


本文整理自 NebulaGraph 核心开发 Yee 在直播《聊聊执行计划这件事》中的主题分享。分享视频参见 B站:https://www.bilibili.com/video/BV1Cu4y1h7gn/
一条 Query 的一生
在开始正式地解读执行计划之前,我们先来了解在 NebulaGraph 中,一条查询语句(Query)是如何被校验、生成语法树,到最后被转为逻辑 / 物理的执行计划。而这个 Query 生命周期,无论是 NebulaGraph 原生查询语言 nGQL 或者是从 v2.x 开始兼容的 openCypher,都会经历从字符串到执行计划的过程。这个过程对应到编程语言,是一个编译的过程。
查询语句的生命周期大概有以下几个阶段:
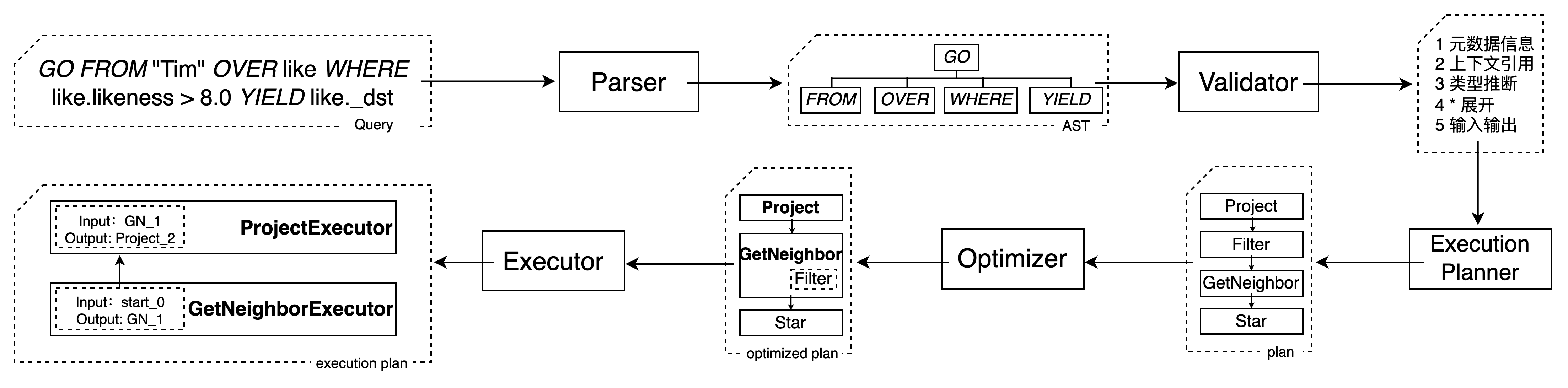
同大多数的数据库类似,一个 Query 的字符串会经过 Parser(词法语法解析器),转成一个 AST(抽象语法树)。而抽象语法树中,不同的查询语句会转成不同的抽象语法树节点。再经过一道 Validator(校验器),进行语句的合法性校验。校验阶段,主要是根据创建点边元素的 Schema 信息(元数据信息)。由于 NebulaGraph 查询语言设计之初是 schema-based 的设定,因此在语句查询时可(基于语句上下文关系)事先进行相关推导,比如某个查询会用到哪些(Schema)类型。
这里插个知识点,在 NebulaGraph 中需要注意两个关键类型:EdgeType(Edge)和 Tag(Vertex),像每条 Edge 对应的边类型 EdgeType,其包含的边类型属性都是有具体的 Data Type。此外,便是每个点 Vertex 的属性,每个点的属性都会归类放到对应的 Tag 中,变成其对应的点类型属性 Tag property。类比关系型数据库的话,Tag 相当于是一张表。在 NebulaGraph 中,点和边的属性虽然受到 Schema 约束,但是对某个边的两端点对应的类型是不作约束。因此,插入点或者是修改点,是通过 ID(VID)进行相关操作,与点类型无关。
