


DDD实战之二:看看代码结构长啥样
真正开始 DDD 旅程前,我想让您看到经过 DDD 设计之后的代码长啥样。我想,这是所有本着“talking is easy, show me your code”理念的程序员都比较在乎的观念。
为此,我特别将“群买菜”生鲜电商系统服务端代码新旧代码结构都显示出来,让您看看原来的旧代码——也就是“事务脚本式”代码长啥样(应该是目前大部分 java 程序员写代码的样子),再让您看看 DDD 改造设计后的新代码长什么样子。然后再通过分析,说清楚为什么传统的“事务脚本”代码不是对真实世界的“同构映射”,而 DDD 代码的“同构映射”在哪。
需要提醒您的是:从今天这个专题开始,可能需要你多花点时间、深入地阅读我写的代码、和文字的每一句话,反复对照着看,甚至来回反复多看几遍,才能真的去理解这些文字了。
我们先来看旧代码的目录结构截图。注意看下面的 1、2、3、4 标注位置(解释下,我这里用的是 spring-boot 开发框架,MyBatisPlus 数据持久框架、MySql5.6 数据库):
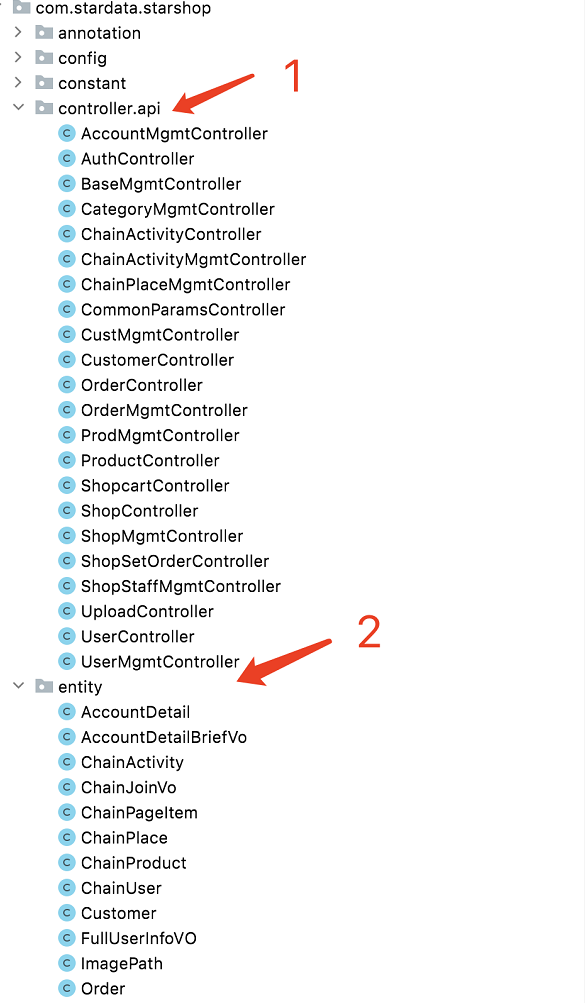


您注意到这里标注的 1、2、3、4 代码位置了吗?是不是代码结构很像大部分 spring-boot 应用框架下代码结构?为了避免您可能不太了解这种代码结构,我还是简单解释下。
标号 1 位置:这里放的是 Controller(控制器)层代码,也就是所有前端访问的接口都在这里实现。按照 MVC 的分层原则,一般来说,这里只会放一些客户端输入参数的解析、以及对 service 层(见下文)的业务方法调用。一般来说,这里的代码都长成下面这样:

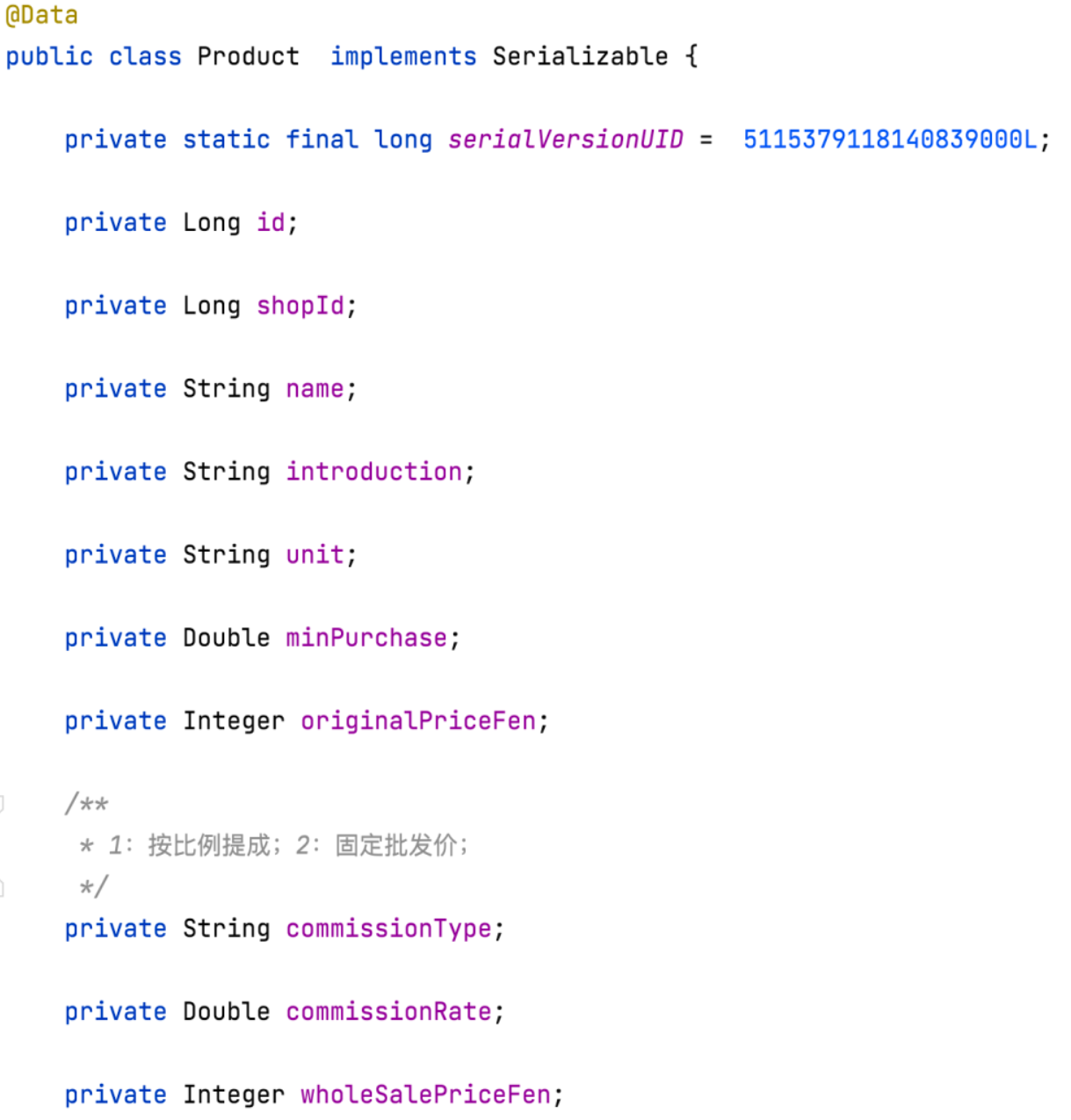
标号 2 位置:这里放的是 entity(数据 bean)层代码,其实都是 POJO 代码,所有类都一一对应到数据库表。一般来说,这里的代码都长成这样:
标号 3 位置:mapper 层,对于 mybatis 持久层框架来说,mapper 和 entity 共同实现了 ORM(对象模型到关系模型的映射)。一般来说,这里的代码长成这样(这里 CustomerMapper 类只是定义了 entity 类 Customer 的映射关系,以及自定义的数据操作方法):

