本篇文章对mysql表的增删查改进行了详细的举例说明解释。对表的增删查改简称CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)。其中重点是对查询select语句进行了详细解释,并且通过多个实际例子来帮助你的理解。希望本篇文章会对你有所帮助。
文章目录
一、表的插入
1、1 指定列插入 和 多行数据插入
1、2 全列插入
1、3 插入选择更新
1、4 替换数据
二、表中的数据查询
2、1 select 语句
2、1、1 全列查询
2、1、2 指定列查询
2、1、3 查询字段为表达式
2、1、4 为查询结果列指定别名
2、1、5 对查询结果去重
2、2 where 语句
2、2、1 where语句简单说明
2、2、2 实例练习
2、3 对查询结果进行排序
2、3、1 升序排序
2、3、2 降序排序
2、3、3 按照多列进行排序
2、4 对筛选的结果进行分页
三、表的数据更新
四、表的数据删除
4、1 delete 删除数据
4、2 truncate 截断表
五、group by 与 聚合函数
5、1 聚合函数
5、2 group by语句
🙋♂️ 作者:@Ggggggtm 🙋♂️
👀 专栏:MySQL 👀
💥 标题:MySQL 表的增删查改💥
❣️ 寄语:与其忙着诉苦,不如低头赶路,奋路前行,终将遇到一番好风景 ❣️
一、表的插入
1、1 指定列插入 和 多行数据插入
我们向在表中指定的一行或者多行插入,怎么做呢?我们有如下表:
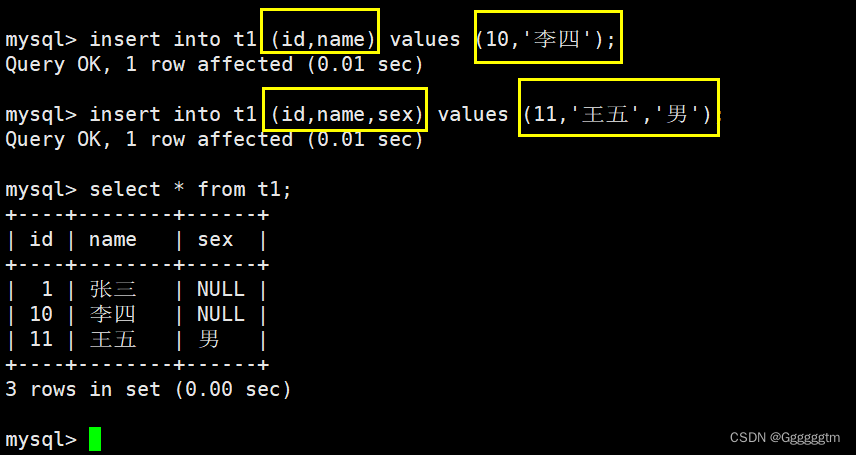
我们现在直插入name的一列,只需要指定要插入的列名称即可。如下图:
我们也可以进行多列进行插入,如下图实例:
但是前提是我们必须满足约束条件,正常插入都是可以的。

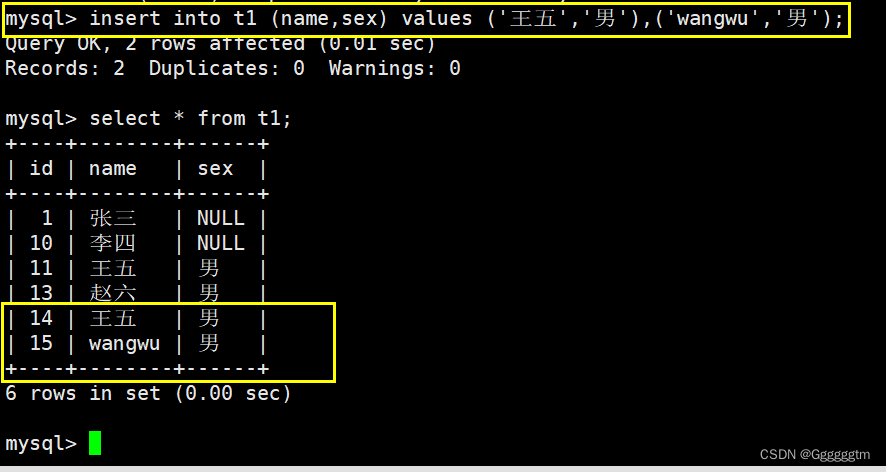
我们也可以一次性插入多行数据,具体示例如下:
从上图也可以很好的看出来,多行插入就是将数据用 ‘,’ 进行隔开即可。
1、2 全列插入
上述情况中讲述了指定列进行插入。当对全列进行插入时,可以不指定对应的列,此时默认的就是全列插入。具体如下图:
当然全列插入也可以显式指定的列名称,一般情况下都是默认省去的。

1、3 插入选择更新
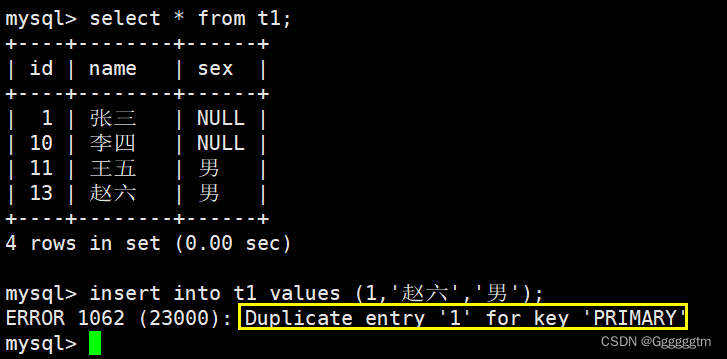
当我们在插入数据时,可能会遇到主键约束或者唯一键约束,从而限制了插入操作。具体如下图:
上图就是出先了主键约束,导致插入失败。但是我们就想以最新的这一条为最终数据,且要求能够插入进去,该怎么办呢?这时可以选择性的进行同步更新操作,语法如下:
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...我们来看一个具体的实际例子:
结合上述的实例,这里简单说名一下:
- UPDATE后面的 column=value,表示当插入记录出现冲突时需要更新的列值;
- 当插入记录并没有冲突时,就不会执行update更新语句,也就是直接插入。
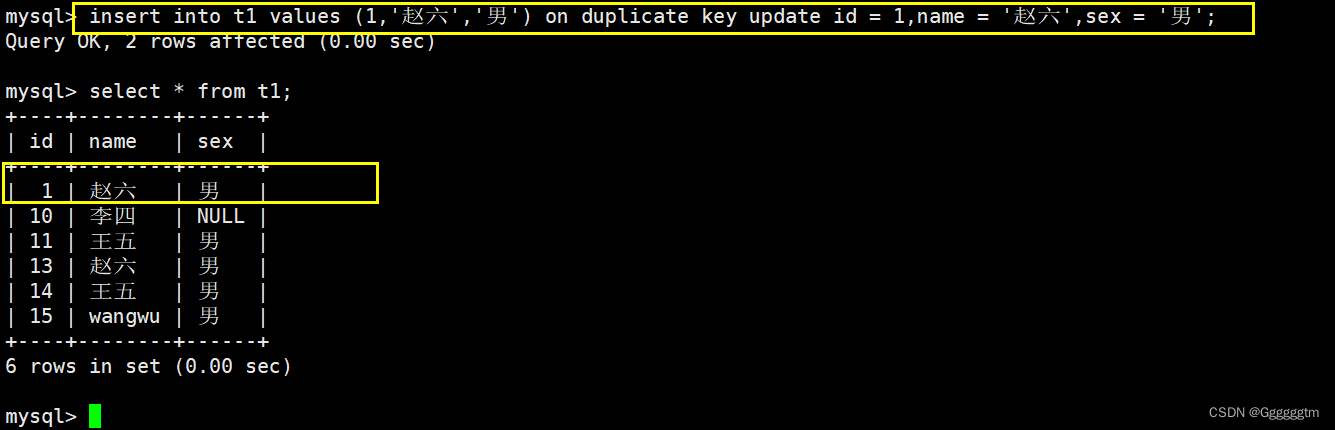
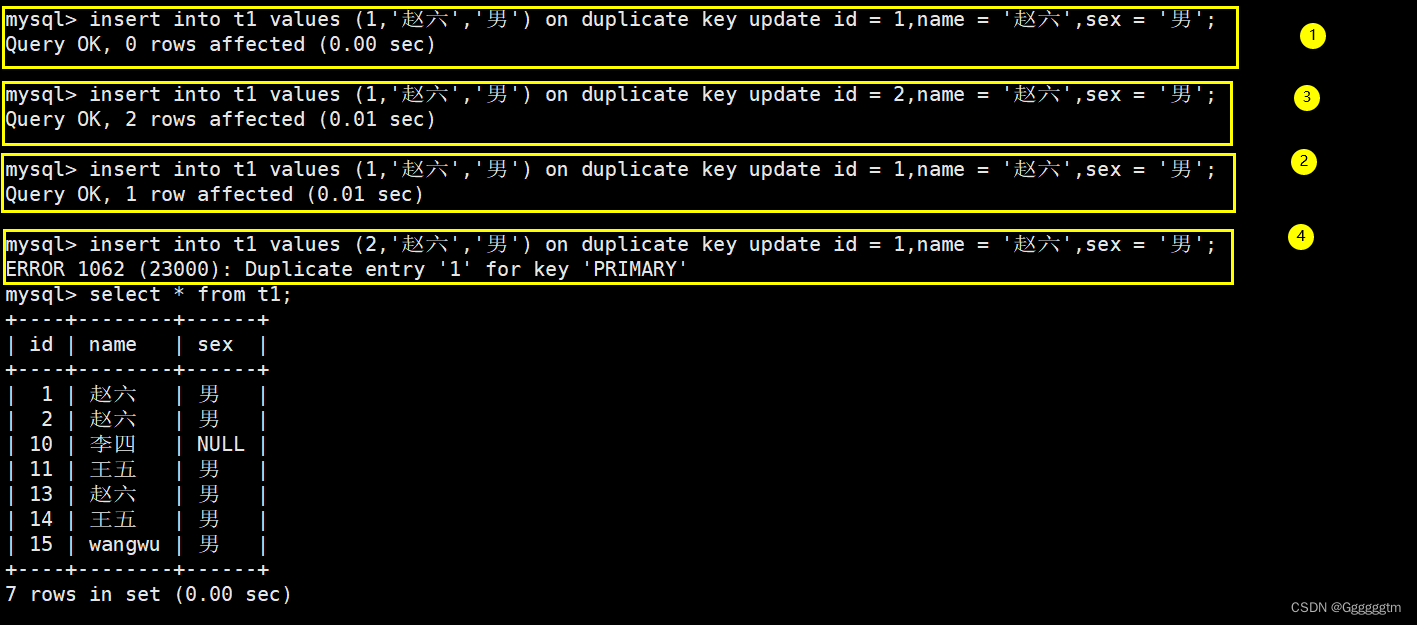 根据上图,我们再来总结一下:
根据上图,我们再来总结一下:
- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等;
- 1 row affected: 表中没有冲突数据,数据被插入;
- 2 row affected: 表中有冲突数据,并且数据已经被更新;
- 如产生数据冲突,且要求更新后的值不能再次产生冲突,否则会更新失败。
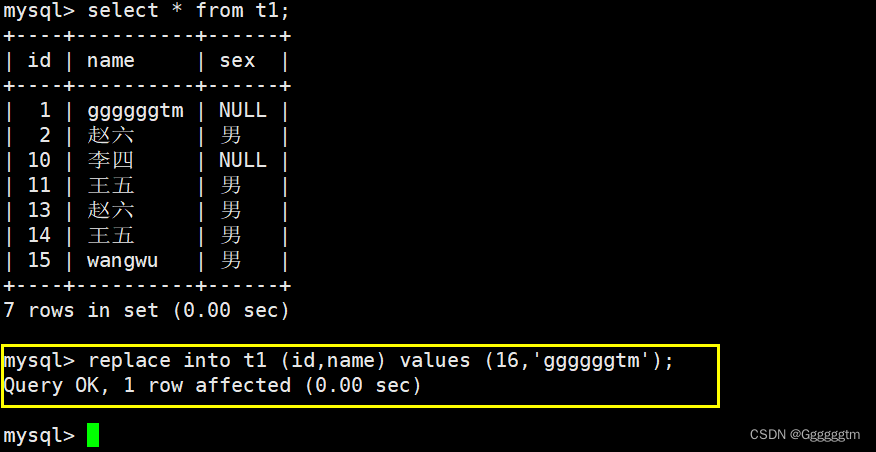
