



从刻在兽骨上的甲骨文,再到写在纸上的汉字,每一次信息载体的变更都是文化进步的重要标志。在如今这个信息数字化的时代,我们在享受着数字化便利的同时,数据也在我们看不见的地方飞速增长着,数据的重要性不言而喻。那应该如何将海量数据完整、有序、持久化地保存下来呢?
程序员小伙伴看到这里应该猜到了我们的今天的主角,没错就是「数据库」。
一、分布式数据库
程序员熟知的单体数据库如 MySQL、Oracle 在二十世纪末诞生并大行其道,直到 2010 年左右移动互联网爆发,席卷而来的海量数据,让单体数据库面临了前所未有的挑战,这也让数据库迎来了百花齐放的时代。
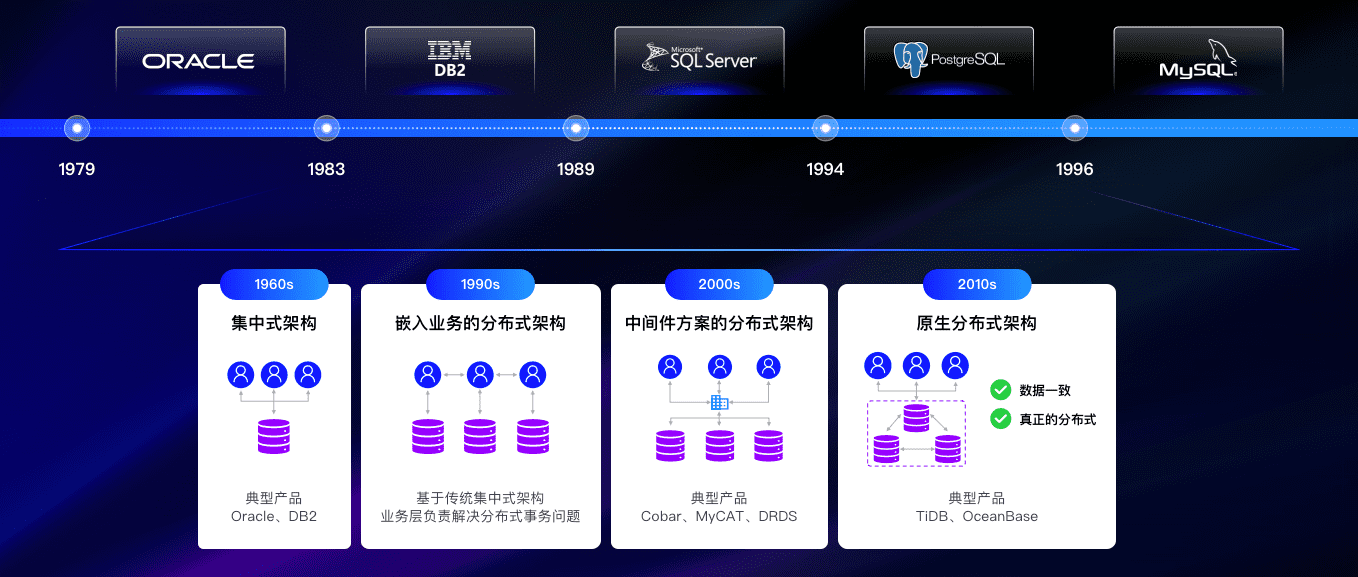
为了解决海量数据存储的问题,程序员们做了诸多尝试,比如堆机器配置、利用分库分表配合中间件实现分布式架构等,却发现治标不治本、换汤不换药,只是延长了问题出现的周期,还引发了维护成本高、上手难度大等问题。因此,新型分布式数据库应运而生,它基于分布式原理把数据处理和存储分到多台普通机器上处理,从根本上解决了单体数据库存储海量数据的瓶颈和性能问题,并优化了传统分布式数据库的数据一致性问题。
分布式数据库虽然能解决数据量瓶颈的问题,但换数据库是个类似动心脏的大手术,不仅风险极大而且“劳民伤财”。那有没有一款开源分布式数据库不仅可以处理海量数据,而且换起来比较轻松呢?
