


作者 | Xin
导读
百度搜索架构部模型架构组,致力于将最新的人工智能技术以更低的成本被百度数亿用户体验到。这个过程中会面临非常多的系统、工程层面的问题,甚至在深度学习模型领域,我们看到越来越多的工作并不拘泥于工程本身。
本文主要分享模型架构组的日常工作,希望感兴趣的同学,可以把简历投给我们。欢迎社招、实习同学投递简历,备注【投递搜索架构组】,邮箱:sti01@baidu.com。
全文5361字,预计阅读时间14分钟。
01 搜索深度学习模型业务及架构演进
如下图所示,我们问一个河流的长度,搜索结果精确返回了河流的长度,而不是返回有答案信息的网页链接让用户依次查找。能做到这样,是深度学习起着至关重要的作用,模型从语料中寻找、判断、截取准确答案,然后呈现给用户。此外,用户还能输入图片并询问图片的内容是什么。
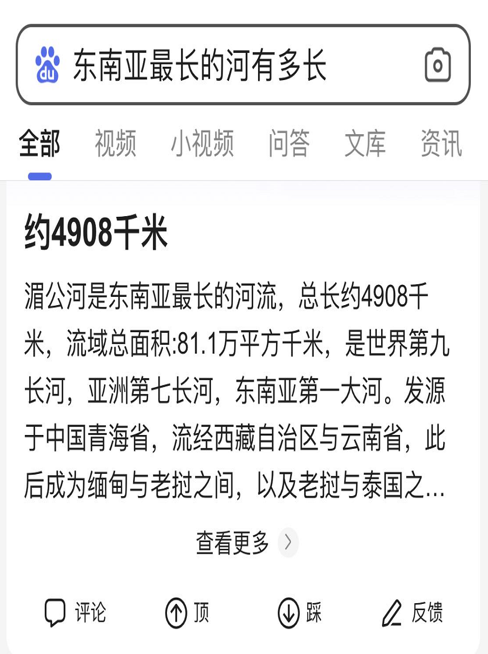

1.1 搜索语义检索通路
纵观搜索的发展的历程,从最初的人工特征,到浅层的机器学习模型,再到不断加深的深度学习模型,我们对用户需求和候选内容的理解能力是持续的提升的,能力提升到一定程度就会影响架构的变化。近几年,架构最大的变化之一,是大规模的深层知识学习模型和系统的落地。

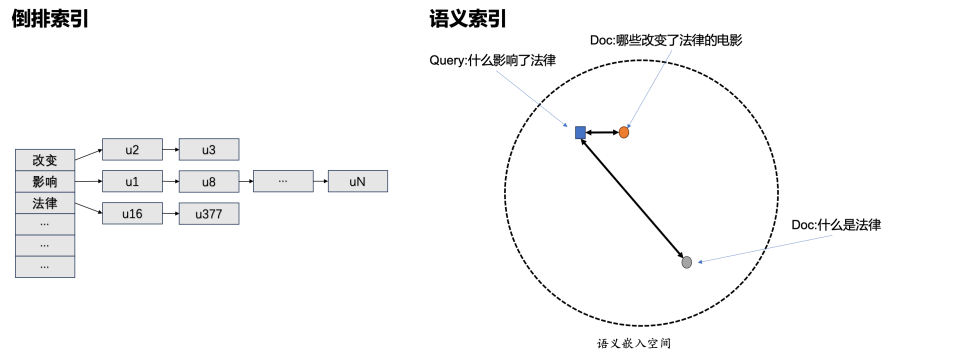
传统的检索的通路的思路,是倒排索引。我们通常理解的索引,是先有文本,再去统计文本中关键词的出现频次,这是正排。那倒排是什么?是用户搜了一个词,我们去看它出现在哪些文本中。但是在中文语境中,一个句子通常会因为改变一两个字或词,整个句子的语义会发生剧烈的变化,比如”山桃红了” vs “山桃花红了”,前者描述的是山桃果实的颜色,后者指的是山桃花的颜色。
