

三级缓存解决循环依赖详解
- 一、什么是三级缓存
- 二、三级缓存详解
-
- Bean实例化前
- 属性赋值/注入前
- 初始化后
- 总结
- 三、怎么解决的循环依赖
- 四、不用三级缓存不行吗
- 五、总结
一、什么是三级缓存
就是在Bean生成流程中保存Bean对象三种形态的三个Map集合,如下:
// 一级缓存Map 存放完整的Bean(流程跑完的)
private final Map singletonObjects = new ConcurrentHashMap(256);
// 二级缓存Map 存放不完整的Bean(只实例化完,还没属性赋值、初始化)
private final Map earlySingletonObjects = new ConcurrentHashMap(16);
// 三级缓存Map 存放一个Bean的lambda表达式(也是刚实例化完)
private final Map> singletonFactories = new HashMap(16);
用来解决什么问题?
这个大家应该熟知了,就是循环依赖
什么是循环依赖?
就像下面这样,AService 中注入了BService ,而BService 中又注入了AService ,这就是循环依赖
@Service
public class AService {
@Resource
private BService bService;
}
@Service
public class BService {
@Resource
private AService aService;
}
这几个问题我们结合源码来一起看一下:
三级缓存分别在什么地方产生的?
三级缓存是怎么解决循环依赖的?
一定需要三级缓存吗?二级缓存不行?
二、三级缓存详解
不管你了不了解源码,我们先看一下Bean的生成流程,看看三级缓存是在什么地方有调用,就三个地方:
- Bean实例化前会先查询缓存,判断Bean是否已经存在
- Bean属性赋值前会先向三级缓存中放入一个lambda表达式,该表达式执行则会生成一个半成品Bean放入二级缓存
- Bean初始化完成后将完整的Bean放入一级缓存,同时清空二、三级缓存
接下来我们一个一个看!

Bean实例化前
AbstractBeanFactory.doGetBean
Bean实例化前会从缓存里面获取Bean,防止重复实例化
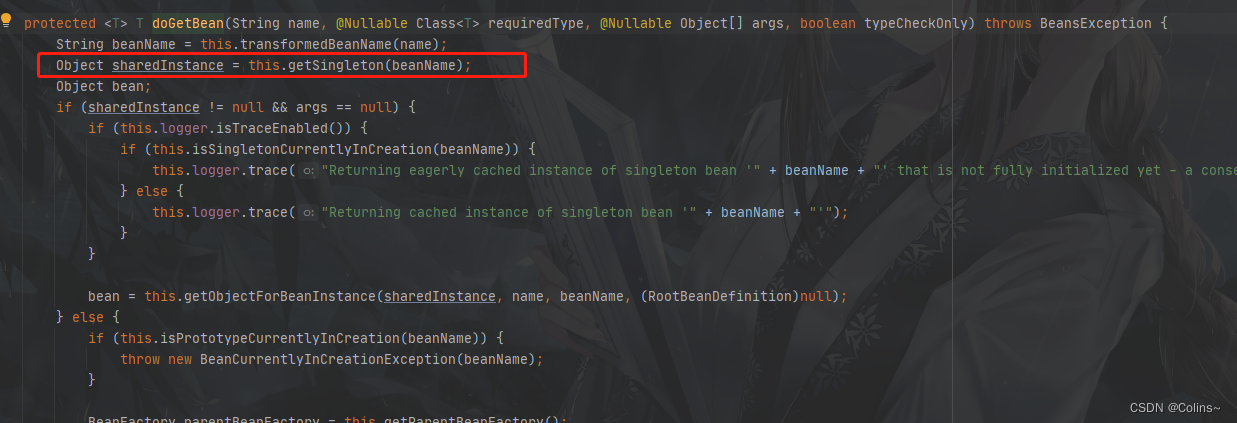
DefaultSingletonBeanRegistry.getSingleton(String beanName, boolean allowEarlyReference)
我们看看这个获取的方法逻辑:
- 从一级缓存获取,获取到了,则返回
- 从二级缓存获取,获取到了,则返回
- 从三级缓存获取,获取到了,则执行三级缓存中的lambda表达式,将结果放入二级缓存,清除三级缓存
public Object getSingleton(String beanName) {
return this.getSingleton(beanName, true);
}
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从一级缓存中获取Bean 获取到了则返回 没获取到继续
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
// 从二级缓存中获取Bean 获取到了则返回 没获取到则继续
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 加一把锁防止 线程安全 双重获取校验
