_one(catalogue_data)
print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")
else:
print("[爬取版面]版面 " + catalogue_url + " 已存在!")
print(f"========finsh catalogue {index+1}" + "/" + "10========")
return True
else:
raise Exception(f"Failed to fetch page {page}. Status code: {response.status_code}")
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
url = 'https://news.berkeley.edu/2024/03/05/meet-our-new-faculty-antoine-levy-economics'
card_response = requests.get(url, headers=self.headers)
soup = BeautifulSoup(card_response.text, 'html.parser')
# 对应的版面id
card_id = catalogue_id
# 文章标题
card_title = cardtitle
# 文章更新时间
updateTime = cardupdatetime
# 操作时间
date = datetime.now()
# 文章作者
try:
author = soup.find('a', href='/author/news').get_text()
except:
author = soup.find('div', 'single-post__heading').find('p').find('a').get_text()
# 原始htmldom结构
html_dom = soup.find('div', 'single-post cb-section cb-stretch')
# 标题上方的冗余
html_cut1 = html_dom.find('div', 'single-post__heading').find('strong')
# 链接冗余
html_cut2 = html_dom.find_all('a', 'a2a_dd share-link')
# 移除元素
if html_cut1:
html_cut1.extract()
if html_cut2:
for item in html_cut2:
item.extract()
html_content = html_dom
# 增加保留html样式的源文本
origin_html = html_dom.prettify() # String
# 转义网页中的图片标签
str_html = self.transcoding_tags(origin_html)
# 再包装成
temp_soup = BeautifulSoup(str_html, 'html.parser')
# 反转译文件中的插图
str_html = self.translate_tags(temp_soup.text)
# 绑定更新内容
content = self.clean_content(str_html)
# 下载图片
imgs = []
try:
img_array = soup.find('figure', 'cb-image cb-float--none cb-float--none--md cb-float--none--lg cb-100w cb-100w--md cb-100w--lg new-figure').find_all('img')
except:
img_array = soup.find('div', 'container container--lg cb-container').find_all('img')
if len(img_array) is not None:
for item in img_array:
img_url = item.get('src')
if img_url is None:
img_url = item.get('data-src')
imgs.append(img_url)
if len(imgs) != 0:
# 下载图片
illustrations = self.download_images(imgs, card_id)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['berkeley-news']
# 创建或选择集合
cards_collection = db['cards']
# 插入示例数据到 cards 集合
card_data = {
'id': card_id,
'catalogueId': catalogue_id,
'type': 'berkeley-news',
'date': date,
'title': card_title,
'author': author,
'updatetime': updateTime,
'url': url,
'html_content': str(html_content),
'content': content,
'illustrations': illustrations,
}
# 在插入前检查是否存在相同id的文档
existing_document = cards_collection.find_one({'id': card_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
cards_collection.insert_one(card_data)
print("[爬取文章]文章 " + url + " 已成功插入!")
else:
print("[爬取文章]文章 " + url + " 已存在!")
# 下载图片
def download_images(self, img_urls, card_id):
result = re.search(r'[^/]+$', card_id)
last_word = result.group(0)
# 根据card_id创建一个新的子目录
images_dir = os.path.join(self.img_output_dir, str(last_word))
if not os.path.exists(images_dir):
os.makedirs(images_dir)
downloaded_images = []
for index, img_url in enumerate(img_urls):
try:
response = requests.get(img_url, stream=True, headers=self.headers)
if response.status_code == 200:
# 从URL中提取图片文件名
img_name_with_extension = img_url.split('/')[-1]
pattern = r'^[^?]*'
match = re.search(pattern, img_name_with_extension)
img_name = match.group(0)
# 保存图片
with open(os.path.join(images_dir, img_name), 'wb') as f:
f.write(response.content)
downloaded_images.append([img_url, os.path.join(images_dir, img_name)])
print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')
except requests.exceptions.RequestException as e:
print(f'请求图片时发生错误:{e}')
except Exception as e:
print(f'保存图片时发生错误:{e}')
return downloaded_images
# 如果文件夹存在则跳过
else:
print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')
return []
# 工具 转义标签
def transcoding_tags(self, htmlstr):
re_img = re.compile(r's*s*', re.M)
s = re_img.sub(r'n @@##1##@@ n', htmlstr) # IMG 转义
return s
# 工具 转义标签
def translate_tags(self, htmlstr):
re_img = re.compile(r'@@##(img.*?)##@@', re.M)
s = re_img.sub(r'', htmlstr) # IMG 转义
return s
# 清洗文章
def clean_content(self, content):
if content is not None:
content = re.sub(r'r', r'n', content)
content = re.sub(r'n{2,}', '', content)
content = re.sub(r' {6,}', '', content)
content = re.sub(r' {3,}n', '', content)
content = re.sub(r'', '', content)
content = content.replace(
' ', '')
content = content.replace(
''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="SourcePh " style="display:none">''',
'')
.replace(' <!--enpcontent', '').replace('', '')
content = content.replace(''
, '').replace(''
, '').replace(' ', ' ')
return content
def run():
# 根路径
root_url = 'https://news.berkeley.edu/'
# 模块地址数组
model_urls = ['https://news.berkeley.edu/news']
# 文章图片保存路径
output_dir = 'D://imgs//berkeley-news'
for model_url in model_urls:
scraper = MitnewsScraper(root_url, model_url, output_dir)
scraper.catalogue_all_pages()
if __name__ == "__main__":
run()
五、效果展示
$(function() {
setTimeout(function () {
var mathcodeList = document.querySelectorAll(‘.htmledit_views img.mathcode’);
if (mathcodeList.length > 0) {
for (let i = 0; i < mathcodeList.length; i++) {
if (mathcodeList[i].naturalWidth === 0 || mathcodeList[i].naturalHeight === 0) {
var alt = mathcodeList[i].alt;
alt = '\(' + alt + '\)';
var curSpan = $('‘);
curSpan.text(alt);
$(mathcodeList[i]).before(curSpan);
$(mathcodeList[i]).remove();
}
}
MathJax.Hub.Queue([“Typeset”,MathJax.Hub]);
}
}, 1000)
});