回到上面的 Query 生命周期,在进行语句校验之后,将之前的词法转成 NebulaGraph 中包含特定算子的执行计划 Execution Planner。随后,执行计划会经过一道优化,通过优化器 Optimizer 变成更优的执行计划,再交由调度器去执行。在传统的数据库中,执行计划分为逻辑计划和物理计划,但在 NebulaGraph 中目前只存在一种计划,便是物理计划,像上面流程图中,Optimzer 处理的计划便是一个物理计划。因此,经过 Optimizer 优化过的 optimized plan,其实是一个可直接执行的物理计划。
而执行计划的运行,主要是由上图的 Executor(其他数据库可能叫 Operator)完成。在执行这层,会涉及到接口交互,例如:同 storage 层“打交道”,会调用 rpc 接口;同 graph 层交互,会调用一些计算算子,像上图加粗的 Project、Filter 这种纯计算算子。除此之外,执行还会涉及到执行模型,比如多线程、Runtime 等问题。社区中大家遇到的一些执行性能问题,可能就同它们有关。
执行计划示例
GO 3 STEPS FROM "player100" OVER follow WHERE $$.player.age > 34 YIELD DISTINCT $$.player.name AS name, $$.player.age AS age | ORDER BY $-.age ASC, $-.name DESC;
示例出处:《nGQL 简明教程 vol.02 执行计划详解与调优》 网址:https://discuss.nebula-graph.com.cn/t/topic/12010
这是一个典型的 nGQL 查询语句,通过 GO 子句遍历,再通过 WHERE 子句进行过滤,最后经由 ORDER BY 排序输出。
下图是上面查询语句生成的执行计划:
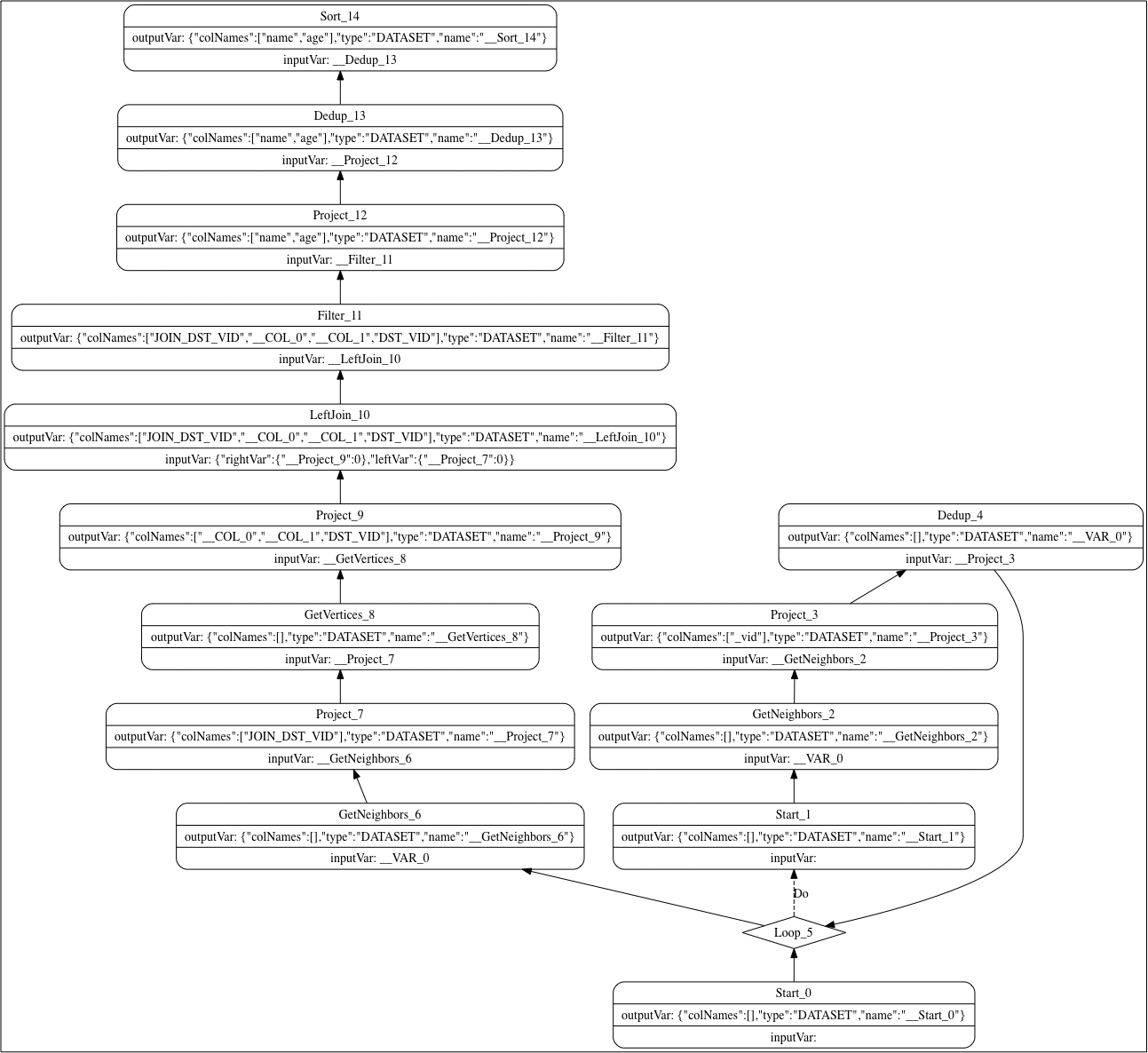
如上所示,这个执行计划还是相对比较复杂的。它同大家见惯的关系型数据库的执行计划不大一样,像右下角的 Loop,左上角单依赖的 LeftJoin 可能同大家之前接触的都不大一样。
从结构上看,同 Neo4j 的树 Tree 结构不同,NebulaGraph 中的执行计划,不仅有方向,还有环。为什么 NebulaGraph 的执行计划结构如此不同呢?