二、OceanBase
今天 HelloGitHub 就给大家介绍一款可以解决上述问题的开源分布式数据库——OceanBase,它从出生那天起就是为了搞定数据库成本、性能的相关痛点。
OceanBase 是一款从蚂蚁集团走出来的完全自主研发、高度兼容 Oracle 和 MySQL 的原生分布式数据库。它于 2021 年开源,具有金融级高可用、水平扩展、分布式事务、省钱(存储成本低)、易迁移等特性,具备机房和城市级别的高可用和容灾的功能(RPO=0,RTO
GitHub 地址:https://github.com/oceanbase/oceanbase
数据库作为最核心的基础服务之一,必须要做到稳定、可靠,没有人会把重要的数据交到一个初出茅庐的“毛头小子”手里。这点在 OceanBase 完全不用担心,因为它已年满“13 岁”,同时凭借高性能、高可用、低成本、无限扩展和服务永远在线的特点,连续 10 年稳定支撑「天猫双 11 」,并成为金融、水利水电、运输、通信、政企等行业诸多企业核心系统的数据底座。

这份“履历”看下来,是不是感觉 OceanBase 挺高大上、上手门槛一定很高对不对?不不不,OceanBase 社区提供了详细的中文文档、有问必答的板块、从入门到进阶的免费课程、奖励丰厚的比赛等,不管你是数据库小白还是大牛,都能给你安排地明明白白!
既然已经看到这里了,相请不如偶遇,下面就和 HelloGitHub 一起从最简单的安装 OceanBase 开始,走近这款目标是“星辰大海”的开源分布式数据库!
三、快速上手
看了这么多是不是都手痒了?那就一起来上手体验下吧!(这部分很短、很快)
3.1 一键安装
下载 all-in-one 一键安装脚本(需要联网)并执行成功后,你就能立马得到一个 OceanBase 数据库实例。
# 下载
bash -c "$(curl -s https://obbusiness-private.oss-cn-shanghai.aliyuncs.com/download-center/opensource/oceanbase-all-in-one/installer.sh)"
