

目录
1、用 panic! 处理不可恢复的错误
对应 panic 时的栈展开或终止
1.1 使用 panic! 的 backtrace
2、用 Result 处理可恢复的错误
2.1 匹配不同的错误
2.2 失败时 panic 的简写:unwrap 和 expect
2.3 传播错误
错误是软件中不可否认的事实,所以 Rust 有一些处理出错情况的特性。在许多情况下,Rust 要求你承认错误的可能性,并在你的代码编译前采取一些行动。这一要求使你的程序更加健壮,因为它可以确保你在将代码部署到生产环境之前就能发现错误并进行适当的处理。
Rust 将错误分为两大类:可恢复的(recoverable)和 不可恢复的(unrecoverable)错误。对于一个可恢复的错误,比如文件未找到的错误,我们很可能只想向用户报告问题并重试操作。不可恢复的错误总是 bug 出现的征兆,比如试图访问一个超过数组末端的位置,因此我们要立即停止程序。
大多数语言并不区分这两种错误,并采用类似异常这样方式统一处理它们。Rust 没有异常。相反,它有 Result 类型,用于处理可恢复的错误,还有 panic! 宏,在程序遇到不可恢复的错误时停止执行。本章首先介绍 panic! 调用,接着会讲到如何返回 Result。此外,我们将探讨在决定是尝试从错误中恢复还是停止执行时的注意事项。
1、用 panic! 处理不可恢复的错误
突然有一天,代码出问题了,而你对此束手无策。对于这种情况,Rust 有 panic!宏。在实践中有两种方法造成 panic:执行会造成代码 panic 的操作(比如访问超过数组结尾的内容)或者显式调用 panic! 宏。这两种情况都会使程序 panic。通常情况下这些 panic 会打印出一个错误信息,展开并清理栈数据,然后退出。通过一个环境变量,你也可以让 Rust 在 panic 发生时打印调用堆栈(call stack)以便于定位 panic 的原因。
对应 panic 时的栈展开或终止
当出现 panic 时,程序默认会开始 展开(unwinding),这意味着 Rust 会回溯栈并清理它遇到的每一个函数的数据,不过这个回溯并清理的过程有很多工作。另一种选择是直接 终止(abort),这会不清理数据就退出程序。
那么程序所使用的内存需要由操作系统来清理。如果你需要项目的最终二进制文件越小越好,panic 时通过在 Cargo.toml 的
[profile]部分增加panic = 'abort',可以由展开切换为终止。例如,如果你想要在 release 模式中 panic 时直接终止:
[profile.release] panic = 'abort'
我们可以再程序中主动抛出一个错误,如下图所示:
fn main() {
panic!("error error error ...")
}运行一下程序,会打印如下信息:

通过上图可以知道:
第一行显示的是程序代码发生错误的位置,main.rs 的第二行第五列开始的。
第二行显示的是panic!里面,我们自定义的错误内容。
第三行告诉我们可以使用 panic! 被调用的函数的 backtrace 来寻找代码中出问题的地方。
1.1 使用 panic! 的 backtrace
让我们来看看另一个因为我们代码中的 bug 引起的别的库中 panic! 的例子,而不是直接的宏调用。示例如下所示:
fn main() {
let arr = [10, 20, 30, 40, 50];
arr[100];
}
这里尝试访问 vector 的第一百个元素(这里的索引是 99 因为索引从 0 开始),不过它只有三个元素。这种情况下 Rust 会 panic。[] 应当返回一个元素,不过如果传递了一个无效索引,就没有可供 Rust 返回的正确的元素。
C 语言中,尝试读取数据结构之后的值是未定义行为(undefined behavior)。你会得到任何对应数据结构中这个元素的内存位置的值,甚至是这些内存并不属于这个数据结构的情况。这被称为 缓冲区溢出(buffer overread),并可能会导致安全漏洞,比如攻击者可以像这样操作索引来读取储存在数据结构之后不被允许的数据。
为了保护程序远离这类漏洞,如果尝试读取一个索引不存在的元素,Rust 会停止执行并拒绝继续。尝试运行上面的程序会出现如下:
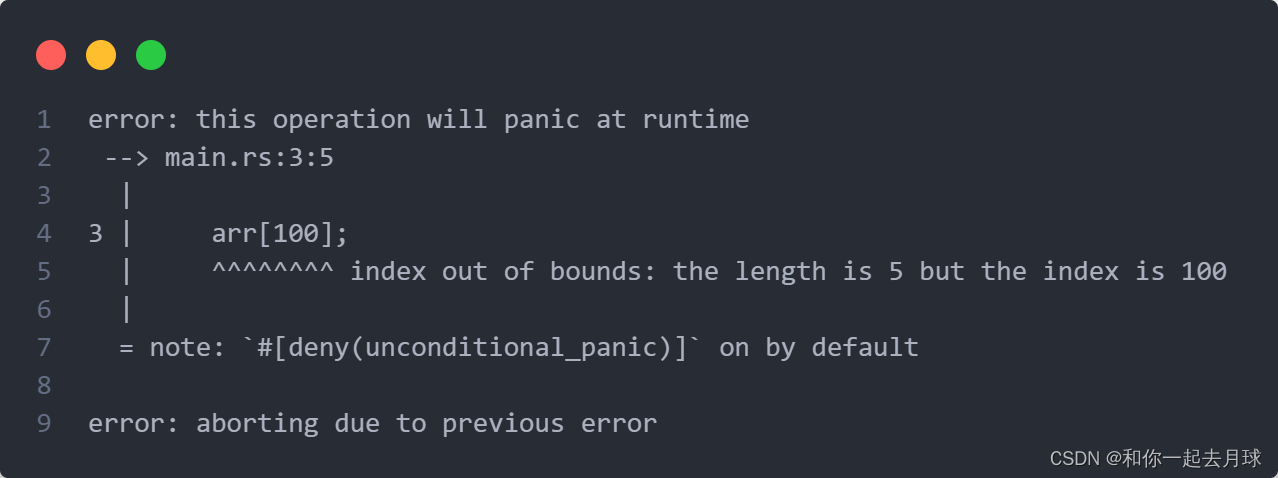
报错:运行时遇到panic错误,在main.rs第三行第五列开始,索引超过边界,长度为5,而索引值确实100。
让我们将 RUST_BACKTRACE 环境变量设置为1 的值来获取 backtrace 看看。
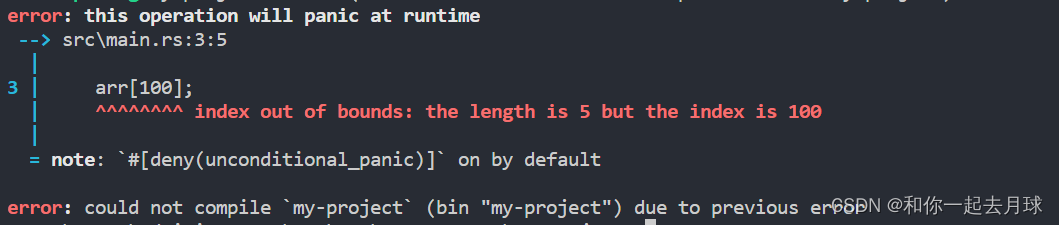
这是数组,报错比较简单,如果其他数据结构我们可以看一下结果,例如:string
fn main() {
let arr = String::from("hello");
arr[100];
}打印结果如下所示:
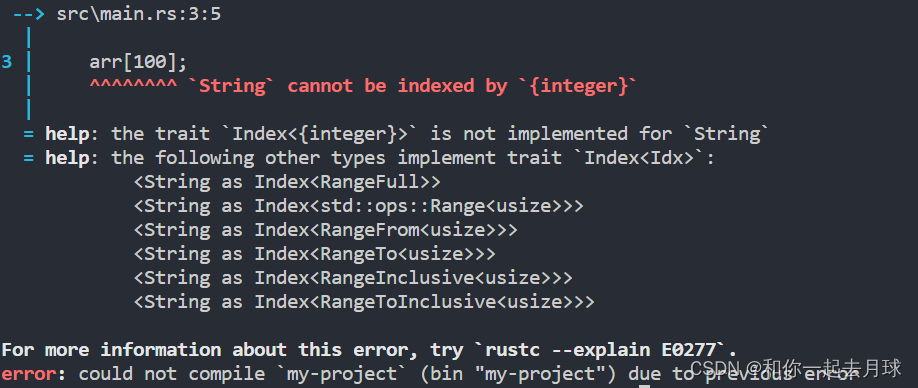
这里有大量的输出!你实际看到的输出可能因不同的操作系统和 Rust 版本而有所不同。为了获取带有这些信息的 backtrace,必须启用 debug 标识。当不使用 --release 参数运行 cargo build 或 cargo run 时 debug 标识会默认启用,就像这里一样。
在上图中,我们可以看到报错具体的文件以及对应的行号,下面还有rust程序报错更加详细的原因,这样可以更快的为我们解决问题,提升自己的效率。
2、用 Result 处理可恢复的错误
大部分错误并没有严重到需要程序完全停止执行。有时候,一个函数失败,仅仅就是因为一个容易理解和响应的原因。例如,如果因为打开一个并不存在的文件而失败,此时我们可能想要创建这个文件,而不是终止进程。
Result 枚举,它定义有如下两个成员,Ok 和 Err:
enum Result {
Ok(T),
Err(E),
}T 和 E 是泛型类型参数;现在你需要知道的就是 T 代表成功时返回的 Ok 成员中的数据的类型,而 E 代表失败时返回的 Err 成员中的错误的类型。因为 Result 有这些泛型类型参数,我们可以将 Result 类型和标准库中为其定义的函数用于很多不同的场景,这些情况中需要返回的成功值和失败值可能会各不相同。
让我们调用一个返回 Result 的函数,因为它可能会失败:看一下如下示例:
use std::fs::File;
fn main() {
let file_result = File::open("hello.txt");
}File::open 的返回值是 Result。泛型参数 T 会被 File::open 的实现放入成功返回值的类型 std::fs::File,这是一个文件句柄。错误返回值使用的 E 的类型是 std::io::Error。这些返回类型意味着 File::open 调用可能成功并返回一个可以读写的文件句柄。这个函数调用也可能会失败:例如,也许文件不存在,或者可能没有权限访问这个文件。File::open 函数需要一个方法在告诉我们成功与否的同时返回文件句柄或者错误信息。这些信息正好是 Result 枚举所代表的。
当 File::open 成功时,greeting_file_result 变量将会是一个包含文件句柄的 Ok 实例。当失败时,greeting_file_result 变量将会是一个包含了更多关于发生了何种错误的信息的 Err 实例。
这里使用match表达式来处理结果:
fn main() {
let file_result = File::open("hello.txt");
let res = match file_result {
Ok(file) => file,
Err(err) => panic!("打开文件发生错误...{:?}", err),
};
}当我们运行以上代码时,看一下输出结果如何:

2.1 匹配不同的错误
上面的代码不管 File::open 是因为什么原因失败都会 panic!。我们真正希望的是对不同的错误原因采取不同的行为:如果 File::open 因为文件不存在而失败,我们希望创建这个文件并返回新文件的句柄。如果 File::open 因为任何其他原因失败,例如没有打开文件的权限,我们可以通过不同分支把错误提示的更加详细。
fn main() {
let file_result = File::open("hello.txt");
match file_result {
Ok(file) => file,
Err(err) => match err.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(file) => file,
Err(err) => panic!("创建文件失败 {:?}", err),
},
other_error => panic!("其他错误 {:?}", other_error),
},
};
}File::open 返回的 Err 成员中的值类型 io::Error,它是一个标准库中提供的结构体。这个结构体有一个返回 io::ErrorKind 值的 kind 方法可供调用。io::ErrorKind 是一个标准库提供的枚举,它的成员对应 io 操作可能导致的不同错误类型。我们感兴趣的成员是 ErrorKind::NotFound,它代表尝试打开的文件并不存在。这样,match 就匹配完 greeting_file_result 了,不过对于 error.kind() 还有一个内层 match。
我们希望在内层 match 中检查的条件是 error.kind() 的返回值是否为 ErrorKind的 NotFound 成员。如果是,则尝试通过 File::create 创建文件。然而因为 File::create 也可能会失败,还需要增加一个内层 match 语句。当文件不能被打开,会打印出一个不同的错误信息。外层 match 的最后一个分支保持不变,这样对任何除了文件不存在的错误会使程序 panic。
2.2 失败时 panic 的简写:unwrap 和 expect
match 能够胜任它的工作,不过它可能有点冗长并且不总是能很好的表明其意图。Result 类型定义了很多辅助方法来处理各种情况。其中之一叫做 unwrap,它的实现就像上个示例中的 match 语句。如果 Result 值是成员 Ok,unwrap 会返回 Ok 中的值。如果 Result 是成员 Err,unwrap 会为我们调用 panic!。这里是一个实践 unwrap 的例子:
fn main() {
let file_result = File::open("hello.txt").unwrap();
}运行一下这个程序,看下对应的输出:

还有另一个类似于 unwrap 的方法它还允许我们选择 panic! 的错误信息:expect。使用 expect 而不是 unwrap 并提供一个好的错误信息可以表明你的意图并更易于追踪 panic 的根源。expect 的语法看起来像这样:
fn main() {
let file_result = File::open("hello.txt").expect("没有读取到文件");
}expect 与 unwrap 的使用方式一样:返回文件句柄或调用 panic! 宏。expect 在调用 panic! 时使用的错误信息将是我们传递给 expect 的参数,而不像 unwrap 那样使用默认的 panic! 信息。它看起来像这样:

在生产级别的代码中,大部分 Rustaceans 选择 expect 而不是 unwrap 并提供更多关于为何操作期望是一直成功的上下文。
2.3 传播错误
当编写一个其实先会调用一些可能会失败的操作的函数时,除了在这个函数中处理错误外,还可以选择让调用者知道这个错误并决定该如何处理。这被称为 传播(propagating)错误,这样能更好的控制代码调用,因为比起你代码所拥有的上下文,调用者可能拥有更多信息或逻辑来决定应该如何处理错误。
例如,示例 9-6 展示了一个从文件中读取用户名的函数。如果文件不存在或不能读取,这个函数会将这些错误返回给调用它的代码:
fn main() {
fn read_file() -> Result {
let file_result = File::open("hello.txt");
let v = String::from("open file success ...");
match file_result {
Ok(_) => Ok(v),
Err(err) => Err(err),
}
}
let res = read_file();
print!("{:?}", res)
}这个函数可以编写成更加简短的形式,不过我们以大量手动处理开始以便探索错误处理;在最后我们会展示更短的形式。让我们看看函数的返回值:Result。这意味着函数返回一个 Result 类型的值,其中泛型参数 T 的具体类型是 String,而 E 的具体类型是 io::Error。
如果这个函数没有出任何错误成功返回,函数的调用者会收到一个包含 String 的 Ok 值 —— 函数从文件中读取到的用户名。如果函数遇到任何错误,函数的调用者会收到一个 Err 值,它储存了一个包含更多这个问题相关信息的 io::Error 实例。