explain format="dot" {
$a=go 2 steps from "Tim Duncan" over like yield like.likeness as c1;
$b=go 1 steps from "Tony Parker" over like yield like.likeness as c1;
$c=yield $a.c1 as c1 union yield $b.c1 as c1;
}
我们来看一下上面这个例子,这里定义了 a、b、c 变量。a 和 b 之间不存在任何关系,都是几跳遍历之后,输出结果。而 c 则是对这两个变量进行了 union 操作。我们来看看这三条语句对应的执行计划:
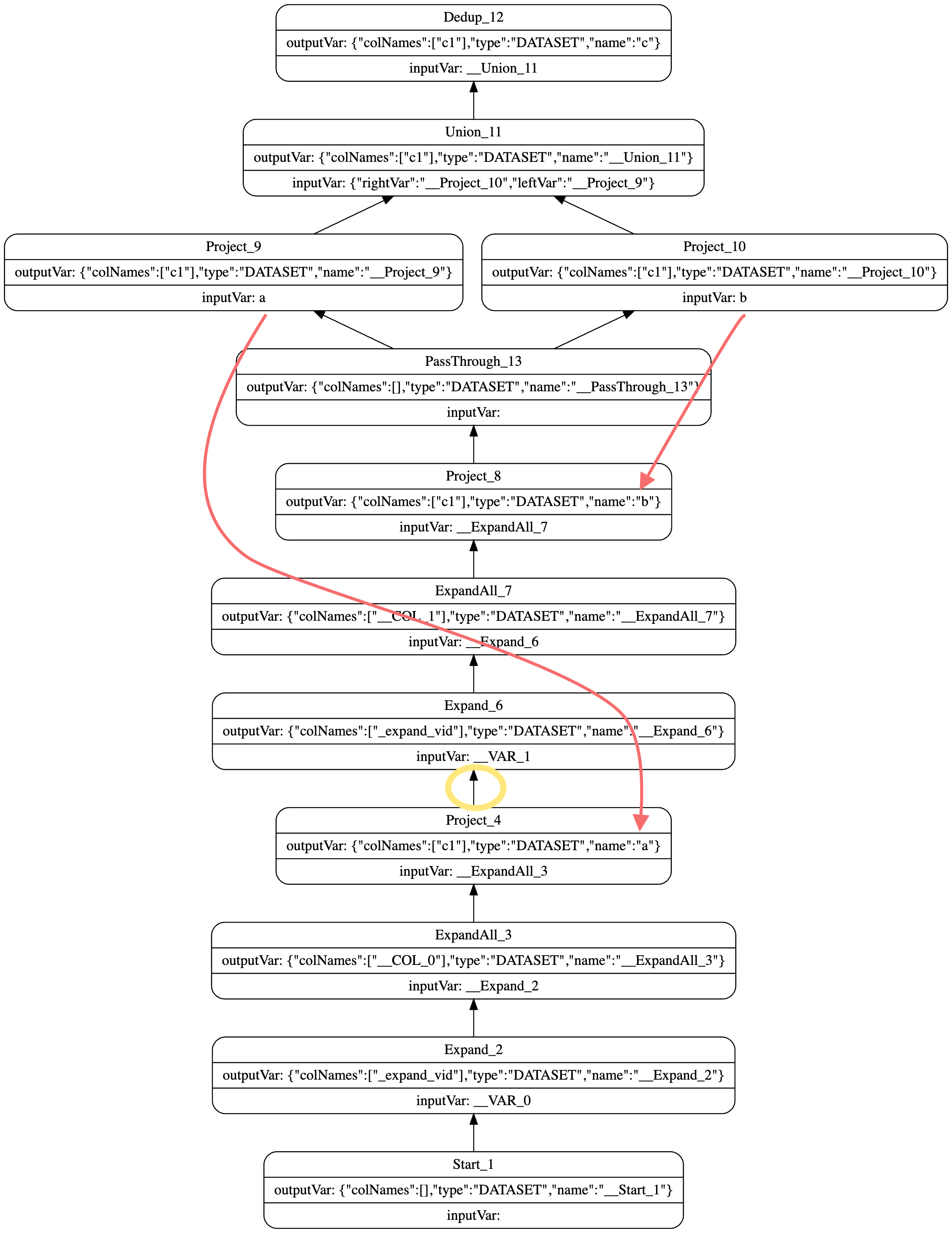
可以看到,第一条语句跟第二条语句,还有第三条语句,在执行依赖上是一个顺序依赖:以上图黄色圈为分界线,黄色圈以下为 a 的 plan,黄色圈以上、Union_11 以下为 b 的 plan,Union_11 及其以上为 c 的 plan。
而数据依赖可以看箭头部分,Project_9 的数据依赖输入为 a,它是由 Project_4 提供的,而非顺序上下方的 PassThrough_13,同理,Project_10 数据依赖是 Project_8 的输出变量 b。
这里需要花点时间区分的是:执行依赖和数据依赖。执行依赖就是上图黑色箭头的顺序依赖,而数据依赖则要看算子对应的 inputVar 来自哪里。因此,数据依赖可能同执行依赖是同一个逻辑顺序,也可能是不同的顺序。
造成上述情况的原因是,nGQL 这个查询语言本身是非常灵活的。不同于 SQL 将 a、b、c 分别生成执行计划,生成 3 个执行计划,在 NebulaGraph 中,像上面这种 a、b 没有数据依赖关系,c 依赖 a、b,在生成 plan 的时候,会将其当成拥有一定顺序 subsequential 的语句进行处理。一条执行计划便可完成多条语句的执行,当然非常灵活,但也变相地增加了语句调优的难度。
再来看一个 openCypher 的例子:
match (v:player)
with v.name as name
