

作者:火山引擎云原生计算研发工程师|雷丽媛
上文我们了解了在字节跳动内部业务快速增长的推动下,经典消息队列 Kafka 的劣势开始逐渐暴露,在弹性、规模、成本及运维方面都无法满足业务需求。因此字节消息队列团队研发了计算存储分离的云原生消息引擎 BMQ,在极速扩缩容及吞吐上都有非常好的表现。本文将继续从整体技术架构开始,介绍字节自研的云原生消息引擎的分层架构在数据存储模型、运维等角度的优势及挑战。
回顾:一文了解字节跳动消息队列演进之路
云原生消息引擎 BMQ 架构
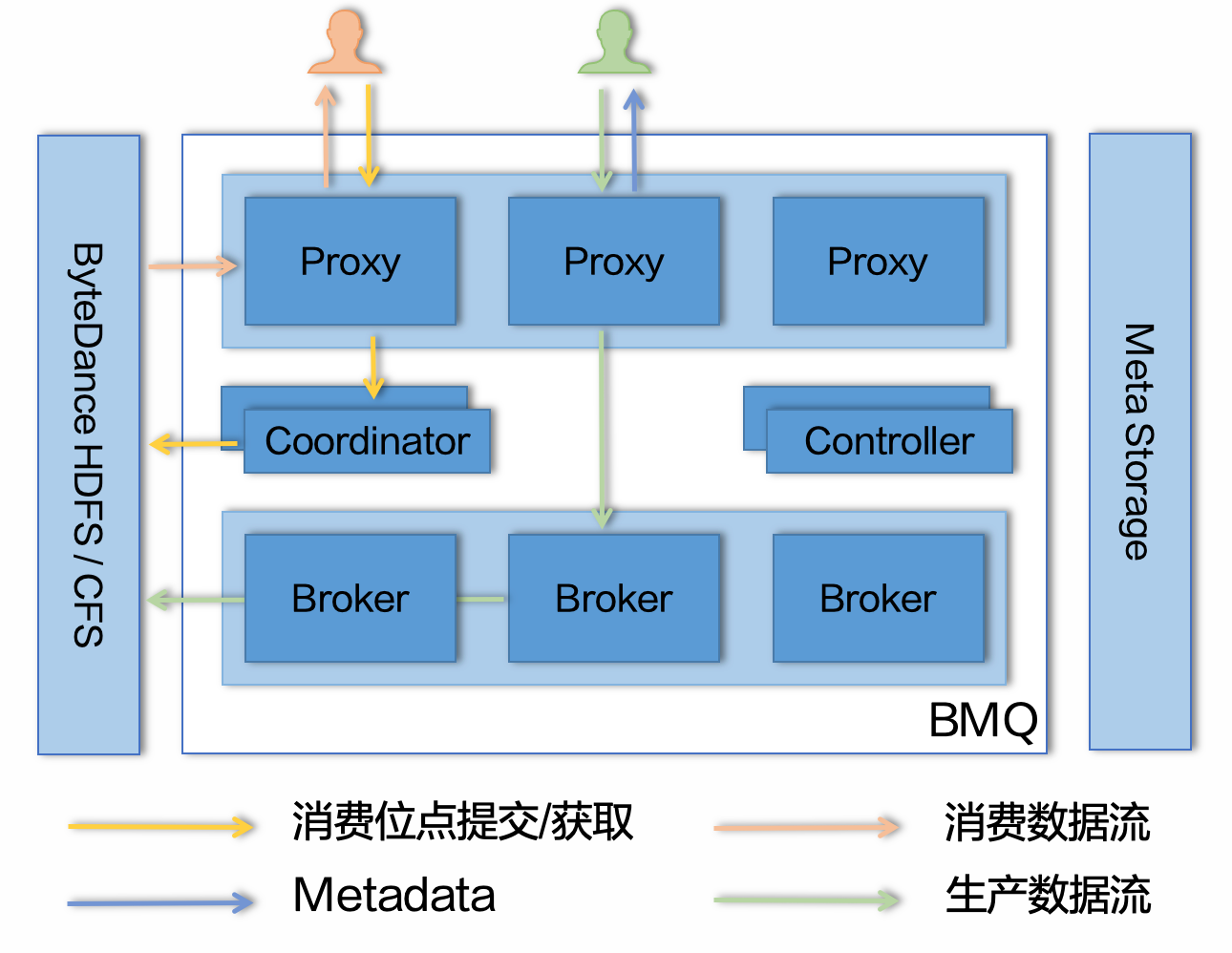
从整体来看,BMQ 与 Kafka 架构最大的不同在于 BMQ 是存算分离的架构,相较于 Kafka 将数据存储在本地磁盘,BMQ 将数据存储在了分布式的存储系统。在 BMQ 内部,主要有四个模块:Proxy,Broker,Coordinator 和 Controller。我们依次来看一下这些模块的主要工作:
-
Proxy 负责接收所有用户的请求,对于生产请求,Proxy 会将其转发给对应的 Broker;对于消费者相关的请求,例如 commit offset,join group 等,Proxy 会将其转发给对应的 Coordinator;对于读请求 Proxy 会直接处理,并将结果返回给客户端。
-
BMQ 的 Broker 与 Kafka 的 Broker 略有不同,它主要负责写入请求的处理,其余请求交给了 Proxy 和 Coordinator 处理。
-
Coordinator 与 Kafka 版本最大的差别在于我们将其从 Broker 中独立,作为单独的进程提供服务。这样的好处是读写流量与消费者协调的资源可以完全隔离,不会互相影响。另外 Coordinator 可以独立扩缩容,以应对不同集群的情况。
