

kNN – K-nearest neighbor 定义
kNN(即 k 最近邻算法)是一种机器学习算法,它使用邻近度将一个数据点与其训练并记忆的一组数据进行比较以进行预测。 这种基于实例的学习为 kNN 提供了 “惰性学习(lazy learning)” 名称,并使算法能够执行分类或回归问题。 kNN 的假设是相似的点可以在彼此附近找到 —— 物以类聚。
作为一种分类算法,kNN 将新数据点分配给其邻居中的多数集。 作为一种回归算法,kNN 根据最接近查询点的值的平均值进行预测。
kNN 是一种监督学习算法,其中 “k” 代表分类或回归问题中考虑的最近邻的数量,“NN”代表为 k 选择的数量的最近邻。
kNN 算法简史
kNN 最初由 Evelyn Fix 和 Joseph Hodges 于 1951 年在为美国军方进行的研究中开发。 他们发表了一篇解释判别分析的论文,这是一种非参数分类方法。 1967 年,Thomas Cover 和 Peter Hart 对非参数分类方法进行了扩展,并发表了他们的 “最近邻模式分类” 论文。 大约 20 年后,詹姆斯·凯勒 (James Keller) 对该算法进行了改进,他开发了一种 “模糊 KNN”,可以产生较低的错误率。
如今,kNN 算法是使用最广泛的算法,因为它适用于从遗传学到金融和客户服务的大多数领域。
kNN 是如何工作的?
kNN 算法作为一种监督学习算法,这意味着它会被输入它记忆的训练数据集。 它依赖于这个标记的输入数据来学习一个函数,该函数在给定新的未标记数据时产生适当的输出。
这使得算法能够解决分类或回归问题。 虽然 kNN 的计算发生在查询期间而不是训练阶段,但它具有重要的数据存储要求,因此严重依赖内存。
对于分类问题,KNN 算法将根据多数分配类标签,这意味着它将使用给定数据点周围最常出现的标签。 换句话说,分类问题的输出是最近邻的众数。
区别:多数投票与相对多数投票
多数投票(majority voting)表示超过 50% 的票数为多数。 如果考虑两个类标签,则这适用。 但是,如果考虑多个类别标签,则适用相对多数投票(plurality voting)。 在这些情况下,超过 33.3% 的任何值都足以表示多数,从而提供预测。 因此,相对多数投票(plurality voting)是定义 kNN 模式的更准确术语。
如果我们要说明这种区别:
二元预测
Y: 🎉🎉🎉❤️❤️❤️❤️❤️多数投票: ❤️
相对多少投票: ❤️
多类别设置
Y: ⏰⏰⏰💰💰💰🏠🏠🏠🏠多数投票:没有
相对多数投票:🏠
回归问题使用最近邻的平均值来预测分类。 回归问题将产生实数作为查询输出。
例如,如果你要制作一个图表来根据某人的身高来预测其体重,则表示身高的值将是独立的,而体重的值将是相关的。 通过计算平均身高体重比,你可以根据某人的身高(自变量)估计其体重(因变量)。
4 种计算 kNN 距离度量的类型
kNN 算法的关键是确定查询点与其他数据点之间的距离。 确定距离度量可以实现决策边界。 这些边界创建不同的数据点区域。 有不同的方法用于计算距离:
- 欧几里得距离(Euclidean distance)是最常见的距离度量,它测量查询点和其他被测量点之间的直线。
- 曼哈顿距离(Manhattan distance )也是一种流行的距离度量,它度量两点之间的绝对值。 它以网格表示,通常称为出租车几何形状 – 如何从 A 点(你的查询点)行驶到 B 点(被测量点)?