match (v:player)--(v2) where v2.name = name
with v2.age as age
match (v:player) where v.age>age
return v.name
在这个多 MATCH 的例子中,每个 MATCH 都可以作为一个 Pattern。像这条语句中第一个 MATCH 的输出结果传递给下面的第二个 MATCH 变成过滤输入,而第三个 MATCH 的过滤输入则来源于第二个 MATCH 的输出。每个 MATCH 通过 WITH 进行连接,它不同 nGQL,存在 Subquery 的概念,在 openCypher 这里,数据依赖关系是线性,非常自然地通过一个个 WITH 传递给下一个 Pattern 的。如果第一个 WITH 没有将结果带到第二个 MATCH,第三个 MATCH 便无法完成。
正是因为这种线性关系,Neo4j 的执行计划是树状的;而 nGQL 因为查询灵活性的缘故,生成执行计划中有向有环图。
执行计划的优化

目前,NebulaGraph 只做了 RBO 优化,即:Rule-Based Optimization 基于规则的优化。NebulaGraph 的 RBO 是基于业界流行的实现方法,有些许的差异化,用户可以基于之前的经验或者相关规则,进行 plan 的优化(变形)。
NebulaGraph 的 RBO 是以 memo + bottom up 方式进行的。
在 NebulaGraph 中,每个 plan 的 plan node 会放到一个小组 group 中,每个 group 中的 plan node 语义上等价,上一个 group node 连接到下一个 group,而下一个 group 中有多个 plan node 的话,便可变化出多个 plan。
整个优化的过程,其实是一个迭代的过程,优化器会找到每个 plan 中最叶子的 plan node,同规则集进行匹配,规则集可以查看这里:https://github.com/vesoft-inc/nebula/tree/master/src/graph/optimizer/rule。如果规则匹配上,则将两个 subplan 进行变形,生成新的 subplan,并插入到相关的 group 中。
