


作者 | Chaos
导读
本文主要介绍百度搜索内容存储团队应对海量互联网数据分析计算需求时,在构建HTAP表格存储系统方向上的一些技术思考。
全文4683字,预计阅读时间12分钟。
01 业务背景
百度搜索内容存储团队主要负责各类数据,如网页、图片、网页关系等,的在线存储读写(OLTP)、离线高吞吐计算(OLAP)等工作。
原有架构底层存储系统普通采用百度自研表格存储(Table)来完成数据的读、写、存工作,此存储系统更偏向于OLTP业务场景。随着近几年大数据计算、AI模型训练的演进,对存储系统OLAP业务场景的依赖越来越重,如数据关系分析、全网数据分析、AI样本数据管理筛选。在OLTP存储场景的架构下,支持OLAP存储需求对资源成本、系统吞吐、业务时效带来了巨大挑战。为此我们在百度自研表格存储之外,结合业务实际workflow针对性优化,增加构建了一套符合业务需求的HTAP表格存储系统。
以下我们将主要介绍在百度内容HTAP表格存储系统设计落地中的一些技术思考,文中的优劣欢迎各位积极交流探讨。
02 存储设计
2.0 需求分析
整套存储设计需要解决的核心问题是——如何在OLTP存储系统中支持OLAP workflow?OLAP workflow在OLTP存储系统上带来的两个最主要的问题是:严重的IO放大率、存算耦合。
-
严重的IO放大率。 IO放大率主要来自两方面,如下图,数据行筛选、数据列筛选。
-
数据行筛选。在表格存储中,数据按照主键从小到大排列,OLAP workflow根据条件筛选过滤出符合条件的数据行,会带来严重的IO放大。
-
数据列筛选。表格存储是宽表结构,业务在一次查询中只会获取部分列,但数据是以行结构保存,需要获取整行再提取出需要的字段,依旧会带来严重的IO放大。
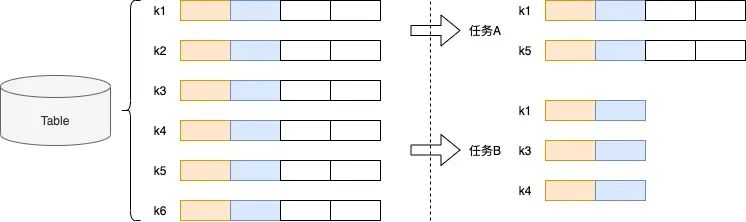
△图2.1
-
存算耦合。 存算耦合主要来自两方面,如下图,存储节点资源冗余、存储空间放大。
-
存储节点资源冗余。在一个存储节点中,OLTP vs OLAP占用的计算资源占比是3:7,为满足OLAP需要,就需要对存储节点进行扩容,然而存储节点的扩容又不仅仅是计算资源。同时,OLAP任务是间歇性的,就会造成忙时供给不足,闲时资源冗余等情况。
-
存储空间放大。为支持每一个OLAP任务的数据访问,存储引擎需要为每一个workflow创建对应的Snapshot,保证workflow完成前所依赖的所有数据文件均有效。当OLAP workflow耗时过长时,会导致Compaction后数据文件无法及时清理的情况,造成存储空间放大。
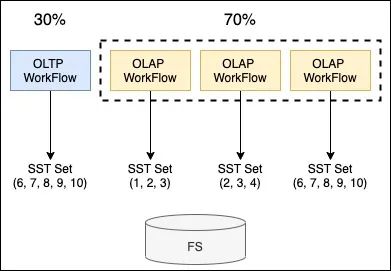
△图2.2 Node
2.1 架构设计
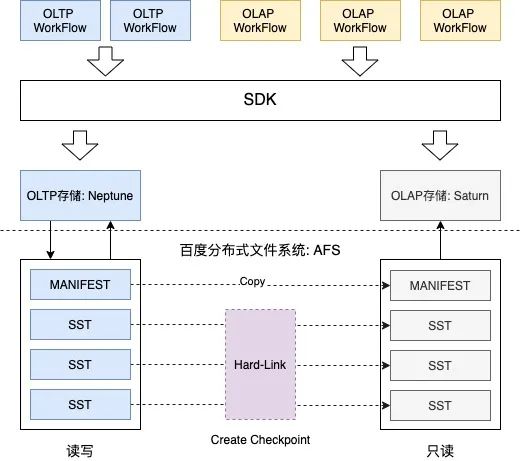
△图2.3
1.架构采用业界HTAP主流设计思想,将OLTP和OLAP workflow拆分到两套存储系统中,如F1 Lightning、ByteHTAP,在SDK层根据任务类型分发到不同的存储系统中。
