

在了解Nginx工作原理之前,我们先来了解下几个基本的概念 以及常见的I/O模型。
基本概念
-
同步:就是指调用方发起一个调用,在没有得到调用结果之前,该调用不返回。换句话说,也就是调用方发起一个调用后,一直等待被调用方返回结果,直到获取结果后才执行后续操作。
生活中的同步场景:等电梯:
- 按电梯方向键 –> 用户发起一个调用
- 电梯不在当前楼层,不做别的事情,继续等待 –> 一直等待结果
- 电梯到了,开门 –> 获取到结果
-
异步:就是指调用方发起一个调用,在没得到调用结果之前,返回该调用。换句话说,也就说调用方发起一个调用后,不等待被调用方返回结果,继续执行后续操作。这种情况下,被调用方一般会在处理完调用请求后,通过状态、通知、或者调用回调函数、接口(由调用方发起调用请求时按要求提供)来通知调用方处理结果。
生活中的异步场景:使用洗衣机洗衣服:
- 将待洗衣服放进洗衣机
- 用户按开始运行按钮 –> 用户发起一个调用
- 洗衣机开始洗衣服 –> 调用方开始处理请求
- 用户去做别的事情,比如打扫卫生、煮饭
- 洗衣机洗完衣服,发出鸣叫声 –> 通知调用方处理结果
-
阻塞:计算机中,主要指进程、线程的因为正在等待某个事件的完成,暂时不具备运行条件而停止运行的一种状态。也称为等待状态。
生活中的阻塞场景:交通堵车
- 道路宽敞,交通顺畅,汽车启动,快速行驶 –> 具备运行条件,运行状态
- 前方出现堵车,刹车,停止运行,等待交通畅顺 –> 失去运行条件,进入阻塞状态
- 交通顺畅,启动汽车,继续前行 –> 获取运行条件,恢复运行状态。
-
非阻塞:
阻塞的对立面,不多解释。
将以上几个概念进行组合,便可得到以下概念:
- 同步阻塞
- 同步非阻塞
- 异步非阻塞
总结
-
同步和异步关注的是消息通信机制,关注调用方发起调用后是否主动等待调用结果还是由被动等待被调用方通知。
-
阻塞和非阻塞关注的是调用方在等待调用结果时的状态。来看下以下这段话可能更好理解。
如果发起一个同步调用, 因为没有得到结果不返回, 那它毫无疑问就是被”阻塞“了(即调用方处于 “等待” 状态)。如果调用发出了以后就直接返回了, 毫无疑问, 调用方没有被“阻塞”。
举个例子:socket通信。
我们都知道,socket服务器进程建立监听后,需要执行
accept调用,来读取客户端建立连接请求,这个就是一个同步调用,此时,如果可以获取到请求,就会立即返回(同步非阻塞),但是此时,如果获取不到连接请求,那么该调用不会返回,进程会一直等待(同步阻塞),
