

作者:尚卓燃(PsiACE)
澳门科技大学在读硕士,Databend 研发工程师实习生
Apache OpenDAL(Incubating) Committer
https://github.com/PsiACE

HuggingFace 是目前全球最流行的 AI 社区,推动数据科学家和企业在模型、数据集和应用等诸多方面进行创新与合作。HuggingFace 上存在各种各样的数据集,不光可以用作学习和练习的样本,也可以作为企业模型数据来源的基石。
为了更好发挥数据集的作用,往往需要对数据集中的原始数据进行清洗,并且归档在数据湖中提供统一的访问入口。Databend 围绕 ETL/ELT 为中心的工作流进行设计,在载入同时即可直接对数据进行清洗、转化、合并等操作;具备丰富的结构化与半结构化数据类型,能够直接查询和分析多种格式的原始数据;企业版还支持虚拟列、计算列等高级特性,确保数据始终就绪。
在这篇文章中,我们将会展示如何利用 Databend 轻松访问 HuggingFace 上托管的数据集,并且使用 SQL 进行简单高效的分析和处理。此外,示例中还包含一个使用 SQL 实现的白盒模型,展示如何在数据仓库中进行类别预测,并验证模型精度。
访问 HuggingFace 数据集
HuggingFace 提供公开可访问的 REST API ,并且支持在上传时将数据集文件自动转化为 Parquet ,使其能够与数据库和数据分析工具轻松集成。
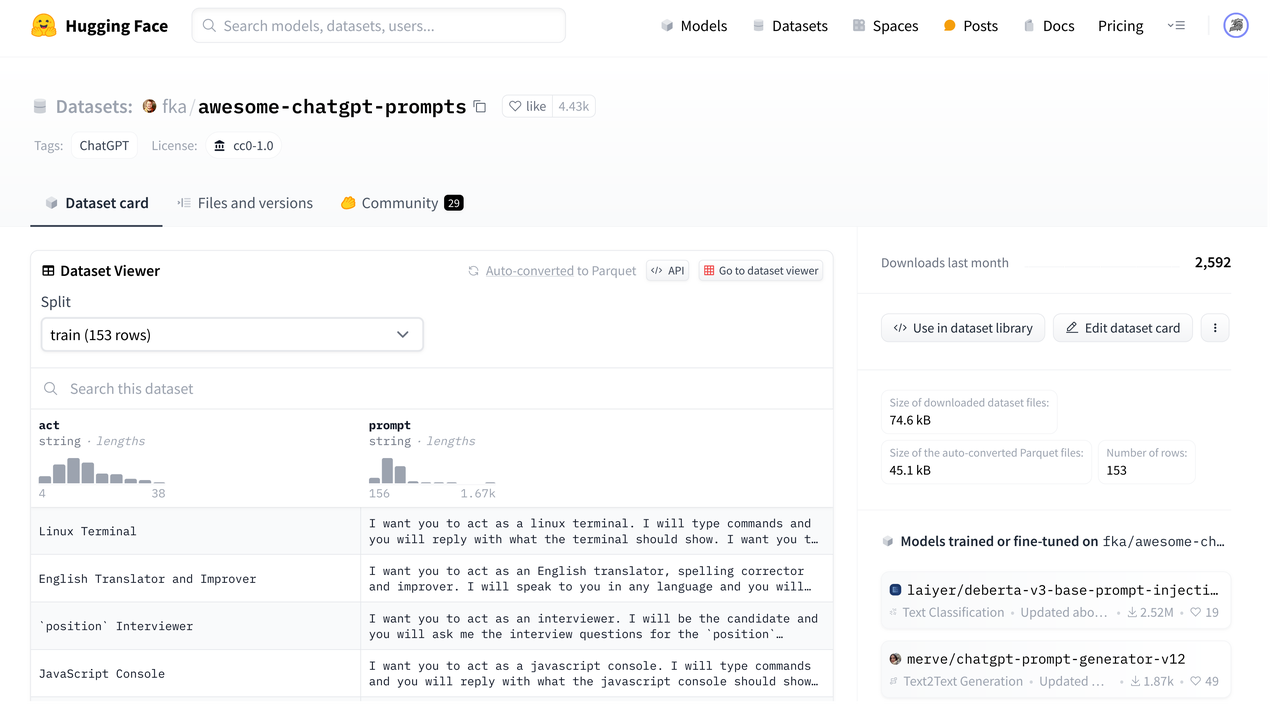
其数据集的页面如下所示,透过 Dataset card 可以直观了解数据的相关信息并获得预览,而 Files and Versions 页面将会有助于了解目录结构和修订版本等信息。
Databend 提供多种与 HuggingFace 集成的方式,在接下来的部分,我们将会以 fka/awesome-chatgpt-prompts 作为例子,说明如何使用 Databend 访问 HuggingFace 数据集。
