


前言:
最近刚接触写Hive SQL,却发现许多查询的执行速度远不如预期。为了提升查询效率,我去阅读了《Hive编程指南》,希望通过理解其底层机制来找到优化的方式,并为未来能编写出高效的SQL奠定基础。谨以此文做个记录。
一、Hive因何而生
先有Hadoop再有Hive
Hadoop实现了一个计算模型——MapReduce,它可以将计算任务分割成多个处理单元然后分散到一群家用的或服务器级别的硬件机器上,从而降低计算成本并提供水平可伸缩性。但是这套编程模型对于大多数数据分析分析师较为复杂和地销,即便是Java开发编写MapReduce程序也需要很多时间和精力。基于此,Hive提供了基于SQL的查询语言(HiveQL),这边能够让拥有SQL知识的用户能够轻松使用Hadoop进行大数据分析,因为Hive的底层会自动将这些查询转换为MapReduce任务。
二、Hive组成模块
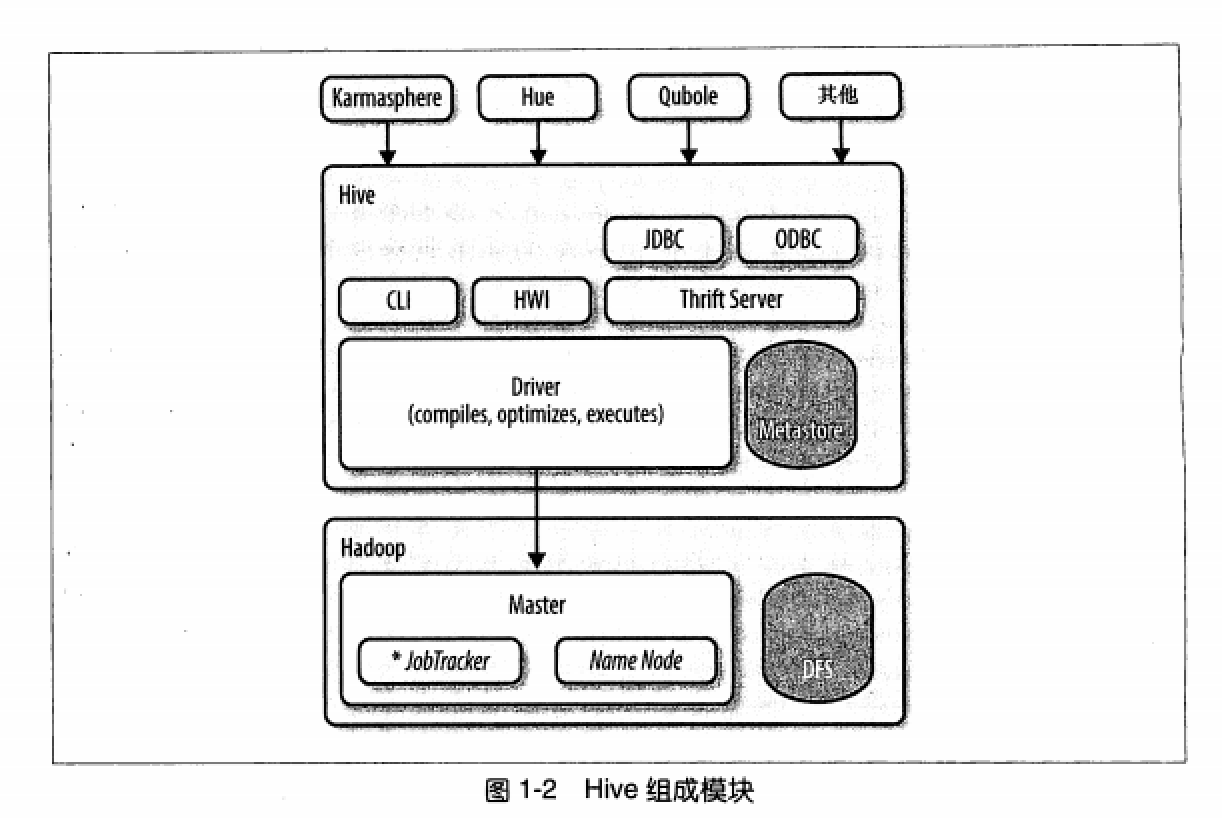
所有的命令和查询都会进入Driver,通过该模块对输入进行解析编译,对需求的计算进行优化,然后按照指定的步骤执行。
Hive通过JobTracker通信来初始化MapReduce任务,需要处理的数据文件是存储在HDFS中的,而HDFS是由NameNode进行管理的。
Metastore(元数据存储)是一个独立的关系型数据库,Hive会在其中保存表模式和其他系统元数据。
三、HQL执行流程
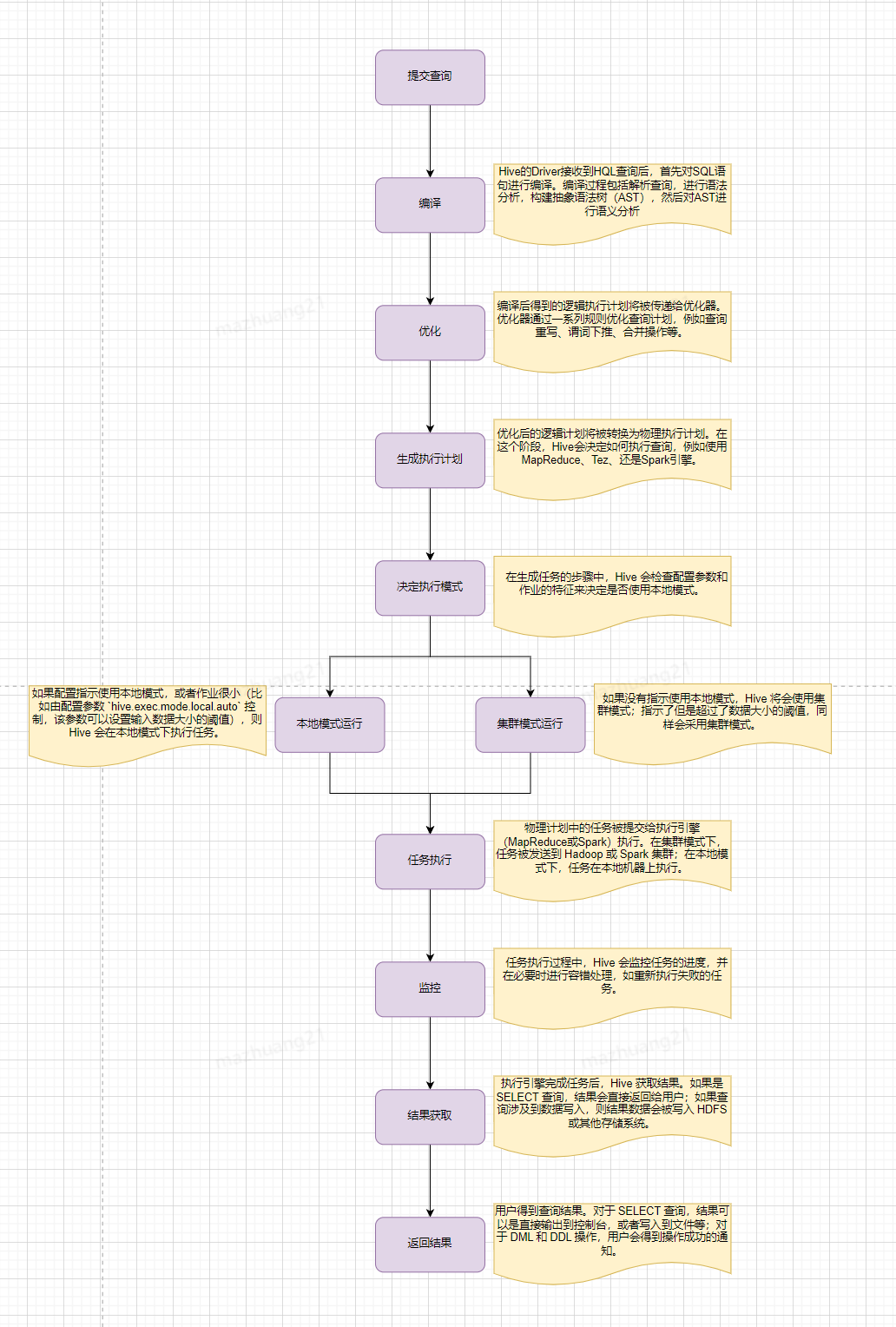
简单来说,Hive会从Hadoop分布式文件系统(HDFS)中读取原始数据,然后根据查询定义,在单节点(本地模式)或者Hadoop集群上(集群模式)执行数据处理。处理完成后,Hive会将结果输出到HDFS或者其他指定的存储位置。
那么,Hive的执行时间主要花费在哪儿呢?我们可优化的部分是哪部分?
Hive的执行时间主要花费在以下几个阶段:
查询编译:Hive 将 HiveQL 查询编译成一个逻辑执行计划,这个计划描述了如何执行查询。此阶段包括语法分析、语义分析、生成逻辑计划、逻辑计划优化和生成物理计划(通常是 MapReduce 作业)。