倒排检索很难捕捉到这种变化,语义索引就很擅长解决这类问题。
那么,语义索引是什么? 我们将用户的query做嵌入表示,映射到一个向量(128/256维)中,然后对全网内容进行检索、embedding映射至向量空间。我们可以把这个向量空间看作语义空间,在向量空间中越接近,语义就越近似,也就能反馈用户更加满意的结果。
1.2 搜索深度学习模型
很多时候,搜索和推荐有一定的共性,但也有诸多不同,这里我对比着讲。
搜索的语义理解模型中,transform 类的结构被广泛应用,文本作为特征,词表范围一般
而推荐模型,涉及大量用户及物料特征、交互特征,词表大小大到TB级,具有宽而较浅的特点。
搜索模型特点:
1、原始文本/图像->embedding
2、Query-Url/title/content
3、深度模型
4、离线预训练 在线多阶段预估
5、计算密集->异构硬件
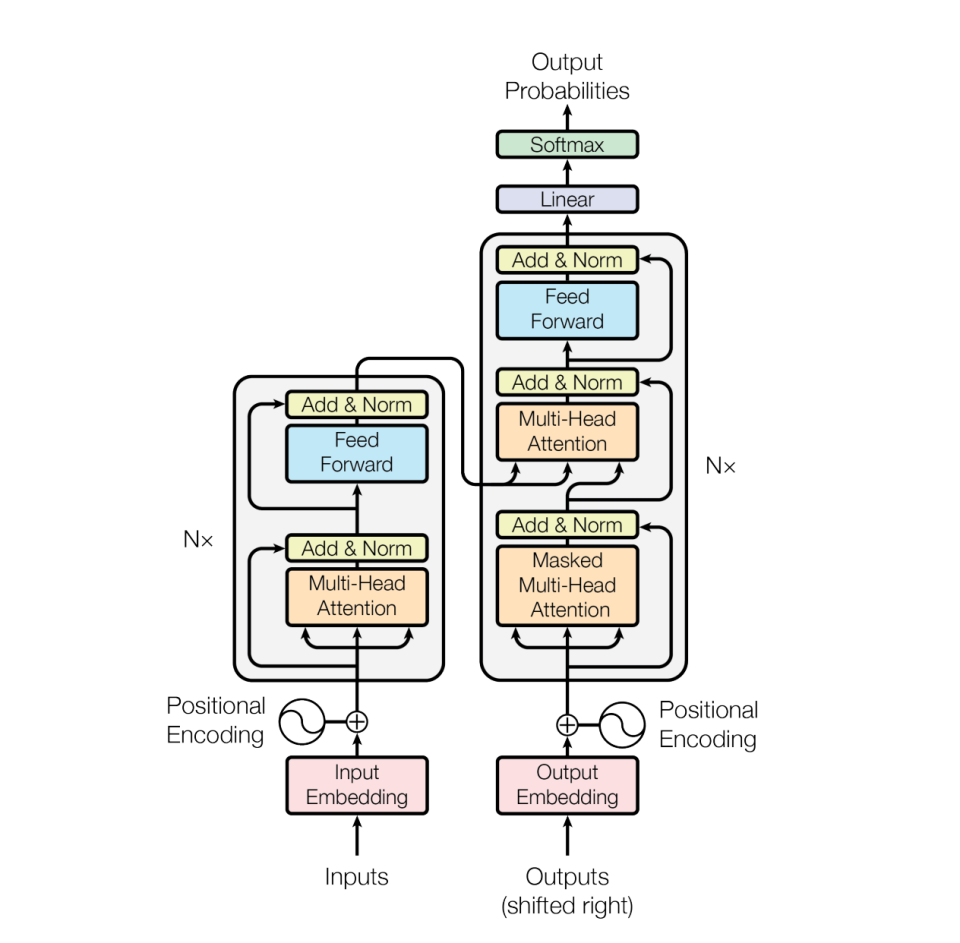
△图片来源:Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
CTR/推荐模型特点:
1、高维离散特征->embedding
2、特征工程 样本拼接 特征抽取
3、浅层DNN
4、时效性->online-learning
5、吞吐密集->CPU+PS
