

文章目录
- 🍔什么是缓存穿透
- 🎄解决办法
-
- ⭐缓存空值处理
-
- 🎈优点
- 🎈缺点
- 🎍代码实现
- ⭐布隆过滤器
-
- 🎍代码实现

🍔什么是缓存穿透
缓存穿透是指在使用缓存机制时,大量的请求无法从缓存中获取到结果,导致请求都要直接访问后端存储系统,从而增加了系统的负载和响应时间。
通常的缓存机制是将请求的结果缓存在内存或其他高速存储介质中,当相同的请求再次到达时,可以直接从缓存中获取结果,避免了从后端存储系统中读取数据的开销。
然而,在缓存穿透的情况下,由于大量请求所对应的数据在缓存中不存在,每个请求都需要直接访问后端存储系统。这可能是因为恶意请求、频繁的随机查询或者查询不存在的数据等原因。
缓存穿透可能导致以下问题:
- 性能下降:由于大量的请求都要直接访问后端存储系统,系统的响应时间会显著增加,导致性能下降。
- 增加负载:后端存储系统承受了大量无效请求的压力,增加了系统的负载,可能导致后端存储系统的性能问题。
- 安全风险:缓存穿透可能为恶意请求提供了一种绕过缓存机制直接访问后端存储系统的途径,可能导致安全漏洞或数据泄露。
