

原文链接
这篇文章写于 2022 年,前一年 GitLab 刚好完成 IPO。目前 GitLab 市值超过 100 亿美金,它的所有收入都来源于同名产品 GitLab,而这篇文章就是全面分析 GitLab 这个产品的数据库 schema。
我花了一些时间研究 GitLab 的 Postgres schema。GitLab 是 Github 的一个替代品。你可以自部署 GitLab,因为它是一个开源的 DevOps 平台。
我之所以要了解 Gitlab 这样的大项目的 schema,是为了与我正在设计的 schema 进行比较,并从他们的 schema 定义中学到一些最佳实践。我确实从中受益良多。
我清楚的知道,最佳实践取决于具体情况,不能盲目应用。
GitLab 的数据库 schema 文件 structure.sql [1] 包含超过 34000 行代码。GitLab 本质上是一个集成式的 Ruby on Rails 应用。虽然通常我们会用 schema.rb 文件来管理数据库的版本迁移,但 GitLab 团队在他们的问题追踪系统中的一个讨论 [2] 说明了他们选择 structure.sql 的原因。
原因在于 schema.rb 只能包含标准的迁移操作(使用 Rails DSL),这样做是为了使数据库 schema 文件对数据库系统保持中立,抽象化特定的 SQL 操作。这导致我们无法利用 PostgreSQL 的一些高级特性,如触发器、分区、物化视图等。
为了充分利用这些高级特性,我们应该考虑使用纯 SQL 格式的schema 文件 structure.sql,而不是 Ruby/Rails 的标准架构文件 schema.rb。
这意味着我们需要修改配置 config.active_record.schema_format = :sql,并重新以 SQL 格式生成数据库 schema。这可能还需要调整一些构建流程。 现在,让我们回顾一下我从 GitLab Postgres schema 中学到的东西。
为表使用正确的主键类型
在我的工作中,我犯了主键类型标准化的错误。这意味着将 bigint 或 uuid 标准化,这样所有表无论其结构、访问模式和增长速度如何,都将具有相同的类型。
当数据库规模较小时,这不会产生任何明显的影响,但当数据库规模扩大时,主键就会对存储空间、写入速度和读取速度产生明显的影响。因此,我们在为表选择正确的主键类型时应进行适当的思考。
正如我在之前的一篇文章 [3] 中所讨论的,当你使用 Postgres 本地 UUID v4 类型而不是 bigserial 类型时,表的大小会增加 25%,插入率则会下降到 bigserial 类型的 25%。这是一个很大的差别。我还与 ULID 进行了比较,但它的性能也很差。其中一个原因可能是 ULID 的实现。
在这种情况下,我很想了解 GitLab 是如何选择主键类型的。
在 573 个表中,380 个表使用 bigserial 主键类型,170 个表使用 serial4 主键类型,其余 23 个表使用复合主键。他们没有使用 uuid v4 主键或其他类似 ULID 的深奥键类型的表。
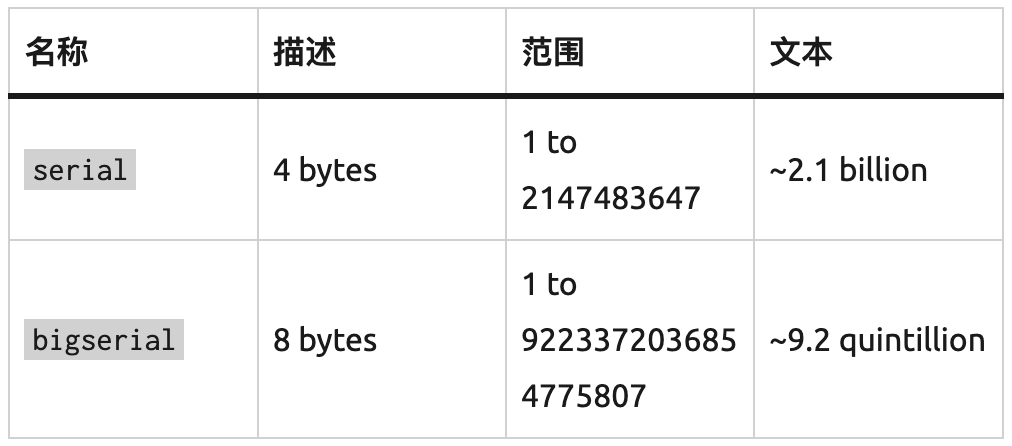
1 quintillion = 10 亿 billion
选择 serial 还是 bigserial 取决于表中记录的数量。
application_settings、badges、chat_teams、notification_settings、project_settings 等表使用串行类型。对于一些表,如 issues、web_hooks、merge_requests 和 projects,我很惊讶地发现它们使用了 serial 类型。
这个 serial 类型可能适用于自部署的社区或企业版本,但对于 GitLab.com SaaS 服务,这可能会造成问题。例如,GitHub 在 2020 年拥有 1.28 亿个公共仓库 [4]。即使每个仓库有 20 个问题,也会超过序列范围。此外,更改表格类型的成本也很高。表需要被重写,意味着你需要耐心等待。如果要对表进行分片,这同样会成为一个问题。
我做了一个快速实验,结果表明,对于我这个有两列和 1000 万条记录的表,将数据类型从 integer 改为 bigint 需要 11 秒。
create table exp_bs(id serial primary key, n bigint not null)
插入 1000 万条记录
insert into exp_bs(n) select g.n from generate_series(1,10000000) as g(n)
变更数据类型
alter table exp_bs alter column id TYPE bigint;
ALTER TABLE
Time: 10845.062 ms (00:10.845)
您还必须更改序列以改变其类型。这种操作很快。
alter sequence exp_bs_id_seq as bigint;
ALTER SEQUENCE
Time: 4.505 ms
所有 bigserial 序列都从 1 开始,直到 bigint 的最大值。