-
Controller 承担组件心跳管理、负载均衡、故障检测及控制命令接入的工作。因为 BMQ 将数据放在分布式存储系统上,因此无需管理数据副本,相较于 Kafka 省去了 ISR 相关的管理。Controller 可以更加专注地关注集群整体流量均衡及故障检测。
在 BMQ 中用户所有请求都会由 Proxy 接入,因此 BMQ 的 Metadata 中的 ‘Broker’ 信息实际上填写的是 BMQ 中 Proxy 的信息,客户端根据 Metadata 请求将生产和消费等请求发送到对应的 Proxy,再由 Proxy 处理或转发。这样的架构有助于 BMQ 做更多的容错工作。例如在 Broker 重启时,Proxy 可以感知到相关错误并进行退避重试,避免将异常直接暴露给客户端;此外我们可以监控 Proxy 在访问其他组件时产生的错误,进行一些自动的故障诊断,并将故障节点自动隔离,避免对用户产生影响。
分层架构的优势
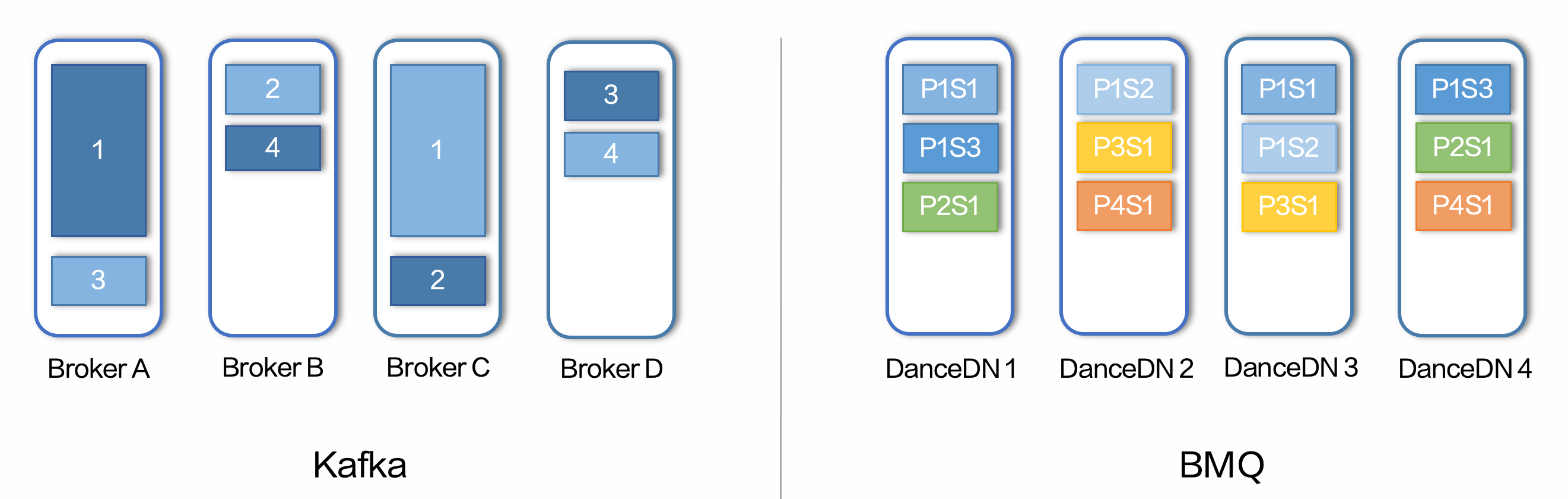
分层架构的优势是显而易见的,BMQ 作为计算层无状态,可以实现秒级的扩缩容或故障机替换。在故障场景下,例如交换机故障或机房故障,可以秒级将流量调度到健康节点恢复服务。
数据存储模型
在分层之后数据存储模型上的优势,主要体现在 BMQ 中,一个 Partition 的数据会和 Kafka 一样被切分为若干个 Segment,Kafka 中的这些 Segment 都会被存储在同一块磁盘上,而在 BMQ 中,因为数据存储在分布式存储中,每一个 Segment 也都被存储在存储池中不同的磁盘上。从上图中可以明显看出,BMQ 的存储模型很好的解决了热点问题。即使 Partition 间数据大小或访问吞吐差别很大,被切割成 Segment 后都能均匀地分散在存储池中。
