

01 引言
2023 年 7 月,阿里云容器服务 ACK 成为首批通过中国信通院“云服务稳定运行能力-容器集群稳定性”评估的产品, 并荣获“先进级”认证。随着 ACK 在生产环境中的采用率越来越高,稳定性保障已成为基本诉求。本文基于 ACK 稳定性保障实践经验,帮助用户全面理解 ACK 稳定性理论和优化策略,并了解如何使用相应的工具和服务进行稳定性保障。
02 K8s 集群稳定性和大规模场景下的挑战
K8s 常见的稳定性痛点
Kubernetes 在提供丰富的技术和功能外,架构和运维具有较高的复杂性,也产生了诸多的痛点。

痛点 1:在发布、弹性等高峰期,集群控制面服务时断时续,甚至完全不可用
面对大流量请求,如果控制面没有自动弹性扩容能力,会无法对负载自适应、导致控制面服务不可用。
例如:客户端存在高频度持续 LIST 集群中的大量资源,集群 apiserver/etcd 无法自动弹性就可能联动出现 OOM。
ACK Pro 托管版 K8s 可以对控制面组件根据负载压力做 HPA 和 VPA,可以有效解决该痛点。
痛点 2:集群节点批量 NotReady 导致雪崩,严重影响业务!
部分节点出现 NotReady,节点上 Pod 被驱逐调度到健康节点,健康节点由于压力过大也变为 NotReady,加剧产生了更多 NotReady 的节点,业务持续重启。
ACK 提供了托管节点池功能,可以对出现 NotReady 的异常节点治愈,重新拉会 Ready 状态,可以有效解决该痛点。
痛点 3:业务高峰期需快速弹性,节点上拉取 Pod 镜像耗时长达分钟级,影响业务
节点上 kubelet 并发拉取镜像遇到网络带宽限制,需要镜像加速功能支持。
ACR 提供了基于 DADI(Data Accelerator for Disaggregated Infrastructure)的按需镜像加载和 P2P 镜像加速的功能,可以加速镜像拉取,可以有效解决该痛点。
痛点 4:Master 节点/组件运维复杂度高,包含资源配置、参数调优、升级管理等
需要大量的线上场景分析和优化、故障处理、规模压测等,来分析、整理并落地最佳实践和配置。
ACK Pro 托管版 K8s 在全网的规模体量上万集群,具有自动弹性和生命周期管理的运维管理架构,有丰富的优化、应急处理等经验,持续将最佳实践和参数优化对托管组件升级。
Kubernetes 集群架构
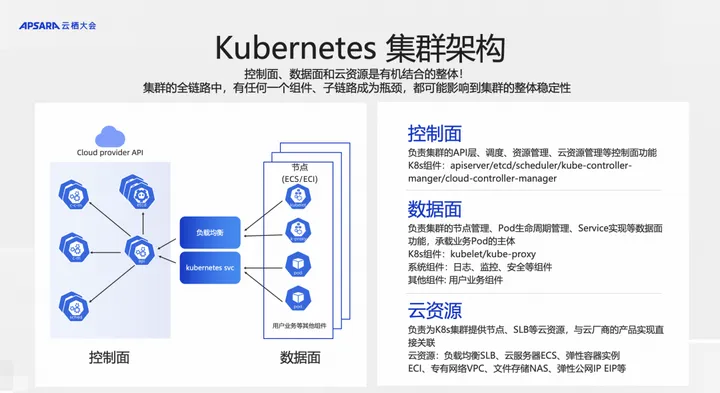
既然有这些痛点,我们从 K8s 架构的角度来分解一下,看看哪些部分可能出现故障和问题:云上 K8s 集群包含控制面、数据面、以及承载控制面和数据面的的云资源。控制面和数据面通过 SLB 和云网络连接。
控制面负责集群的 API 层、调度、资源管理、云资源管理等控制面功能,K8s 组件:apiserver/etcd/scheduler/kube-controller-manger/cloud-controller-manager。
数据面负责集群的节点管理、Pod 生命周期管理、Service 实现等数据面功能,承载业务Pod的主体。包含:K8s 组件,kubelet/kube-proxy;系统组件,日志、监控、安全等组件;其他组件,用户业务组件。
控制面、数据面和云资源是有机结合的整体!集群的全链路中,任何一个组件、子链路成为瓶颈,都可能影响到集群的整体稳定性。
我们需要从 K8s 系统中发现瓶颈、治理以及优化瓶颈,最终实现 K8s 系统在给定云资源情况下的稳定、高效的利用。
Kubernetes 稳定性体现