比如上图左侧的 Filter 算子,它和 GetNeighbors 算子通过某个 rule 匹配上了,便会生成新的 GetNeighbors node,它带有 Filter。新的 GetNeighbors node 会插入到之前的 Filter 所在的 group,因为 memo 的原因,新的 GetNeighbors 便可同之前的 GetNeighbors 连接的 subplan Start 进行连接。
基于 RBO 默认如果匹配上规则,则匹配上规则之后生成的新的 plan 是优于之前的 plan,新的 plan 会直接替代旧的 plan。因此,这个执行计划最后会变成右侧这样。
几个执行计划调优的 flag
上文提到过,执行计划中会有个 Runtime 阶段,下面参数主要是影响 graph 这边 Runtime 阶段的执行效率。
-
--max_job_size:每个算子内部并发的最大 job 数; -
--min_batch_size:算子内部并发执行时,切分任务时的最小 batch 行数; -
--optimize_appendvertices:AppendVertices 算子内部的性能优化控制,当没有悬挂边时可以打开该项减少 RPC 调用。
max_job_size 主要控制 graph 部分算子的并发程度,同 min_batch_size 配合使用。这和 NebulaGraph 的物化模型有关,在 NebulaGraph 中每个算子在被执行完之后,其结果会被物化到内存中,在下一次迭代的时候去对应内存中捞取数据,而不是通过 Pipeline 的方式进行计算。max_job_size 和 min_batch_size 这两个 flag 控制了迭代过程中每个线程可处理的 batch 数量,从而达到优化的效果。
optimize_appendvertices 参数主要是用来服务 MATCH 语句的,当我们使用 MATCH 时,可能会常遇到一个情况:用 MATCH 去做路径查找时,希望这个路径中是不存在悬挂边的。假如,你知道你的数据中不存在悬挂边,可以设置 optimize_appendvertices 为 true,这样就无需再同 storage 交互去验证是否这条边的起始点存在,从而会节约执行时间。
执行计划如何看?