任务调度:编译生成的 MapReduce 作业被提交到 Hadoop 集群的资源管理器(如 YARN),等待资源调度和作业执行。
数据读写:读取存储在 HDFS 上的数据以及写入最终结果到 HDFS,这个过程涉及大量的磁盘 I/O 操作,尤其是在处理大量数据集时。
MapReduce 作业执行:包括
Map 阶段:执行过滤、投影等操作;
Shuffle 阶段:Map 任务输出的中间数据在网络上传输并在 Reduce 节点上进行排序和合并;
Reduce 阶段:执行聚合、排序等操作;
网络传输:在 MapReduce 的 Shuffle 阶段,中间数据需要在集群节点之间传输,这可能导致显著的网络延迟。
通常,MapReduce 作业的执行时间(尤其是 Shuffle 和 Reduce 阶段)以及数据的读写操作是 Hive 查询中最耗时的部分,也是我们优化过程中主要关注的部分,接下来我们看下有哪些常见的优化方式。
四、Hive常见的优化方式
本地模式
-- 开启本地模式,默认为false
hive.exec.mode.local.auto=true
原理:有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务的时间消耗可能会比实际job的执行时间要多得多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。用户可以通过设计属性
hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。实践有效,但如果并行执行的SQL过多,容易造成本地内存溢出。
map-side JOIN优化
#-- Hive v0.7之前需要通过添加标记 /*+ MAPJOIN(X) */ 触发,如下图
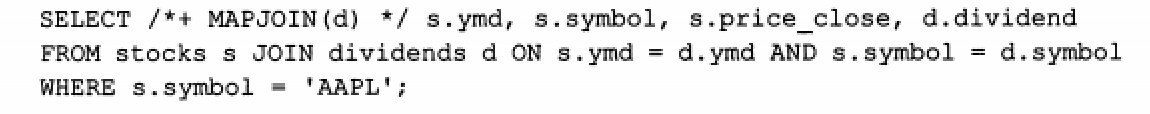
-- Hive v0.7版本开始之后,通过设置hive.auto.convert.JOIN的值为true开启
set hive.auto.convert.JOIN=true
-- 设置小表的大下,单位为字节
set hive.mapjoin.smalltable.filesize=25000000