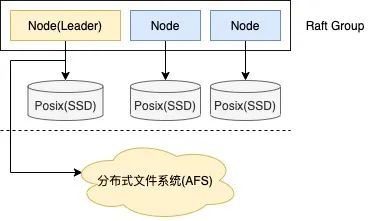
2.OLTP存储系统——Neptune,采用Multi-Raft分布式协议组建存储集群,采用本地磁盘(SSD/HDD等) + 百度分布式文件系统AFS组成存储介质。
3.OLAP存储系统——Saturn,Serverless设计模式,无常驻Server,即用即加载,贴合OLAP workflow的不确定性和间歇性。
4.OLTP与OLAP存储系统间,采用数据文件硬链的方式进行数据同步,全版本替换,成本低、速度快,充分贴合Saturn Serverless设计模式。
如上架构设计图,可将OLTP与OLAP workflow拆分到两套独立的系统中,解决上述提到的存算耦合问题。
- 解决存储空间放大问题。 空间放大主要带来的问题是存储节点成本,Workflow分离的架构将OLAP需要的数据文件采用AFS低成本存储,减少了对存储节点存储空间的压力。
△图2.4
OLAP存储系统的数据写入并没有使用常见的log redo或raft learner模式,最主要还是在保证OLAP存储系统的Serverless特性的同时,又能实时感知到OLTP系统的最新写入结果。
- 解决存储节点资源冗余问题。 拆分后,分布式存储节点将大量重型OLAP workflow转移到OLAP存储——Saturn中,将极大减少存储节点的计算压力。同时,OLAP存储的Serverless设计模式又可贴合workflow的不确定性和间歇性。
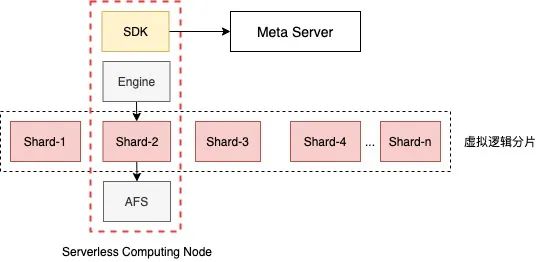
△图2.5 Saturn Serverless模型
计算节点可以部署在任意计算集群中,如Map-Reduce、自研计算节点Pioneer等,在SDK中直接初始化存储引擎,从AFS中访问对应分片的数据文件。计算节点可充分利用云原生系统(PaaS)的弹性资源,解决资源常驻冗余问题。
2.2 存储引擎优化思路
结合上面的分析以及设计思路,已有效地解决了存算耦合问题。在本节中,我们将重点介绍解决IO放大率问题的一些优化思路。
2.2.1 数据行分区
数据行分区思想在很多OLAP存储系统中很常见,如当前比较流行的一些数据湖架构,ClickHouse、IceBerg等。在表格存储中,数据行分区的好处是可以极大减少在数据行筛选过程中IO放大率。以下是我们在存储引擎中支持数据行分区的设计思路:
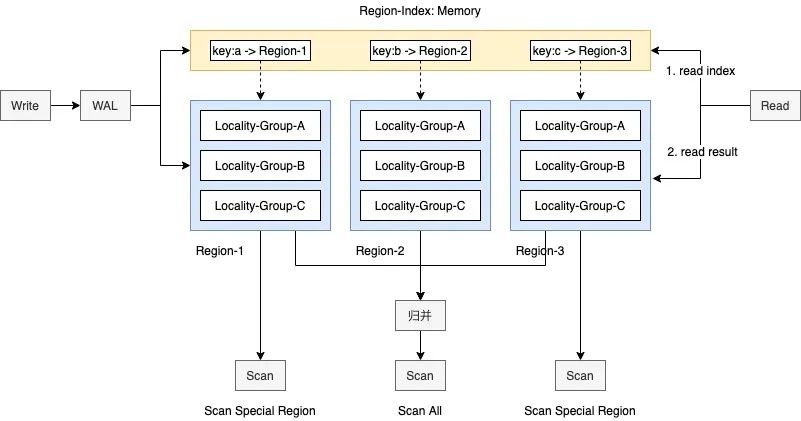
△图2.6
数据行分区的思想在OLTP和OLAP存储引擎中都有使用,OLTP存储引擎以数据行分区构建的数据文件可直接被OLAP存储引擎加载,减少了OLAP存储的数据构建工作。
数据行分区在Write、Read、Scan场景下的处理流程分别为:
1.Write操作。 Write时会根据请求中的特殊Region描述,如分区键,找到需要写入的Region-Index和Region上下文,前者保存Key的分区索引信息,后者中保存实际数据,操作记录由WAL中保存。