# 执行
source ~/.oceanbase-all-in-one/bin/env.sh && obd demo
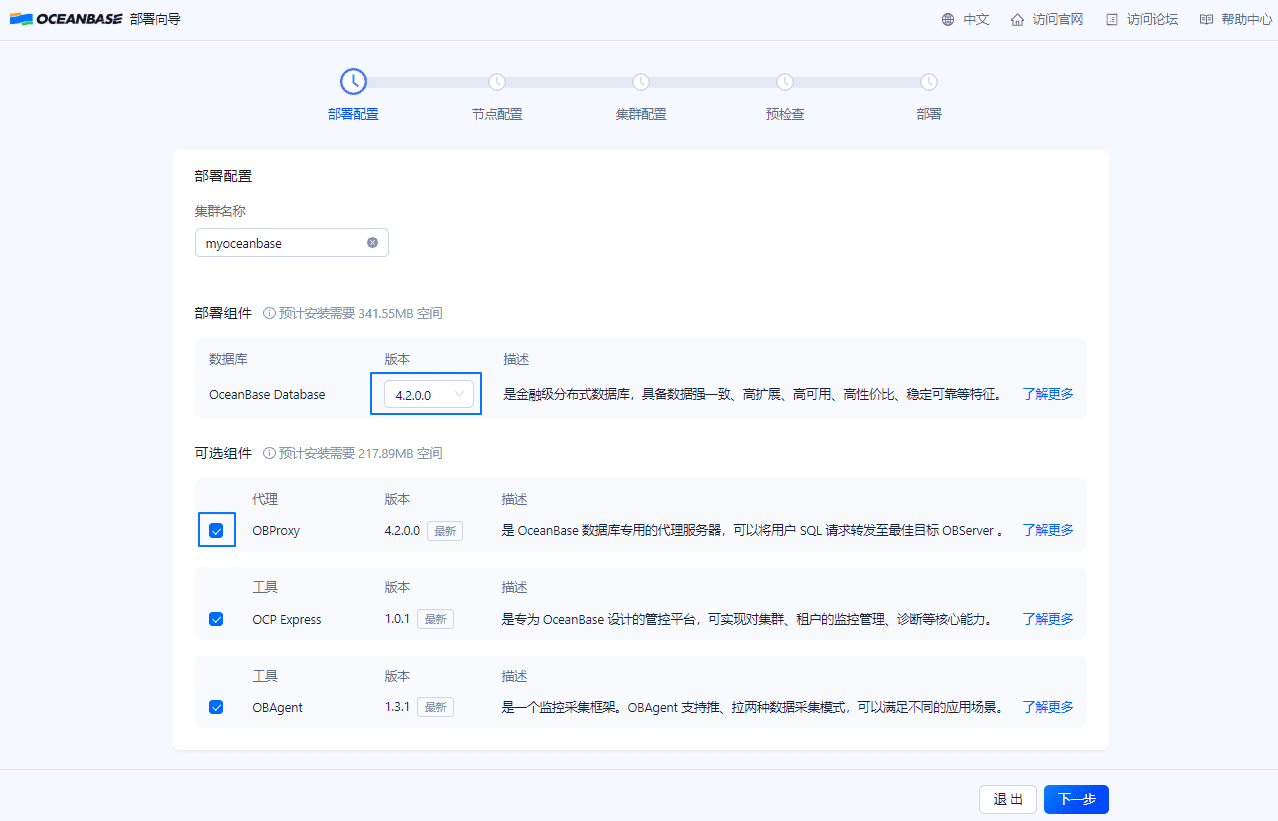
这里介绍的方法为本地体验使用,部署 OceanBase 集群可执行 obd web 命令,然后打开浏览器进入「安装部署向导」完成部署。
[admin@test001 ~]$ obd web
start OBD WEB in 0.0.0.0:8680
please open http://172.xx.xxx.233:8680
3.2 Docker 启动
下面介绍一下,如何通过 Docker 快速启动 OceanBase。
# 1.部署一个 mini 模式实例
docker run -p 2881:2881 --name oceanbase-ce -e MINI_MODE=1 -d oceanbase/oceanbase-ce
# 2. 连接 OceanBase
docker exec -it oceanbase-ce ob-mysql sys # 连接 root 用户 sys 租户
login as root@sys
Command is: obclient -h127.1 -uroot@sys -A -Doceanbase -P2881
Welcome to the OceanBase. Commands end with ; or g.
Your OceanBase connection id is 3221487727
Server version: OceanBase_CE 4.1.0.0 (r100000192023032010-0265dfc6d00ff4f0ff4ad2710504a18962abaef6) (Built Mar 20 2023 10:12:57)
Copyright (c) 2000, 2018, OceanBase and/or its affiliates. All rights reserved.
