

目录
- H2数据库入门以及实际开发时的使用
-
- 1. H2数据库的初识
-
- 1.1 H2数据库介绍
- 1.2 为什么要使用嵌入式数据库?
- 1.3 嵌入式数据库对比
-
- 1.3.1 性能对比
- 1.4 技术选型思考
- 2. H2数据库实战
-
- 2.1 H2数据库下载搭建以及部署
-
- 2.1.1 H2数据库的下载
- 2.1.2 数据库启动
-
- 2.1.2.1 windows系统可以在bin目录下执行h2.bat
- 2.1.2.2 同理可以通过cmd直接使用命令进行启动:
- 2.1.2.3 启动后控制台页面:
- 2.1.3 spring整合H2数据库
-
- 2.1.3.1 引入依赖文件
- 2.1.4 数据库通过file模式实际保存数据的位置
- 2.2 H2数据库操作
-
- 2.2.1 Mysql兼容模式
- 2.2.2 Mysql模式的使用
- 2.3 H2数据库URL详细配置以及使用
- 3. H2数据库开发使用时注意问题和细节
-
- 3.1 逆向工程细节和踩过的坑
-
- 3.1.1 mybatis-plus-generator
- 3.1.2 使用H2原生提供的数据库初始化方法
- 4. 总结
H2数据库入门以及实际开发时的使用
注意:可以直接移步至【2. H2数据库实战】目录下进行对H2数据库的快速使用
1. H2数据库的初识
1.1 H2数据库介绍
官方文档地址:http://www.h2database.com/html/main.html
H2的开发始于2004年5月, 但它在2005年12月14日首次发表。 H2的原作者Thomas Mueller也是Hypersonic SQL的原始开发者。 2001年,他加入PointBase公司。在那里他编写了商业JavaSQL数据库PointBaseMicro。 在这一点上,他不得不停止Hypersonic SQL。HSQLDB集团成立 继续从事Hypersonic SQL代码库的工作。 名称H2代表Hypersonic 2号,但H2不与Hypersonic SQL或HSQLDB共享代码 。H2是从头开始构建的。
原作者Thomas Mueller在StackOverFlow主页:https://stackoverflow.com/users/382763/thomas-mueller
1.2 为什么要使用嵌入式数据库?
在小型的应用程序中,例如小型掌上游戏机,不适合部署高达几百兆的数据库服务器,同时也没有联网的必要,一种轻量级的数据库需求由此诞生!
与常见的数据库相比,嵌入式数据库具有体积小、功能齐备、可移植性、健壮性等特点,例如我们所熟知的 SVN 版本控制软件就使用到了 SQLite 作为内置数据库,SQLite 的安装包只有不到 350 KB,在微型机中也有着广泛的应用,例如安卓、IOS 等移动设备操作系统都内置了 SQLite 数据库!
鉴于嵌入式数据库的种类比较多,有商业收费的、也有开源免费的!本文主要介绍开源免费版的,例如 Derby、SQLite、H2、Berkeley DB 、HSQLDB 等,本文主要介绍H2数据库的应用,下面就一起来看看吧!