上面说了些原理,下面可是实操下,教你看懂执行计划,以及如何去优化它。
将 PROFILE 或者是 EXPLAIN 加在对应的语句前面,即可得到相关的执行计划。像这样:
profile GET SUBGRAPH 5 STEPS FROM "Yao Ming" OUT like where like. likeness > 80 YIELD VERTICES AS nodes, EDGES AS relationshipis;
explain GET SUBGRAPH 5 STEPS FROM "Yao Ming" OUT Like where like. likeness > 80 YIELD VERTICES AS nodes, EDGES AS relationshipis;
如果你不知道数据量的情况下,用 EXPLAIN 可查看对应的执行计划构成,它不包括该语句各个算子的执行时间。
在社区中,常会到一类问题:我通过 SUBGRAPH 进行条件过滤时,是不是每一跳都会应用到边过滤。相信通过这个例子,你就能知道是不是每跳都会应用到条件过滤了。
Execution Plan (optimize time 41 us)
-----+-------------+--------------+----------------+----------------------------------
| id | name | dependencies | profiling data | operator info |
-----+-------------+--------------+----------------+----------------------------------
| 2 | DataCollect | 1 | | outputVar: { |
| | | | | "colNames": [ |
| | | | | "nodes", |
| | | | | "relationshipis" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__DataCollect_2" |
| | | | | } |
| | | | | inputVar: [ |
| | | | | { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Subgraph_1" |
| | | | | } |
| | | | | ] |
| | | | | distinct: false |
| | | | | kind: SUBGRAPH |
-----+-------------+--------------+----------------+----------------------------------
| 1 | Subgraph | 0 | | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Subgraph_1" |
| | | | | } |
| | | | | inputVar: __VAR_0 |
| | | | | src: COLUMN[0] |
| | | | | tag_filter: |
| | | | | edge_filter: (like.likeness>80) |
| | | | | filter: (like.likeness>80) |
| | | | | vertexProps: [ |
| | | | | { |
| | | | | "props": [ |
| | | | | "_tag" |
| | | | | ], |
| | | | | "tagId": 2 |
| | | | | }, |
| | | | | { |
| | | | | "props": [ |
| | | | | "_tag" |
| | | | | ], |
| | | | | "tagId": 4 |
| | | | | }, |
| | | | | { |
| | | | | "props": [ |
| | | | | "_tag" |
