

Python爬虫技术系列-02HTML解析-BS4
- 2 Beautiful Soup解析
-
- 2.1 Beautiful Soup概述
-
- 2.1.1 Beautiful Soup安装
- 2.1.2 Beautiful Soup4库内置对象
- 2.2 BS4 案例
-
- 2.2.1 读取HTML案例
- 2.2.2 BS4常用语法
-
- 1Tag节点
- 2 遍历节点
- 3 搜索方法
-
- 1) find_all()
- 2)find()
- 3) CSS选择器
- 2.3 BS4综合案例
-
- 2.3.1 需求:爬取三国演义小说的所有章节和内容
- 2.3.2 爬取小说数据,并排错
2 Beautiful Soup解析
参考连接:
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#
http://c.biancheng.net/python_spider/bs4.html
2.1 Beautiful Soup概述
2.1.1 Beautiful Soup安装
Beautiful Soup 简称 BS4(其中 4 表示版本号)是一个 Python 第三方库,它可以从 HTML 或 XML 文档中快速地提取指定的数据。Beautiful Soup 语法简单,使用方便,并且容易理解,因此您可以快速地学习并掌握它。本节我们讲解 BS4 的基本语法。
BS4下载安装
由于 Bautiful Soup 是第三方库,因此需要单独下载,下载方式非常简单,执行以下命令即可安装:
pip install beautifulsoup4==4.11.1 -i https://pypi.tuna.tsinghua.edu.cn/simple。
由于 BS4 解析页面时需要依赖文档解析器,所以还需要安装 lxml 作为解析库:
pip install lxml
2.1.2 Beautiful Soup4库内置对象
Beautiful Soup4库的内置对象:
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,对象可以归纳为BeautifulSoup ,Tag , NavigableString , Comment 四种。
BeautifulSoup 对象为一个文档的全部内容,可以认为BeautifulSoup 对象是一个大的Tag对象。
Tag对象与XML或HTML原生文档中的tag相同。代表html文档中的标签,Tag对象可以包含其他多个Tag对象。Tag.name返回标签名,Tag.string返回标签中的文本。
NavigableString对象html文档中的文本,即Tag中的字符串用NavigableString对象包装。
Commern对象是一种特殊的NavigableString对象,用来包装文档中注释和特殊字符串。
2.2 BS4 案例
2.2.1 读取HTML案例
1.创建 BS4 解析对象第一步,这非常地简单,语法格式如下所示:
#导入解析包
from bs4 import BeautifulSoup
#创建beautifulsoup解析对象
soup = BeautifulSoup(html_doc, 'html.parser')
上述代码中,html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 ‘lxml’ 或者 ‘html5lib’,示例代码如下所示:
# 第一步 导入依赖库
from bs4 import BeautifulSoup
#coding:utf8
html_doc = """
"bs4测试"
标签文本div中文本
"""
# 第二步,加载数据为BeautifulSoup对象:
soup = BeautifulSoup(html_doc, 'html.parser')
#prettify()用于格式化输出html/xml文档
print(soup.prettify())
# 第三步,获取文档中各个元素:
# 利用soup.find('div')获取div标签
tag_node = soup.find('div')
print(type(tag_node),'t:',tag_node)
# 遍历div标签对象,获取其中的各个对象
for item in tag_node:
print(type(item),'t:',item)
输出结果:
html>
head>
title>
"bs4测试"
title>
head>
body>
div>
span class="cla01">
标签文本
span>
div中文本
div>
body>
html>
class 'bs4.element.Tag'> : div>span class="cla01">标签文本span>div中文本div>
class 'bs4.element.Tag'> : span class="cla01">标签文本span>
class 'bs4.element.NavigableString'> : div中文本
class 'bs4.element.Comment'> : 注释代码
从结果可以看出soup.find(‘div’)返回值为Tag类型,输出结果为该标签的全部内容。
for循环中print(type(item),‘t:’,item)会输出div标签的所有各个对象,该div标签包含的对象如下:
一个Tag对象,值为标签文本;
一个NavigableString’文本对象,值为div中文本;
一个Comment’注释对象,值为注释代码。
外部文档可以通过 open() 的方式打开读取,语法格式如下:
soup = BeautifulSoup(open('html_doc.html', encoding='utf8'), 'lxml')
2.2.2 BS4常用语法
下面对爬虫中经常用到的 BS4 解析方法做详细介绍。
