

建设并维护一个亿级的搜索引擎并非易事,也不存在一劳永逸的最优治理方法。本文是在实践中不断学习和总结的成果,介绍了如何搭建一个可支持从千万级到亿级商品量级的搜索系统,并实现查询总 QPS 从百级增长到千级,写入总 QPS 从百级增加到万级的过程。其中,ES 资源扩容是必不可少的,但除此之外,本文还将重点介绍一些扩容无法解决的 ES 性能问题。希望通过本文大家可以对 ES 的使用场景有更多数据和使用上的参考。由于篇幅有限,关于稳定性治理的部分将在下篇文章中进行介绍。
业务介绍
平台招商管理系统服务于抖音电商平台活动的多实体招商场景,会通过招商平台来进行收品,选品,然后分发品到各 C 端系统。招商的实体也非常的多样化,有达人直播间,商品招商,优惠券招商等等,其中商品招商是我们体量最大的招商实体。

招商平台服务架构
数据中心
数据中心是一个基于 ES 的搜索服务,提供可配置化的、可扩展的、通用的数据获取编排服务,是支持招商平台数据查询的通用服务。
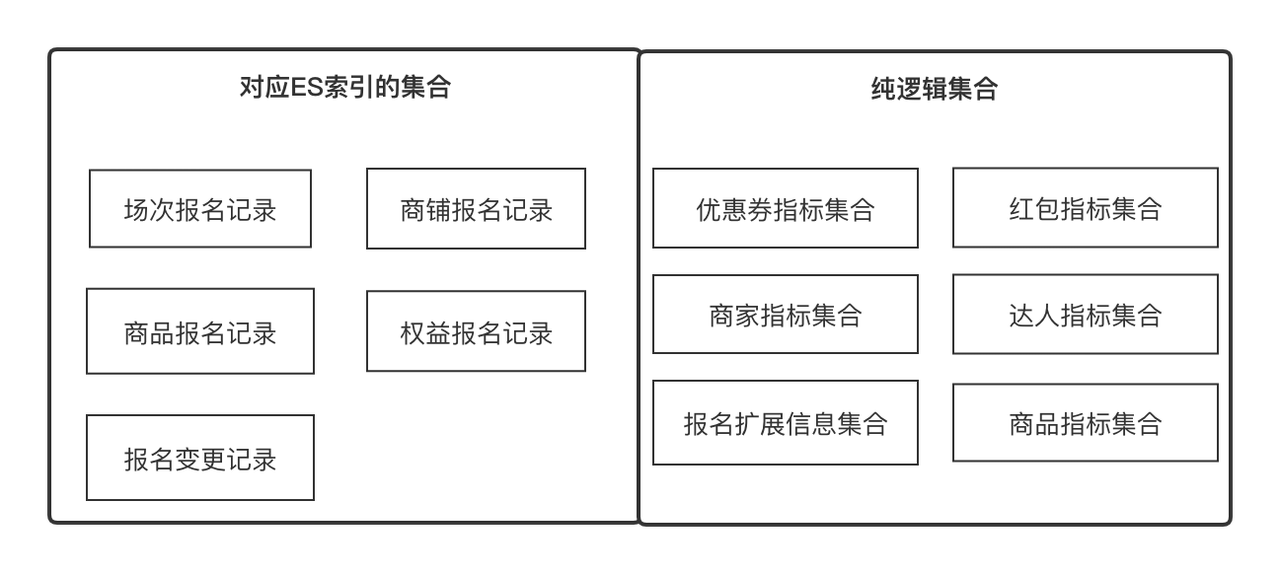
关键概念了解:
-
指标:指标是被我们用来描述一个实体或者对象的某个属性的元数据,比如商品名称,店铺体验分,达人等级,报名记录 ID,同时它也可以是某个对象的最小更新和获取单位,比如商品比价信息。一切有明确语义的字段我们都可以定义为指标
。 -
集合:表示一组可通过某种共性收敛的集合,比如商品属性集合,店铺属性集合,分别可以用商品 ID,店铺 ID 去获取,也可以是商品报名记录集合,通过报名记录 ID 获取,它在业务上表达一组有关联关系的指标,和指标是1对多的关系。
-
Solution:数据获取方案,我们抽象出指标和集合两个概念,是为了数据可以以最小单位获取,并且可以不断横向扩展,Solution 帮我们抽象不同集合下的指标的获取方式。
-