fka/awesome-chatgpt-prompts 是一个流行的 GPT Prompts 数据集,包含 153 条高质量的 Prompts 及其对应的场景。
外部 Stage/Location
现在很多数据库支持使用 HTTPS 协议直接访问远端的数据文件,这种模式不光适用于 HuggingFace ,也可以与其他提供 HTTPS 访问的文件服务集成。但是,直接使用远程 URL 访问存在一些弊端,比如遇到预期外的响应、错误的转义和编解码、为了定位文件需要进行复杂的 JSON 解析。
Databend 除了支持上述方式之外,还可以直接将 HuggingFace 文件系统作为外部 Location 访问或者挂载为外部 Stage,能够有效避免访问问题,轻松处理数据查询。
对于 HuggingFace ,其适用的 externalLocation 参数如下:
externalLocation ::=
"hf://[]"
CONNECTION = (
)
URI格式:hf://{repo_id}/path/to/file,其中repo_id 类似 fka/awesome-chatgpt-prompts 。
支持的配置包括:
-
repo_type: HuggingFace 仓库类型,默认为dataset,可用选项有dataset,model。 -
revision: HuggingFace 修订版本,默认为main。可以是仓库中的分支、标签或提交。 -
token: HuggingFace 的 API 令牌。
以外部 Location 的形式查询原始 CSV 数据文件
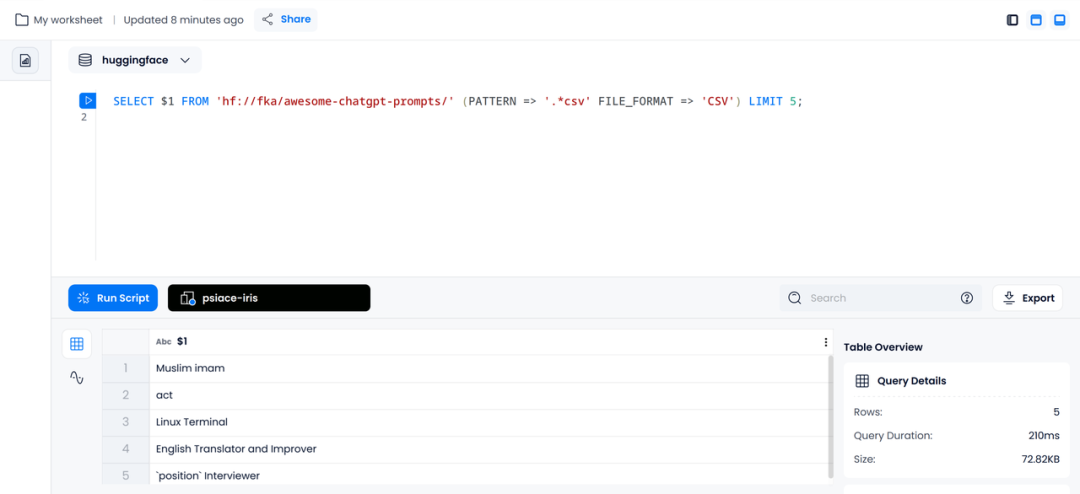
下面示例展示了如何使用 Databend 直接查询 fka/awesome-chatgpt-prompts 的原始 CSV 数据文件,并列出其中 CSV 文件第一列的 5 条数据。