常见I/O模型
基础知识
内核态/用户态
操作系统为了保护自己,设计了用户态、内核态两个状态。应用程序一般工作在用户态,当调用一些底层操作的时候(比如 I/O 操作),就需要切换到内核态才可以进行。
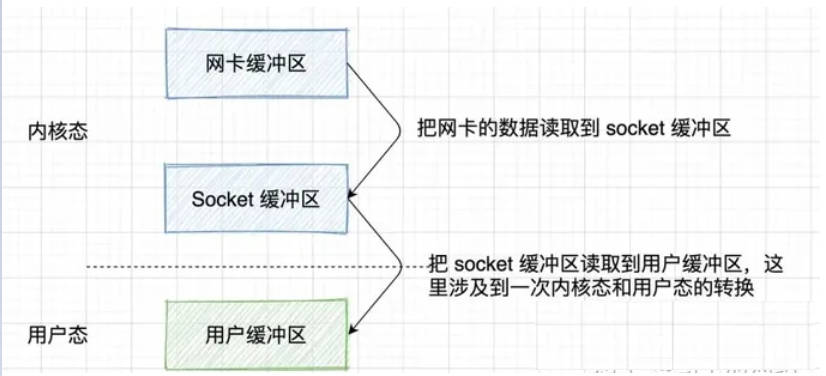
应用程序从网络中接收数据的大致流程
服务器从网络接收的大致流程如下:
- 数据通过计算机网络来到了网卡
- 把网卡的数据读取到 socket 缓冲区
- 把 socket 缓冲区读取到用户缓冲区,之后应用程序就可以使用了
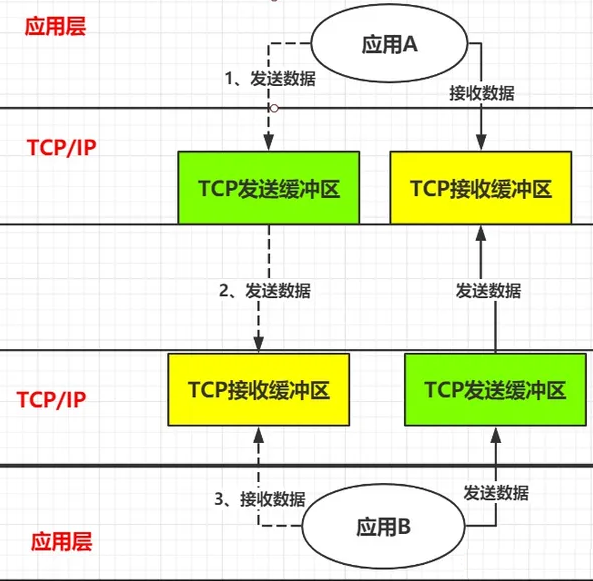
以两个应用程序通讯为例,当“A”向”B” 发送一条消息,大致会经过以下流程:
第一步: 应用A把消息发送到 TCP发送缓冲区。
第二步: TCP发送缓冲区再把消息发送出去,经过网络传递后,消息会发送到B服务器的TCP接收缓冲区。
第三步: B再从TCP接收缓冲区去读取属于自己的数据。
因为应用之间发送消息是间断性的,所以,当应用尝试从TCP缓冲区接收数据时,并不一定能读取到数据,此外,
TCP缓冲区是有大小限制的,当缓冲区因为写入速率过快被“填满”时,也无法继续写入数据,这就是为啥会有I/O阻塞的原因之一(除此之外,数据从socket缓冲区拷贝到用户空间也是需要时间的,即也可能造成阻塞)。
I/O类型划分
根据是否造成阻塞,可以将I/O类型分成阻塞和非阻塞:
-
阻塞I/O
指在进行 I/O 操作时,如果数据没有准备好或无法立即读取/写入,程序会被阻塞(阻塞调用)等待数据准备好或操作完成,然后才能继续执行后续的操作。阻塞 I/O 是一种同步 I/O 操作。
-
非阻塞IO
是指在进行 I/O 操作时,如果数据没有准备好或无法立即读取/写入,程序会立即返回,并继续执行后续的操作。在非阻塞 I/O 中,程序不会等待 I/O 操作的完成,而是立即返回,继续执行其他任务,然后通过轮询或选择函数(如 select、poll、epoll 等)来检查是否有 I/O 可用。非阻塞 I/O 是一种异步 I/O 操作。
根据是否同步,可以将I/O类型划分成同步和异步:
-
同步IO
它是指程序在进行 I/O 操作时,必须等待 I/O 完成后才能继续执行后续的操作。
-
异步I/O
