

Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标自动调整 Deployment 、ReplicaSet 或 StatefulSet 或其他类似资源,实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适用于无法缩放的对象,例如DaemonSet。
HPA基本原理
Kubernetes 中的 Metrics Server 持续采集所有 Pod 副本的指标数据。HPA 控制器通过 Metrics Server 的 API(Heapster 的 API 或聚合 API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的副本控制器(Deployment、RC 或 ReplicaSet)发起 scale 操作,调整 Pod 的副本数量,完成扩缩容操作。
一、安装 metrics-server
HAP 前提条件
默认情况下,Horizontal Pod Autoscaler 控制器会从一系列的 API 中检索度量值。 集群管理员需要确保下述条件,以保证 HPA 控制器能够访问这些 API:
对于资源指标,将使用 metrics.k8s.io API,一般由 metrics-server 提供。 它可以作为集群插件启动。
对于自定义指标,将使用 custom.metrics.k8s.io API。 它由其他度量指标方案厂商的“适配器(Adapter)” API 服务器提供。 检查你的指标管道以查看是否有可用的 Kubernetes 指标适配器。
对于外部指标,将使用 external.metrics.k8s.io API。可能由上面的自定义指标适配器提供。
Kubernetes Metrics Server:
Kubernetes Metrics Server 是 Cluster 的核心监控数据的聚合器,kubeadm 默认是不部署的。
Metrics Server 供 Dashboard 等其他组件使用,是一个扩展的 APIServer,依赖于 API Aggregator。所以,在安装 Metrics Server 之前需要先在 kube-apiserver 中开启 API Aggregator。
Metrics API 只可以查询当前的度量数据,并不保存历史数据。
Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 下维护。
必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 kubelet Summary API 获取数据。
1.获取yaml文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml -O metrics-server.yaml
- 编辑yaml文件。之前部署集群用的自签名证书,metrics-server直接请求kubelet接口会证书校验失败,因此deployment中增加
- --kubelet-insecure-tls参数。另外镜像原先在registry.k8s.io,国内下载不方便,下面的配置中修改成了国内镜像仓库地址。内网环境中可以先下载,然后再推到内网镜像仓库,镜像也改成内网镜像地址。
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
# image: registry.k8s.io/metrics-server/metrics-server:v0.6.4
image: registry.cn-hangzhou.aliyuncs.com/rainux/metrics-server:v0.6.4
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
metrics-server pod无法启动,出现日志unable to fully collect metrics: … x509: cannot validate certificate for because … it doesn’t contain any IP SANs …
解决方法:在metrics-server中添加–kubelet-insecure-tls参数跳过证
- 发布
kubectl apply -f metrics-server.yaml- 查看是否在运行
root@1nd1009:~# kubectl get pods -n kube-system | grep metrics
metrics-server-5945c955f5-ls5qj 1/1 Running 1 (7d22h ago) 12d
- 获取集群的指标数据
root@1nd1009:~# kubectl get --raw /apis/metrics.k8s.io/v1beta1 | python3 -m json.tool
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "metrics.k8s.io/v1beta1",
"resources": [
{
"name": "nodes",
"singularName": "",
"namespaced": false,
"kind": "NodeMetrics",
"verbs": [
"get",
"list"
]
},
{
"name": "pods",
"singularName": "",
"namespaced": true,
"kind": "PodMetrics",
"verbs": [
"get",
"list"
]
}
]
}
查看 top 命令的帮助
kubectl top –help
查看node节点的资源使用情况
kubectl top node
查看pod的资源使用情况
kubectl top pod
查看所有命名空间的pod资源使用情况
kubectl top pod -A
二、Horizontal Pod Autoscaler 工作原理
原理架构图
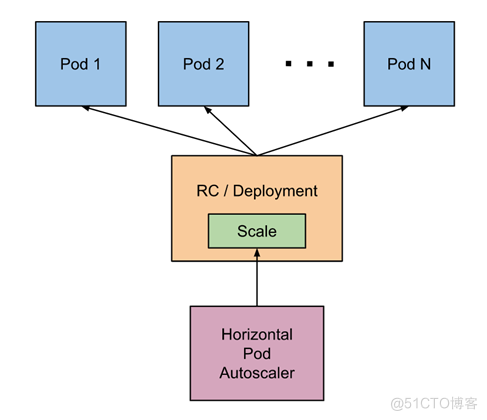
自动检测周期由 kube-controller-manager 的 –horizontal-pod-autoscaler-sync-period 参数设置(默认间隔为 15 秒)。