SELECT $1 FROM 'hf://fka/awesome-chatgpt-prompts/' (PATTERN => '.*csv' FILE_FORMAT => 'CSV') LIMIT 5;
以外部 Stage 的形式查询转化的 Parquet 数据文件
前面提到 HuggingFace 提供转化后的 Parquet 文件,而 Databend 也支持以外部 Stage 形式挂载 HuggingFace 文件系统,下面的示例展示了其用法:
创建 Stage
对于本示例,转化后的文件位于 refs%2Fconvert%2Fparquet 这个分支的 /default/train/ PATH 下,我们可以直接挂载这个路径。
CREATE STAGE IF NOT EXISTS stage_huggingface_fka_prompts url = 'hf://fka/awesome-chatgpt-prompts/default/train/' connection = (revision = 'refs%2Fconvert%2Fparquet');
列出对应文件:
可以利用 PATTERN 列出 Stage 中符合特定模式的文件名,方便查询和分析。
LIST @stage_huggingface_fka_prompts PATTERN = '.*parquet';

查询数据
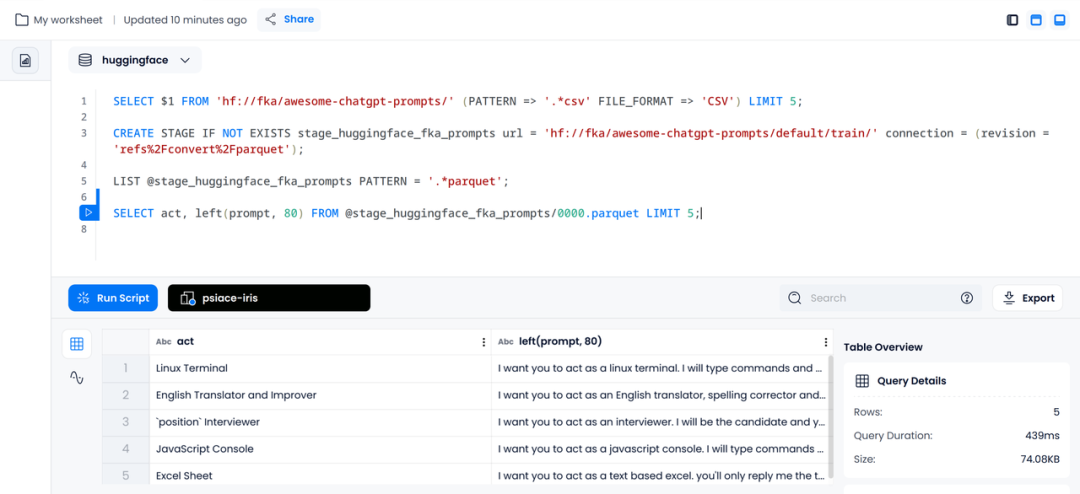
由于此前已经从 CSV 文件中获取了文件的信息,在查询 Parquet 文件时候,我们可以直接选取其中的列,考虑到 prompt 在终端中不方便全部展示,这里截断为 80 个字符。
SELECT act, left(prompt, 80) FROM @stage_huggingface_fka_prompts/0000.parquet LIMIT 5;
