


前言
使用Selenium 创建多个浏览器,这在自动化操作中非常常见。
而在Python中,使用 Selenium + threading 或 Selenium + ThreadPoolExecutor 都是很好的实现方法。
应用场景:
- 创建多个浏览器用于测试或者数据采集;
- 使用Selenium 控制本地安装的 chrome浏览器 去做一些操作
- …
文章提供了 Selenium + threading 和 Selenium + ThreadPoolExecutor 结合的代码模板,拿来即用。
知识点📖📖
| 作用 | 链接 |
|---|---|
threading用于实现多线程 |
https://docs.python.org/zh-cn/3/library/threading.html |
concurrent.futures.ThreadPoolExecutor 使用线程池来异步执行调用 |
https://docs.python.org/zh-cn/3/library/concurrent.futures.html |
上面两个都是 Python 内置模块,无需手动安装~
导入模块
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
多线程还是线程池?
在Selenium中,使用 多线程 或者是 线程池,差别并不大。主要都是网络I/O的操作。
在使用 ThreadPoolExecutor 的情况下,任务将被分配到不同的线程中执行,从而提高并发处理能力。与使用 threading 模块相比,使用 ThreadPoolExecutor 有以下优势:
- 更高的并发处理能力:线程池 可以动态地调整线程数量,以适应任务的数量和处理要求,从而提高并发处理能力。