优惠劵

东离与糖宝
关注
关注
-



152
点赞
-


踩
-



128
收藏
觉得还不错?
一键收藏

-

打赏
-


191
评论
-

复制链接
专栏目录
【伯克利CS61B教材——Java 学习教程】 Head First Java 中文版
05-08
中文版的伯克利CS61B教材——经典Java 学习教程 《Head First Java 第二版 》
加州伯克利射频教程
02-16
加州伯克利射频教程
191 条评论
您还未登录,请先
登录
后发表或查看评论
伯克利人工智能作业吃豆人——四大寻路算法,以及改进
07-22
伯克利人工智能先导课cs188作业,吃豆人,包含四大寻路算法寻找最短路径,代码有注释,实现了吃豆人最短路径吃完所有豆子的a星算法的改进版
美国一流大学社会筹资策略对我国地方高校的启示——以加州大学伯克利分校为例
06-12
多元化的社会筹资可为我国地方高校提供资金支持和社会资源,支持学校进一步改革发展。相比于国外一流大学社会筹资工作,我国地方高校的筹资经验明显不足。通过对美国加州大学伯克利分校与我国地方高校社会筹资策略的比较分析,提出了适合我国地方高校的筹资策略。
DSW2018-tutorials:伯克利数据科学研讨会上的GDSO教程
05-01
DSW 2018教程
以下是GDSO Data Science Workshop 2018讲习班前教程中使用的一些材料
7月9日:
7月10日:
7月11日:
7月12日:
7月13日:
豆瓣电影短评:Scrapy 爬虫+数据清理/分析+构建中文文本情感分析模型
datayx的文章
10-17

