

查询并聚合一个「给定长度的时间范围的数据」,是时序数据中常见的一种查询模式。例如 PromQL 中的 Range selector,就原生地支持了这种时序查询。但对于通用的数据库查询语言 SQL ,这类时序查询很难通过原生的 SQL 完成,所以我们在 GreptimeDB 中引入了扩展的 SQL Range 查询语法,将时序查询能力与 SQL 高度灵活的表达能力相结合,实现了 SQL 对时序数据查询的原生支持。
✨ 让数据动起来! 使用 SQL 在 GreptimeDB 上实现动态 Range 查询 https://greptime.cn/playground

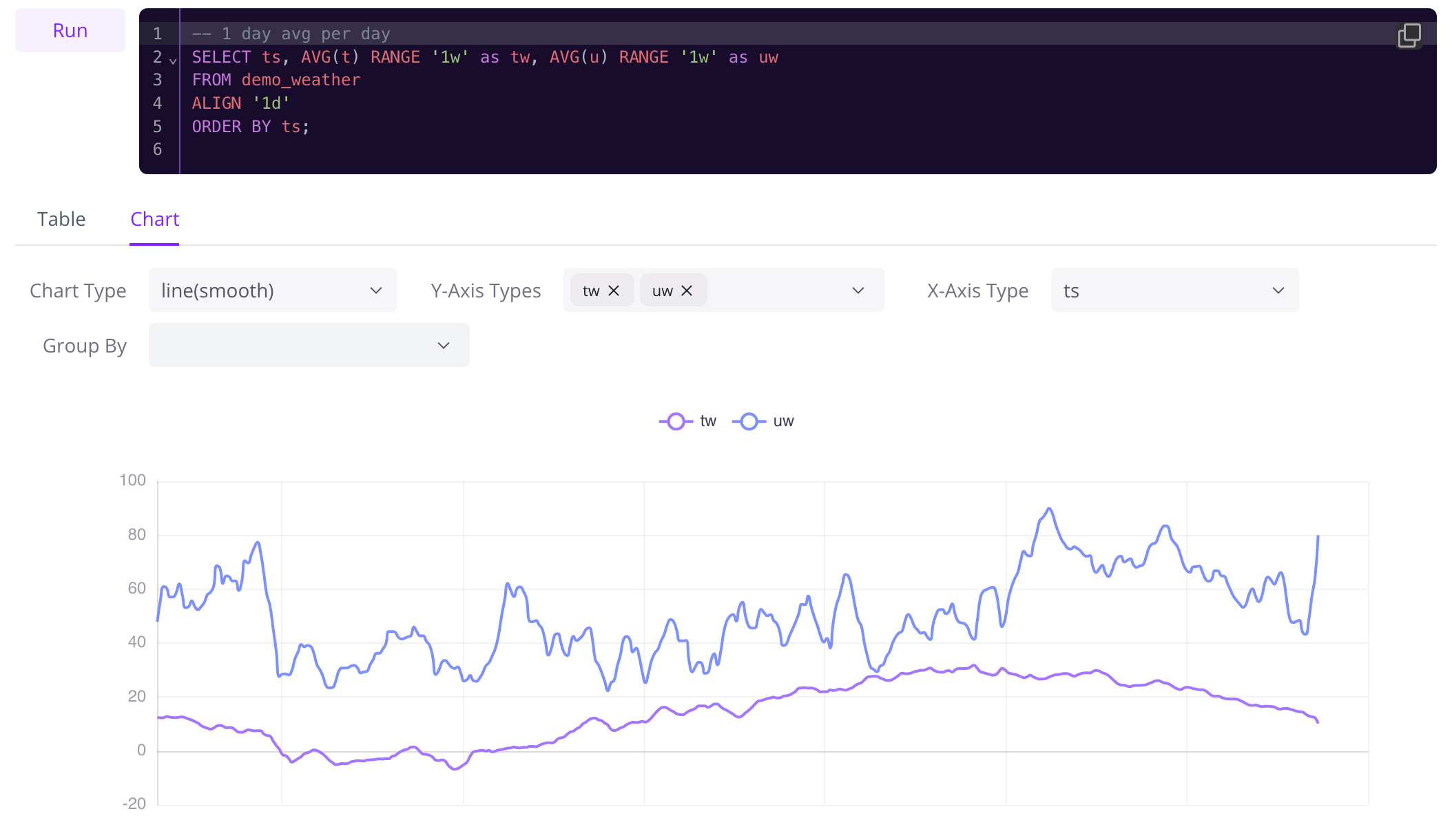
🔧 点击链接加入我们的 Playground,立即体验👆
示例
我们用一个例子来介绍 Range 查询。下面这张表 temperature 记录了不同城市在不同时间的气温:
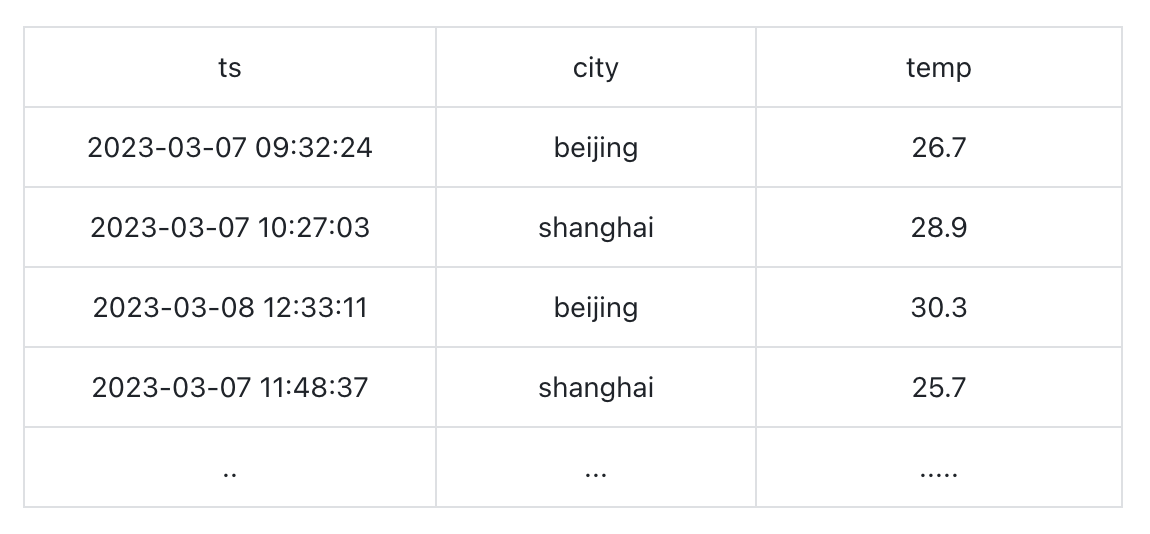
我们想查询北京从 2023 年 5 月 2 日(时间戳为 1682985600000 )以前的:
- 每日的日平均气温;
- 每日的周平均气温;
- 如果某天的数据点缺失,则以前后两天平均气温均值作为这天的平均气温。
我们首先从 PromQL 的视角来看如何去写这句查询,对于两条查询,都需要以天为步长进行查询。对于日平均气温,需要向前聚合一天的数据,对于周平均气温,需要每次向前聚合一周的数据,并求出平均值。另外我们需要使用 @ 将查询时间对齐到时间戳 1682985600000。
最后的查询为:
-- 日平均气温
avg_over_time(temperature{city="beijing"}[1d] @ 1682985600000) step=1d
-- 周平均气温
avg_over_time(temperature{city="beijing"}[7d] @ 1682985600000) step=1d