使用 SQL 的 数据科学
上面介绍了如何对位于 HuggingFace 的远程数据集进行简单查询,这一节中我们来看一个具体的案例,探索使用 SQL 的数据科学。
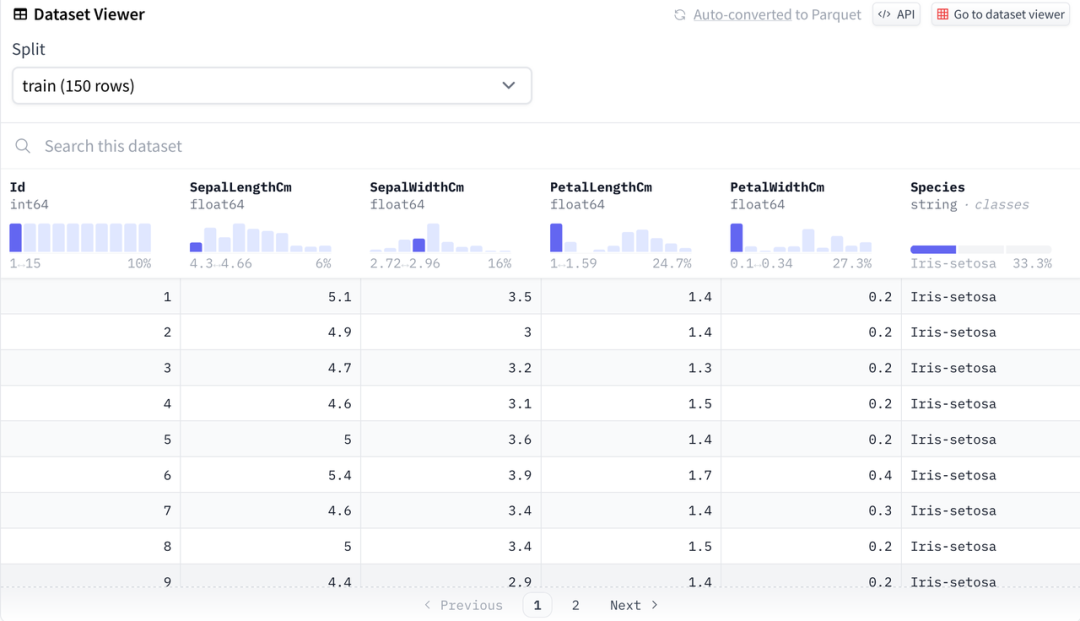
为了方便理解,我们选取数据科学入门常用的鸢尾花分类数据集(iris)作为示例。Iris 数据集出现在 R.A. Fisher 1936年的经典论文 The Use of Multiple Measurements in Taxonomic Problems ,也可以在 UCI 机器学习知识库中找到,非常适合演示简单的分类模型。
本文中使用的 HuggingFace 数据集位于 https://huggingface.co/datasets/scikit-learn/iris 。
数据挂载
我们将会将数据集挂载为 Databend 的外部 Stage :
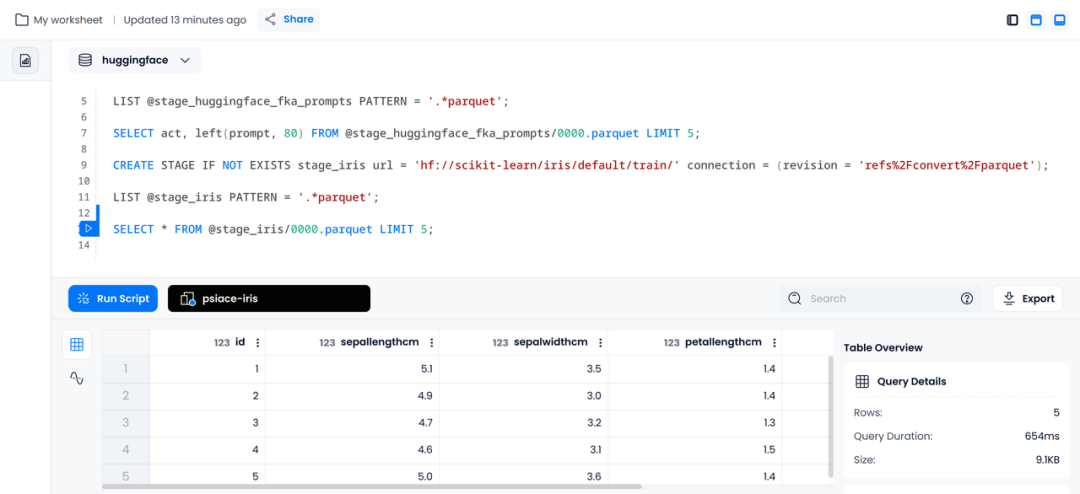
CREATE STAGE IF NOT EXISTS stage_iris url = 'hf://scikit-learn/iris/default/train/' connection = (revision = 'refs%2Fconvert%2Fparquet');
LIST @stage_iris PATTERN = '.*parquet';
SELECT * FROM @stage_iris/0000.parquet LIMIT 5;
数据清洗
外部 Stage 中的数据相当于是原始数据,为了满足数据规范和使用需要,可以在导入时进行清洗,对于 Iris 数据集,典型的清洗操作包括:
- 移除
id列。 - 将
species列转换成类别标签,即整数形式。 - 将特征列从
float64转换成float32。 - 将特征列重命名为蛇形命名法(snake case)。