2.Read操作。 Read操作相比通常直接访问数据,需要多进行一次分区索引访问,为减少多一次访问带来的性能折损,我们将分区索引信息全内存化。由于索引数据非常小,因此全内存化是可接受的。
3.Scan操作。 Scan操作相比之下没有任何变更,但在Scan特殊分区场景下可大量减少IO放大。因为相比之前的行过滤模式,可直接跳过大量不需要的数据。
在业务存储支持时,合理设置数据行分区,可极大减少数据行筛选过程中的IO放大率。
2.2.2 增量数据筛选
在实际业务中,有很大一个场景时获取近期(如近几个小时、近一天)有值变化的数据,常规的做法是Scan全量数据,以时间区间作为过滤条件,筛选出符合条件的结果。但如此的筛选逻辑会带来严重的IO放大,因为满足条件的结果只占全量结果的一小部分。为此,我们在引擎层调整优化Compaction时机以及调整筛选流程,减少增量数据筛选过程中需要访问的数据文件集合,降低IO放大,业务提速。
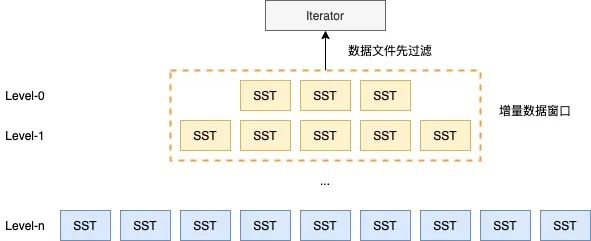
△图2.7 LSMT
2.2.3 动态列结构
在OLAP存储引擎中,还存在一类访问场景会带来IO放大问题,数据列筛选。在表格存储系统中,一个Key可以包含多个列族(Column Family),一个列族中可以包含任何多个数据字段,这些字段以行结构存储在同一物理存储(Locality Group)中,当筛选特定数据列时,需要进行整行读取,然后过滤出需要的字段,这也将带来IO放大问题。
同时,OLAP workflow的访问不确定性导致存储层无法及时调整数据在物理存储中的结构。为此,我们引入动态列结构的概念,在逻辑层对业务透明,在物理层根据近期OLAP workflow特性及时调整物理结构。
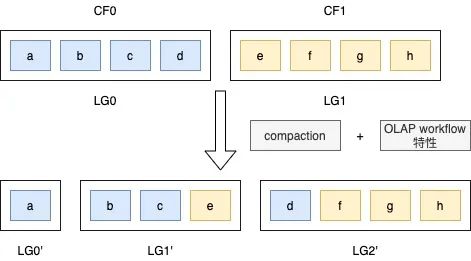
△图2.8
如上图,在逻辑存储中,分为两个LG,根据workflow特性,把业务常用的访问字段在Compaction阶段存放在同一物理存储结构中,反之,这样可以减少字段筛选阶段的IO放大率。
动态列结构只在OLAP存储引擎中生效,我们在原有OLAP存储中引入workflow收集以及compaction任务,将从OLTP存储中同步的数据构建成更适合OLAP场景的存储结构。
03 计算与调度
在本节,我们将介绍在此HTAP表格存储系统基础上,如何设计实现任务计算和调度系统,简化业务使用成本,提升业务效率。
在大量搜索内容OLAP workflow中,从表格存储系统中提取筛选数据只占全部任务的一小部分,大量任务需要对数据进行加工处理得到需要的结果。常规的做法是多任务串联,这样做的缺陷是大量中间临时数据存储开销。
为此我们为HTAP表格存储系统构建了一套计算与调度系统,系统两大特点:任务开发SQL化、数据处理FaaS化。
3.1 SQL化与FaaS化
我们充分贴合上述存储系统特性,自研了一套数据查询语言——KQL,KQL类似于SQL Server语法。同时,又结合存储系统特性以及计算框架,支持一些特殊语言能力,最主要的是能支持原生FaaS函数定义,当然也支持外部FaaS函数包依赖。