CREATE SEQUENCE audit_events_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
使用内部和外部 ID
通常,不向外部世界公开主键是一个好习惯。这在你使用 integer 或 bigint 型的顺序自增标识符时尤为重要,因为它们是可预测的。
因此,我很想知道在创建 GitLab 问题时会发生什么。是向外部用户公开主键 id,还是使用其他 id?如果公开 issues 表的主键 id,那么在项目中创建 issue 时,它就不会以 1 开头,你可以很容易猜出 GitLab 中存在多少个问题。这既不安全,用户体验也很差。
为了避免将主键暴露给终端用户,常见的解决方案是使用两个 ID。第一个是你的主键 id,它保持在系统内部,从不暴露于任何公共环境。第二个 id 是我们与外部世界共享的。根据我过去的经验,我使用 UUID v4 作为外部 id。正如我们在前一点中讨论的,使用 UUID 有存储成本。
GitLab 也在需要与外部世界共享 id 的表中使用内部和外部 id。像 issues、ci_pipelines、deployments、epics 以及其他一些表有两个 id – id 和 iid。下面是 issue schema 的一部分。如下所示,iid 的数据类型为 integer。
CREATE TABLE issues (
id integer NOT NULL,
title character varying,
project_id integer,
iid integer,
// ……)
正如你所看到的,有 id 和 iid 两列。iid 列的值与最终用户共享。一个 issue 使用 project_id 和 iid 进行唯一标识。这是因为可能有多个 issue 具有相同的 iid。为了更清楚地说明这一点,如果您创建了两个项目,并在每个版本库中创建了一个 issue,那么这两个项目的可见 ID 都必须是 1,如下图所示。sg 和 sg2 项目都以 issue ID 1 开始。
https://gitlab.com/shekhargulati123/sg/-/issues/1
https://gitlab.com/shekhargulati123/sg2/-/issues/1
它们在 project_id 和 iid 上都有一个唯一索引,以便快速有效地获取 issue。
CREATE UNIQUE INDEX index_issues_on_project_id_and_iid ON public.issues USING btree (project_id, iid);
使用带有检查约束的 text 字符类型
Postgres 文档 [5] 中描述了三种字符类型。
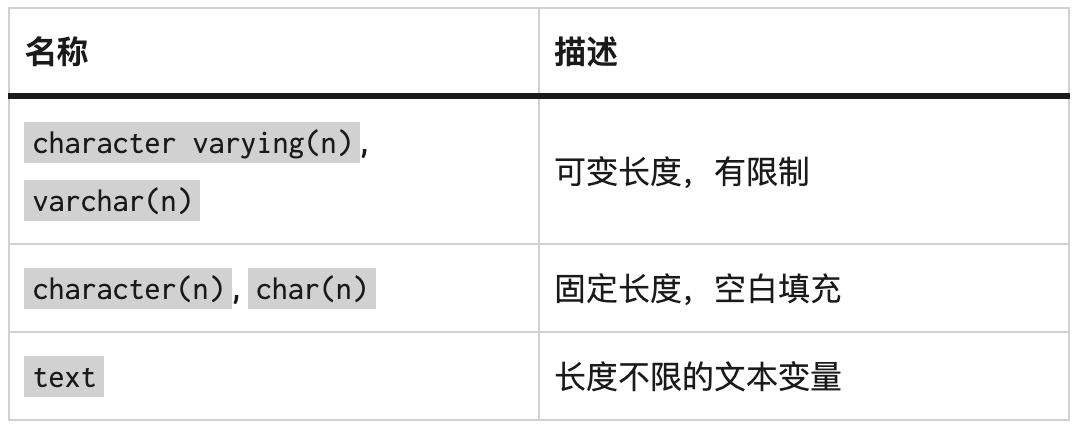
我主要使用 character varying(n) 或 varchar(n) 来存储字符串值。GitLab schema 既使用character varying(n),也使用 text,但更常用的是 text 类型。下面是一个这样的示例表。
CREATE TABLE audit_events (
id bigint NOT NULL,
author_id integer NOT NULL,
entity_id integer NOT NULL,
entity_type character varying NOT NULL,
details text,
ip_address inet,
author_name text,
entity_path text,
target_details text,
created_at timestamp without time zone NOT NULL,
target_type text,
target_id bigint,
CONSTRAINT check_492aaa021d CHECK ((char_length(entity_path) 可以看到,除了 entity_type 之外,所有其他列都是 text 类型。他们使用 CHECK 来定义长度约束。
正如网上多篇文章 [6,7] 所述,这两种类型的性能差别不大。它们底层都采用了 varlena 类型来存储。
varchar(n) 的问题在于,如果 n 的限制变多,就需要独占锁。这可能会导致性能问题,具体取决于表的大小。
而使用 CHECK 约束的 text 列则没有这个问题。但在写入过程中会有一点代价。 让我们做一个简单的实验来证明这一点。我们先创建一个简单的表
create table cv_exp (id bigint primary key, s varchar(200) default gen_random_uuid() not null);
create index sidx on cv_exp (s);
插入 1000 万条记录
insert into cv_exp(id) select g.n from generate_series(1,10000000) as g(n);
如果我们将 s 的长度从 200 增加到 300,那么它很快执行完。
alter table cv_exp alter column s type varchar(300);