❯ 接下来我们通过一个例子进一步感受池化存储的优势。
在 Kafka 的使用中,我们经常会有回溯数据的需求,以上图中的数据分布为例,例如业务有需求回溯 Partition 1 全部的数据,高吞吐的 IO 会影响磁盘的性能,在 Kafka 存储模型中与 Partition 1 Leader 同在一块磁盘的 Partition 3 Follower 就会受到影响,使得 Partition 3 处于 Under Replica 的状态。这个状态会持续到用户将 Partition 全部数据回溯完成。
而在 BMQ 的存储模型中,Partition 1 的数据分散在不同磁盘上,热点会随着用户的回溯进程转移,不会持续影响同一块磁盘。且对于回溯访问的磁盘,仅有已经存储在该磁盘的其他 Segment 刚好被用户消费时,或有新的 Segment 要写入该磁盘的时候会受影响。此外我们也可以通过一些策略避免写入有热点访问的磁盘来降低热点访问对新写入的影响。总结来看,Kafka 存储模型下,热点访问对同磁盘其他访问的影响大、持续长、且优化空间不大;而 BMQ 的池化存储模型中,热点影响范围小、持续时间短,并且可以通过一些策略优化进一步降低影响。
运维及故障影响
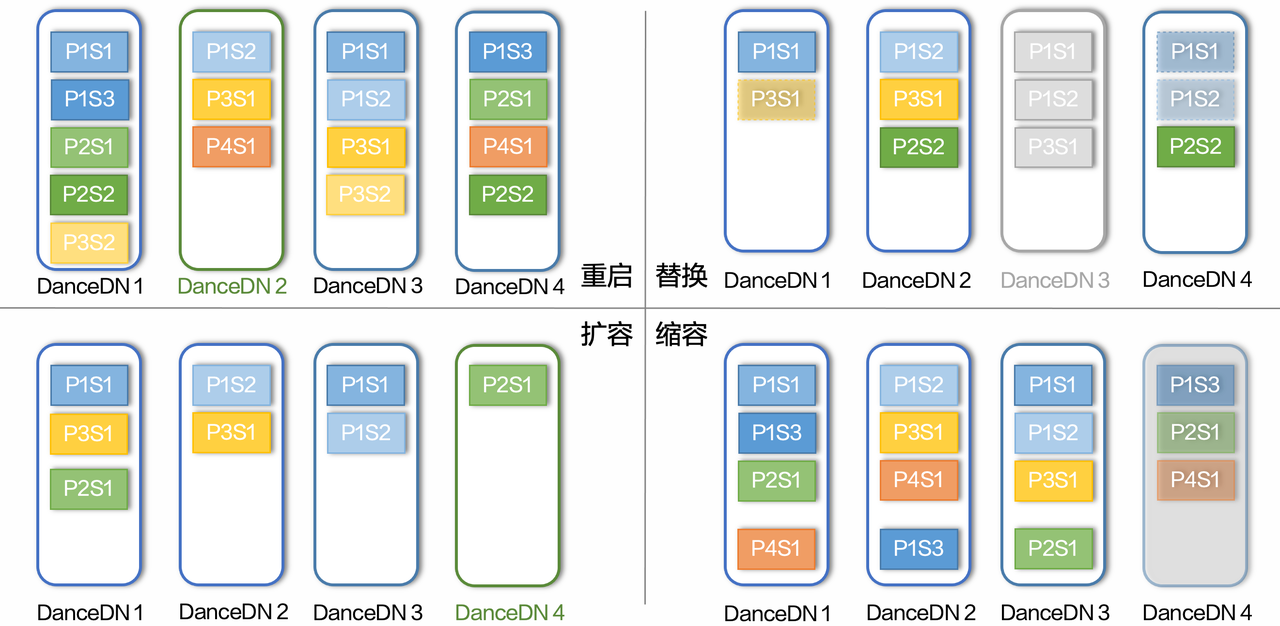