是指程序发起 I/O 请求后进行 I/O 操作时,不需要等待 I/O 操作的完成,继续执行其他任务,是一种非阻塞的 I/O 操作方式。当 I/O 操作完成后,系统会通知程序,程序再去获取或处理完成的 I/O 结果。
异步I/O常见的2种实现方式:
-
callback 回调函数
通过注册回调函数,在 I/O 操作完成时由操作系统或库调用该函数处理结果。
-
信号(signal)
通过使用信号机制,在 I/O 操作完成时由操作系统发送相应的信号给进程,进程通过信号处理函数来处理 I/O 完成的事件。
-
接下来,就上图B应用从TCP缓冲区读取数据为例,来了解下常见的几种I/O模型。
阻塞型I/O
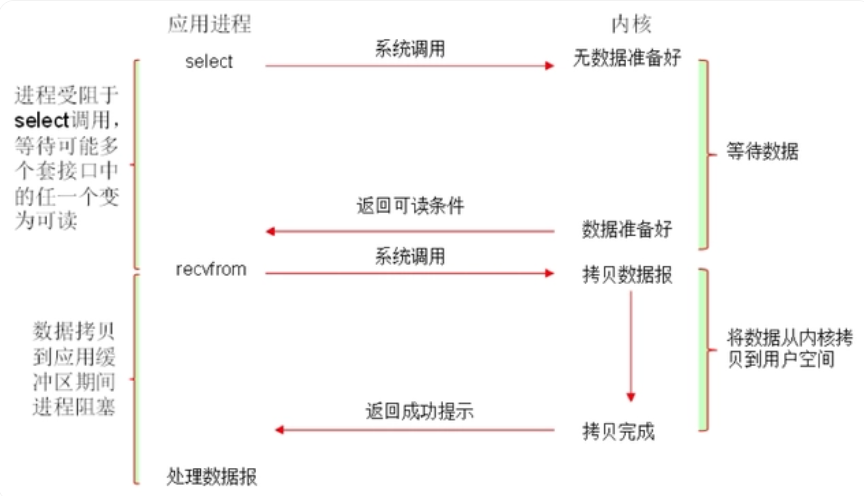
在应用调用recvfrom读取数据时,其系统调用直到数据包到达且被复制到应用缓冲区中或者发送错误时才返回,在此期间一直会等待,即被阻塞

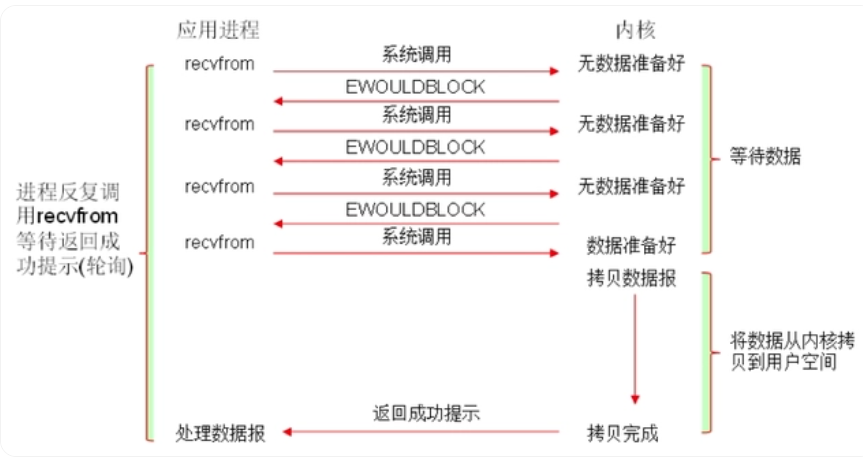
非阻塞型I/O
在应用调用recvfrom读取数据时,如果该缓冲区没有数据的话,系统会直接返回一个EWOULDBLOCK错误,不会让应用一直等待。
在没有数据的时候会即刻返回错误标识,那也意味着如果应用要读取数据就需要不断的调用recvfrom请求,直到读取到它数据要的数据为止。
复用型I/O
如果在并发的环境下,可能会N个人向应用B发送消息,这种情况下我们的应用就必须创建多个线程去读取数据,每个线程都会自己调用recvfrom 去读取数据。那么此时情况可能如下图:
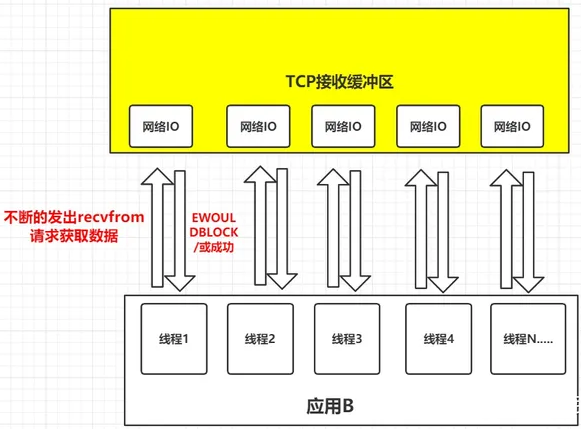
如上图,并发情况下服务器很可能一瞬间会收到几十上百万的请求,这种情况下应用B就需要创建几十上百万的线程去读取数据,同时又因为应用线程是不知道什么时候会有数据读取,为了保证消息能及时读取到,那么这些线程自己必须不断的向内核发送recvfrom 请求来读取数据;
那么问题来了,这么多的线程不断调用recvfrom 请求数据,且不说服务器能不能扛得住这么多线程,就算扛得住那么很明显这种方式是不是太浪费资源了。
所以,有人就提出了一个思路,能不能提供一种方式,可以由一个线程监控多个通信socket(每个socket对应一个文件描述符fd),这样就可以只需要一个或几个线程就可以完成数据状态询问的操作,当有数据准备就绪之后再分配对应的线程去读取数据,这么做就可以节省出大量的线程资源出来,这个就是I/O复用模型的思路,如下图