Databend 中可以利用 COPY INTO 语句在载入时完成数据清洗。
创建对应的表
执行下述语句,可以在 Databend 中创建符合数据规范的表。
CREATE TABLE iris (
sepal_length FLOAT,
sepal_width FLOAT,
petal_length FLOAT,
petal_width FLOAT,
species INT
);
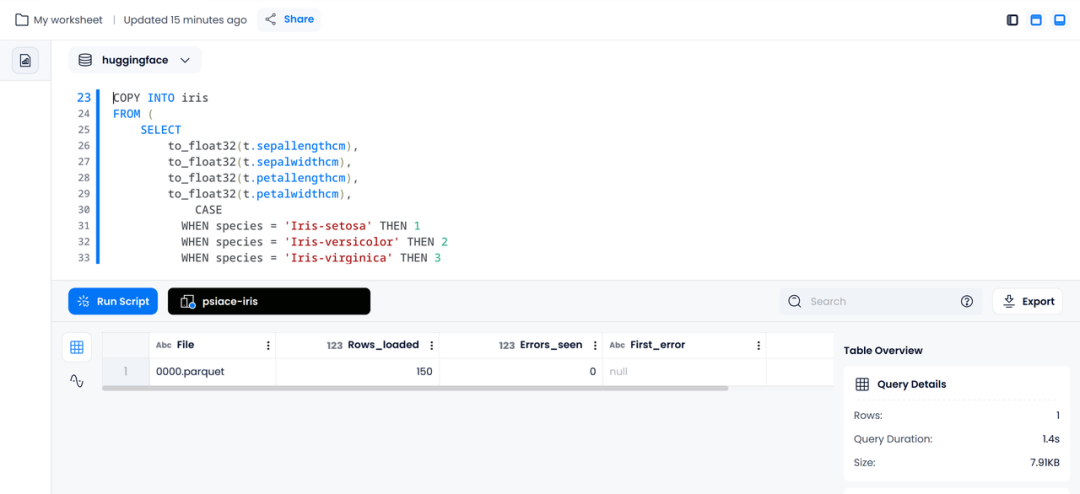
使用 COPY INTO 导入数据
执行下述语句,可以在导入数据的同时,一步到位完成数据清洗工作。
COPY INTO iris
FROM (
SELECT
to_float32(t.sepallengthcm),
to_float32(t.sepalwidthcm),
to_float32(t.petallengthcm),
to_float32(t.petalwidthcm),
CASE
WHEN species = 'Iris-setosa' THEN 1
WHEN species = 'Iris-versicolor' THEN 2
WHEN species = 'Iris-virginica' THEN 3
ELSE NULL
END AS species
FROM @stage_iris t
)
FILE_FORMAT = (TYPE = PARQUET)
PATTERN = '.*parquet';
基本统计
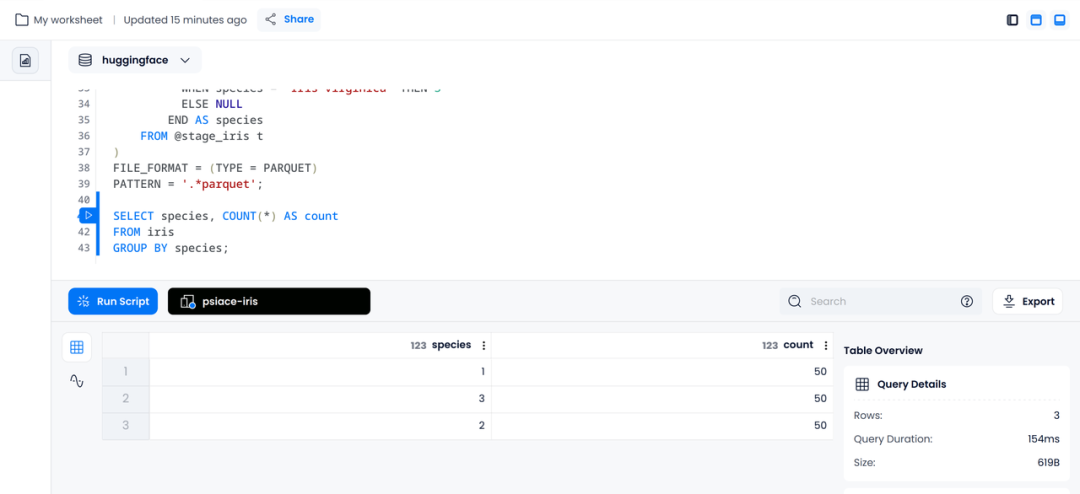
执行下述语句,我们可以得到清洗后数据中,不同类别的数目各有多少。
SELECT species, COUNT(*) AS count
FROM iris
GROUP BY species;
基本分析
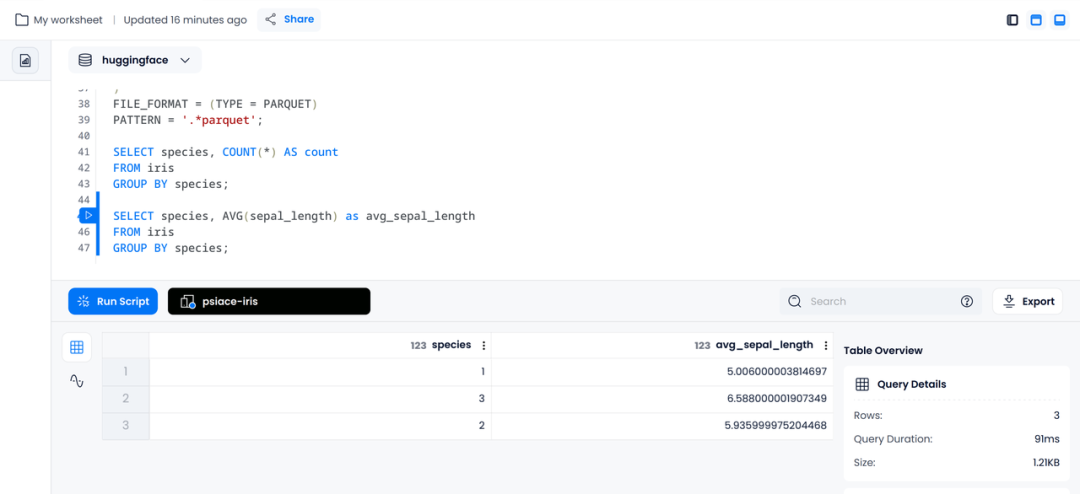