从运维角度来看,BMQ 的存储模型也有非常大的优势。无论重启、替换、扩容还是缩容,Kafka 都需要数据拷贝。以扩容为例,新扩容的 Broker 需要作为 Partition 的 follower,将数据从 leader 所在 Broker 拷贝至本地,全部拷贝完成后新 Broker 才可以晋升为 leader 提供服务。而矛盾的地方在于,当业务流量上涨急需扩容时,Broker 已经没有多余的带宽来支持拷贝数据了。而 BMQ 所依赖的分布式存储系统则没有这个问题,同样以扩容为例,新扩充进来的存储节点可以立即提供读写服务,无需做额外的数据拷贝,不会对原有存储造成额外压力。而在替换和缩容场景,分布式存储依然需要一些数据拷贝来补齐副本,但对业务影响会小很多。因为数据存储是分散的,因此拷贝的 IO 也会分散在多台存储上。
从故障影响角度分析,以两副本的配置为例,在 Kafka 场景下,任意两台 Broker 宕机都会造成某个 Partition 无法读写,且数据全部丢失。在 BMQ 的存储模型下,任意两台存储节点的异常都不会影响新写入的数据,因为只要存活的存储节点可以支持写入流量,新写入的数据就可以选择剩余健康的存储节点写入。对于已经存入的数据,两台存储节点宕机会导致同时存在这两台机器上的 Segment 无法读取,若这个 Segment 是最近写入的尚未被消费的,则会影响这部分数据的消费,但若这个 Segment 刚好是一个历史数据,没有消费者需要,那就不会对业务产生实际影响。
分层架构的挑战
上面我们讨论了分层架构带来的优势,下面要来分析下挑战以及 BMQ 的解决方案。分层存储之后 BMQ 访问数据的代价增加了,访问存储在分布式系统上的数据延时会比直接读取本地磁盘稍高,并且我们也需要考虑对分布式存储系统元信息及存储节点的压力情况。下面我们来分别看一下 BMQ 在生产和消费这两条链路上是如何克服这些困难的。
生产
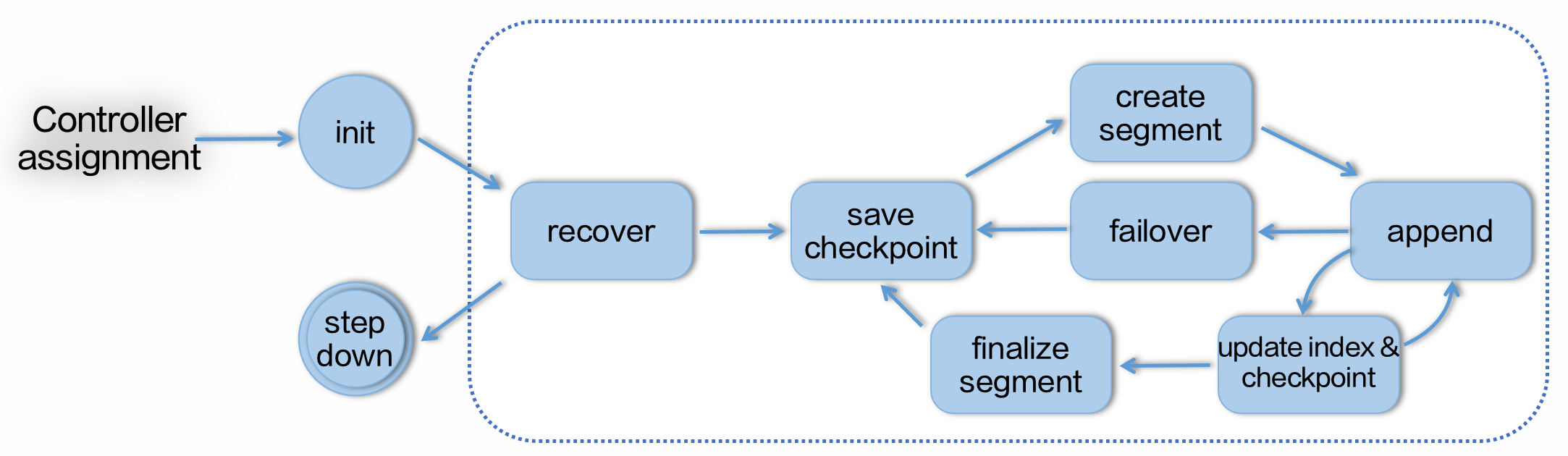