Beautiful Soup 将 HTML 文档转换成一个树形结构,该结构有利于快速地遍历和搜索 HTML 文档。下面使用树状结构来描述一段 HTML 文档:
html>head>title>网页标题title>head>h1>www.baidu.comh1>p>b>搜索引擎b>p>body>html>
树状图如下所示:
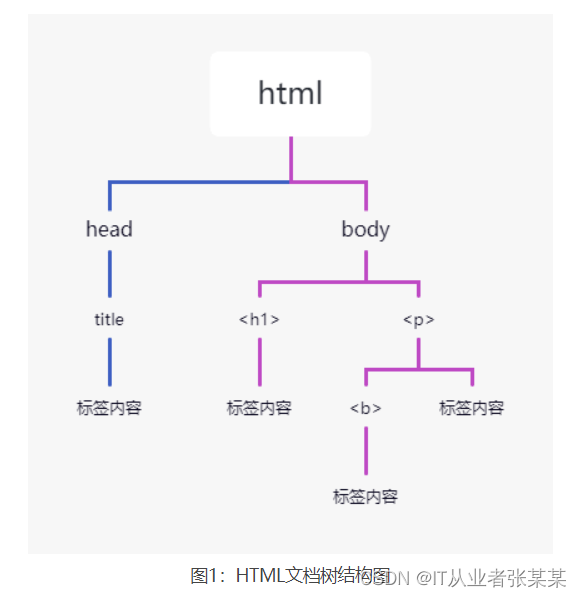
1Tag节点
# 标签(Tag)是组成 HTML 文档的基本元素。在 BS4 中,通过标签名和标签属性可以提取出想要的内容。看一组简单的示例:
# 纯文本复制
from bs4 import BeautifulSoup
html_doc = 'www.baidu.com
'
soup = BeautifulSoup(html_doc, 'html.parser')
#获取整个div标签的html代码
print(soup.div)
#获取span标签
print(soup.div.p.span)
#获取p标签内容,使用NavigableString类中的string、text、get_text()
print(soup.div.p.text)
#返回一个字典,里面是多有属性和值
print(soup.div.p.attrs)
#查看返回的数据类型
print(type(soup.div.p))
#根据属性,获取标签的属性值,返回值为列表
print(soup.div.p['class'])
#给class属性赋值,此时属性值由列表转换为字符串
soup.div.p['class']=['Web','Site']
print(soup.div.p)
输出为:
div>p class="Web site url">span>www.baidu.com/span>/p>/div>
span>www.baidu.com/span>
www.baidu.com
{'class': ['Web', 'site', 'url']}
class 'bs4.element.Tag'>
['Web', 'site', 'url']
p class="Web Site">span>www.baidu.com/span>/p>
2 遍历节点
# Tag 对象提供了许多遍历 tag 节点的属性,比如 contents、children 用来遍历子节点;parent 与 parents 用来遍历父节点;而 next_sibling 与 previous_sibling 则用来遍历兄弟节点 。示例如下:
# 纯文本复制
#coding:utf8
from bs4 import BeautifulSoup
html_doc = '''
- 01
- 02
- 03
'''
soup = BeautifulSoup(html_doc, 'html.parser')
body_tag=soup.body
print(body_tag)
print("# 以列表的形式输出,所有子节点")
print(body_tag.contents)
print(r"# Tag 的 children 属性会生成一个可迭代对象,可以用来遍历子节点,示例如下")
for child in body_tag.children:
print(child)
输出为:
body>
div class="useful">
ul>
li class="cla-0" id="id-0">a href="/link1">01/a>/li>
li class="cla-1">a href="/link2">02/a>/li>
li>strong>a href="/link3">03/a>/strong>/li>
/ul>
/div>
/body>
# 以列表的形式输出,所有子节点
['n', div class="useful">
ul>
li class="cla-0" id="id-0">a href="/link1">01/a>/li>
li class="cla-1">a href="/link2">02/a>/li>
li>strong>a href="/link3">03/a>/strong>/li>
/ul>
/div>, 'n']
# Tag 的 children 属性会生成一个可迭代对象,可以用来遍历子节点,示例如下
div class="useful">
ul>
li class="cla-0" id="id-0">a href="/link1">01/a>/li>
li class="cla-1">a href="/link2">02/a>/li>
li>strong>a href="/link3">03/a>/strong>/li>
/ul>
/div>
3 搜索方法
Beautiful Soup定义了很多搜索方法,本小节着重 find_all(), find() 和 select()几个。
find_all()函数可以搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。
find_all(self, name=None, attrs={}, recursive=True, string=None, **kwargs)
name 参数对应tag名称,如soup.find_all(“div”)表示查找所有div标签。
attrs表示属性值过滤器。如soup.find_all(class_=“cla”)表示查找class属性值为cla的所有元素。其它的属性过滤器还可以为id=”main”等。
recursive为True会递归查询,为False只检索直系节点。
text:用来搜文档中的字符串内容,该参数可以接受字符串 、正则表达式 、列表、True。
limit:由于 find_all() 会返回所有的搜索结果,这样会影响执行效率,通过 limit 参数可以限制返回结果的数量
find()函数是find_all()的一种特例,仅返回一个值。