4090
向AI转型的程序员都关注了这个号????????????机器学习AI算法工程 公众号:datayx项目——豆瓣电影Top250的短评分析Scrapy 爬虫 + 数据清理 + 数据分析…
记录免费的学习资源-视频教程
丨Anna丨的博客
06-10
4272
名称
分类
全新小迪Web渗透工程师第十四期
Web安全
边界安全渗透测试工程师培训教程
Web安全
米斯特白帽子WEB安全第二期培训教程
Web安全
价值1800元的爱安全渗透测试全套培训
Web安全
2016全新小迪WEB安全培训教程
Web安全
价值1273美元!2017年最新 EthicalHacking A-Z黑客教程合集
Web安全
Kali Linux Web安全初级入门
Web安全
Web…
什么是Apache Spark?这篇文章带你从零基础学起
大数据
05-12
6138
导读:Apache Spark是一个强大的开源处理引擎,最初由Matei Zaharia开发,是他在加州大学伯克利分校的博士论文的一部分。Spark的第一个版本于2012…
[Python黑帽] 二.Python能做什么攻击?正则表达式、网络爬虫和套接字通信入门
杨秀璋的专栏
09-11
1万+
Python黑帽第二篇文章将分享Python网络攻防基础知识,看看Python能做什么,以及正则表达式、网络爬虫和套接字通信入门基础。本文参考了i春秋ADO老师的课程内容,这里真心推荐大家去学习ichunqiu的课程,同时也结合作者的经验进行讲解。希望这篇基础文章对您有所帮助,更希望大家提高安全意识,也欢迎大家讨论。
[网络安全自学篇] 十四.Python攻防之基础常识、正则表达式、Web编程和套接字通信(一)
热门推荐
杨秀璋的专栏
09-29
2万+
这是作者的系列网络安全自学教程,主要是关于网安工具和实践操作的在线笔记,特分享出来与博友共勉,希望您们喜欢,一起进步。前文分享了Wireshark抓包原理知识,并结合NetworkMiner工具抓取了图像资源和用户名密码,本文将讲解Python网络攻防相关基础知识,包括正则表达式、Web编程和套接字通信。本文参考了爱春秋ADO老师的课程内容,这里也推荐大家观看他Bilibili和ichunqiu的课程,同时也结合了作者之前的经验进行讲解。
Python爬虫利器
suqieer的博客
03-05
1557
网络爬虫是自动化从互联网上抓取数据的技术。在 Python 中,有几个强大的库可以帮助我们完成这项任务,其中requests用于处理 HTTP 请求和 Cookies,lxml提供了 XPath 解析功能,而则是用于解析 HTML 和 XML 文档的利器。本文将为你介绍这三个工具的基本概念和使用方法。
Python爬虫打印状态码为521,返回数据为乱码?
m0_74972727的博客
03-09
279
注意:如何已添加cookie,出现断网情况,需要重新获取cookie。
python爬虫第学习基础—-注释与变量
喔的嘛呀的博客
03-09
534
在我们工作编码的过程中,如果一段代码的逻辑比较复杂,不是特别容易理解,可以适当的添加注释,以辅助自己或者其他编码人员解读代码。
【python】六个常见爬虫案例【附源码】
m0_73367097的博客
03-06
7633
常见爬虫案例
一个爬虫自动化数据采集的故事~
最新发布
十一姐的博客
03-09
809
当逆向很难很难的时候,偶尔爬虫妥协道自动化数据采集,也未尝不可
向爬虫而生—Redis 探究篇8<保障缓存和持久化数据一致性的研究与实现(中) `方案篇`>
晦涩难董先生
03-09
812
先更新缓存再更新持久化存储的策略通过异步更新和幂等性操作来提高系统性能和可靠性。异步更新策略可以提高响应性和并发处理能力,而幂等性操作和幂等命令可以保证相同的操作只产生一次效果。然而,我们需要根据具体的业务需求和性能要求来权衡使用这些策略。使用基于分布式锁的方式可以确保在更新缓存和持久化存储同时进行时的一致性。然而,分布式锁也带来了性能和可靠性的问题,需要根据具体的需求和系统环境进行权衡和调优。在实际应用中,选择合适的分布式锁方案和正确的使用方式是确保系统可靠性的关键。
python 爬虫编码(encoding和apparent_encoding)区别
m0_74972727的博客
03-08
759
如果两个属性返回不同的编码,通常建议优先考虑response.apparent_encoding,因为它可能是网页内容实际使用的编码。当然,在解析网页内容时,最好的做法是先检查和确认编码是否正确,必要时手动调整后再进行解析。
python知网爬虫论文pdf下载+立即可用(动态爬虫)
Braylon的博客
03-09
440
python实现动态爬虫知网论文,搜索+自动翻页+下载
收集数据利器
Ruby网络爬虫教程:从入门到精通下载图片
Z_suger7的博客
03-05
616
