


一、背景
目前实时数仓提供的投放实时指标优先级别越来越重要,特别下游为规则引擎提供的数仓数据,直接对投放运营的广告投放产生直接影响,数据延迟或者异常均可能产生直接或者间接的资产损失;从投放管理平台的链路全景图投放全景图来看,目前投放是一个闭环的运行流程,实时数仓处于数据链路中的关键节点,实时数据直接支持规则引擎的自动化操作,以及投放管理平台的手动控盘;实时节点事故,将可能导致整个投放链路无法正常运行;为使投放链路达到99.9%的稳定性,需要对链路任务做相关的稳定性提升,优先级提升。

研发测试综合评估方案对投放实时链路增加一条备链路,投放需求迭代,通过备链路进行迭代修改,完成修改后进行主备链路Diff,确保Diff通过率99.9%,即可上线。
二、实现方案
-
数据准备:主备链路产出的数据分别实时写入到ODPS中。
-
数据采集:测试工具服务同时采集主备链路数据切片,保留2份同一个时间周期的数据。
-
数据降噪&Diff:工具采集数据后将进行第一步的降噪处理;主备数据开始对比&第二步降噪处理。
-
数据Diff结果:加工数据对比的结果,判断出每个字段的差异量,再最终判断出整体数据的差异量,给出结果。
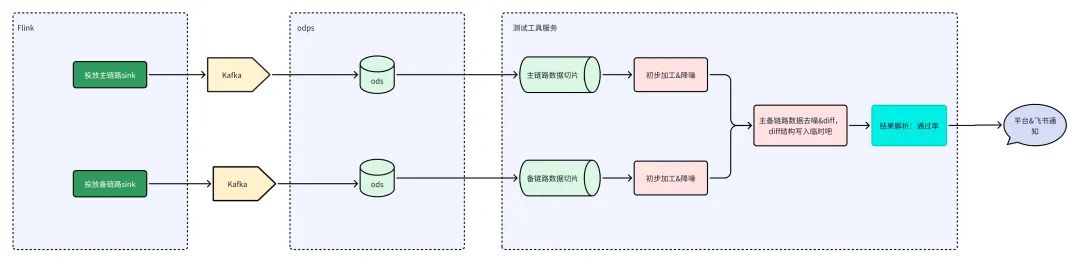
三、搭建主备链路
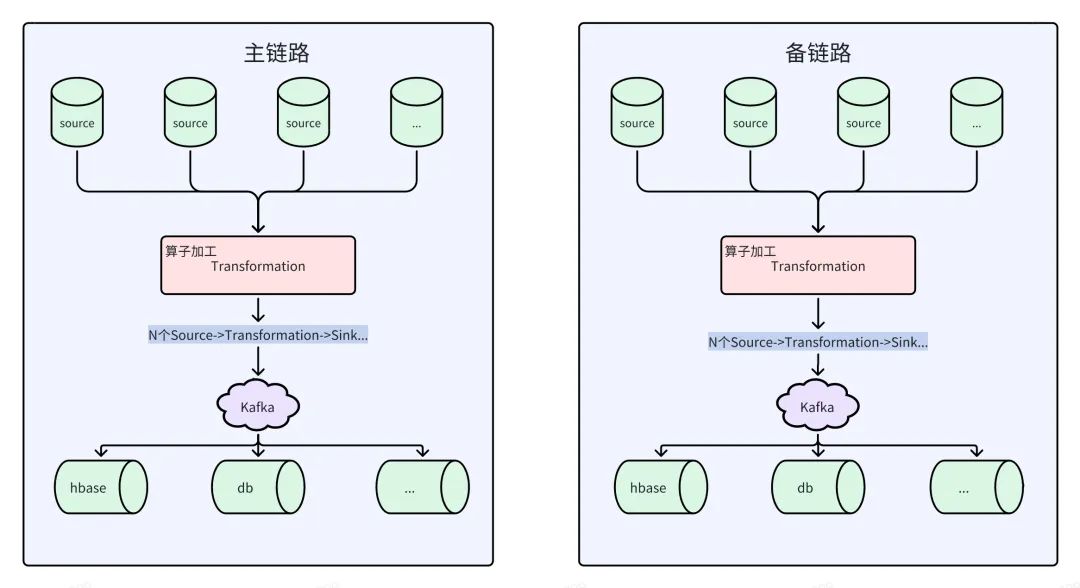
实时链路解释:源头数据写入Kafka,Flink消费Kafka数据作为数据源(Source),结合属性字段做算子加工处理(Transformatin),处理结果写入Kafka(Sink),做下一步处理。经过一个个Flink任务节点加工分流到应用数据库中。
四、数据准备-数据切片
时间窗口切片
根据测试时间点,进行切片,取当天0点~执行时间段数据进行固定,确保数据不再更新。
业务场景切片
不同业务场景迭代进行切片,下发数据流提供多种下游场景数据,针对发生迭代的业务场景数据进行切片固定。如:fields_a=’b’
五、主备链路数据Diff-去噪
数据漂移问题
问题现象:数据流在不断更新,同一条业务数据的数据流更新的最新的一条,主链路可能进入当天分区中,备链路可能进入到第二天分区中。
去噪方案:数据流取末尾1条数据。
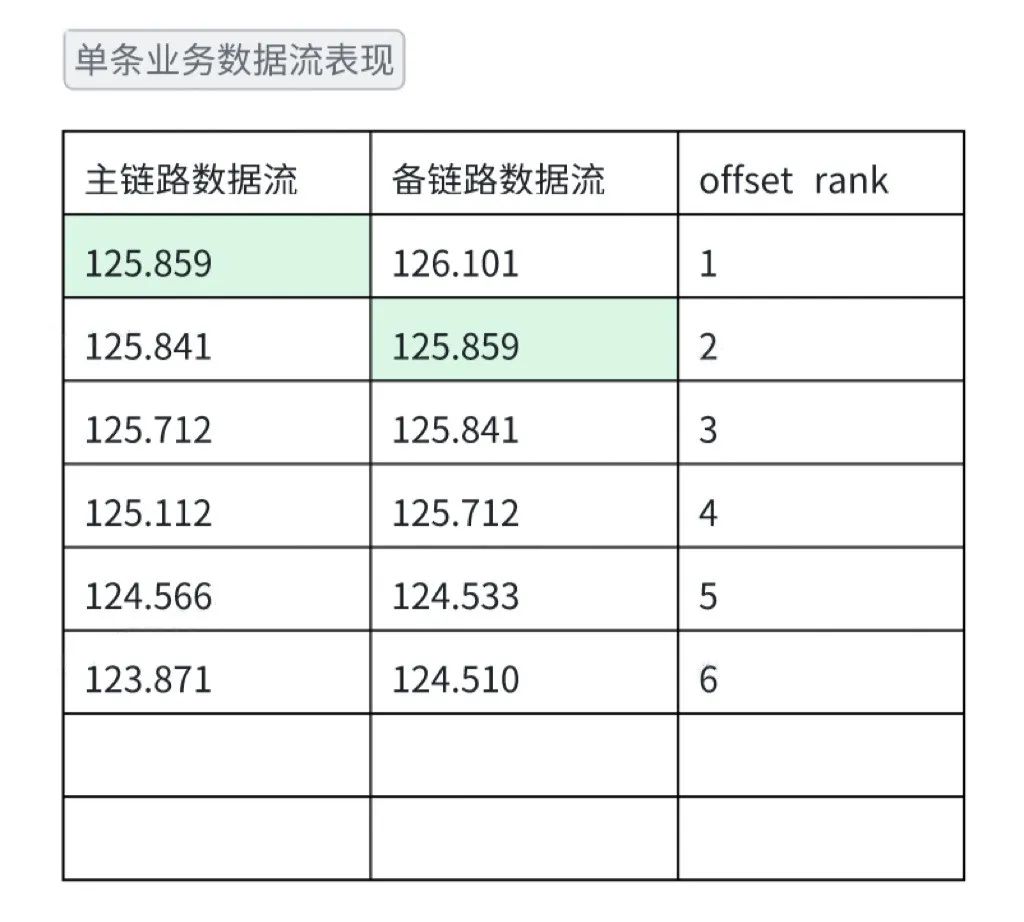
数据更新频率问题
问题现象:同一条业务数据在更新过程中,主链路可能发生了10次更新,后面五次数据不发生改动,备链路只发生了5次更新。
去噪方案:同一个业务数据取数据流的N条数据。
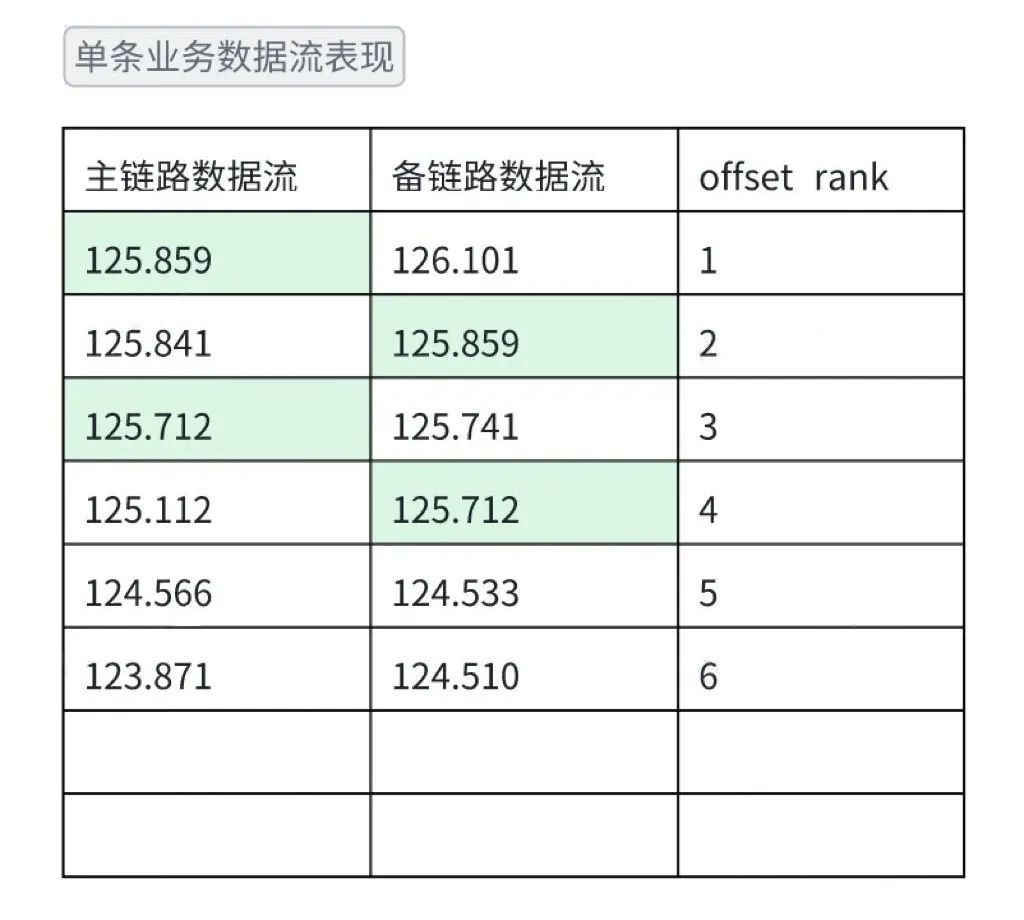
数据更新时效问题
问题现象:同一条业务数据更新过程中,主链路更新三个数据为11.68、12.9、13.05;备链路更新三个数据为11.68、12.9、13.1;可以看出后面1次更新的数据并不一样。
去噪方案:同一个业务数据的数据流融合成一个list,主备相互判断末尾数据是否存在于对方截取的数据流list中。
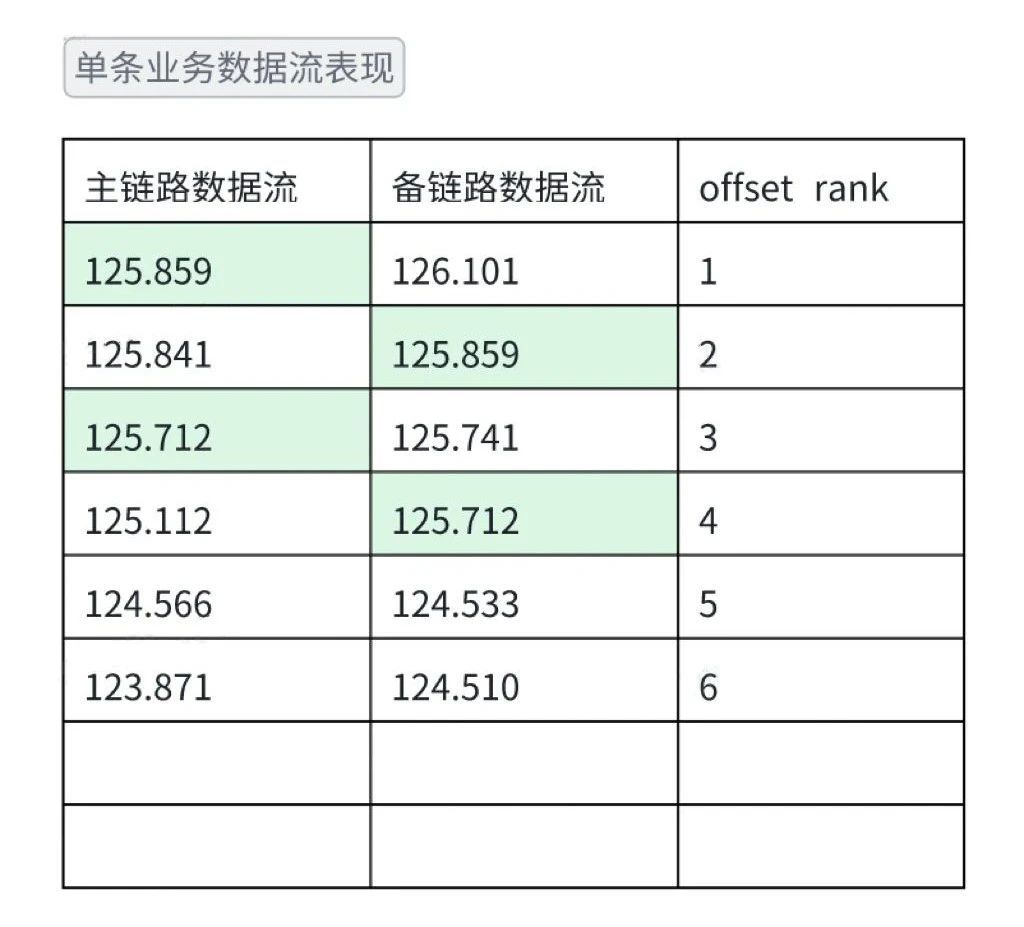
属性字段值不统一问题
问题现象:存在空字符和null、0和0.0的情况,Diff结果为不通过,实际业务含义是OK的。
去噪方案:统一转换后进行Diff。
主备链路message字段解析属性字段不一致问题
