

作者:壮怀、竹刚
AIGC 中的 Stable Diffusion 文生图模型是开源流行的跨模态生成模型,用于生成给定文本对应的图像。但由于众所周知的原因,GPU 资源出现了一卡难求的现状,如何通过云计算快速提升业务规模,降低文生图的计算成本,以及更好的保护自定义的扩展模型?针对文生图模型特性和规模化场景,本文提供了一种新的思路,通过云原生部署方式提供推理服务 API,使用 CPU 矩阵计算能力针对模型进行无侵入优化,以及机密计算的环境的无缝切换,可以有效的替代部分 GPU 推理需求,提供稳定、高效、高性价比且安全的文生图服务。
通过在 Kubernetes 集群内添加阿里云第八代企业级 CPU 实例 g8i,不修改模型本身,通过云原生化的部署和推理优化,在 CPU 节点上实现秒级响应的成本低廉的文生图服务。本文介绍如何在 ACK 集群中快速部署一个使用 CPU 加速的 Stable Diffusion 文生图示例服务,并且您还可以将这个示例服务无缝迁移到机密虚拟机节点池中,为您的推理服务提供数据安全保护。
准备环境
在 ACK 集群内创建一个使用阿里云第八代企业级实例 g8i 的节点池,确保实例规格的 CPU 大于或等于 16vCPU,可以使用 ecs.g8i.4xlarge,ecs.g8i.8xlarge 或 ecs.g8i.12xlarge 实例规格。(如果你还没有一个阿里云 Kubernetes 集群,请参见创建 Kubernetes 托管版集群 [ 1] 。)
一步生成文生图服务
- 使用默认参数执行以下命令,在集群内部署一个使用的 Stable Diffusion XL Turbo 模型。
helm install stable-diffusion-ipex https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.9.tgz
- 等待约 10 分钟,然后执行以下命令检查 Pod 状态,确保运行正常。
kubectl get pod |grep stable-diffusion-ipex
预期输出:
stable-diffusion-ipex-577674874c-lhnlc 1/1 Running 0 11m
stable-diffusion-ipex-webui-85d949d9bd-mcwln 1/1 Running 0 11m
服务部署完成后,对外提供了一个文生图 API 和 web UI。
测试文生图服务
- 执行以下命令,将 Stable Diffusion XL Turbo 模型服务提供的 web UI 转发到本地。
kubectl port-forward svc/stable-diffusion-ipex-webui 5001:5001
预期输出:
Forwarding from 127.0.0.1:5001 -> 5001
Forwarding from [::1]:5001 -> 5001
-
在浏览器中打开 http://127.0.0.1:5001/ ,访问 web UI 页面。
-
在这个 web UI 页面中,您可以点击【生成图片】按钮使用输入的提示词生成图片。
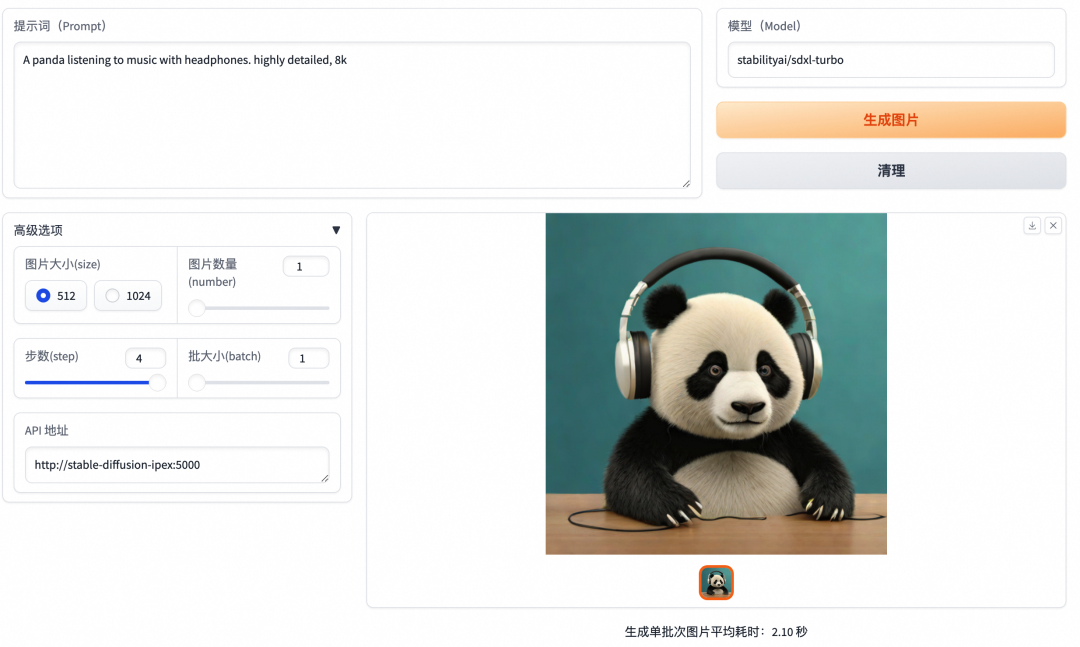
测试提示词:
"A panda listening to music with headphones. highly detailed, 8k."