synchronized(this.singletonObjects) {
// 从一级缓存中获取Bean 获取到了则返回 没获取到继续
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 从二级缓存中获取Bean 获取到了则返回 没获取到则继续
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 从三级缓存中获取 没获取到则返回
ObjectFactory> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 获取到了 执行三级缓存中的lambda表达式
singletonObject = singletonFactory.getObject();
// 并将结果放入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 从三级缓存中移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
属性赋值/注入前
AbstractAutowireCapableBeanFactory.doCreateBean
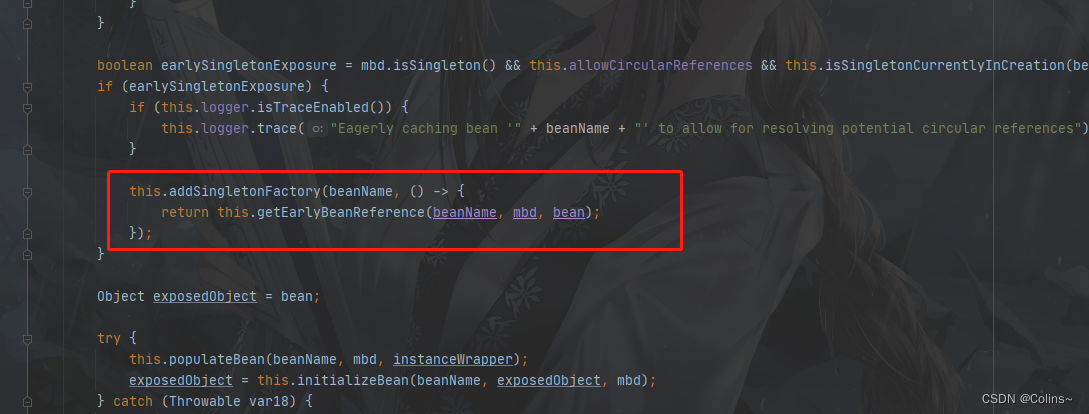
DefaultSingletonBeanRegistry.addSingletonFactory
这里就是将一个lambda表达式放入了三级缓存,我们需要去看一下这个表达式是干什么的!!
protected void addSingletonFactory(String beanName, ObjectFactory> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized(this.singletonObjects) {
// 一级缓存中不存在的话
if (!this.singletonObjects.containsKey(beanName)) {
// 将lambda表达式放入三级缓存
this.singletonFactories.put(beanName, singletonFactory);
// 清除二级缓存
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
AbstractAutowireCapableBeanFactory.getEarlyBeanReference
该方法说白了就是会判断该Bean是否需要被动态代理,两种返回结果:
- 不需要代理,返回未属性注入、未初始化的半成品Bean
- 需要代理,返回未属性注入、未初始化的半成品Bean的代理对象
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && this.hasInstantiationAwareBeanPostProcessors()) {
Iterator var5 = this.getBeanPostProcessors().iterator();
// 遍历后置处理器
while(var5.hasNext()) {
BeanPostProcessor bp = (BeanPostProcessor)var5.next();
// 找到实现SmartInstantiationAwareBeanPostProcessor接口的
// 该接口getEarlyBeanReference方法什么时候会执行?