我们已经了解了 K8s 集群架构,那么如何评估 K8s 集群的稳定性呢?
集群稳定性涵盖 Kubernetes 服务可用性、处理时延、请求 QPS 和流量吞吐、资源水位等要素。
Kubernetes 稳定性风险和挑战
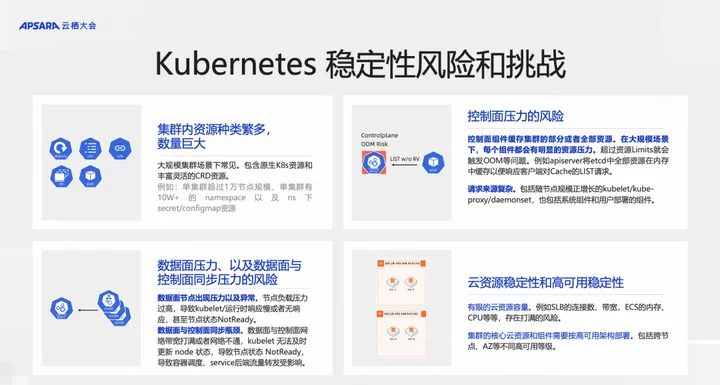
结合刚才介绍的 K8s 的架构和稳定性体现,我们来看看 K8s 集群的稳定性风险和挑战,在大规模场景下稳定性风险和挑战会更加突出。
挑战 1:集群内资源种类繁多,数量巨大
大规模集群场景下常见。包含原生 K8s 资源和丰富灵活的 CRD 资源。节点是 K8s 的一种资源,节点规模大的集群是大规模集群的一种;从 K8s 治理的角度,集群中某种资源数量巨大,例如 configmap、secrets 等,即便节点数不大,也可以称为大规模集群。
例如:单集群超过 1 万节点规模、单集群有 10W+ 的 namespace 以及 ns 下 secret/configmap 资源。
挑战 2:控制面压力的风险
控制面组件缓存集群的部分或者全部资源。在大规模场景下,每个组件都会有明显的资源压力。超过资源 Limits 就会触发 OOM 等问题。例如 apiserver 将 etcd 中全部资源在内存中缓存以便响应客户端对 Cache 的 LIST 请求。
请求来源复杂。包括随节点规模正增长的 kubelet/kube-proxy/daemonset,也包括系统组件和用户部署的组件。
挑战 3:数据面压力、以及数据面与控制面同步压力的风险
数据面节点出现压力以及异常。节点负载压力过高,导致 kubelet/运行时响应慢或者无响应,甚至节点状态 NotReady。数据面与控制面同步瓶颈。
数据面与控制面网络带宽打满或者网络不通,kubelet 无法及时更新 node 状态,导致节点状态 NotReady,导致容器调度、service 后端流量转发受影响。
挑战 4:云资源稳定性和高可用稳定性
有限的云资源容量。例如 SLB 的连接数、带宽,ECS 的内存、CPU 等等,存在打满的风险。
集群的核心云资源和组件需要按高可用架构部署。包括跨节点、AZ 等不同高可用等级。
03 ACK 稳定性治理和优化策略
ACK K8s 稳定性概述