原理:如果所有表中有一个表足够得小,是可以完成载入内存中的,那么这时Hive可以执行一个map-side JOIN,将小表完全放到内存,Hive便可以直接和内存中的小表进行逐一匹配,从而减少所需要的reduce过程,有时甚至可以减少某些map task任务。
并发执行
-- 通过设置参数hive.exec.parallel值为true,开启并发执行,默认为false
set hive.exec.parallel=true
原理:Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段等。默认情况下,Hive一次只会执行一个阶段。但是有些阶段并非完全互相依赖的,也就是说这些阶段是可以并行执行的,这样可以使得整个job的执行时间缩短。
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。
动态分区调整
-- 启用动态分区,默认为false;
SET hive.exec.dynamic.partition=true;
-- 启用动态分区模式为非严格模式。开启严格模式时们必须保证至少有一个分区时静态的。
SET hive.exec.dynamic.partition.mode=nonstrict;
-- 设置在一个动态分区插入操作中可以创建的最大分区数量
SET hive.exec.max.dynamic.partitions=1000;
-- 设置每个节点可以创建的最大分区数量
SET hive.exec.max.dynamic.partitions.pernode=100;
当执行查询时,如果查询条件包含分区键,Hive可以仅扫描相关分区的数据,从而减少了扫描的数据量,提高查询效率;在执行动态分区的插入时,这些分区也可以并行写入,从而提高了数据写入的并行度和性能。通过以上参数,可更好的使用动态分区。
合并小文件
--是否和并Map输出文件,默认true
SET hive.merge.mapfiles=true;
--是否合并 Reduce 输出文件,默认false
SET hive.merge.mapredfiles=true;
-- 设置合并文件的大小阈值