- 更好的性能:线程池 可以根据任务的类型和大小动态地调整线程数量,从而提高性能和效率。
- …
总之,使用 线程池 可以提高并发处理能力,更易于管理,并且可以提供更好的性能和效率。
但是选择多线程,效果也不差。
所以使用哪个都不必纠结,哪个代码量更少就选哪个自然是最好的。
多个浏览器✨
Selenium自动化中需要多个浏览器,属于是非常常见的操作了。
不管是用于自动化测试、还是爬虫数据采集,这都是个可行的方法。
这里示例的代码中,线程池的运行时候只有 多线程 的一半!!!
多线程与 多 浏览器🧨
这份代码的应用场景会广一些,后续复用修改一下 browser_thread 函数的逻辑就可以了。
这里模拟相对复杂的操作,在创建的浏览器中新打开一个标签页,用于访问指定的网站。
然后切换到新打开的标签页,进行截图。
代码释义:
- 定义一个名为 start_browser 的函数,用于创建 webdriver.Chrome 对象。
- 定义一个名为 browser_thread 的函数,接受一个 webdriver.Chrome 对象和一个整数作为参数,用于打开指定网页并截图。 切换到最后一个窗口,然后截图。
- main函数创建了5个浏览器,5个线程,执行上面的操作,然后等待所有线程执行完毕。
# -*- coding: utf-8 -*-
# Name: multi_thread.py
# Author: 小菜
# Date: 2023/6/1 20:00
# Description:
import threading
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
def start_browser():
service = ChromeService(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