1、4 替换数据
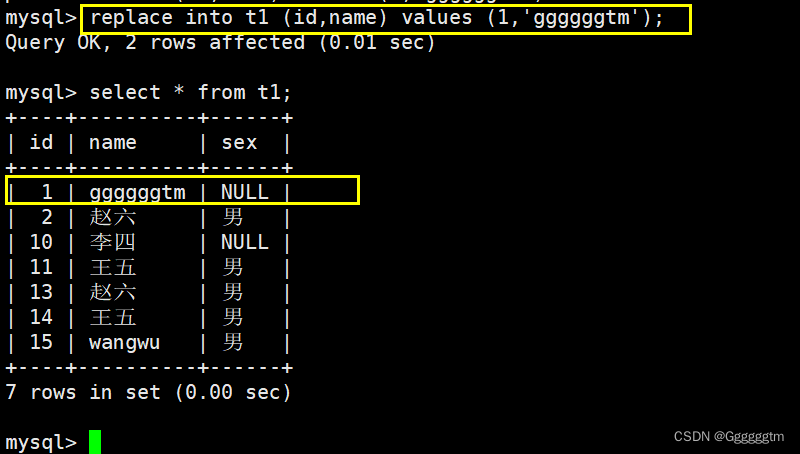
替换数据与插入和更新数据有点类似。我们直接来看一个实例:
我们再来对替换进行简单的总结一下:
- 如果表中没有冲突数据,则直接插入数据。
- 如果表中有冲突数据,则先将表中的冲突数据删除,然后再插入数据。
从上图中可以看到,有2 rows affected。说明表中有冲突数据,冲突数据被删除后重新插入。我们在如下实例:
我们再来总结一下,可以通过受影响的数据行数来判断本次数据的插入情况:
- 1 row affected:表中没有冲突数据,数据直接被插入。
- 2 rows affected:表中有冲突数据,冲突数据被删除后重新插入。
二、表中的数据查询
2、1 select 语句
select语法如下:
SELECT [DISTINCT] {* | {column [, column] ...} [FROM table_name] [WHERE ...] [ORDER BY column [ASC | DESC], ...] LIMIT ...说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- { }中的 | 代表可以选择左侧的语句或右侧的语句。
下面我们将会对select进行逐步分析讲解。
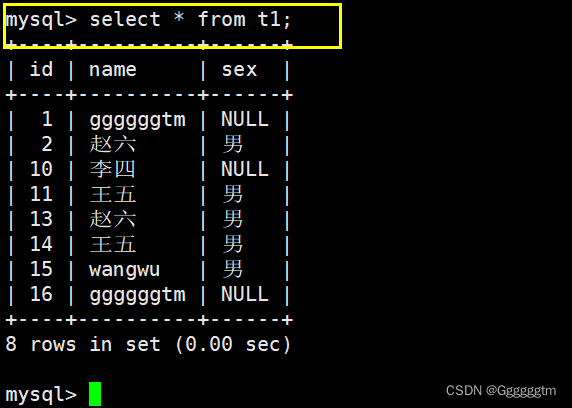
2、1、1 全列查询
全列查询就是将表中的所有数据查询出来。其实在上面我们也一直在用。具体也可看下图理解:
上图中的 * 代表了所有的列,也就是全列查询。但是通常情况下不建议使用 * 进行全列查询
- 查询的列越多,意味着需要传输的数据量(查询到的数据需要通过网络从MySQL服务器传输到本主机)越大;
- 可能会影响到索引的使用。
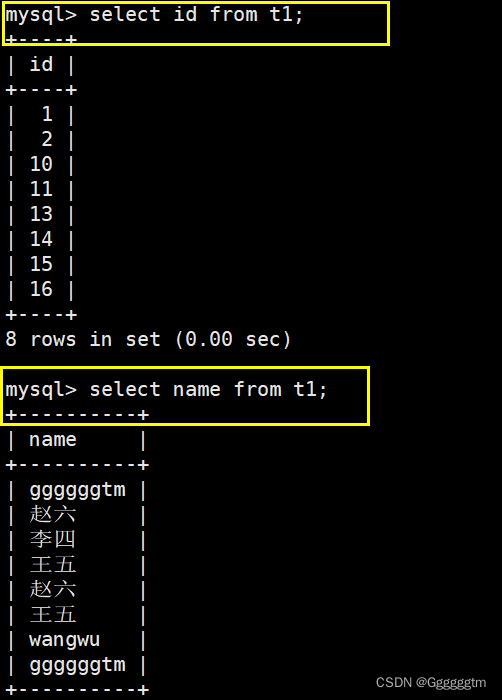
2、1、2 指定列查询
我们也可以指定列进行查询,具体如下图:
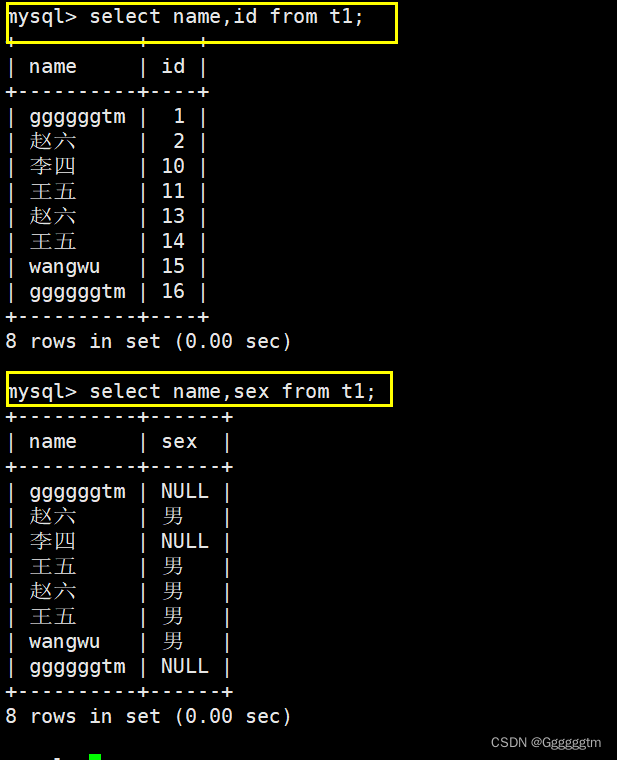
同时我们也可以指定多列,也不需要按照创建表的顺序来查找。具体如下:
2、1、3 查询字段为表达式
select后面不仅仅可以跟字段属性或者子句,也可以跟表达式。我们看如下图:
如上图所示,select后表达式中可以包含常量,比如数字或字符串。可以进行基本的数学运算,如加法、减法、乘法和除法。但是我们主要注意的是,NULL并不参与任何运算。
我们再看如下例子:
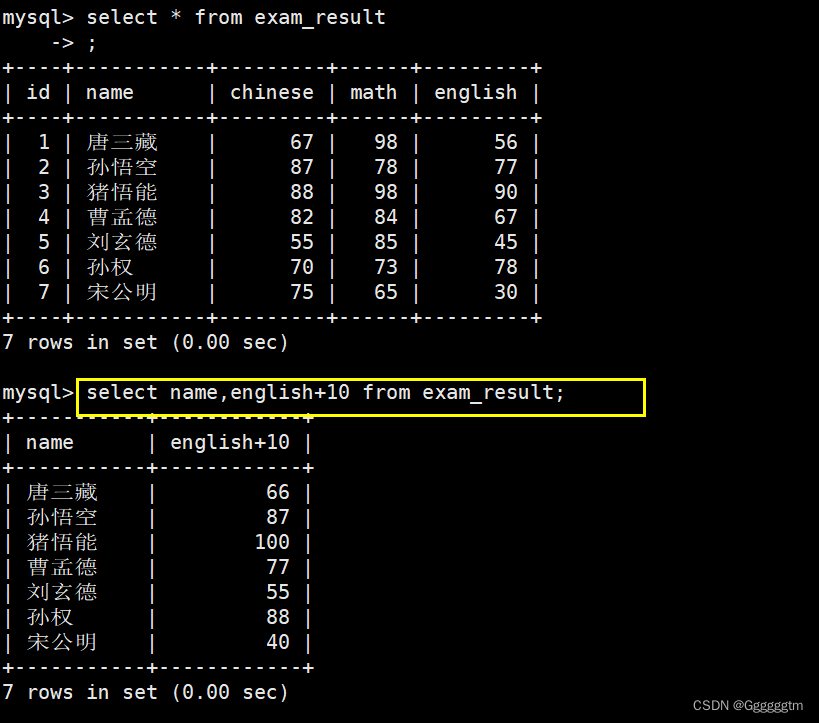
上图中的english+10是对所查到的english成绩进行了加10操作,这里不要理解错误了。我们再看如下例子:
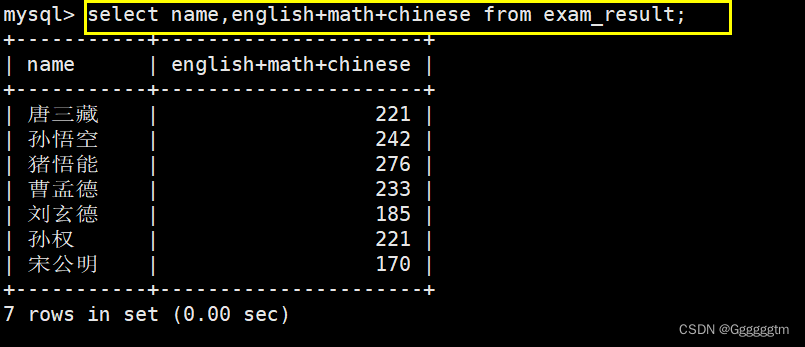
上图的SQL语句中,我们主要是对三项成绩进行的相加,也就是我们平常所需的总成绩。
2、1、4 为查询结果列指定别名
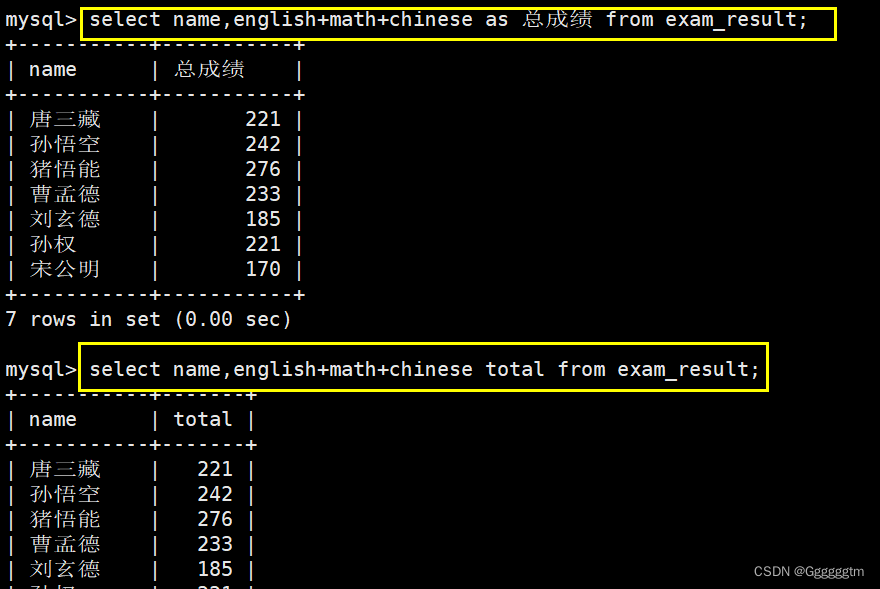
在上述的总成绩中,我们不难看出总成立的列明太长了,而且意思表达的也不明确。在我们查询中,就可以为查询的结果列指定别名。语法如下:
SELECT column [AS] alias_name [...] FROM table_name;具体实例如下图:
上图中我们写出了两种方法,其实是一种:as 可以省去。我们只需要将别名跟在我们所查询的列名后即可。
2、1、5 对查询结果去重
有时候我们所查出来的数据会有大量的重复,然而我们并不需要这样的结果。而是想直接查看去重后的结果。具体如下图:
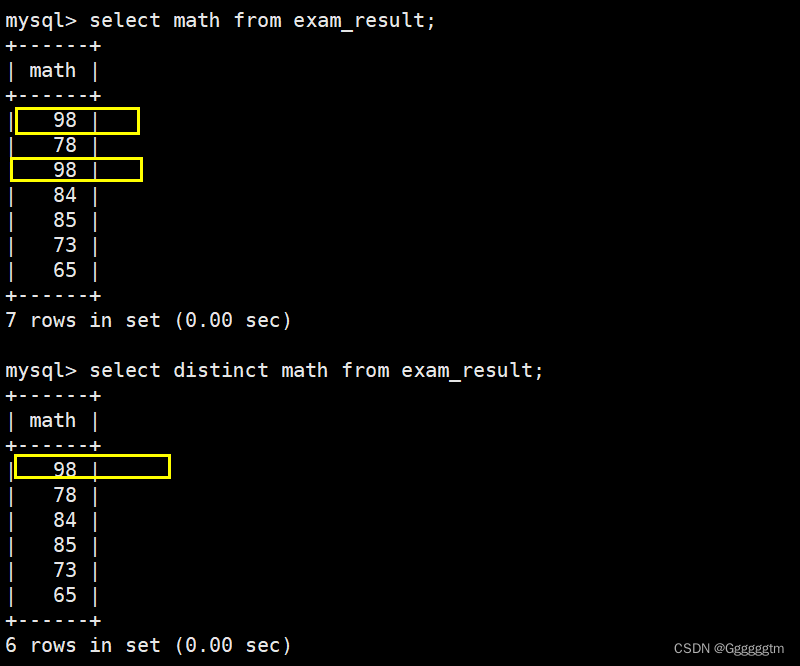
2、2 where 语句
2、2、1 where语句简单说明
