

目录
前言
一、ShardingSphere4.1.1的spring boot配置
二、ShardingSphere的分片策略
三、SpringBoot 整合 ShardingSphere4.1.1
四、ShardingSphere实现分布式事务控制
前言
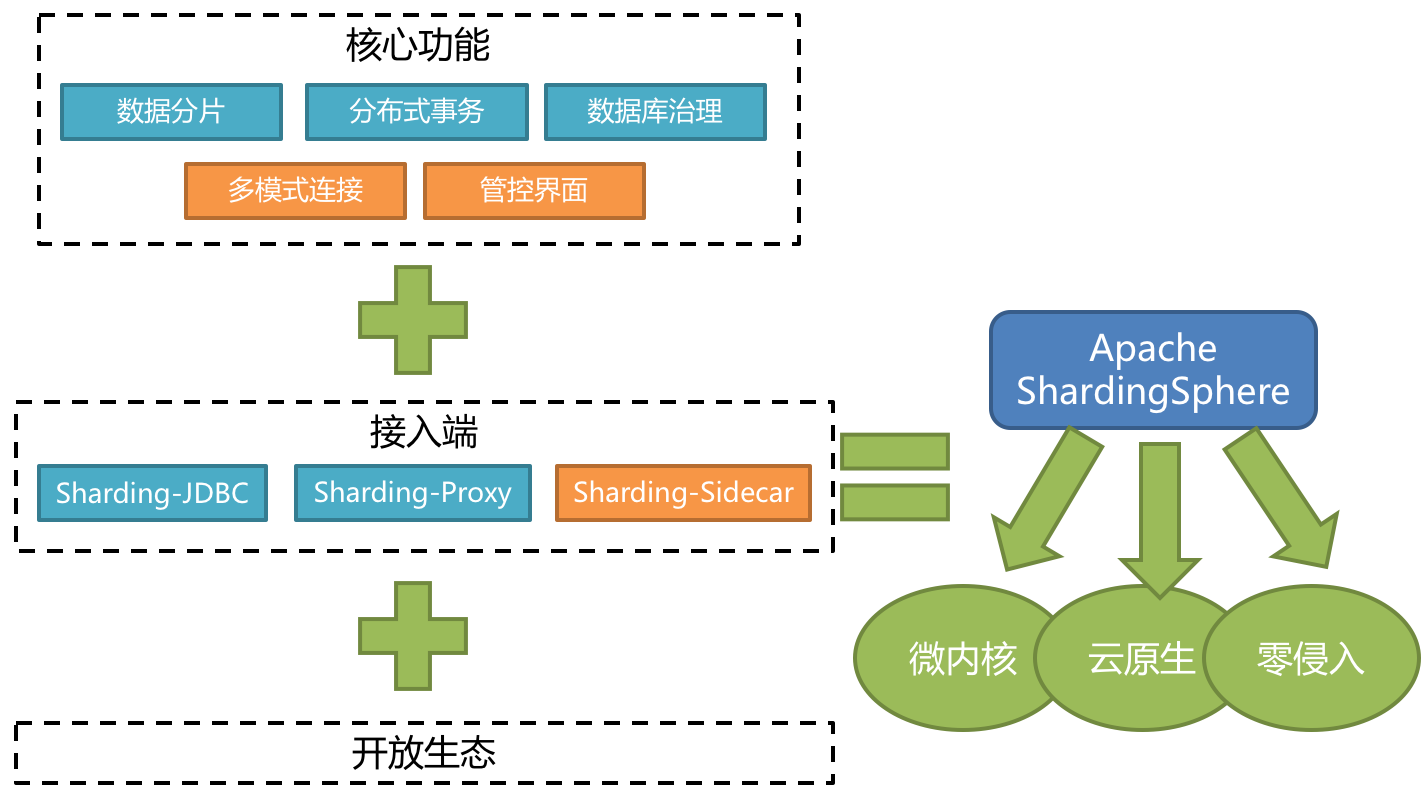
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
一、ShardingSphere4.1.1的spring boot配置
引入Maven依赖
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.1.1
Spring boot的yaml规则配置
spring:
shardingsphere:
enabled: true #是否开启sharding
props:
sql:
show: true #是否显示sql语句日志
#多数据源配置
datasource:
names: master,slave1,slave2 #自定义真实的数据源名字,多个数据源逗号隔开
master: #主数据源,master来自上方真实数据源取的名字
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/master
username: demo
password: 123456
#xxx:xx #数据库连接池的其它属性
salve1: #从数据源,salve1来自上方真实数据源取的名字
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/salve1
username: demo
password: 123456
salve2: #从数据源,salve2来自上方真实数据源取的名字
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/salve1
username: demo
password: 123456
#主从节点,读写分离配置 (在不使用数据分片功能,只需要读写分离功能情况下的配置)
masterslave:
name: ms #自定义一个虚拟数据源名字,用于自动路由下方主从数据源
master-data-source-name: master # 指定主数据源
slave-data-source-names: # 指定从数据源
- slave1
- slave2
load-balance-algorithm-type: round_robin #从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM
#数据分片 + 读写分离
sharding:
master-slave-rules: #在使用数据分片功能情况下,配置读写分离功能
ds0: #自定义一个虚拟数据源名字,用于自动路由下方主从数据源
masterDataSourceName: master # 指定主数据源
slaveDataSourceNames: # 指定从数据源
- slave1
- slave2
loadBalanceAlgorithmType: round_robin
binding-tables:
- t_user #指明了分库分表要处理的虚拟表名字
tables:
t_user: #自定义一个虚拟表名字,后续sql语句中就使用这个表名字,会自动路由到真实的表名
actualDataNodes: master$->{1..2}.t_user$->{1..10} #指定真实的数据源.表名,这里表示两个master数据源,10张表t_user
keyGenerator: #主键自动生成策略
column: uid #指定表字段名
type: SNOWFLAKE #指定雪花算法
props:
worker: #指定雪花算法的工作中心
id: 1
#分表策略, 可选项有 inline, standard, complex, hint, none
tableStrategy:
inline: #inline(行表达式分片策略)- 根据单一分片键进行精确分片
shardingColumn: uid #指定分片键(表字段)
algorithmExpression: t_user$->{uid%2+1} #指定分片算法,这里是取模算法
standard: #standard(标准分片策略) - 根据单一分片键进行精确或者范围分片
shardingColumn: uid
#指定精确分片算法的实现类, 必选项
preciseAlgorithmClassName: cn.demo.strategy.TablePreciseAlgorithm
#指定范围分片算法的实现类
rangeAlgorithmClassName: cn.demo.strategy.TableRangeAlgorithm
complex: #complex(复合分片策略) - 根据多个分片键进行精确或者范围分片
shardingColumn: uid
#指定复合分片算法实现类
algorithmClassName: cn.demo.strategy.TableComplexAlgorithm