网络爬虫技术在信息时代扮演着重要的角色,它可以自动化地获取互联网上的信息,为用户提供便利的数据服务。本文将带领读者从零开始,通过学习Ruby编程语言,逐步掌握网络爬虫的设计与实现,重点介绍如何利用网络爬虫技术下载图片。Ruby拥有丰富的第三方库,使得开发者能够轻松地处理各种任务,包括网络爬虫。在本教程中,我们将使用Ruby编写网络爬虫程序,并利用其中的Gem包来发送网络请求、解析HTML页面等。在设计网络爬虫程序时,我们需要考虑到各种情况和问题,并制定相应的解决方案。
手把手教你设计cpu——risc-v处理器
06-28
### 回答1:
很高兴听到您对RISC-V处理器的设计感兴趣。以下是一些基本步骤,可以帮助您开始设计自己的RISC-V处理器:
1. 确定处理器的需求和规格:在设计处理器之前,您需要确定处理器的需求和规格。这包括处理器的性能、功耗、指令集等方面。
2. 学习RISC-V指令集架构:RISC-V是一种开放的指令集架构,您需要学习它的指令集和编码方式。您可以在RISC-V官方网站上找到相关的文档和教程。
3. 设计处理器的微架构:微架构是处理器的实现细节,包括指令流水线、寄存器文件、ALU等。您需要设计一个合适的微架构来实现RISC-V指令集。
4. 编写Verilog代码:Verilog是一种硬件描述语言,您需要使用Verilog编写处理器的代码。您可以使用Verilog模拟器来验证您的代码是否正确。
5. 进行综合和布局布线:综合是将Verilog代码转换为门级电路的过程,布局布线是将门级电路布置在芯片上的过程。您可以使用EDA工具来完成这些步骤。
6. 进行仿真和验证:最后,您需要对处理器进行仿真和验证,以确保它能够正确地执行RISC-V指令集。
希望这些步骤可以帮助您开始设计自己的RISC-V处理器。祝您好运!
### 回答2:
随着计算机技术的不断发展,处理器作为计算机的中央处理单元,一直处于不断更新和迭代的状态。在这个过程中,越来越多的人开始将目光投向自己动手设计处理器的领域,以提高对计算机结构的理解和掌握能力。而RISC-V处理器则成为了越来越受欢迎的处理器设计体系结构之一。下面,我们就来手把手教你设计RISC-V处理器。
首先,需要了解RISC-V处理器的体系结构和指令集,掌握其特点,以便更好地进行设计。RISC-V架构采用精简指令集(Reduced Instruction Set Computing,RISC)的思想,指令集清晰简单,易于扩展和实现,同时提供了不同的指令长度和地址宽度,满足多种应用场景的需求。
其次,需要明确设计RISC-V处理器的目的和需求。例如,设计一款高性能处理器,需要考虑运算速度、处理带宽、低功耗等方面的需求,而设计一款嵌入式处理器,则需要考虑尺寸、功耗、集成度等方面的需求。在确定需求后,可以选择适合的设计方法和实现方式。
接着,需要进行设计和仿真。采用硬件描述语言(如Verilog或VHDL)进行设计,利用仿真软件进行仿真调试,逐步完善处理器的各项功能。需要注意的是,设计时需要清晰明确每一阶段的功能和相应的接口,保证设计的可扩展性。
最后,进行硬件实现和验证。将设计好的RTL电路转换为FPGA或ASIC中的物理实现,进行性能测试和功能验证,发布仿真测试结果和设计文档,确保设计能够满足预期的性能和功能要求,并能够进一步优化和升级。
在以上步骤中,需要掌握的知识包括计算机体系结构、数字电路设计、硬件描述语言的使用等。需要长期的学习和实践,才能够熟练掌握处理器设计的各个环节,并能够设计出具备高性能、低功耗、灵活可扩展等特点的处理器。
### 回答3:
RISC-V是一个由加州大学伯克利分校推出的开源指令集架构,它的设计理念是简化指令集,更加注重可扩展性、可定制性和易于实现。设计RISC-V处理器需要了解计算机体系结构以及数字电路原理,下面将手把手教你设计CPU。
第一步,需要确定处理器的架构。RISC-V处理器一般采用五级流水线结构,包括取指、译码、执行、访存和写回。在这个流水线结构中,每个阶段都有对应的功能,可以保证指令的按序执行。
第二步,需要确定指令集架构。RISC-V有基础指令集和标准扩展指令集,需要根据使用需求选择相应的扩展指令集并实现相应的操作。
第三步,需要进行处理器的逻辑设计。包括指令寄存器(IR)、程序计数器(PC)、指令存储器(IM)、寄存器堆、ALU(算数逻辑单元)、数据存储器(DM)等,这些模块通过总线相互连接构成处理器的基本结构。
第四步,需要进行数字电路的设计。处理器逻辑的实现需要用到器件和电路,需要根据设计的结构和功能实现相应的数字电路。
第五步,进行验证和调试。在设计完成后,需要进行仿真验证和调试工作,以保证设计的正确性和稳定性。
总的来说,设计RISC-V处理器需要掌握计算机体系结构、数字电路原理和基础编程知识,需要进行详细、全面的规划和设计。设计过程中需要不断地验证和调整,确保设计的正确性和稳定性,最终完成一个高质量且符合需求的处理器设计。
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助
-