SET hive.merge.size.per.task=256000000;
-- 设置小文件的平均大小阈值
SET hive.merge.smallfiles.avgsize=128000000;
由于一些小批量的写入、MapReduce作业切割、数据倾斜等原因,Hive中可能会产生大量小文件,通过以上参数可进行小文件合并以减少读取文件时的开销、降低NameNode压力,提升查询效率。
数据倾斜优化
数据倾斜指的是在分布式处理过程中,数据不均匀地分配给各个节点处理,导致部分节点负载过重,而其他节点负载轻松,从而影响整体计算效率。数据倾斜出现的原因主要如下:
键值分布不均匀:有些键值对应的数据远多于其他键值;
量相同键值:大量数据使用相同的键(如null或者特定的默认值)进行分组;
不合理的JOIN操作:在JOIN大表时,如果小表的某个键值在大表中分布不均,导致JOIN后的结果倾斜;
不合理的分区策略:数据分区时没有考虑数据的实际分布,导致分区不均匀。
主要解决方案有:
自定义分区策略:实现自定义分区期,根据数据的特点进行更合理的分区;
扩展键值:对倾斜的键添加随机前缀或编号,使其分散到多个分区;
过滤大键值数据:识别出倾斜的键值(如null、空值)进行单独处理或过滤掉不重要的数据。
最后就是我们关系型数据库常用的优化方式同样也适用与Hive。例如通过使用小表关联大表的方式减少查询数据量,提高查询效率;Hive同样也有索引的概念,通过建立索引减少MapReduce的输入数据量,但同样和关系型数据库一样,是否使用索引需要进行仔细评估,因为维护索引也需要额外的存储空间,而且创建索引同样消耗计算资源;Hive同样也有EXPLAIN关键字,用于查询Hive时如何将查询转化为MapReduce任务的,使用EXPLAIN EXTENDED语句可以产生更多的输出信息,有兴趣大家可自行查看。
总体而言,这本书对于刚入门学习写HQL的我来说收获很大,让我初步对Hive有了基本的认知,也让我对我写的SQL有了更深入的了解。但是该书中的Hive应该版本比较低了,和我们现在所使用的可能有所偏差,不过入个门足够了。本文除了书中内容还有些我个人理解,如有错误,欢迎指正。
作者: 马壮
来源:京东云开发者社区 转载请注明来源