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
obclient [oceanbase]>
至此,我们已成功进入 OceanBase 命令行,可以写 SQL 啦!但写几条 SQL 演示我感觉没啥意思,下面我打算深入 OceanBase 底层介绍下它的核心技术。
四、核心技术
OceanBase 采用 C++ 语言编写,下面这段代码是 OceanBase 0.1(2010年)就定义的一个最基本的 C++ 枚举类型 ObObjtype,用来表述数据库中存储的数值类型。

如今 OceanBase 已支持五十余种数值类型,而这段依然“活着”的早期代码见证并体现了 OceanBase 十多年来的架构发展。
2021 年 OceanBase 将 300 万行核心代码开源,供程序员们学习和共建。篇幅有限,这里仅简单地介绍下 OceanBase 的存储引擎和事务引擎两部分的核心技术,这两点也是程序员在面试时,聊到数据库经常会被问到的面试题。希望读完这部分后,可以帮助你可以对数据库底层技术有一个整体的了解,触类旁通对数据库底层技术产生兴趣。
4.1 存储引擎
目前,数据库存储引擎的两大顶流数据结构是 B+ 树(MySQL)和 LSM-Tree(HBase、RocksDB),OceanBase 的存储引擎就是基于 LSM-Tree 构建的高压缩引擎。
LSM-Tree(日志结构合并树)是一种分层、有序、面向磁盘的数据结构。它的核心思想是将内存中的增量数据(MemTable),逐层向磁盘上的静态数据 SSTable 进行转储与合并,初衷是为了将小粒度的随机写聚合成大粒度的顺序追加写,从而减少机械磁盘悬臂的频繁机械运动,提升 I/O 效率。
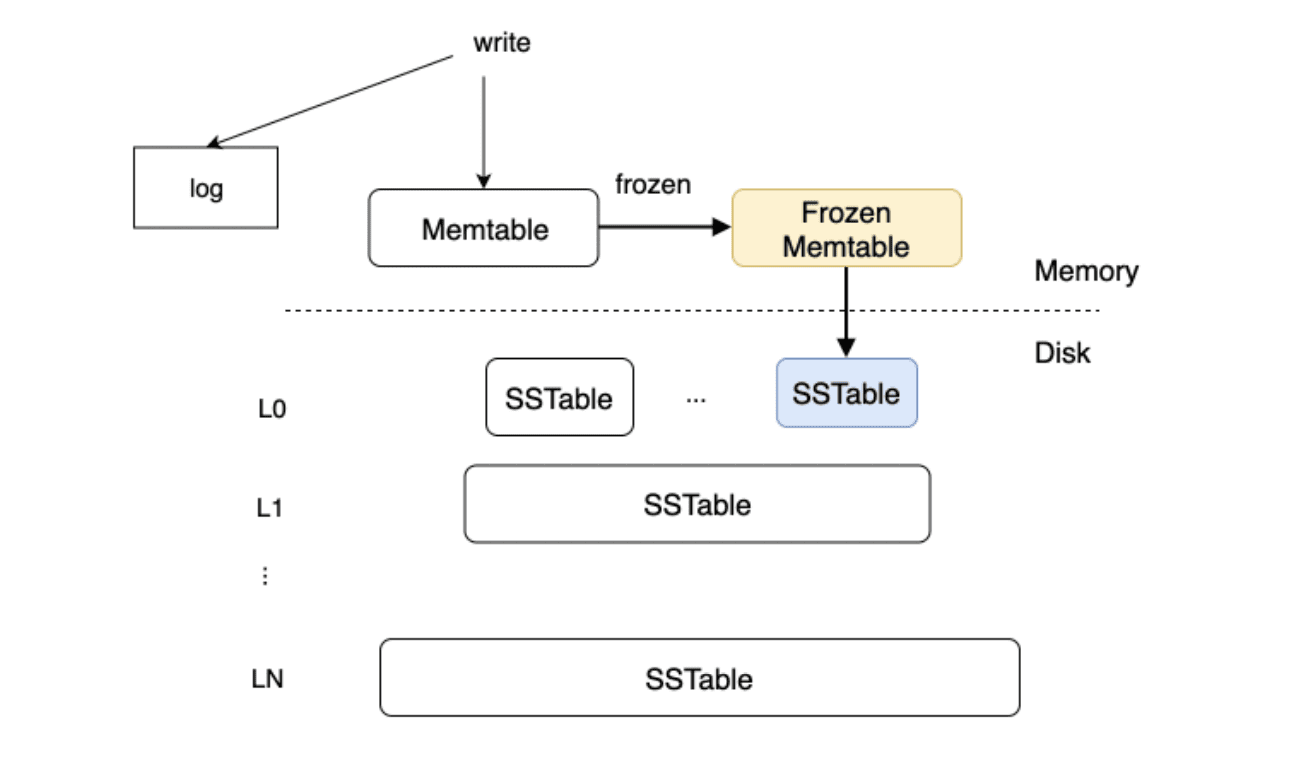
SSTable
SSTable 代表内部有序的磁盘文件。数据按照 key 排序,可以使用二分搜索的方式快速得到指定 key 的数据。磁盘上的 SSTable 被划分为多个层级(Level),层级数字越低表示数据被写入的时间越近,层级数字越大表示数据越旧。