首先介绍一下 BMQ 数据写入的流程。上文介绍过 Broker 是主要负责数据写入的节点,由 Controller 负责将 Partition 分配到各个 Broker 上。因为 Kafka 协议中 Partition 内部的数据是有序的,因此每个 Partition 只会在唯一一个 Broker 上调度。Controller 调度的时候也会综合考虑 Broker 的负载及 Partition 的流量等因素,最终做到 Broker 之间的负载均衡。
如上图所示,当一个 Partition 被调度到 Broker 上之后,便开始了它的生命周期。首先 Partition 会进行 Recover,即从上一个 Checkpoint 恢复数据,并将最终结果保存,这样做是避免因意外宕机导致用户已经写入成功的数据丢失。之后 Partition 便会创建一个新的 Segment 开始写入数据,期间会写入索引等信息。当文件长度到达配置长度,或者文件写入持续到达配置时间后会被关闭,存储相关元信息,并开启一个新的 Segment 写入。依次循环,直到 Controller 将 Partition 从这个 Broker 调度走,或发生异常 Partition 退出。
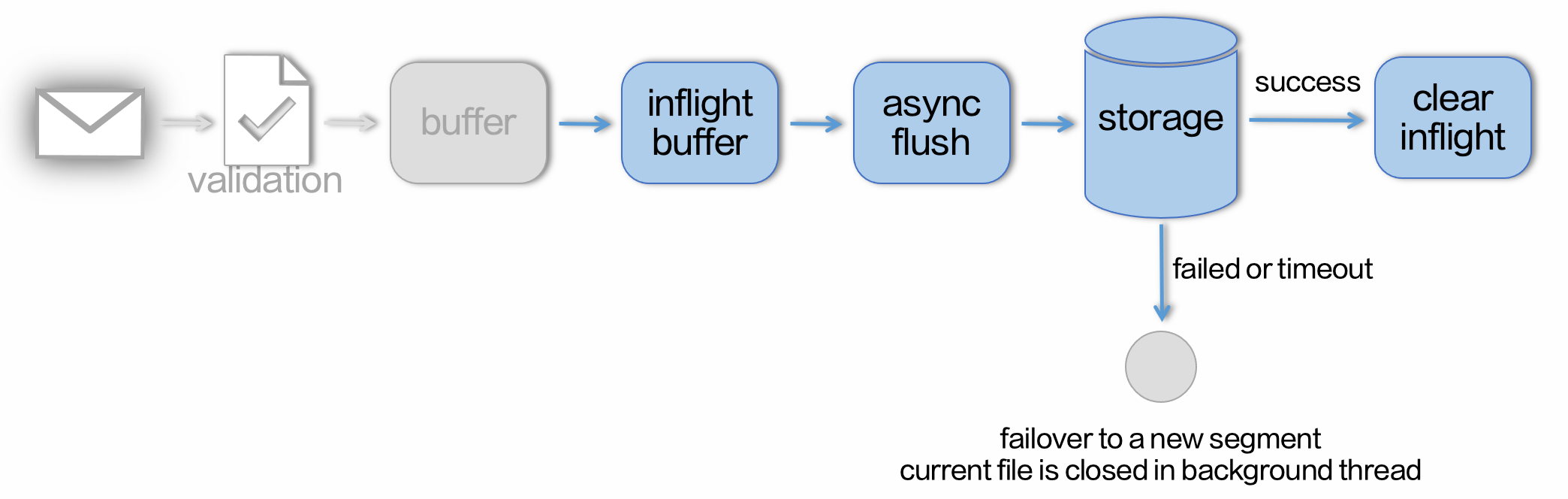
我们可以看到在状态集中有一个 Failover 节点,这个节点是 BMQ 降低分布式存储延时毛刺的关键。每一次写入 BMQ 会先将数据放入一个 Inflight Buffer 中,之后通过异步调用分布式存储的 Flush 接口持久化数据。若 Flush 在预期时间内返回成功,那么 Inflight Buffer 数据中的数据会被清除,同时返回给用户写入成功的回应。