问题现象:message字段存储数据JSON格式。同一条业务数据,主备链路解析的JSON对应的属性字段并不是完全一致的,两者之间存在差异。
去噪方案:通过代码解析出全量的属性字段,确保可以完全Diff。
message范本:
{"fields_a":"20230628","fields_b":"2023-06-22 19:48:24","fields_c":"2","fields_d":"plan","fields_e":"3******","fields_f":"0.0","fields_g":"2","fields_h":"4*****","fields_i":"ext","fields_j":"binlog+odps","fields_k":"2","fields_l":"STATUS_*****","fields_m":"1********","fields_n":"孙**","fields_o":"2023-06-28T22:19:43.872"}
转换JSON:
{
"fields_a": "20230717",
"fields_d": "plan",
"fields_e": "3******",
"fields_aj": "33761.125",
"fields_p": "37934.0",
"fields_r": "1250.412",
"fields_s": "1250.412",
"fields_t": "33761.125",
"fields_w": "33761.125",
"fields_m": "1*********",
"fields_v": "33761.125",
"fields_y": "33761.125",
"fields_n": "孙**",
"fields_z": "1250.412",
"fields_ai": "27",
"fields_ak": "",
"fields_aa": "33761.125",
"fields_ab": "33761.125",
"fields_ac": "33761.0",
"fields_al": "0.1002",
"fields_i": "***",
"fields_j": "***",
"fields_k": "2",
"fields_ad": "1.0",
"fields_ak": "37934.0",
"fields_x": "1250.412",
"fields_y": "0.0",
"fields_ag": "27",
"fields_af": "27",
"fields_ah": "0.0",
"fields_al": "0.0",
"fields_am": "0.0",
"fields_ao": "37934.0",
"fields_ap": "37934.0",
"fields_an": "33761.125",
"fields_aq": "1*********",
"fields_ae": "27",
"fields_o": "2023-07-17T23:59:00.103",
"fields_ar": "0.1002"
}
以上五点问题可以通过SQL进行去噪,整体去噪SQL范本如下:
SET odps.sql.mapper.split.size = 64;
