

我们知道如果程序中并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束时,会因为频繁创建线程而大大降低系统的效率,因此出现了线程池的使用方式,它可以提前创建好线程来执行任务。本文主要通过java的ThreadPoolExecutor来查看线程池的内部处理过程。
1 ThreadPoolExecutor
java.uitl.concurrent.ThreadPoolExecutor类是线程池中最核心的一个类,下面我们来看一下ThreadPoolExecutor类的部分实现源码。
1.1 构造方法
ThreadPoolExecutor类提供了如下4个构造方法
// 设置线程池时指定核心线程数、最大线程数、线程存活时间及等待队列。
// 线程创建工厂和拒绝策略使用默认的(AbortPolicy)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
// 设置线程池时指定核心线程数、最大线程数、线程存活时间、等待队列及线程创建工厂
// 拒绝策略使用默认的(AbortPolicy)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
// 设置线程池时指定核心线程数、最大线程数、线程存活时间、等待队列及拒绝策略
// 线程创建工厂使用默认的
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
// 设置线程池时指定核心线程数、最大线程数、线程存活时间、等待队列、线程创建工厂及拒绝策略
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize 通过观察上述每个构造器的源码实现,我们可以发现前面三个构造器都是调用的第四个构造器进行的初始化工作。
下面解释一下构造器中各个参数的含义:
- corePoolSize:核心池的线程个数上线,在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中。
- maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程。
- keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0。
- unit:参数keepAliveTime的时间单位。
- workQueue:一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响;
- threadFactory:线程工厂,主要用来创建线程;
- handler:表示当拒绝处理任务时的策略。有以下四种取值:ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。 ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务。
1.2 核心方法
在ThreadPoolExecutor类中,最核心的任务提交方法是execute()方法,虽然通过submit也可以提交任务,但是实际上submit方法里面最终调用的还是execute()方法。
public void execute(Runnable command) {
// 判断提交的任务command是否为null,若是null,则抛出空指针异常;
if (command == null)
throw new NullPointerException();
// 获取线程池中当前线程数
int c = ctl.get();
// 如果线程池中当前线程数小于核心池大小,进入if语句块
if (workerCountOf(c) 主要方法addWorker。
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 如果线程池状态大于SHUTDOWN或者线程池状态等于SHUTDOWN,firstTask不等于null
// 或者线程池状态等于SHUTDOWN,任务队列等于空时,直接返回false结束。
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
// 如果线程数量大于等于最大数量或者大于等于上限
//(入参core传true,取核心线程数,否则取最大线程数),直接返回false结束。
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false
// CAS操作给工作线程数加1,成功则跳到retry处,不再进入循环。
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
// 如果线程池状态与刚进入时不一致,则跳到retry处,再次进入循环
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 新建一个线程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 如果线程池状态在SHUTDOWN之前或者
// 线程池状态等于SHUTDOWN并且firstTask等于null时,进入处理。
if (rs largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// 启动线程
t.start();
workerStarted = true;
}
}
} finally {
// 如果线程添加失败,则将新增的对应信息删除
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
1.3 任务执行run方法
在上述addWorker中,当调用线程的start方法启动线程后,会执行其中的run方法。
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 如果任务不为空或者新获取到的任务不为空
while (task != null || (task = getTask()) != null) {
w.lock();
// 当线程池状态,大于等于 STOP 时,保证工作线程都有中断标志。
// 当线程池状态,小于STOP时,保证工作线程都没有中断标志。
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
2 整体处理过程
通过上述源码分析,我们可以得出线程池处理任务的过程如下:
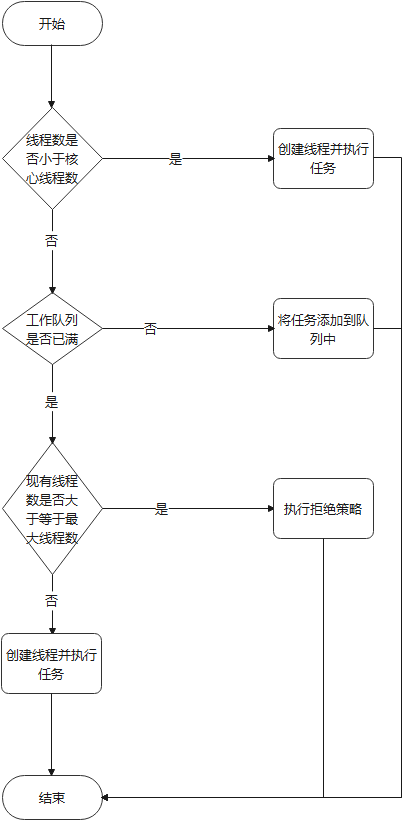
3 总结
本文从源码层面主要分析了线程池的创建、运行过程,通过上述的分析,可以看出当线程池中的线程数量超过核心线程数后,会先将任务放入等待队列,队列放满后当最大线程数大于核心线程数时,才会创建新的线程执行。
作者:京东物流 管碧强
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
