

写在前面
本文主要介绍了发布于 2023 年 SIGMOD 的论文《Kepler: Robust Learning for Faster Parametric Query Optimization》,该文章针对参数化查询,将参数化查询优化与查询优化结合,旨在减少查询规划时间的同时提高查询性能。
为此,作者提出了一种端到端的、基于深度学习的参数化查询优化方法,名为 Kepler (K-plan Evolution for Parametric Query Optimization: Learned, Empirical, Robust)。
数化查询是指具有相同 SQL 结构,只在绑定的参数值上不同的一类查询。举个例子,考虑以下查询结构:
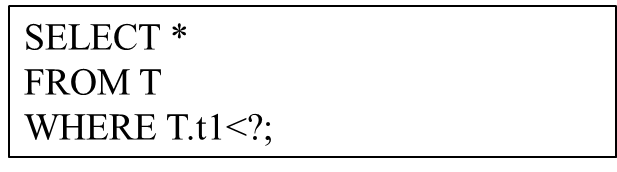
该查询结构可以看作一个参数化查询的模板,”?”处代表着不同的参数值。用户执行的 SQL 语句都具有该查询结构,只是实际的参数值可能不同,这就是一个参数化查询。这样的参数化查询在现代数据库中的使用十分频繁。由于其不断重复执行同一查询模板,为提升它的查询性能带来了机遇。
参数化查询优化 (PQO) 用于优化上述参数化查询的性能,目标是尽可能地减少查询规划时间,同时避免性能的回归。现有的方法过度依赖于系统内置的查询优化器,使其受到优化器固有的次优性的限制。作者认为,参数化查询的理想系统不应该只通过 PQO 减少查询规划时间,也应该通过查询优化 (QO) 提高系统的查询执行性能。
查询优化 (QO) 用于帮助一条查询找到其最优的执行计划。现有的改进查询优化的方法大多应用了机器学习,如基于机器学习的基数/成本估计器。但目前基于学习的查询优化方法存在一些缺点: (1)推理时间过长; (2)泛化能力差; (3)对性能的提升不明确; (4)不具有鲁棒性,性能可能会回归。
上述缺点为基于学习的方法带来了挑战,因为它们不能保证预测结果对执行时间的提升。为解决上述问题,作者提出了 Kepler:一种端到端的基于学习的参数化查询优化方法。
作者将参数化查询优化解耦为两个问题:候选计划生成和基于学习的预测结构。主要分为三个步骤:新颖的候选计划生成、训练数据收集以及鲁棒神经网络模型设计。三者结合,减少了查询规划时间的同时提高了查询执行性能,同时满足了 PQO 和 QO 的目标。接下来,我们首先介绍 Kepler 的总体架构,然后具体讲解每个模块的具体内容。
总体架构
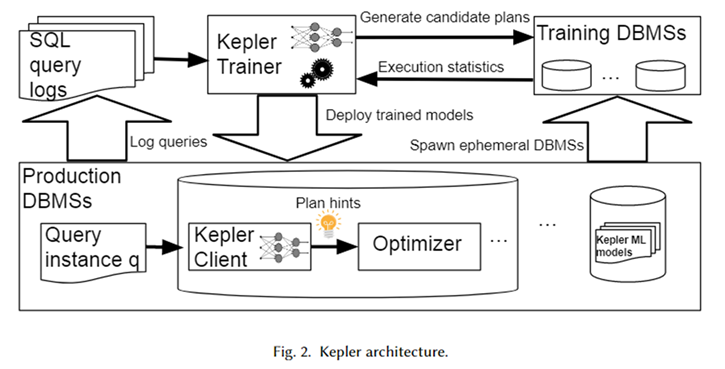
Kepler 的总体架构如上图所示。首先,从数据库系统日志中获取参数化查询模板以及对应的的查询实例(即带有实际参数值的查询),组成一个工作负载。Kepler Trainer 用于为该工作负载训练神经网络预测模型。它首先在整个工作负载上生成候选计划,并在临时的数据库系统中进行执行,获得实际的查询执行时间。
利用该查询时间训练神经网络模型。训练完成后将其部署于生产环境下的数据库系统中,称为 Kepler Client。当用户输入一个查询实例时,Kepler Client 可以为其预测最佳的执行计划,用 plan hint 的形式交给优化器,从而生成并执行最佳计划。
候选计划生成:Row Count Evolution
候选计划生成的目标在于构建一组计划,使其为工作负载中的每个查询实例都包含近最优的执行计划。此外,应该尽可能的小,以免后续训练数据收集过程开销过大。二者互相约束,如何平衡这两个目标是候选计划生成的一个主要挑战。
