

前言
程序记录日志的过程,就是将需要记录的内容写入到磁盘文件中的过程。与生活的物流场景类似,好比是一车货物通过一套运输体系运送至目的地的过程,然而在这套物流体系中,我们往往不需要自己完成整套打包、上车、运输、卸货等全套流程,只需要将包打好之后交由专业的物流公司即可。对于我们今天所要描述的日志场景而言,日志内容是需要运送的货物,日志框架就是物流公司,而目的地就是磁盘上的文件(或其他日志收集服务器)。在 Java 的语言体系中,针对日志处理很早有了很好的日志框架 log4j、 logback以及 jul(Java Util Logging) 等,这些框架替我们隐藏了日志记录的技术细节,程序员只需要使用 Logger这一个工具类,即可高效的完成业务日志的记录,如下面代码所示:
Logger logger = LogFactory.getLogger("PoweredByEDAS");
String product = "EDAS";
logger.info("This is powered by product: " + product);
这一篇文章是想通过几个技术点来说明日志记录过程中的性能实践,计算机领域的性能往往都遵循着冰山法则,即你能看得见的、程序员能感知的只是其中的一小部分,还有大量的细节隐藏在冰山之下,如下图所示:

简单针对上图做一个说明:当程序员在业务代码中通过 http://logger.info的方式对日志内容进行输出后,日志的目的地是磁盘,而在最终将日志内容刷入磁盘之前,它需要经过日志框架、JVM、Linux 文件系统的层层处理。这就好比在物流运输过程中,期间有多个经停站点,在某些站点可能还需要进行换乘。运输中用到的整个交通体系(车、司机、道路等)就是我们图中的所画的“日志通道”。根据这个图,也给出了我们进行系统性优化的思路,即:避免通道拥塞、减少看得见的业务开销、躲开看不见的系统开销。
避免通道拥塞
交通体系中,避免通道拥塞的思路主要是两个:1) 尽量控制运输流量 ,2) 优化整个交通运输体系(修更多的道路,增加更多的信息化技术等等)。在日志输出场景中,程序员能控制的主要是业务日志的内容和日志策略的配置,还有相当一部分能力依赖底层基础设施的性能。针对程序员能控制的,我们尽量优化;而对于我们无法控制的,我们尽量解耦。这是我们这一章节阐述的主要思路。
减少业务输出内容
直观来说,日志内容越大,对整个系统会造成一些更大的压力。为了量化差别,我们进行了下面的测试对比:第一组,我们仅仅将不同日志大小写入内存。第二组中,我们将不同的日志大小写入磁盘文件。写入内存我们使用了 Log4j 中的 CountingNoOp Appender ,他的作用是在进行日志的正式输出时,仅仅对输出的日志做计数统计,这样的一种测试方式,从某种程度上能衡量出来单纯日志框架的处理效率。
在下图所呈现的测试结果中,我们可以看到,即使不进行刷盘的动作,写入的吞吐量随着内容的大小而明显下降
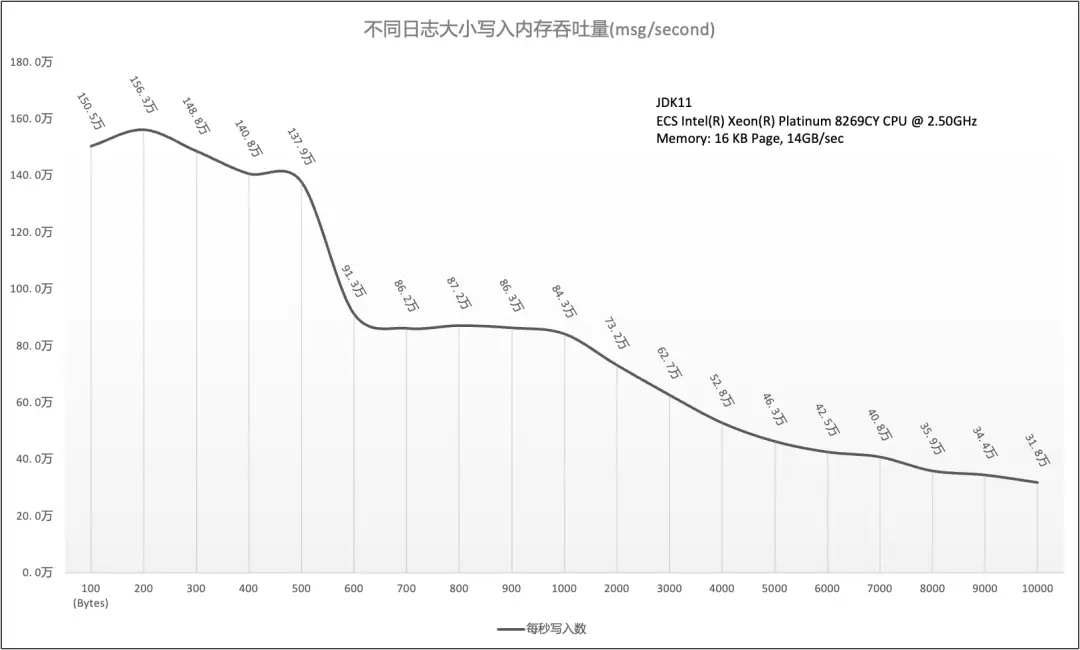