hint: #hint策略 - 使用与sql无关的方式进行分片
#指定hint分片算法实现类
algorithmClassName: cn.demo.strategy.DbHintAlgorithm
none: #不使用分片策略
#分库策略, 可选项有 inline, standard, complex, hint, none
databaseStrategy:
inline: #配置跟上方表策略相同
standard:
hint:
none:
二、ShardingSphere的分片策略
- inline(行表达式分片策略) – 根据单一分片键进行精确分片
- standard(标准分片策略) – 根据单一分片键进行精确或者范围分片
- complex(复合分片策略) – 根据多个分片键进行精确或者范围分片
- hint策略 – 使用与sql无关的方式进行分片
1. inline(行表达式分片策略) – 根据单一分片键进行精确分片
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为user_0到user_7。
#inline 单分片键策略, sql不支持 >, {cid%2+1} #分片算法,取模
#分库策略配置
database-strategy:
inline:
sharding-column: cid #分片字段
algorithm-expression: db_$->{cid%2+1} #分片算法,取模2. standard(标准分片策略) – 根据单一分片键进行精确或者范围分片
对应StandardShardingStrategy,支持精确和范围分片,提供对SQL语句中的=,IN,BETWEEN AND、>、=、
精确分片算法接口: PreciseShardingAlgorithm, 必选的,用于处理=和IN的分片
范围分片算法接口: RangeShardingAlgorithm,用于处理BETWEEN AND, >, =,
#standard 单分片键策略, 支持精确和范围分片
#分表策略配置
table-strategy:
standard:
sharding-column: cid #分片字段
#指定精确分片算法的实现类, 必选项
precise-algorithm-class-name: cn.demo.strategy.TablePreciseAlgorithm
#指定范围分片算法的实现类
range-algorithm-class-name: cn.demo.strategy.TableRangeAlgorithm
#分库策略配置
database-strategy:
standard:
sharding-column: cid
precise-algorithm-class-name: cn.demo.strategy.DbPreciseAlgorithm
range-algorithm-class-name: cn.demo.strategy.DbRangeAlgorithm自定义类实现精确或范围分片算法
注意:集合参数Collection availableTargetNames 表示数据源或者实际表的名字集合,
如果是分表策略就是实际表的名字集合, 如果是分库策略就是数据源名字集合
- table分表策略
/**
* standard分片策略的表精确分片算法实现类
* 实现接口 PreciseShardingAlgorithm, 泛型类T是分片键的字段类型
*/
public class TablePreciseAlgorithm implements PreciseShardingAlgorithm {
/**
* 精确分片算法:用于处理=和IN的分片
* @param availableTargetNames - 数据源或者实际表的名字集合
* @param preciseShardingValue - 包含逻辑表名、分片列和分片列的值
* @return 返回分片后的实际表名
*/
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue preciseShardingValue) {
//获取分片列的值
Long value = preciseShardingValue.getValue();
//获得虚拟表名
String logicTableName = preciseShardingValue.getLogicTableName();
//实现course_$->{cid%2+1} 取模分片算法
long index = value % 2 + 1;
//拼接获得实际表名
String actualTableName = logicTableName + "_" + index;
//判断配置的实际表集合中是否有该实际表名
if(availableTargetNames.contains(actualTableName)) {
return actualTableName;
}
return null;
}
}/**
* standard分片策略的范围分片算法实现类
* 实现接口 PreciseShardingAlgorithm, 泛型类T是分片键的字段类型
*/