执行下述语句,我们可以得到每种鸢尾花的平均萼片长度:
SELECT species, AVG(sepal_length) as avg_sepal_length
FROM iris
GROUP BY species;
使用 SQL 预测鸢尾花类型
利用 SQL 表达简单的白盒模型,能够直观感受到模型的预测标准,并且省去与模型服务进行交互的步骤。
下面的示例仅供演示使用,并不符合严谨的训练、验证、应用的数据科学流程。
在数据科学家利用数据进行分析之后,我们可以得到一些可以量化的分类依据,结合 CASE WHEN 语句,可以使用 SQL 对简单的模型进行表达。
SELECT
sepal_length,
sepal_width,
petal_length,
petal_width,
species,
CASE
WHEN petal_width = 0.75 AND petal_width = 0.75 AND petal_width = 1.35 AND sepal_width = 0.75 AND petal_width = 1.35 AND sepal_width >= 2.65 THEN 2
WHEN petal_width >= 0.75 AND petal_width >= 1.75 THEN 3
END AS prediction
FROM
iris;
上述 SQL 将会在选中的数据后附加一个预测列,展示预测的类别。
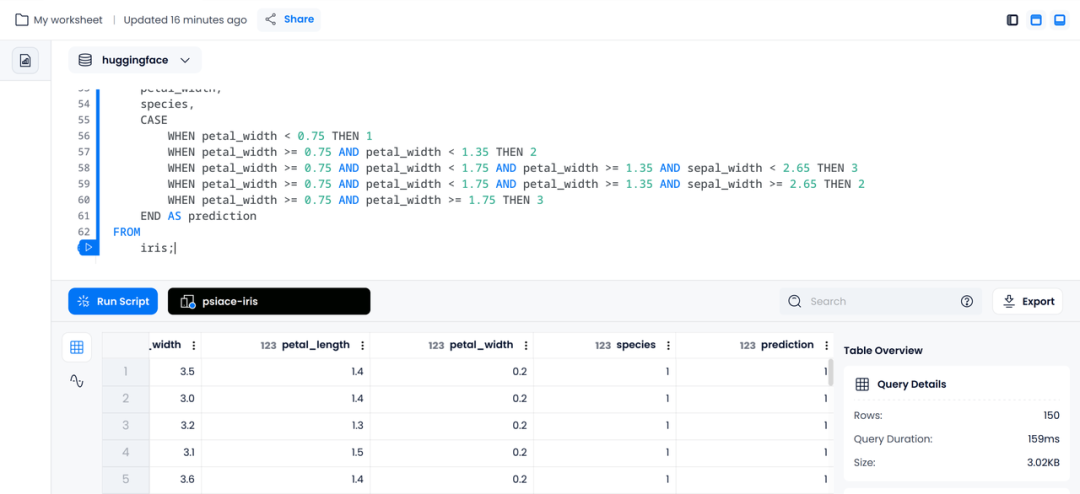
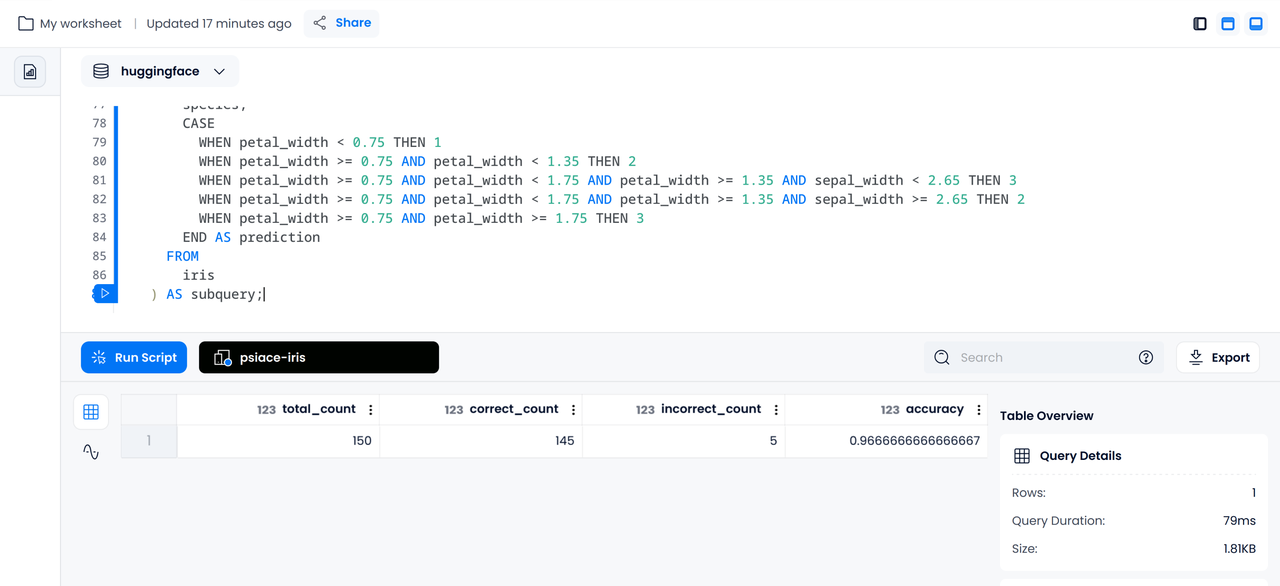
由于我们的鸢尾花数据集本身是具有类别的,所以可以使用 SQL 根据预测结果进一步计算模型在数据集上的精度:
SELECT
COUNT(*) AS total_count,