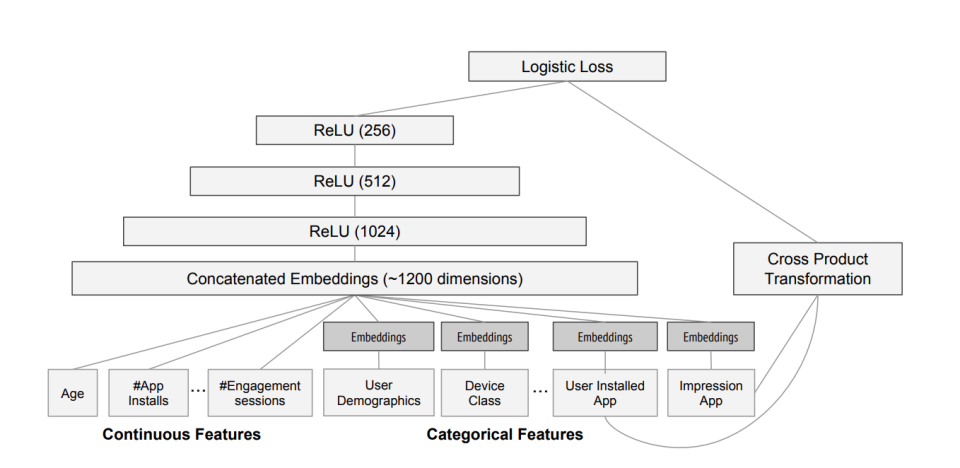
△ctr经典模型 Wide&Deep示意图 (图片来源:Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C])
1.3 搜索深度学习模型在语义检索通路中的应用
语义检索通路主要包括离线通路(下图左侧)和在线通路(下图右侧)。我们可以看到无论是离线还是在线,都用到了深度学习模型ERNIE。
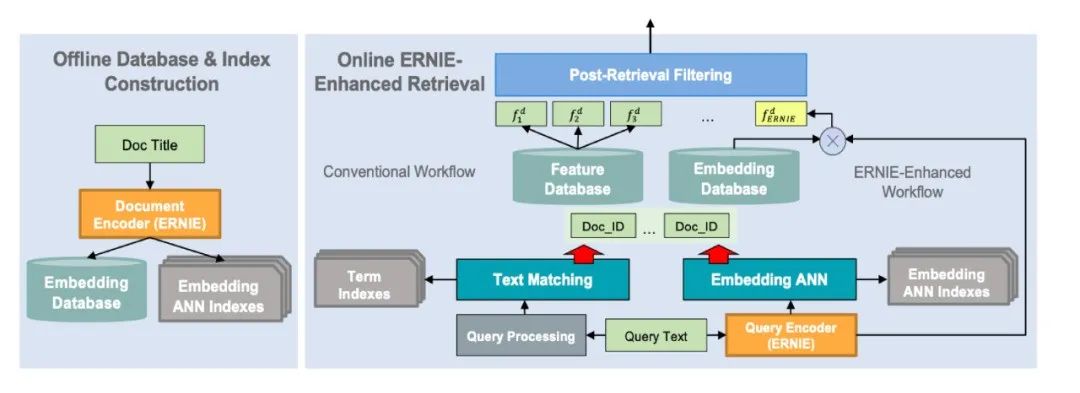
△图片来源:Liu Y, Lu W, Cheng S, et al. Pre-trained language model for web-scale retrieval in baidu search[C]
离线侧,全网文本数量非常多,都需要检索到我们的库中做embedding,这个工作需要离线通路提前算好,存在数据库中。
在线侧,当用户输入query text后,同时进入传统检索通路(Query processing)和语义检索通路(Query Encoder)。语义检索通路中,用户query通过深度学习模型(图中是ERNIE模型)计算出一个向量,再与库中向量对比检索,快速找出与query向量尽可能接近的文本。这是第一步,后续还有非常多的复杂工作。
02 搜索超大规模在线推理系统
2.1 在线系统与近线/离线系统
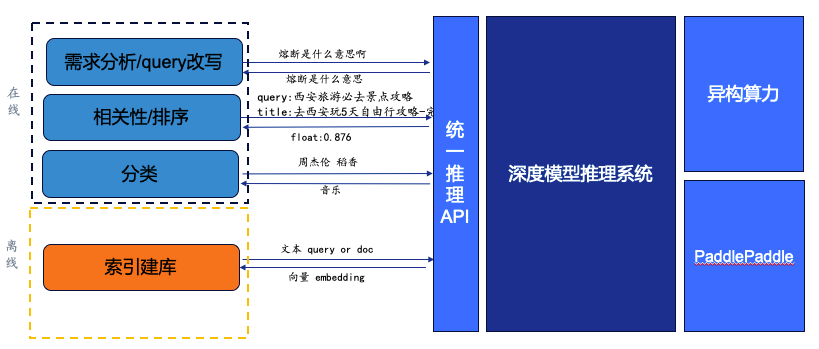
搜索在线推理系统,是根据用户query进行实时计算并返回结果,模型主要分为三部分:需求分析/query改写、相关性/排序、分类。