以及这样(在 MP 中,只有需要实现自定义的 SQL 操作方法,才需要这个 CustomerMapper.xml 文件):

标号 4 位置:Service(服务)层,这里是所有业务逻辑实现的核心代码处,几乎所有的业务逻辑都是在这里实现的。一般来说,这里会有 interface+implementation 组合的实现方式。比如:OrderService 和 OrderServiceImpl,分别长下面这样:
OrderService 接口类

OrderServiceImpl 实现类



从上面的代码中 ,我们可以很明显地看出如下几点:
-
Controller/entity/mapper 基本上都是利用框架的 annonation(注解)和公共工具类代码(如 json 解析等)实现的很少的代码;
-
显然,大部分业务逻辑都是在 Service 层的实现类里面实现的;
-
Service 层实现类代码的逻辑写的很长,且完全是“平铺直述”的。我这里展示的 OrderSeriveImple 的 create 方法——创建订单,就写了 135 行。从我的代码截图中的注释可以看出来,我是想好了一步一步要怎么对数据库进行 CRUD,先填写好注释,然后写代码的。这种代码,说白了就是“CRUD+计算逻辑”组合的代码;
-
事实上,这种“平铺直述”式的代码,是很容易被程序理解的,写起来也很容易,基本上不用“杀死”太多脑细胞,所以团队很容易就开始实施项目工程,随便找一个具有基本 java 编程经验(一般一年以上经验即可)就能够开始着手业务代码的开发;
-
这种代码,我们就叫做”事务脚本式”代码,或者说叫“贫血模型”代码。
-
之所以叫“事务脚本”,我个人的理解:本质上跟 20 年前写数据库存储过程代码没有本质区别(只是换了个语言书写、运行代码的位置从数据库服务器内部提到了应用服务器);
-
又之所以叫“贫血模型”代码,是因为 entity 层的那些 POJO 对象如 Order 等,没有任何业务行为的封装(比如:Order 类应该自己生成自己的订单号、提货号等),只有属性而没有行为的对象,就是“贫血”对象,基于“贫血”对象实现的业务逻辑代码,就叫“贫血模型”代码。
根据这里的代码分析,我们是不是能够发现一个关键问题:这里的 Controller/entity/mapper/service,事实上和真实世界的业务之间关系,是没有任何映射的——也就是说:“代码世界”和“真实世界”是异构的。具体来说,我们可以分以下几点来看。