但若因为网络或者慢节点问题导致写入超时,那么 Broker 会直接创建一个新的 Segment 文件,将 Inflight Buffer 中的数据直接写入新的文件,并在后台异步将之前的 Segment 文件关闭。对于异步关闭的这个文件,元信息只会包含成功返回的数据长度,最后超时的部分则不会被记录,这样即使超时数据最终确实写入了分布式存储,也不会被用户读取造成数据重复,这一整个过程就是我们说的 Failover。
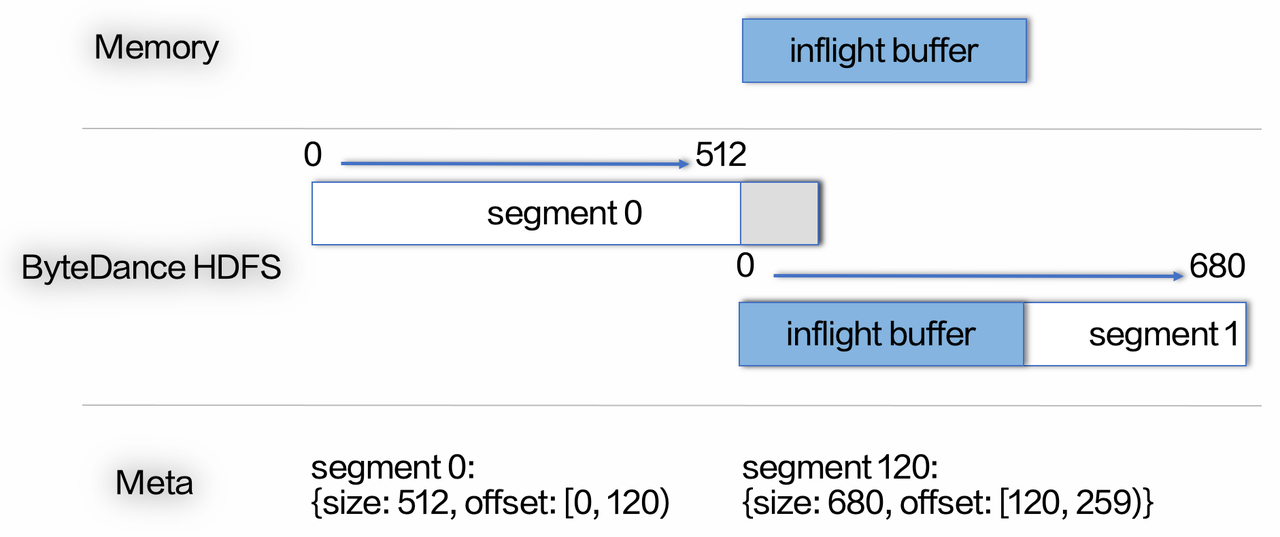
为什么通过切一个文件就能解决这个问题呢?这也与存储模型有关。Kafka 因为一个 Partition 数据均被存储在一块磁盘上,那么若是因为磁盘异常引起的延时抖动,无论如何切换文件都是不能解决的。但是在 BMQ 中,每个 Segment 都是一个文件,而每个文件的多个副本都会随机地分布在整个存储池中。那么若存储池中有少数慢节点,随机切换一个节点大概率可以绕过故障的节点。因此,在慢节点问题及偶发的磁盘热点问题上,BMQ 可以更加灵活地规避,降低这些问题对用户的影响。
当然,BMQ 的分层架构对于底层的分布式存储系统也提出了较高的要求。火山引擎上分布式存储系统由 C++ 实现,是一个高性能的分布式文件系统。能够提供 5w QPS 写入及 15w QPS 读取的元信息访问能力;写入访问延时 p99 约在 10 毫秒左右,读取延时 p99 为亚毫秒级别;并且单集群可以承载 50 亿文件。同时在数据写入方面对写入延时也做了很多优化,包括慢节点的检测和规避、利用 NVMe 加速的多介质存储功能等。
消费
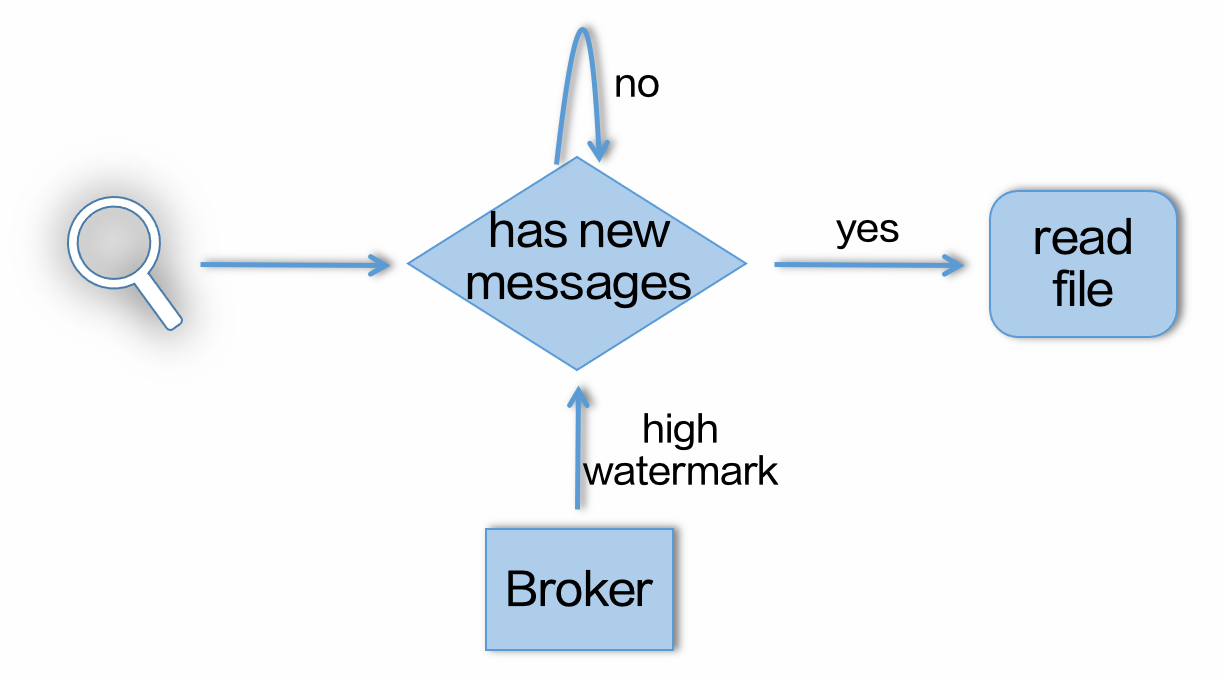