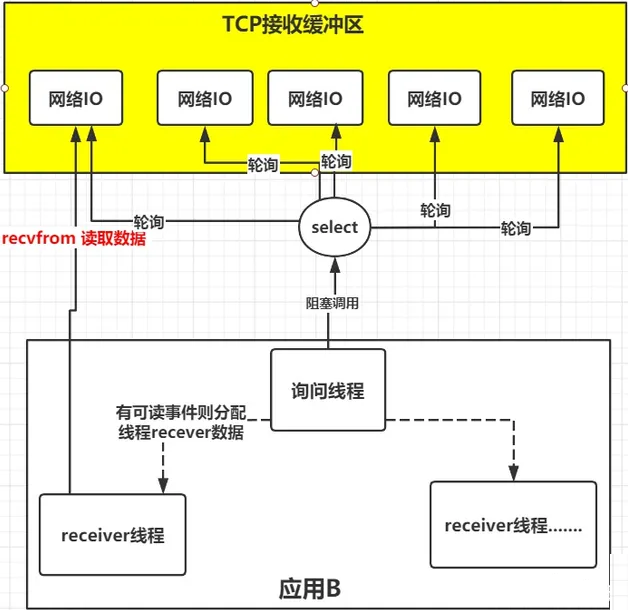
进程通过将一个或多个fd传递给select,阻塞在select操作上,select帮我们侦测多个fd是否准备就绪,当有fd准备就绪时,select返回数据可读状态,应用程序再调用recvfrom读取数据。
说明:复用I/O的基本思路就是通过select或poll、epoll 来监控多fd ,来达到不必为每个fd创建一个对应的监控线程,从而减少线程资源创建的目的。
信号驱动型I/O
复用I/O模型解决了一个线程可以监控多个fd的问题,但是select是采用轮询的方式来监控多个fd的,通过不断的轮询fd的可读状态来知道是否有可读的数据,而无脑的轮询就显得有点暴力,因为大部分情况下的轮询都是无效的,所以有人就想,能不能不要我总是去问你是否数据准备就绪,能不能我发出请求后等你数据准备好了就通知我,所以就衍生了信号驱动I/O模型。
于是信号驱动I/O不是用循环请求询问的方式去监控数据就绪状态,而是在调用sigaction时候建立一个SIGIO的信号联系,当内核数据准备好之后再通过SIGIO信号通知线程数据准备好后的可读状态,当线程收到可读状态的信号后,此时再向内核发起recvfrom读取数据的请求,因为信号驱动I/O的模型下应用线程在发出信号监控后即可返回,不会阻塞,所以这样的方式下,一个应用线程也可以同时监控多个fd,如下图。
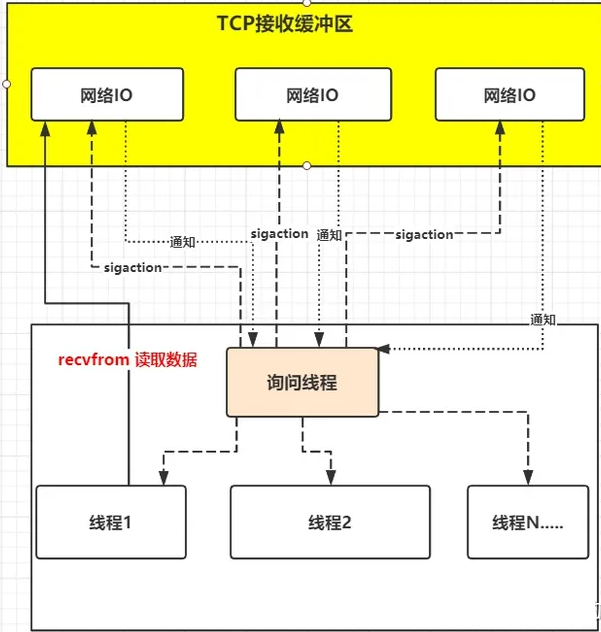
首先开启套接口信号驱动I/O功能,并通过系统调用sigaction执行一个信号处理函数,此时请求即刻返回,当数据准备就绪时,就生成对应进程的SIGIO信号,通过信号回调通知应用线程调用recvfrom来读取数据
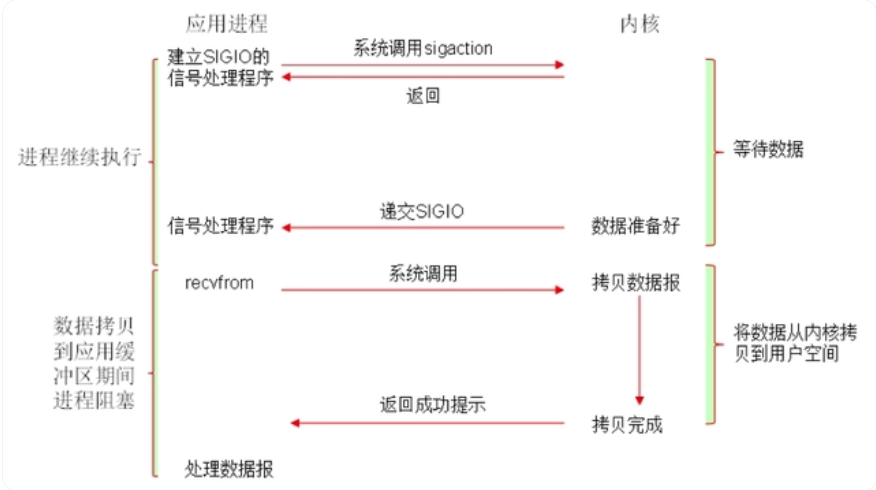
说明:信号驱动 I/O 和多路复用型I/O的主要区别在于:信号驱动型 I/O 的底层实现机制是事件通知,而多路复型用 I/O 的底层实现机制是遍历+回调。
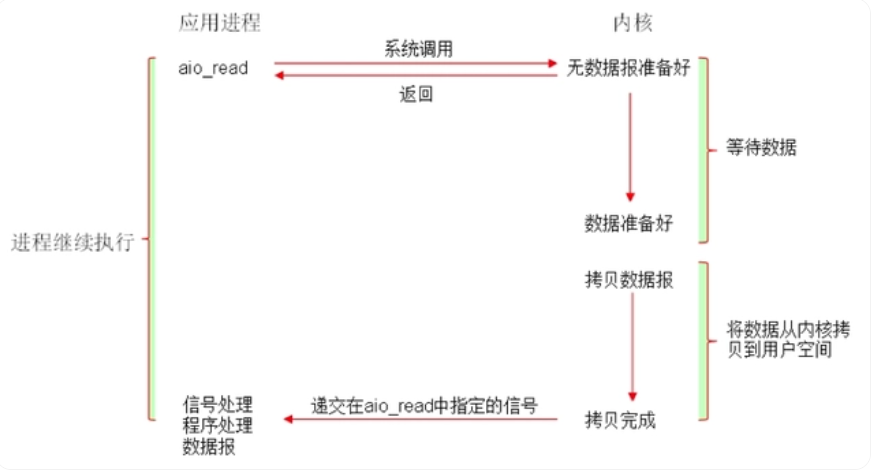
异步I/O
不管是I/O复用还是信号驱动,要读取一个数据总是要发起两阶段的请求,第一次发送select请求,询问数据状态是否准备好,第二次发送recevform请求读取数据。
有没有有一种方式,我只要发送一个请求我告诉内核我要读取数据,然后我就什么都不管了,然后内核去帮我去完成剩下的所有事情?