自定义表头:自定义表头即指任何一个二维行数据列表要展示的 Title,它和指标是 1 对多的关系;
-
筛选项:筛选项即指任何一个二维行数据列表需要使用的筛选项,它可指标是 1 对 1 的关系;
-
审核视图:审核视图指的是审核业务场景下,由一组自定义表头和一组筛选项可动态渲染出来的一个审核页面。

在功能设计中,通过指标–>【筛选项,自定义表头】–>审核视图–>最终动态渲染出一个审核页面的过程,由于我们是多实体多场景招商,不同实体不同场景需要不一样的审核视图,所以我们设计出来的这一系列能力,可以动态组合任何需要的审核视图效果。
数据中心就是为了上层业务提供通用数据获取能力的,包括数据同步,数据查询。数据来源目前有两个,外部 RPC 接口,以及报名记录 ES,数据中心整合了两套数据获取方案,对外完全无感知,即获取哪个集合下的哪些数据指标即可。
ES 搭建的意义就是为了支持招商报名记录的筛选统计能力的,为上层业务输出它想要的数据内容。
从 0 到 1 搭建 ES 集群
从 0 到 1 搭建系统,在满足基本业务需求的基础上,稳定性方面需要支持以下两点;
-
基本容灾机制,是指当系统因为基础组件,以及读写流量变化使性能受到影响时,业务能及时自我调整。
-
数据最终一致性,指报名记录 DB –> ES 多机房数据是完整的。
方案调研
ES 集群容量评估
ES 集群容量评估是为了保证集群搭建起来以后能够在未来一段时间内提供稳定服务的,主要需要能够解决以下问题:
-
每个索引应该设置多少分片,后续预估数据增量有多少,读写流量预估;
-
单个集群应该设置几个数据实例,单个数据实例采用什么规格;
-
了解垂直扩容和水平扩容的区别,当数据量超预期激增,或者流量超预期激增,我们的应对策略是什么,以及 ES 集群容灾应该怎样设计。
关键解决办法:
-
ES 索引分片数一旦设定,不可修改,所以确定分片数很重要,通常分片数和 ES 实例成整数倍关系,保证负载均衡;
-
