

从工程化的角度,对鹏城.脑海大模型训练语料处理、模型训练优化、模型应用等方面做出了全面详细的经验分享。
我们有幸邀请到了鹏城实验室高效能云计算所算法工程师陶恒韬老师来进行鹏城.脑海大模型训练过程的讲解。在课程中,陶老师从工程化的角度,对鹏城.脑海大模型训练语料处理、模型训练优化、模型应用等方面做出了全面详细的经验分享。
鹏城.脑海大模型介绍
鹏城·脑海(PengCheng Mind)大模型计划:旨在打造自然语言预训练大模型底座,将实现2000亿参数稠密型AI大模型
鹏城·脑海大模型:
- 以中文为核心的文本大模型基座
- 2000亿级别参数,稠密型自回归式语言模型
- 依托“鹏城云脑II”千卡集群,基于昇思MindSpore多维分布式并行技术进行预训练
- 保障大模型的数据安全隐私,输出内容符合中文核心价值观
- 大模型能力持续演进,快速迭代更新
训练语料处理和使用
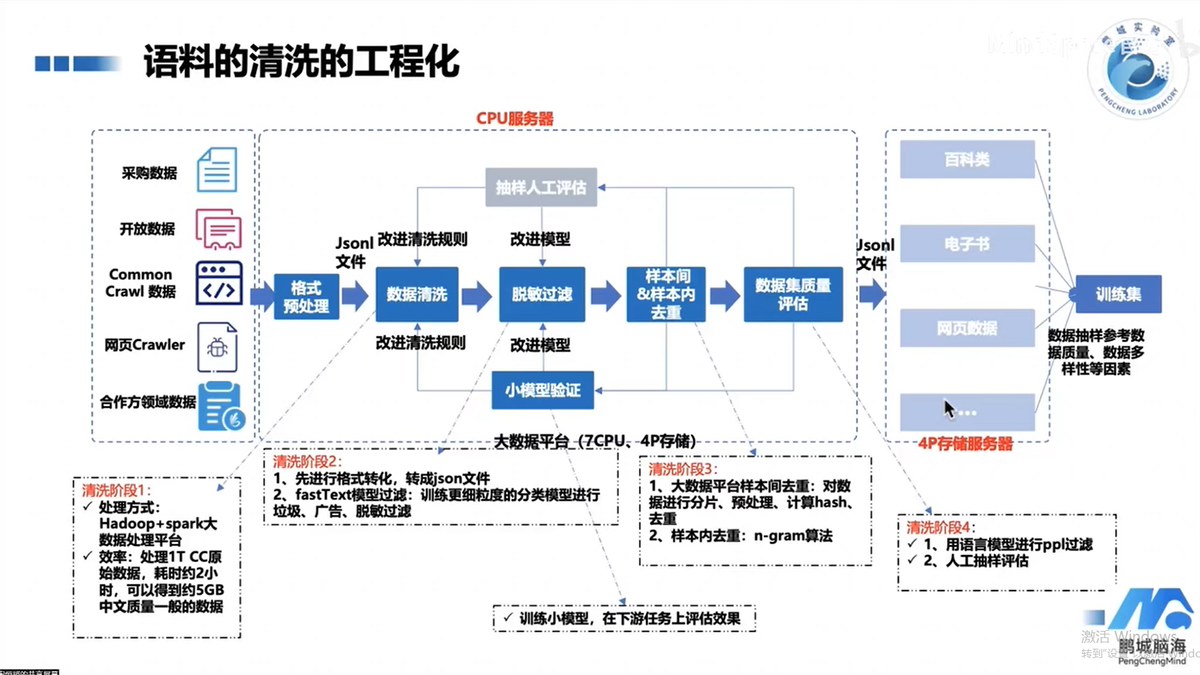
语料清洗工程化:收集数据——格式预处理——数据清洗——脱敏过滤——样本间和样本内去重——数据集质量评估
- 脱敏过滤:通过分类模型进行过滤,并不断迭代优化,包含敏感词和文本过滤器、广告词过滤器、质量评估器
- 样本间和样本内去重:样本间采用计算hash去重,样本内采用n-gram算法去重
