


原文:.NET8动态PGO简析
作者:江湖评谈,公众号同名:江湖评谈(Jianghupt),欢迎关注。
前言
.NET8在性能方面的惊人飞跃,远超过去所取得成就,这在很大程度上归功于动态PGO。【 I dare say the improvements in .NET 8 in the JIT are an incredible leap beyond what was achieved in the past, in large part due to dynamic PGO…官方原话】
详细
在早期的.NET方法只编译一次,在第一次调用该方法的时候,JIT启动以生成该方法的代码。后续的调用以及当前的调用都会使用JIT生成的代码来运行程序,这是一个简单的无冲突的时代,但是也是一个原始的时代。
简单和原始在于,方法只编译一次,再无其它可能性。无冲突在于,尤其是.NET开源时代,分层,动态PGO,OSR等等都会破坏原有的代码逻辑,造成一定的复杂度,而早期的.NET不存在这种状况。
优化是编译器里面最耗时的操作,编译器可以花费超长的时间来优化一段代码或者一个指令集。但是程序使用者,或者软件使用者,或者软件开发者没有超长的时间去等待编译器慢慢的完成一个方法的编译。这是很致命的。
在编译时间和代码质量上需要权衡利益得失。好的代码质量,需要更长的时间去编译,差的代码质量,则编译更快。这取决于JIT本身是如何工作的。大量的事实证明,在程序中大部分方法都只是调用一次或者几次,耗费很多的时间去优化这些方法。优化的时间反而超过了这些方法本身运行的时间,这完全是得不偿失的。
为了解决这种情况,.NET Core3.0中引入了新的JIT功能,称之为分层编译。通过分层一个方法可能会被编译多次,在第一次编译的时候被编译为0层(tier0),在0层当中JIT优先考虑的是代码编译的速度,而不是质量。在0层的编译特点是,最小优化(min opts,但是依然会保持一些优化),之所以这样,是因为它需要更快速的编译而不是更好质量的代码。
0层之后,会有1层(tier1)。这一层是基于0层的代码运行情况而来,比如JIT收集到0层的某个方法,运行的时间超过了60ms,运行的次数超过了2次(.NET8 R2R函数进入分层编译队列的阈值,比如Console.ReadLine方法),那么JIT就会把0层的这个方法放入到分层编译队列,进行编译之后该方法就会进一步优化形成了1层(tier1),此后调用该方法和当前调用该方法都会调用1层的代码,而弃用了0层的代码。
神来之笔
这里需要注意了,只有极少数的符合阈值的方法才能够进入1层。这样其实是0层和1层共生运行一个程序的过程,既保证了代码的质量,又保证了程序运行的速度,这是.NET8的一个神奇点。但是它的好处远不止于此。
神奇点1,代码从0层被优化到1层,JIT在0层的时候就会收集到代码的信息,并且在编译到1层的时候,会进行相对应的优化。如果JIT直接从一开始把代码编译到1层,那么可能无法拥有这样的优化。举个例子,比如0层有个方法,它里面有个静态只读字段,0层编译的时候它一定被初始化过了。JIT就可以根据它收集到的初始化的内容,在生成1层代码的时候进行相对应的优化。
神奇点2,有一种情况,一个方法可能只运行了寥寥几次或者只有一次。但是它里面有for循环这种代码,一直不停的运行。如果没有分层编译,它直接进入了Tier1,这样很粗暴的方式明显不行。为了解决这个问题,.NET中引入了OSR(On-Stack Replacement),当一个循环计数达到一定的阈值,JIT将编译该方法的新优化版本,此后从最小代码优化版本调到新优化版本中继续执行。非常巧妙的一个方式。
神奇点3,基于配置文件的静态优化(PGO)已经存在了几十年。适用于多种环境和语言,比如C/C++,Python,Java等等。这种原理主要是,在一些代码关键地方收集信息,下次运行根据这些信息重新构建应用程序。因为做到这些需要一些编译器或者其它一些配置,称之为静态PGO。而通过分层,Tier0优化到Tier1的基础上,所有的都是JIT自行收集,自行判断,自行优化,无须任何额外的开发工作,或者基础设施的配置,它就是动态PGO。
神奇点4,把R2R纳入到分层编译。R2R是一个预编译镜像,它里面存储的Native Header是完全的二进制运行代码,它跟AOT的不同在于它运行了一定的次数之后,会被JIT进行重新优化编译。如果不把它纳入到分层编译,这对动态PGO的性能是一个很大的阻碍。
编译分支和例子
一般的来说,即时编译分为两个分支。即源码编译和R2R(它大量的应用在System.Private.CoreLib.dll里面)预编译(AOT不属于即时编译,这里需要注意)。