在MySQL中,select语句用于从数据库表中检索数据。where子句用于筛选select语句的结果集,只返回满足特定条件的行。以下是对where子句的一些常见用法和详解:
- 选择特定列:WHERE子句通常与列名一起使用,用于筛选特定列的数据。
- 比较运算符:WHERE子句可以使用各种比较运算符(如等于(=)、不等于(!=)、大于(>)、小于(=)和小于或等于(
- 逻辑运算符:WHERE子句还可以使用逻辑运算符(如AND、OR和NOT)来组合多个条件。
- 聚合函数:WHERE子句还可以与聚合函数一起使用,如COUNT、SUM、AVG等,以对数据进行计数、求和或计算平均值等操作。
2、2、2 实例练习
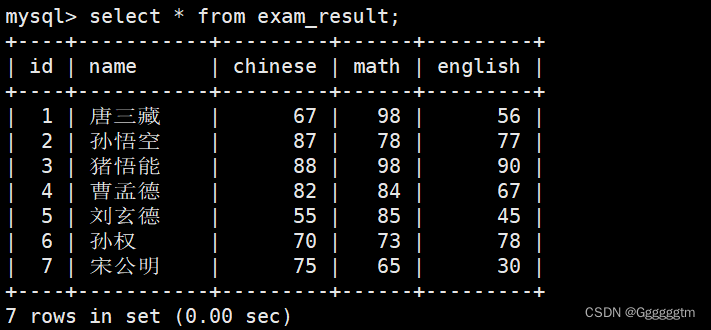
我们练习使用的表仍然是 exam_result 表,如下图:
英语不及格的同学及英语成绩
(首先分析我们都需要查询哪些信息:英语成绩和同学姓名。在select查询的列为姓名和英语成绩后,再用where子句来筛选英语成绩小于60即可。结果图下图: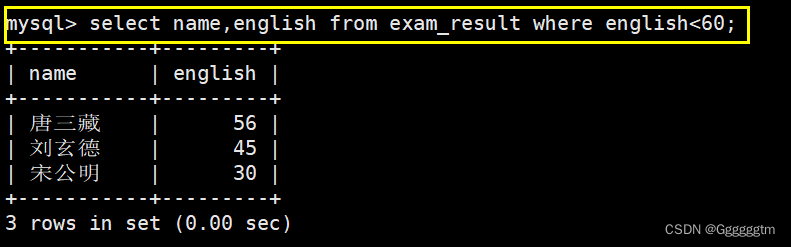
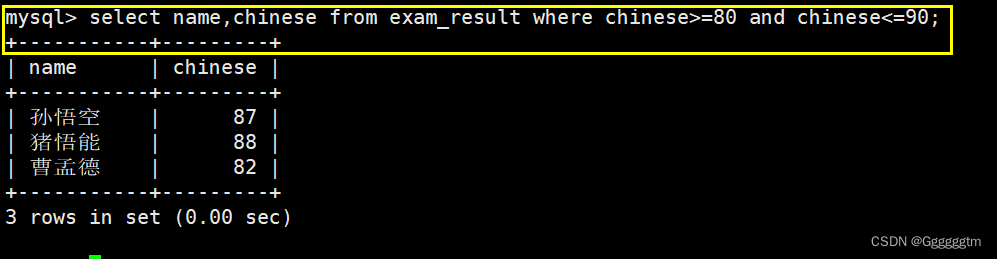
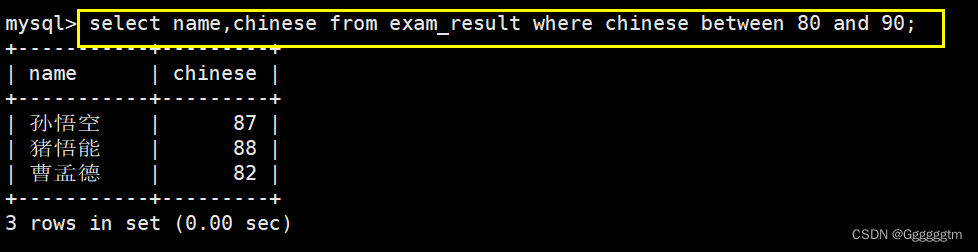
语文成绩在
[80, 90]
分的同学及语文成绩所需要查询的列:语文成绩和姓名。筛选条件:chinese >= 80 并且 chinese
注意:sql语句中不区分大小写。
我们发现两边都是闭区间,所以我们还可以使用between A and B来进行筛选。 结果如下图:
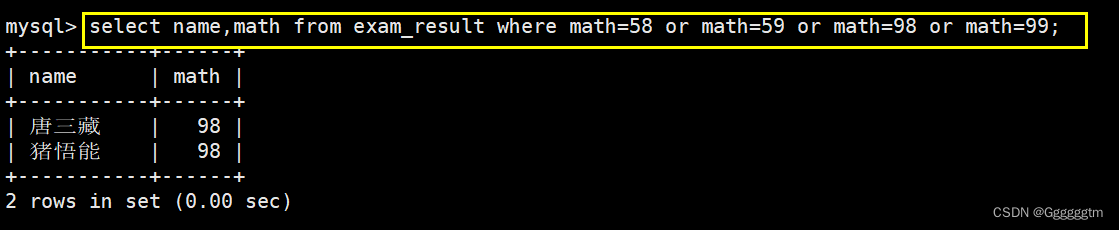
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
所需查询的列:数学成绩和同学姓名。筛选条件:数学成绩是 58 或者 59 或者 98 或者 99 。我们发现他们之间的关系是或,可以用 or 来进行筛选。如下图:
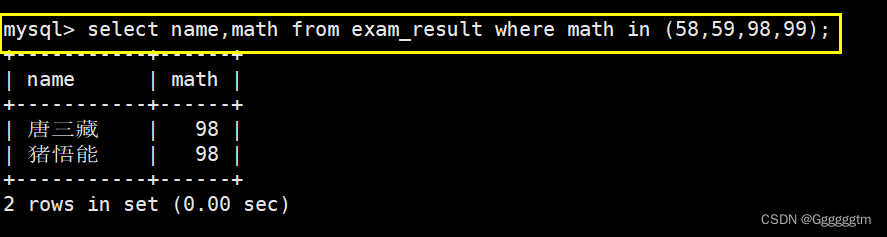
此外,我们也可以使用in(A,B,C,D,……)。具体如下图:
姓孙的同学 及 孙某同学
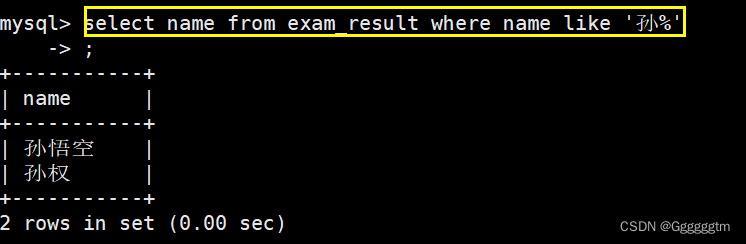
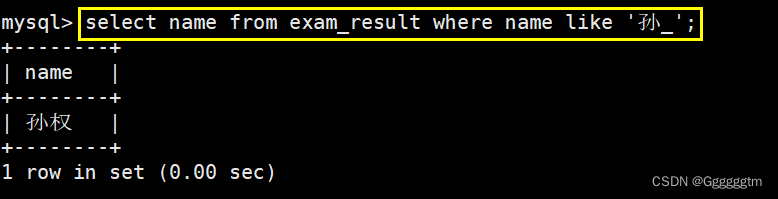
所要查询的列:同学姓名。筛选条件:模糊匹配性孙的同学。注意:姓孙的同学和孙某同学是不一样的概念。姓孙的同学,姓名可以是两个字,三个字等等。孙某代表的是姓孙,且姓名为两个字的同学。
可以使用like关键字进行模糊匹配,用于匹配特定模式的数据。like关键字可以与通配符配合使用,通配符包括 % 和 _ 。
- % 通配符:匹配任意长度的任意字符,包括零个字符。例如,
'%abc'可以匹配以abc结尾的任意字符串;'abc%'可以匹配以abc开头的任意字符串;'%abc%'可以匹配包含abc的任意字符串。- _ 通配符:匹配单个字符。例如,
'a_c'可以匹配abc、adc等。那么就很好的可以匹配到我们所需要查找的姓孙的同学或者孙某同学了,具体如下图:
我们再来看看对孙某同学的查询:
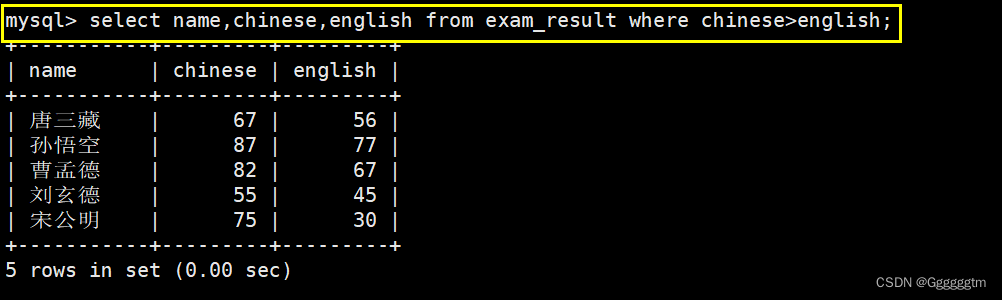
语文成绩好于英语成绩的同学
所需查询的列:同学姓名,语文、英语成绩。筛选条件:语文成绩大于英语成绩。在比较时,可以两个列进行比较(条件中比较运算符两侧都是字段)。具体如下图:
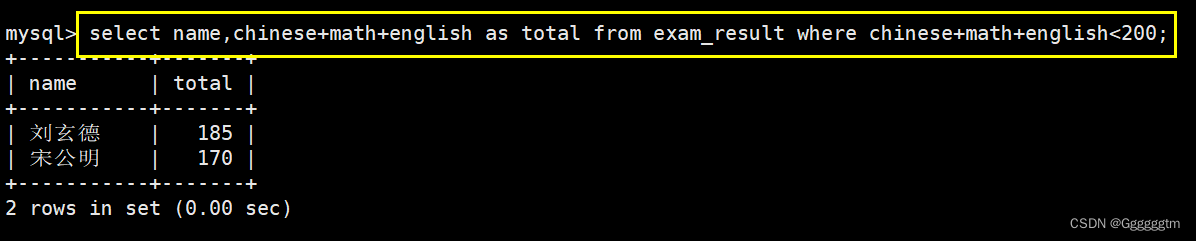
总分在 200 分以下的同学
所需要查询的列:同学姓名,三科总成绩。筛选条件:总成绩小于200分。具体如下图:
上图中我们对三科成绩进行了指定别名,打印输出的正是我们指定的别名。那么有的同学就想到:在where子句中也使用total去判断筛选,这样就会更加方便。问题是:这样可以吗?我们看如下图:
实际上并不可以的,上述报错中提到找不到 ‘total’ 列。为什么呢?我们不是指定别名了吗?这就与sql语句的执行顺序有关了。执行顺序与下图:
我们来分析一下为什么这样执行:首先应该找到在那张表里去筛选数据,然后带着筛选条件去查找遍历数据,最后将找到的数据进行选择列进行打印。那么where子句比指定别名要先执行,所以在where子句中找不到我们指定的别名。总的来说,在where子句中不能使用select中指定的别名:
- 查询数据时是先根据where子句筛选出符合条件的记录。
- 然后再将筛选出的数据进行打印出我们所需要的列,打印前会执行指定别名。


语文成绩 > 80 并且不姓孙的同学
所需要查询的列:语文成绩,同学姓名。筛选条件:语文成绩大于80,并且不性孙(not like)。我们看如下图:

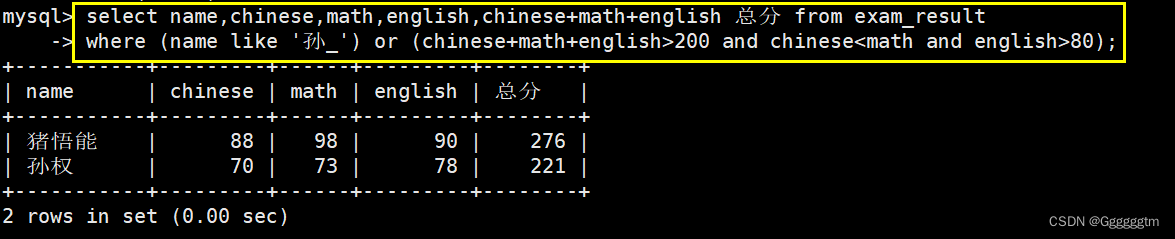
孙某同学,否则要求总成绩 > 200 并且 语文成绩 数学成绩 并且 英语成绩 > 80
查询的列:同学姓名,各科成绩和总成绩。筛选条件:孙某 或者 总成绩 > 200 并且 语文成绩 数学成绩 并且 英语成绩 > 80。我们看如下结果:
注意:当有多个与、或条件时,我们应该多加括号来保证执行顺序,避免出现不必要的错误。
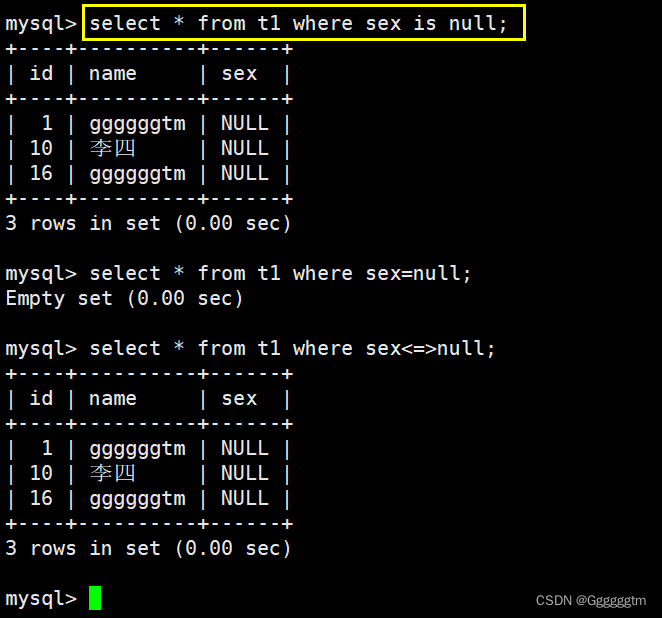
NULL 的查询
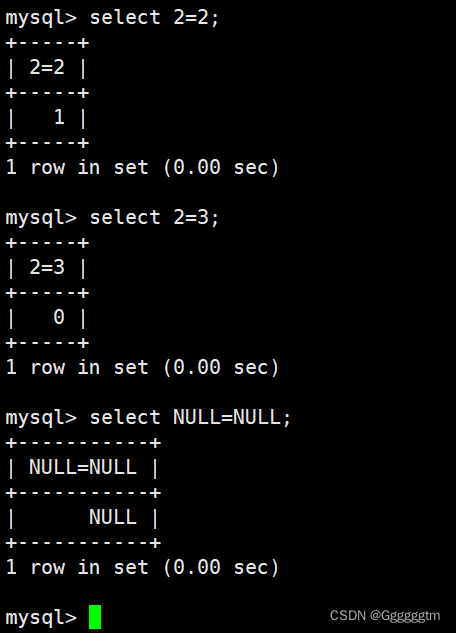
NULL的查询比较特殊。我们前面也提到了NULL不能用 ‘=’ 来判断,是不安全的。结果如下:
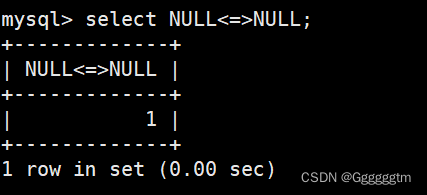
因为NULL并不参与运算。所以结果只能是NULL。我们可以使用 ‘ ’来判断NULL。结果如下:
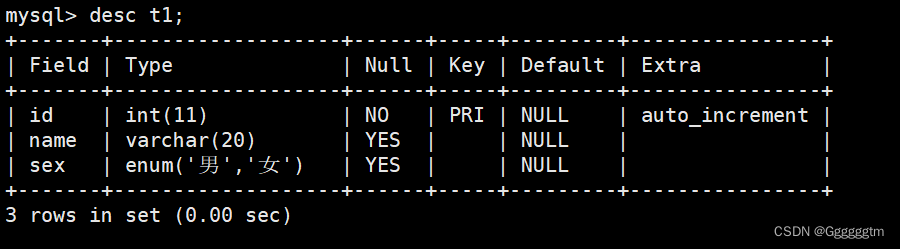
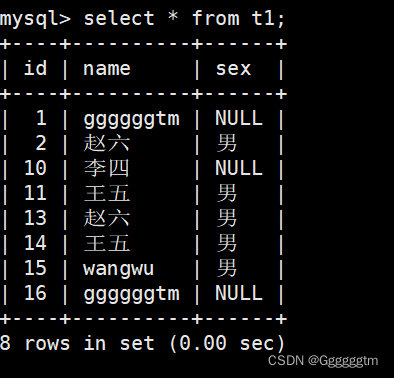
然而 ‘ ’并不符合我们的使用习惯。所以我们也可以使用is null 或者 is not null来判断。我们现在有如下表:
我们把sex为NULL的行找出来。结果如下:
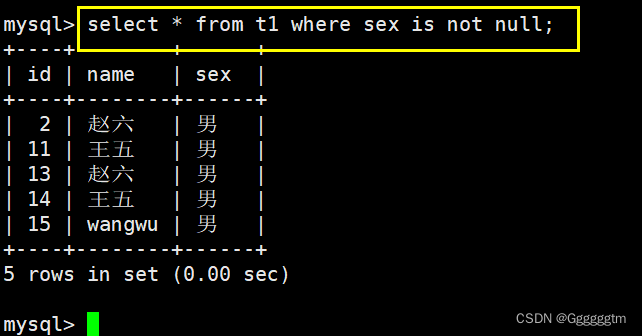
我们再来找到sex不为null行,结果如下图:
2、3 对查询结果进行排序
在MySQL中,可以使用ORDER BY子句对查询结果进行排序。ORDER BY子句允许您按照一个或多个列的值对结果进行排序,以及是升序(ASC)还是降序(DESC)排序和默认为 升序(ASC)。注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序。
2、3、1 升序排序
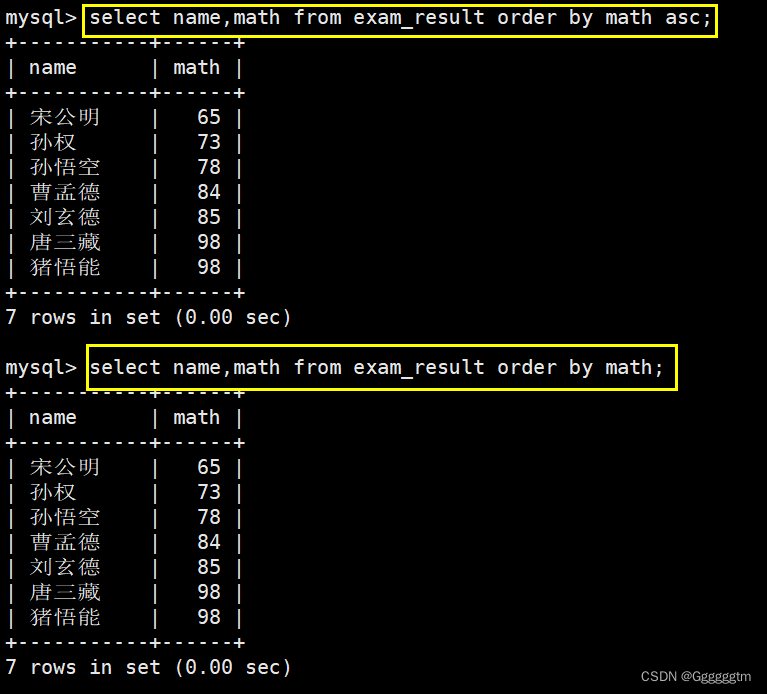
同学及数学成绩,按数学成绩升序显示
所要查询的列:姓名,数学成绩。要求:按照成绩升序。结果如下图:
2、3、2 降序排序
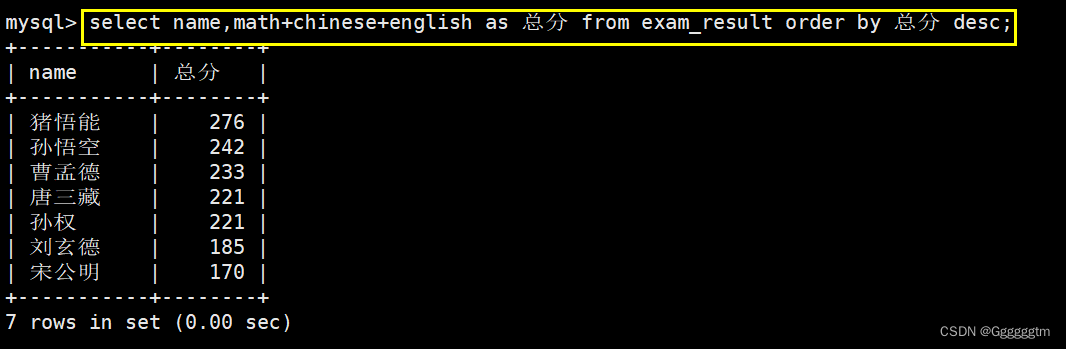
查询同学及总分,由高到低
所需要查询的列:姓名,总成绩。要求:总成绩从高到低,也就是降序。结果如下图:
上述结果确实是按照降序进行排序的。但是我们发现order by 子句中可以使用列的别名。这又是为什么呢?这也与其select语句的执行顺序有关,如下图:
我们可以理解为,先找到所需要查询的表,然后查询所有的指定的列的数据,最后对查找的数据进行排序。所以在order by 子句中是可以使用列的别名。