public class TableRangeAlgorithm implements RangeShardingAlgorithm {
/**
* 范围分片算法:用于处理BETWEEN AND, >, =, doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
//实现范围查询 cid between 200 and 300 中的上限和下限值
Range valueRange = shardingValue.getValueRange();
Long lower = valueRange.lowerEndpoint(); //下限值200
Long upper = valueRange.upperEndpoint(); //上限值200
//下面自行实现逻辑判断分片后的实际表名,这里就不具体实现了
return availableTargetNames;
}
}- DB分库策略
/**
* standard分片策略的表精确分片算法实现类
* 实现接口 PreciseShardingAlgorithm, 泛型类T是分片键的字段类型
*/
public class DbPreciseAlgorithm implements PreciseShardingAlgorithm {
/**
* 精确分片算法:用于处理=和IN的分片
* @param availableTargetNames - 数据源或者实际表的名字集合
* @param preciseShardingValue - 包含逻辑表名、分片列和分片列的值
* @return 返回数据源名字
*/
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue preciseShardingValue) {
//获取配置的所有数据源名字集合
System.out.println("===> names: "+availableTargetNames);
return null;
}
}3. complex(复合分片策略) – 根据多个分片键进行精确或者范围分片
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的逻辑,需要配合ComplexShardingStrategy使用。
复合分片算法接口: ComplexKeysShardingAlgorithm
#complex 多个分片键策略, 支持精确和范围分片
#分表策略配置
table-strategy:
complex:
sharding-column: cid, user_id #分片字段, 可以指定多个
algorithm-class-name: cn.demo.strategy.TableComplexAlgorithm
#分库策略配置
database-strategy:
complex:
sharding-column: cid, user_id #分片字段, 可以指定多个
algorithm-class-name: cn.demo.strategy.DbComplexAlgorithm/**
* complex 多个分片键的分片策略
* 实现接口 PreciseShardingAlgorithm, 泛型类T是分片键的字段类型
*/
public class TableComplexAlgorithm implements ComplexKeysShardingAlgorithm {
/**
* complex 多个分片键的分片算法
*
* @param availableTargetNames - 数据源或者实际表的名字集合
* @param shardingValue - 含逻辑表名、分片列和分片列的值
* @return 返回实际表名集合
*/
@Override
public Collection doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
Collection result = new ArrayList();
String logicTableName = shardingValue.getLogicTableName();
//shardingValue.getColumnNameAndShardingValuesMap
//获得分片列名和分片值的对应map
Map> mp1 = shardingValue.getColumnNameAndShardingValuesMap();
//shardingValue.getColumnNameAndRangeValuesMap
//获得分片列名和分片范围值的对应map
Map> mp2 = shardingValue.getColumnNameAndRangeValuesMap();
return availableTargetNames;
}
}对于两个分片键的场景,可以采用基因法
在电商场景中,使用订单 ID 和买家 ID 查询数据的问题。在这个场景中,我们选择使用订单 ID 作为分片键是一个没有异议的选择。那么此时,我们通过 APP 来查询自己的订单时,查询条件变为了分片键之外的买家 ID,默认情况下,查询语句中不带有分片键会导致全路由情况。面对这样的情况,应如何设计一个高效的分片策略?