在另外一组的测试中,我们再将不同日志大小的内容写入文件,再做类似的对比,从实验结果来看我们能得出两个简单的结论:
- 与只写入内存的吞吐量相比,二者的吞吐量随着日志内容的变大差距越来越大。
- 同时随着输出内容的数量变多,在磁盘场景下呈现明显的下滑趋势,随着内容的增多,呈现逐渐趋平的趋势。
具体结果如下图:

上图中的测试数据是我们从一个 IO 设备提供了 400MB/s 左右的速度中获得;在 IO 没有被用满的情况下,增加写入内容尚能提升整体的写入量,但是一旦达到设备的瓶颈。继续写入将造成写入的堆积。不过两组数据均能得出相同的结论,即:更大的日志文本内容,只会导致更差的处理时间。类比到生活中运输的场景,如果我们要运输的货物非常大的时候,那么就需要我们的货车具备更大空间的、更强的动力,而且运输速度也会更慢。同时过重的货物会有动力失调,轮胎爆胎等风险。为了提高运输效率和健康度,就应该尽量避免运超大型的货物。从我们的日志场景出发,过大的日志会同样会在在 CPU、内存、IO 等资源上均会对系统产生不同程度的冲击。
减少系统输出内容
压缩Logger输出:
在获取一个 Logger 进行日志输出时,大多数程序员的编程习惯是直接使用 Class 对象进行获取,参见如下的代码片段:
package com.alibabacloud.edas.demo;
public class PoweredByEdas {
private static Logger logger = LogFactory.getLogger(
ProweredByEdas.class);
public void execute() {
String product = "EDAS";
logger.info("Prowered by " + product);
}
}
而在进行日志输出时,如果 logger 是 Class 将默认输出对应它所对应的 FQCN,即:com.alibabacloud.edas.demo.PoweredByEdas
其实我们可以使用 logger 的 re-format 方式,将其进行压缩,比如,在 logback 中使用 %logger{5} 或 %c{5} 精简后,logger 在输出时将压缩成为c.a.e.d.PoweredByEdas,平均每条日志将减少 19 字符。
// 使用默认 [%logger] 进行输出
2023-11-11 16:14:36.790 INFO [com.alibabacloud.edas.demo.PoweredByEdas] Prowered by EDAS
// 使用默认 [%logger{5}] 进行输出
2023-11-11 16:24:44.879 INFO [c.a.e.d.PoweredByEdas] Prowered by EDAS
不过这种日志处理由于做字符串的拆分和截取,会额外耗费一定的 CPU,如果是计算密集型的业务(CPU 占用本来就很高的情况下)则不建议生产使用。
压缩异常输出