// AOP动态代理的时候 该方法执行就是判断该Bean是否需要被代理
// 需要代理则会创建代理对象返回
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor)bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
// 这个Object有两种情况,一是实例化后的半成品Bean,二是半成品Bean动态代理后的代理对象
return exposedObject;
}
注意:这里只是把lambda表达式放入了三级缓存,如果不从三级缓存中获取,这个表达式是不执行的,一旦执行了,就会把半成品Bean或者半成品Bean的代理对象放入二级缓存中了
初始化后
AbstractBeanFactory.doGetBean
这里注意啊,这个getSingleton方法传参传了个lambda表达式,这个表达式内部就是Bean的实例化过程,初始化完成后,是要需要执行这个getSingleton方法的
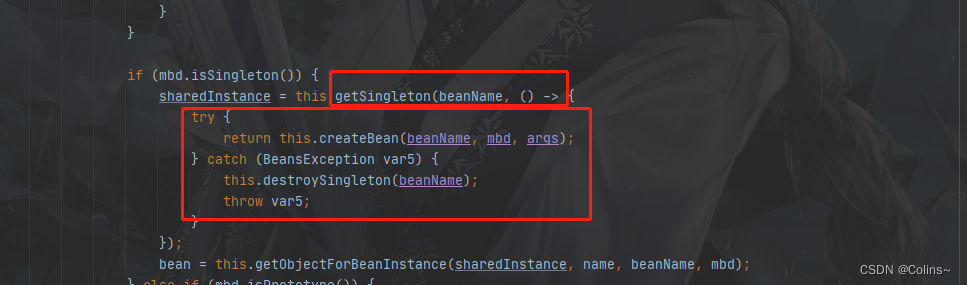
DefaultSingletonBeanRegistry.getSingleton(beanName, singletonFactory)
这个方法与上面那个不一样,重载了
public Object getSingleton(String beanName, ObjectFactory> singletonFactory) {
synchronized(this.singletonObjects) {
// 第一次进来这里获取肯定为null
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 省略................
try {
// 注意啊,这个就是执行外面那个传参的lambda表达式
// 所以这里才会跳到createBean方法那里去执行
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// 省略................
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
this.afterSingletonCreation(beanName);
}
// 到了这说明Bean创建完了