单个分片的大小在 10~30G 是比较合理的,索引过大会影响查询性能;
-
流量激增可以依靠扩容解决,数据激增可删除存量老旧数据或增加分片数解决;并且必须采用多机房容灾部署方案部署,互为容灾机房。
数据同步链路选型
主要解决 DB 报名记录如何同步到 ES,其它相关联的指标如何写入 ES,如何更新及保证数据的一致性。
-
DB -> ES 需要是准实时数据流,报名记录等信息的变化必须是准实时可搜索到的;
-
报名记录除了本身字段还需要补充其报名商品,店铺,达人等属性字段,也写入到 ES,且
能够支持部分更新,所以 ES 写入方式只能是 Upsert 方式; -
单条报名记录更新必须是有序的,且不可冲突的。
ES 索引基本配置调研
了解必不可少的 ES 基本原理和配置。
-
{“dynamic”: false}避免 es mappings 自动膨胀,或新增非预期索引类型;
-
index.translog.durability=async,异步刷新 translog 有利于提升写入性能,但是有丢数据风险;
-
ES 默认 refresh interval为 1s,即表示数据写入成功后最快一秒可以查到。
数据同步方案
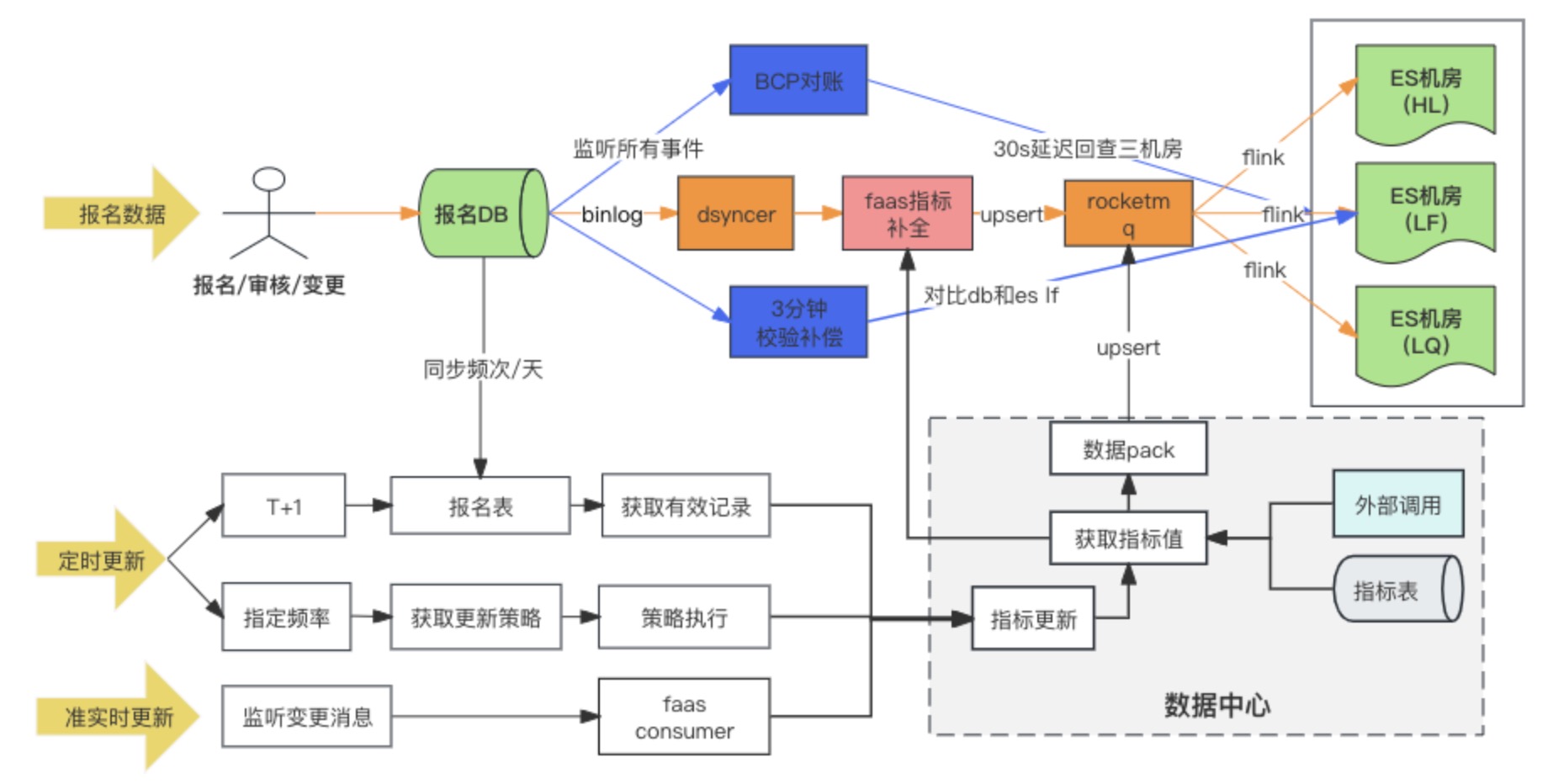
数据同步链路图
DB –> ES 数据同步方案,最终采用的是异构数据同步写 RocketMQ + Flink 多机房消费的方式,同时当报名记录首次写入时通过 Faas 自定义转换脚本填充扩展指标,扩展指标的更新依赖变更消息监听和定时任务两种方式。调研的时候,DB -> ES 多机房的方案其实有三种,最终我们选择了第三种方案,以下我们对比下三个方案的差异点:
方案一:通过 异构数据同步(Dsyncer)直接写入 ES 多机房

缺点:
-
直写在满足 ES 同步部署多机房的诉求上是处于弱势的,因为无法保证多机房同时写成功,那部署多个异构数据分别写可以吗?可以的,即工作量增加三倍,大约十几个索引。