异常信息的记录,是我们的系统在线上出现问题或者故障时的一个重要的排查依据,他的全面与否很多时候直接影响了问题解决的效率,然而过多的异常信息记录,往往容易把真正有用的信息进行覆盖。而当我们将系统中抛出的异常拆开来看的时候,不难看出通篇的堆栈信息中,能对自己排查问题产生帮助的信息,往往只有几行,如下图所示:

根据笔者自己的经验,在将异常直接进行打印输出之前,我们可以尝试将重新遍历异常堆栈,将信息重新整理之后再输出,具体实践可参考以下几点:
- 保留栈顶的几帧:栈顶往往包含的是最为关键的信息,是案发的第一现场,他的信息完整性显得尤为重要。
- 保留业务栈帧:在 Java 语言中,大家会遵循给业务代码一个单独包名的实践,此时我们可以利用包名进行栈帧的过滤和保留操作。
- 抽样打印全栈信息:这里可以根据具体的业务情况而定,需要将全栈信息进行随机输出的原因是有的时候可能会追踪到一些系统级别的 BUG 或想了解他的一些机制。全栈信息的输出有助于问题的追根溯源。
压缩异常不仅能带来性能上的提升,而且还能节省大量的存储空间,这里感兴趣的同学可以进一步查阅之前的一篇文章:《十行代码让日志存储降低80%》
解耦通道依赖
如果说上面提到的减少内容是把承载的货物减轻的话,那么针对通道的优化思路就是优化交通运输的整体效率;站在应用的角度上思考,通道的优化,和系统运行时的状态、以及所使用框架的实现方式有着莫大的关系,言下之意就是有着很大一部分的内容不受编程人员的控制。对于不受控制的部分,我们的思路是最大限度解耦底层的实现,具体思路是两个:
- 在进行日志内容写入时,通过异步缓冲区解耦业务代码到通道(从日志框架 到 JVM 到 操作系统 FileSystem)的瓶颈。
- 在进行文件内容落盘时,通过大文件切分成小文件的方式,尽量解耦硬件级别的瓶颈。
如下图所示:
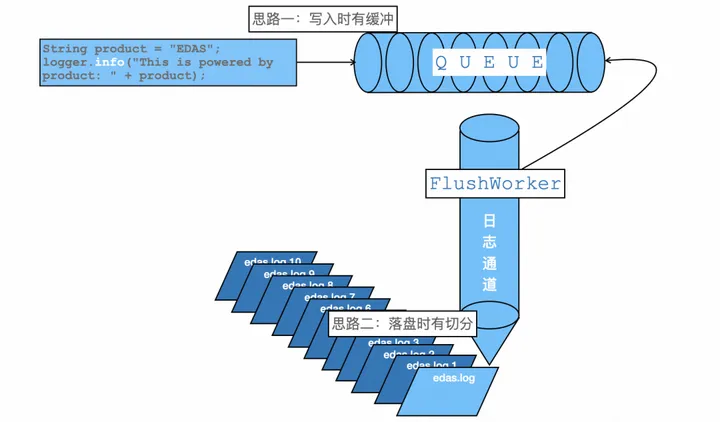
使用异步日志
由于异步的方式是业务代码先把日志内容放入一个缓冲区,再由专门的线程异步刷入到文件系统中,这样可以最大限度确保业务的吞吐不受底层框架的影响。但是是否所有日志都适合异步的策略这个需要根据业务场景进行区分:常规业务日志如遇到日志丢弃的场景可能对于业务影响不会太大,但是有的场景是必须做到严格数据一致,比如 RocketMQ 的 Commit Log,因为一条日志代表着一条完整的业务消息的投递情况,他必须和业务状态的返回做到严格一致,这种情况异步方式就不是一个好的选择;在 Log4j 中,他也提供了两种方式,一种是细粒度的 Appender 级别的配置,一种是全局的配置;下图展示的是三种策略对于性能吞吐的影响:
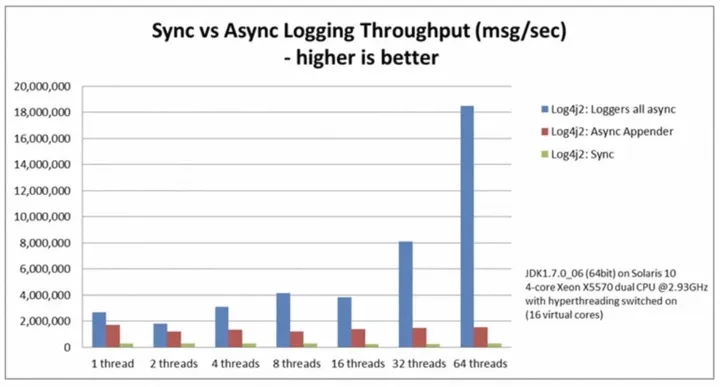
简单解读上图:首先,同步写入的性能在所有场景中都是最低的,这个和我们常规的认知是一致的;而AsyncLogger (蓝色柱状图) 的 TPS 却能随着 Worker 的增加而增加,但 AsyncAppender只能持平 。这一点和我们常规的认知有些出入,带着这个疑虑,我们下面稍微深入的探究一下。
