


近期, OpenAI 的开发者大会迅速成为各大媒体及开发者的热议焦点,有人甚至发出疑问“向量数据库是不是失宠了?”
这并非空穴来风。的确,OpenAI 在现场频频放出大招,宣布推出 GPT-4 Turbo 模型、全新 Assistants API 和一系列增强功能。其中,王炸功能 Assistants API 的内置工具支持了代码解释器、知识库检索以及函数调用,允许接入外部知识(文档)、使用更长的提示和集成各种工具。它能够帮助开发者分担繁重的工作,并构建高质量的 AI 应用。
乍一看,OpenAI Assistants 自带的检索功能十分强大,但如果对行业足够了解,便会发现其仍存在诸多限制。OpenAI Assistants 检索严格限制了数据规模,且缺乏定制化的能力。因此,搭建高效的应用还需要使用自定义的检索器。所幸,OpenAI 的函数调用能力允许开发者无缝接入自定义的检索器,从而打破对于知识库数据量的限制,更好地适应多样化的用例。
今天我们就来聊聊 OpenAI Assistants 内置检索功能的限制及其解决方案——用 Milvus 向量数据库实现自定义检索功能。
01.OpenAI Assistants 检索存在局限性?试试自定义检索
OpenAI Assistants 内置的检索工具突破了模型固有知识库的限制,支持用户通过额外数据(如内部产品信息或用户提供的文档)来增强大模型。但是,OpenAI Assistants 检索仍然具有局限性。
限制 1: 可扩展性
OpenAI Assistants 内置检索对文件大小和数量都有限制。这些限制不利于大型文档仓库:
-
每个 Assistant 最多支持 20 个文件
-
每个文件最大为 512 MB
-
我们在测试中发现了关于 Token 的隐藏限制——每个文件最多 200 万个 Token
-
每个企业账号下文件大小总和最多 100 GB
上述限制会严重限制拥有大量数据的组织机构。在此情况下,就需要使用一套可以摆脱存储上限、支持灵活扩展的解决方案——集成 Milvus(https://zilliz.com/what-is-milvus)或 Zilliz Cloud(https://cloud.zilliz.com.cn/signup)这样的向量数据库检索更大体量的知识库。
限制 2: 无法定制检索
虽然 OpenAI Assistants 的内置检索是一套开箱即用的解决方案,但它无法根据每个应用的特殊需求(如:搜索延时、索引算法)进行定制。使用第三方向量数据库,可以帮助开发者灵活配置、调优检索过程,从而满足生产环境中的各种需求,提升应用的整体效率。
限制3 :缺乏多租户支持
OpenAI Assistants 中内置的检索功能绑定 Assistant,每个知识库产生的费用按 Assistant 个数成倍增长。如果开发者的应用需要为数百万用户提供共享文档,或者为特定用户提供私人化的信息,OpenAI Assistants 的内置检索功能就无法满足需求了。
下表显示了在 OpenAI Assistants 中存储文档的成本:

根据上表的定价计算,其代价十分高昂——每月每 GB 的存储需要花费 6 美元。(参考 AWS S3 的收费仅为 0.023 美元。)具体 Assistants API 定价可在此 (https://openai.com/pricing)获取。如果将共享文档复制到每个 Assistant 中,会显著增加存储成本,所以在 OpenAI 上存储重复的文档是一种不现实的方案。但是,如果让所有用户都共享同一个 Assistant,那么将无法支持用户检索自己的私有文档。
因此,对于需要检索大量数据集的应用来说,选择一个可扩展、高效、具有高性价比的检索器显得尤为重要。
值得庆幸的是,OpenAI 灵活的函数调用功能支持开发者在 OpenAI Assistants 中无缝集成自定义的检索器 。这套解决方案一方面保留了 OpenAI 出色的 AI 能力,另一方面又可以满足应用可扩展性的需求。
02.使用 Milvus 实现 OpenAI Assistants 检索定制化
Milvus 是一款高度灵活、可扩展的开源向量数据库,毫秒内即可实现十亿级别向量的存储和检索。由于优秀的扩展性和超低的查询延时,Milvus 是定制 OpenAI Assistants 检索的首选。
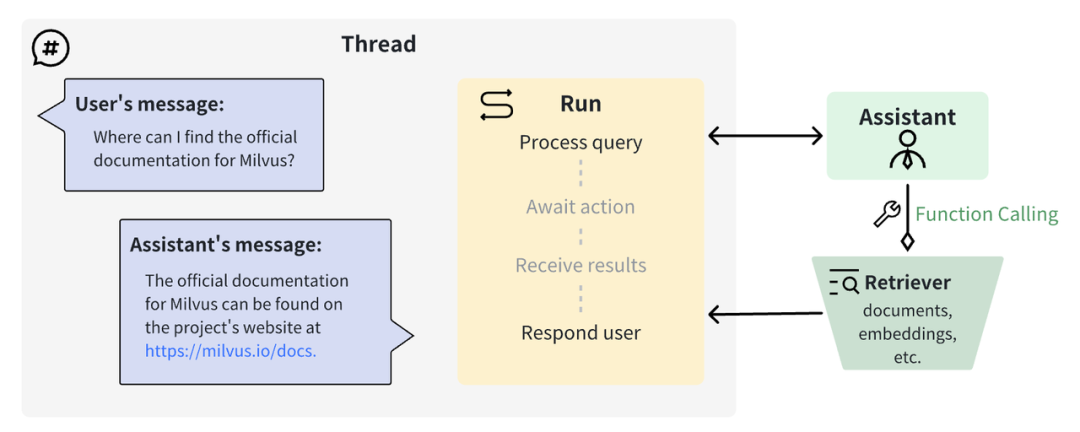 |OpenAI Assistant 函数调用的工作原理
|OpenAI Assistant 函数调用的工作原理
用 OpenAI 函数调用和 Milvus 向量数据库搭建自定义检索器
在接下来的教程中,我们将展示构建自定义检索器、并将其集成到 OpenAI Assistants 的具体步骤。
- 配置环境。
pip install openai==1.2.0
pip install langchain==0.0.333
pip install pymilvus
export OPENAI_API_KEY=xxxx # Enter your OpenAI API key here
- 使用向量数据库构建自定义检索器。我们选择 Milvus 作为向量数据库、 LangChain 作为调用框架。
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
# Prepare retriever
vector_db = Milvus(
embedding_function=OpenAIEmbeddings(),
connection_args = {'host': 'localhost', 'port': '19530'}
)
retriever = vector_db.as_retriever(search_kwargs={'k': 5}) # change top_k here
- 将文档导入 Milvus。LangChain 会解析文档、将其切分成片段,并转换为向量。随后这些文档片段和相应的向量会被导入 Milvus 向量数据库。当然,我们也可以自定义每个步骤,进一步提高检索质量。
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Parsing and chunking the document.
filepath = 'path/to/your/file'
doc_data = TextLoader(filepath).load_and_split(
RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
)
# Embedding and insert chunks into the vector database.
vector_db.add_texts([doc.page_content for doc in doc_data])
至此,一个自定义的检索器已经搭建完成,可以支持私有数据下的语义搜索。接下来,我们需要将这个检索器集成到 OpenAI Assistants,从而实现内容生成。
- 使用 OpenAI 的函数调用功能创建一个 Assistant,并提示 Assistant 在回应请求时使用名为 CustomRetriever的函数工具。
import os
from openai import OpenAI
# Setup OpenAI client.
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# Create an Assistant.
my_assistant = client.beta.assistants.create(
name='Chat with a custom retriever',
instructions='You will search for relevant information via retriever and answer questions based on retrieved information.',
tools=[
{
'type': 'function',
'function': {
'name': 'CustomRetriever',
'description': 'Retrieve relevant information from provided documents.',
'parameters': {
'type': 'object',
'properties': {'query': {'type': 'string', 'description': 'The user query'}},
'required': ['query']
},
}
}
],
model='gpt-4-1106-preview', # Switch OpenAI model here
)
- Assistant 采用异步方式调用函数工具。首先开启线程并调用 Assistant,其状态存储在名为Run 的对象中。在运行过程中,如果 Assistant 认为有必要调用CustomRetriever函数,会暂停运行等待异步提交函数调用结果。通过轮询来获取Assistant 发出调用的命令。
QUERY = 'ENTER YOUR QUESTION HERE'
# Create a thread.
my_thread = client.beta.threads.create(
messages=[
{
'role': 'user',
'content': QUERY,
}
]
)
# Invoke a run of my_assistant on my_thread.
my_run = client.beta.threads.runs.create(
thread_id=my_thread.id,
assistant_id=my_assistant.id
)
# Wait until my_thread halts.
while True:
my_run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=my_run.id)
if my_run.status != 'queued':
break
- 当查询到 Assistant 正在等待函数调用结果,即可对查询语句进行向量搜索并通过 Run 提交结果至 Assistant,让其继续进行内容生成。
# Conduct vector search and parse results when OpenAI Run ready for the next action
if my_run.status == 'requires_action':
tool_outputs = []
for tool_call in my_run.required_action.submit_tool_outputs.tool_calls:
if tool_call.function.name == 'Custom Retriever':
search_res = retriever.get_relevant_documents(QUERY)
tool_outputs.append({
'tool_call_id': tool_call.id,
'output': ('nn').join([res.page_content for res in search_res])
})
# Send retrieval results to your Run service
client.beta.threads.runs.submit_tool_outputs(
thread_id=my_thread.id,
run_id=my_run.id,
tool_outputs=tool_outputs
)
- 最终,提取并解析与 OpenAI Assistant 的完整对话。
messages = client.beta.threads.messages.list(thread_id=my_thread.id)
for m in messages:
print(f'{m.role}: {m.content[0].text.value}n')
至此,我们已成功实现用自定义的检索功能来增强 OpenAI Assistant 的回答能力。

03.总结
看到这里,相信大家对于【是否需要向量数据库】已经有了答案:虽然 OpenAI Assistants 的内置检索工具令人眼前一亮,但它仍旧存在诸多存储限制,如:可扩展性较差,无法满足多样的、定制化的用户需求等。可以这样理解,OpenAI Assistants 适用于个人用户,但无法满足数据量更大、业务更复杂的应用需求。
如果想要克服 OpenAI Assistants 的种种限制和不利因素,开发者可以考虑使用例如 Milvus 或 Zilliz Cloud 等向量数据库搭建自定义检索功能,从而实现更灵活的问答应用。
做一波预告!在后续的文章中,我们将继续测评 OpenAI Assistants 内置检索和基于外部向量数据库的方案,从性能、成本和功能等维度进行详细比较。届时亦会发布一系列的性能测试结果,敬请关注!