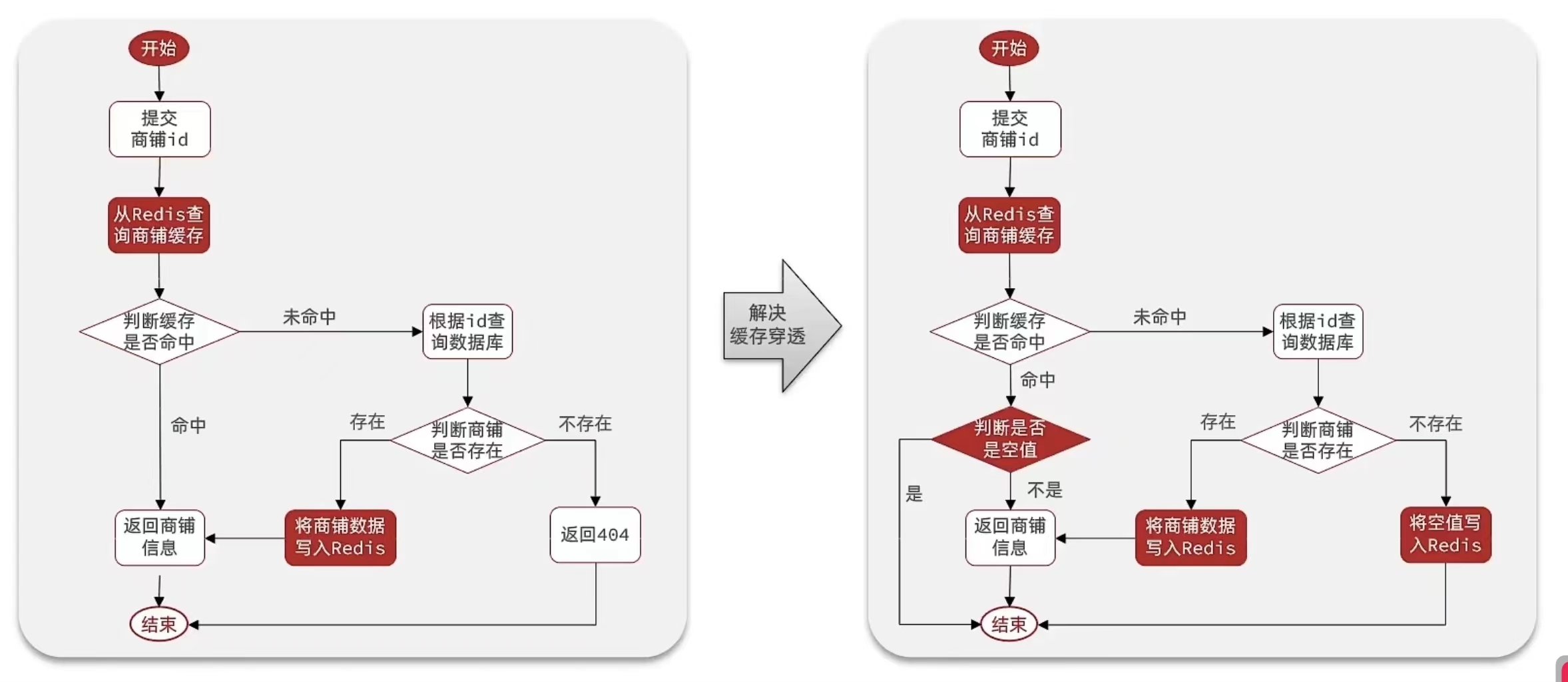
🎄解决办法
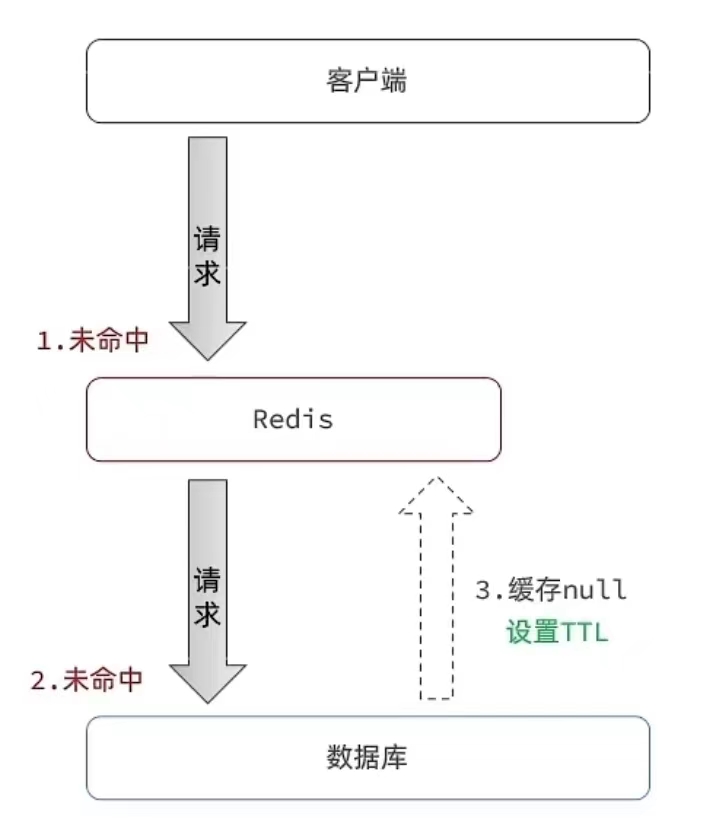
- 缓存空值处理:对于不存在的数据,也将其缓存起来,但缓存的值为空,这样下次再有相同的请求到达时,可以直接返回空结果,避免对后端存储系统的重复查询。
- 布隆过滤器(Bloom Filter):使用布隆过滤器可以快速判断请求所对应的数据是否存在于缓存中,从而减少对后端存储系统的无效查询。
⭐缓存空值处理
🎈优点
实现简单,维护方便
🎈缺点
- 额外的内存消耗
- 可能造成短期数据的不一致
🎍代码实现
@Service
public class ShopServiceImpl extends ServiceImplShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Resource
private CacheClient cacheClient;
@Override
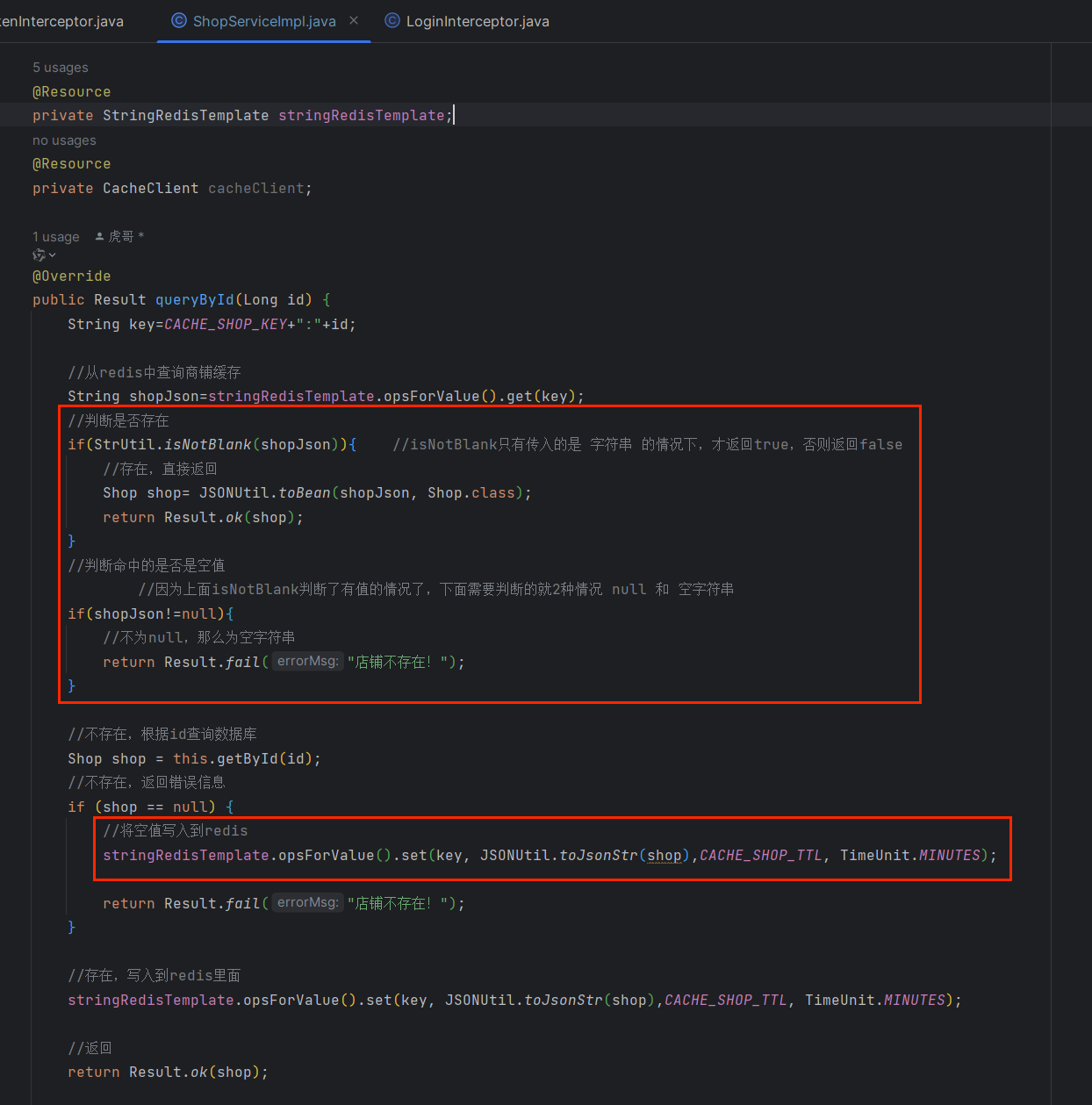