1.Log4j2 AsyncAppender
下面是 AsyncAppender 的配置方式,框架提供了更多的参数来做更多精细化的控制,核心参数解读如下:
-
- shutdownTimeout:等待worker线程处理日志的时间,默认为0,表示无限等待;
- bufferSize:缓冲队列的大小,默认为1024;
- blocking:是否采用阻塞式,默认为true。当队列满时,会同步等待。
500
1024
true
简单解读其设计意图:框架会先提供一个系统缓冲区来缓存即将写入的内容,但是当缓冲区满时,框架还提供了两种策略进行选择,第一种是直接丢弃,第二种是进行等待,但是具体等待多长时间也依然可以配置。
2.Log4j2 AsyncLogger
与 AsyncAppender 相比,其使用上也更为简单,只需要通过设置启动参数-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector便可全局启用异步日志。同样,AsyncLogger 也会有缓冲区的大小的设置,默认是 256K 。当超出缓冲区大小时,可以使用丢弃策略。可以通过配置参数-Dlog4j2.asyncQueueFullPolicy=discard和-Dlog4j2.discardThreshold=INFO 来明确指定丢弃哪一级别的日志。值得一提的是,AsyncLogger 使用了 LMAX Disruptor的高性能队列,这是为什么 AsyncLogger 相比于 AsyncAppender 在单线程吞吐和多线程并发方面具有更好的性能的关键。LMAX Disruptor为什么相比阻塞队列性能能随线程数扩展,主要有三点:首先,解决了伪共享问题;其次,无锁的队列设计,只需CAS的开销;最后,需要明确的,对比的是该日志场景下的队列性能。
com.lmax
disruptor
与 Log4j 一样,Logback 也有着类似的策略,这里我们就不再赘述它的具体使用方式,下面的表格中,我们总结了在各种策略下的优缺点,希望在大家进行选型时能有所帮助:
| log4j2 AsyncLogger | log4j2 Async Appender | logback AsyncAppender | 同步日志 | |
| 性能 | 最优 | 较好 | 较好 | 差 |
| 易用 | 易用,只需jvm参数-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector即可启用 | 配置较为复杂,需要配置多个AsyncAppender | 配置较为复杂,需要配置多个AsyncAppender | 易用 |
| 内存压力 | 较大 | 较大 | 较大 | 较小 |
| 是否会丢失日志 | 进程退出时 或 IO 跟不上 | 进程退出时 或 IO 跟不上 | 进程退出时 或 IO跟不上 | 无 |
