

一、实验目的
1、通过实验和分析,评估不同的等待机制在Python动态网页爬虫中的使用效果和性能差异。
2、通过对比不同等待机制的优缺点,可以更好地了解何时使用何种等待机制,并选择最适合自己需求的方法。
3、对于网页进行请求,然后抓取所需的内容,最后存储数据,可以了解爬取的过程。
二、实验内容和要求
Exercise 1
1、利用实际的Python动态网页爬虫为例,来了解3种等待(Waits) 机制
2、详细的实作内容可以参考以下的GitHub网址
https://github.com/mikekul116/pythonpchome-scraper
Exercise 2
比较三种等待机制,各自的优缺点
Exercise 3
1、实验分析三种等待机制,各自适用的数据量状态与应用
2、跑一支任意程序,针对不同的等待,连续三次,纪录时间,做成图
Exercise 4
https://www.webscrapingpro.tw/what-is-web-scraping/
实际范例演练
三、实验环境
Python
四、实验方法和步骤
1、利用实际的Python动态网页爬虫为例,来了解3种等待(Waits) 机制
由于提供的代码中的selenium库版本较低,而新版本的selenium库可以不必设置driver.exe路径。如果不修改代码则需要降低selenium库的版本,或者修改代码。我下面的代码都是修改代码,而不是降低selenium库的版本。
(1)强制等待(sleep)
a、导入所需的库
b、创建一个Chrome浏览器的实例

c、browser.get()方法打开目标网站

d、设置强制等待等待时间,等待页面加载完成

e、使用find_element()方法找到需要的元素,并执行相应的操作

(2)明确等待(explicit)
a、导入所需的库

b、创建一个Chrome浏览器的实例

c、browser.get()方法打开目标网站

d、设置明确等待等待时间,等待页面加载完成
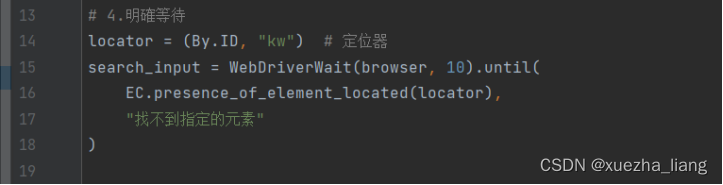
e、定位到需要的元素,并执行相应的操作