SUM(CASE WHEN subquery.species = subquery.prediction THEN 1 ELSE 0 END) AS correct_count,
SUM(CASE WHEN subquery.species subquery.prediction THEN 1 ELSE 0 END) AS incorrect_count,
SUM(CASE WHEN subquery.species = subquery.prediction THEN 1 ELSE 0 END) / COUNT(*) AS accuracy
FROM
(
SELECT
sepal_length,
sepal_width,
petal_length,
petal_width,
species,
CASE
WHEN petal_width = 0.75 AND petal_width = 0.75 AND petal_width = 1.35 AND sepal_width = 0.75 AND petal_width = 1.35 AND sepal_width >= 2.65 THEN 2
WHEN petal_width >= 0.75 AND petal_width >= 1.75 THEN 3
END AS prediction
FROM
iris
) AS subquery;
总结
在这篇文章中,我们展示了如何使用 Databend 直接访问和查询 HuggingFace 数据集。并且展示了如何使用 SQL 对数据进行预处理,使其符合数据规范。此外,利用 CASE WHEN 语句,我们可以轻松表达简单的模型,在 SQL 中完成对 Iris 数据集的预测任务,并且进行精度统计。
本文涉及的所有操作均可以在 Databend Cloud(海外版)上直接体验。如果你对使用 Databend 进行数据科学分析感兴趣,也欢迎使用 Databend Cloud 上就绪的计算集群进行一步探索。