| 兼容性 | Appender中ThreadLocal相关的pattern、filter异常 | Appender中ThreadLocal相关的pattern、filter异常 | Appender中ThreadLocal相关的pattern、filter异常 | 无 |
| 是否受磁盘满或IO受限影响 | 丢弃时,不受影响 | 丢弃时,不受影响 | 丢弃时,不受影响 | 影响 |
| 配置注意点1 | XxFileAppender指定immediateFlush为false | XxFileAppender指定immediateFlush为false | XxFileAppender指定immediateFlush为false | XxFileAppender指定immediateFlush为true |
| 配置注意点2 | 设置丢弃策略-Dlog4j2.asyncQueueFullPolicy=discard和-Dlog4j2.discardThreshold=INFO | 设置丢弃策略-Dlog4j2.asyncQueueFullPolicy=discard和-Dlog4j2.discardThreshold=INFO | 设置丢弃策略:neverBlock为true | 无 |
使用滚动日志
对于操作系统而言,小文件的处理相比于大文件,从系统资源角度,大文件往往意味着更多的内存占用,更多的 I/O 操作、更苛刻的磁盘空间、更多的总线带宽等等,当任意方资源出现瓶颈时,还会带来更多的 CPU 使用进而造成系统更高的 Load。而小文件除了在上述资源角度带来更好的优化空间之外,还在运维管理上提供了更多便利,如:使用更小的磁盘、尽早归档、尽早清理磁盘空间等等。在生产实践中,适当使用滚动日志,是一项极为可观的实践,下面的例子是在 log4j 中的的配置片段,配置内容为在时间上以天滚动,大小上按 100MB 滚动,最多保留 5 个文件的策略来对日志文件进行滚动:
${commonPattern}
5
减少看得见的业务开销
看得见的业务开销,就好比是在运输途中的货物,我们期望打包装车的货物是最终都会使用到的;即确定能上车才进行打包,确定最终要运输才装车。在日志输出的场景中,我们也分为两部分来阐述:
确定输出才执行(避免构建复杂日志参数)
在一些需要记录详细日志内容的场景中,往往需要根据上下文中的某些参数再进行全量信息的获取(如:查询数据库),这样的动作暗含这一次开销很大的调用开销,这个时候我们推荐使用”logger.isXXEnabled()”来进行控制。既确定对应的日志 Level 满足所需才开启对应的查询,参考下面的代码所呈现的方式:
// 不推荐
log.debug("Powered by {}", getProductInfoByCode("EDAS"));
// 推荐
if (log.isDebugEnabled()) {
log.debug("Powered by {}", getProductInfoByCode("EDAS"));
}