(3)隐含等待(implicit)
a、导入所需的库

b、创建一个Chrome浏览器的实例

c、browser.get()方法打开目标网站

d、设置隐含等待等待时间,等待页面加载完成

e、使用find_element()方法找到需要的元素,并执行相应的操作

2、比较三种等待机制,各自的优缺点
强制等待(sleep):
优点:实现简单,直接暂停程序执行指定的时间。
缺点:不灵活,等待时间固定,无法根据页面加载情况来调整等待时间。如果页面加载较快,等待时间过长导致浪费;如果页面加载较慢,等待时间过短导致找不到元素而报错。
例子:你在家里等朋友来拜访,但你不知道他们什么时候会到达。于是你决定在指定的时间等待一段时间,比如说你决定等待10分钟。在这10分钟内,你无论朋友们是否到达,你都会一直等待。就是说你在指定的时间段内等待,无论条件如何,这个就是强制等待。
隐式等待(Implicit):
优点:全局设置,适用于整个测试用例,不需要在每个操作中都添加等待时间。
缺点:只能等待元素可见或不可见,不能精确控制等待的条件和时间。如果页面加载较慢,等待时间较长;如果页面加载较快,可能会导致找不到元素而报错。
例子:比如你点了一道菜。告诉你这道菜需要15分钟准备好。你可以在这15分钟内做其他事情。如果菜在15分钟内准备好了,你就可以立即享用。但如果菜需要更长的时间,你可以继续等待。这就是隐式等待,你等待一段时间,但不需要一直关注等待的条件。
显式等待(Explicit):
优点:可以根据具体的条件和时间来等待,非常灵活。可以等待元素可见、可点击、存在、消失等多种条件。
缺点:需要在每个等待的操作中明确指定条件和时间,相对来说稍微繁琐一些。
例子:比如去机场接机。你知道飞机将在特定的时间降落,但你不知道具体什么时候。你可以使用手机上的APP获得航班信息,从而获取飞机的准确位置和预计到达时间。你可以根据这些信息决定何时出发去接机。这就是显式等待,你根据特定的条件和时间来等待,直到满足条件后再执行下一步操作。
3、跑一支任意程序,针对不同的等待,连续三次,纪录时间,做成图,并进行分析
代码思路:在Chrome浏览器中打开百度网站,并进行四种不同的等待方法(循环方式)的测试。通过记录开始时间和结束时间,计算出每种等待方法的耗时,并保存在列表中。最后使用matplotlib模块绘制出各种等待方法的耗时图。
a.导入所需的库
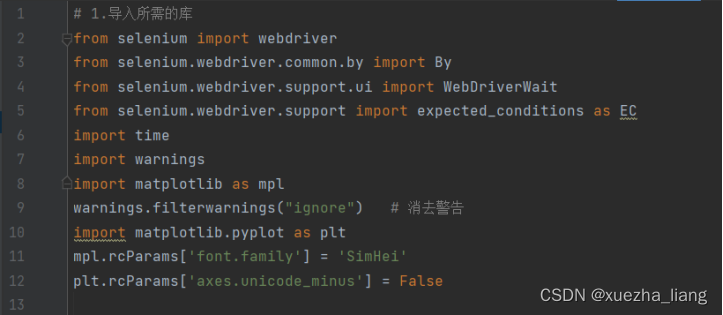
导入matplotlib模块用于绘图;导入selenium的webdriver模块用于创建浏览器驱动;导入time模块用于计时;导入warnings模块用于消除警告;通过matplotlib相关参数设置中文字体为SimHei,消除坐标轴负号显示问题。
b.创建浏览器驱动

c.定义等待方法的时间列表和名称列表

d.执行搜索并记录时间(循环4次(无等待、强制等待、隐含等待、明确等待))
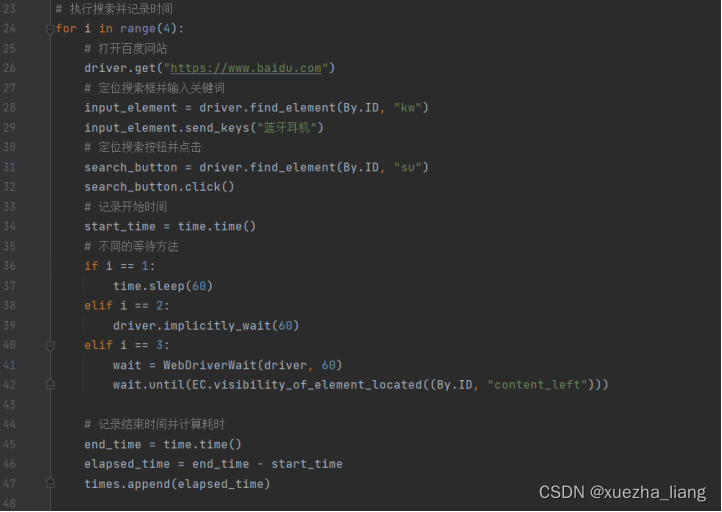
e.关闭浏览器驱动

