


去年出过一期「程序员黑话集」,一直想着更新一季,正好最近业内接连发生了几起影响比较大的故障,那我们就专门做一期「故障专辑」吧。
故障
故障有好几种叫法,比较正式的
- 故障 – Outage
- 事故 – Incident
不怎么严重的,时间很短的
- 抖了一下 – Jitter(多用于网络)
- Hiccup (中文翻译是打了个嗝,不过中文里貌似没有这个讲法)
通俗点的说法
- 挂了/崩了- Down
500
当在请求某个网络资源时,服务器内部发生错误时,返回的错误编号。扩展为系统发生内部故障。

变更
虽然突然的流量暴涨,或者光缆被挖断,数据中心着火,被雷劈都有可能,但绝大多数时候,故障都是变更导致的。

变更分为三大类:
- 代码变更 – Code Change
- 配置变更 – Config Change
- 数据库变更 – Database Change
左移 (shift-left)
降低变更风险的一个方法,就是做变更前检查,问题越早发现越好。因为变更的流水线是从左往右画的,起点在左边。所以左移就是把检查尽量靠近起点。
金丝雀 (Canary)
以前矿工下井,会带一只金丝雀,如果井下空气出现状况,更敏感的金丝雀会先有异常。这个概念也带到了软件研发里。会循序渐进地做变更。另外一种叫法是灰度 (Grayscale)。

单元化/区域化 (Regionalization)
在互联网公司逐渐普及的架构,主要由 AWS 发扬光大,把服务进行隔离。
爆炸半径 (Blast Radius)
金丝雀和单元化都是为了降低爆炸半径,减少故障的影响面。

值班 (On-call)
也叫 Carry the pager。以前带着的传呼机叫做 Pager。现在传呼机被手机/软件取代了,但 Pager 这个名字沿用了下来。

复盘 (Postmortem)
原义是尸检报告。在软件研发领域,指详细的故障分析报告。
惊群 (Thundering Herd)

打雷后,动物一下子被惊醒了,到处乱窜,造成混乱。在故障恢复阶段要小心的问题,很容易刚拉起一个服务,立马又被积压的请求打挂。
结语
船停在港口是最安全的,但那不是造船的目的。软件需要持续的变更迭代,变更就有风险。但研发团队可以通过引入工具,来降低风险,针对一开始变更的三种类型,市面上也有成熟的开源方案: 代码变更 – 老牌的有 Jenkins,新兴的有 Drone CI 和 Zadig

配置变更 – Apollo

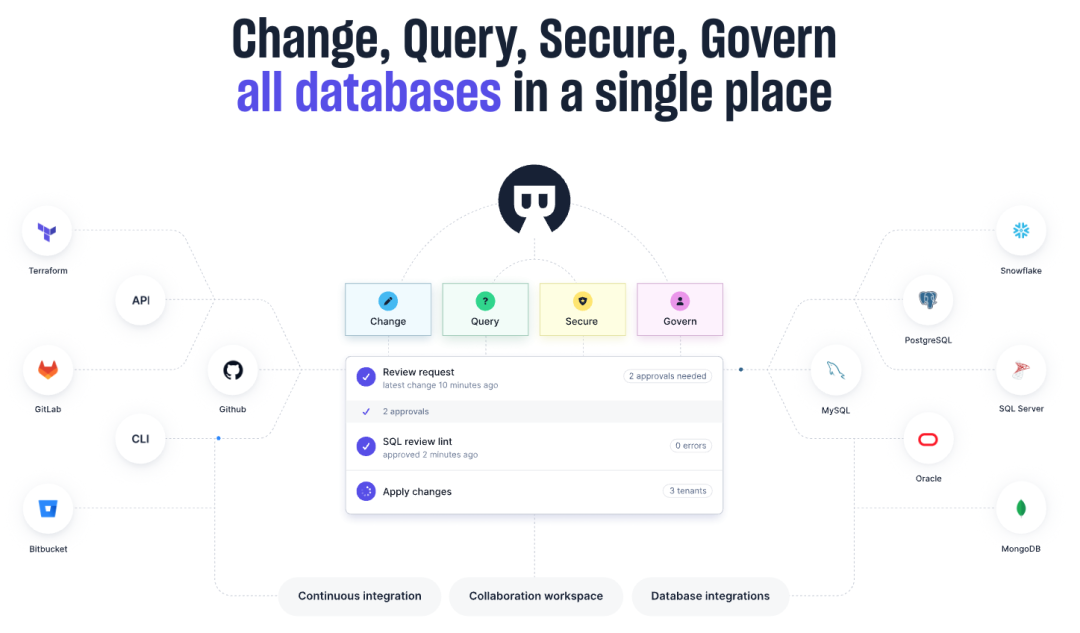
数据库变更 – Bytebase
🍀好运!
💡 更多资讯,请关注 Bytebase 公号:Bytebase