select()函数用于通过css选择器进行文档的筛选。
find_all() 与 find() 是解析 HTML 文档的常用方法,它们可以在 HTML 文档中按照一定的条件(相当于过滤器)查找所需内容。find() 与 find_all() 的语法格式相似,希望大家在学习的时候,可以举一反三。
BS4 库中定义了许多用于搜索的方法,find() 与 find_all() 是最为关键的两个方法,其余方法的参数和使用与其类似。
1) find_all()
find_all() 方法用来搜索当前 tag 的所有子节点,并判断这些节点是否符合过滤条件,find_all() 使用示例如下:
from bs4 import BeautifulSoup
import re
html_doc = '''
加入我们阅读所有教程
百度一下
soso一下
- 01
- 02
- 03
'''
soup = BeautifulSoup(html_doc, 'html.parser')
# 查询全部li标签:
print("---result00---")
result00 = soup.find_all('li') # 查询全部li标签
print(result00)
# 查询符合条件的第1个标签:
print("---result01---")
result01 = soup.find_all('li',limit=1) # 查询符合条件的第1个标签
print(result01)
# 结合属性过滤,查询符合条件的标签:
print("---result02---")
result02 = soup.find_all('li', class_="cla-0") # 结合属性过滤,查询符合条件的标签
print(result02)
# 结合多个属性过滤,查询符合条件的标签:
print("---result03---")
result03 = soup.find_all('li', class_="cla-0",id="id-0") # 结合多个属性过滤,查询符合条件的标签
print(result03)
#列表行书查找tag标签
print("---result04---")
print(soup.find_all(['p','a']))
#正则表达式匹配id属性值
print("---result05---")
print(soup.find_all('a',id=re.compile(r'.d')))
print(soup.find_all(id=True))
#True可以匹配任何值,下面代码会查找所有tag,并返回相应的tag名称
print("---result06---")
for tag in soup.find_all(True):
print(tag.name,end=" ")
print(" ")
#输出所有以b开始的tag标签
print("---result07---")
for tag in soup.find_all(re.compile("^d")):
print(tag.name)
# BS4 为了简化代码,为 find_all() 提供了一种简化写法,如下所示:
print("---result08---")
#简化前
print(soup.find_all("p"))
#简化后
print(soup("p"))
输出为:
---result00---
[li class="cla-0" id="id-0">a href="/link1">01/a>/li>, li class="cla-1">a href="/link2">02/a>/li>, li>strong>a href="/link3">03/a>/strong>/li>]
---result01---
[li class="cla-0" id="id-0">a href="/link1">01/a>/li>]
---result02---
[li class="cla-0" id="id-0">a href="/link1">01/a>/li>]
---result03---
[li class="cla-0" id="id-0">a href="/link1">01/a>/li>]
---result04---
[p class="vip">加入我们阅读所有教程/p>, a href="https://www.baidu.com" id="link4">百度一下/a>, a href="https://www.sos.com">soso一下/a>, a href="/link1">01/a>, a href="/link2">02/a>, a href="/link3">03/a>]
---result05---
[a href="https://www.baidu.com" id="link4">百度一下/a>]
[a href="https://www.baidu.com" id="link4">百度一下/a>, li class="cla-0" id="id-0">a href="/link1">01/a>/li>]
---result06---
html body p a a div ul li a li a li strong a
---result07---
div
---result08---
[p class="vip">加入我们阅读所有教程/p>]
[p class="vip">加入我们阅读所有教程/p>]
2)find()
ind() 方法与 find_all() 类似,不同之处在于 find_all() 会将文档中所有符合条件的结果返回,而 find() 仅返回一个符合条件的结果,所以 find() 方法没有limit参数。使用示例如下:
from bs4 import BeautifulSoup
import re
html_doc = '''
加入我们阅读所有教程
百度一下