如下是一段KQL语句例子以及说明:
function classify = { #定义一个Python FaaS函数
def classify(cbytes, ids):
unique_ids=set(ids)
classify=int.from_bytes(cbytes, byteorder='little', signed=False)
while classify != 0:
tmp = classify & 0xFF
if tmp in unique_ids:
return True
classify = classify >> 8
return False
}
declare ids = [2, 8];
declare ts_end = function@gettimeofday_us(); # 调用Native Function获取时间
declare ts_beg = @ts_end - 24 * 3600 * 1000000; # 四则运算
select * from my_table region in timeliness # 利用存储分区特性,从my_table中的timeliness分区获取数据
where timestamp between @ts_beg and @ts_end # 利用存储增量区间特性,筛选增量数据
filter by function@classify(@cf0:types, @ids) # 在Filter阶段调用自定义FaaS函数
convert by json outlet by row;
desc: # 对计算框架进行特殊描述
--multi_output=true;
3.2 任务生成与调度
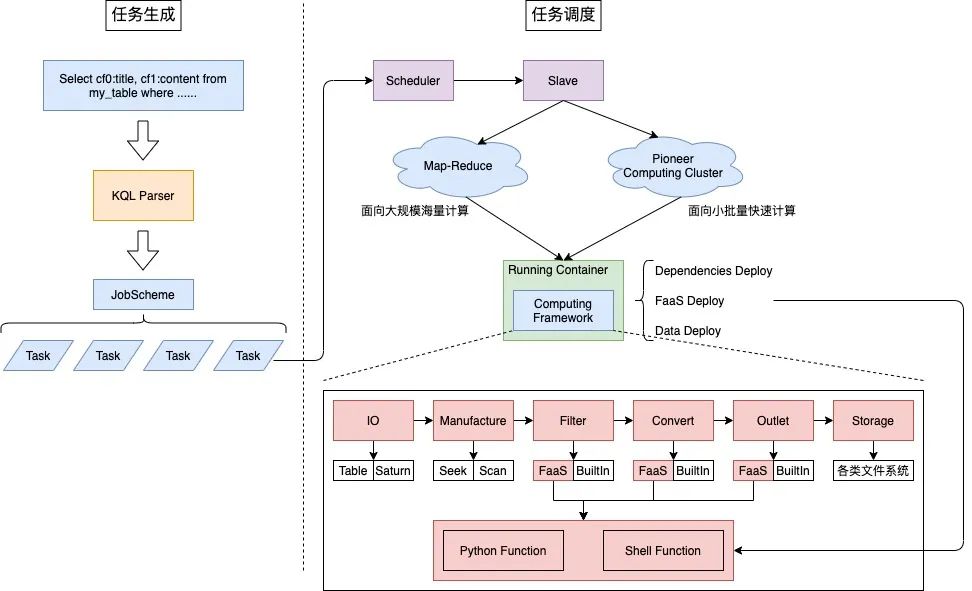
1.任务生成。 在任务生成阶段将KQL语句解析优化成相关的调度任务,一个Job包含多个Task。
2.任务调度。
-
任务调度的计算节点可以是Map-Reduce,也可以是自研计算集群Pioneer,负责不同计算场景。
-
任务运行容器负责数据依赖部署和运行计算框架。
-
计算框架采用插件化设计思想,依托KQL语言进行差异化描述。计算框架的最大特点是,可在数据处理节点执行用户自定义FaaS函数。
04 总结
当前HTAP表格存储系统已在全网网页数据离线加速、AI模型训练数据管理、图片存储以及各类在线离线业务场景落地,数据存储规模达>15P,业务提速>50%。
与此同时,随着大模型时代的到来,对存储系统带来了更多的挑战,我们也将继续深度优化,设计更高性能、高吞吐的HTAP表格存储系统。
——END——
推荐阅读
大模型时代,“人人可AI”的百度开发者平台长什么样?
数十万QPS,百度热点大事件搜索的稳定性保障实践
百度搜索万亿规模特征计算系统实践
通过Python脚本支持OC代码重构实践(三):数据项使用模块接入数据通路的适配
百度搜索智能化算力调控分配方法