等式 1 公式化了具体的计划生成目标。其中,为工作负载 W 上的一个查询实例,为优化器选择的执行计划,为理想情况下,在计划集中的最优计划,ExecTime 为对应计划在实例上的执行时间。因此,等式1的内涵为,在整个工作负载上,候选计划集相比优化器生成的计划集,在执行时间上带来的加速。算法旨在最大化该加速效果。
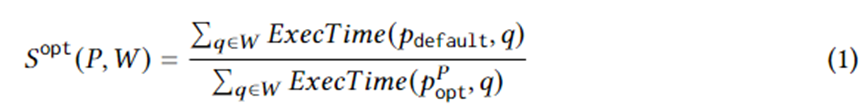
为此,本文提出了 Row Count Evolution (RCE),一种通过随机扰动优化器基数估计来生成新计划的算法。它为每个查询实例生成一系列计划,合并成为整个工作负载的候选计划集。该算法的思路来源在于:基数的错误估计是优化器次优性的主要原因。同时,候选计划生成阶段并不需要为每个查询实例找到具体的单一 (近) 最优计划,而是只要包含了该 (近) 最优计划即可。
RCE 算法是通过迭代不断产生新的计划的。首先,初始迭代计划为优化器产生的计划。为了构建后续迭代,首先需要从上一代计划中均匀随机采样。对于每一个采样出来的计划,扰动 (改变) 其 join 子计划的 cardinality。
扰动方法是,在其当前预估 cardinality 的指数间隔范围内随机采样。将扰动后的 cardinality 交给优化器,生成对应的最佳计划。对每个计划重复 N 次,产生许多执行计划,其中没出现过的执行计划保留作为下一代计划,并重复上述过程。
我们给出一个具体的实例来形象化的说明上述算法,如下图所示。首先,Base Plan 为优化器选择的最佳计划,他有两个 join 子计划,分别为 A join B 和 C join D,它们预估的基数分别为 40 和 17。
接下来,从指数间隔范围 10-1~101 为两个 join 子计划生成扰动集,分别为 [4,40,400] 和 [1,17,170]。从扰动集中随机采样,并将其交给优化器进行计划的选择。Plan 1 即为优化器在 cardinality 分别为 400 和 17 时选择出来的新计划。重复 N 次,最终生成了 C1 个计划作为下一代。接下来,从中采样 S 个计划,并为每个计划重复上述流程,形成第 2 代计划。
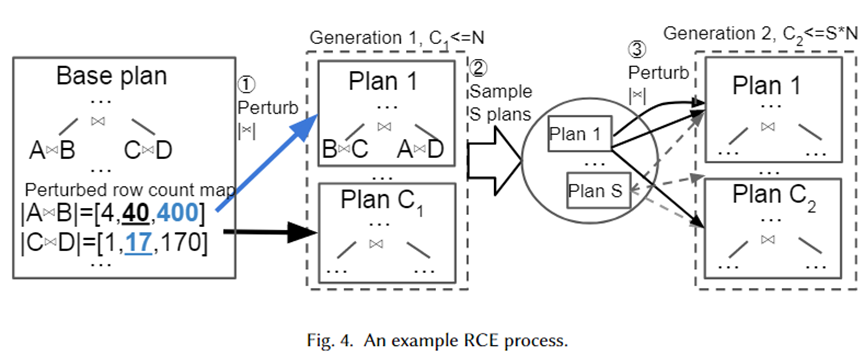
作者采用指数间隔范围作为扰动集的原因是为了符合优化器基数估计误差的分布。通过上述算法可知,只要扰动的次数足够多,会产生很多的 cardinality 以及其对应的 plan。这样,当一个查询实例到来时,我们的计划集中应该存在和真实 cardinality 相近的 plan,可以视为该实例的 (近) 最优计划。
训练数据收集
产生候选计划集后,在工作负载上执行每个计划,已生成执行时间数据,以便进行有监督的最佳计划预测。采用实际执行数据而不是优化器估计的 cost,可以避免优化器次优性带来的限制。执行过程是可并行的。然而,执行所有计划是一笔很大的开销。因此,作者提出了两种策略来减少不必要的次优计划执行带来的资源浪费。
Adaptive timeouts and plan execution reordering,自适应的超时机制和计划执行重排序。作者采用一种超时机制来限制次优计划的执行。对于每个查询实例,在执行每个计划时,可以记录目前最短执行时间。