f.通过matplotlib进行绘图

g.绘图结果
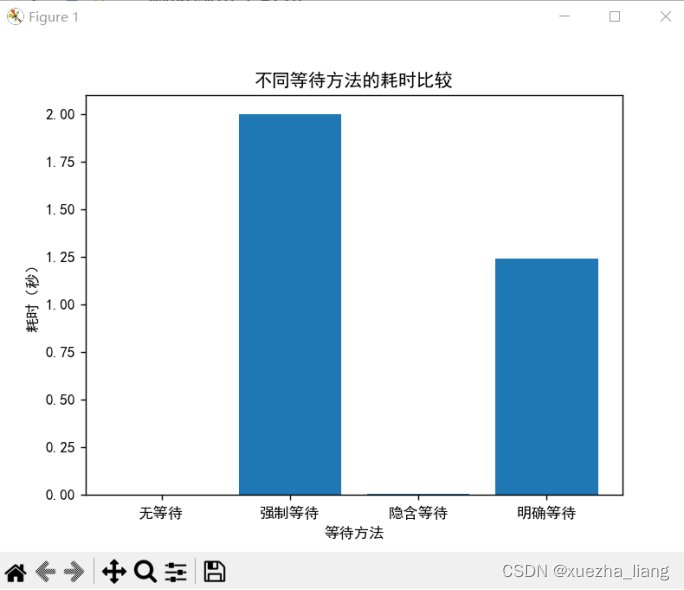
1、等待时间为2秒
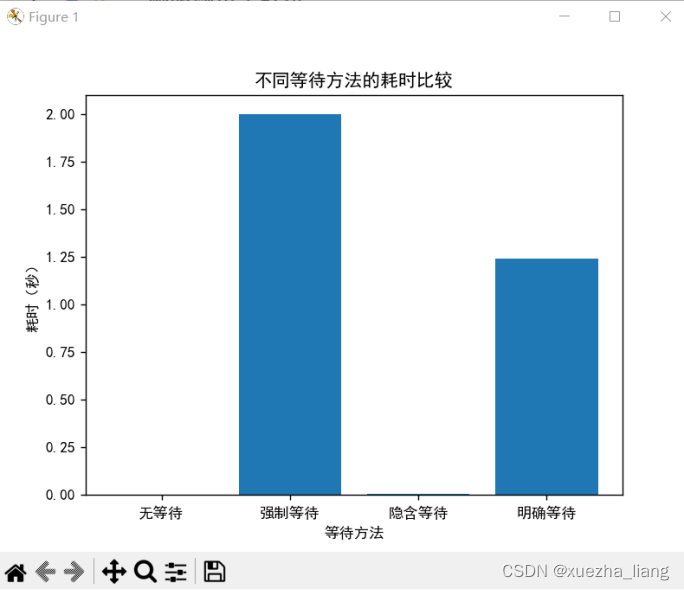
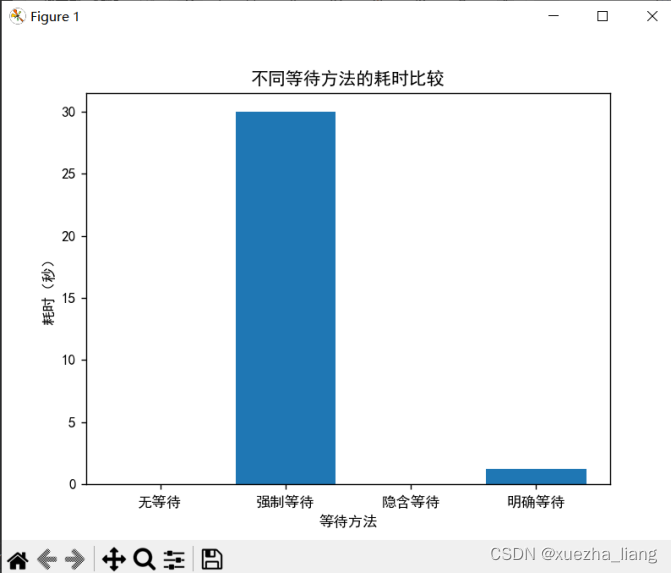
2、等待时间为30秒
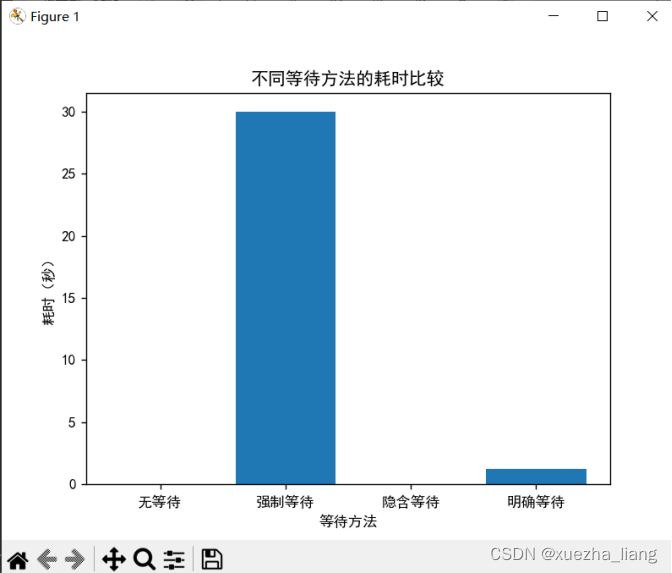
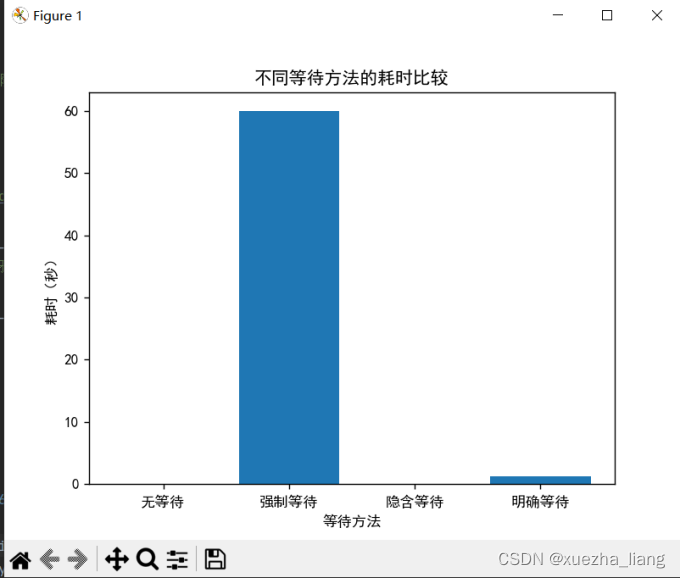
3、等待时间为一分钟(60秒)