当一个消费请求到达 Kafka Broker,Broker 会查看当前是否有足够多的已写入数据返回给消费者,如果条件满足则会读取数据并返回。这个流程非常简单清晰,但这个流程不能直接照搬到 BMQ,因为 BMQ 底层是分布式存储系统,如果对于每个请求都直接从存储层读取数据,那么对于分布式存储系统的元信息和数据节点都是极大地压力,并且延时也会变得非常高。因此直接处理消费请求的 BMQ Proxy 针对读流程设计了多个缓存机制。
第一个缓存系统非常直观,我们称之为 Message Cache。顾名思义,这个缓存存储的是消息数据。Message Cache 会将每个 Partition 末尾的一部分数据从远端读取回来,并缓存在内存中,以供消费者读取。若这个 Partition 有多个消费组,那么理想情况下,他们只会产生一次分布式文件系统的实际数据读取,其余请求均会从 Proxy 内存中直接获取数据。不同于 Kafka 依赖于 Page Cache,BMQ 的 Message Cache 拥有丰富的淘汰策略以应对不同的生产消费场景,使得缓存命中率更高。
当然,不是所有的请求都能够完美的命中 Message Cache,一些消费者会因为消费资源不足或业务需求消费一些较老的数据,而这部分数据无法被 Message Cache 覆盖。如果在这种请求发生时 Proxy 直接读取分布式存储系统则会对其造成一次元数据的访问,当请求变多时分布式存储系统的元数据节点将不堪重负。因此 Proxy 设计来 File Cache 来应对这种情况。Proxy 会缓存某个 Segment 的文件句柄,即这个 Segment 所对应文件的文件句柄。因为 Kafka 的消费场景下,用户大多数情况都是顺序消费,因此一个消费请求这一次所访问的文件很大概率是上一次请求访问过的文件。线上实践效果来看,File Cache 可以帮助我们减少 70% 对后端存储的元信息访问请求。
