

又是一年一度 AWS re:Invent,这次关系型数据库最重磅的发布是 Amazon Aurora Limitless Database (无限数据库)。在 AWS 高级副总裁 Peter DeSantis 的 Keynote 里,也用了将近一半的篇幅回顾了 AWS 关系型数据库的发展历程。
2009 – RDS

把 MySQL, PostgreSQL 托管到了云上,从无到有。
2014 – Aurora


基于 log 架构 (内部代号 Grover),打造了 Aurora。在保持了 MySQL / PostgreSQL 完全兼容的同时,大大提升了性能和可用性。
2018 – Aurora Serverless



通过内部代号 Caspian,为数据库优化的虚拟化技术,提供了数据库资源的无缝上下伸缩。
2023 – Aurora Limitless


通过自研的时钟同步,来实现高性能的分布式事务,推出了可以横向写扩展的分布式数据库。
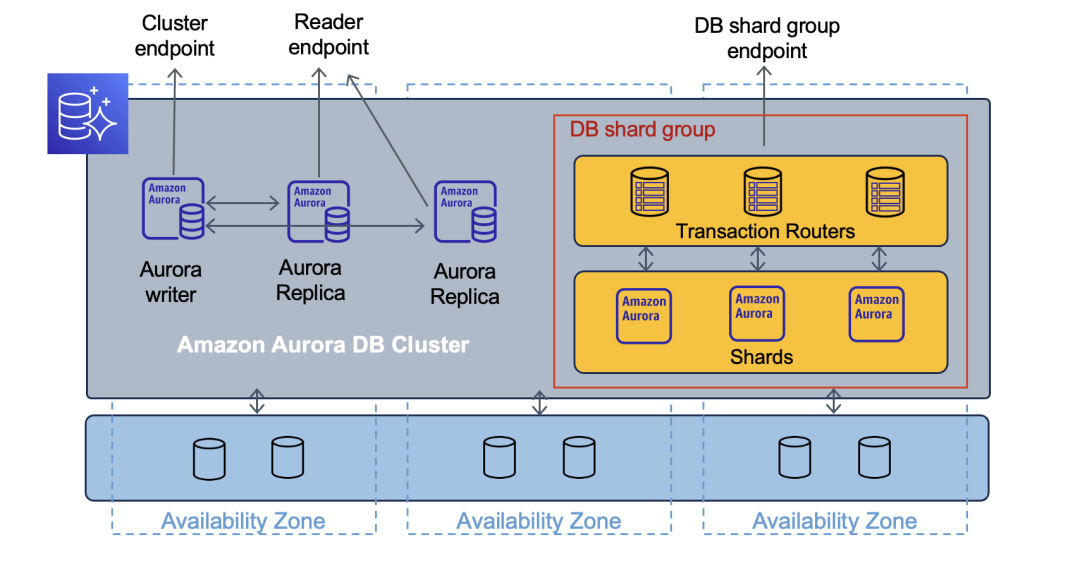
从架构上看,Aurora Limitless 类似于 Google Spanner,两者都属于分布式数据库 (NewSQL)。分布式数据库最难的点是实现高性能分布式事务,这里 Aurora Limitless 也是采用了和 Google Spanner TrueTime 类似的方案。目前Aurora Limitless 的资料还很少,后续还要关注它和原生 PostgreSQL 的兼容性,以及它的性能。

说到数据库兼容性,这次 Aurora Limitless 率先推出的是 PostgreSQL 的支持而不是 MySQL。我想是两个原因,一是 PostgreSQL 的代码更加容易适配 Aurora Limitless 的架构。Limitless 的架构需要一个解析 SQL 的 Router 组件,而 PostgreSQL server 层的代码更容易被剥离出来做一个 Router;另一个是在国外 PostgreSQL 的使用量也已经赶上 MySQL 了。
整体回顾
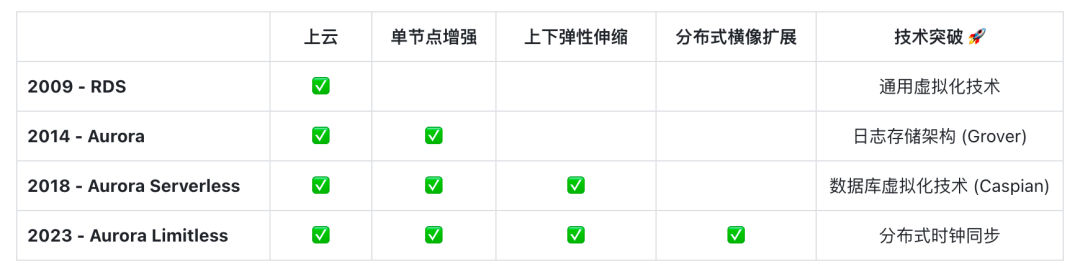 AWS 关系型数据库经过 15 年的迭代,4 次技术突破对应 4 代产品,达到了现在 Aurora Limitless 的形态。从数据库核心看,Aurora Limitless 已经是接近完全形态。剩下的大问题都集中在开发工作流上,比如在线大表变更,瞬间复制出一个数据库用于开发 / 测试。
AWS 关系型数据库经过 15 年的迭代,4 次技术突破对应 4 代产品,达到了现在 Aurora Limitless 的形态。从数据库核心看,Aurora Limitless 已经是接近完全形态。剩下的大问题都集中在开发工作流上,比如在线大表变更,瞬间复制出一个数据库用于开发 / 测试。
无到无限的路已经走完,也期待 Aurora 的未来,从无限走向无瑕 (Limitless to Flawless)。
💡 更多资讯,请关注 Bytebase 公号:Bytebase