于是有人设计了一种方案,应用只需要向内核发送一个read 请求,告诉内核它要读取数据后即刻返回;内核收到请求后会建立一个信号联系,当数据准备就绪,内核会主动把数据从内核复制到用户空间,等所有操作都完成之后,内核会发起一个通知告诉应用,我们称这种模式为异步IO模型。
Nginx工作原理
众所周知,Nginx采用多进程和异步非阻塞事件驱动模型对外提供服务。
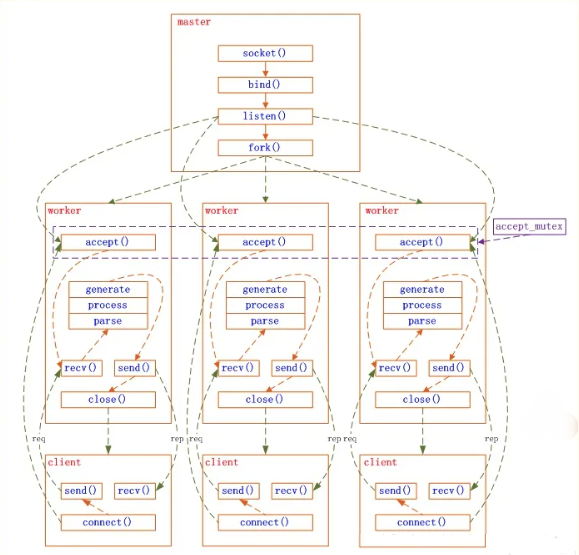
多进程机制
生产环境,Nginx服务实现基本采用的都是多进程模式:一个master进程和N个worker进程(其中N>=1,虽然可以配置为0,但是没有意义),每个worker进程只包含一个主线程,进程间通过共享内存的方式,来共享缓存数据、会话持久性数据等
master 进程并不处理网络请求,主要用于管理worker进程,具体包括以下主要功能:
-
接收来自外界的信号。
-
向各worker进程发送信号。
-
监控woker进程的运行状态
当worker进程因为出现异常而退出时,自动重新启动新的worker进程
-
停启用worker进程。
当woker进程退出后(异常情况下),master会自动启动新的woker进程。
而worker 进程则负责处理网络请求与响应。每个请求只会在一个 worker 进程中处理,每个worker进程,只能处理自己接收的请求。
Nginx 在启动时,会先解析配置文件,得到需要监听的IP地址和端口,然后在 master 进程中创建socket,并绑定要监听的IP地址和端口,再执行端口监听,接着fork worker进程(关于fork介绍参见下文),由于worker进程是由master进程fork出来的,所以worker进程将继承master进程的socket文件描述符。worker进程创建后,都会执行accept等待并提取全连接队列中的连接请求。所以,当有连接请求时,所有worker进程都会收到通知,并“争着”与客户端建立连接,这就是所谓的“惊群现象”。但是由于只有一个连接请求,所以,同时只会有一个worker进程能成功建立连接,并创建已连接描述符,然后通过已连接描述符来与客户端通信,读取请求 -> 解析请求 -> 处理请求 -> 返回响应给客户端 ,最后才断开连接 ,未成功建立连接的请求将再次被挂起。
这就好比你往一群正在睡觉的鸽子中间扔一块较大的食物,瞬间惊动所有的鸽子,然后所有鸽子都去争抢那块食物,最终只有一只鸽子抢到食物,没抢到食物的鸽子回去继续睡觉,等待下一块食物到来。这样,每扔一块食物,都会惊动所有的鸽子,即为惊群。
大量的进程被激活又挂起,显然,在请求连接数量比较低的情况下,这种方式会比较消耗系统资源。为了避免这种惊群效应,Nginx提供了一个accept_mutex指令,将设置指令值为on,可以确保工作进程按序获取连接。具体实现其实是添加了一个全局互斥锁,每个工作进程在执行accept调用之前先去申请锁,申请到则继续处理,获取不到则放弃accept, 这样就保证了同一时刻只有一个work进程能accept连接,避免了惊群问题。
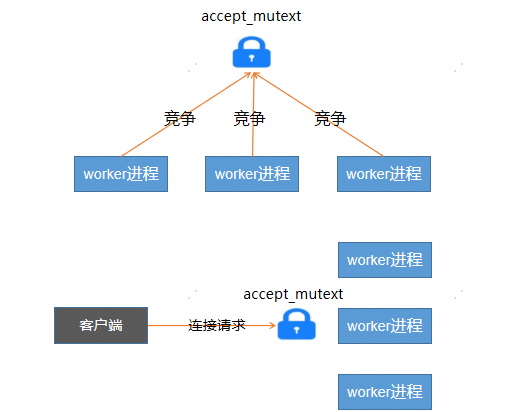
worker进程会竞争监听客户端的连接请求:这种方式可能会带来一个问题,就是可能所有的请求都被一个worker进程给竞争获取了,导致其他进程都比较空闲,而某一个进程会处于忙碌的状态,这种状态可能还会导致无法及时响应连接而丢弃掉本有能力处理的请求。针对这种现象,Nginx使用了一个名为ngx_accept_disabled的变量控制worker进程是否去竞争获取accept_mutex锁。
Nginx代码(ngx_event_accept.c)实现中,ngx_accept_disabled被赋值为nginx单个进程的所有连接总数/8,减去剩余空闲连接数量,其中,单个进程的所有连接总数即为nginx.conf里配置的worker_connections值。
ngx_accept_disabled = ngx_cycle->connection_n / 8
- ngx_cycle->free_connection_n;
ngx_event.c
void ngx_process_events_and_timers(ngx_cycle_t *cycle)