在 BMQ 拥有优越的消费性能上也需要强大的分布式存储系统的加持。除了上一节提到的高性能的元数据节点,也需要存储系统支持读取的慢节点检测,即如果当前读取的节点延时较高,Client 端会自动切换另外一个节点读取。再加上 NVMe 分层存储的加速,BMQ 可以以较低延时达到非常理想的消费吞吐。
总结与展望
总体来看,分层架构给 BMQ 带来了极大的性能收益及可运维性的提升,同时也给我们带了来很多的挑战。BMQ 也通过不停的探索和优化,成功克服了这些困难,很好的支撑了业务的发展。在线上实践中,目前我们承接了 TB/s 级别的入流及数十 TB/s 级别的的峰值吞吐,其中最大 Topic 峰值达到数百 GB/s 入流和 TB/s 级别的出流吞吐。
当然,我们也在思考如何在各种场景下持续优化云原生消息引擎能力为用户带来更加极致的使用体验。对于一些特定的场景,探索将 Proxy 和 Broker 融合,在降低部署成本的同时提供更加极致的读写延时体验。未来,我们也将持续优化自动检测能力,使它更智能、更准确判断故障的同时更快地隔离异常节点,缩短影响时间,持续为 BMQ 的稳定性保驾护航。此外我们也在探索更加极致的弹性能力,在保障租户吞吐能力的同时,可以根据流量潮汐自动扩缩容实例,实现极致地降本增效。后续,我们还会介绍更多技术能力,敬请期待。
火山引擎云原生消息引擎 BMQ 基于云原生全托管服务,支持灵活动态的扩缩容和流批一体化计算,能够有效地处理大数据量级的实时流数据,帮助用户构建数据处理的“中枢神经系统”,广泛应用于日志收集、数据聚合、离线数据分析等业务场景。