soso一下
- 01
- 02
- 03
'''
soup = BeautifulSoup(html_doc, 'html.parser')
print("---result101---")
result101 = soup.find('li') # 查询单个标签,与find_all("li", limit=1)一致
# 从结果可以看出,返回值为单个标签,并且没有被列表所包装。
print(result101)
print("---result102---")
#根据属性值正则匹配
print(soup.find(class_=re.compile('0')))
#attrs参数值
print(soup.find(attrs={'class':'vip'}))
# 使用 find() 时,如果没有找到查询标签会返回 None,而 find_all() 方法返回空列表。示例如下:
print("---result103---")
print(soup.find('bdi'))
print(soup.find_all('audio'))
# BS4 也为 find()提供了简化写法,如下所示:
print("---result104---")
#简化写法
print(soup.body.a)
#上面代码等价于
print(soup.find("body").find("a"))
# 获得文本,并添加分隔符,去掉两端空格:
print("---result105---")
result105 = soup.find('ul').get_text("----", strip=True)
print(result105)
输出如下:
---result101---
li class="cla-0" id="id-0">a href="/link1">01/a>/li>
---result102---
li class="cla-0" id="id-0">a href="/link1">01/a>/li>
p class="vip">加入我们阅读所有教程/p>
---result103---
None
[]
---result104---
a href="https://www.baidu.com" id="link4">百度一下/a>
a href="https://www.baidu.com" id="link4">百度一下/a>
---result105---
01----02----03
3) CSS选择器
BS4 支持大部分的 CSS 选择器,比如常见的标签选择器、类选择器、id 选择器,以及层级选择器。Beautiful Soup 提供了一个 select() 方法,通过向该方法中添加选择器,就可以在 HTML 文档中搜索到与之对应的内容。应用示例如下:
#coding:utf8
html_doc = """
"bs4测试案例网站"
加入我们阅读所有教程
百度一下
soso一下
- 01
- 02
- 03
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
#根据元素标签查找
print("---result201---")
print(soup.select('title'))
#根据属性选择器查找
print("---result202---")
print(soup.select('a[href]'))
#根据class类查找
print("---result203---")
print(soup.select('.vip'))
#后代节点查找
print("---result204---")
print(soup.select('html head title'))
#查找兄弟节点
print("---result205---")
print(soup.select('p + a'))
#根据id选择p标签的兄弟节点
print("---result206---")
print(soup.select('p ~ #link4'))
#nth-of-type(n)选择器,用于匹配同类型中的第n个同级兄弟元素
print("---result207---")
print(soup.select('p ~ a:nth-of-type(1)'))
#查找子节点
print("---result208---")
print(soup.select('ul > li'))
print(soup.select('ul > .cla-1'))
输出如下:
---result201---
[title>"bs4测试案例网站"/title>]
---result202---
[a href="https://www.baidu.com" id="link4">百度一下/a>, a href="https://www.sos.com">soso一下/a>, a href="/link1">01/a>, a href="/link2">02/a>, a href="/link3">03/a>]
---result203---
[p class="vip">加入我们阅读所有教程/p>]
---result204---
[title>"bs4测试案例网站"/title>]
---result205---
[a href="https://www.baidu.com" id="link4">百度一下/a>]
---result206---
[a href="https://www.baidu.com" id="link4">百度一下/a>]
---result207---
[a href="https://www.baidu.com" id="link4">百度一下/a>]
---result208---
[li class="cla-0" id="id-0">a href="/link1">01/a>/li>, li class="cla-1">a href="/link2">02/a>/li>, li>strong>a href="/link3">03/a>/strong>/li>]