return driver
def browser_thread(driver: webdriver.Chrome, idx: int):
url_list = ['https://www.csdn.net/', 'https://www.baidu.com',
'https://music.163.com/', 'https://y.qq.com/', 'https://cn.vuejs.org/']
try:
driver.execute_script(f"window.open('{url_list[idx]}')")
driver.switch_to.window(driver.window_handles[-1])
driver.save_screenshot(f'{idx}.png')
return True
except Exception:
return False
def main():
for idx in range(5):
driver = start_browser()
threading.Thread(target=browser_thread, args=(driver, idx)).start()
# 等待所有线程执行完毕
for thread in threading.enumerate():
if thread is not threading.current_thread():
thread.join()
if __name__ == "__main__":
main()
运行结果
- 运行时长在9.28秒(速度与网络环境有很大关系,木桶效应,取决于最后运行完成的浏览器
- 看到程序运行完成后,多出了5张截图。
线程池与 多 浏览器🎍
这份代码与 多线程与 多浏览器 的操作基本一致。速度上却比多线程节省了一半。
# -*- coding: utf-8 -*-
# Name: demo2.py
# Author: 小菜
# Date: 2023/6/1 20:00
# Description:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from concurrent.futures import ThreadPoolExecutor, as_completed
MAX_WORKERS = 5
service = ChromeService(ChromeDriverManager().install())
def start_browser():
driver = webdriver.Chrome(service=service)
return driver
def browser_task(driver: webdriver.Chrome, idx: int):
url_list = ['https://www.csdn.net/', 'https://www.baidu.com',
'https://music.163.com/', 'https://y.qq.com/', 'https://cn.vuejs.org/']
try:
driver.execute_script(f"window.open('{url_list[idx]}')")
driver.switch_to.window(driver.window_handles[-1])
driver.save_screenshot(f'{idx}.png')
return True
except Exception:
return False
def main():
executor = ThreadPoolExecutor(max_workers=MAX_WORKERS)