metrics-server 提供 metrics.k8s.io API 为pod资源的使用提供支持。
15s/周期 -> 查询metrics.k8s.io API -> 算法计算 -> 调用scale 调度 -> 特定的扩缩容策略执行。
2)HPA扩缩容算法
从最基本的角度来看,Pod 水平自动扩缩控制器根据当前指标和期望指标来计算扩缩比例。
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]
1
1、扩容
如果计算出的扩缩比例接近 1.0, 将会放弃本次扩缩, 度量指标 / 期望指标接近1.0。
2、缩容
冷却/延迟: 如果延迟(冷却)时间设置的太短,那么副本数量有可能跟以前一样出现抖动。 默认值是 5 分钟(5m0s)–horizontal-pod-autoscaler-downscale-stabilization
3、特殊处理
丢失度量值:缩小时假设这些 Pod 消耗了目标值的 100%, 在需要放大时假设这些 Pod 消耗了 0% 目标值。 这可以在一定程度上抑制扩缩的幅度。
存在未就绪的pod的时候:我们保守地假设尚未就绪的 Pod 消耗了期望指标的 0%,从而进一步降低了扩缩的幅度。
未就绪的 Pod 和缺少指标的 Pod 考虑进来再次计算使用率。 如果新的比率与扩缩方向相反,或者在容忍范围内,则跳过扩缩。 否则,我们使用新的扩缩比例。
指定了多个指标, 那么会按照每个指标分别计算扩缩副本数,取最大值进行扩缩。
yaml文件
root@1nd1009:~/hpa# cat hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hap-nginx
spec:
maxReplicas: 10 # 最大扩容到10个节点(pod)
minReplicas: 1 # 最小扩容1个节点(pod)
metrics:
- resource:
name: cpu
target:
averageUtilization: 30 # CPU 平局资源使用率达到30%就开始扩容,低于30%就是缩容
# 设置内存
# AverageValue:30
type: Utilization
type: Resource
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hap-nginx
---
apiVersion: v1
kind: Service
metadata:
name: hap-nginx
spec:
type: NodePort
ports:
- name: "http"
port: 80
targetPort: 80
nodePort: 30080
selector:
service: hap-nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hap-nginx
spec:
replicas: 1
selector:
matchLabels:
service: hap-nginx
template:
metadata:
labels:
service: hap-nginx
spec:
containers:
- name: hap-nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 200m
memory: 200Mi
主要参数解释如下:
`scaleTargetRef:目标作用对象,可以是Deployment、ReplicationController或ReplicaSet。
minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个Pod的内存使用率为40%,这个值就是上面设置的阈值averageUtilization。
metrics:目标指标值。在metrics中通过参数type定义指标的类型;通过参数target定义相应的指标目标值,系统将在指标数据达到目标值时(考虑容忍度的区间,见前面算法部分的说明)触发扩缩容操作。
对于CPU使用率,在target参数中设置averageUtilization定义目标平均CPU使用率。
对于内存资源,在target参数中设置AverageValue定义目标平均内存使用值。
执行部署
kubectl apply -f hpa.yaml
检查运作状态
root@1nd1009:~/hpa# kubectl get pod
NAME READY STATUS RESTARTS AGE
hap-nginx-6fc96575f8-r4qg6 1/1 Running 0 82m
查看端口
root@1nd1009:~/hpa# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hap-nginx NodePort 10.99.41.1 80:30080/TCP 93m
使用 ab 工具进行压测
apt-get install apache2-utils -y开始压测
root@1nd1009:~/hpa# ab -n 1000000 -c 100 http://192.168.10.9:30080/index
This is ApacheBench, Version 2.3
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.10.9 (be patient)
apr_socket_recv: Connection refused (111)
Total of 8533 requests completed
#-c:并发数
#-n:总请求数
root@1nd1009:~# kubectl get pod -w | grep hap
hap-nginx-6fc96575f8-2bt46 1/1 Running 0 115s
hap-nginx-6fc96575f8-5f7zx 1/1 Running 0 2m10s
hap-nginx-6fc96575f8-ftq8v 1/1 Running 0 114s
hap-nginx-6fc96575f8-r4qg6 1/1 Running 0 2m10s
hap-nginx-6fc96575f8-tfz9v 1/1 Running 0 13m
已经实现了根据CPU 动态扩容了