(1)需求分析/query改写,是通过深度学习模型返回一个语义相近的query
当用户问:“熔断是什么意思啊?” 其中含有口语化表达,通过调用深度模型返回一个语义相近的query:“熔断是什么意思”,使召回的答案更丰富、准确。
(2)相关性/排序,需要用到粗排/精排模型,将用户query与title相关的网页信息做拼接,让模型计算相关性,得出的分数决定了返回用户结果时的排名。
当用户问:“西安旅游必去景点攻略”,模型给出的分数越高,就代表网页和用户需求越接近,返回“float:0.876”。
(3)分类,即通过模型进行类型识别,返回类型。
当用户问:“周杰伦 稻香” ,模型识别出这是一个音乐需求,我们就可以为用户展现音乐类型的卡片。
搜索离线系统,用于处理时效性不高的任务。搜索的用户使用会呈现明显的波峰波谷形态,尤其是后半夜用户流量非常低,冗余的资源就可以进行离线计算,将计算结果存入语料库。比如文章最开始提到的珠峰海拔的问题,深度模型可以直接从语料库中抽取答案。还有一些是纯粹的离线任务,我们采用批量建库、批量刷库的形式拿到索引,并存储到数据库中。
2.2 深度模型推理系统
搜索系统中非常多的任务都会用到深度模型,我们希望各用户、各业务方都能用同一套API来调用深度模型,这部分就是我们做的工作了。
在深度推理系统之后,它的后端由于大家模型种类、大小、尺寸都不一样,包括异构算力,都需要我们把深度模型推理服务部署上去。
那么,如果并发量变大,我们如何做到均匀调度、让系统稳定可靠呢?