-
直写 Bulk 的写入能力是相对弱的,随着流量波动写入尖刺也会比较明显,对 ES 的写入性能不友好。
-
直写无法保证 ES 多更新入口的情况下单条报名记录的有序更新,增加全局 Version 版本可以?可以的,但太重了。
优点:依赖路径最短,写入延迟低,系统风险最小,对于小流量的业务,以及同步场景简单的业务是完全没问题的。
方案二:通过 RocketMQ 写 ES 单机房
在 DB 通过 RocketMQ 写 ES 单机房后,通过 ES 提供的数据跨集群复制能力,将数据同步到其它机房。

方案三:通过 RocketMQ + Flink 方式写 ES 多机房 ✅
在 DB 通过 RocketMQ 写 ES 集群时,分别起多个独立的 Conusmer Group 任务,系统可采用 Flink 分布式系统,将数据分别写入多个机房。
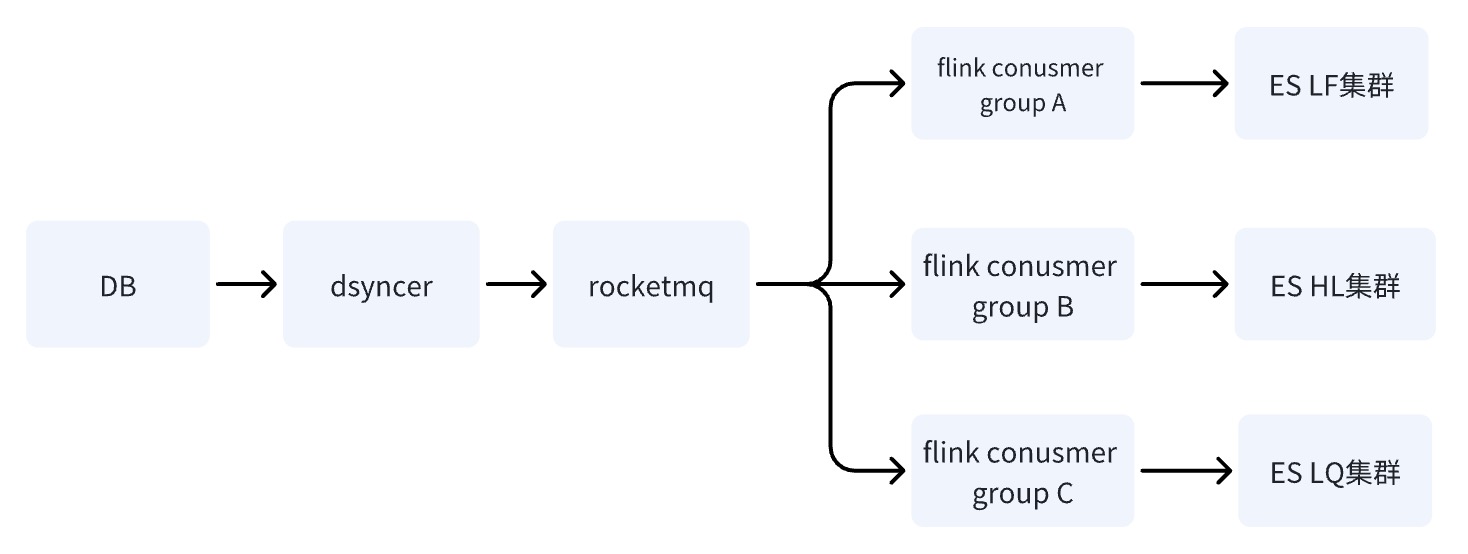
方案二和方案三的区别点只有一个:就是写多机房的方式不同,方案二是写到一个机房,然后将数据准实时同步到其它机房,而方案三是其多个独立的 Consumer 分别写多机房。
方案二和方案三的缺点是一样的:依赖路径最长,写入延迟容易受基础组件抖动的影响,然而方案二的致命缺点是
系统存在单点风险,假设通过 LF 同步数据到 HL 和 LQ,那么在 LF 挂掉之后系统也就无法使用了。
系统存在单点风险,假设通过 LF 同步数据到 HL 和 LQ,那么在 LF 挂掉之后系统也就无法使用了。
方案三的优点是多机房写入链路互相独立,相比方案二任何一条链路出问题,都不会对业务造成风险;RocketMQ 能轻松解决单 Key 顺序更新问题,
这也是方案一不可取的原因。
这也是方案一不可取的原因。
为什么通过 RocketMQ 写入就能解决乱序和冲突问题呢?