ths = list()
for idx in range(5):
driver = start_browser()
th = executor.submit(browser_task, driver, idx=idx)
ths.append(th)
# 获取结果
for future in as_completed(ths):
print(future.result())
if __name__ == "__main__":
main()
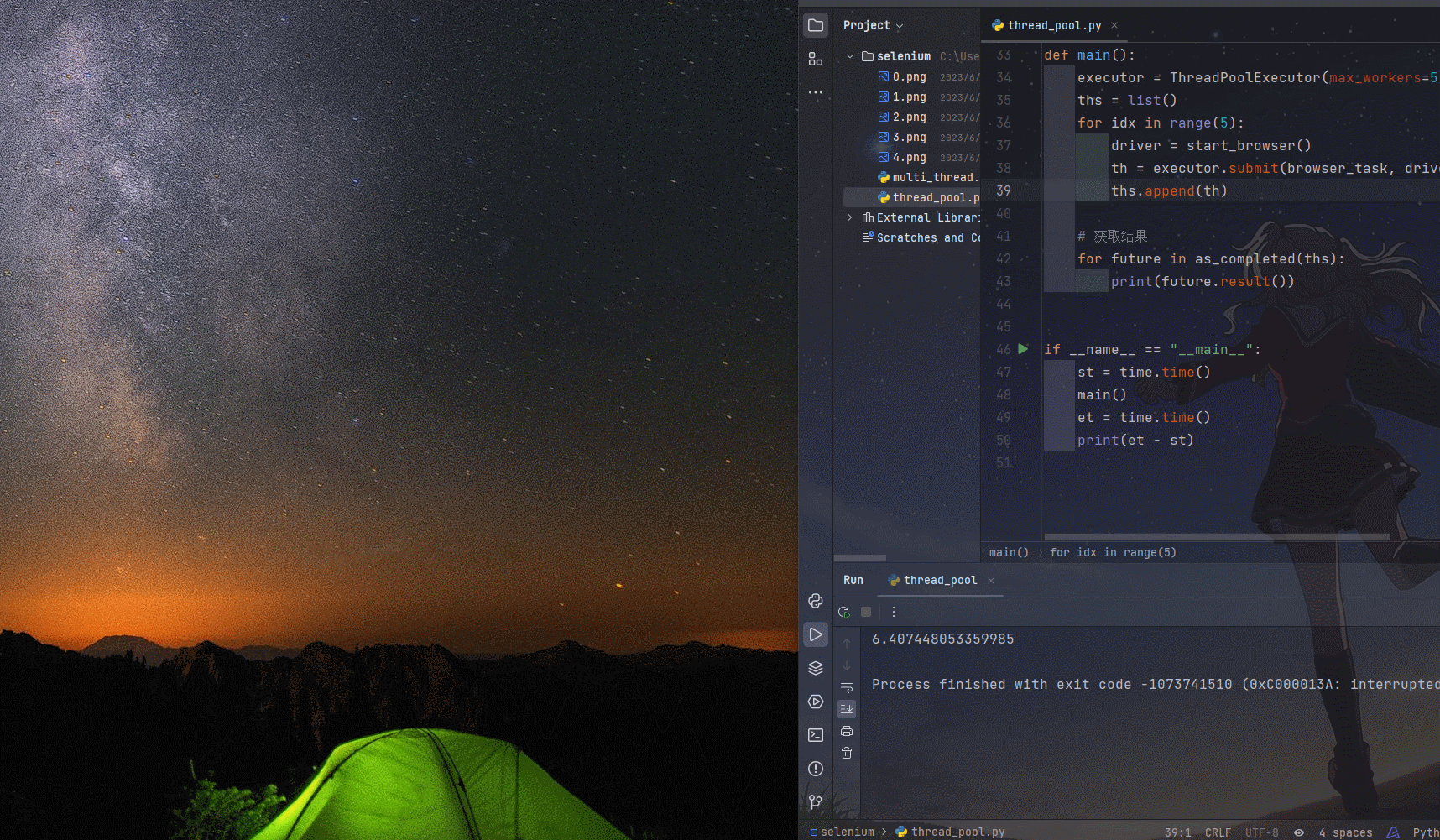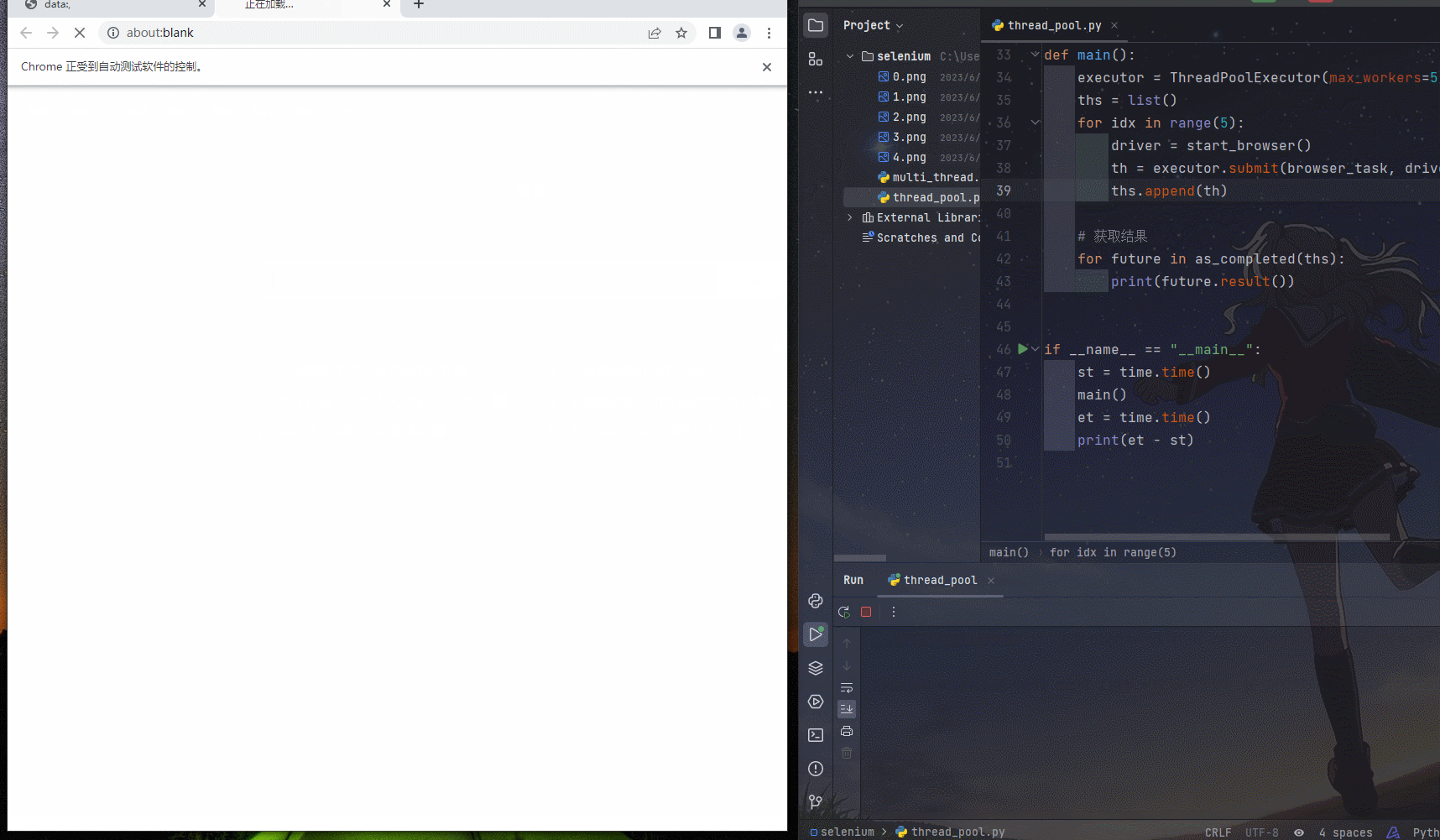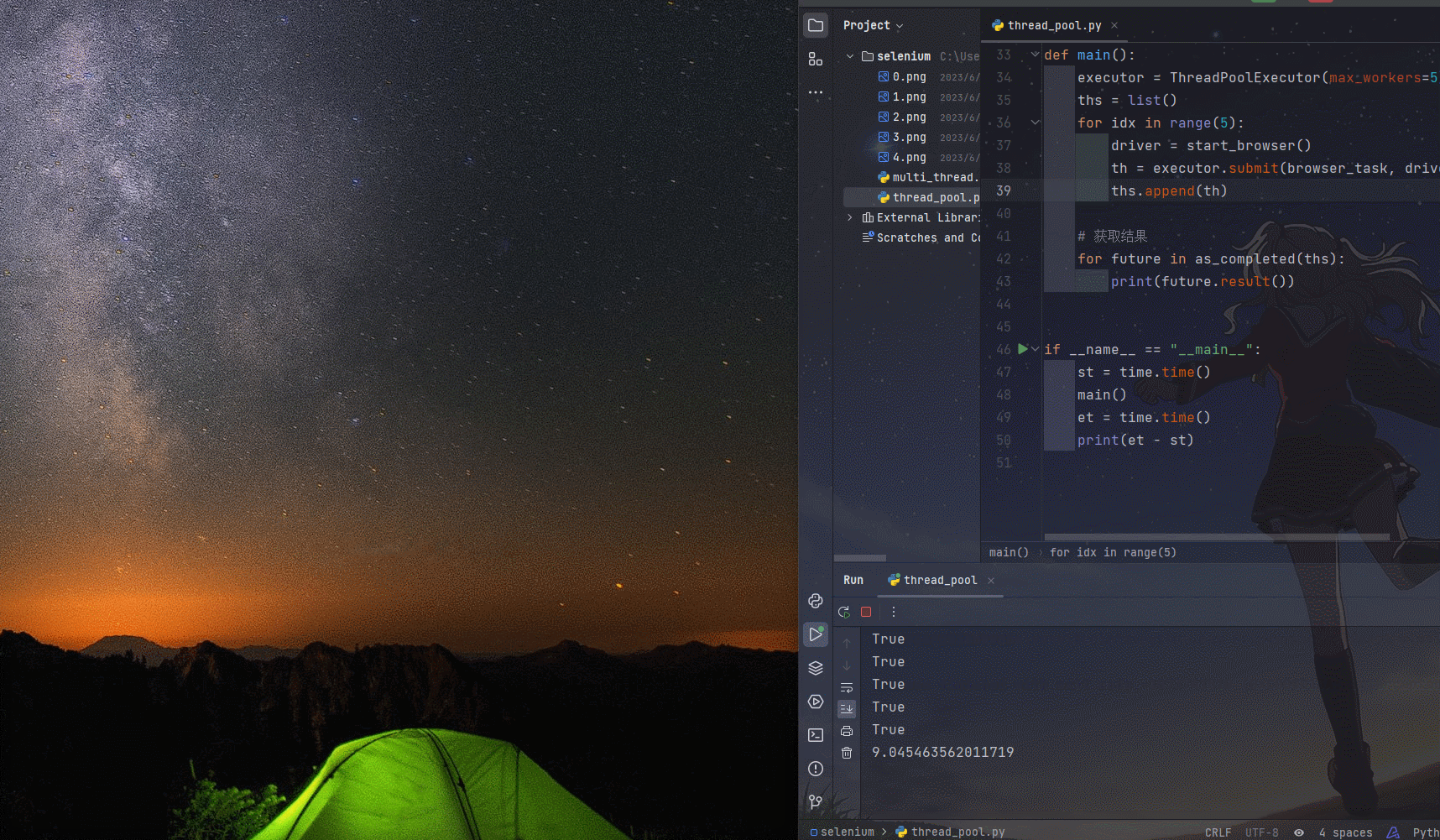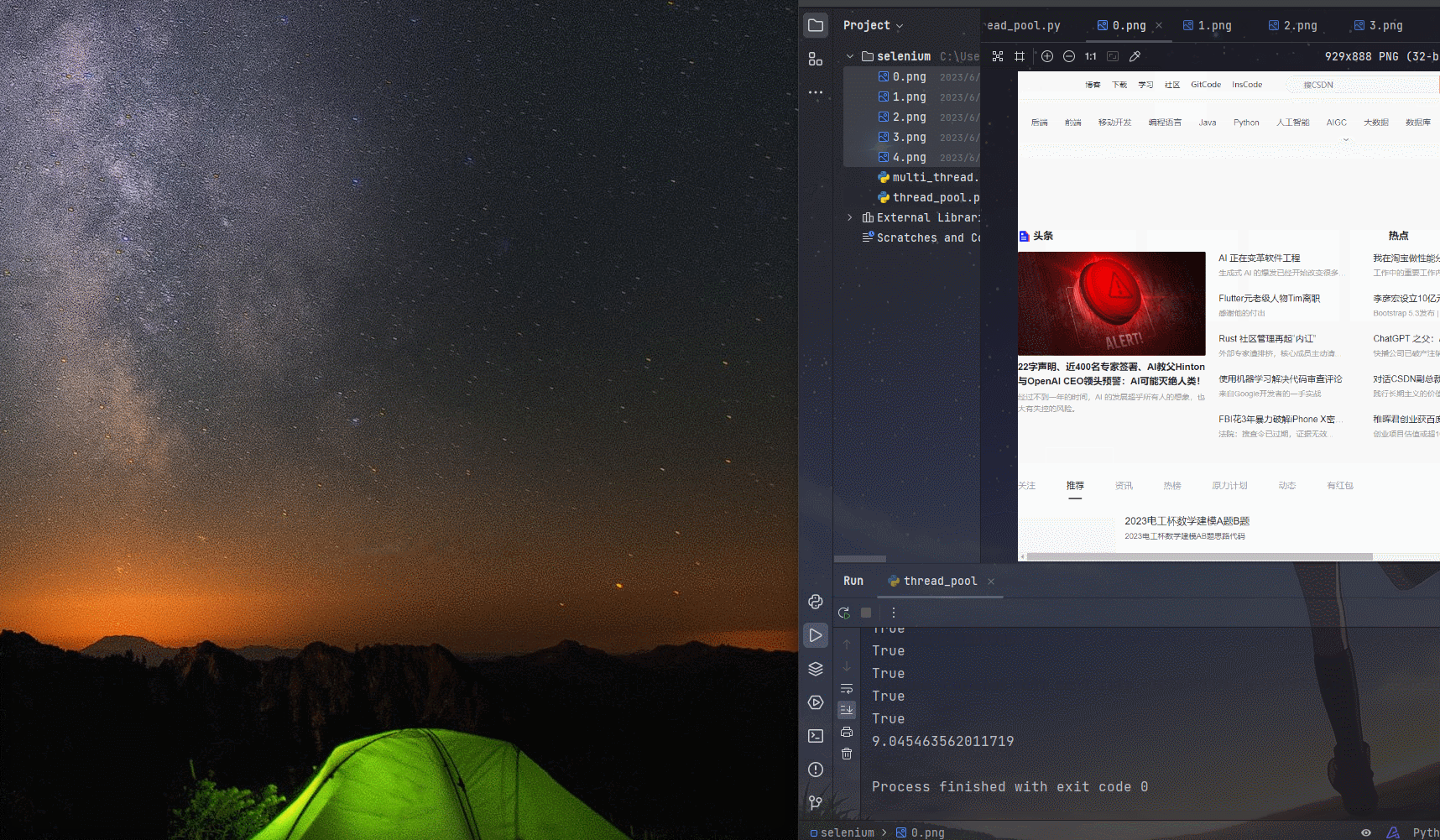
运行结果
- 运行时长在4.5秒(运行效果图不是很匹配,但确实是比多线程快很多。
- 看到程序运行完成后,多出了5张截图。
多个标签页
这个的应用场景有点意思。
这里的操作与上面的 多个浏览器其实是差不多的。
区别在于:上面打开多个浏览器,这里打开多个标签页。
所以这个需要考量一个问题:资源争夺。与是这里用上了 threading.Lock 锁,用以保护资源线程安全。
多线程与 多 标签页🎃
代码释义:
- 与上面差不多,不解释了。
# -*- coding: utf-8 -*-
# Name: demo2.py
# Author: 小菜
# Date: 2023/6/1 20:00
# Description:
import threading
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
service = ChromeService(ChromeDriverManager().install())