一旦某个计划的执行时间超过该最短执行时间的一定范围,便可以不再执行,因为他一定不是最优的执行计划。同时,最短执行时间是不断更新的。此外,根据其他查询实例上每个计划的执行情况,按照执行时间升序执行查询计划,可以作为一种启发式的方案来加速超时机制。
Online plan covering pruning,在线计划集剪枝。在为前 N 个查询实例执行所有计划后,利用 Set Cover 问题将其剪枝为 K 个计划。后续的数据收集和模型训练都使用这 K 个计划。Set Cover 问题的定义如下图所示。
在本文的上下文环境中,代表所有查询实例,可以表示为不同的计划,每个计划是某些查询实例的近最优计划。因此,该问题可以表述为,用尽可能最小的计划集,为所有查询实例提供近最优性。该问题是 NP 的,因此作者采用贪心算法来解决。

鲁棒的最佳计划预测
收集好候选计划集的实际执行时间的训练数据后,采用有监督的机器学习来为任意一个查询实例预测最佳计划。训练的目标在逻辑上可以用以下等式来表示。其中代表模型为查询实例选择的最佳计划。该等式的内涵为模型选择的计划相比与优化器选择的计划带来的加速。它的上限是等式 1。换句话说,模型要尽可能捕获到 RCE 生成的候选计划所带来的加速。
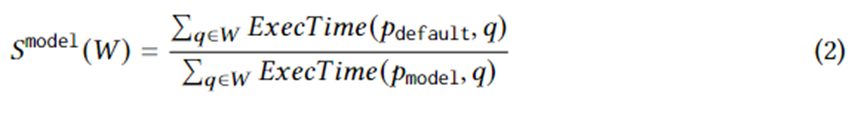
模型的结构采用前向神经网络,并应用了机器学习不确定性的最新进展,即 Spectral-normalized Neural Gaussian Processes (SNGPs),谱归一化高斯处理过程。将其结合到神经网络中,提高模型收敛性的同时,使得神经网络可以输出预测的不确定性。当不确定性高于个阈值时,将计划预测的工作返还给优化器,由优化器决定最佳计划。
模型的特征采用的是每个参数的实际值。为了将参数的实际值能够输入到神经网络中,需要进行一些预处理,尤其是字符串类型的数据。对于字符串类型的数据,作者通过一个固定大小的词汇表以及不在词汇表中的桶来将其表示为 one-hot 向量,并加入一层嵌入层来学习该 one-hot 向量的嵌入,进而能够处理字符串类型的数据。
实验效果
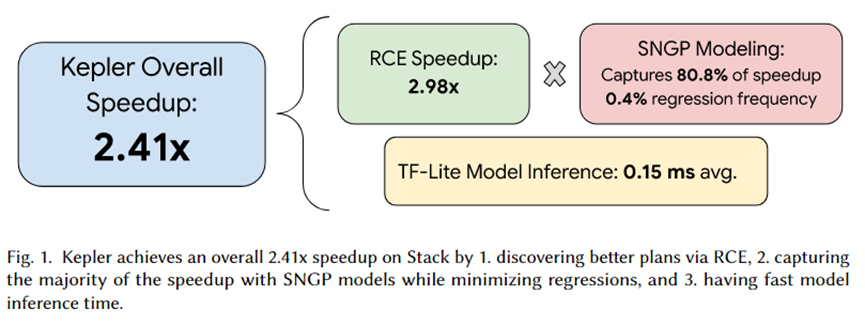
本文作者将 Kepler 集成于 PostgreSQL,并组织了一系列实验。实验的总结如上图所示,Kepler 总共带来的加速效果为 2.41 倍。其中,RCE 生成的候选计划集能够带来 2.92 倍的加速,被 SNGP 预测模型捕获到了 80.8%,并且仅有 0.4% 的回归。此外,模型的推理时间平均只有 0.15ms。
总结
本文提出了 Kepler,一种基于学习的方法,可以稳健地加速参数化查询。其通过 Row Count Evolution (RCE) 算法生成候选计划集,并在 workload 上执行以获取实际执行时间,利用该实际执行时间训练预测模型。
预测模型采用机器学习不确定性估计的最新进展 Spectral-normalized Neural Gaussian Processes (SNGPs),提高收敛性的同时输出预测的不确定性,根据该不确定性选择由该模型还是优化器完成计划预测的任务。实验证明 RCE 可以带来很高的加速效果,并且 SNGP 在避免回归的同时尽可能捕获到 RCE 带来的加速效果。因此,同时完成了 PQO 和 QO 的目标,即减少查询规划时间的同时,提高了查询执行性能。