2023 年 7 月,ACK 成为首批通过中国信通院“云服务稳定运行能力-容器集群稳定性”评估的产品,并荣获“先进级”认证。
ACK K8s 稳定性优化,源于大规模实践经验沉淀,具体包括:ACK 全网管理了数万个 K8s 集群,对线上丰富的客户和业务场景提供全面的支持;ACK 作为底座承载了双十一、618 等超大规模的电商业务,经受住了阿里巴巴电商场景的极限压力的考验;对社区原生 K8s 做参数、性能、架构等优化,并形成产品能力。
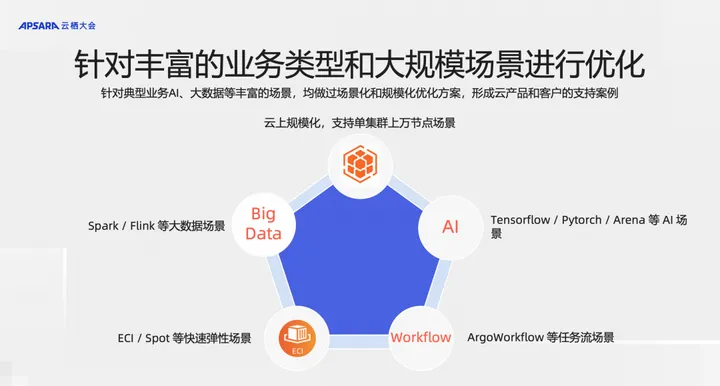
ACK 针对丰富的业务类型和大规模场景进行优化,例如:
- 云上的大规模化场景,支持单集群上万节点
- Sark/Flink 等大数据场景
- Tensforflow/Pytorch 等 AI 场景
- ECI/Spot 等快速弹性场景
- ArgoWorkflow 等任务流场景
ACK 集群稳定性治理关键点

1. 高可用架构
控制面全面按高可用架构部署。
数据面提供丰富的高可用产品能力和配置,便于用户提升集群的高可用性。
2. K8s 优化
包括 APIServer/Etcd/KCM/Scheduler/Kubelet/Kube-proxy 等组件的优化、参数配置等。
3. 集群容量规划和自动弹性
例如:规范 LIST 请求使用、优先使用 Informer 机制、优先使用 PB 协议等等。
4. 系统组件、用户组件优化
控制面托管组件支持根据请求负载自动弹性扩缩容,控制面可观测对用户透出。
数据面提供丰富的集群、节点、工作负载、Ingress 等监控告警。
5. 质量巡检、故障演练、压测体系
ACK 组件和集群自动化巡检、定期进行的故障演练和应急预案恢复验证、高效的压测体系。
6. 数据面优化
节点自动运维和自愈能力,镜像加速和 P2P 传输。
下面针对部分优化关键点详细展开说明。
高可用架构
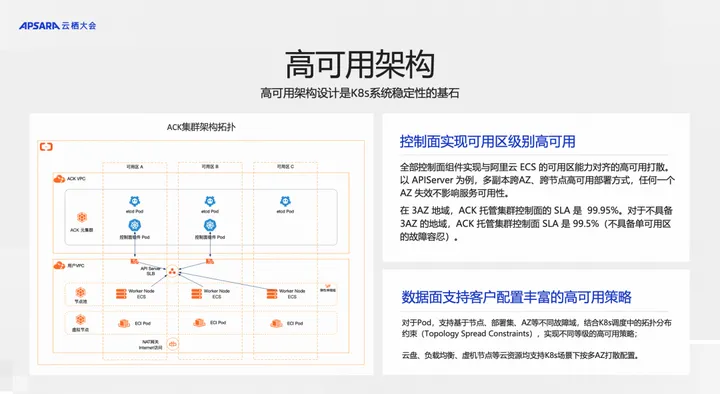
控制面实现可用区级别高可用 全部控制面组件实现与阿里云 ECS 的可用区能力对齐的高可用打散。
以 APIServer 为例,多副本跨 AZ、跨节点高可用部署方式,任何一个 AZ 失效不影响服务可用性。在 3AZ 地域,ACK 托管集群控制面的 SLA 是 99.95%。对于不具备 3AZ 的地域,ACK 托管集群控制面 SLA 是 99.5%(不具备单可用区的故障容忍)。