1.3 嵌入式数据库对比
1.3.1 性能对比
在许多情况下,H2比其他(开源和非开源)数据库引擎更快。请注意,这主要是在一台计算机上运行的单个连接基准测试,其中有许多非常简单的针对数据库的操作。此基准测试不包括非常复杂的查询。H2的嵌入式模式比客户端-服务器模式更快,因为每个语句的开销大大减少。
援引官方文档做出的性能测试报告和可能性分析:
Embedded:
| Test Case | Unit | H2 | HSQLDB | Derby |
|---|---|---|---|---|
| Simple: Init | ms | 1021 | 2510 | 6762 |
| Simple: Query (random) | ms | 513 | 653 | 2035 |
| Simple: Query (sequential) | ms | 1344 | 2210 | 7665 |
| Simple: Update (sequential) | ms | 1642 | 3040 | 7034 |
| Simple: Delete (sequential) | ms | 1697 | 2310 | 9981 |
| Simple: Memory Usage | MB | 18 | 15 | 13 |
| BenchA: Init | ms | 801 | 2877 | 6576 |
| BenchA: Transactions | ms | 1369 | 2629 | 4987 |
| BenchA: Memory Usage | MB | 12 | 15 | 9 |
| BenchB: Init | ms | 966 | 2544 | 7161 |
| BenchB: Transactions | ms | 341 | 2316 | 815 |
| BenchB: Memory Usage | MB | 14 | 10 | 10 |
| BenchC: Init | ms | 2630 | 3144 | 7420 |
| BenchC: Transactions | ms | 1732 | 1742 | 2735 |
| BenchC: Memory Usage | MB | 19 | 34 | 11 |
| Executed statements | # | 2222032 | 2222032 | 2222032 |
| Total time | ms | 14056 | 25975 | 63171 |
| Statements per second | #/s | 158084 | 85545 | 35174 |
Client-Server
| Test Case | Unit | H2 | HSQLDB | Derby | PostgreSQL | MySQL |
|---|---|---|---|---|---|---|
| Simple: Init | ms | 27989 | 48055 | 47142 | 32972 | 109482 |
| Simple: Query (random) | ms | 4821 | 5984 | 14741 | 4089 | 15140 |
| Simple: Query (sequential) | ms | 33656 | 49112 | 95999 | 35676 | 143536 |
| Simple: Update (sequential) | ms | 9878 | 23565 | 31418 | 26113 | 50676 |
| Simple: Delete (sequential) | ms | 13056 | 28584 | 43955 | 20985 | 64647 |
| Simple: Memory Usage | MB | 18 | 15 | 15 | 2 | 4 |
| BenchA: Init | ms | 20993 | 42525 | 38335 | 27794 | 107723 |
| BenchA: Transactions | ms | 16549 | 29255 | 28995 | 23113 | 65036 |
| BenchA: Memory Usage | MB | 12 | 18 | 11 | 1 | 4 |
| BenchB: Init | ms | 26785 | 48772 | 39756 | 32369 | 115398 |
| BenchB: Transactions | ms | 898 | 10046 | 1916 | 818 | 1794 |
| BenchB: Memory Usage | MB | 16 | 11 | 12 | 2 | 5 |
| BenchC: Init | ms | 18266 | 26865 | 39325 | 24547 | 70531 |
| BenchC: Transactions | ms | 6569 | 7783 | 9412 | 8916 | 19150 |
| BenchC: Memory Usage | MB | 17 | 35 | 13 | 2 | 7 |
| Executed statements | # | 2222032 | 2222032 | 2222032 | 2222032 | 2222032 |
| Total time | ms | 179460 | 320546 | 390994 | 237392 | 763113 |
| Statements per second | #/s | 12381 | 6932 | 5683 | 9360 | 2911 |
H2
Version 2.0.202 (2021-11-25) was used for the test. For most operations, the performance of H2 is about the same as for HSQLDB. One situation where H2 is slow is large result sets, because they are buffered to disk if more than a certain number of records are returned. The advantage of buffering is: there is no limit on the result set size.
测试使用了版本2.0.202(2021年11月25日)。对于大多数操作,H2的性能与HSQLDB大致相同。H2比较慢的一种情况是结果集比较大,因为如果返回的记录超过一定数量,结果集就会被缓冲到磁盘。缓冲的优点是:对结果集大小没有限制。
HSQLDB
Version 2.5.1 was used for the test. Cached tables are used in this test (hsqldb.default_table_type=cached), and the write delay is 1 second (SET WRITE_DELAY 1).