在这里说明一下:NULL值比任何值都要小。
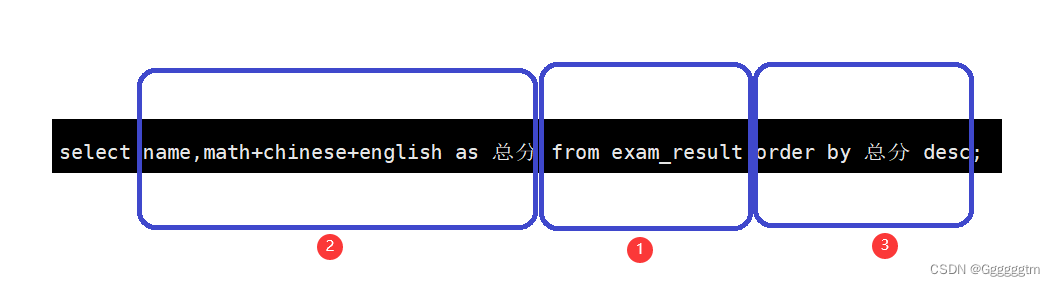
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
所需查询的列:姓名和数学。筛选条件:姓孙或者姓曹。要求:成绩由高到低,也就是降序。结果如下:
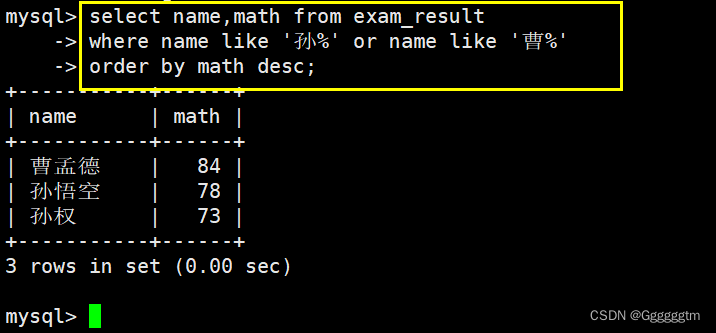
2、3、3 按照多列进行排序
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示所需要查询的列:同学姓名和各科成绩。要求:
依次按 数学降序,英语升序,语文升序。我们看如下结果: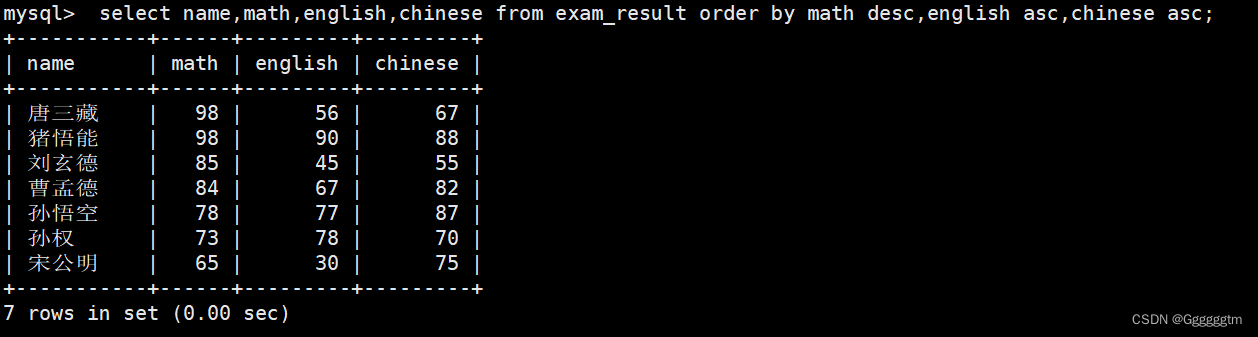 注意:所有行首先是按照math进行降序排序。然后再math相同的情况下再按照english进行升序排序。最后再math相同,english相同的情况下,再按照语文进行升序排序。发现越靠后的排序,其要求的条件越多。
注意:所有行首先是按照math进行降序排序。然后再math相同的情况下再按照english进行升序排序。最后再math相同,english相同的情况下,再按照语文进行升序排序。发现越靠后的排序,其要求的条件越多。
2、4 对筛选的结果进行分页
在MySQL中,可以使用
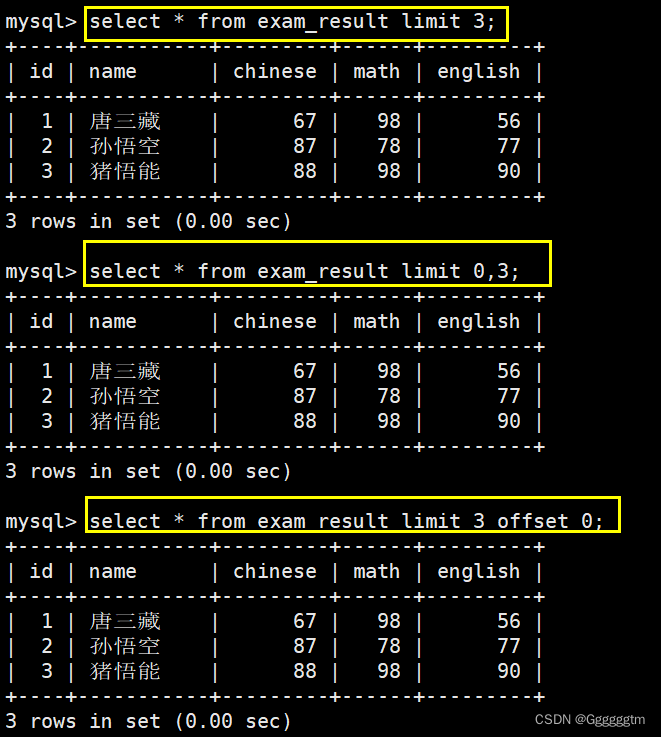
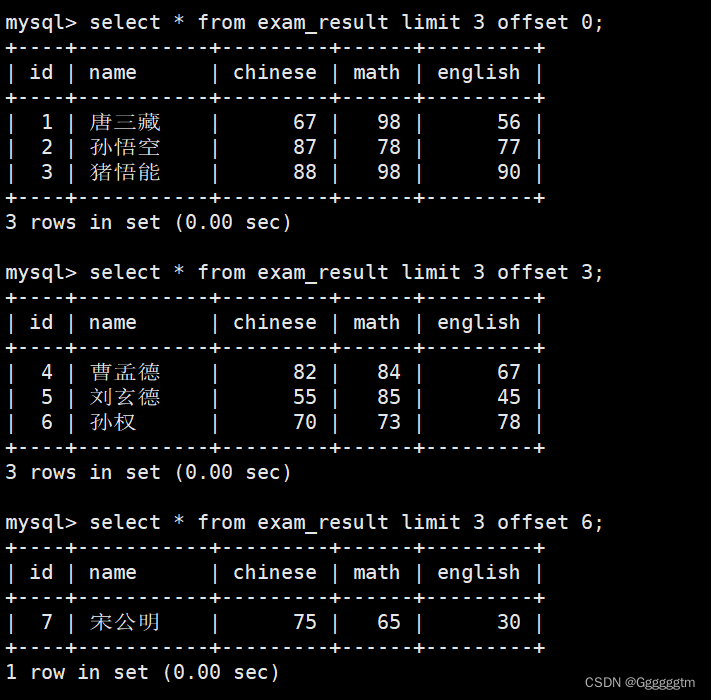
LIMIT和OFFSET子句对筛选结果进行分页。LIMIT用于指定每页返回的记录数量,而OFFSET用于指定从第几行开始返回结果。常用语法如下:-- 从 0 开始,筛选 n 条结果 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n; -- 从 s 开始,筛选 n 条结果 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n; -- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;我们结合如下实例来理解一下:
通常情况下,一张表的数据会很多,我们需要将这张表进行分页显示。就可以用到 limit 语句。具体如下图:
我们将七条语句分为了3页进行显示。注意,当从某个偏移量开始打印n行数据时,且该表中从某个偏移量开始到最后并不够n行,那么默认就打印到最后一行。
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死。或者按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 …..页
三、表的数据更新
在MySQL中,可以使用UPDATE语句对表进行更新。UPDATE语句用于修改表中的数据。语法如下:
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;简单说明:
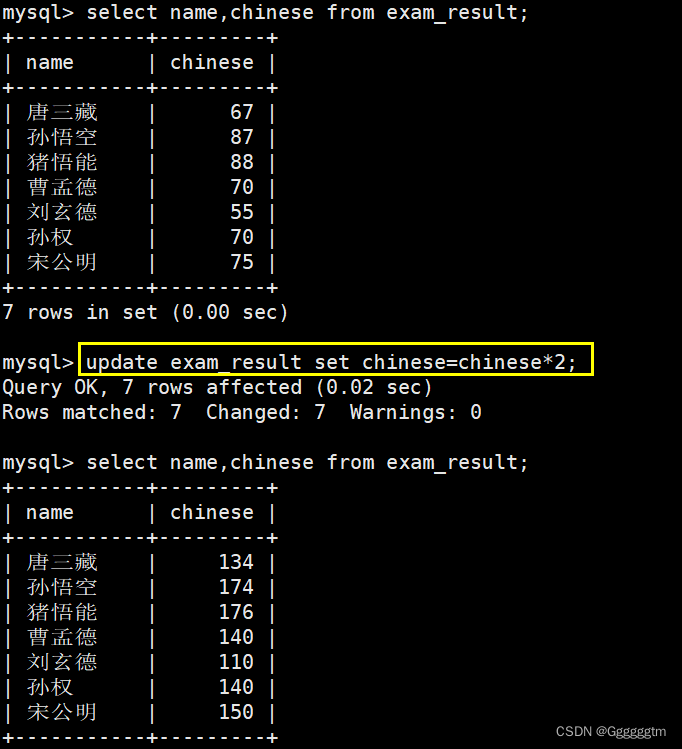
table_name是要更新的表的名称。column1,column2, … 是要更新的列的名称。value1,value2, … 是要设置的新值。WHERE condition是一个可选的条件,用于指定要更新的行。如果不提供条件,则会更新表中的所有行。下面我们看几个实际例子来理解一下。下面的实例中全部是根据下表进行更新的:
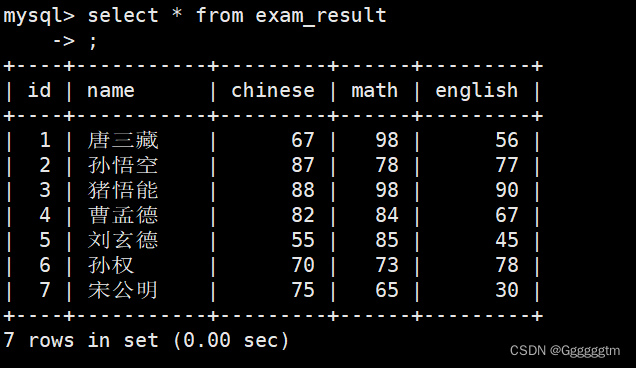
将孙悟空同学的数学成绩变更为 80 分
我们只需要确定要更新的列和更新的条件即可。结果如下图:
注意:一定要加where条件进行筛选,否则所有人的数学成绩都将被更新为80。

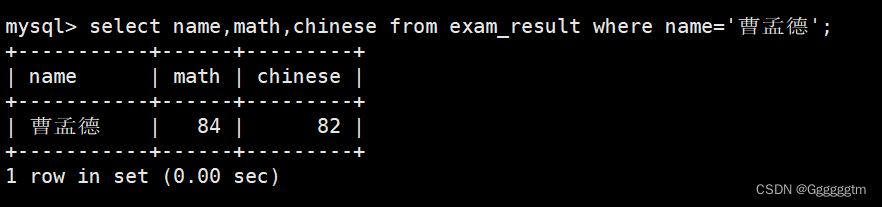
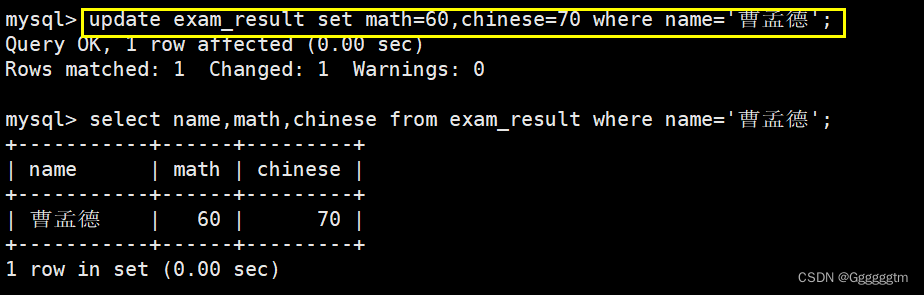
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
我们先来查看一下曹孟德的成绩:
接下来我们再修改发现思路就会很清晰了,修改结果如下图:
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
怎么可以很好的找到倒数前三名同学呢?升序排序,然后使用limit不就行了吗!我们先筛选出倒数前三的同学,如下:
那么接下来就对倒数前三名同学的数学成绩加上30分的操作,具体如下:
我们对比后发现,他们的总成绩确实增加了30。那么排名当然也会有所改变。需要注意的是:在更新数学成绩时,不支持 math += 30 这种语法。
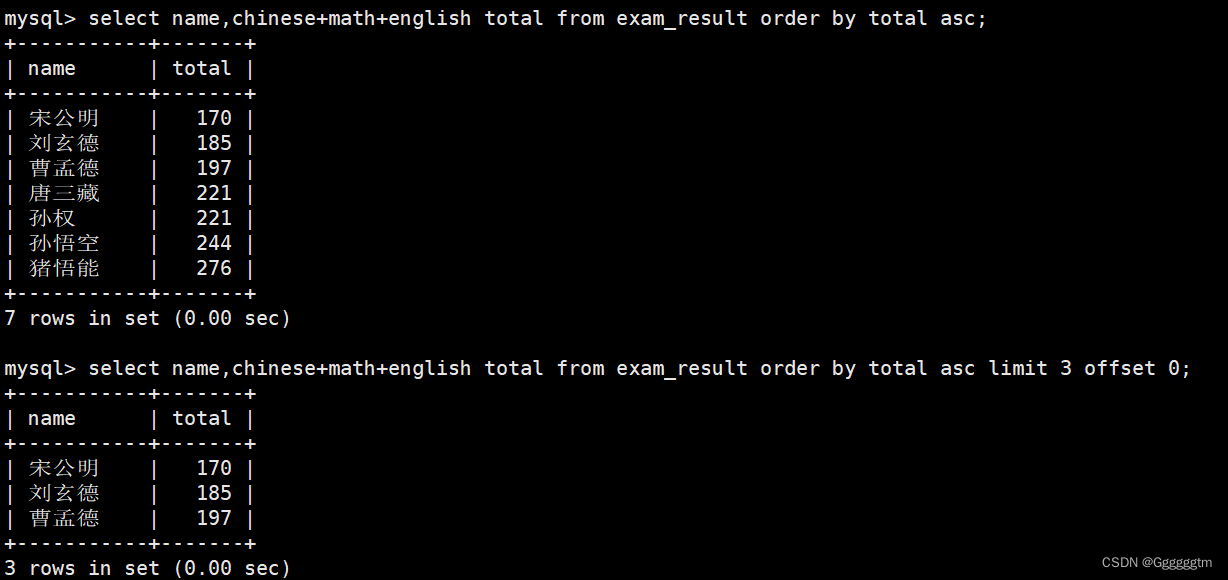

将所有同学的语文成绩修改为原来的2倍
我们发现是所有同学,所以就不用再筛选同学了。直接看结果:
注意,在我们使用更新全表的语句之前,一定要先确定你是否要对所有数据进行更新!
四、表的数据删除
4、1 delete 删除数据
在MySQL中,要删除表中的数据,可以使用DELETE语句。DELETE语句用于从表中删除满足特定条件的行。以下是删除表中的数据的语法:
DELETE FROM table_name WHERE condition;其中,
table_name是要删除数据的表的名称,condition是一个可选的条件,用于指定要删除的行。如果要删除所有行,可以使用通配符*。下面我们结合实际例子来理解一下。
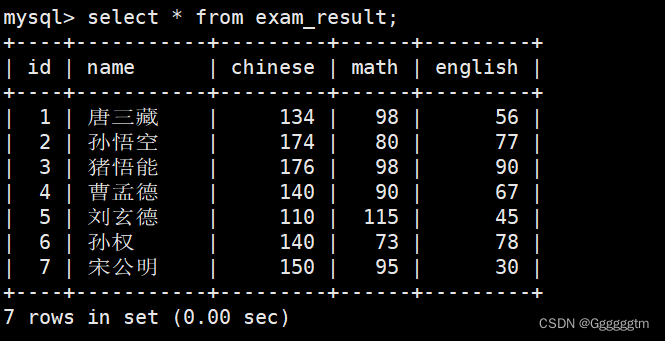
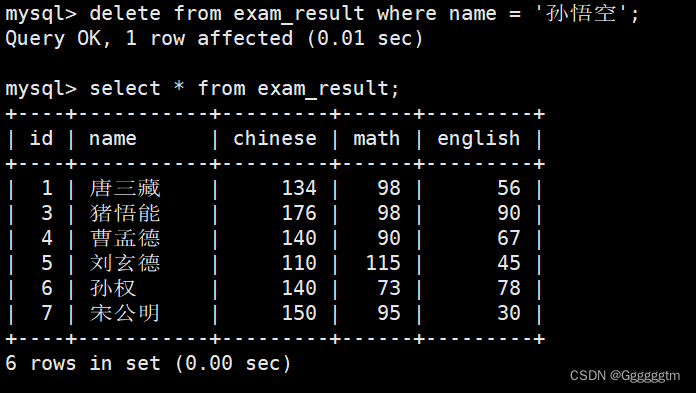
删除孙悟空同学的考试成绩
我们直接看结果:
我们看到,孙悟空的id为2,所以那一行的数据就会被全部删除。
删除整张表的数据
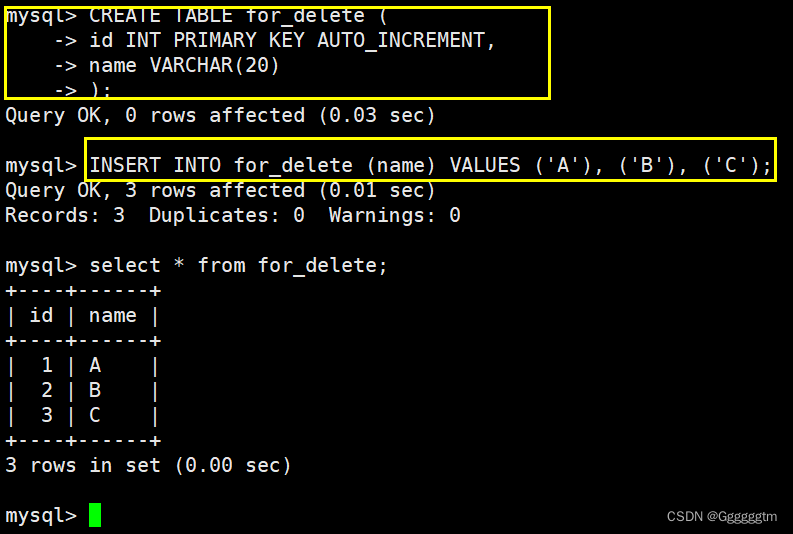
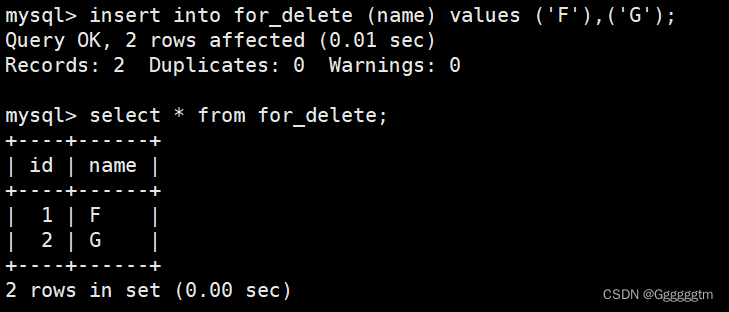
当我们在删除某个表中的数据时,并不添加任何筛选条件,相当于删除整张表中的数据。我们先来创建一个表并且插入一些新的数据,如下图:
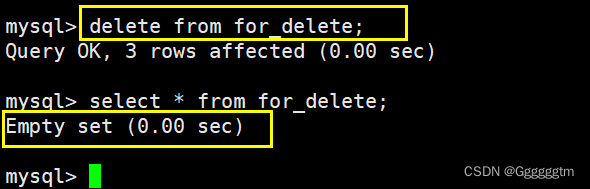
我们在对整张表进行删除,如下图:
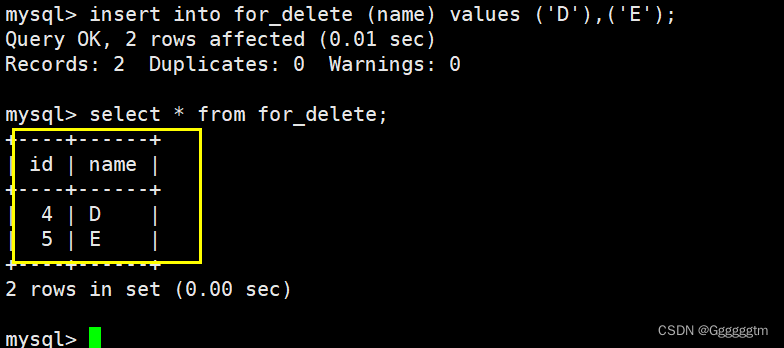
我们再来插入一些数据观察一下:
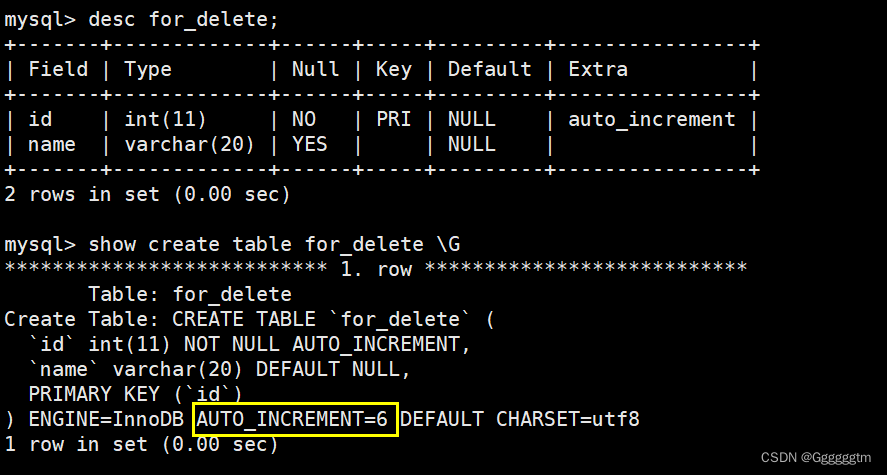
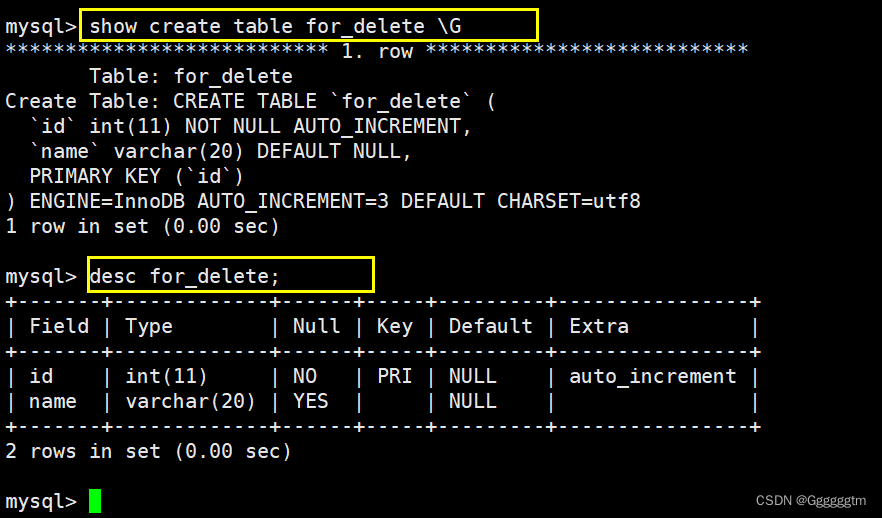
通过上图发现,我们新插入的值的id并不是从0开始的。而是接着原来的自增长的值进行插入的。我们再来查看一下表结构和创建表时的相关信息。如下图:
通过上图可以看到,delete删除数据并不会删除表的结构,同时有一个
AUTO_INCREMENT=n的字段,该字段就是我们设置的自增长字段,应并不会对此产生影响。
4、2 truncate 截断表
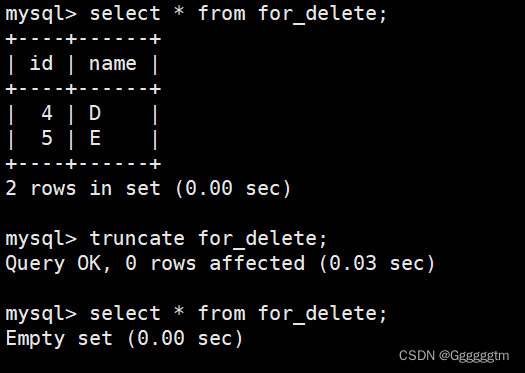
我们在使用truncate对表的数据进行删除,如下图:
再来进行插入一些数据观察一下,如下图:
通过上图可以发现,这次的id值是从1开始了。我们再来观察一下表结构和创建表时的相关信息,如下图:
通过上图可以发现,truncate会重置auto_increment字段的。但是,truncate只能对整表操作,不能像delete一样针对部分数据操作。