大厂常常使用的方案是基因法,即将买家 ID 融入到订单 ID 中,作为订单 ID 后缀。这样,指定买家的所有订单就会与其订单在同一分片内了,如下图所示
4. hint策略 – 使用与sql无关的方式进行分片
对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略
hint分片算法接口: HintShardingAlgorithm
#hint 片键策略
#分表策略配置
table-strategy:
hint:
algorithm-class-name: cn.demo.strategy.TableHintAlgorithm
#分库策略配置
database-strategy:
hint:
algorithm-class-name: cn.demo.strategy.DbHintAlgorithmpublic class TableHintAlgorithm implements HintShardingAlgorithm {
/**
* Sharding.
*
* sharding value injected by hint, not in SQL.
*
* @param availableTargetNames available data sources or tables's names
* @param shardingValue sharding value,来自hintManager设置的值
* @return sharding result for data sources or tables's names
*/
@Override
public Collection doSharding(Collection availableTargetNames, HintShardingValue shardingValue) {
return null;
}
}ShardingSphere使用ThreadLocal管理分片键值进行Hint强制路由。可以通过编程的方式向HintManager中添加分片值,该分片值仅在当前线程内生效。 Hint方式主要使用场景:
1.分片字段不存在SQL中、数据库表结构中,而存在于外部业务逻辑。
2.强制在主库进行某些数据操作。
Hint分片算法需要用户实现HintShardingAlgorithm接口,ShardingSphere在进行Routing时,将会从HintManager中获取分片值进行路由操作。
获取HintManager
HintManager hintManager = HintManager.getInstance();添加分片键值
- 使用hintManager.addDatabaseShardingValue来添加数据源分片键值。
- 使用hintManager.addTableShardingValue来添加表分片键值。
分库不分表情况下,强制路由至某一个分库时,可使用hintManager.setDatabaseShardingValue方式添加分片。通过此方式添加分片键值后,将跳过SQL解析和改写阶段,从而提高整体执行效率。
清除分片键值
分片键值保存在ThreadLocal中,所以需要在操作结束时调用hintManager.close()来清除ThreadLocal中的内容。
代码示例
// Sharding database and table with using hintManager.
String sql = "SELECT * FROM t_order";
try (HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.addDatabaseShardingValue("t_order", 1);
hintManager.addTableShardingValue("t_order", 2);
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}
// Sharding database without sharding table and routing to only one database with using hintManger.
String sql = "SELECT * FROM t_order";
try (HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.setDatabaseShardingValue(3);
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}三、SpringBoot 整合 ShardingSphere4.1.1
1. POM文件引入shardingSphere相关依赖
mysql
mysql-connector-java
org.mybatis.spring.boot
mybatis-spring-boot-starter
com.alibaba
druid-spring-boot-starter
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.1.1
org.apache.shardingsphere
sharding-transaction-xa-core
4.1.1
2. 分表的建表语句
在course数据库下创建两张表course_1, course_2
-- course.course_1 definition
CREATE TABLE `course_1` (
`cid` bigint(20) NOT NULL COMMENT 'ID',
`cname` varchar(100) NOT NULL,
`user_id` varchar(64) NOT NULL,
`cstatus` tinyint(4) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- course.course_2 definition
CREATE TABLE `course_2` (
`cid` bigint(20) NOT NULL COMMENT 'ID',
`cname` varchar(100) NOT NULL,
`user_id` varchar(64) NOT NULL,
`cstatus` tinyint(4) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;3. yaml配置文件配置sharding分库分表的配置
-
分表yaml配置
#配置分库分表策略
#配置数据源
spring:
shardingsphere:
props:
sql:
show: true #显示sql语句日志
datasource:
names: m1 #指定一个虚拟数据库名称