- 数据集分布:中文为核心,覆盖40个不同领域,以经济、文学、教育、医学、法律等为主导
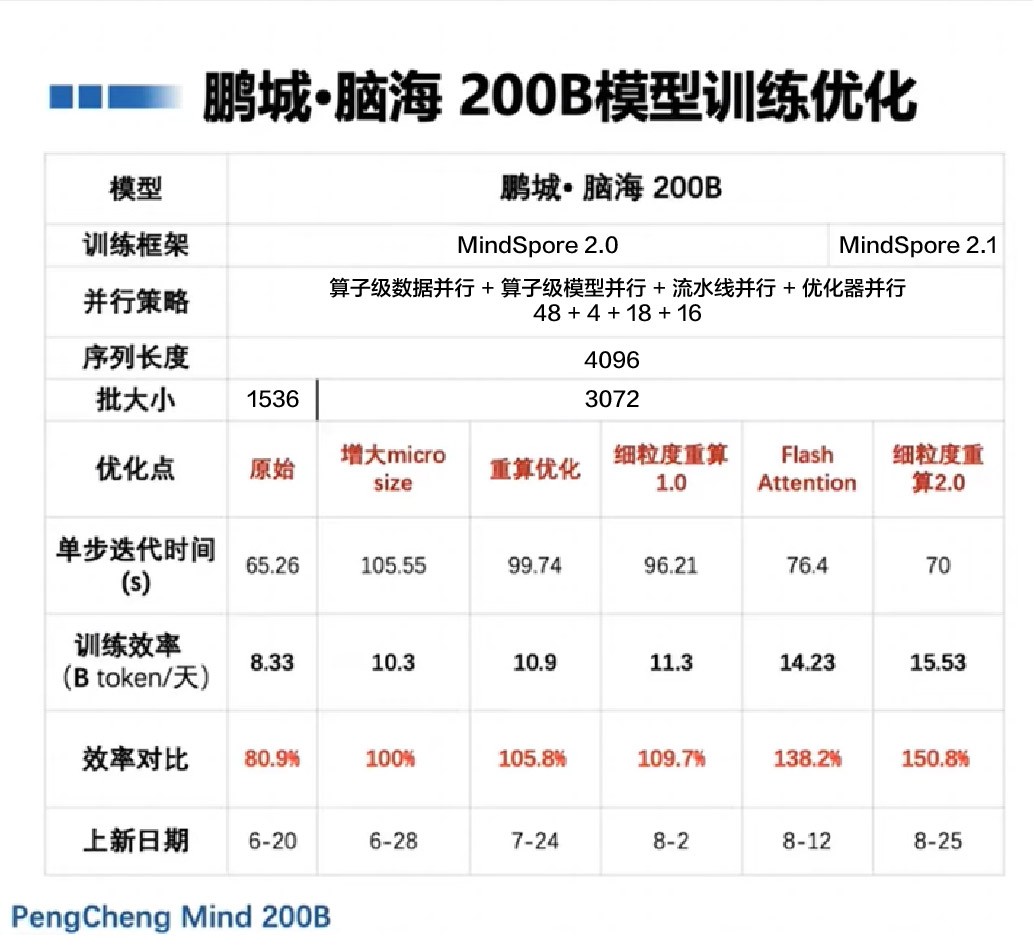
200B模型训练过程
模型结构:Transformer Decoder only,延续GPT-175B模型结构,并在其基础上进行了相应拓展
- 延续PanGu-α,在Transformer decoder层上添加top query查询层,用于预测下一token
- 位置编码采用旋转位置编码(ROPE)
- 使用FlashAttention进行加速优化
训练策略:对比PanGu-α,重构训练策略,采用数据+模型+流水线+优化器并行
- 重计算:时间换空间,不保存正向算子计算结果,在计算反向算子时,如需要相应正向结果,再重新计算正向算子
- 选择性重算:整网重算存在显存空余,选择部分算子重算,提升显存利用率和训练效率
- 细粒度重算:针对不同层的算子进行差异化的重算配置,搭配流水线并行的均衡配置,提高可配置选择性重算的空间
分布式并行配置:机柜之间的带宽
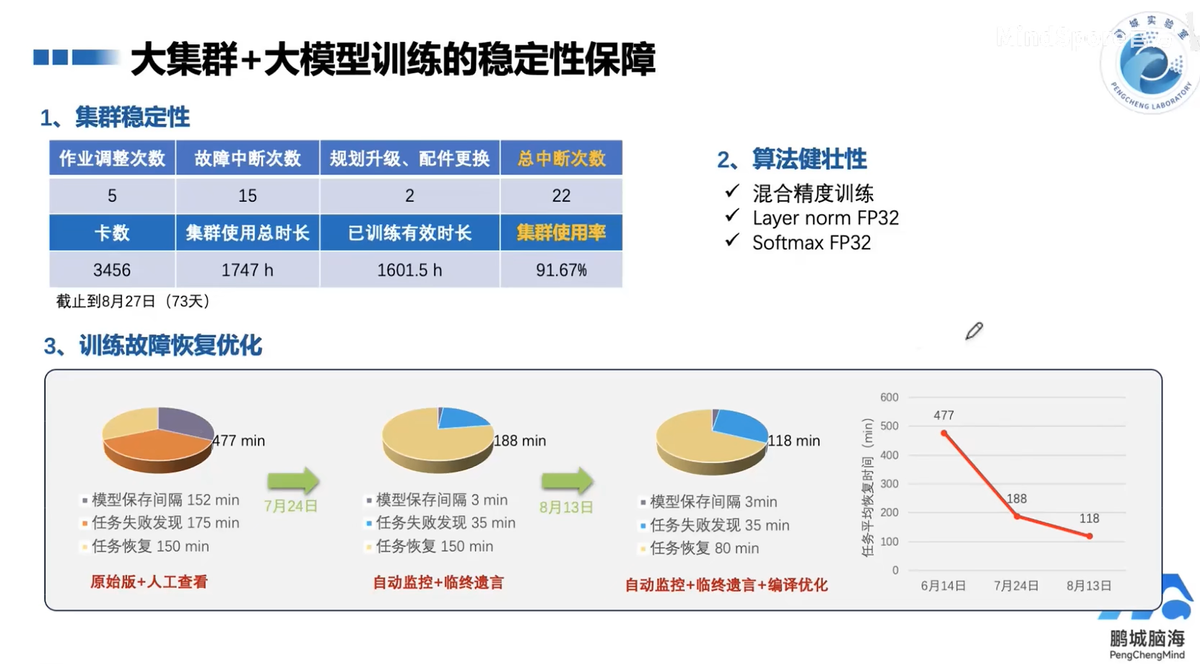
大集群+大模型训练的稳定性保障
- 算法健壮性:混合精度训练,针对精度敏感的Layer norm和softmax采用FP32