- 闵可夫斯基距离(Minkowski distance)是欧几里得距离度量和曼哈顿距离度量的推广,它可以创建其他距离度量。 它是在赋范向量空间中计算的。 在 Minkowski 距离中,p 是定义计算中使用的距离类型的参数。 如果 p=1,则使用曼哈顿距离。 如果 p=2,则使用欧几里德距离。
- 汉明距离(Hamming distance),也称为重叠度量,是一种与布尔向量或字符串向量一起使用的技术,用于识别向量不匹配的位置。 换句话说,它测量两个长度相等的字符串之间的距离。 它对于错误检测和纠错码特别有用。
如何选择最佳的 k 值
要选择最佳 k 值(考虑的最近邻的数量),你必须尝试几个值,以找到能够生成最准确的预测且误差最少的 k 值。 确定最佳值是一种平衡行为:
-
低 k 值会使预测不稳定
- 举个例子:一个查询点被 2 个绿点和 1 个红色三角形包围。 如果 k=1 并且最接近查询点的点恰好是绿点之一,则算法将错误地将绿点预测为查询结果。 低 k 值意味着高方差(模型与训练数据拟合得太紧密)、高复杂性和低偏差(模型足够复杂,可以很好地拟合训练数据)。
-
高 k 值有噪音
- 较高的 k 值将提高预测的准确性,因为需要计算众数或平均值的数量更多。 但是,如果 k 值太高,则可能会导致低方差、低复杂性和高偏差(模型不够复杂,无法很好地拟合训练数据)。
理想情况下,你希望找到一个介于高方差和高偏差之间的 k 值。 还建议为 k 选择奇数,以避免分类分析中出现平局。