首先,从业务模块划分这个“最粗”的粒度来说,我们其实是可以简单的、凭直觉进行模块划分的,不用全部业务模块放在一个工程项目中,是可以按照业务模块(比如:店铺管理、订单管理、商品管理等)进行项目目录划分、也就是项目团队分组的。
事实上,目前市面上的大多数软件公司,就是根据业务经验或直觉简单粗暴的将项目划分了多个团队在进行开发。但这种划分方式,虽然也可以七七八八准确——但我们需要意识到的是,这样简单粗暴的凭经验直觉的划分,跟 DDD 方法论做的设计划分相比(划分到限界上下文这个粒度的设计,在 DDD 中叫做“战略设计”),至少有 3 个不足:
- 软件代码如何划分是严格的“工程性问题”,而所有工程性问题,往往会“差之毫厘谬以千里”!这种经验直觉的划分,很可能会遗漏掉一些很重要的“限界上下文”识别。而正因为这些重要的“限界上下文”的遗漏,导致了一些模糊地带,发现要么是没必要的模块间耦合、要么是没必要的重复。
- DDD“限界上下文”的识别,不但要区分出到底要划分为几个模块(其实“模块”是个很模糊的词,可以用来划分微服务、也可以用来划分代码目录结构,视需要而定),还需要识别这些“限界上下文”之间的协作关系和边界。而这些协作关系,才真正“清晰准确、代码行级”定义了哪些代码归属模块 A、哪些代码归属模块 B——也就是边界,以及这些模块是通过 RPC 或本地调用关系在协作、还是异步消息事件在协作、甚至直接就没有协作。
- 一般来说,DDD 的“限界上下文”需要对应到业务子领域,而业务子领域的重要程度将决定限界上下文的重要程度。业务子领域针对某个具体的软件系统来说,是可以从业务角度判断出哪些必须建设为软件的核心竞争力、哪些则可以作为次要模块甚至通过外包来实现。这些对“限界上下文”模块的不同“重要程度”定义,将会促使项目管理层从效率的角度采用不同的技术栈。比如:目前市面上不同的程序员薪资水平是不同的、招聘难度是不同的;不同技术栈的成熟程度、可适用的编程特性是不同的(比如:java 比较成熟适合企业级应用开发,而 python 适合数据处理类开发,node.js 适合跟第三方互联网系统连接等)。
其次,到模块内部,其代码的层次结构划分,如果按照 mvc 思想,最后还是又回到了类似 controller/entity/mapper/service 这样的划分方式。而这种划分方式,又和“真实世界”有什么同构映射关系呢?可以说,没有!