 没帮助
没帮助
-

 一般
一般
-

 有帮助
有帮助
-

 非常有帮助
非常有帮助
提交
window.csdn.csdnFooter.options = {
el: ‘.blog-footer-bottom’,
type: 2
}
东离与糖宝

CSDN认证博客专家
CSDN认证企业博客
码龄3年

Java领域优质创作者
- 100
- 原创
- 97
- 周排名
- 317
- 总排名
- 35万+
- 访问
-

- 等级
- 3万+
- 积分
- 1万+
- 粉丝
- 1万+
- 获赞
- 1万+
- 评论
- 1万+
- 收藏
















 私信
关注
私信
关注
![]()


热门文章
-
python超详细基础文件操作【建议收藏】
24869
-
Mybatis-Plus 实现增删改查 — Mybatis-Plus 快速入门保姆级教程(一)
23589
-
初级爬虫实战——人民网
21869
-
一文带你深入浅出Web的自动化测试工具Selenium 4.xx【建议收藏】
16624
-
Spring概述与核心概念学习 — Spring入门(一)
16222
分类专栏
-

python
14篇
-

MongoDB
8篇
-

从全栈开发到前后端部署项目实例
-

合作推广
19篇
-

资源分享
-

代码随想录算法训练营
-

mysql
3篇
-
vue
6篇
-

mybatis
3篇
-

SSM项目实例
12篇
-

SpringMVC
5篇
-

前后端软件安装与环境配置
2篇
-

纪念日
1篇
-

JAVA基础
4篇
-

Spring入门
8篇
-

mybatis-plus入门
2篇
-

操作系统
4篇
-

SpringBoot
3篇
-

Git
1篇
-

Redis
3篇
-

Nginx
1篇
-

HTTP
1篇
-

JS
1篇

最新评论
您愿意向朋友推荐“博客详情页”吗?
-
强烈不推荐
-
不推荐
-
一般般
-
推荐
-
强烈推荐
提交
最新文章
-
爬虫实战——巴黎圣母院新闻【内附超详细教程,你上你也行】
-
初级爬虫实战——麻省理工学院新闻
-
python超详细基础文件操作【建议收藏】
2024年16篇
2023年84篇
目录
$(“a.flexible-btn”).click(function(){
$(this).parents(‘div.aside-box’).removeClass(‘flexible-box’);
$(this).parents(“p.text-center”).remove();
})
服务器托管,北京服务器托管,服务器租用,机房机柜带宽租用

咨询:董先生
电话13051898268 QQ/微信93663045!
上一篇: 80.springboot的自动配置原理?
下一篇: nacos的基本使用

LeoToJavaer:
大佬的文章让我对这领域的技术问题有了更深入的了解,尤其是大佬提到的那些“坑点”,我相信能够在实际应用中避免或解决很多问题。谢谢大佬的分享,期待大佬的更多精彩文章,让我们共同学习、进步。
程序边界:
春天来了,虽然天气有点凉,但是万物复苏,一切充满生气,是个令人神往的季节。大佬的文章更是增添了几分生机,如同远野上含苞欲放的花朵,期待大佬更多佳作。
从零开始的-CodeNinja之路:
文章干货满满!作者在阐述每个知识点时,都力求详尽且清晰,使得读者可以轻松理解并掌握。此外,文章中还引用了一些具有代表性的代码片段,这些代码既展示了编程的魅力,也使得读者能够更好地理解相关概念和技巧
爱编程的喵喵:
优质好文,博主的文章细节很到位,兼顾实用性和可操作性,感谢博主的分享,期待博主持续带来更多好文
征途黯然.:
 对爬虫实战巴黎圣母院新闻内附超详细教程你上你也行的解释非常清晰,文章真的很好。
对爬虫实战巴黎圣母院新闻内附超详细教程你上你也行的解释非常清晰,文章真的很好。