ALTER TABLE
Time: 37.460 ms
但是,如果我们将 s 的长度从 300 减少到 100,就会花费相当多的时间。
alter table cv_exp alter column s type varchar(100);
ALTER TABLE
Time: 35886.638 ms (00:35.887)
让我们对 text 列做同样的处理。
create table text_exp (id bigint primary key, s text default gen_random_uuid() not null,CONSTRAINT check_15e644d856 CHECK ((char_length(s) 插入 1000 万条记录。
insert into text_exp(id) select g.n from generate_series(1,10000000) as g(n);
在 Postgres 中没有 alter 约束。您必须删除约束,然后添加新约束。
alter table text_exp drop constraint check_15e644d856;
重新添加。
alter table text_exp add constraint check_15e644d856 CHECK ((char_length(s) 正如您所看到的,与具有长度检查的 character varying 或 varchar(n) 相比,具有 CHECK 约束的 text 类型可以让你轻松改进 schema。
我还注意到,他们在不需要长度检查的地方使用了 character varying ,如下图所示。
CREATE TABLE project_custom_attributes (
id integer NOT NULL,
created_at timestamp with time zone NOT NULL,
updated_at timestamp with time zone NOT NULL,
project_id integer NOT NULL,
key character varying NOT NULL,
value character varying NOT NULL
);
命名规范
命名遵循以下规则。
- 所有表都采用复数形式,如 issues、projects、audit_events、abuse_reports、approvers 等。
- 表使用模块名称作为前缀,以提供命名空间。例如,所有与合并请求功能相关的表都以 merge_request 前缀开头,如下所示:
- merge_request_assignees
- merge_request_blocks
- merge_request_cleanup_schedules
- merge_request_context_commit_diff_files
- merge_request_context_commits
- 等等…
- 表和列的命名遵循蛇形命名法(snake_case),即使用下划线将两个或更多单词连接起来,例如 title、created_at、is_active。
- 表达布尔值的列根据其用途遵循以下三种命名规则之一:
- 功能开关,如 create_issue、send_email、packages_enabled、merge_requests_rebase_enabled 等。
- 实体状态,如 deployed、onboarding_complete、archived、hidden等。
- 限定词,以 is_xxx 或 has_xxx 开头,如 is_active、is_sample、has_confluence 等。我认为这些可以通过上述两种方式来表达。
- 索引的命名遵循 index_#{table_name}on#{column_1}and#{column_2}_#{condition} ,例如 index_services_on_type_and_id_and_template_when_active、index_projects_on_id_service_desk_enabled。
带时区和不带时区的时间戳
GitLab 同时使用了 带时区的时间戳 和 不带时区的时间戳。 根据我的理解,系统执行动作时采用的是 不带时区的时间戳,而涉及用户操作时则使用 带时区的时间戳。例如,以下 SQL 示例中的 created_at 和 updated_at 字段就采用了不带时区的时间戳,而 closed_at 字段则使用了带时区的时间戳。
CREATE TABLE issues (
id integer NOT NULL,
title character varying,
created_at timestamp without time zone,
updated_at timestamp without time zone,
closed_at timestamp with time zone,
closed_by_id integer,
);