[li class="cla-1">a href="/link2">02/a>/li>]
2.3 BS4综合案例
2.3.1 需求:爬取三国演义小说的所有章节和内容
import requests
from bs4 import BeautifulSoup
#需求:爬取三国演义小说的所有章节和内容
if __name__ == '__main__':
#UA伪装:将对应的User-Agent封装到一个字典中
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
#对首页的页面进行爬取
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
# page_text = requests.get(url=url,headers=headers).text
page_text = requests.get(url=url,headers=headers).content
#在首页中解析出章节的标题和详情页的url
#1、实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中
soup = BeautifulSoup(page_text,'html.parser')
li_list = soup.select("#main_left > div > div.book-mulu > ul>li")
base_url = "https://www.shicimingju.com"
num = 1
for i in li_list:
num += 1
if num >=5:
break
# 第一回·宴桃园豪杰三结义 斩黄巾英雄首立功
print(i.text)
detail_url = base_url+i.a['href']
page_text = requests.get(url=detail_url,headers=headers).content
soup = BeautifulSoup(page_text,'html.parser')
# #main_left > div.card.bookmark-list
temp = soup.select("#main_left > div.card.bookmark-list")
# ResultSet
for j in temp:
print(j.text)
# print(i)
print("*"*40)
输出为:
第一回·宴桃园豪杰三结义 斩黄巾英雄首立功
卷一
天功第一 天道变化,消长万汇,契地之力,乃有成尔。天贵
...
****************************************
第二回·张翼德怒鞭督邮 何国舅谋诛宦竖
第 二 回 贾夫人仙逝扬州城 冷子兴演说荣国府
诗云:
...
****************************************
```python
import requests
from bs4 import BeautifulSoup
#需求:爬取三国演义小说的所有章节和内容
if __name__ == '__main__':
#UA伪装:将对应的User-Agent封装到一个字典中
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
#对首页的页面进行爬取
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
# page_text = requests.get(url=url,headers=headers).text
page_text = requests.get(url=url,headers=headers).content
#在首页中解析出章节的标题和详情页的url
#1、实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中
soup = BeautifulSoup(page_text,'html.parser')
#解析章节标题和详情页的url
li_list = soup.select('.book-mulu > ul > li')
fp = open('./sanguo.txt','w',encoding='utf-8')
num = 0
for li in li_list:
num += 1
if num >5:
break
title = li.a.string
#详情页面的url
detail_url = 'http://www.shicimingju.com'+li.a['href']
#对详情页发起请求,解析出章节内容
detail_page_text = requests.get(url=detail_url,headers=headers).content
#解析出相关章节内容
detail_soup = BeautifulSoup(detail_page_text,'html.parser')
div_tag = detail_soup.find('div',class_='chapter_content')
#解析到了章节的内容
content = div_tag.text
fp.write(title+':'+content+'n')
print(title,'successful!')
输出为:
第一回·宴桃园豪杰三结义 斩黄巾英雄首立功 successful!
第二回·张翼德怒鞭督邮 何国舅谋诛宦竖 successful!
第三回·议温明董卓叱丁原 馈金珠李肃说吕布 successful!
第四回·废汉帝陈留践位 谋董贼孟德献刀 successful!
第五回·发矫诏诸镇应曹公 破关兵三英战吕布 successful!
...