正确的 k 值也与你的数据集相关。 要选择该值,你可以尝试查找 N 的平方根,其中 N 是训练数据集中的数据点数量。 交叉验证策略还可以帮助你选择最适合你的数据集的 k 值。
kNN算法的优点
kNN 算法通常被描述为 “最简单” 的监督学习算法,这导致了它的几个优点:
- 简单:kNN 非常简单且准确,因此很容易实现。 因此,它通常是数据科学家首先要学习的分类器之一。
- 适应性强:一旦将新的训练样本添加到数据集中,kNN 算法就会调整其预测以包含新的训练数据。
- 易于编程:kNN 仅需要几个超参数 – k 值和距离度量。 这使得它成为一个相当简单的算法。
此外,kNN 算法不需要训练时间,因为它存储训练数据,并且仅在进行预测时使用其计算能力。
kNN 的挑战和局限性
虽然 kNN 算法很简单,但它也存在一系列挑战和限制,部分原因在于它的简单性:
- 难以扩展:由于 kNN 占用大量内存和数据存储,因此带来了与存储相关的费用。 这种对内存的依赖也意味着该算法是计算密集型的,这反过来又是资源密集型的。
- 维数灾难:这是指计算机科学中发生的一种现象,其中一组固定的训练示例受到维度数量不断增加以及这些维度中特征值固有增加的挑战。 换句话说,模型的训练数据无法跟上超空间维度的演变。 这意味着预测变得不太准确,因为查询点和相似点之间的距离在其他维度上变得更宽。