另一个例子是 merge_request_metrics 表,其中 latest_closed_at、first_comment_at、first_commit_at 和 last_commit_at 字段使用了带时区的时间戳,而 latest_build_started_at、latest_build_finished_at 和 merge_at 则采用了不带时区的时间戳。你可能会对 merge_at 不使用时区感到疑惑。我认为这是因为系统可以基于特定的条件或检查来执行合并操作。
CREATE TABLE merge_request_metrics (
id integer NOT NULL,
latest_build_started_at timestamp without time zone,
latest_build_finished_at timestamp without time zone,
merged_at timestamp without time zone,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
latest_closed_at timestamp with time zone,
first_comment_at timestamp with time zone,
first_commit_at timestamp with time zone,
last_commit_at timestamp with time zone,
first_approved_at timestamp with time zone,
first_reassigned_at timestamp with time zone
);
外键约束
外键约束是两个表之间行的逻辑关联。通常在查询中使用外键来连接表。
外键约束是一种数据库机制,用于强制维护外键关系的完整性(参考完整性),确保子表只有在父表中存在对应行时才能进行引用。此约束还通过多种方式防止不同表中出现 “孤儿行 (orphaned row)”。
过去几年里,我参与的多个项目中,团队/架构师决定不采用外键约束,主要原因是担心性能影响。
外键创建时可能会导致性能下降的一个情况是,当它与 ON DELETE CASCADE 操作一起使用时。这种操作的机制是,如果父表中的一行被删除,子表中所有引用该行的记录也会在同一事务中被删除。本来可能预期删除一行,结果却可能导致删除数百、数千乃至更多的子表行。但这种情况只有在一个父行与大量子表行关联时才会出现问题。
团队不采用外键约束的另外两个原因是:
- 在线 DDL schema 迁移操作中,特别是在 MySQL 中,外键约束的兼容性不好。
- 一旦将数据分片至多个数据库服务器,维护外键约束变得困难。
类似 PlanetScale(基于开源 Vitess 数据库)的兼容 MySQL 的 serverless 数据库不支持外键。
因此,我很想知道 GitLab 是否使用外键约束。
除了 audit_events 、abuse_reports、web_hooks_logs 和 spam_logs 等少数几个表之外,GitLab 在大多数表中都使用了外键约束。我认为不在这些表中使用外键约束有两个主要原因。这两个原因是:
- 这些表在本质上是不可变的。一旦条目被写入,你就不想再更改它们了
- 这些表的行数可达数百万(或更多),因此即使是很小的性能损失也会造成很大影响
GitLab 使用外键的其他表都使用了 ON DELETE CASCADE、ON DELETE RESTRICT 和 ON DELETE SET NULL 操作。下面分别举例说明。
ALTER TABLE ONLY todos
ADD CONSTRAINT fk_rails_a27c483435 FOREIGN KEY (group_id) REFERENCES namespaces(id) ON DELETE CASCADE;
ALTER TABLE ONLY projects
ADD CONSTRAINT fk_projects_namespace_id FOREIGN KEY (namespace_id) REFERENCES namespaces(id) ON DELETE RESTRICT;
ALTER TABLE ONLY authentication_events
ADD CONSTRAINT fk_rails_b204656a54 FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE SET NULL;
- ON DELETE SET NULL 会将匹配记录的子表引用列设置为空。这会导致记录成为孤儿,但由于 NULL 的存在,你可以很容易地识别它们。在此操作中,删除一条记录也会导致子表中更新多条记录。这可能会导致大型事务、过度锁定和复制滞后。
- ON DELETE RESTRICT 可以防止删除引用的子表记录。这不会导致子表成为孤儿,因为如果有子表引用父表记录,就无法删除父表记录。你会得到如下所示的异常。
ERROR: update or delete on table "a" violates foreign key constraint "fk_a_id" on table "b"
DETAIL: Key (id)=(1) is still referenced from table "b".