| | | | | ], |
| | | | | "tagId": 3 |
| | | | | } |
| | | | | ] |
| | | | | edgeProps: [ |
| | | | | { |
| | | | | "props": [ |
| | | | | "_dst", |
| | | | | "_rank", |
| | | | | "_type", |
| | | | | "likeness" |
| | | | | ], |
| | | | | "type": 5 |
| | | | | } |
| | | | | ] |
| | | | | steps: 5 |
-----+-------------+--------------+----------------+----------------------------------
| 0 | Start | | | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Start_0" |
| | | | | } |
-----+-------------+--------------+----------------+----------------------------------
Tue, 17 Oct 2023 17:35:12 CST
生成在终端的这个执行计划是表结构的,通过 id 和 dependence 可查看到对应的依赖关系,从而解决之前提到过的执行计划中有环这种问题。
先看看当中 subgraph 算子信息,我们可以 edge_filter 中带有表达式,如果 edge_filter / tag_filter 中带有表达式,则表示该表达式被计算下推了。
下面是通过 PROFILE 查看到的更具体的执行计划:
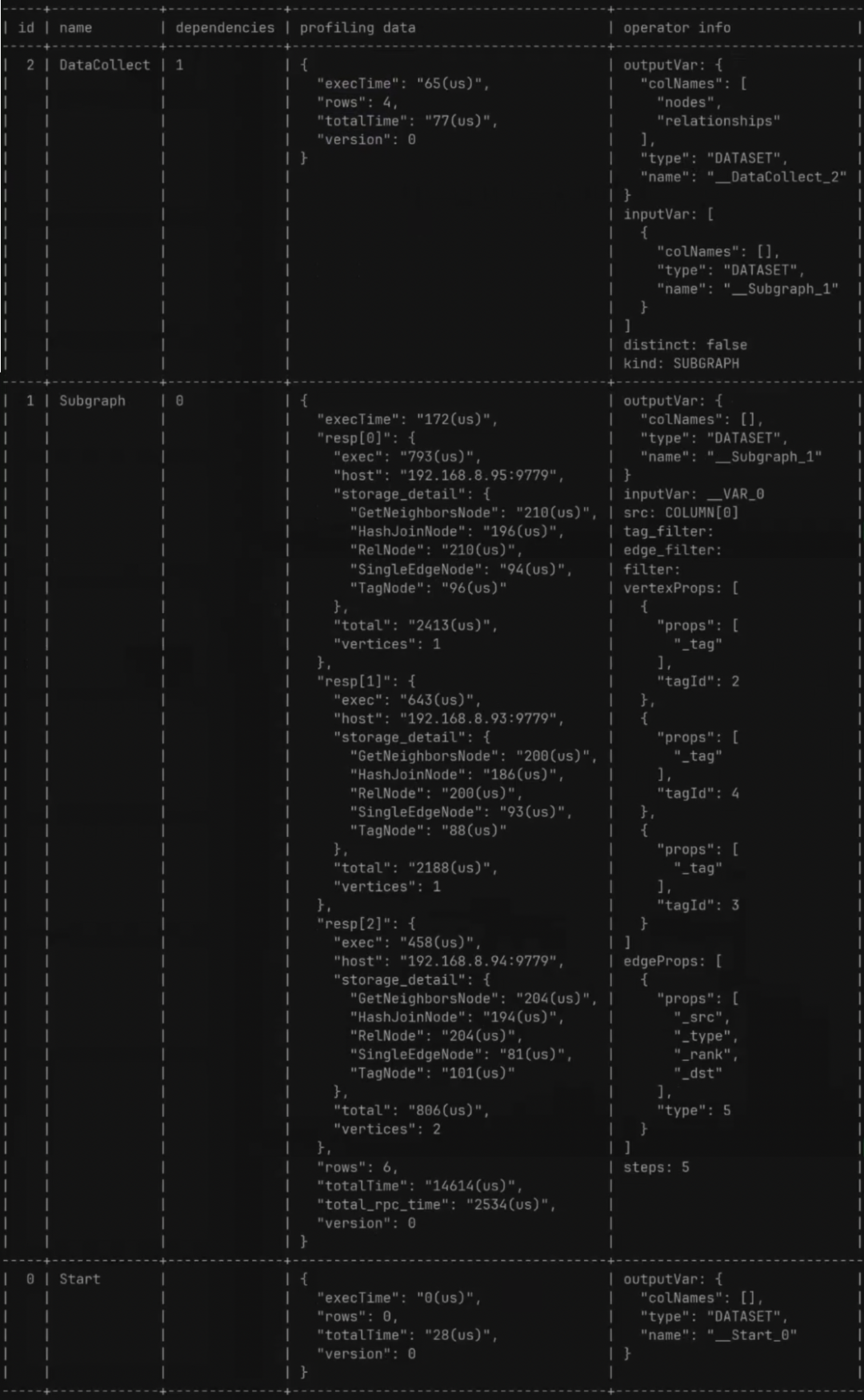
DataCollect 算子有这些参数:
-
execTime:graphd 的处理时间; -
rows:返回的数据条数; -
totalTime:从算子起始到到算子退出时间; -
version:像前面章节提到过的 LOOP,其实 LOOP 里面有一个 LOOP body,对应也是一个 subplan。而这个 subplan 则是会被重复执行,且数据放在同一个变量当中,而这个变量则会有多个版本,即 version。假如算子不在 LOOP body 内,则只有一个 verison。默认为 0;
Subgraph 算子有这些参数(同上面已讲解参数去重):
-
resp[]:每个 storage 节点执行的结果 -
exec:storaged 的处理时间,同上面的 graphd 处理时间的execTime; -
storage_detail:storage 信息,由于 subgraph 需要同 storage 交互,因此由这个字段用来记录 storage 这边 plan node 的执行时间; -
total:storage client 接收到 graphd 请求到 storage client 发送请求的时间,即 storaged 本身的处理时间加上序列化和反序列化的时间; -
vertices:该语句涉及的点的数据; -
total_rpc_time:graphd 调用 storage client 发出请求到接收到请求时间;
生成格式的执行计划
在刚开始的时候展示的执行计划和实操时展示的执行计划格式并不相同,profile format="" 来完成格式指定,默认为表结构,可通过格式指定,指定为 .dot 格式,在终端复制出来执行计划,前往在线网站:https://dreampuf.github.io/GraphvizOnline/#digraph 进行格式渲染。
以上,便是一个全方位的执行计划讲解。当然你可以通过阅读思为的《nGQL 简明教程 vol.02 执行计划详解与调优》,了解更多的例子从而掌握执行计划。
推荐阅读
- 《nGQL 简明教程 vol.02 执行计划详解与调优》:https://discuss.nebula-graph.com.cn/t/topic/12010