SET odps.stage.joiner.num = 4000;
SET odps.stage.reducer.num = 1999;
CREATE TABLE table_diff AS
SELECT a.fields_as AS fields_as_main
,b.fields_as AS fields_as_branch
,a.fields_at AS fields_at_main
,b.fields_at AS fields_at_branch
,a.fields_d AS fields_d_main
,b.fields_d AS fields_d_branch
,a.fields_i AS fields_i_main
,b.fields_i AS fields_i_branch
,a.fields_j AS fields_j_main
,b.fields_j AS fields_j_branch
,a.fields_aw AS fields_aw_main
,b.fields_aw AS fields_aw_branch
,a.fields_k_json_key AS fields_k_json_key_main
,b.fields_k_json_key AS fields_k_json_key_branch
,a.fields_k_json_key_list AS fields_k_json_key_list_main
,b.fields_k_json_key_list AS fields_k_json_key_list_branch
,CASE WHEN a.fields_k_json_key = b.fields_k_json_key THEN 0
WHEN b.fields_k_json_key_list RLIKE a.fields_k_json_key THEN 0
WHEN a.fields_k_json_key_list RLIKE b.fields_k_json_key THEN 0
ELSE 1
END AS fields_k_json_key_diff_flag
FROM (
SELECT fields_as
,fields_at
,fields_d
,fields_i
,fields_j
,fields_aw
,MAX(CASE WHEN rn = 1 THEN fields_k_json_key END) AS fields_k_json_key
,CONCAT_WS(',',COLLECT_SET(fields_k_json_key)) AS fields_k_json_key_list
FROM (
SELECT *
,CASE WHEN NVL(GET_JSON_OBJECT(message,'$.fields_k'),'') = '' THEN '---'
WHEN GET_JSON_OBJECT(message,'$.fields_k') IN ('0','0.0') THEN '0-0-0'
ELSE GET_JSON_OBJECT(message,'$.fields_k')
END AS fields_k_json_key
,ROW_NUMBER() OVER (PARTITION BY fields_as,fields_at,fields_d,fields_i,fields_j,fields_aw ORDER BY offset DESC ) AS rn