大表分区
GitLab 通过分区技术来处理可能增长至庞大规模的表格,目的是为了提升查询性能。
- 按范围分区(PARTITION BY RANGE):这种分区方法根据选定的范围来分区表格数据。这种策略通常适用于需要对时间序列数据进行分区的场景。例如,audit_events(审计事件)和 web_hook_logs(Web 钩子日志)表就采用了这种分区策略。
- 按列表分区(PARTITION BY LIST):这种分区方法根据某一列的离散值来对表格数据进行分区。loose_foreign_keys_deleted_records(松散外键删除记录)表就是采用这种分区策略的例子。
- 按哈希分区(PARTITION BY HASH):这种分区方法通过为每个分区指定一个模数和余数来进行。每个分区将包含那些其分区键的哈希值除以指定模数后得到指定余数的行。product_analytics_events_experimental(产品分析事件实验)表采用了这种分区策略。 有关 Postgres 分区的更多信息,请参阅 Postgres 文档。
使用 Trigrams 和 gin_trgm_ops 支持 LIKE 搜索用例
GitLab 使用 GIN(通用反向索引)索引来执行高效搜索。
GIN 索引类型是为处理可细分的数据类型而设计的,您希望搜索单个组件值(数组元素、文本文档中的词条等)”。- 汤姆-莱恩
由于 LIKE 操作支持任意通配符表达式,因此从根本上说很难编制索引。其中一个例子是问题表,您可能想对标题和描述字段进行搜索。因此,我们使用 pg_trgm 扩展来创建一个可用于 Trigrams 的索引。
CREATE INDEX index_issues_on_title_trigram ON issues USING gin (title gin_trgm_ops);
CREATE INDEX index_issues_on_description_trigram ON issues USING gin (description gin_trgm_ops);
GIN 索引使搜索变得高效。让我们来看看实际操作。 我们将创建一个简单的表,如下所示。
create table words(id serial primary key, word text not null);
让我们插入一些数据。我从这个链接中提取了 CSV 格式的英语单词列表。
copy words(word) from '/Users/xxx/Aword.csv' CSV;
select count(*) from words;
count
-------
11616
(1 row)
我们将在 word 列上创建一个 btree 索引,稍后我们将使用 gin 索引来显示其效率。
create index id1 on words using btree (word);
让我们运行解释计划查询。
EXPLAIN select * from words where word like '%bul%';
QUERY PLAN
-----------------------------------------------------------
Seq Scan on words (cost=0.00..211.20 rows=1 width=14)
Filter: (word ~~ '%bul%'::text)
(2 rows)
现在,让我们删除 btree 索引。
drop index id1;
安装 pg_trm 扩展。
CREATE EXTENSION pg_trgm;
创建索引。
create index index_words_on_word_trigram ON words USING gin (word gin_trgm_ops);
现在,运行 Explain。
EXPLAIN select count(*) from words where word like '%bul%';
QUERY PLAN
----------------------------------------------------------------------------------------------------
Aggregate (cost=16.02..16.03 rows=1 width=8)
-> Bitmap Heap Scan on words (cost=12.01..16.02 rows=1 width=0)
Recheck Cond: (word ~~ '%bul%'::text)
-> Bitmap Index Scan on index_words_on_word_trigram (cost=0.00..12.01 rows=1 width=0)
Index Cond: (word ~~ '%bul%'::text)
(5 rows)
GitLab 还使用 tsvector 支持完整的全文搜索。
在主数据存储中进行文本搜索的优势在于:
- 实时索引。创建索引无延迟
- 访问完整数据
- 降低架构的复杂性
使用 jsonb
正如我在前一篇文章中所讨论的,我在 schema 设计中将 json 数据类型用于以下用例:
- 转储稍后处理的请求数据
- 支持附加字段
- 一对多关系,其中多方都没有自己的标识
- Key Value
- 更简单的 EAV (Entity-Attribute-Value) 设计
GitLab schema 设计也在多个表中使用 jsonb 数据类型。他们主要将其用于上述列表中的 1 和 2 用例。与纯文本存储相比,使用 jsonb 的优势在于 Postgres 支持对 jsonb 数据类型进行高效查询。 例如,表 error_tracking_error_events 以 jsonb 数据类型存储有效负载。这是一个转储请求数据的示例,将在后面的用例中进行处理。
CREATE TABLE error_tracking_error_events (
id bigint NOT NULL,
payload jsonb DEFAULT '{}'::jsonb NOT NULL,
// ...