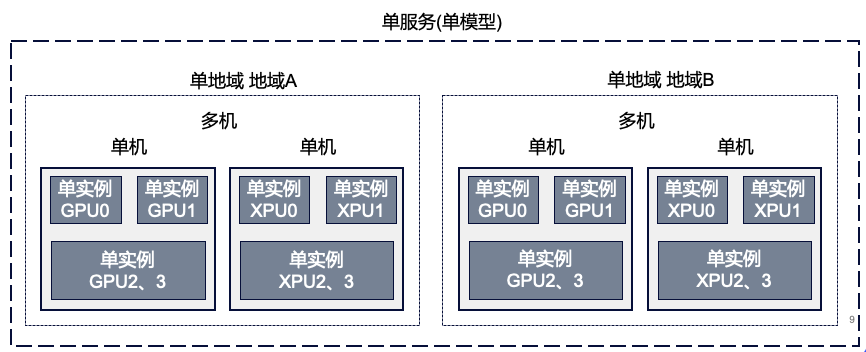
首先是均匀调度。 下图为公司内部模型部署的一种典型方案,我们每个人拿到的计算机叫做单机,但是单机粒度较大需要进行虚拟化,切分出更小的粒度来提供服务、做扩缩容等,我们称作实例。
在对外提供服务时,单机多实例无法支撑巨大的并发量,所以需要扩展多机多实例,在百度搜索这种海量用户的场景,会在多地多个机房部署这样的服务。均匀调度的意思,是当大量并发请求产生时,需要让各地实例最小粒度能够均匀利用,不能发生一些机器拥堵、一些机器没利用起来的情况。
再者是稳定可靠。 架构领域有一个非常有名说法,说“架构工作就是在不稳定的硬件之上构建一套稳定的系统”。当我们的实例和机器数量变得多时,某个硬件出故障其实就成为必然现象了,如何及时检测故障并迁移,保证用户体验,就是我们需要保障的事情。
此外,我们还希望整个推理系统的速度足够快,有足够高的吞吐,尽可能降低资源成本。 如下图所示,推理系统的请求由brpc输入,brpc是在公司内部各模块间通过网络调用的,可以让用户用类似本地函数的调用方式调用其他服务。系统收到请求后会识别inferfence request里的信息,包括要访问什么模型、访问什么版本、输入了什么等,之后进入处理流水线。
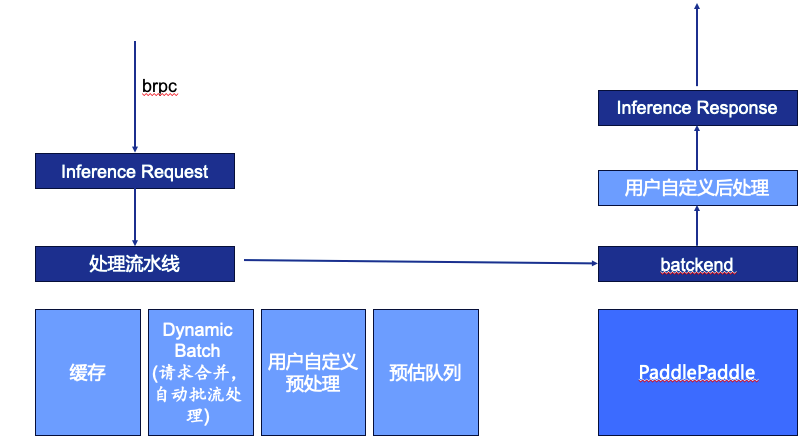
处理流水线包含四个部分:
(1)缓存,如果一段时间内有相同请求计算过了,会直接通过缓存返回给用户,而不调用GPU
(2)Dynamic Batch,很多线上模块是以Batch=1触发模型计算,但batch=1对硬件利用不充分,部分计算单元也会因为batch较小变为带宽瓶颈。为了充分利用硬件会在时延允许的条件下尽可能把batch开大,所以我们会以一定的时间窗口或其他规则将请求合并以batch的形式做推理,之后再拆开返回用户。
(3)用户自定义的预处理,对应于自然语言处理模型,相遇将明文转化为ID。为什么要用户自定义的预处理?这跟搜索对接的业务方向多有关,各业务方有不同的数据预处理方式,所以交给用户自定义更合适。
(4)预估队列,经过预处理的请求会进入一个队列中,这个队列会按顺序进入后端的预估引擎,经过预估引擎计算后进入用户的自定义的后处理,后处理可以将输出结果进行优化,再返回上游。
以上是超大规模在线推理系统的概况。
03 深度模型优化实践
3.1 模型优化瓶颈