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/course?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&rewriteBatchedStatements=true
username: test
password: 123456
#分表配置, 这里使用主键cid 作为分表字段
sharding:
tables:
course: #指定一个虚拟表名称
actual-data-nodes: m1.course_$->{1..2} #实际使用的表节点, 数据库.表名
key-generator: #主键自动生成策略
column: cid
type: SNOWFLAKE #使用雪花ID
props:
worker:
id: 1
table-strategy: #分表策略
inline: #inline策略
sharding-column: cid #分表字段
algorithm-expression: course_$->{cid%2+1} #分表算法,求模取余算法-
分库yaml配置
#配置分库分表策略
#配置多个数据源
spring:
shardingsphere:
datasource:
names: m1,m2 #指定多个虚拟数据库名称
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/course1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&rewriteBatchedStatements=true
username: test
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/course2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&rewriteBatchedStatements=true
username: test
password: 123456
#分库分表配置
sharding:
tables:
course: #指定一个虚拟表名称
actual-data-nodes: m$->{1..2}.course_$->{1..2} #m1.course 数据库.表名
key-generator: #主键自动生成策略
column: cid
type: SNOWFLAKE #使用雪花ID
props:
worker:
id: 1
table-strategy: #分表策略
inline: #inline策略
sharding-column: cid #分表字段
algorithm-expression: course_$->{cid%2+1} #分表算法,求模取余算法
database-strategy: #分库策略
inline: #inline策略
sharding-column: user_id #分库字段
algorithm-expression: m$->{user_id % 2 + 1} #分库算法,求模取余算法
4. 启动类上移除Druid数据源的自动配置
@SpringBootApplication(exclude = DruidDataSourceAutoConfigure.class )
public class ShardingsphereApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingsphereApplication.class, args);
}
}5. 插入测试数据
正常使用mapper接口进行数据插入即可
@Service
public class CourseService {
@Autowired
private CourseMapper courseMapper;
@PostConstruct
private void init() {
this.insert();
}
public void insert() {
for (int i=1;i插入结果:
course_1表
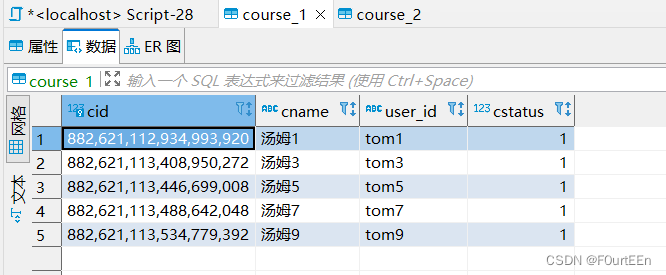
course_2表

四、ShardingSphere实现分布式事务控制
引入Maven依赖
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
${shardingsphere.version}
org.apache.shardingsphere
sharding-transaction-xa-core
${shardingsphere.version}
org.apache.shardingsphere
sharding-transaction-base-seata-at
${sharding-sphere.version}
ShardingSphere要实现事务控制需要手动声明一个PlatformTransactionManager事务管理器Bean,否则事务不会生效。还要将ShardingDataSource 数据源注入到事务管理器中。
/**
* 事务管理器中注入Sharding数据源 ShardingDataSource
*/
@Bean
@Primary
public PlatformTransactionManager platformTransactionManager(ShardingDataSource shardingDataSource) {
PlatformTransactionManager manager = new DataSourceTransactionManager(shardingDataSource);
return manager;
}后续使用注解@EnableTransactionManagement开启事务,注解@Transactional标注在需要事务控制的方法上。
@Transactional
@ShardingTransactionType(TransactionType.XA) // 支持TransactionType.LOCAL, TransactionType.XA, TransactionType.BASE
public void insert() {
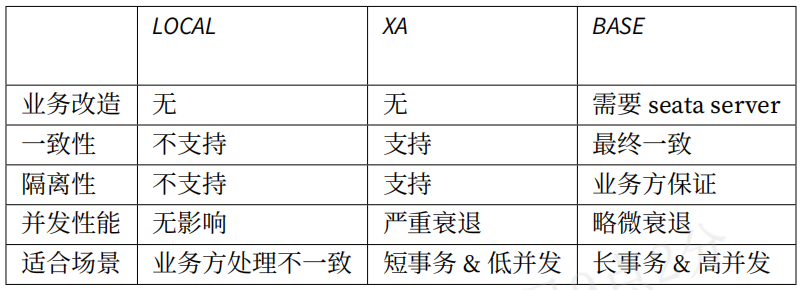
jdbcTemplate.execute("INSERT INTO t_order (user_id, status) VALUES (?, ?)", (PreparedStatementCallbackSharding支持事务类型TransactionType.LOCAL, TransactionType.XA, TransactionType.BASE
本文参考shardingsphere官网网站文档
使用手册 :: ShardingSphere