但上面的查询存在一些问题。PromQL 强调的是做数据的查询,但不能很好地处理查询中缺失数据点的情况,也就是如何对查询的数据作平滑。PromQL 只是存在 Lookback delta 的机制(具体见:https://promlabs.com/blog/2020/07/02/selecting-data-in-promql/#lookback-delta),用一些旧的数据来代替缺失的数据点。这样的默认行为在某些情况下并不是用户想要的。因为 Lookback delta 的机制的存在,会导致聚合的数据携带一些旧值。在默认情况下,PromQL 很难做到数据精确性的控制。并且针对我们上面提出的数据平滑要求,PromQL 也没有很好的办法完成。
如果从传统的 SQL 出发,因为 SQL 中不存在 Lookback delta 的机制,我们可以精确地控制我们数据选择和聚合的范围。所见即所得,进行比较精确的查询。
上述查询本质上是以天为单位,对每天和每周的数据做聚合。针对日平均气温,我们可以利用 date_trunc 这一 scalar 函数,该函数能够将时间截断到某一个精度上,我们使用这个函数将时间截断到天这一单位,最后再以天为单位对数据进行聚合,就能得到我们想要的结果:
-- 日平均气温
SELECT
day,
avg(temp),
FROM (
SELECT
date_trunc('day', ts) as day
temp,
FROM
temperature
WHERE
city="beijing" and ts 这样也基本满足了我们的需求,但是这种查询问题在于:
- 写起来非常繁琐,需要写子查询;
- 应用范围有限,用这种办法只能求出日平均气温,没法求出周平均气温。因为 SQL 中的聚合要求每一条数据只能属于一个 group。但是在时序查询中,如果每次采样的时间是一星期,步长是一天的话,一条数据必然会被多个 group 使用,针对这种查询传统 SQL 无能为力;
- 还是没办法解决空白数据填充的问题。
在上面讨论之后,我们需要思考:这种查询本质上是时序查询,但是我们所使用的 SQL——虽然有非常灵活的表达能力,但却不是专门为时序数据库设计的。我们需要一些新的 SQL 扩展语法,在 SQL 中来简单的描述这种时序查询。一些时序数据库如 InfluxDB 提供了 group by time 语法, QuestDB 提供了 Sample By 语法,这些实现为我们的 Range 查询提供了思路。下面介绍如何使用 GreptimeDB 提供的 Range 语法来进行上述查询。