控制面实现可用区级别高可用全部控制面组件实现与阿里云 ECS 的可用区能力对齐的高可用打散。以 APIServer 为例,多副本跨 AZ、跨节点高可用部署方式,任何一个 AZ 失效不影响服务可用性。在 3AZ 地域,ACK 托管集群控制面的 SLA 是 99.95%。对于不具备 3AZ 的地域,ACK 托管集群控制面 SLA 是 99.5%(不具备单可用区的故障容忍)。
数据面支持客户配置丰富的高可用策略。
对于 Pod,支持基于节点、部署集、AZ 等不同故障域,结合 K8s 调度中的拓扑分布约束(Topology Spread Constraints),实现不同等级的高可用策略;云盘、负载均衡、虚机节点等云资源均支持 K8s 场景下按多 AZ 打散配置。
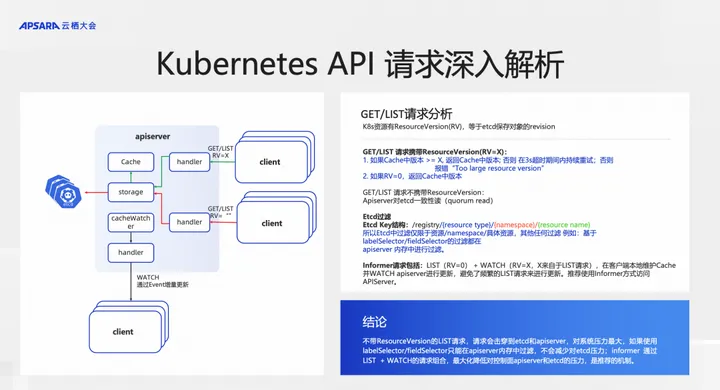
在分析 APIServer 优化前,先来看一下 K8s API 请求的分析。
这里的结论为:不带 ResourceVersion 的 LIST 请求,请求会击穿到 etcd 和 apiserver,对系统压力最大,如果使用 labelSelector/fieldSelector 只能在 apiserver 内存中过滤,不会减少对 etcd 压力;informer 通过 LIST + WATCH 的请求组合,最大化降低对控制面 apiserver 和 etcd 的压力,是推荐的机制。
APIServer 稳定性优化
1. APIServer 自动弹性
ACK 管控基于访问压力和集群容量实现 APIServer 实例自动弹性。
2. 软负载均衡
方法:负载不均会导致个别 APIServer 实例资源开销大、容易触发 OOM。Goaway 特性概率性断开并新建 TCP 连接, 实现负载均衡的效果。作用:帮助稳定运行的集群能解决负载不均衡问题。
3. 托管组件可观测性透出
全部托管组件 apiserver、etcd 等监控告警对用户透出。支持识别可能存在的非规范 LIST 请求的 Grafana 看板,帮助用户评估组件行为。
4. 集群资源清理 关闭不需要功能
及时清理不使用的 Kubernetes 资源,例如 configmap、secret、pvc 等;及时清理不使用的 Kubernetes 资源,例如 configmap、secret、pvc 等。
Etcd 稳定性优化