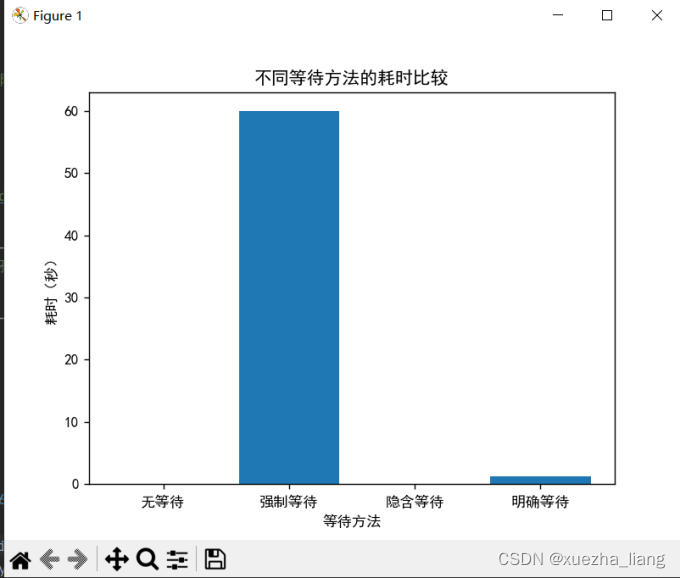
4、实际范例演练https://www.webscrapingpro.tw/what-is-web-scraping/
由于范例中的爬取的网站无法在国内登录,所以我选择更改爬取的网址。
代码思路:通过使用Python的requests库来向特定URL发送HTTP请求,从网页上获取信息。然后,使用BeautifulSoup库对HTML进行解析,提取出所需的信息。最后,将提取到的信息按照CSV格式写入到指定的文件中。
(1)导入所需的库
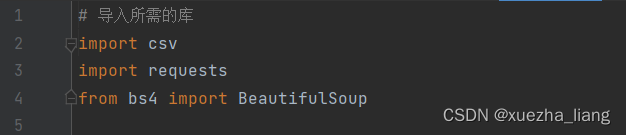