{
# 略...
if (ngx_use_accept_mutex) {
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--;
} else {
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
} else {
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
}
# ...略
}
由以上代码可知,当且仅当剩余连接数小于总连接数的八分之一时,ngx_accept_disabled值才大于0。当ngx_accept_disabled大于0时,不会去获取accept_mutex锁,也就是等于让出获取连接的机会,很显然可以看出,当空闲连接越少时,ngx_accept_disable越大,于是让出的机会就越多,这样其它进程获取锁的机会也就越大,就这样,实现不同worker之间的负载均衡。
注意:Nginx 1.11.3版本之前,accept_mutex指令默认值为on,1.11.3版本之后默认为off,即默认关闭。
支持EPOLLEXCLUSIVE标识的系统(Linux 4.5+,glibc 2.24 )或者listen指令中使用reuseport选项时,不必开启accept_mutex。
EPOLLEXCLUSIVE说明:
为被附加到目标文件描述符fd的epfd文件描述符设置独占唤醒模式。因此,当一个事件发生,并且多个epfd文件描述符附加到同一个使用EPOLLEXCLUSIVE的目标文件时,一个或多个epfd将收到具有epoll_wait(2)的事件。此场景默认(当未设置EPOLLEXCLUSIVE时)所有epfd接收事件。
EPOLLEXCLUSIVE只能与 EPOLL_CTL_ADD操作一起指定。
说明:EPOLLEXCLUSIVE 功能支持的实现代码中也用到了ngx_accept_disabled变量,如下
ngx_event.c
static void
ngx_reorder_accept_events(ngx_listening_t *ls)
{
ngx_connection_t *c;
/*
* Linux with EPOLLEXCLUSIVE usually notifies only the process which
* was first to add the listening socket to the epoll instance. As
* a result most of the connections are handled by the first worker
* process. To fix this, we re-add the socket periodically, so other
* workers will get a chance to accept connections.
*/
if (!ngx_use_exclusive_accept) {
return;
}
#if (NGX_HAVE_REUSEPORT)
if (ls->reuseport) {
return;
}
#endif
c = ls->connection;
if (c->requests++ % 16 != 0
&& ngx_accept_disabled read, NGX_READ_EVENT, NGX_DISABLE_EVENT)
== NGX_ERROR)
{
return;
}
if (ngx_add_event(c->read, NGX_READ_EVENT, NGX_EXCLUSIVE_EVENT)
== NGX_ERROR)
{
return;
}
}
#endif
reuseport配置示例:
http {
server {
listen 80 reuseport
...