所以,最终我们还是可以得出结论:这种传统的代码架构,是没有考虑和真实世界的“同构映射”的。而这种对“同构映射”的缺失,才是导致我们出现“真实业务其实没多大变化、但某个需求却为什么引起软件代码翻天覆地的变化呢?”这样疑惑的根本原因——DDD 方法论,就是用来解决这个问题的!
我们再来看看使用 DDD 设计后,新的代码结构长什么样。下面是新代码的结构截图(同样注意下面的 1~8 标号):
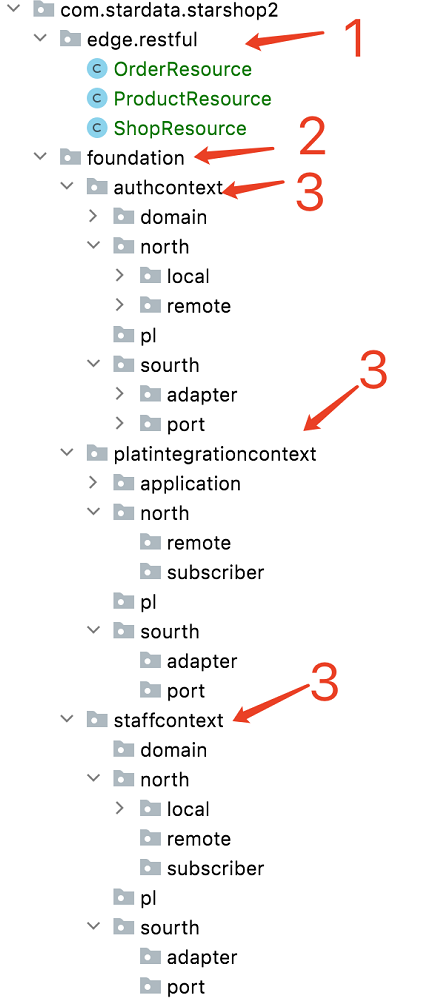
对上面的代码标号位置,我来逐个解释如下(需要说明的是:这里目录排序是 IDEA 开发工具自动按字母顺序排序,不是代码设计先后顺序):
标号 1 位置:这里放的是边缘层(edge)代码。由于“群买菜”小程序前端界面已经开发完成,并且这是一个前后端分离项目,前端代码我并没有打算修改,所以这里就多了个“界面适配”的代码工作。一般来说,这种代码就叫“边缘层”。边缘层放的代码,都是类似这种为了前端界面适配、第三方系统接口适配之类的代码。这种代码,也可以叫做“为前端提供的后端”(Backend for Frontend, BFF)。理论上,这种 BFF 层的代码,可以由前端团队开发的,我可以选择技术栈是 Node.js,使用 js 或 ts 语言进行开发。
标号 2 位置:这里显示的是“基础层”(foudation)。在 DDD 的系统架构中,限界上下文(具体概念介绍见后面,这里你只需要理解为它类似于子系统或业务模块划分就好)是可以根据“业务子域”不是核心层,而分为“基础层”和“业务价值层”。一般来说,“业务价值层”对应到最核心的业务模块,是一个软件系统的核心竞争力所在,是需要严格按照 DDD 的理念进行战术设计、并采用测试驱动开发模式、投入最懂业务的程序员去工作的;而“基础层”一般都是非核心业务模块,比如:业务相关基础类、工具类、伴生系统的对接等——需要注意的是:“基础层”不是“基础资源层”,基础层指的是业务模块处于非核心地位、而基础资源指的是数据库、中间件这些技术组件。
标号 3 位置:这里显示了多个限界上下文,都是以 xxxcontext 这样的目录取名。在“基础层”和“业务价值层”中,都会出现多个“限界上下文”。每个限界上下文可以分离到不同的项目团队去负责、甚至分离到不同的微服务中心中。还是那句话,现在你还不用太深入的理解“限界上下文”,暂时只需要理解它是一种模块划分的说法就好(后面会逐步深入解释)。
标号 4 位置:这里显示出来了“业务价值层”的代码——也就是该软件系统中需要作为最核心竞争力的那些模块,同样下面也会有多个“限界上下文”。
标号 5 位置:DDD 战术设计软件分层的“菱形架构”下,“领域”(domain)层的代码放这里,也是业务逻辑最核心的代码——所有的“充血”模型代码。从这里开始,我们解释某个“限界上下文”内的代码结构。具体这些代码怎么设计的细节,我们后面会讲,现在你只需要知道这里放的是“业务逻辑核心”即可。
标号 6、8 位置:在 DDD 战术设计软件分层的“菱形架构”下,为了让“限界上下文”在满足外部的各种调用需求、以及需要调用或与别的“限界上下文”通讯时,不至于因为与本模块业务逻辑无关的、各种外在因素变化而引起本模块内代码逻辑的“动荡不安”,而引入了“北向网关”、“南向网关”概念。分别说明如下:
标号 6 就里面就是“北向网关”的代码,里面又分为 local 和 remote 两个典型的目录。“北向网关”的作用,就是让限界上下文可以向外输出各类应用服务。local 目录下方的是本限界上下文向外提供的“应用服务”,是将 domain 内各种“充血模型”代码进行封装后的、完整的业务逻辑;而 remote 目录下,放的是对 local 目录为了满足“远程调用”而进行的代码封装——如 RPC 调用、跨服务器消息事件订阅等,并不存在任何业务逻辑。
标号 8 里面就是“南向网关”的代码,里面又分为“端口(port)”和“适配器(adaper)”两个典型的目录。“南向网关”的作用,就是是让本限界上下文通过其请求外部资源。典型的 3 类外部资源请求有:访问数据持久层(关系或非关系数据库)、调用别的限界上下文服务(在微服务架构中,往往是 RPC 远程调用)、向别的限界上下文发布消息。我们都知道,这些对外部资源的请求,可能会因为外部资源的技术底层不同,而存在不同的实现方式。为了能够隔离“领域层”对具体技术底层的依赖,就分离出来 port 层和 adapter 层。在 java 语言实现中,port 层就是 interface,没有任何实现代码,只有方法定义;而 adaper 层就是 implemetaion,具体实现到不同持久层(如不同关系数据库 oracle/mysql 等、不同 nosql 数据库 redis/mongodb 等)。然后,根据 IoC(依赖倒置)原则在 java 中通过“依赖注入”来将 adaper 目录下的具体实现与 domain 层的代码连接起来。
标号 7 位置:这里是“发布语言”(published language, pl)层。说白了,“发布语言”就是让“北向网关”向外输出服务时,能与服务调用者之间有个“统一语言”,比如:输入输出参数的结构性定义、事件消息的格式定义等等。因为,我们是不用将限界上下文内部的“领域”层的内部对象结构“泄露”到外部的,所以我们必须要有这个“发布语言”层。
好了,解释完了按照 DDD 进行的代码结构设计,我们还是要回答一个问题:DDD 对真实世界进行“同构映射”后的代码逻辑到底在哪里呢?
答案是:在“领域”(Domain)层里面!所谓的“北向网关”、“发布语言”、“南向网关”层的作用,都只是为了让外部的请求、被请求资源的底层技术,不要去“打扰”我们“业务逻辑”的“同构化”映射!
这就相当于是说:领域层才是 DDD 对“业务逻辑”映射后的核心,其它都只是对这些“核心业务逻辑”的层次“包装”而已!
那么,显然,从技术角度来说,懂得领域层如何设计才是 DDD 战术设计层面最重要的技能!因为,“北向网关”、“发布语言”、“南向网关”这 3 层的代码开发,都是常规套路,没啥“业务知识”含量,甚至可以用机器人来实现(也就是通过代码自动生产工具)。
最后,解释下反复提到的 DDD 战略设计和战术设计的区别:
大体上来说,DDD 战略设计,就是识别出有哪些限界上下文、以及清晰的定义限界上下文的关系和边界,就基本完成了(虽然还有些修修补补的工作,比如要不要边缘层、本软件系统跟哪些第三方外部系统接口等,但这些其实已经不能叫“设计”了,因为不需要花多少脑子了);
DDD 战术设计,核心就是完成“领域”层内的“聚合”、“领域服务”的设计,也就是“核心业务逻辑”的设计。具体怎么玩,我后面会一点点演示。
本文由博客一文多发平台 OpenWrite 发布!