if (newSingleton) {
// 这里就会把Bean放入一级缓存中了 同时清除二、三级缓存
this.addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
DefaultSingletonBeanRegistry.addSingleton
protected void addSingleton(String beanName, Object singletonObject) {
synchronized(this.singletonObjects) {
// 放入一级缓存
this.singletonObjects.put(beanName, singletonObject);
// 清除二、三级缓存
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
总结
整个过程就三个地方跟缓存有关,我们假设现在要实例化A这个Bean,看看缓存是怎么变化的:
- 实例化前,获取缓存判断(三个缓存中肯定没有A,获取为null,进入实例化流程)
- 实例化完成,属性注入前(往三级缓存中放入了一个lambda表达式,一、二级为null)
- 初始化完成(将A这个Bean放入一级缓存,清除二、三级缓存)
以上则是单个Bean生成过程中缓存的变化!!
三、怎么解决的循环依赖
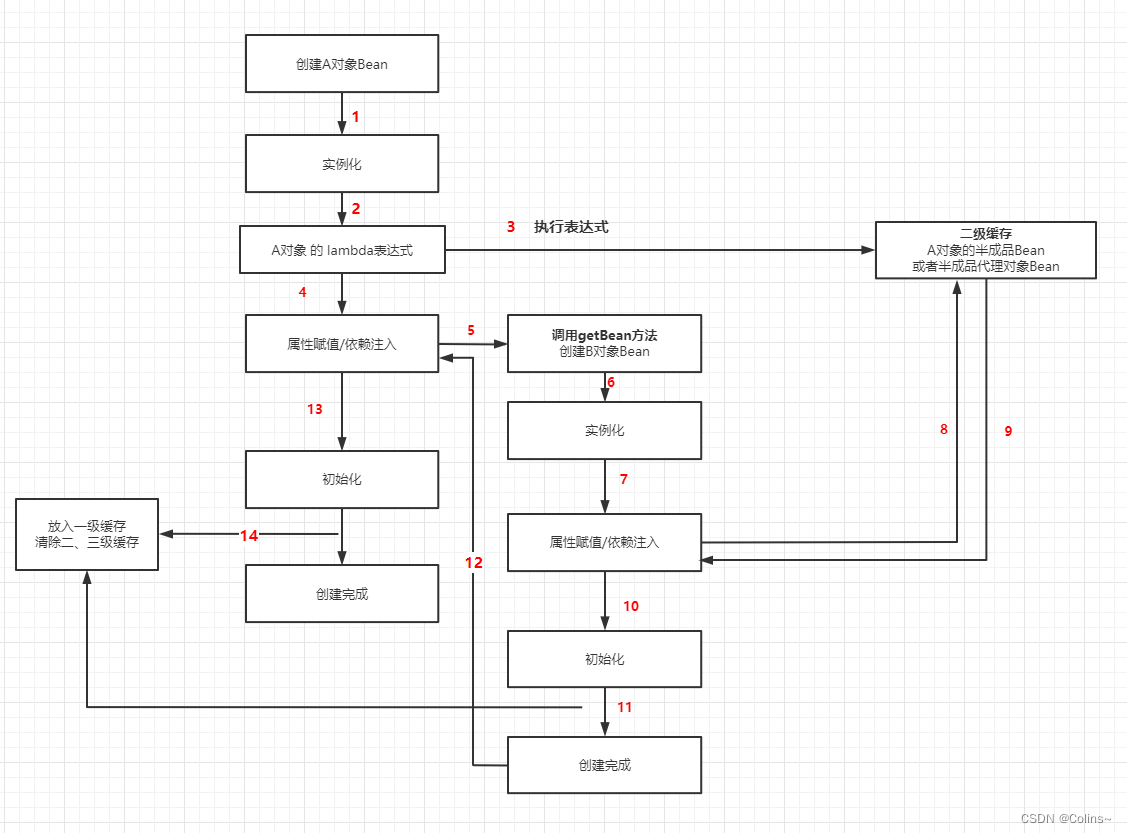
上面我们把Bean流程中利用缓存的三个重要的点都找出来了,也分析了会带来什么变化,接下来看看是怎么解决的循环依赖,我们看个图就懂了:
以A注入B,B注入A为例:
A属性注入前就把lambda表达式放入了第三级缓存,所以B再注入A的时候会从第三级缓存中找到A的lambda表达式并执行,然后将半成品Bean放入第二级缓存,所以此时B注入的只是半成品的A对象,B创建完成后返回给A注入,A继续初始化,完成创建。
注意: B注入的半成品A对象只是一个引用,所以之后A初始化完成后,B这个注入的A就随之变成了完整的A
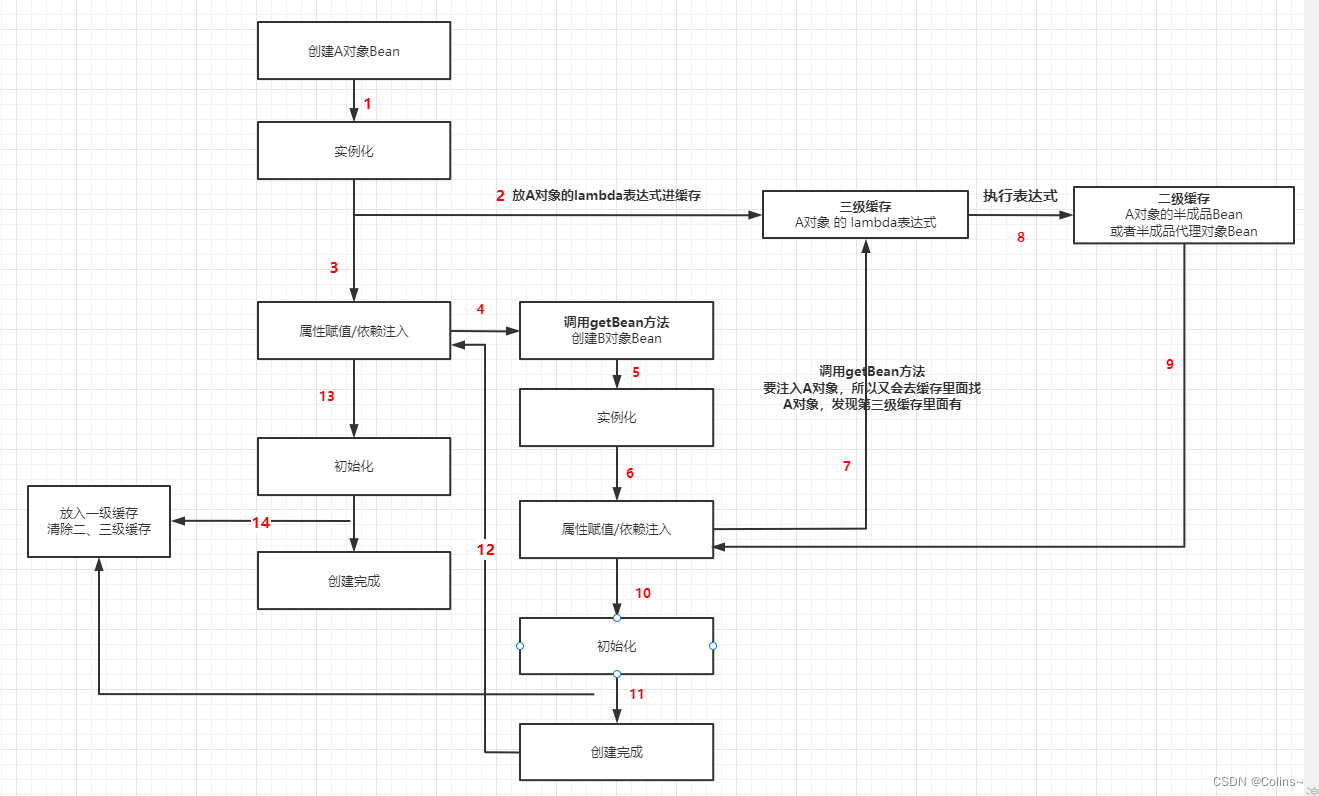
从上述看第三级缓存是用来提前暴露Bean对象引用的,所以解决了循环依赖,但是第二级缓存的这个半成品Bean对象干嘛的呢?