}
}
reuseport选项说明
此参数 (Nginx 1.9.1)指示为每个工作进程创建一个单独的侦听套接字(在Linux 3.9+和DragonFly BSD上使用SO_REUSEPORT套接字选项,或在FreeBSD 12+上使用SO_REUSEPORT_LB),允许系统内核在工作进程之间分配传入连接。这目前仅适用于Linux 3.9+、DragonFly BSD和FreeBSD 12+(1.15.1)。
fork简介
什么是fork?fork是复制进程的函数,程序开始运行时会产生一个进程,当这个进程(代码)执行到fork()时,就会通过复制当前进程(包括代码、数据等)来创建一个新进程,我们称之为子进程,而当前被复制的进程我们称之为父进程,此时父子进程是共存的,他们一起向下执行代码。除了少部分内容(比如进程ID),子进程和父进程几乎完全相同,可以做完全相同的事情,当然,如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
Nginx进程模型
异步非阻塞事件驱动模型
事件驱动模型概述
所谓事件驱动就是指在持续事务管理过程中,进行决策的一种策略,即根据当前出现的事件,调动可用资源,执行相关任务,使不断出现的问题得以解决,防止事务堆积。
在计算机编程领域,事件驱动模型对应一种程序设计方式,该设计的基本结构一般由事件收集器、事件发送器和事件处理器组成。其中,事件收集器专门负责收集所有事件,包括来自用户的(如鼠标点击、键盘输入事件等)、来自硬件的(如时钟事件等)和来自软件的(如操作系统、应用程序本身等)。事件发送器负责将收集器收集到的事件分发到目标对象中。事件处理器做具体的事件响应工作。
事件驱动模型一般会采用这种实现思路:设计一个事件循环,不断地检查目前要处理的事件信息,然后使用事件发送器将待处理事件传递给事件处理器进行处理(事件处理器要事先在事件收集器里注册自己想要处理的事件)。
Nginx中的事件驱动模型
为什么几个worker进程能支持高并发的请求呢?这得益于Nginx采用的异步非阻塞事驱动模型,毫无例外。
对于传统的web服务器(比如Apache)而言,其所采用的事件驱动往往局限于TCP连接建立、关闭事件上,一个连接建立以后,在其关闭之前的所有操作都不再是事件驱动,而是退化成顺序执行每个操作的批处理模式,这样每个请求在连接建立后都将始终占用着系统资源,直到关闭才会释放资源。其事件消费者一般是一个线程、进程。
传统的web服务器不同,Nginx将一个请求划分为多个阶段来异步处理,每个阶段只处理请求的一部分,如果请求的这一部分发生阻塞,Nginx不会等待,它会处理其他请求的某一部分。每个阶段对应不同的事件,都采用事件驱动的方式进行处理。整个执行过程中,Nginx不会为每个消费事件创建一个进程或线程,其事件消费者只能是某个模块,仅在被调用时占用当前进程资源,这样避免了由于创建大量线程、进程带来的频繁上下文切换繁,从而避免过高的CPU资源占用,同时也降低了对服务器其它资源(比如内存)的占用。
由于Nginx工作性质决定了每个请求的大部份生命都是在网络传输中,实际上花费在服务器自身的时间片不多,这就是分阶段异步处理请求的情况下,为数不多的进程就能解决高并发的秘密所在。
Nginx支持多种事件驱动模型并在创建worker进程时,初始化对应的事件驱动模型,不指定使用特定模型的情况下,如果平台支持多种模型,Nginx通常会自动选择最高效的模型,如果需要,也可以使用use指令显式指定使用的模型。以下是支持的模型(库):
-
select— 标准方法。Nginx编译过程中如果没有其他更效率事件驱动模型库,它将自动编译该库。可以使用--with-select_module和--without-select_module两个参数强制启用或禁用此模块的构建。 -
poll— 标准方法。Nginx编译过程中如果没有其他更效率事件驱动模型库,它将自动编译该库。可以使用--with-poll_module和--without-poll_module两个参数强制启用或禁用此模块的构建。 -
kqueue— 用于FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0, 和macOS的高效方法。 -
epoll— 用于Linux 2.6+的高效方法1.11.3版本开始,支持
EPOLLRDHUP(Linux 2.6.17, glibc 2.8) 和EPOLLEXCLUSIVE(Linux 4.5, glibc 2.24) 标识一些旧发行版本比如SuSE 8.2提供添加epoll支持的补丁到2.4内核。
-
/dev/poll— 用于Solaris 7 11/99+, HP/UX 11.22+ (eventport), IRIX 6.5.15+, 和Tru64 UNIX 5.1A+的高效方法。 -