测试使用了版本2.5.1。此测试中使用缓存表(hsqldb.default_table_type=cached),写入延迟为1秒(SET WRITE_DELAY 1)。
Derby
Version 10.14.2.0 was used for the test. Derby is clearly the slowest embedded database in this test. This seems to be a structural problem, because all operations are really slow. It will be hard for the developers of Derby to improve the performance to a reasonable level. A few problems have been identified: leaving autocommit on is a problem for Derby. If it is switched off during the whole test, the results are about 20% better for Derby. Derby calls FileChannel.force(false), but only twice per log file (not on each commit). Disabling this call improves performance for Derby by about 2%. Unlike H2, Derby does not call FileDescriptor.sync() on each checkpoint. Derby supports a testing mode (system property derby.system.durability=test) where durability is disabled. According to the documentation, this setting should be used for testing only, as the database may not recover after a crash. Enabling this setting improves performance by a factor of 2.6 (embedded mode) or 1.4 (server mode). Even if enabled, Derby is still less than half as fast as H2 in default mode.
版本10.14.2.0用于测试。Derby显然是这个测试中最慢的嵌入式数据库。这似乎是一个结构性的问题,因为所有的操作都很慢。Derby的开发人员将很难将性能提高到合理的水平。已经查明了一些问题:保持自动提交是Derby的一个问题。如果在整个测试过程中关闭它,结果对德比来说要好20%左右。Derby调用FileChannel.force(false),但每个日志文件只调用两次(而不是在每次提交时)。禁用此调用可以将Derby的性能提高大约2%。与H2不同,Derby不在每个检查点调用FileDescriptor.sync()。Derby支持禁用耐久性的测试模式(系统属性derby.system.durability=test)。根据文档,此设置应仅用于测试,因为数据库在崩溃后可能无法恢复。启用此设置可将性能提高2.6倍(嵌入式模式)或1.4倍(服务器模式)。即使启用,Derby在默认模式下的速度仍不到H2的一半。
PostgreSQL
Version 13.4 was used for the test. The following options where changed in postgresql.conf: fsync = off, commit_delay = 100000 (microseconds). PostgreSQL is run in server mode. The memory usage number is incorrect, because only the memory usage of the JDBC driver is measured.
测试使用了版本13.4。postgresql.conf中更改了以下选项:fsync =关闭,提交延迟= 100000(微秒)。PostgreSQL在服务器模式下运行。内存使用数量不正确,因为只测量JDBC驱动程序的内存使用。
MySQL
Version 8.0.27 was used for the test. MySQL was run with the InnoDB backend. The setting innodb_flush_log_at_trx_commit and sync_binlogcode> (found in the my.ini / community-mysql-server.cnf file) was set to 0. Otherwise (and by default), MySQL is slow (around 140 statements per second in this test) because it tries to flush the data to disk for each commit. For small transactions (when autocommit is on) this is really slow. But many use cases use small or relatively small transactions. Too bad this setting is not listed in the configuration wizard, and it always overwritten when using the wizard. You need to change those settings manually in the file my.ini / community-mysql-server.cnf, and then restart the service. The memory usage number is incorrect, because only the memory usage of the JDBC driver is measured.
测试使用了版本8.0.27。MySQL与InnoDB后端一起运行。设置innodb_flush_log_at_trx_commit和sync_binlogcode〉(可在my.ini/community-mysql-server. cnf文件中找到)被设置为0。否则(默认情况下),MySQL会很慢(在本测试中大约每秒140条语句),因为它尝试在每次提交时将数据刷新到磁盘。对于小事务(当自动提交打开时),这确实很慢。但许多用例使用的是小型或相对小型的事务。糟糕的是,配置向导中没有列出此设置,而且在使用向导时总是覆盖它。您需要在文件my.ini/community-mysql-server.cnf中手动更改这些设置,然后重新启动服务。内存使用数量不正确,因为只测量JDBC驱动程序的内存使用。
SQLite
SQLite 3.36.0.3, configured to use WAL and with synchronous=NORMAL was tested in a separate, less reliable run. A rough estimate is that SQLite performs approximately 2-5x worse in the simple benchmarks, which perform simple work in the database, resulting in a low work-per-transaction ratio. SQLite becomes competitive as the complexity of the database interactions increases. The results seemed to vary drastically across machine, and more reliable results should be obtained. Benchmark on your production hardware.