- 过度拟合:如前所述,k 的值将影响算法的行为。 当 k 值太低时尤其可能发生这种情况。 较低的 k 值可能会过度拟合数据,而较高的 k 值会 “平滑” 预测值,因为算法会在更大的区域内对值进行平均。
顶级 kNN 用例
kNN 算法因其简单性和准确性而广受欢迎,具有多种应用,特别是用于分类分析时。
- 相关性排名:kNN 使用自然语言处理 (NLP) 算法来确定哪些结果与查询最相关。
- 图像或视频的相似性搜索:图像相似性搜索使用自然语言描述来查找与文本查询匹配的图像。
- 模式识别:kNN 可用于识别文本或数字分类中的模式。
- 金融:在金融领域,kNN可以用于股市预测、货币汇率等。
- 产品推荐和推荐引擎:想想 Netflix! “如果你喜欢这个,我们认为你也会喜欢……” 任何使用该句子版本的网站,无论是否公开,都可能使用 kNN 算法来为其推荐引擎提供动力。
- 医疗保健:在医学和医学研究领域,kNN算法可用于遗传学中计算某些基因表达的概率。 这使得医生能够预测癌症、心脏病或任何其他遗传性疾病的可能性。
- 数据预处理:kNN 算法可用于估计数据集中的缺失值。
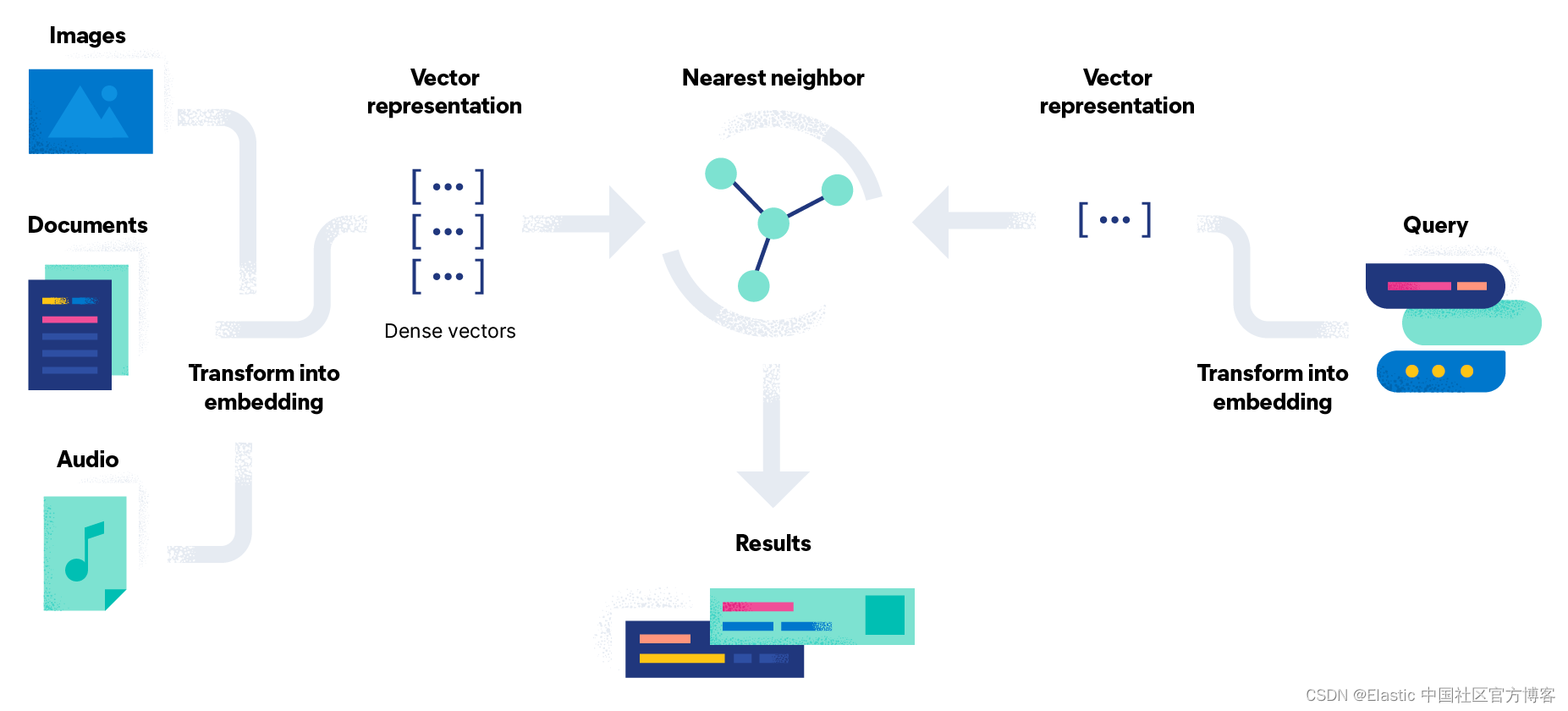
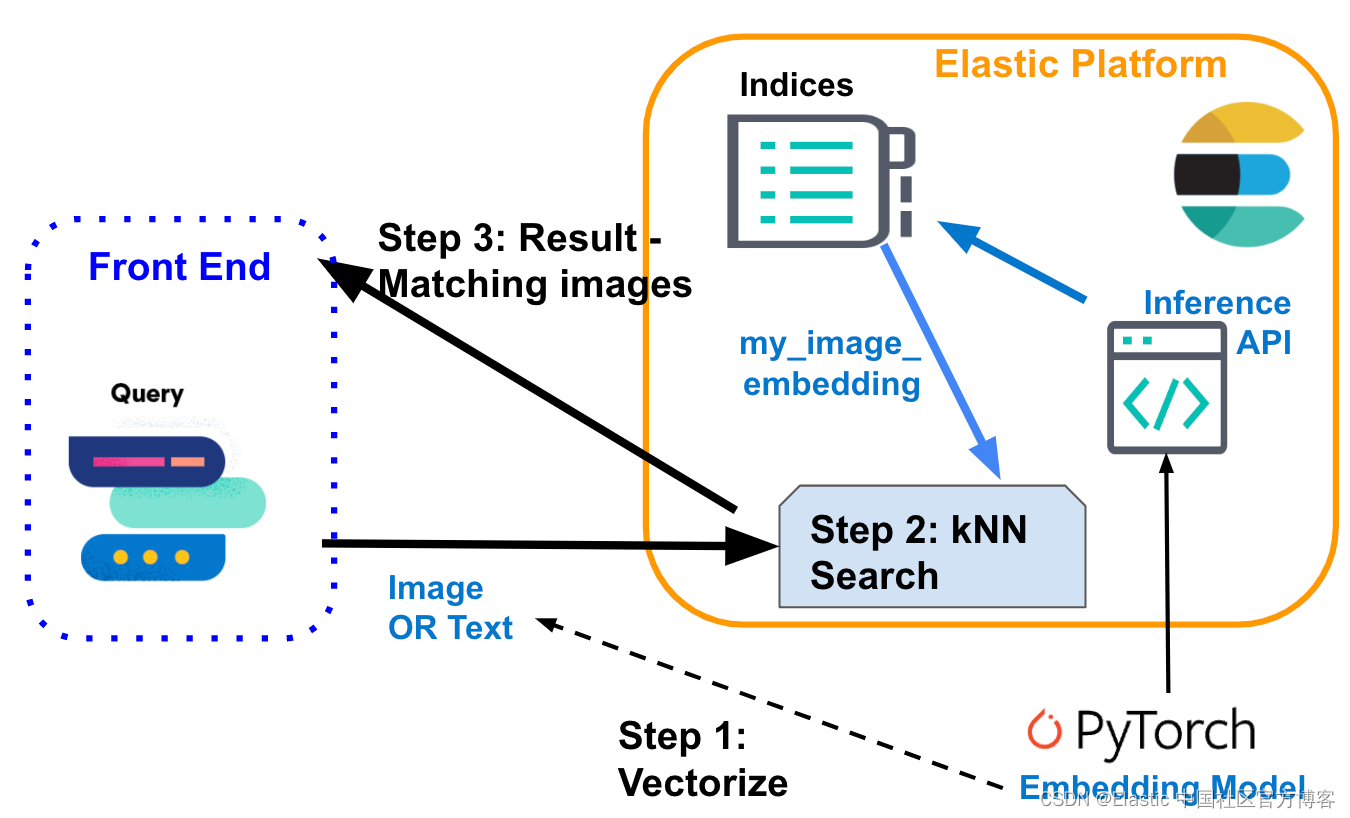
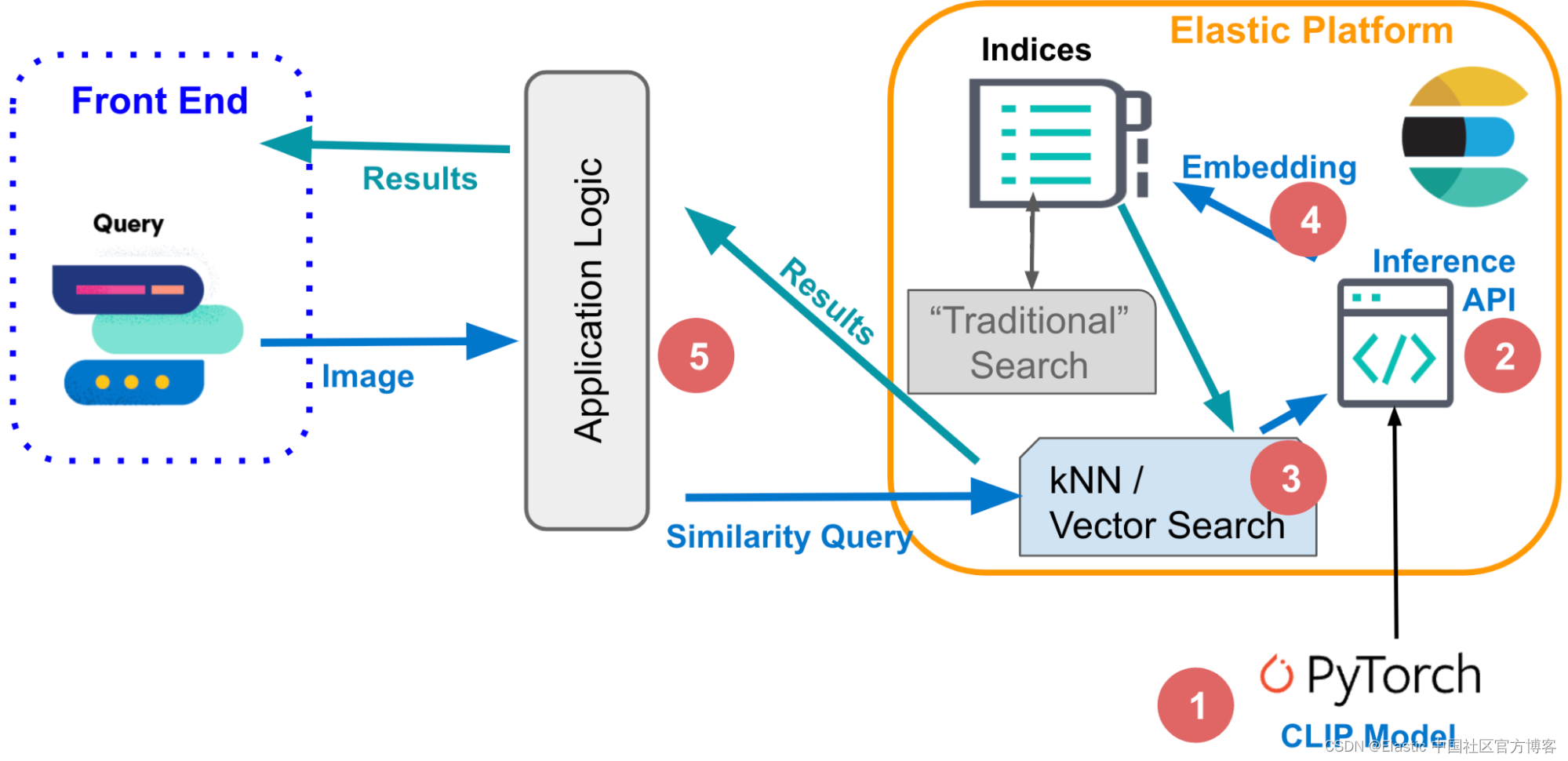
使用 Elastic 进行 kNN 搜索