MemTable
MemTable 是纯内存状态的数据结构。为了便于后续进行顺序读取生成磁盘上的 SSTable,一般采用排序树(红黑树/AVL 树)、SkipList 等这类有顺序的数据结构。
结论
OceanBase 选用 LSM-Tree 是看中了其批量写入具有更好的写操作吞吐量,相较于 B+ 树 SSTable 没有定长块限制,适合做解压/压缩,读取速度更快。从而实现了 OceanBase 的高性能、数据压缩带来的存储低成本和 OLAP(线上分析处理)的能力。
4.2 事务引擎
事务就是数据库中一系列数据操作的集合,集合可能有大有小,但无论集合中有多少操作,要么一起操作成功,要么失败一起回滚。无论集合中有多少操作,对于用户来说,就是一个操作。
4.2.1 背景知识
事务的 ACID 属性:
- 原子性(Atomicity):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用。
- 一致性(Consistency):确保从一个正确的状态转换到另外一个正确的状态,这就是一致性。要么事务成功,进入一个新的状态,要么事务回滚,回到过去稳定的状态。
- 隔离性(Isolation):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间是独立的。
- 持久性 (Durability):一个事务被提交之后,对数据库中数据的改变是持久的,即使数据库发生故障,比如断电宕机,也不应该对其有任何影响。
由于一个事务包含多个操作,可能出现事务进行到一半发生故障的情況,此时数据库会处于不一致的状态。数据库要恢复到一致性状态,要么撤销已经执行的操作,恢复到事务执行前的状态,要么重做未完成的操作,恢复到事务执行后的状态。要知道哪些操作需要撤销、哪些操作需要重做,一般会用到一种技术「日志」。
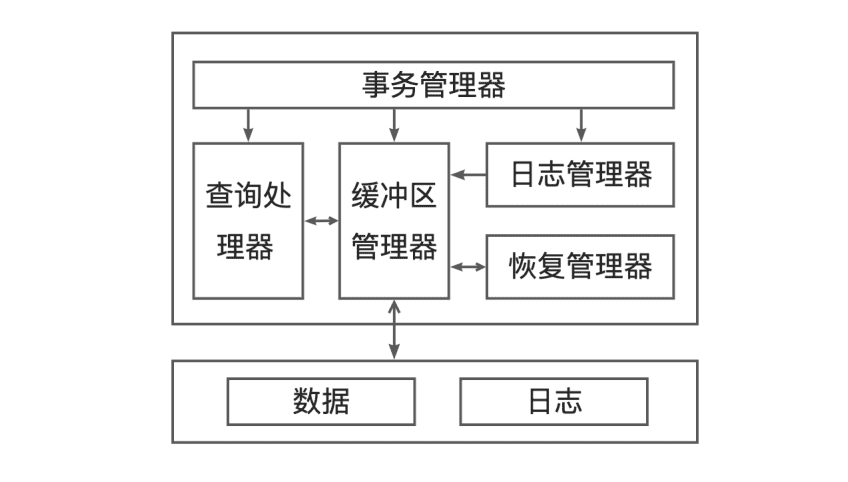
在数据库设计中,将记录撤销操作的日志称为 undo log,将记录重做操作的日志称为 redo log。