FROM table_main
WHERE pt = 20230628
-- AND fields_i = 'realMetric'
)
WHERE rn
字段去噪问题
问题现象:涉及字段逻辑修改的情况下,Diff结果是不通过的,影响Diff结果。
去噪方案:需要对逻辑修改的字段抛弃,不再判断发生逻辑修改的字段,通过Java灵活控制。
String[] jsonColumnListStrings = jsonColumnList.split(",");
List jsonColumnLists = new ArrayList();
String[] iterationColumnStrings = iterationColumn.split(",");
List iterationColumnLists = Arrays.asList(iterationColumnStrings);
for (String s:jsonColumnListStrings){
if(!iterationColumnLists.contains(s)){//判断字段是否为去噪字段
jsonColumnLists.add(s);
}
}

六、Diff结果分析
根据主备Diff合成的SQL可以产出对比的结果表,对执行结果分析既可以判断本次执行是否通过。
分析逻辑1:判断每一个对比字段通过占比
提供研发分析哪一个解析的字段通过率低.
分析逻辑2:判断所有字段通过占比总记录数
此指标即可判断本次Diff是否通过,如果占比99.9%,表示通过。
分析SQL样本:
SELECT round(SUM(CASE WHEN fields_k_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS fields_k_ratio
,round(SUM(CASE WHEN fields_m_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS fields_m_ratio
,round(SUM(CASE WHEN fields_e_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS fields_e_ratio
,round(SUM(CASE WHEN fields_a_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS fields_aratio
,round(SUM(CASE WHEN fields_n_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS fields_n_ratio
,round(SUM(CASE WHEN fields_p_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS fields_p_ratio
,round(SUM(CASE WHEN fields_ac_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS fields_ac_ratio