上面的逻辑虽然简单,原理也简单易懂,但是我们很多的客户因为这样的代码太多而带来的性能退化案例不在少数,一个很典型的例子就是JSON序列化大的对象,究其原因代码往往是在日常迭代中对于工程实施没有规范,Code Review 流程的缺失而导致恶化。
确定输出才拼接(使用参数占位符)
与上面的 Case 类似,这个实践也简单有效。使用参数占位符方式,有两个好处。首先,它更容易编写,对于记录内容的句子完整性和可读性上相比直接拼接字符串会友好很多;其次,由于它生成内容延迟的特性,可以保证在需要真实输出时,才对内容进行填充,这样无形之中就节省了很多的开销。代码样例如下:
String product = "EDAS";
//推荐
log.debug("Powered by {}", product);
//不推荐
log.debug("Powered by " + product);
不过可能有的同学心中会有一个疑虑:如果日志级别为 “DEBUG”,他带来的性能开销难道不是一样(或更差)的吗?带着这个疑虑,我们使用 log4j 这个框架针对性的做了一个测试,测试效果如下图所示:
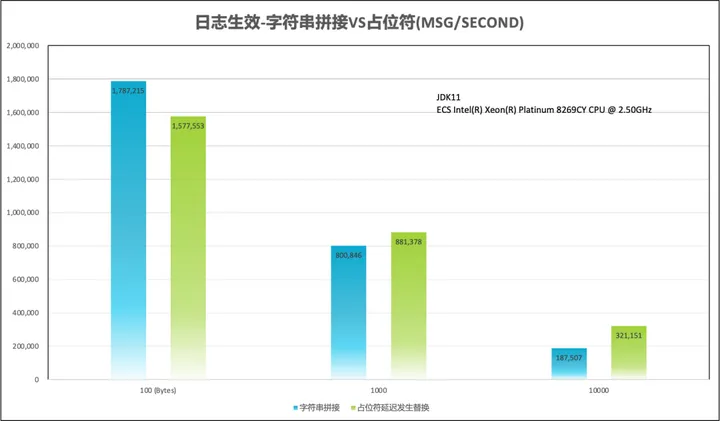
上图的测试结果,能得出以下两个结论:1)在输出字符较短时,字符串拼接比占位符快,因占位符方式需要执行占位符扫描替换过程。2)但是随着输出字符越来越大,占位符反过来比字符串拼接更快,而且越长的字符串快的越多。原因是针对长字符的输出,日志框架会有针对性的优化。在 log4j2 中,它使用 ThreadLocal 缓存并复用了StringBuilder 对象,无需每次都为大的 StringBuilder 构建一个大对象。而字符串拼接则每次都创建新的StringBuilder 对象。
躲开看不见的系统开销
继续类比到货物运输的场景,看不见的系统开销,就好比是整车中的资产折旧,道路状况与司机驾驶习惯造成的综合油耗。在计算机软件中,我们常说的系统开销为主要资源的开销(计算、内存、磁盘、网络等),在这篇文章中,我们主要从内存与计算两个角度阐述:
避免多余的内存资源(Garbage Free)
“Garbage Free” 也叫做 “No GC”,即不产生 GC;这是 log4j2 中新引入的一项内存优化技术,设计目标是减少对垃圾回收(GC)的压力,他的实现原理比较简单:通过重复利用对象来避免不必要的对象创建。实现方式包括将需要重复利用的对象放置于线程的 ThreadLocal 中,或者重复利用 ByteBuffer 来避免创建不必要的字符串对象。通过这个两个技术手段避免 GC 的开销后,它能够显著降低延迟。官方提供的性能测试结果对比如下:
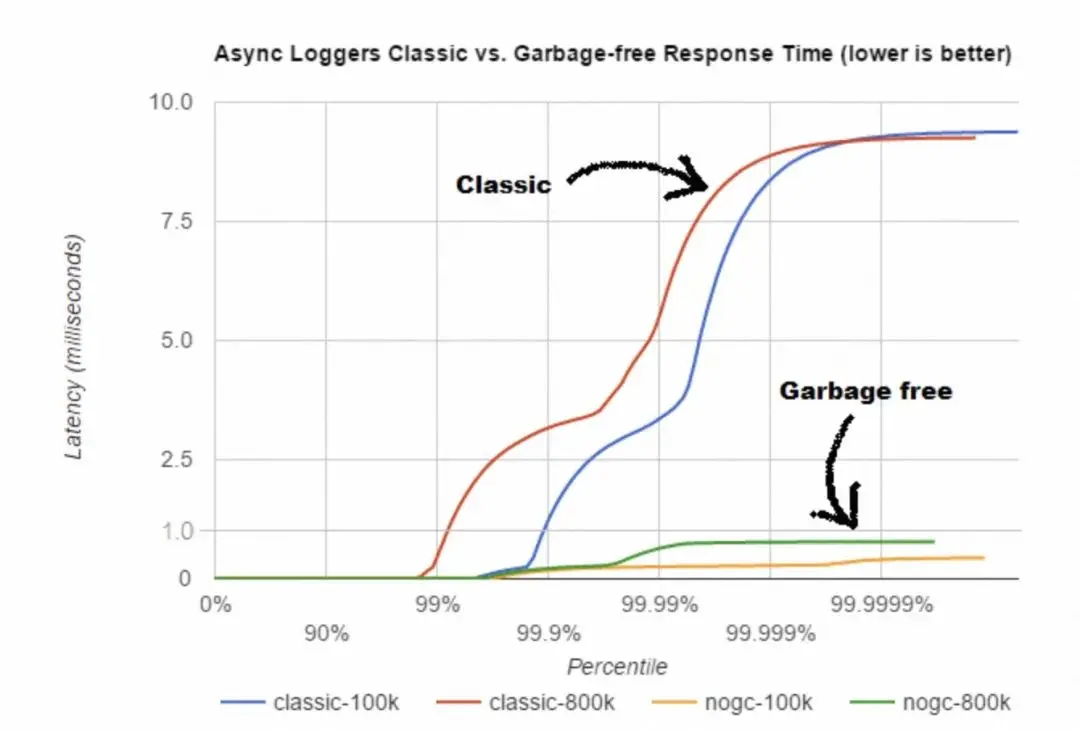
需要注意的是,传统的 J2EE Web 应用程序的场景中,会有热加载的诉求,由于 Garbage Free 会缓存很多大的 StringBuilder 在 ThreadLocal 中,这在程序热加载时可能会造成潜在的内存泄漏。因此当检测到是 J2EE Web 应用程序时,log4j2 会默认禁用这项技术。如需强制开启,可在启动参数中加入 -Dlog4j2.enable.threadlocals=true -Dlog4j2.enable.direct.encoders=true。