(2)使用BeautifulSoup来解析网页内容
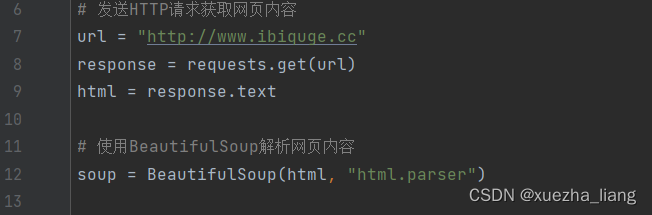
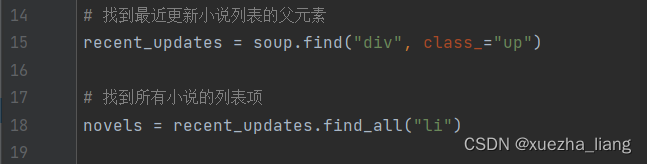
(3)找到最近更新小说列表的父元素和列表项
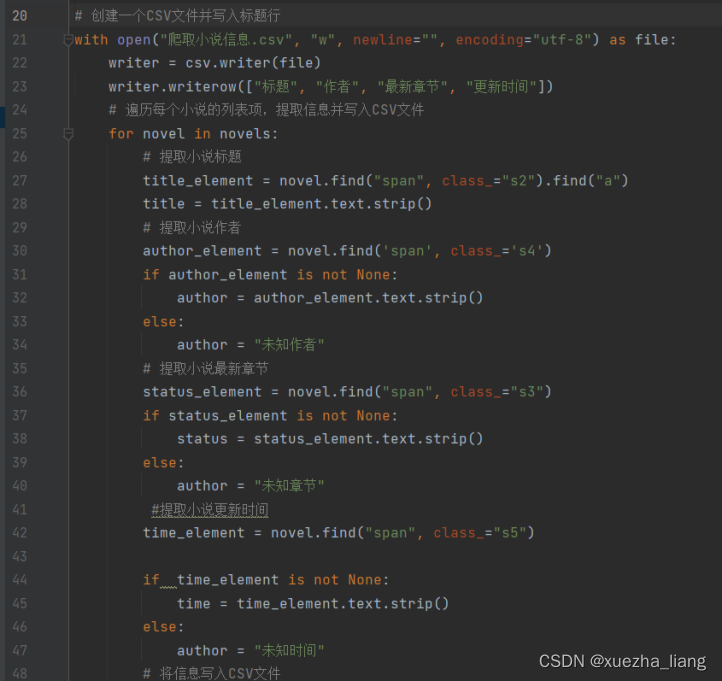
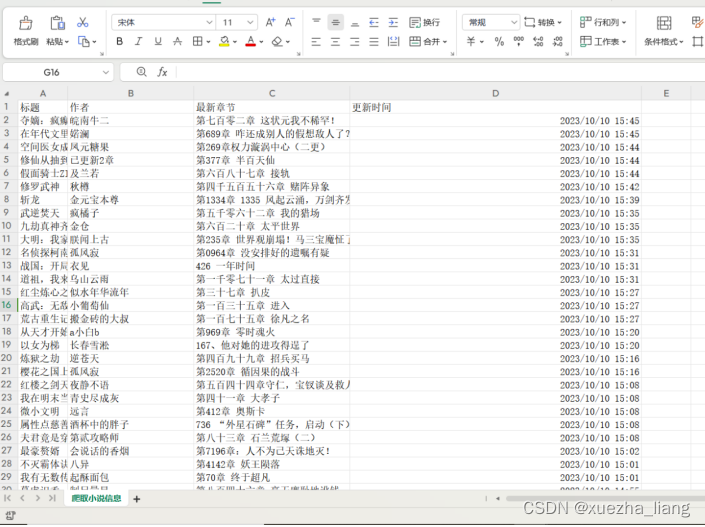
(4)创建csv文件并且写入标题行,遍历每个小说的列表项,提取信息并写入CSV文件