public Result queryById(Long id) {
String key=CACHE_SHOP_KEY+":"+id;
//从redis中查询商铺缓存
String shopJson=stringRedisTemplate.opsForValue().get(key);
//判断是否存在
if(StrUtil.isNotBlank(shopJson)){ //isNotBlank只有传入的是 字符串 的情况下,才返回true,否则返回false
//存在,直接返回
Shop shop= JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
//判断命中的是否是空值
//因为上面isNotBlank判断了有值的情况了,下面需要判断的就2种情况 null 和 空字符串
if(shopJson!=null){
//不为null,那么为空字符串
return Result.fail("店铺不存在!");
}
//不存在,根据id查询数据库
Shop shop = this.getById(id);
//不存在,返回错误信息
if (shop == null) {
//将空值写入到redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.fail("店铺不存在!");
}
//存在,写入到redis里面
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
//返回
return Result.ok(shop);
}
⭐布隆过滤器
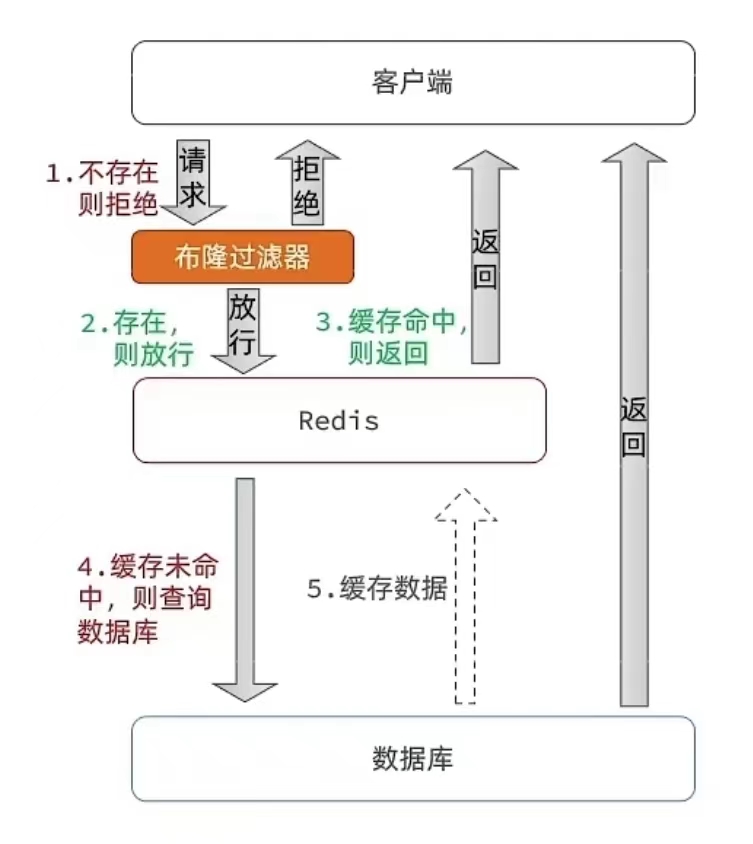
布隆过滤器是一种空间效率高、适合大规模数据的概率型数据结构,用于判断一个元素是否可能存在于一个集合中。布隆过滤器由一个位数组和多个哈希函数组成。其核心思想是通过多个哈希函数对输入元素进行映射,将元素映射到位数组的多个位置上,从而实现元素的快速查找。
假设布隆过滤器使用一个长度为 m 的位数组和 k 个独立的哈希函数,初始时所有位都置为 0。当要插入一个元素时,将该元素经过 k 个哈希函数得到的 k 个哈希值作为索引,在位数组中将这 k 个位置的值置为 1。