eventport— event port方法用于 Solaris 10+ (推荐使用/dev/poll替代该方法)。
select,poll,epoll是较为常见的3种模型,其中epoll最效率,是poll的增强版,是Nginx的默认事件驱动模型,也是Nginx能支持高并发的关键因素。相对于select、poll来说,具有以下优点:
-
支持一个进程打开最大文件描述符数量
-
I/O效率不随文件描述符数量的增加而线性下降
poll和select都是创建一个待处理事件列表,然后把这个列表发给内核,返回的时候,再去轮询检查这个列表。以判断这个事件是否发生。在描述符太多的情况下,效率就明显低下了。而
epoll则把事件描述符列表的管理交给内核。一旦有某个事件发生,内核将发生事件的事件描述符交给Nginx的进程,而不是将整个事件描述符列表交给进程,让进程去轮询具体是哪个描述符。epoll避免了轮询整个事件描述符列表,所以效率更高。 -
使用mmap加速内核与用户空间的消息传递
从流程上来讲,epoll模型的使用主要分为三步:
- 创建
epoll实例的句柄 - 往句柄中添加需要监听的事件文件描述符
- 等待需要监听的文件描述符上对应的事件的触发。
这里的句柄可以简单的理解为一个eventpoll结构体实例,这个结构体中有一个红黑树和一个队列,红黑树中主要存储需要监听的文件描述符,而队列则是存储所监听的文件描述符中发生的目标事件。
Nginx每个worker进程都维护了一个epoll句柄,在创建完句柄之后,会通过epoll_ctl()方法,将监听socket对应的文件描述符添加到句柄中(对应eventpoll红黑树中的一个节点)。此外,调用epoll_ctl()方法添加文件描述符之后,会将其与相应的设备(网卡)进行关联,当设备驱动发生某个事件时,就会回调当前文件描述符的回调方法ep_poll_callback(),生成一个事件,并且将该事件添加到eventpoll的事件队列中。最后,事件循环中通过调用epoll_wait()方法从epoll句柄中获取对应的事件(本质就是检查eventpoll的事件队列是否为空,如果有事件则将其返回,否则就会等待事件的发生)。这里获取的事件一般都是accept事件,即接收到客户端请求,在处理这个事件的时候,会获取与客户端通信用的已连接文件描述符,并继续通过epoll_ctl()方法将其添加到当前的epoll句柄中,继续通过epoll_wait()方法等待其数据的读取和写入事件以接收和发送数据给客户端。
Nginx热部署原理
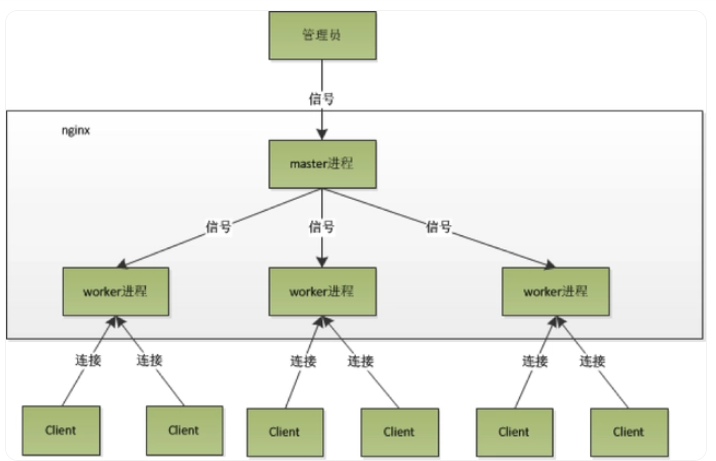
如上图,master进程充当整个进程组与用户的交互接口,可以通过向master进程发送信号来实现相关操作。比如执行kill -HUP masterPID命令,给master进程发送KILL -HUP信号,告诉Nginx,平滑重启nginx,要求重启过程中不能中断服务。
master进程接收到KILL -HUP信号后会执行以下操作:
- 重新加载配置文件
- 启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。
- 新的worker在启动后,就开始接收新的请求,而老的worker进程在收到来自master的信号后,不再接收新的请求,并继续处理当前进程已接收的请求直至所有请求处理完成,最后退出。
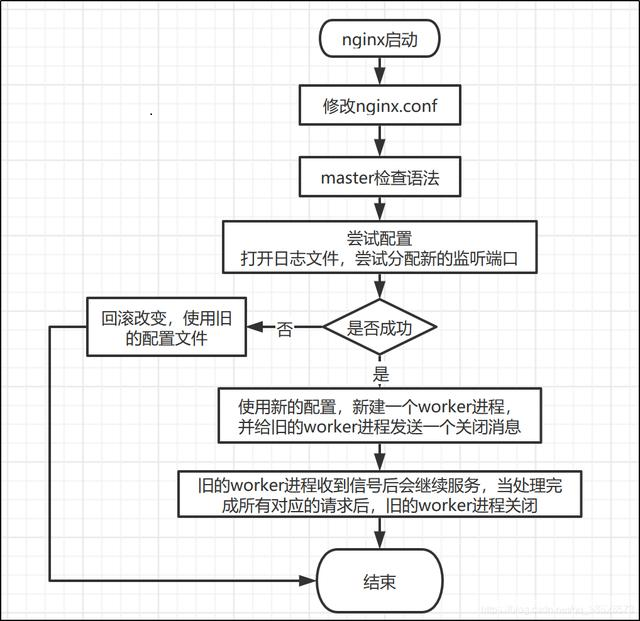
直接给master进程发送信号,这是比较传统的操作方式,Nginx 0.8本之后,引入了一系列命令行参数,来方便我们管理Nginx。比如,nginx -s reload,平滑重启nginx,nginx -s stop,停止运行Nginx。命令本质也是给master进程发送信号。
KILL -HUP简介
在Linux中,Kill 命令用于发送信号给进程,其中SIGHUP代表Hangup,在UNIX系统中,这个信号通常被用来重新读配置文件,而对于一些进程而言,重新读取配置文件之后,它们会尝试将自己的行为变为默认行为,而不需要重启或重载。
Kill -HUP,简单理解就是发送给进程的一种信号,它能够让进程重读它的配置文件并且重新打开它的日志文件。在发送Kill -HUP信号时,操作系统会把SIGHUP信号发送到进程表,然后内核会从内核级别的进程表中查找那些进程已经注册了SIGHUP信号。如果它们对SIGHUP信号进行了处理或者忽略了该信号,则不做处理,否则内核就会把SIGHUP信号发送给进程。
当某个进程接收到SIGHUP信号后,它会根据自己的处理方式来处理该信号,通常包括:如果进程正在运行,则进程暂停,然后运行信号处理程序;如果进程处于休眠状态,则先唤醒进程,再运行信号处理程序