假设A同时注入了B和C,B和C又都注入了A,这时A注入B,实例化B的过程和上述是一样的,但随后还会注入C,那这个C在注入A的时候还会有第三级缓存用吗?没了吧,所以它就只能用第二级缓存的半成品Bean对象了,同样也是引用而已
四、不用三级缓存不行吗
可能很多小伙伴得到的答案就是不行,而且答案是因为不确定这个Bean是不是代理对象,所以搞了个lambda表达式?答案真的是这样吗??
我们分析一下:AOP动态代理在没有循环依赖的时候是在哪里执行的?Bean初始化后!有循环依赖的时候是在属性赋值前,中间就间隔了一个属性注入对吧,没错,在属性注入的时候注入的是原始对象的引用还是代理对象的引用这个很重要,但是属性注入会影响AOP的结果吗?是否AOP创建代理对象和切面有关,和属性注入无关,所以我们完全可以在属性注入之前就知道这个Bean是代理对象还是非代理对象,就像下面这样,我不将表达式放入第三级缓存了,而是直接执行,将结果放入第二级缓存
这样可不可以?可以吧,这样用二级缓存就解决了,但是在一个对象没有属性赋值、初始化前就创建代理对象是有风险的!像这么做不管有没有产生循环依赖,只要有AOP动态代理对象的产生就有一分风险,这么做是得不偿失的,所以有了三级缓存,三级缓存是只有在循环依赖以及AOP动态代理同时产生时才会有风险。可以说是因为存在循环依赖所以被迫的导致Bean对象提前的暴露了引用!!! 所以这下懂了吧
至于为什么多例、构造器注入这两种情况解决不了循环依赖就很简单了:
循环依赖的解决原理是在对象实例化后提前暴露了引用,而这两种情况都还没实例化呢
五、总结
- 一级缓存:用于存储被完整创建了的bean。也就是完成了初始化之后,可以直接被其他对象使用的bean。
- 二级缓存:用于存储半成品的Bean。也就是刚实例化但是还没有进行初始化的Bean
- 三级缓存:三级缓存存储的是工厂对象(lambda表达式)。工厂对象可以产生Bean对象提前暴露的引用(半成品的Bean或者半成品的代理Bean对象),执行这个lambda表达式,就会将引用放入二级缓存中
经过以上的分析,现在应该懂了吧:
循环依赖是否一定需要三级缓存来解决? 不一定,但三级缓存会更合适,风险更小
二级缓存能否解决循环依赖? 可以,但风险比三级缓存更大
第二级缓存用来干嘛的? 存放半成品的引用,可能产生多对象循环依赖,第三级缓存产生引用后,后续的就可以直接注入该引用
多例、构造器注入为什么不能解决循环依赖? 因为循环依赖的原理的实例化后提前暴露的引用,这两种情况还没实例化
个人博客: 全是干货,相信不会让你失望