);
你可以使用 JSON schema 来验证 JSON 文档的结构。
另一个例子是下图中的 operations_strategies 表。您不知道可能会收到多少个参数,因此需要像 jsonb 这样灵活的数据类型。
CREATE TABLE operations_strategies (
id bigint NOT NULL,
feature_flag_id bigint NOT NULL,
name character varying(255) NOT NULL,
parameters jsonb DEFAULT '{}'::jsonb NOT NULL
);
支持附加字段用例如下所示。
CREATE TABLE packages_debian_file_metadata ( created_at timestamp with time zone NOT NULL, updated_at timestamp with time zone NOT NULL, package_file_id bigint NOT NULL, file_type smallint NOT NULL, component text, architecture text,fields jsonb,);
他们还使用 jsonb 来存储已经是 JSON 格式的数据。例如,在表 vulnerability_finding_evidences 中,报告数据已经是 JSON 格式,因此他们将其保存为 jsonb 数据类型。
CREATE TABLE vulnerability_finding_evidences (
id bigint NOT NULL,
created_at timestamp with time zone NOT NULL,
updated_at timestamp with time zone NOT NULL,
vulnerability_occurrence_id bigint NOT NULL,
data jsonb DEFAULT '{}'::jsonb NOT NULL
);
其他花絮
- 审计字段(如 updated_at)只用于可修改记录的表中。例如,issues 就有一个 updated_at 列。对于只可附加的不可变日志表(如 audit_events),则没有 updated_at 列,如下代码片段所示。有 updated_at 列的 issues 表。
CREATE TABLE issues (
id integer NOT NULL,
title character varying,
author_id integer,
project_id integer,
created_at timestamp without time zone,
updated_at timestamp without time zone,
// removed remaining columns and constraints
);
没有 updated_at 列的 audit_events 表。
CREATE TABLE audit_events (
id bigint NOT NULL,
author_id integer NOT NULL,
entity_id integer NOT NULL,
created_at timestamp without time zone NOT NULL,
// removed remaining columns and constraints
);
-
- 枚举值存储为 smallint 而非 character varying,以节省空间。唯一的问题是不能更改枚举值的顺序。在下面的示例中,reason 和 severity_level 是枚举值。
CREATE TABLE merge_requests_compliance_violations (
id bigint NOT NULL,
violating_user_id bigint NOT NULL,
merge_request_id bigint NOT NULL,
reason smallint NOT NULL,
severity_level smallint DEFAULT 0 NOT NULL
);
- 在少数几个表(如 issues 和 ci_builds)中使用乐观锁定机制,以防止多方同时编辑所导致的冲突。乐观锁定假设数据冲突的情况极少,如果发生冲突,应用会抛出异常并忽略更新。如果表中存在 lock_version 字段,则 Active Record 会支持乐观锁定,每次更新都会增加 lock_version 列的值。锁定机制可确保两次实例化的记录在第一次也被更新的情况下,最后保存的记录会引发 StaleObjectError 异常。下面显示的 ci_builds 表使用了 lock_version 列。
CREATE TABLE ci_builds (
status character varying,
finished_at timestamp without time zone,
trace text,
lock_version integer DEFAULT 0,
// removed columns
CONSTRAINT check_1e2fbd1b39 CHECK ((lock_version IS NOT NULL))
);
- 使用 inet 来存储 IP 地址。我不知道有 inet 类型。他们在 audit_events 和 authentication_events 表中使用了 inet。
CREATE TABLE audit_events (
id bigint NOT NULL,
ip_address inet,
// ……
);
GitLab 并未在所有存储 ip_address 的表中使用 inet。例如,在 ci_runners 和 user_agent_details 表中,他们将其存储为 character varying。我不清楚为什么他们没有在所有存储 ip 地址的表中使用相同的类型。
与将 ip 地址存储为纯文本类型相比,您应该选择 inet 类型,因为这些类型提供了输入错误处理和专门功能。
让我们快速了解一下它的操作。首先,我们将创建一个包含两个字段(id 和 ip_addr)的表。