4.2.2 分布式事务
在分布式场景下,OceanBase 采用了两阶段提交、Paxos 协议等手段来保证事务正确执行。
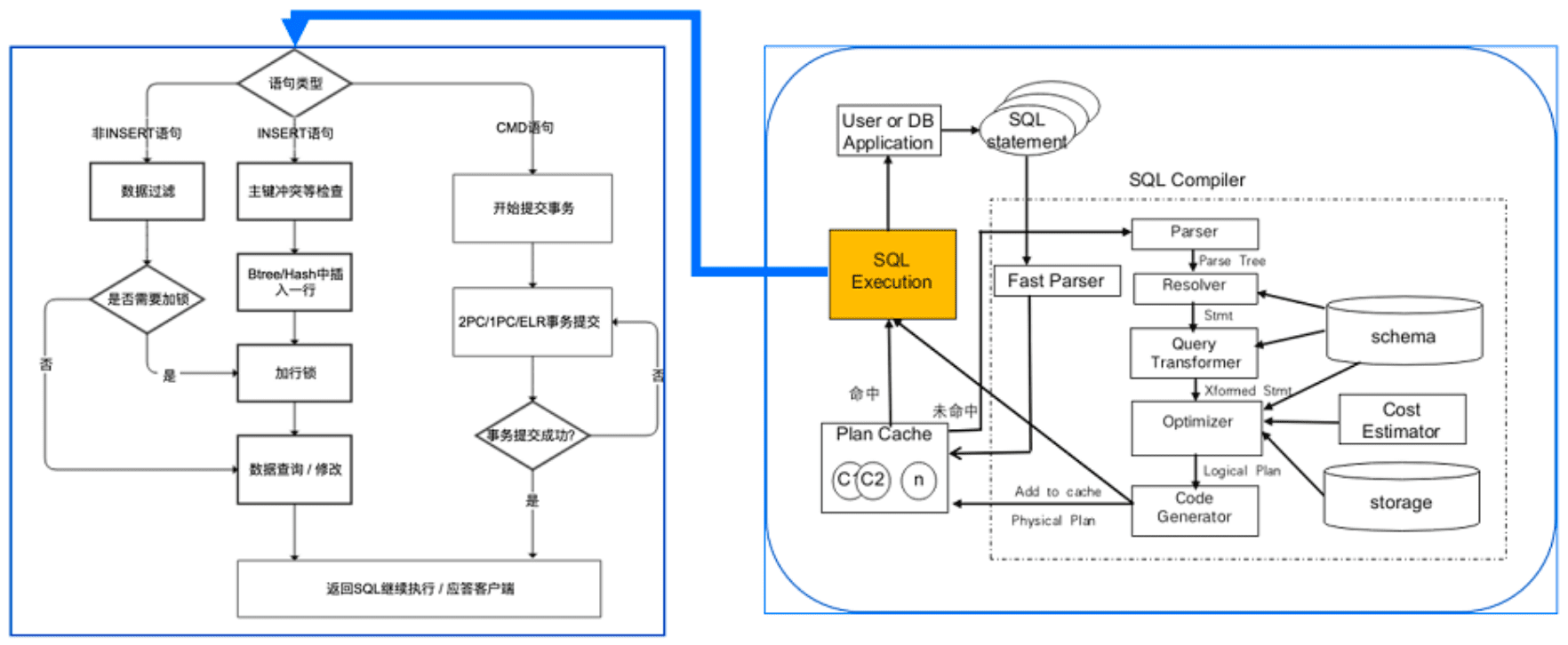
上图右边是 OceanBase SQL 引擎执行过程,左边是事务引擎执行过程。从上图可以看到,为保证事务的一致性需要做很多事情,主要分为「事务执行」和「事务提交」两部分,下面简单介绍下 OceanBase 确保事务正确执行的三大核心技术。
1、redo 日志
对于单个机器来说,OceanBase 数据库通过 redo 日志记录了数据的修改,通过 WAL 机制在宕机重启之后恢复数据。保证事务一旦提交成功,事务数据就不会丢失。对于分布式集群来说,OceanBase 数据库通过 Paxos 协议将数据同步到多个副本,只要多数派副本存活事务数据就不会丢失。
2、版本号管理
为了支持数据读写不互斥,OceanBase 数据库存储了多个版本的数据。多版本一致性通过读版本和数据版本来保证,每个成功提交的事务都会为数据增加一个版本,读请求只能读到小于等于读取版本号的已提交数据,从而保证并发读写的一致性和性能。
3、两阶段提交(事务提交)
分布式系统中,事务操作的表或者分区可能分布在不同机器上。OceanBase 数据库采用两阶段提交协议保证事务的原子性,确保多个节点上的事务要么都提交要么都回滚。
结论
OceanBase 对事务的两阶段提交、版本号管理、redo 日志,以及弱一致性读进行了大量优化,在保证事务 ACID 的基础上,大幅提升了分布式事务的并发性能。
如果看到这里,勾起了你对分布式数据库底层技术的“馋虫”,可以去看看《OceanBase 数据库源码解析》这本书“解馋”。
五、单机分布式一体化架构
可能很多开发者和我一样都觉得分布式数据库是“高不可攀”的存在,认为这个大家伙安装麻烦、配置要求高、需要多台机器。
这里就要表扬下 OceanBase 的“接地气”了,它的单机分布式一体化架构,不仅能让个人用户在本地运行(可在 4C16G 的小型机运行),还能让企业用户实现“一次选择终生受用”!