我们的深度模型优化,其实是针对某些瓶颈去做优化。GPU模型通常面临着三类瓶颈:IO瓶颈、CPU瓶颈、GPU瓶颈。如下图所示,训练的整个过程包括:读取数据、前向推理、反向传播,我们推理过程可以拆分成读取数据、前向推理两部分。
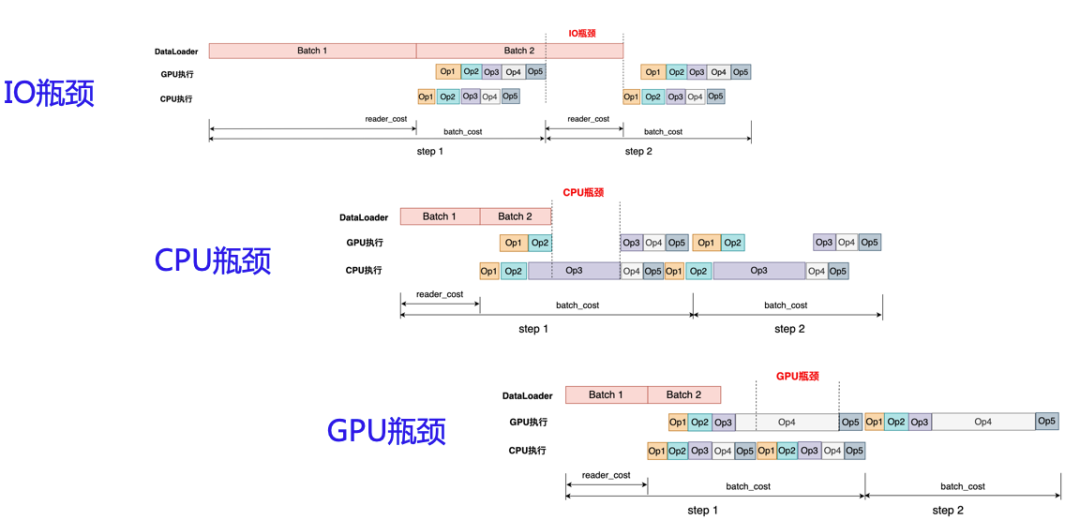
(1)IO瓶颈,是指batch1和batch2数据处理的间隔期,需要加速数据的读取速度;
(2)CPU瓶颈,是由于CPU给GPU分配的工作量少导致GPU利用率不够的情况。场景是多OP的深度模型在GPU回拆解成多OP序列进行计算,在此之前需要CPU先做处理,GPU运算结束但CPU还没把下一个任务发射过来;
(3)GPU瓶颈,如果出现了GPU瓶颈,说明GPU的利用率已经比较充分了,这是比较好的状态。
3.2 模型优化工作
模型优化工作分为三个方面:训练、推理和小型化。
3.2.1 训练优化
(1)数据读取
我们针对场景做数据读取的优化。原因是在模型不断增大后,我们不断的尝试将模型切分,在单机多卡上训练,甚至在多机上训练,不同的切分方式也会导致很多时候数据处理并没有对场景做深度适配。

(2)框架调度
我们在训练模型的过程中,一般是训练一些step后做一次评估。在实际工作中,我们发现很多框架的训练是在多卡上,但评估确在单卡上,这就出现了可优化的空间。
(3)kernel融合/开发
这是在训练和推理场景都会遇到的工作, kernel融合可以减少 CPU的发射开销,此外 GPU单kernel任务也会相对增大,不容易出现CPU瓶颈。
在识别到不够高效的kernel后,我们会进行kernel融合的开发。
(4)模型实现-等价替换
无论用paddle框架或是其他,都会提供很多OP,这是想实现一个功能,就可以用不同的op来达到同样的功能,这为用户带来非常高的自由度。但是不同的op在实际的执行过程中有低效和高效之分的,所以我们一部分工作就是去识别并替换成更高效的实现。
3.2.2 推理优化
除了kernel融合/开发、等价替换等,推理优化还包括GPU/CPU负载均衡、模型结构剪裁。
(1)GPU/CPU负载均衡
在推理场景,CPU的工作量并不太多,包括预处理、kernel lunch和后处理,我们可以把一些 GPU并不擅长的工作放在CPU执行,包括对访存比较高但运算量较少的op,放在CPU进行更合理。
(2)模型结构剪裁