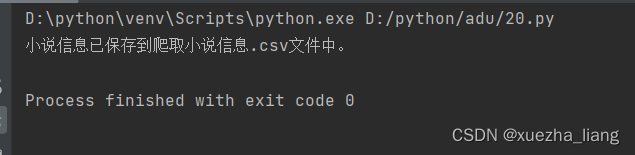
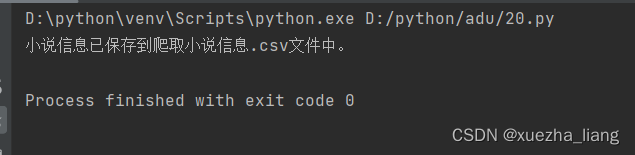
(5)查看csv文件
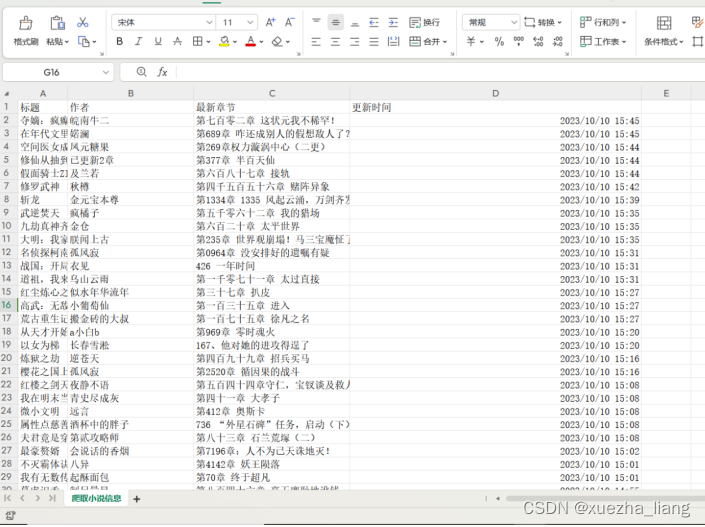
五、实验结果
1、第一题结果截图
a.强制等待运行截图
b.明确等待运行截图
c.隐含等待运行截图
2、第三题结果截图
a.等待时间为2秒
b.等待时间为30秒
c.等待时间为一分钟(60秒)
3、第四题结果截图
六、实验总结
本次实验主要是通过实际的Python动态网页爬虫的例子,来了解三种等待机制:强制等待、隐含等待和明确等待。在实验中,我们使用了selenium库来模拟浏览器操作,以及time库来实现等待功能。
在强制等待中,我们使用time库的sleep方法来暂停程序的执行,等待指定的时间。这种方法简单直接,但是不灵活,等待时间固定,无法根据页面加载情况来调整等待时间。
在隐含等待中,我们使用selenium库的implicitly_wait方法来设置全局的等待时间,等待页面加载完成。这种方法适用于整个测试用例,不需要在每个操作中都添加等待时间,但是只能等待元素可见或不可见,不能精确控制等待的条件和时间。
在明确等待中,我们使用selenium库的WebDriverWait和expected_conditions方法来实现等待功能。这种方法可以根据具体的条件和时间来等待,非常灵活。可以等待元素可见、可点击、存在、消失等多种条件,但是需要在每个等待的操作中明确指定条件和时间,相对来说稍微繁琐一些。
通过比较三种等待机制的优缺点,我们可以得出以下结论:
强制等待(sleep):实现简单,直接暂停程序执行指定的时间,但是不灵活,等待时间固定,无法根据页面加载情况来调整等待时间。
隐含等待(Implicit):全局设置,适用于整个测试用例,不需要在每个操作中都添加等待时间,但是只能等待元素可见或不可见,不能精确控制等待的条件和时间。
明确等待(Explicit):可以根据具体的条件和时间来等待,非常灵活,可以等待元素可见、可点击、存在、消失等多种条件,但是需要在每个等待的操作中明确指定条件和时间,相对来说稍微繁琐一些。
还有,通过跑一支任意程序,针对不同的等待机制连续三次,纪录时间并绘制成图,可以进一步分析不同等待机制的性能差异。
最后,我们通过实例对于网页进行请求,然后抓取所需的内容,最后存储数据。