-
首先 ES 写入是基于 Version 版本号做乐观锁控制的,如果同时并发更新同一条记录,那么我们同时拿到的 Version 版本是一样的,假设是1,那么大家都将 Version 更新成2去写入,就会发生冲突,总是发生冲突就会造成丢失更新的问题;
-
一般业务场景都是需要保证基于 Key 有序消费,也是 Partition 有序消费,有序消费需要有两个必要条件:消息被存储时保持和发送的顺序一致;消息被消费时保持和存储的顺序一致。
所以业务想要消息的有序消费,就需要保证发送消息同 Key 发送到同一个 Partition,消费消息保证同 Key 消息始终被同一个 Consumer 消费。但事实上,上面提到的两个必要条件是理想状态下的,有些情况下是没法完全保证的,比如 Consumer Rebalance,比如写某 Broker 实例一直失败,具体下面会再分析出现原因和解决版本。
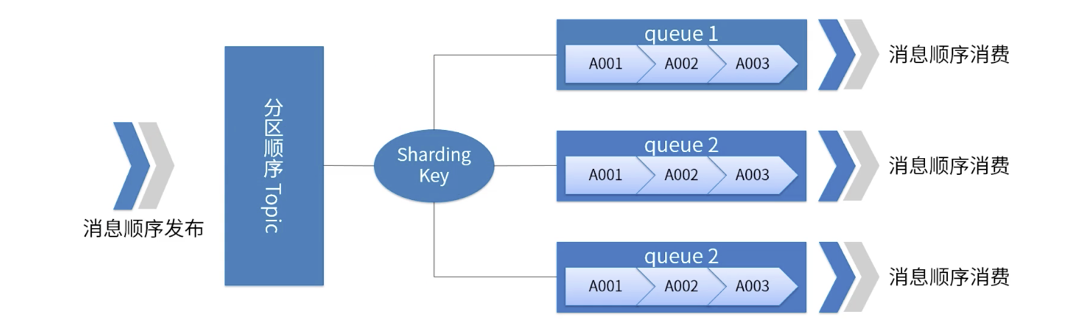
一张图说明 RocketMQ 分区有序
-
对于指定的一个 Topic,所有消息根据 Sharding Key 分成多个(Queue)。
-
同一个 Queue 内的消息按照严格的 FIFO 顺序进行发布和消费。
-
Sharding Key 是顺序消息中用来区分不同分区的关键字段,和普通消息的 Key 是完全不同的概念。
-
适用场景:性能要求高,根据消息中的 Sharding Key 去决定消息发送到哪一个 Queue,一般分区有序就可以满足我们的业务要求,同时性能高。
这里需要注意的是
:通过 RocketMQ 也许已经帮业务解决 99% 的乱序问题了,但并不是 100%,极端情况下消息仍可能出现乱序消费问题,比如发生 ABA 现象,比如 Partiton 故障时消息被重复发送到其他 Partition 队列等,所以一致性对账必不可少。
:通过 RocketMQ 也许已经帮业务解决 99% 的乱序问题了,但并不是 100%,极端情况下消息仍可能出现乱序消费问题,比如发生 ABA 现象,比如 Partiton 故障时消息被重复发送到其他 Partition 队列等,所以一致性对账必不可少。
多层对账机制