- 训练故障恢复优化:自动监控+临终遗言+编译优化
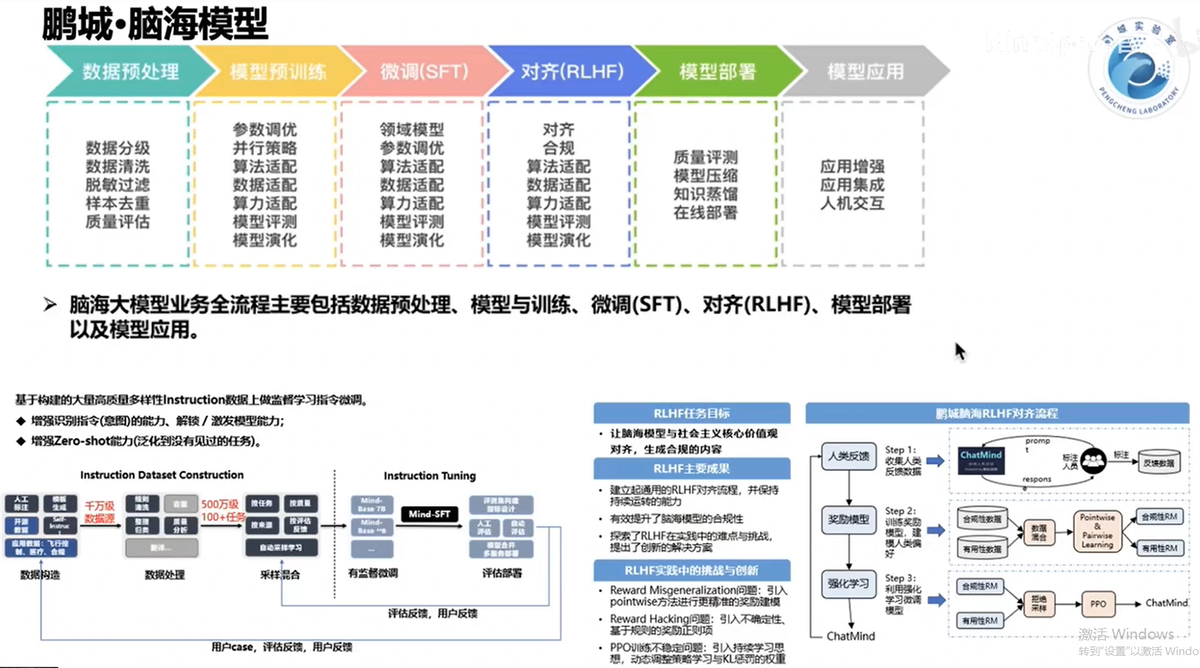
鹏城·脑海模型全流程开发:数据预处理—模型预训练—微调(SFT)–对齐(RLHF)–模型部署—模型应用
【下节课程预告】
下周六(2024年1月20日)我们即将迎来国产开源大语言模型另一位重磅玩家——CPM-Bee中英文双语基座大模型。在下节课程中,我们非常荣幸地邀请到了OpenBMB开源社区技术负责人、清华大学硕士,同时也是CPM-Bee开源搭模型项目主要维护者 龚柏涛老师来进行CPM-Bee模型的讲解。
这里我们稍稍剧透下课程内容,各位小伙伴1月20日 14:00-15:30不见不散!
- CPM-Bee模型结构:CPM-Bee的模型结构介绍
- CPM-Bee数据格式:介绍CPM-Bee的结构化输入输出数据格式,以及相应的分词、位置编码的方法
- CPM-Bee微调及推理演示:基于例子演示,介绍Mindspore+CPM-Bee的使用方法,包括推理、微调等
昇思MindSpore技术公开课大模型专题第二期课程火爆来袭!未报名的小伙伴抓紧时间参与课程,并同步加入课程群,有免费丰富的课程资源在等着你。课程同步赋能华为ICT大赛2023-2024,助力各位选手取得理想成绩!
戳我立即了解课程
点击关注,第一时间了解华为云新鲜技术~