lock = threading.Lock()
def start_browser():
driver = webdriver.Chrome(service=service)
return driver
def browser_thread(driver: webdriver.Chrome, idx: int):
url_list = ['https://www.csdn.net/', 'https://www.baidu.com',
'https://music.163.com/', 'https://y.qq.com/', 'https://cn.vuejs.org/']
try:
lock.acquire()
driver.execute_script(f"window.open('{url_list[idx]}')")
driver.switch_to.window(driver.window_handles[idx + 1])
driver.save_screenshot(f'{idx}.png')
return True
except Exception:
return False
finally:
lock.release()
def main():
driver = start_browser()
for idx in range(5):
threading.Thread(target=browser_thread, args=(driver, idx)).start()
# 等待所有线程执行完毕
for thread in threading.enumerate():
if thread is not threading.current_thread():
thread.join()
if __name__ == "__main__":
main()
运行结果
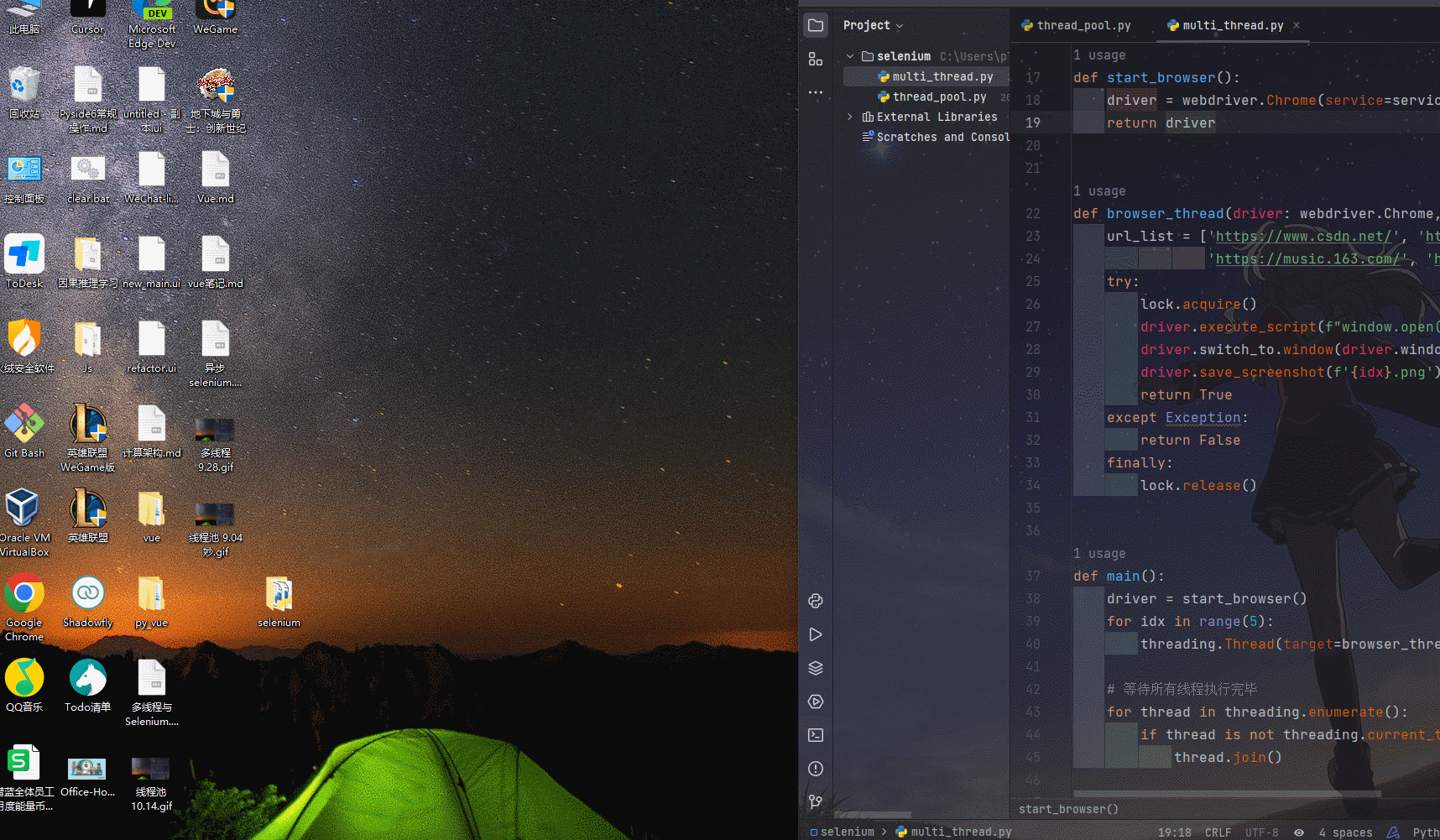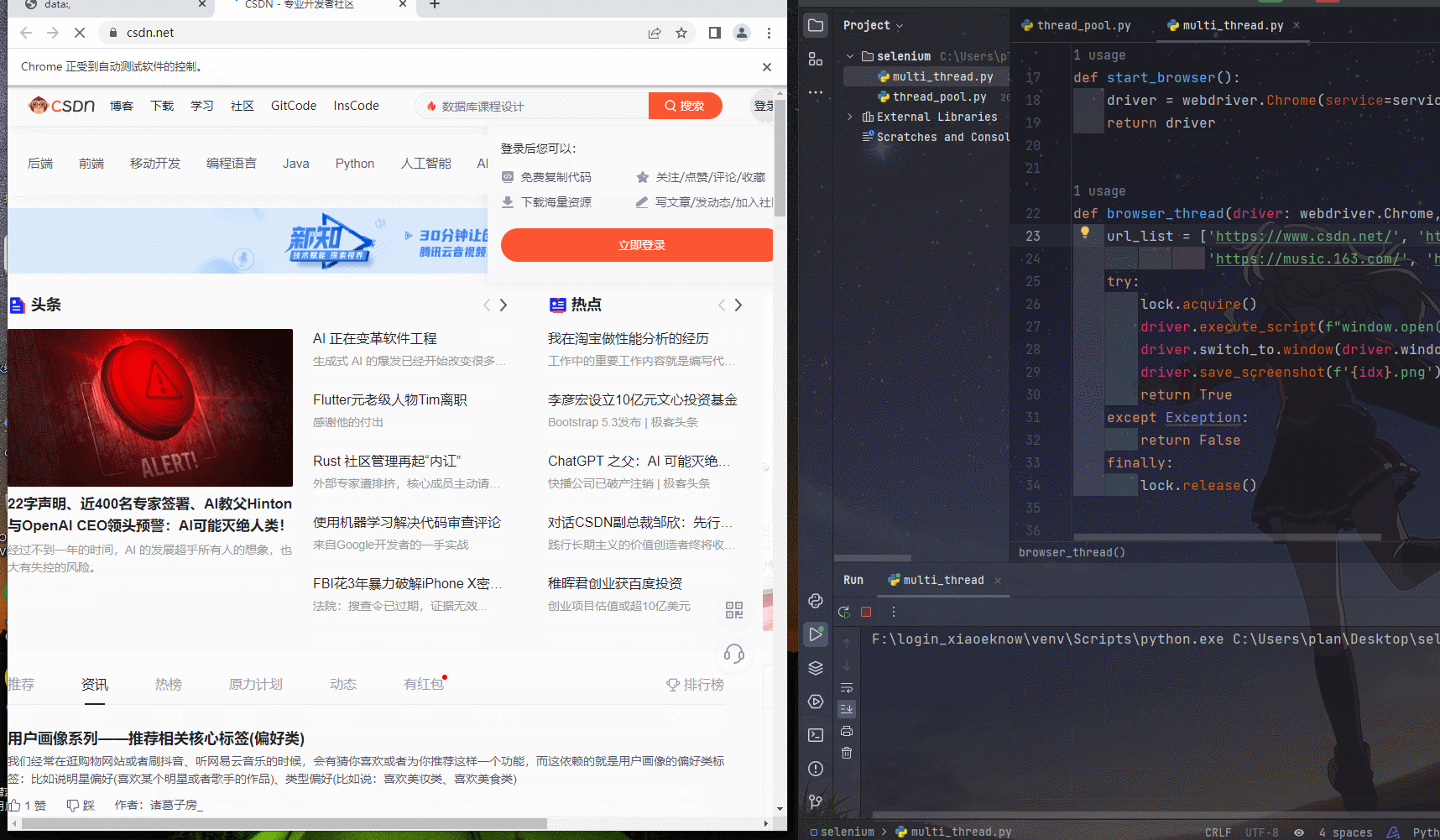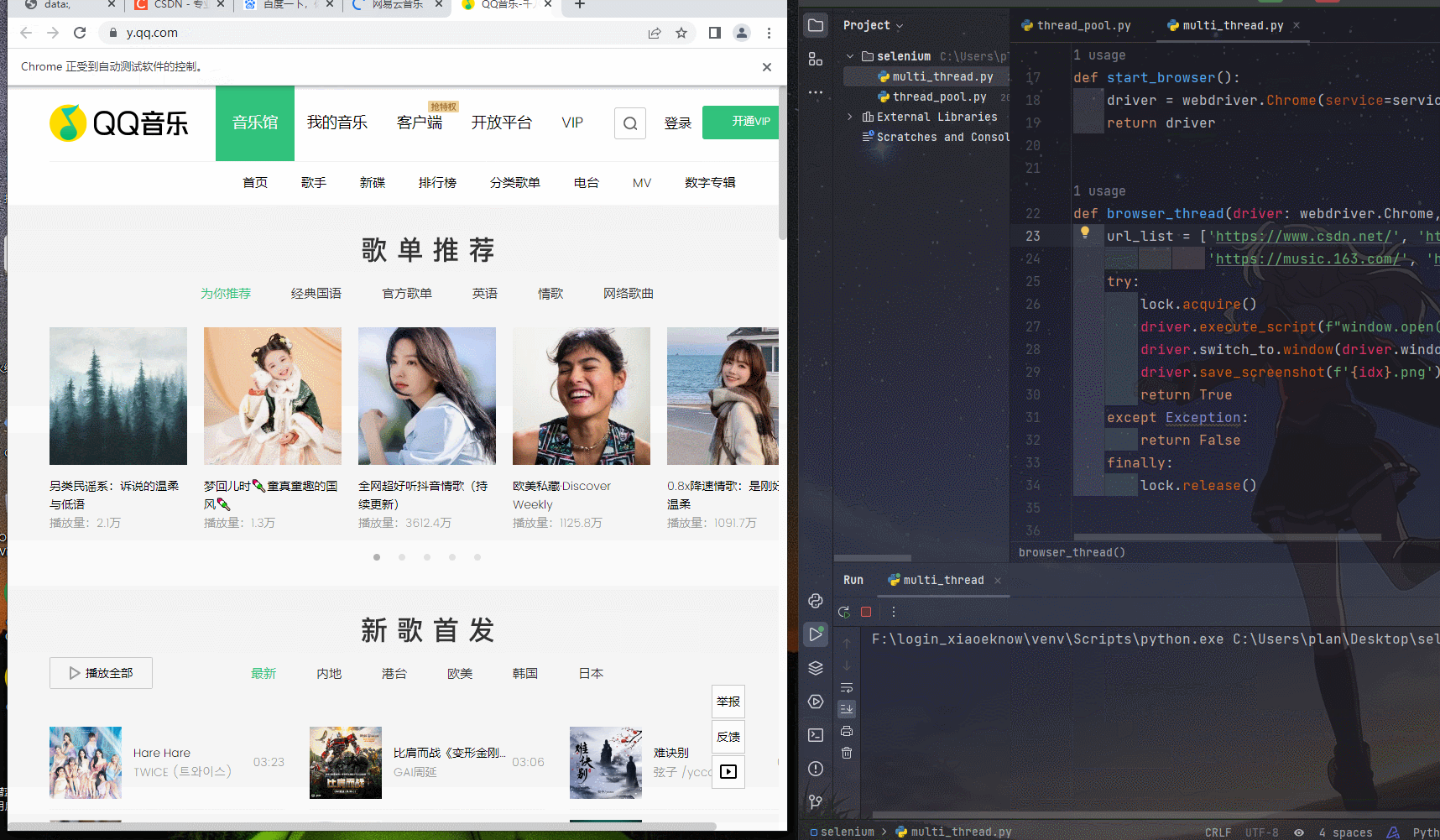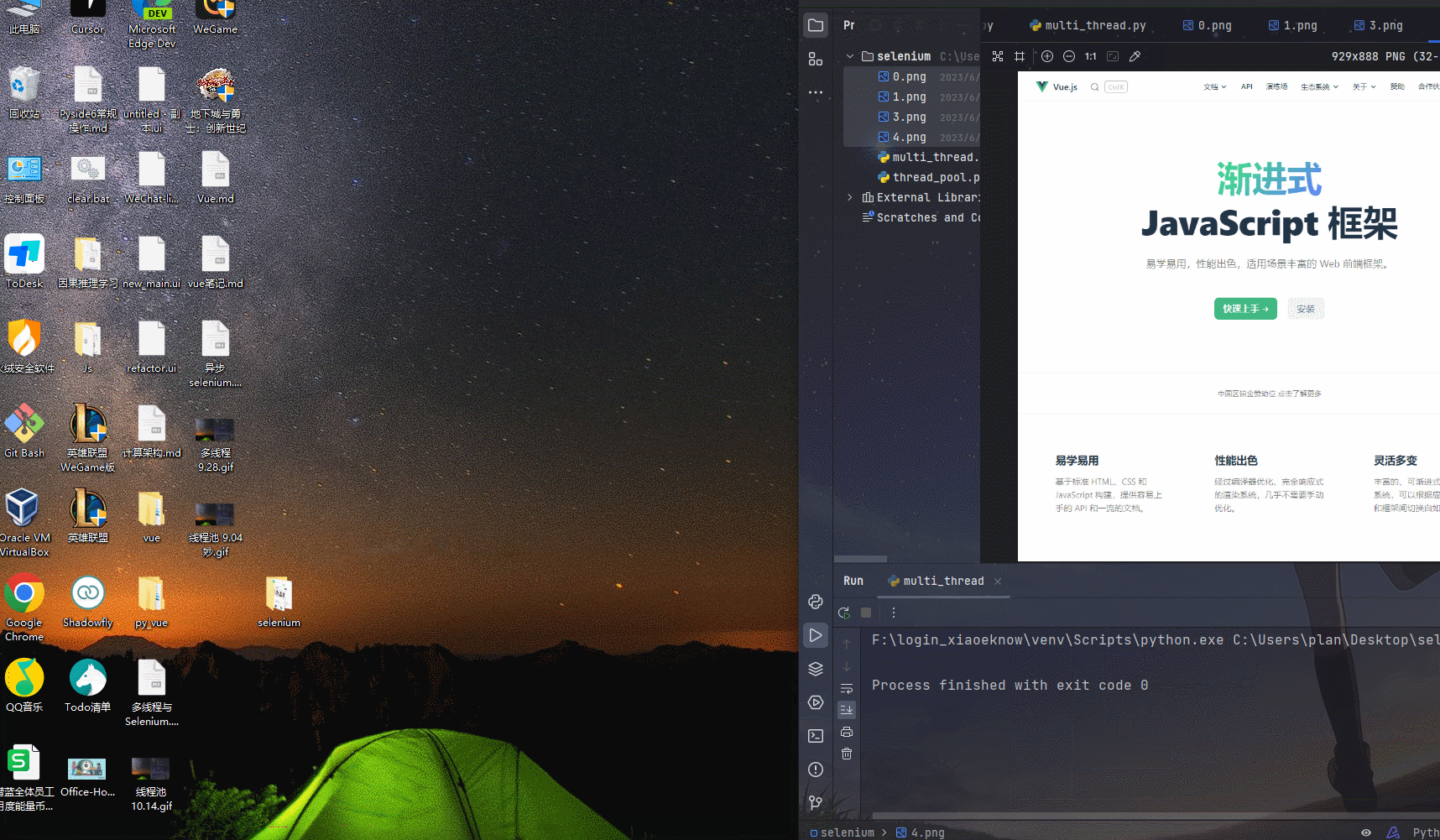
线程池与 多 标签页👀
这里不展示运行结果了,因为效果与 多线程与 多 标签页 一致。
# -*- coding: utf-8 -*-
# Name: thread_pool.py
# Author: 小菜
# Date: 2023/6/1 20:00
# Description:
import time
import threading
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from concurrent.futures import ThreadPoolExecutor, as_completed
MAX_WORKERS = 5
service = ChromeService(ChromeDriverManager().install())
lock = threading.Lock()
def start_browser():
driver = webdriver.Chrome(service=service)
return driver
def browser_task(driver: webdriver.Chrome, idx: int):
url_list = ['https://www.csdn.net/', 'https://www.baidu.com',
'https://music.163.com/', 'https://y.qq.com/', 'https://cn.vuejs.org/']
try:
lock.acquire()
driver.execute_script(f"window.open('{url_list[idx]}')")
driver.switch_to.window(driver.window_handles[idx + 1])
driver.save_screenshot(f'{idx}.png')
return True
except Exception:
return False
finally:
lock.release()
def main():
driver = start_browser()
executor = ThreadPoolExecutor(max_workers=MAX_WORKERS)
ths = list()
for idx in range(5):
th = executor.submit(browser_task, driver, idx=idx)
ths.append(th)
# 获取结果
for future in as_completed(ths):
print(future.result())
if __name__ == "__main__":
st = time.time()
main()
et = time.time()
print(et - st)
总结⚡⚡
本文章介绍了 Selenium + threading 和 Selenium + ThreadPoolExecutor 来创建多个浏览器或多个标签页的操作。
文中示例的代码比较简单,所以 线程池 比 多线程 运行的更加快。
但在实际的使用过程中,可以根据自己的喜好去选择 线程池 还是 多线程 。
后话
本次分享到此结束,
see you~🐱🏍🐱🏍