对账机制是解决 DB->ES 的数据一致性问题的,前面说 DB –> ES 是准实时数据流,并且依赖链路比较长,它在不同的状态下,我们都需要有对应的监控,对账和补偿策略,保证数据最终一致性。
这里我们是做了三层对账,通过对账平台对账,实现分钟级对账,以及离线对账,需要多层对账的原因会在下文一一进行解释。

DB 同步 ES 链路故障分析图
业务校验平台(BCP)秒级对账
参考上图,会发现 DB –> ES 同步依赖依赖组件比较多,这种情况下我们更需要一个
全局视角的对账来发现同步链路问题,即 BCP 实时对账。
全局视角的对账来发现同步链路问题,即 BCP 实时对账。
BCP 对账是监听 Binlog 直接查 ES 多机房对账的单流对账,仅依赖 Binlog 流,中间环节出现的数据同步延迟,或者阻塞都可通过 BCP 对账快速发现;细心的同学会发现,如果 Binlog 断流,BCP 对账就对不出来了,后面说怎么解决这种情况,但至少可以看出来, 除了 DB->DBus,BCP 对账足以发现大部分同步延迟问题。为什么采用单流而非多流?
-
避免多流对账的数据流链路较长,会带来的不可控延迟问题,导致校验准确性偏低。
-
BCP 对账的维护成本会大大降低,因为采用多流的话,多机房对账我们需要维护多份 BCP 对账,这其中依赖维护的基础组件更多。
BCP 对账 DB 写入总会触发 ES Get 请求,对 ES 有一定的查询资源消耗,但是 Get 请求是性能非常好的查询方式,比如我们在写入1000 QPS 以内是完全没问题的。
Get 请求需要注意一个参数 Realtime,请求时需要设置成 False,不然它每次请求都会触发一次 Refresh 操作,对系统写入性能是有影响的。
mgetReq := EsClient.MultiGet().
Realtime(false)
Realtime(false)
分钟级对账
上节说到业务校验平台(BCP)对账覆盖不到的路径是 DB->DBus,也就是 Binlog 断流的情况。通常 Binlog 断流可能已经意味着更严重的事故,但我们要做到的就是方方面面。
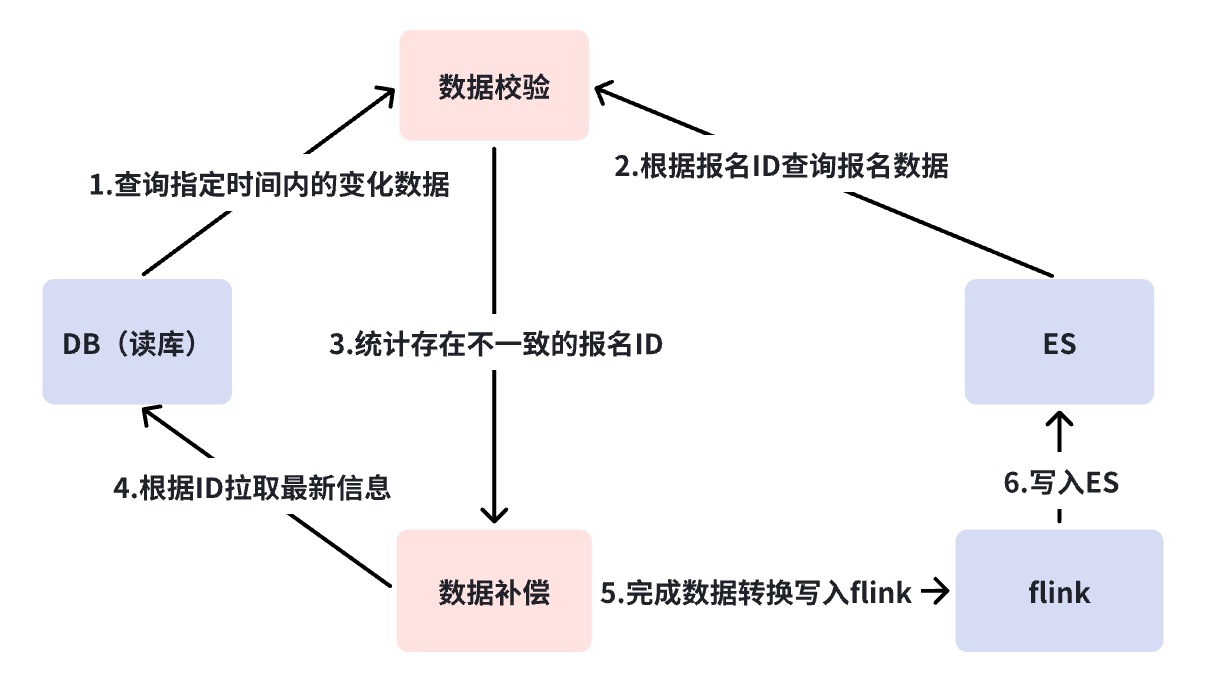
分钟级别对账是直接查询 DB 和 ES 进行对账,不依赖任何组件,当发生不一致时则自动补偿。分钟级别对账一方面弥补 BCP 对账的不足,第二点则是加入了补偿机制。BCP 不补偿的原因是因为 BCP 主要还是为了发现问题,所以要保持轻量快速,还有就是它依然依赖 RocketMQ,DBus 等基础组件,这种补偿仍然覆盖不住所有异常场景。