当要查询一个元素时,同样将该元素经过 k 个哈希函数得到的 k 个哈希值作为索引,并检查对应的位数组位置是否都为 1,若有任何一个位置为 0,则可以确定该元素不存在于集合中;若都为 1,则该元素可能存在于集合中。
布隆过滤器的优势在于具有较高的空间效率和查询效率,适合大规模数据的情况。由于使用了多个哈希函数,可以有效减少冲突的概率,降低误判率。然而,布隆过滤器也存在一定的缺陷,即可能出现误判(即判断某个元素存在于集合中,但实际上并不存在),这是由于不同元素经过哈希函数映射后的索引可能存在冲突。因此,在使用布隆过滤器时需要权衡误判率和空间利用率。
总的来说,布隆过滤器通过位数组和多个哈希函数实现了高效的元素判断,是一种适合大规模数据场景下的概率型数据结构
🎍代码实现
实现引入依赖
dependency>
groupId>com.google.guava/groupId>
artifactId>guava/artifactId>
version>29.0-jre/version>
/dependency>
配置启动类
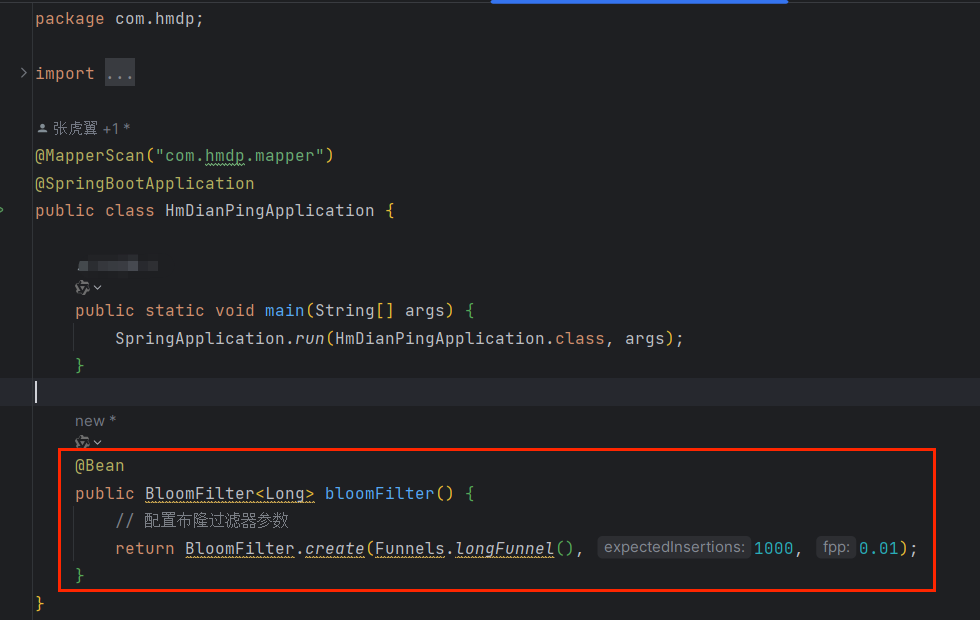
编写核心代码