1. Data 和 Event etcd 分拆
Data 和 Event 存放到不同的 etcd 集群。数据和事件流量分离,消除事件流量对数据流量的影响;降低了单个 etcd 集群中存储的数据总量,提高了扩展性。
2. Etcd 根据资源画像 VPA
根据 Etcd 资源使用量,动态调整 etcd Pod request/limits,减少 OOM。
3. AutoDefrag
operator 监控 etcd 集群 db 使用情况,自动触发 defrag 清理 db,降低 db 大小,提升查询速度。
Scheduler/KCM/CCM 稳定性优化

QPS/Burst 参数调优。KCM/Scheduler/CCM 的 QPS/Burst 参数在规模化场景下需要提升,避免核心组件出现客户端限流;同时观测 APIServer 监控,避免 APIServer 对核心组件限流。
组件稳定性优化


1. 规范组件 LIST 请求
必须使用全量 LIST 时添加 resourceVersion=0,从 APIServer cache 读取数据,避免一次请求访问全量击穿到 etcd;从 etcd 读取大量数据,需要基于 limit 使用分页访问。加快访问速度,降低对控制面压力。
2. 序列化编码方式统一
对非 CRD 资源的 API 序列化协议不使用 JSON,统一使用 Protobuf,相比于 JSON 更节省传输流量。
3. 优选使用 Informer 机制
大规模场景下,频繁 LIST 大量资源会对管控面 APIServer 和 etcd 产生显著压力。频繁 LIST 的组件需要切换使用 Informer 机制。基于 Informer 的 LIST+WATCH 机制优雅的访问控制面,提升访问速度,降低对控制面压力。
4. 客户端访问资源频度
客户端控制访问大规模全量资源的频度,降低对管控的资源和带宽压力。
5. 对 APIServer 访问的中继方案
大规模场景下,对于 Daemonset、ECI pod 等对 APIServer 进行访问的场景,可以设计可横向扩容的中继组件,由中继组件统一访问 APIServer,其他组件从中继组件获取数据。例如 ACK 的系统组件 poseidon 在 ECI 场景下作为 networkpolicy 中继使用。降低管控的资源和带宽压力,提升稳定性。
04 ACK 稳定性产品功能和最佳实践器
针对刚才提到的 K8s 稳定性风险和挑战,我们看一下 ACK 是如何进行稳定性治理和优化的。ACK 提供了高效丰富的稳定性产品功能,这里着重从可观测性、故障预防与定位、自动化节点运维角度来介绍产品功能,对应的产品功能分别是:
- Prometheus for ACK Pro
- 容器 AIOps 套件
- 托管节点池
帮助客户提升透明可观测、风险可预测、故障可定位、运维自动化的稳定性保障。
Prometheus for ACK Pro
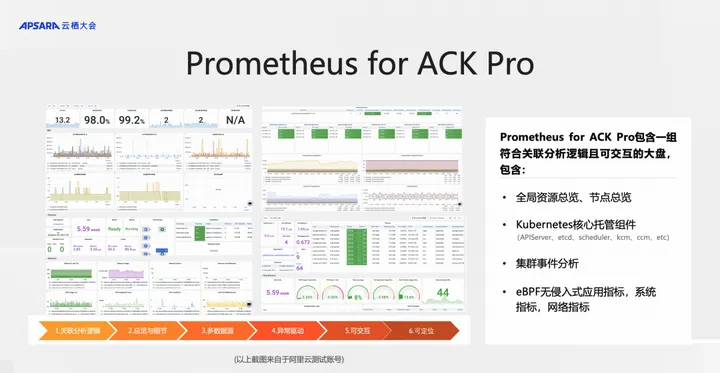
在透明可观测方面,ACK 支持从应用层、APM 层、K8s 层到基础设施层的全景可观测。PrometheusforACKPro 结合容器服务最佳实践经验,提供了可以关联分析、可交互的大盘。
例如:
- 全局资源总览、节点总览
- K8s核心托管组件的监控,例如 apiserver,etcd 等等
- 集群事件分析
- 在节点层结合 eBPF 实现了无侵入式应用监测
基于 ACKPrometheusforACKPro,可以全面覆盖数据面和控制面的可观测性。
容器 AIOps 套件-故障预防与定位

在智能运维方面,ACK 的容器 AIOps 套件凭借 10 年大规模容器运维经验沉淀,自动化诊断能力能够覆盖 90% 的运维问题。
基于专家系统+大模型,AIOps 套件提供全栈巡检、集群检查、智能诊断三大功能。
- 全栈巡检,定位集群风险巡检。可以扫描集群健康度和潜在风险,例如云资源配额余量、K8s 集群关键资源水位,并提供修复的解决方案。
- 集群检查,定位运维操作前的检查。例如企业在业务升级过程中经常遇到的K8s版本较老,基于各种顾虑不敢升级的问题,阿里云 ACK 可以自动识别出应用是否在使用 K8s 老版本废弃的 API、集群资源是否足够,帮助企业规避升级过程中遇到的风险。
- 智能诊断,定位诊断 K8s 问题。可以诊断异常的 Pod,Node,Ingress,Service,网络和内存。
托管节点池

在节点自动化运维方面,托管节点池是 ACK 面向数据面提供的产品功能。定位是让用户专注上层应用部署,ACK 负责节点池基础运维管理。
支持自升级、自愈、安全修复、极速弹性四大功能。
- 自升级是指自动升级 kubelet 和节点组件。
- 自愈是指自动修复运行时和内核问题。例如发现 NotReady 的节点,并治愈恢复为 Ready 状态。
- 安全修复是指支持 CVE 修复和内核加固。
- 极速弹性是基于 ContainerOS 以及通用 OS 的快速弹性。P90 统计算法下,完成 1000 节点扩容只需要 55s。
05 展望
ACK 稳定性保障建设会持续演进,会继续为客户提供安全、稳定、性能、成本持续优化的产品和稳定性保障!
作者:贤维 马建波 古九 五花 刘佳旭
原文链接
本文为阿里云原创内容,未经允许不得转载。