,round(SUM(CASE WHEN fields_ar_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS fields_ar_ratio
,round(SUM(CASE WHEN fields_k_json_key_diff_flag = 0 AND fields_m_json_key_diff_flag = 0 AND fields_e_json_key_diff_flag = 0 AND fields_a_json_key_diff_flag = 0 AND fields_n_json_key_diff_flag = 0 AND fields_p_json_key_diff_flag = 0 AND fields_ac_json_key_diff_flag = 0 AND fields_ar_json_key_diff_flag = 0 THEN 1 ELSE 0 END) / COUNT(1) * 100,4) AS total_ratio
,COUNT(1) AS total_cnt
FROM table_diff
;
七、工具服务化
后端服务化处理逻辑
主备对比SQL合成
将Diff的SQL植入到代码中,通过代码控制数据切片、去噪等场景,完成测试SQL合成。
for(String s:jsonColumnLists){
selectSql1 = selectSql1 + " case when NVL(GET_JSON_OBJECT(message,'$." + s + "'),'')='' then '---' when get_json_object(message,'$." + s + "') in ('0','0.0') then '0-0-0' else get_json_object(message,'$." + s + "') end AS " + s + "_json_key,";
selectSql2 = selectSql2 + " max(case when rn =1 then " + s + "_json_key end) as " + s + "_json_key,concat_ws(',',collect_set(" + s + "_json_key)) as " + s + "_json_key_list,";
mergeSql = mergeSql + " a." + s + "_json_key as " + s + "_json_key_main,b." + s + "_json_key as " + s + "_json_key_branch,a." + s + "_json_key_list as " + s + "_json_key_list_main,b." + s + "_json_key_list as " + s + "_json_key_list_branch,case when a." + s + "_json_key = b." + s + "_json_key then 0 when b." + s + "_json_key_list rlike a." + s + "_json_key then 0 when a." + s + "_json_key_list rlike b." + s + "_json_key then 0 else 1 end as " + s + "_json_key_diff_flag,";