2.3.2 爬取小说数据,并排错
from multiprocessing import get_context
from turtle import title
import requests
from bs4 import BeautifulSoup
import lxml
if __name__ == '__main__':
url = 'https://b.faloo.com/1190629.html'
headers={
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
page_text = requests.get(url= url,headers=headers).content
soup = BeautifulSoup(page_text,'lxml')
li_list = soup.select('.DivTd')
fp = open('./siheyuan.txt','w',encoding='utf-8')
num = 0
for DivTd in li_list:
num += 1
if num >5:
break
title = DivTd.a.string
new_url = 'https:' + DivTd.a['href']
new_page_text = requests.get(url= new_url,headers=headers).content
new_soup = BeautifulSoup(new_page_text,'lxml')
#content = new_soup.find('div',class_='noveContent')
content = new_soup.select('.noveContent')
for noveContent in content:
work = noveContent.p.string
fp.write(title+'n'+str(content)+'n')
print(title+'------抓取完成')
输出为:
001.新人报道------抓取完成
002.你咋不跟领导干一架呢------抓取完成
003.确定过眼神,就是要抓的人------抓取完成
004.领导,他又抓一个------抓取完成
005.搓搓这小子锐气------抓取完成
006.反扒队,你就是江晨?------抓取完成
007.莫伸手,伸手必被抓------抓取完成
008.贼王气得嗷嗷大哭------抓取完成
009.抓到耗子就是好猫------抓取完成
010.到底是哪里露出了马脚------抓取完成
011.就你们贼多?------抓取完成
012.近身格斗,不带怕的------抓取完成
013.分贼不均------抓取完成
014.这是指导工作去了------抓取完成
015.三千罪犯,我全都要------抓取完成
016.我怀疑你送人头------抓取完成
017.上个厕所就抓到一个?------抓取完成
018.这待遇,要馋哭了------抓取完成
019.又是要搞事情的节奏啊------抓取完成
020.师父给你定个小目标------抓取完成
021.先让你跑个红绿灯------抓取完成
022.这货是个人肉扫描机------抓取完成
023.这还带买一送一的?------抓取完成
024.这乞丐有问题?------抓取完成
025.抓捕体验极差------抓取完成
026.给我整不会了------抓取完成
027.这排场,真阔气------抓取完成
028.利刃-重案组------抓取完成
029.我能受这委屈?------抓取完成
030.这年轻人不讲武德------抓取完成
031.年纪不大,谱子不小------抓取完成
032.神秘的状元巷------抓取完成
033.当我挂白开的?------抓取完成
034.有些人慌了呀------抓取完成
035.你好,开门查水表------抓取完成
036.队友太秀,求安慰------抓取完成
037.组队刷副本------抓取完成
038.出了名的老实人------抓取完成
039.我天生就结巴------抓取完成
040.秀还是你秀------抓取完成
041.这就叫专业------抓取完成
042.垃圾桶的艺术------抓取完成
043.这就开张了?------抓取完成
044.抱大腿的觉悟(第五更)------抓取完成
045.时代变了?(第六章)------抓取完成
046.你敢拆我空调?(第七更)------抓取完成
047.三个硬茬子------抓取完成
048.朋友,露个面吧------抓取完成
049.你敢脸探草丛?------抓取完成
050.高效流水线------抓取完成
051.抓超载了(第五更)------抓取完成
052.伤害了多少人(加更一章)------抓取完成
053.还有论车的?(加更第二章)------抓取完成
054.来了一条收杆鱼------抓取完成
055.各位,等我回来------抓取完成
056.实在关不下了------抓取完成
057.枪来------抓取完成
058.我摊牌了,不装了------抓取完成
059.把那孩子带回来------抓取完成
060.让你拐个空气------抓取完成
061.枪声就是命令------抓取完成
062.开枪听个响------抓取完成
063.能跑赢我的,只有年龄(第五更)------抓取完成
064.他又来了------抓取完成
065.活生生撵我两个小时------抓取完成
066.我能让你出院?------抓取完成
067.战前晋升------抓取完成
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
ipython-input-45-4e73a887f2ec> in module>()
14 fp = open('./siheyuan.txt','w',encoding='utf-8')
15 for DivTd in li_list:
---> 16 title = DivTd.a.string
17 new_url = 'https:' + DivTd.a['href']
18 new_page_text = requests.get(url= new_url,headers=headers).content
AttributeError: 'NoneType' object has no attribute 'string'