-- 日平均气温
SELECT
ts,
avg(temp) RANGE '1d' FILL LINEAR,
FROM
temperature
WHERE
city="beijing" and ts 我们为一个 SELECT 语句引入了一个关键字 ALIGN,代表每次时序查询的步长,ALIGN 会将时间对齐到日历上。在聚合函数后引入了一个 RANGE 关键词,代表在每次数据聚合的范围,FILL LINEAR 表示数据点为空的时候的数据填充方式,即以数据平均值填充。通过这样的方式,我们比较轻松的完成了上文所提出的几个要求。
通过 Range 查询,我们可以很优雅的在 SQL 中表达时序查询。弥补了 SQL 在时序查询上描述能力不足的问题,并且可以结合 SQL 强大的表达能力,实现更加复杂的数据查询功能。
Range 查询还有更灵活的使用方式,具体使用参见文档: https://docs.greptime.com/reference/sql/range
更多实现逻辑请点击文档链接进行参考。
关于 Greptime 的小知识:
Greptime 格睿科技于 2022 年创立,目前正在完善和打造时序数据库 GreptimeDB,格睿云 GreptimeCloud 和可观测工具 GreptimeAI 这三款产品。
GreptimeDB 是一款用 Rust 语言编写的时序数据库,具有分布式、开源、云原生和兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时降低长期存储成本;GreptimeCloud 可以为用户提供全托管的 DBaaS 服务,能够与可观测性、物联网等领域高度结合;GreptimeAI 为 LLM 量身打造,提供成本、性能和生成过程的全链路监控。
GreptimeCloud 和 GreptimeAI 已正式公测,欢迎关注公众号或官网了解最新动态!
官网:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