SQLite3.36.0.3,配置为使用WAL,并且synchronous=NORMAL,在一个单独的、不太可靠的运行中进行了测试。粗略估计,SQLite在简单基准测试中的性能要差2- 5倍,因为这些基准测试在数据库中执行简单的工作,导致每事务工作量比率较低。随着数据库交互复杂性的增加,SQLite变得越来越有竞争力。不同机器的结果似乎差异很大,应获得更可靠的结果。在您的生产硬件上进行基准测试。
The benchmarks used include multi-threaded scenarios, and we were not able to get the SQLite JDBC driver we used to work with them. Help with configuring the driver for multi-threaded usage is welcome.
使用的基准测试包括多线程场景,我们无法获得用于处理它们的SQLite JDBC驱动程序。欢迎提供有关配置驱动程序以用于多线程的帮助。
Firebird
Firebird 3.0 (default installation) was tested, but failed on multi-threaded part of the test. It is likely possible to run the performance test with the Firebird database, and any information on how to configure Firebird for this are welcome.
测试了Firebird 3.0(默认安装),但在测试的多线程部分失败。很可能可以使用Firebird数据库运行性能测试,欢迎提供有关如何为此配置Firebird的任何信息。
Why Oracle / MS SQL Server / DB2 are Not Listed
The license of these databases does not allow to publish benchmark results. This doesn’t mean that they are fast. They are in fact quite slow, and need a lot of memory. But you will need to test this yourself.