create table e (id serial primary key, ip_addr inet not null);
我们可以插入一条有效记录,如下所示。
insert into e(ip_addr) values ('192.168.1.255');
我们还可以插入带掩码的记录,如下所示。
insert into e(ip_addr) values ('192.168.1.5/24');
这两条记录都将被插入。
select id, abbrev(ip_addr) from e;
id | abbrev
----+----------------
1 | 192.168.1.255
2 | 8.8.8.8
3 | 192.168.1.5/24
(3 rows)
如果我们试图保存无效数据,则插入将失败。
insert into e(ip_addr) values ('192.168.1');
ERROR: invalid input syntax for type inet: "192.168.1"
LINE 1: insert into e(ip_addr) values ('192.168.1');
你可以使用 Postgres 支持的 inet 操作符检查子网是否包含 IP 地址,如下所示。
select * from e where ip_addr 如果要检查子网是否包含或相等,我们可以执行以下操作。
select * from e where ip_addr Postgres 还支持许多其他操作符和函数。你可以在 Postgres 文档中阅读它们。
- Postgres 的 bytea 数据类型用于存储SHA、加密令牌、加密密钥、加密密码、指纹等。
- Postgres 的数组类型用于存储具有多个值的列。
数组应在完全确定不需要在数组中的项目与其他表之间创建任何关系的情况下使用。它应该用于紧密耦合的一对多关系。
例如,在下图所示的表中,我们将 *_ids 存储为数组,而不是以平面方式存储并定义与其他表的关系。我们不知道有多少用户和项目会被提及,因此创建诸如 mentioned_user_id1 , mentioned_user_id2, mentioned_user_id3 等列会造成浪费。
CREATE TABLE alert_management_alert_user_mentions ( id bigint NOT NULL, alert_management_alert_id bigint NOT NULL, note_id bigint, mentioned_users_ids integer[], mentioned_projects_ids integer[], mentioned_groups_ids integer[]);
Postgres 数组的另一个常见用例是存储 hosts、tags 和 urls 等字段。
CREATE TABLE dast_site_profiles (
id bigint NOT NULL,
excluded_urls text[] DEFAULT '{}'::text[] NOT NULL,
);
CREATE TABLE alert_management_alerts (
id bigint NOT NULL,
hosts text[] DEFAULT '{}'::text[] NOT NULL,
);
CREATE TABLE ci_pending_builds (
id bigint NOT NULL,
tag_ids integer[] DEFAULT '{}'::integer[],
);
总结
通过 GitLab 的数据库 schema 设计,我学到了很多。他们并不是盲目地将相同的实践应用于所有表设计。每个表都根据其目的、存储的数据类型以及增长速度做出最佳决策。
如果你需要像 GitLab 一样约束表结构设计的话,可以使用 Bytebase 的 SQL 审核功能,针对包括 Postgres 的各种数据库,它提供了上百条 SQL 审核规则。
参考资料
- Gitlab schema structure.sql – https://gitlab.com/gitlab-org/gitlab/-/blob/master/db/structure.sql
- Issue 29465: Use structure.sql instead of schema.rb – https://gitlab.com/gitlab-org/gitlab/-/issues/29465
- Choosing Primary Key Type in Postgres – https://shekhargulati.com/2022/06/23/choosing-a-primary-key-type-in-postgres/
- Github’s Path to 128M public repositories – https://towardsdatascience.com/githubs-path-to-128m-public-repositories-f6f656ab56b1#:~:text=There%20are%20over%20128%20million%20public%20repositories%20on%20GitHub.
- Postgres Character Types Documentation – https://www.postgresql.org/docs/current/datatype-character.html
- Difference between text and varchar (character varying) – https://stackoverflow.com/questions/4848964/difference-between-text-and-varchar-character-varying
- CHAR(x) vs. VARCHAR(x) vs. VARCHAR vs. TEXT – https://www.depesz.com/2010/03/02/charx-vs-varcharx-vs-varchar-vs-text/
💡 更多资讯,请关注 Bytebase 公号:Bytebase