Elasticsearch 使你能够实现 kNN 搜索。 支持两种方法:近似 kNN(approximate kNN)和精确(exact)、强力 kNN(brute-force)。 你可以在相似性搜索、基于 NLP 算法的相关性排名以及产品推荐和推荐引擎的上下文中使用 kNN 搜索。
使用 Elastic 实现 kNN 搜索
K-最近邻常见问题解答
何时使用 kNN?
使用 kNN 根据相似性进行预测。 因此,你可以使用 kNN 在自然语言处理算法的上下文中进行相关性排名、相似性搜索和推荐引擎或产品推荐。 请注意,当数据集相对较小时,kNN 非常有用。
kNN 是有监督机器学习还是无监督机器学习?
kNN 是监督机器学习。 它被提供一组它存储的数据,并且仅在查询时处理数据。
kNN 代表什么?
kNN 代表 k-近邻算法,其中 k 表示分析中考虑的最近邻的数量。
接下来你应该做什么
只要你准备好…我们可以通过以下 4 种方式帮助你将数据引入你的业务:
- 开始免费试用,看看 Elastic 如何帮助你的业务。
- 浏览我们的解决方案,了解 Elasticsearch 平台的工作原理以及我们的解决方案如何满足你的需求。
- 通过我们 45 分钟的网络研讨会,了解如何设置 Elasticsearch 集群并开始数据收集和摄取。
- 与你认识并喜欢阅读本文的人分享这篇文章。 通过电子邮件、LinkedIn、Twitter 或 Facebook 与他们分享。