三分钟一次的对账默认情况下我们会认为组件功能完好,只是某节点出现短暂延迟而产生补偿,如果频繁发生补偿报警就需要进一步分析链路到底是哪里出了问题?此时在我们的场景下我会把链路一分为二,确认下 RocketMQ 之前链路出问题了,还是 RocketMQ 以及后续消费链路出现的问题。通过故障分析图,如果是 RocketMQ 之前链路出问题,比如 Binlog 断流、异构数据同步平台组件挂了等,则补偿数据直接写到 RocketMQ 中,消费到多机房的,此时读流量不用切流,且能够保证多机房数据的一致性。但如果 RocketMQ 挂了就会直接去写 ES 了,因为此时我们无法保证多机房同时写成功,所以我们的决策是只写单机房,将所有流量切换到单机房。
RocketMQ挂掉是个非常不好的信号,这里情况是比较复杂的。因为直写 ES,如果写流量高,系统此时失去了限流保护,ES 不一定扛得住;单机房不一定能够同时承受所有读流量;如果频繁发生写入冲突还需要做业务写入口降级。所以 RocketMQ 挂掉,可以理解为写链路的中枢系统瘫痪了,
这是最不想看到的情况,所以 RocketMQ 的 SLA 是业务的基线。
这是最不想看到的情况,所以 RocketMQ 的 SLA 是业务的基线。
T+1 离线对账
离线对账,是将 DB 和 ES 的数据天级同步到 Hive,增量数据校验最终一致性,如果不一致则自动发起补偿,离线对账是同步链路数据一致性的底线,数据最迟 T+1 补偿成功。
总结
以上我们已经完成了第一阶段的搭建,完成了容灾部署,一致性对账,以及基本系统异常应对策略。此时 ES 可以支持千万级别的商品索引的读写请求,单机房流量在 500 ~ 100 QPS 之间波动,写流量基本维持在 500 QPS 左右。
但随着业务的发展,ES 集群多次出现 CPU 暴涨,一个或多个机房同时被打满,查询延迟突然增加,然而读写流量却波动不大,或远不及系统峰值的情形,这种风险归源于 ES 集群出现的性能问题,以及业务的使用姿势问题。这部分内容我们将在下篇 ES 搜索引擎的稳定性治理中为大家继续介绍。
文章来源|字节跳动商业平台 王丹