delete语句用于删除指定条件下的行。它会保留表结构,并且可以使用WHERE子句来选择要删除的特定行。但是,delete操作可能会导致性能问题,特别是当表非常大时,因为每次删除都需要进行磁盘I/O操作。 另一方面,truncate语句用于删除表中的所有行,包括索引和约束等对象。与delete不同,
TRUNCATE不会记录任何事务日志,因此执行速度非常快。但是,一旦执行了truncate操作,就无法恢复被删除的数据,除非有备份。综上所述,如果你需要删除表中的某些特定行,应使用delete。而如果你需要从表中快速删除所有数据,并且可以接受无法恢复丢失数据的风险,那么应该使用truncate。需要注意的是,在使用truncate之前,请确保已经创建了适当的备份以防万一。
五、group by 与 聚合函数
GROUP BY语句用于根据一个或多个列的值对结果进行分组,并应用聚合函数来汇总每一组的数据。这意味着你可以按照特定的字段对数据进行分组,并且对于每个组,你都可以使用聚合函数来计算出该组的一些统计数据。
下面我们先来学习一下聚合函数的使用。
5、1 聚合函数
常见的聚合函数包括但不限于以下几种:
- COUNT:计算指定列中的行数。
- SUM:对指定列中的数值进行求和。
- AVG:计算指定列的平均值。
- MAX:返回指定列中的最大值。
- MIN:返回指定列中的最小值。
我们再结合几个实际的例子来理解一下聚合函数的使用。依据下表进行查询:
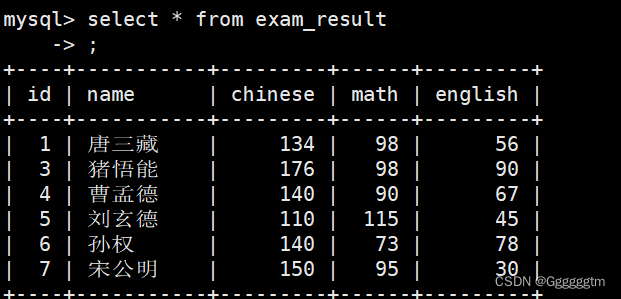
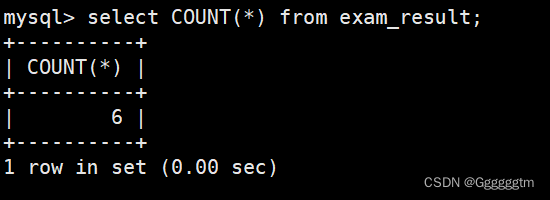
统计班级共有多少同学
使用 * 号进行统计,且不受NULL的影响。结果如下图:
注意,我们的exam_result 表中并没有id=2的行,所以是一共为6行。我们也可以使用表达式进行统计,如下图:
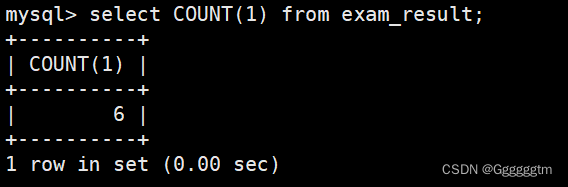
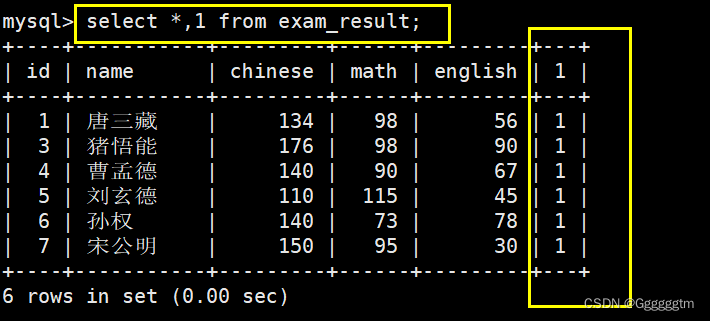
怎么理解上图中的用表达式来统计呢?这种写法相当于在查询表中数据时,自行新增了一列列名为特定表达式的列,我们就是在用count函数统计该列中有多少个数据,等价于统计表中有多少条记录。具体如下图:
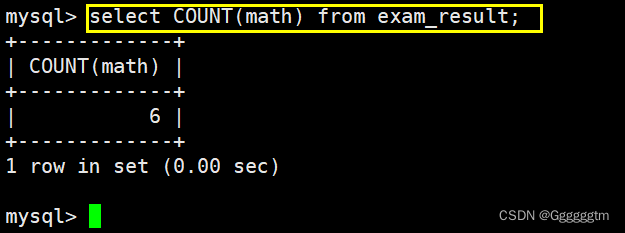
如果是要统计具体的某一个列的字段个数,那么NULL并不会计算在内。
统计本次考试的数学成绩分数个数
这个跟统计总人数区别不大,我们直接看结果:
如果我们想统计去重后的数学成绩的个数呢?如下图:
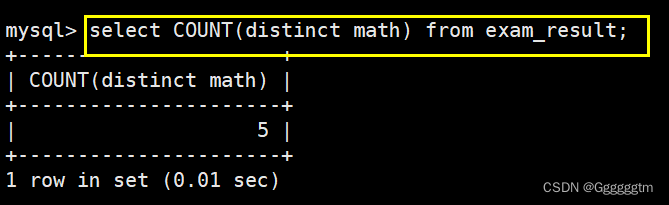
统计数学成绩总分
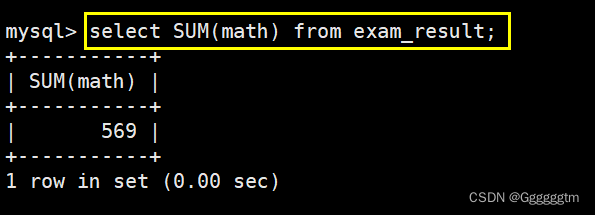
我们直接用SUM聚合函数就可以将筛选出来的成绩相加到一起。如下图:
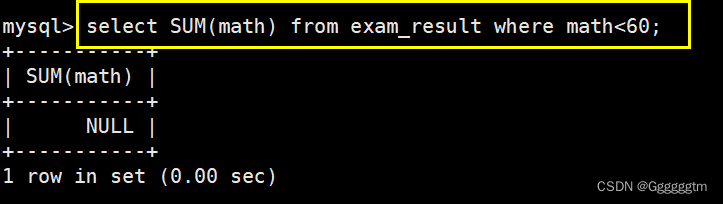
再加上筛选条件,查看数学成绩低于60分的总成绩。如下图:
正如上图所示,如果有低于60分的会统计出来。如果没有的话,会输出一个NULL。
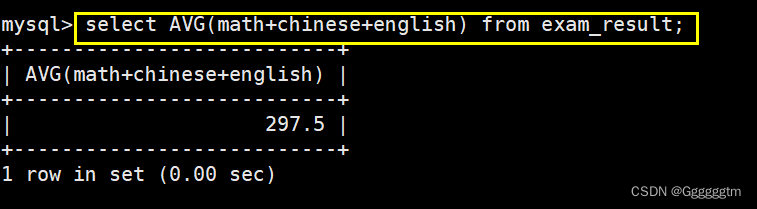
统计平均总分
我们只需要将所有的成绩加起来,在用AVG聚合函数求平均分即可。具体如下图:
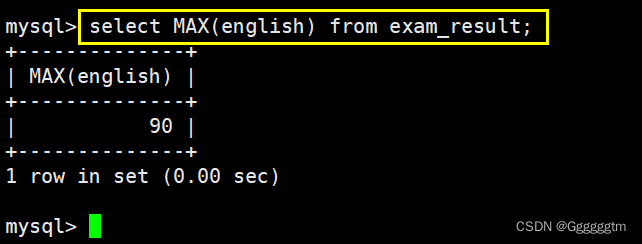
返回英语最高分
直接使用MAX聚合函数即可。如下图:
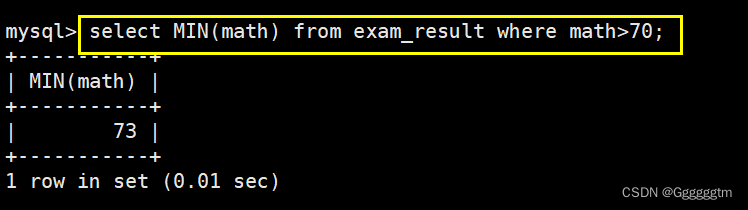
返回 > 70 分以上的数学最低分
首先筛选出数学成绩大于70分的,在使用聚合函数MIN即可。如下图:
5、2 group by语句
在select中使用group by 子句可以对指定列进行分组查询,语法如下:
select column1, column2, .. from table group by column;下面我们结合实际例子来理解一下group by 的使用。
我们现在有如下三张表:
其中员工表(emp)的表结构和表中的内容如下:
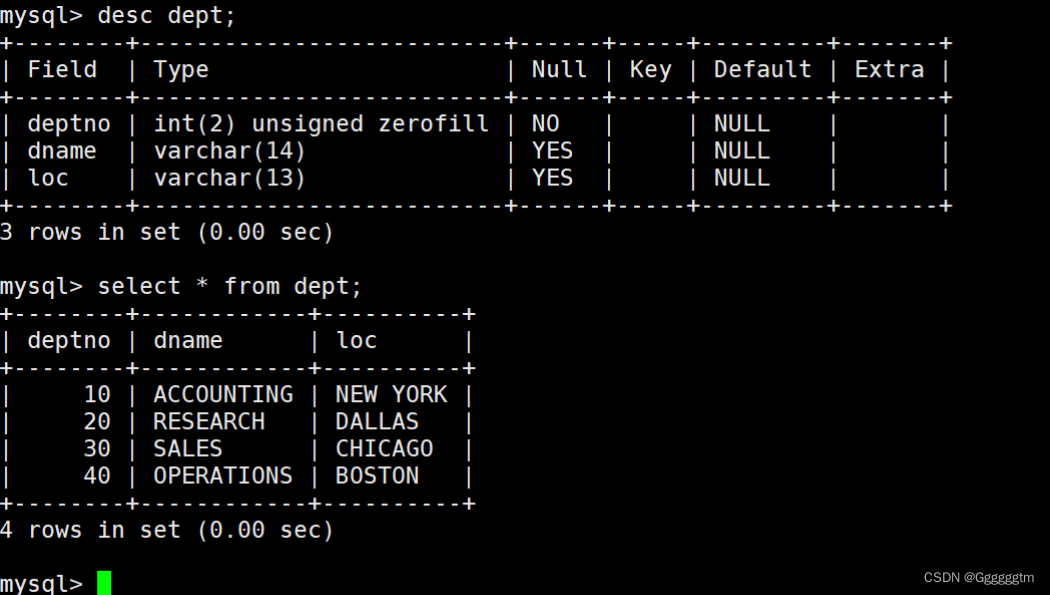
部门表(dept)的表结构和表中的内容如下:
工资等级表(salgrade)的表结构和表中的内容如下:

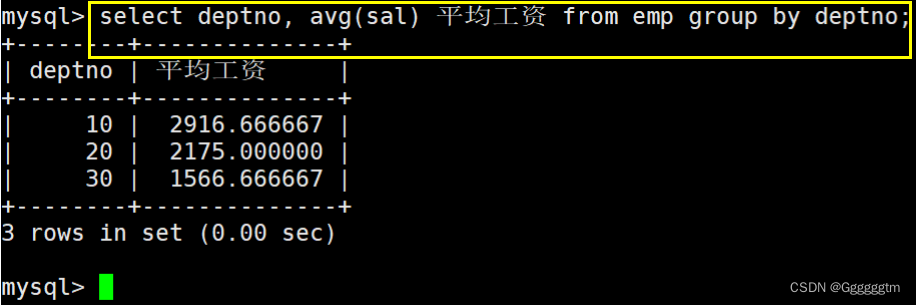
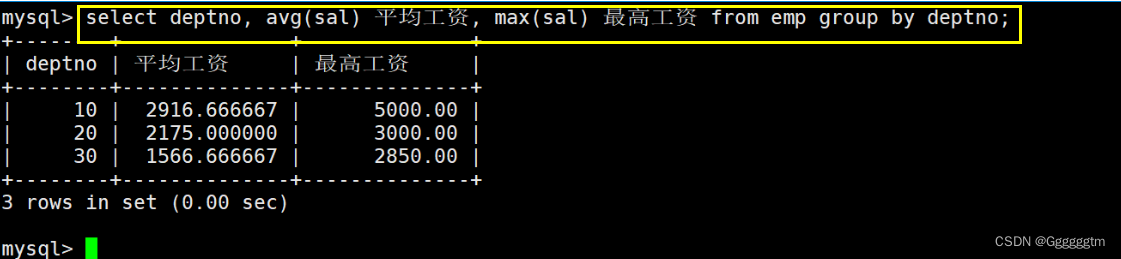
显示每个部门的平均工资和最高工资
首先,我们肯定是要对每个部分进行分类的。相同的部门归到一类在进行统计。结果如下图:
简单解释一下:上述SQL语句会先将表中的数据按照部门号进行分组,然后各自在组内做聚合查询得到每个组的平均工资和最高工资。
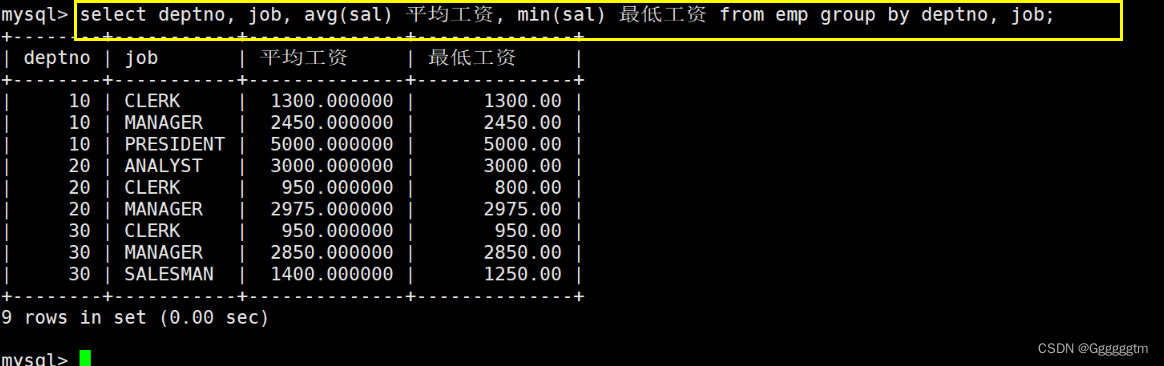
显示每个部门的每种岗位的平均工资和最低工资
注意,我们需要按照部们和岗位进行分组,然后在使用AVG和MIN聚合函数。具体如下图:
上述语句中,我们是先按照部分进行分类。如果部门号相同时,再按照job进行分类。其分类字段用逗号隔开。
显示平均工资低于2000的部门和它的平均工资
首先我们应该根据部门进行分类筛选出平均工资,如下图:
然后再筛选出平均工资低于2000的。结果如下图:
细心的同学发现了,我们在分组筛选时,用的having而不是where。他们有什么区别呢?
在MySQL中,HAVING和WHERE都是用于过滤查询结果的SQL语句,它们在功能上有些相似,但也有一些关键的区别。
- 适用场景:WHERE用于在SELECT语句中基于列的值进行过滤,而HAVING用于在GROUP BY查询中过滤聚合函数的结果。换句话说,WHERE用于单个行的过滤,而HAVING用于组级别的过滤。
- 数据类型:WHERE子句通常用于过滤数据表中的单个行,而HAVING子句通常用于过滤聚合函数的结果集(如COUNT、SUM等)。
- 使用频率:WHERE通常在大多数查询中使用,因为它可以更直接地过滤单个行。另一方面,HAVING在需要基于聚合函数的结果进行过滤时使用较少,因为它需要处理聚合数据。
- 返回结果:WHERE和HAVING返回的结果集可能不同。WHERE通常返回单个行或行的组合,而HAVING通常返回一个结果集,其中包含所有符合条件的组的数据。
我们也发现了,where子句中不能使用聚合函数和别名,而having子句中可以使用聚合函数和别名。这就涉及到了分组聚合的SQL语句的执行顺序了。含有having子句的SQL如下:
SELECT ... FROM table_name [WHERE ...] [GROUP BY ...] [HAVING ...] [order by ...] [LIMIT ...];从上述语法中我们也能看出来,where子句放在表名后面,而having子句必须搭配group by子句使用,放在group by子句的后面。SQL中各语句的执行顺序为:where、group by、select、having、order by、limit。
总的来说,WHERE和HAVING在功能上有所不同,适用于不同的查询场景。在大多数情况下,WHERE子句应该足够满足大多数查询需求,除非你需要在GROUP BY查询中使用聚合函数并需要对其进行过滤。
ps:在group by中出现的字段,都是可以在select中进行查询的。where子句中不能使用聚合函数和别名,而having子句中可以使用聚合函数和别名。