}
rowNumberSql ="ROW_NUMBER() OVER (PARTITION BY fields_as,fields_at,fields_d,fields_i,fields_j,fields_aw ORDER BY offset DESC ) AS rn ";
selectSql1 = selectSql1 + rowNumberSql;
whereSql1 = whereSql1 + bizdate + " AND fields_i = 'realMetric' ";
String pretreatmentSqlMain = "";
String pretreatmentSqlBranch = "";
pretreatmentSqlBranch = selectSql2.substring(0,selectSql2.length()-1) + " from(" + selectSql1 + " from " + branchLinkTableName + whereSql1 + ")" + whereSql2 + groupSql.substring(0,groupSql.length()-1);
pretreatmentSqlMain = selectSql2.substring(0,selectSql2.length()-1) + " from(" + selectSql1 + " from " + masterLinkTableName + whereSql1 + ")" + whereSql2 + groupSql.substring(0,groupSql.length()-1);
mergeSql = mergeSql.substring(0,mergeSql.length()-1) + " from (" + pretreatmentSqlMain + ")a left join (" + pretreatmentSqlBranch + ")b " + joinSql.substring(0,joinSql.length()-3) + ";";
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMddHHmmss");
String dateStr = simpleDateFormat.format(new Date());
this.resultDataCreateSql = "set odps.sql.mapper.split.size=64;set odps.stage.joiner.num=4000;set odps.stage.reducer.num=1999; create table du_temp.diff_main_branch_" + dateStr + "_test as " + mergeSql;
log.info(resultDataCreateSql);
this.resultDataTable = "du_temp.diff_main_branch_" + dateStr + "_test";
log.info(resultDataTable);