源码编译即所谓未PreJIT编译,0层一般都是未优化(not optimized),未检查(not instrumented),在0层进行了检查但是未优化,此后在1层生成优化性代码。R2R即所谓PreJIT编译,因为R2R可能已经被优化过了。所以0层它是已优化,未检查,会在0层进行检查。到了1层已优化已检查,然后会再次生成一个优化性的代码,也称之为1层(但其实已经是2层 了)。参考如下图:
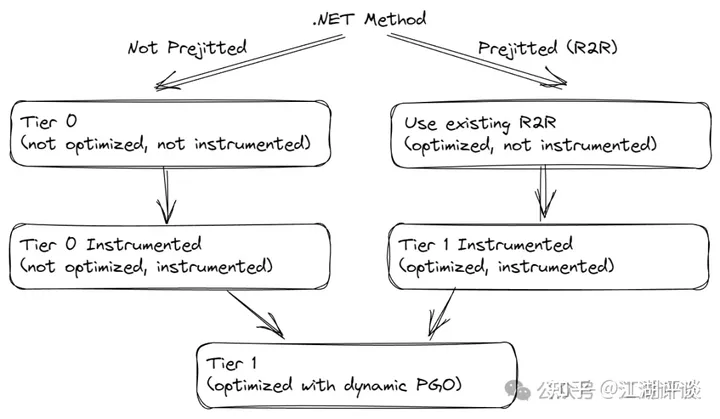
下面看下Tier0优化的一个例子,上面说到Tier0是确保编译速度,而忽略代码质量。但是不代表Tier0不进行代码优化。下面就是0层代码优化的例子。
// dotnet run -c Release -f net8.0
MaybePrint(42.0);
static void MaybePrint(T value)
{
if (value is int)
Console.WriteLine(value);
}0层JIT可以进行一定常量折叠(在编译的时候评估常量而不是在运行的时候),这可以让0层生成更少的代码。一般的来说,0层JIT大部分时间都是与虚拟机交互。如果能够减少一些永远不会使用的分支,可以大幅度提高编译的时间,也能获得更好的代码质量。将DOTNET_JitDisasm设置为MaybePrint,运行
dotnet run -c Release -f net7.00层代码如下:
Assembly listing for method Program:$>g__MaybePrint|0_0[double](double)
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-0 compilation
; MinOpts code
; rbp based frame
; partially interruptible
G_M000_IG01: ;; offset=0000H
55 push rbp
4883EC30 sub rsp, 48
C5F877 vzeroupper
488D6C2430 lea rbp, [rsp+30H]
33C0 xor eax, eax
488945F8 mov qword ptr [rbp-08H], rax
C5FB114510 vmovsd qword ptr [rbp+10H], xmm0
G_M000_IG02: ;; offset=0018H
33C9 xor ecx, ecx
85C9 test ecx, ecx
742D je SHORT G_M000_IG03
48B9B877CB99F97F0000 mov rcx, 0x7FF999CB77B8
E813C9AE5F call CORINFO_HELP_NEWSFAST
488945F8 mov gword ptr [rbp-08H], rax
488B4DF8 mov rcx, gword ptr [rbp-08H]
C5FB104510 vmovsd xmm0, qword ptr [rbp+10H]
C5FB114108 vmovsd qword ptr [rcx+08H], xmm0
488B4DF8 mov rcx, gword ptr [rbp-08H]
FF15BFF72000 call [System.Console:WriteLine(System.Object)]
G_M000_IG03: ;; offset=0049H
90 nop
G_M000_IG04: ;; offset=004AH
4883C430 add rsp, 48
5D pop rbp
C3 ret
; Total bytes of code 80System.Console:WriteLine里面的代码都是可以进行优化的,但是.NET7里面0层它解析出了MaybePrint,并未意识到其根本不会执行。现在在.NET8里面JIT意识到分支永远不会执行,所以生成如下:
; Assembly listing for method Program:$>g__MaybePrint|0_0[double](double) (Tier0)
; Emitting BLENDED_CODE for X64 with AVX - Windows
; Tier0 code
; rbp based frame
; partially interruptible
G_M000_IG01: ;; offset=0x0000
push rbp
mov rbp, rsp
vmovsd qword ptr [rbp+0x10], xmm0
G_M000_IG02: ;; offset=0x0009
G_M000_IG03: ;; offset=0x0009
pop rbp
ret
; Total bytes of code 11