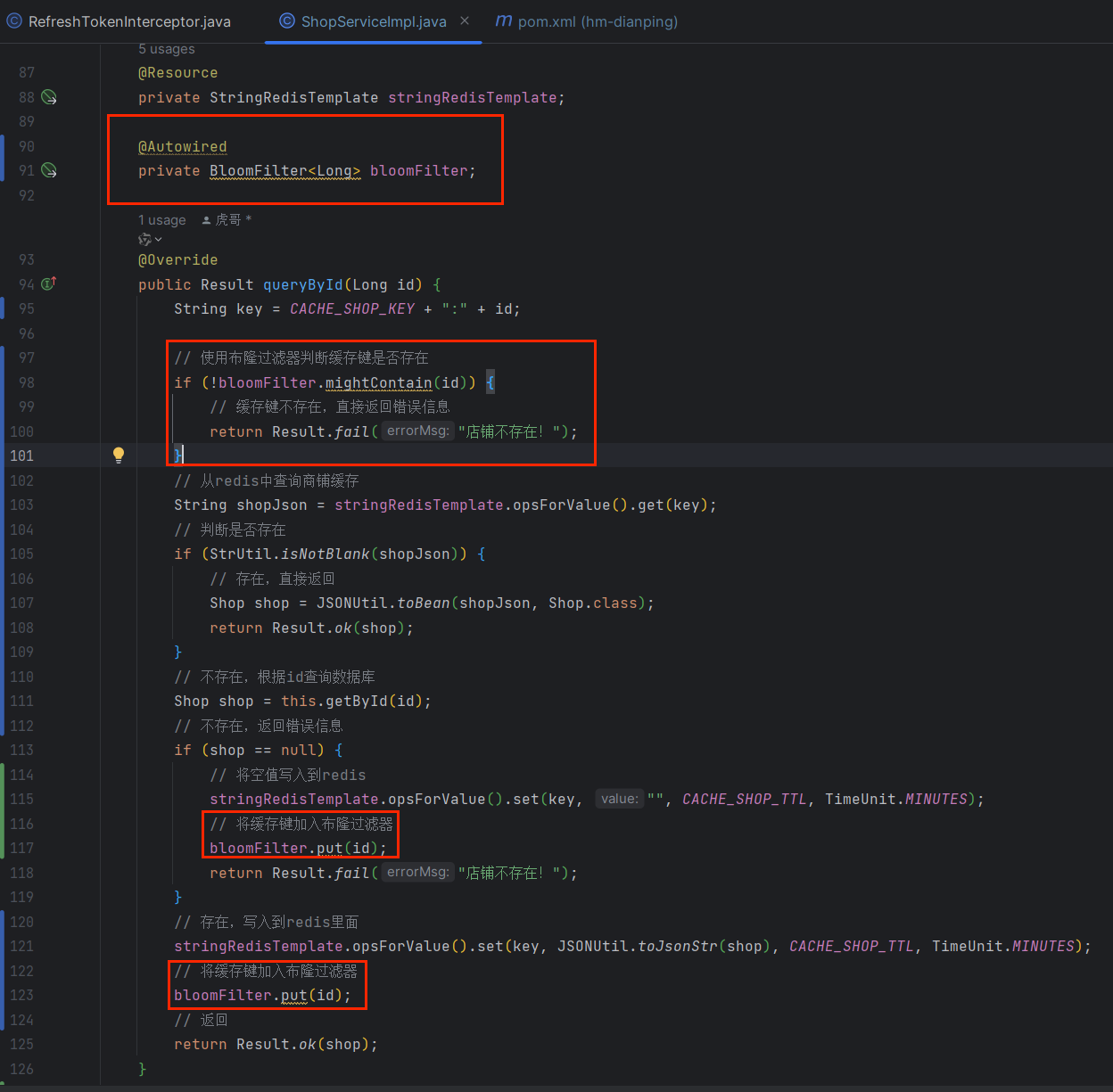
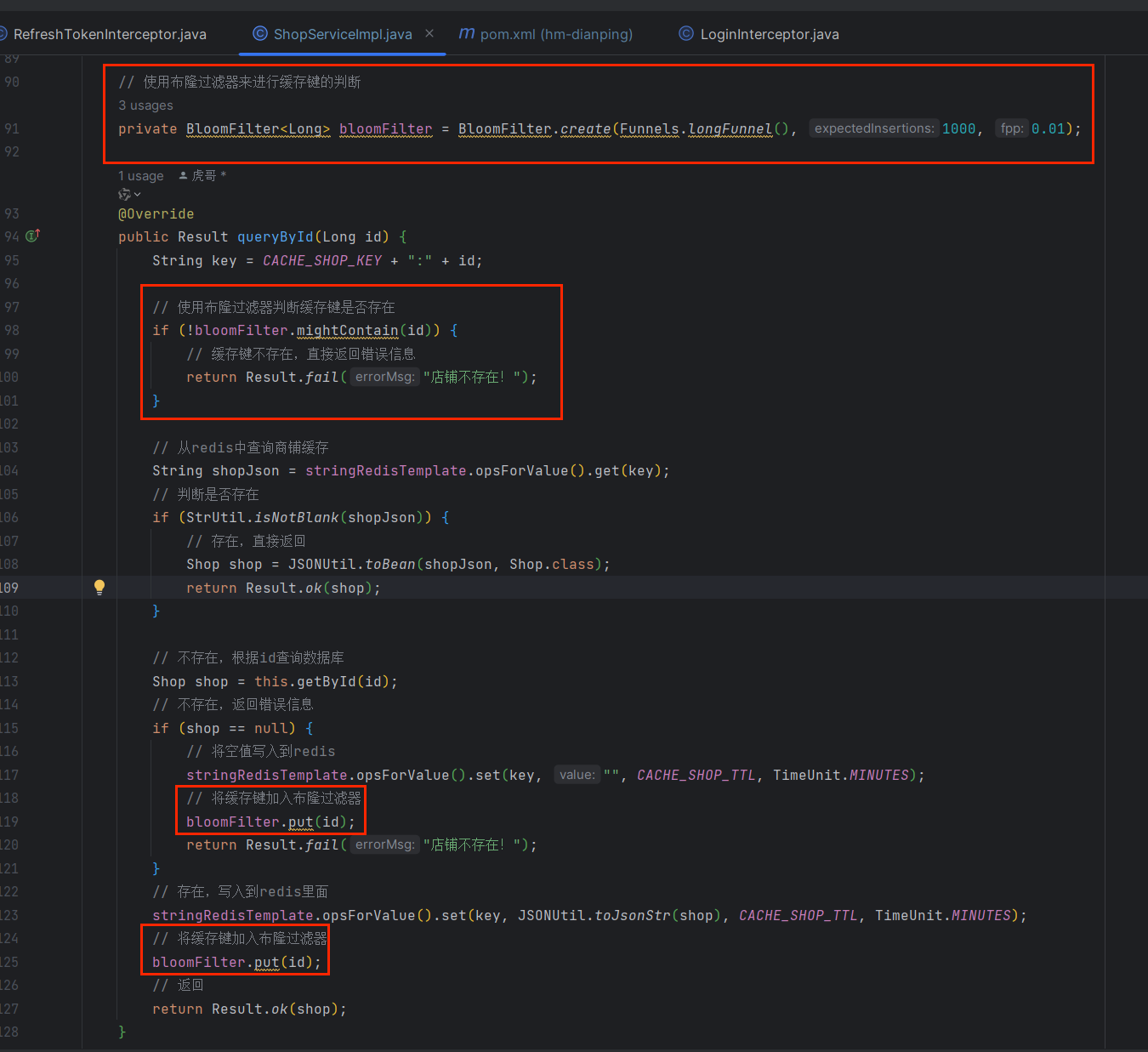
@Service
public class ShopServiceImpl extends ServiceImplShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Autowired
private BloomFilterLong> bloomFilter;
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY + ":" + id;
// 使用布隆过滤器判断缓存键是否存在
if (!bloomFilter.mightContain(id)) {
// 缓存键不存在,直接返回错误信息
return Result.fail("店铺不存在!");
}
// 从redis中查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 不存在,根据id查询数据库
Shop shop = this.getById(id);
// 不存在,返回错误信息
if (shop == null) {
// 将空值写入到redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 将缓存键加入布隆过滤器
bloomFilter.put(id);
return Result.fail("店铺不存在!");
}
// 存在,写入到redis里面
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 将缓存键加入布隆过滤器
bloomFilter.put(id);
// 返回
return Result.ok(shop);
}
更加详细的布隆过滤器讲解,请参考我的Redis专栏Redis专栏里面讲解布隆过滤器的文章
在技术的道路上,我们不断探索、不断前行,不断面对挑战、不断突破自我。科技的发展改变着世界,而我们作为技术人员,也在这个过程中书写着自己的篇章。让我们携手并进,共同努力,开创美好的未来!愿我们在科技的征途上不断奋进,创造出更加美好、更加智能的明天!