//合成过滤结果数据的sql
String resultSql = " select ";
String totalResultSql = "round(sum(case when ";
for(String s:jsonColumnLists){
resultSql = resultSql + " round(sum(case when " + s + "_json_key_diff_flag = 0 then 1 else 0 end)/count(1)*100,4) as " + s + "_ratio,";
totalResultSql = totalResultSql + " " + s + "_json_key_diff_flag = 0 and";
}
this.resultDataFiltrate = resultSql + totalResultSql.substring(0,totalResultSql.length()-3) + " then 1 else 0 end)/count(1)*100,4) as total_ratio , count(1) as total_cnt from " + this.resultDataTable + ";";
log.info(resultDataFiltrate);
Diff结果报告解析
...}
else if(testType.equals("主备diff")) {
for (Map.Entry entry:testResultRecord.entrySet()) {
List listValue = (List) entry.getValue();
this.resultData.put(entry.getKey().toString(),listValue.get(0)) ;
if(Double.parseDouble(listValue.get(0))0){
this.testStatus = "失败";
}else {
this.testStatus = "成功";
}
}
平台可视化
- 创建任务

- 执行列表

- 结果报告-平台展示
如下图:一次执行失败的结果,通过率为99.8471,未达到99.99%。
- 结果报告-飞书通知
如下样例:
执行需求名称:主备Diff-521 执行者:*** 执行类型:主备Diff 执行编号:20230628204636 执行备链路表名:table_main 执行主链路表名:table_branch 执行备链路表分区:20230628 执行结果明细表:table_diff 执行结果明细汇总: fields_am_ratio:99.9958 fields_z_ratio:99.9826 fields_af_ratio:99.9856 fields_ba_ratio:99.9964 fields_al_ratio:99.9915 fields_ad_ratio:99.9873 fields_r_ratio:99.9826 fields_aa_ratio:99.9906 fields_ai_ratio:99.9856 fields_v_ratio:99.9917 fields_ak_ratio:99.9909 fields_m_ratio:99.9969 fields_ak_ratio:99.9945 fields_bb_ratio:99.9964 fields_bc_ratio:99.9957 fields_bd_ratio:99.9954 fields_ae_ratio:99.9856 fields_be_ratio:99.9952 fields_bf_ratio:99.9955 fields_t_ratio:99.9917