避免多余的计算资源(避免元信息打印)
日志输出时的元数据信息打印是指在进行内容输出时,将程序运行时的与相关代码信息进行输出,这些内容包括:类名称、文件名、方法名、行号等。以获取行号为例,下图展示了在不同的日志框架下使用行号输出与不使用的性能差异。图中很清晰的展示了几乎所有的框架在进行行号输出时性能的急剧下降:

我们的疑问是:Why?以 Log4j2 为例,在进行 Location 计算时,是通过构建一个 Throwable 的方式拿到堆栈之后,然后再反向寻找与 Logger 同名的类所在的栈帧,再进行 Location 的获取。这个过程光听听是不是就好感人?感兴趣的同学可以查阅对应的代码,如下:
public StackTraceElement calcLocation(final String fqcnOfLogger) {
if (fqcnOfLogger == null) {
return null;
}
// LOG4J2-1029 new Throwable().getStackTrace is faster than Thread.currentThread().getStackTrace().
final StackTraceElement[] stackTrace = new Throwable().getStackTrace();
boolean found = false;
for (int i = 0; i
总结
本文是从 EDAS 团队在客户服务的过程中将日志配置相关的工单答疑整理输出,尝试给出几条 JAVA 日志的经验实践。受限于笔者自身的知识面,可能无法一一枚举出所有的有性能影响的因素,如果您有其他额外的补充,欢迎留言与我们交流。大家也可以加入钉群 “云上微服务应用管理最佳实践 – EDAS(一):21958624” 与我们沟通。另外EDAS也推出了运行时调整日志配置的能力,欢迎使用。
参考链接
Garbage Free: https://logging.apache.org/log4j/2.x/manual/garbagefree.html
Log4j 配置:https://logging.apache.org/log4j/2.x/manual/configuration.html
Logback 配置:https://logback.qos.ch/manual/configuration.html
EDAS 运行时日志动态调整:https://help.aliyun.com/zh/edas/user-guide/dynamic-log-configuration-2261535
十行代码让日志存储降低80%:https://mp.weixin.qq.com/s/MIBHh5NO0GvWBOVJ_Jzn2w
作者:骄龙、孤弋
原文链接
本文为阿里云原创内容,未经允许不得转载。