"A dog listening to music with headphones. highly detailed, 8k."
“A robot cat eating spaghetti, digital art, 8k.”
“A large blob of exploding splashing rainbow paint, with an apple emerging, 8k.”
“An astronaut riding a galloping horse, 8k.”
“A family of raccoons living in a small cabin, tilt shift, arc shot, 8k.”
“A tree walking through the forest, tilt shift, 8k.”
“An octopus attacks New York, 8k.”
“Motorcyclist on a racing track, highly detailed, 8k.”
“Humans building a highway on Mars, cinematic, 8k.”
性能测试
使用不同 ECS g8i 实例规格在 Stable Diffusion XL Turbo 模型中生成 512×512、1024×1024 图片的耗时信息(单个 batch)。下表结果数据仅为实验参考,实际数据可能会因您的操作环境而发生变化。
| 实例规格 | Pod Request/Limit | 参数 | 单次平均耗时 (512×512) | 单次平均耗时 (1024×1024) |
|---|---|---|---|---|
| ecs.g8i.4xlarge(16 vCPU 64 GiB) | 14/16 | batch: 1step: 4 | 2.2s | 8.8s |
| ecs.g8i.8xlarge(32 vCPU 128 GiB) | 24/32 | batch: 1step: 4 | 1.3s | 4.7s |
| ecs.g8i.12xlarge(48 vCPU 192 GiB) | 32/32 | batch: 1step: 4 | 1.1s | 3.9s |
从推理速度的绝对性能来看,在多 batch 和多步的推理场景下,CPU 的推理速度仍然与 A10 的 GPU 实例有所差距。采用 ecs.g8i.8xlarge 的 CPU 机型、step 为 30、batch 为 16 时,图片生成速度为 0.14 images/s;采用 A10 的 GPU 实例、step 为 30,batch 为 16 时,图片生成速度为 0.4 images/s。但从最佳图像生成质量的推理性能来看,采用 ecs.g8i.8xlarge 的 CPU 机型、step 为 4、batch 为 16 时,图像生成速度为 1.2 images/s,仍可实现秒级出图性能。
因此,通过合理运用 CPU 加速策略和文生图模型推理的最佳实践,ECS g8i 等第八代 CPU 实例可用于替代 GPU 推理实例,提供稳定、高效、高性价比且安全机密的文生图服务。
在追求性价比、模型安全 TEE 和大规模资源供给的文生图推理场景下,建议采用 ecs.g8i.4xlarge 机型运行 stabilityai/sdxl-turbo 及相关的微调模型,以最优性价比的方式提供高质量的文生图服务。
- 使用 ecs.g8i.8xlarge 实例代替 ecs.gn7i-c8g1.2xlarge 时,可有效节省约 9% 的成本,并依然保持 1.2 images/s 的图像生成速度。
- 使用 ecs.g8i.4xlarge 实例替代 ecs.gn7i-c8g1.2xlarge 时,图像生成速度降为 0.5 images/s,但可有效节省超过 53% 的成本。
One more things,更安全的机密推理
使用 ACK 集群的 TDX 机密虚拟机节点池,通过采用 ECS g8i 实例并结合 AMX + IPEX 技术,能够有效加速文生图模型的推理速度,并可以开启TEE实现对模型推理的安全保护。通过简单的打标和更新模型部署,可以把模型部署迁移进入内存加密的机密虚拟机环境。
-
在 ACK 集群内创建一个机密计算节点池,参考创建机密虚拟机节点池 [ 2] 。
-
将以下内容保存为 tdx_values.yaml。说明此处以为 TDX 机密虚拟机节点池配置了标签 nodepool-label=tdx-vm-pool 为例,如果您配置了其他标签,需替换 nodeSelector 中 nodepool-label 取值。
nodeSelector:
nodepool-label: tdx-vm-pool
- 执行以下命令,将部署的 Stable Diffusion 示例模型迁移到 TDX 机密计算节点池。
helm upgrade stable-diffusion-ipex https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.9.tgz -f tdx_values.yaml
结论
在追求性价比、模型安全和大规模资源供给的文生图推理场景下,建议采用 ecs.g8i.4xlarge, ecs.g8i.8xlarge,ecs.g8i.12xlarge 机型补充,代替部分 GPU 实例运行 stabilityai/sdxl-turbo 及相关的微调模型,通过合理运用节点池管理,应用和 API 的部署模版 Helm Chart,Intel CPU 加速扩展,以最优性价比的方式提供稳定、高效、安全机密的文生图服务。
- 使用 ecs.g8i.8xlarge 实例代替 ecs.gn7i-c8g1.2xlarge 时,可有效节省约 9% 的成本,并依然保持 1.2 images/s 的图像生成速度。
- 使用 ecs.g8i.4xlarge 实例替代 ecs.gn7i-c8g1.2xlarge 时,图像生成速度降为 0.5 images/s,但可有效节省超过 53% 的成本。
更详细参考:https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/using-tee-cpu-to-accelerate-text2image-inference
相关链接:
[1] 创建 Kubernetes 托管版集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/create-an-ack-managed-cluster-2#task-skz-qwk-qfb
[2] 创建机密虚拟机节点池https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/create-tdx-confidential-vm-node-pools