fields_ag_ratio:99.9856 fields_p_ratio:99.9909 fields_bg_ratio:99.9948 fields_a_ratio:99.9969 fields_d_ratio:99.9969 fields_x_ratio:99.9826 fields_an_ratio:99.9917
fields_ap_ratio:99.9909 fields_ar_ratio:99.9915 fields_y_ratio:99.9917 fields_bh_ratio:99.9955 fields_aj_ratio:99.9916 fields_bi_ratio:99.987 fields_ac_ratio:99.9908 fields_s_ratio:99.9826 fields_ab_ratio:99.9906 fields_i_ratio:99.9969 fields_bj_ratio:99.9951 fields_ah_ratio:99.9959
fields_k_ratio:99.9969
fields_e_ratio:99.9969 fields_bk_ratio:99.9962 fields_bl_ratio:99.8748 fields_al_ratio:99.9958 fields_j_ratio:99.9969
fields_bm_ratio:99.9951 fields_n_ratio:99.9969 fields_ao_ratio:99.9909 fields_w_ratio:99.9906 fields_bn_ratio:99.9965 fields_bo_ratio:99.9912 fields_bcrate_ratio:99.987 fields_y_ratio:99.9958 主备diff执行结果汇总数据: total_ratio:99.8471
total_cnt:714259 执行结果失败明细:
fields_bl_ratio:99.8748
total_ratio:99.8471% 执行结果状态:失败
八、主备diff工具接入发布流程
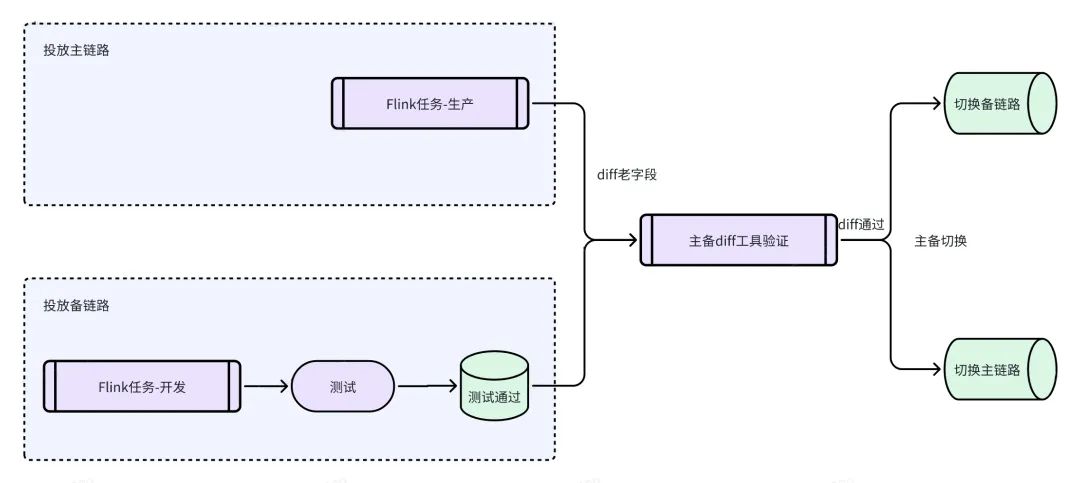
投放备链路最终经过主备Diff工具测试通过的情况下,完成上线,目前相当于一条备用生产线。
后续版本迭代,需求上线前通过Diff工具验证通过,即可符合上线要求。
九、总结
实时计算不同于离线数仓,数据的稳定性和准确性很难把控,复杂的链路通过简单的测试无法保障整体数据的质量,双链路Diff的形式可以在迭代中更好保障实时数据的质量。
对于主备Diff的实现中:最大的痛点往往是数据的噪点非常的大,需要通过技术手段进行降噪,确保数据对比结果的准确性和可靠性。
*文/诗雨
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!