对于业务模型,可能会在存在训练时需要但推理时不需要的运算部分,可以在模型导出过程中将不需要的部分去掉。
3.2.3 模型小型化
小型化分为三个方向:蒸馏、量化、剪枝
(1)服务化蒸馏
蒸馏是一种模型压缩技术,将一个复杂的、大型的模型 (teacher) 的知识转移到另一个更小、更简单的模型(student)中。小模型可以与大模型保持相似的训练结果。
在实际业务场景中,随着teacher数量不断增长,蒸馏过程无法并行,teacher模型前向推理是串行的且耗时占比会越来越高,成为主要瓶颈。所以从工程师的视角,我们将 teacher放在异构的算力上去推理,一方面将串行的teacher前向推理并行化,另一方面可以将闲置的资源利用起来,如下图所示,整体加速蒸馏效率。
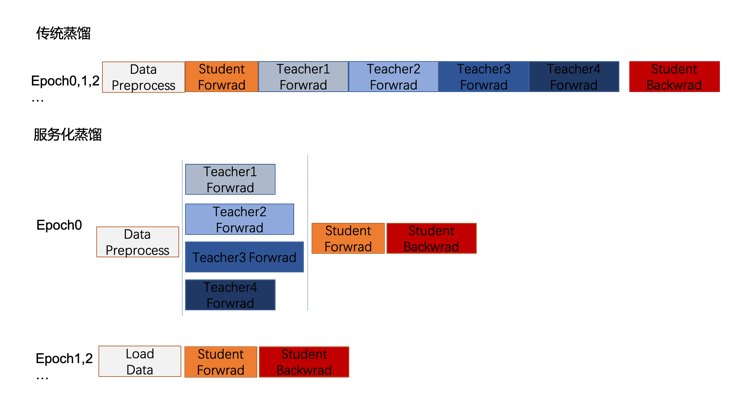
(2)量化
在推理过程中,我们希望将FLOAT32量化到更低位数,如INT8、INT4等,以期达到更低的内存占用、更低的功耗和更快的计算速度。
一方面我们在尽可能保持量化工具的先进性,探索前沿各种新的量化算法,将量化前后的指标效果损失降到最低。另一方面我们在构建自动量化的机制,让更多模型能够享受量化带来的速度提升。
(3)剪枝
剪枝按照粒度来讲,从细粒度的单参数裁剪,按照一定pattern将不重要的权重置为0,但需要搭配特定的硬件才能在整体看到速度提升。
粒度更粗一点,对于transformer类的模型,可以裁剪attention head,将不重要或者提供信息较少的head识别出来并去除。甚至可以更大胆一点,直接跳过一些层的推理。
04 总结
百度搜索架构部模型架构组的工作非常有挑战性和意义,我们致力于将最新的人工智能技术以更低的成本带给百度数亿用户体验到。我们不仅关注深度学习模型在搜索领域的工程应用和优化,还不断探索和研究新的技术手段,以不断提升搜索模型的效率和性能,同时也在尝试用深度模型重塑架构。如果你对搜索、语义检索、深度模型优化加速等领域感兴趣,欢迎加入我们的团队,一起为用户的搜索体验做出贡献。
——END——
推荐阅读
文生图大型实践:揭秘百度搜索AIGC绘画工具的背后故事!
大模型在代码缺陷检测领域的应用实践
通过Python脚本支持OC代码重构实践(二):数据项提供模块接入数据通路的代码生成
对话InfoQ,聊聊百度开源高性能检索引擎 Puck
浅谈搜索展现层场景化技术-tanGo实践