个人开发者可以轻松地在自己的笔记本电脑上把 OceanBase 跑起来!重点是,单机下的 OceanBase 性能和 MySQL 基本持平。
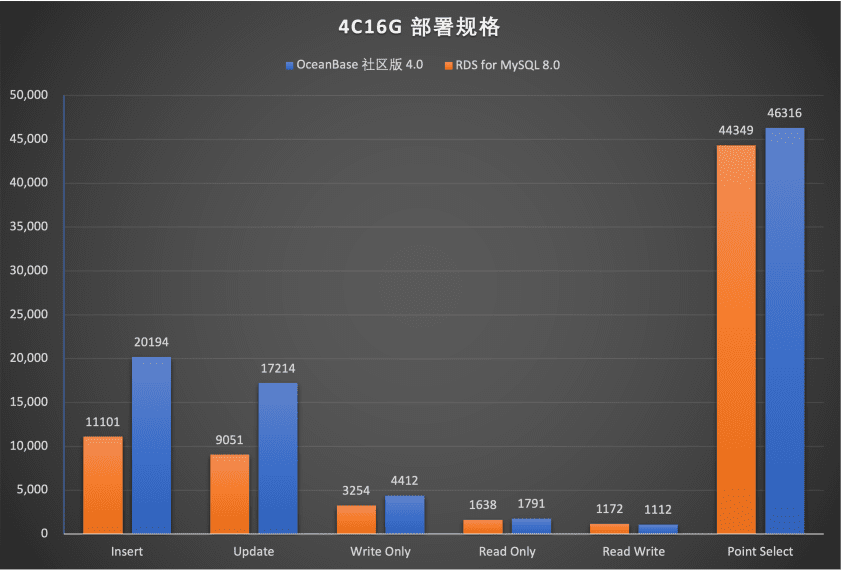
企业用户可以实现“一次选择终生受用”。在公司业务发展的初期,单机部署形态的数据库完全可以满足需求。因此,在业务初期数据量还很小的时候,提供一个尽可能低的启动规格非常重要,而且 OceanBase 单机性能也不错。而在业务高速增长期,OceanBase 良好的扩展性、弹性扩容和高性能,轻松应对不断增加的用户数据和性能需求,尽可能节省存储和运维成本。

六、最后
对于企业而言 OceanBase 的金融级高可用、弹性扩容、高性能、降低成本的特性,能够切实解决业务上的痛点。
- 水平扩展:支持业务快速的扩容缩容,同时通过准内存处理架构实现高性能。支持集群节点超过数千个,单集群最大数据量超过 3PB,最大单表行数达万亿级。
- 高性能:TPC-C 记录(7.07 亿 tmpC)和 TPC-H 记录(1526 万 QphH @30000GB)。
- 高可用:支持同城/异地容灾,可实现多地多活,满足金融行业 6 级容灾标准(RPO=0,RTO
- 实时分析:基于“同一份数据,同一个引擎”,同时支持在线实时交易及实时分析两种场景,“一份数据”的多个副本可以存储成多种形态,从根本上保持数据一致性。
- MySQL 强兼容:高度兼容 MySQL,提供自动迁移工具,支持迁移评估和反向同步以保障数据迁移安全。
- 低成本:基于 LSM-Tree 的高压缩引擎,存储成本相比 MySQL 降低 60%-90%;原生支持多租户架构,一个 OceanBase 集群可以创建多个 MySQL 实例,可为多个独立业务提供服务,且租户间数据隔离,降低部署和运维成本。
对于个人开发者来说,OceanBase 不仅开放了内核源代码,而且 OceanBase 社区还提供了丰富的数据库相关的中文资料和教程。这些都是学习数据库非常好的材料。值得一提的是,OceanBase 有一套严格的代码准入流程,如果你的代码能合并进 300 万行的开源项目,那绝对是一件值得自豪的事情!
GitHub 地址:https://github.com/oceanbase/oceanbase
以上就是本期的所有内容,希望今天 HelloGitHub 的推荐没有让你失望,如果觉得 OceanBase 还不错的话就关注一下吧!