这些数据库的许可证不允许发布基准测试结果。但这并不意味着他们的速度很快。它们实际上相当慢,并且需要大量内存。但你需要自己测试一下。
1.4 技术选型思考
从官网测试性能分析中可以发现,基于java的嵌入式数据库针对于内存来说总体H2数据库速度较快,运行效率较高。其中复杂数据库交互复杂度上升,可以进行考虑SQLite。H2针对于轻量化,和小数据的保存和查询比其他数据库有一定优势。详情见【1.3.1 性能对比 】
2. H2数据库实战
2.1 H2数据库下载搭建以及部署
2.1.1 H2数据库的下载
数据库下载:http://www.h2database.com/html/download.html
h2
|—bin
| |—h2-2.1.214.jar //H2数据库的jar包(驱动也在里面)
| |—h2.bat //Windows控制台启动脚本
| |—h2.sh //Linux控制台启动脚本
| |—h2w.bat //Windows控制台启动脚本(不带黑屏窗口)
|—docs //H2数据库的帮助文档(内有H2数据库的使用手册)
|—service //通过wrapper包装成服务
|—src //H2数据库的源代码
|—build.bat //windows构建脚本
|—build.sh //linux构建脚本
2.1.2 数据库启动
注意: 在file模式下只支持一个进程连接,如果有多个进程需要连接同一个url可以用Automatic Mixed Mode模式,关键字AUTO_SERVER=TRUE进行处理通过AUTO_SERVER_PORT=9090进行指定端口。当然此方法不适用于内存数据库即:jdbc:h2:mem:test_mem此类连接模式。
2.1.2.1 windows系统可以在bin目录下执行h2.bat

上图为执行的批处理文件详情
2.1.2.2 同理可以通过cmd直接使用命令进行启动:
启动命令:
java -cp h2-2.1.214.jar org.h2.tools.Server
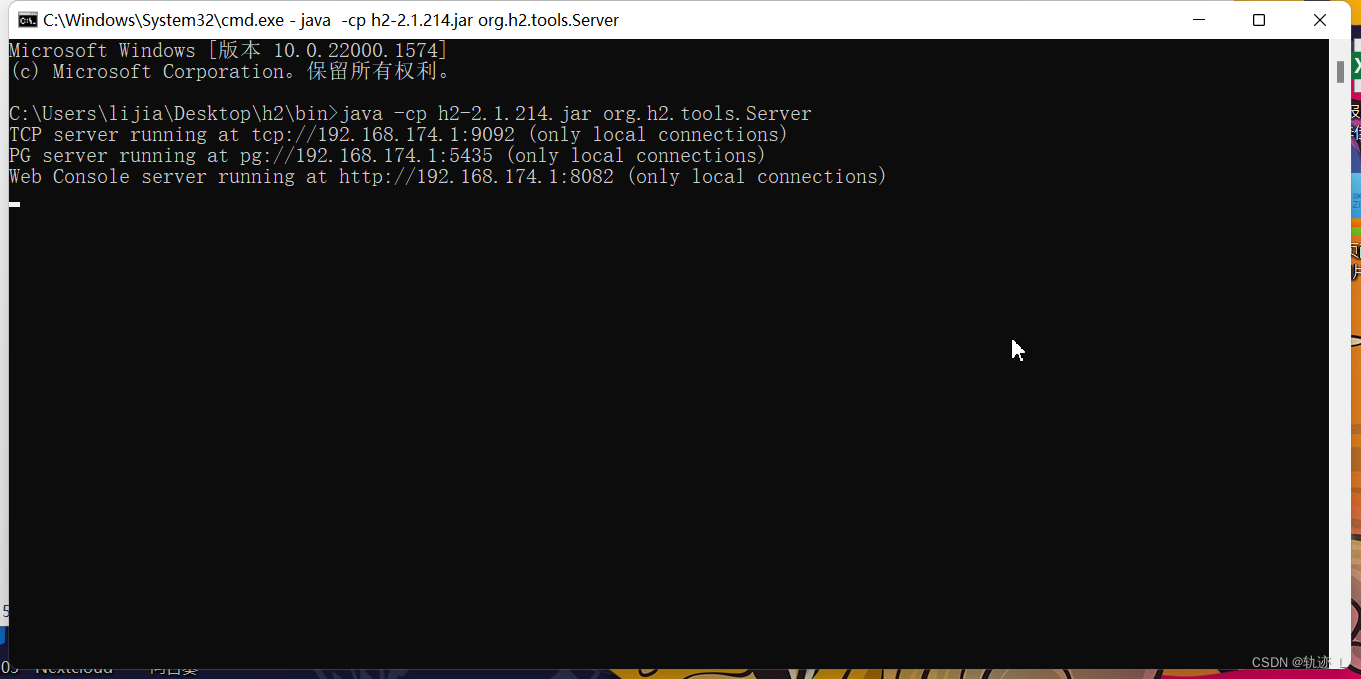
2.1.2.3 启动后控制台页面:
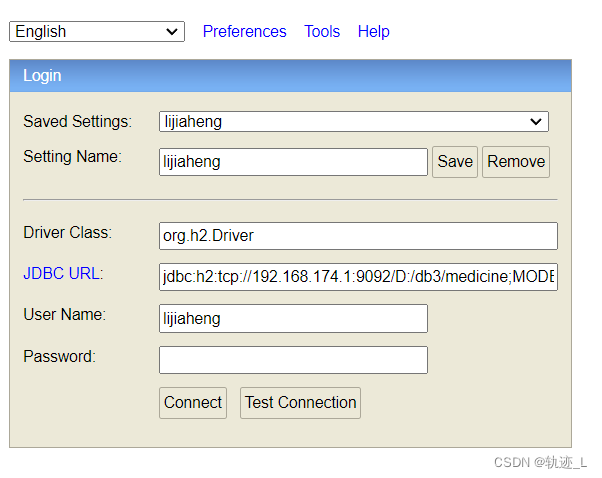
注意: 第一次登陆可以用sa进行,密码可以不填。使用其他用户名登陆会自动创建用户,如果指定密码则下次登陆需要输入指定后的密码。
登陆后可以点击快速创建数据库脚本进行demo:
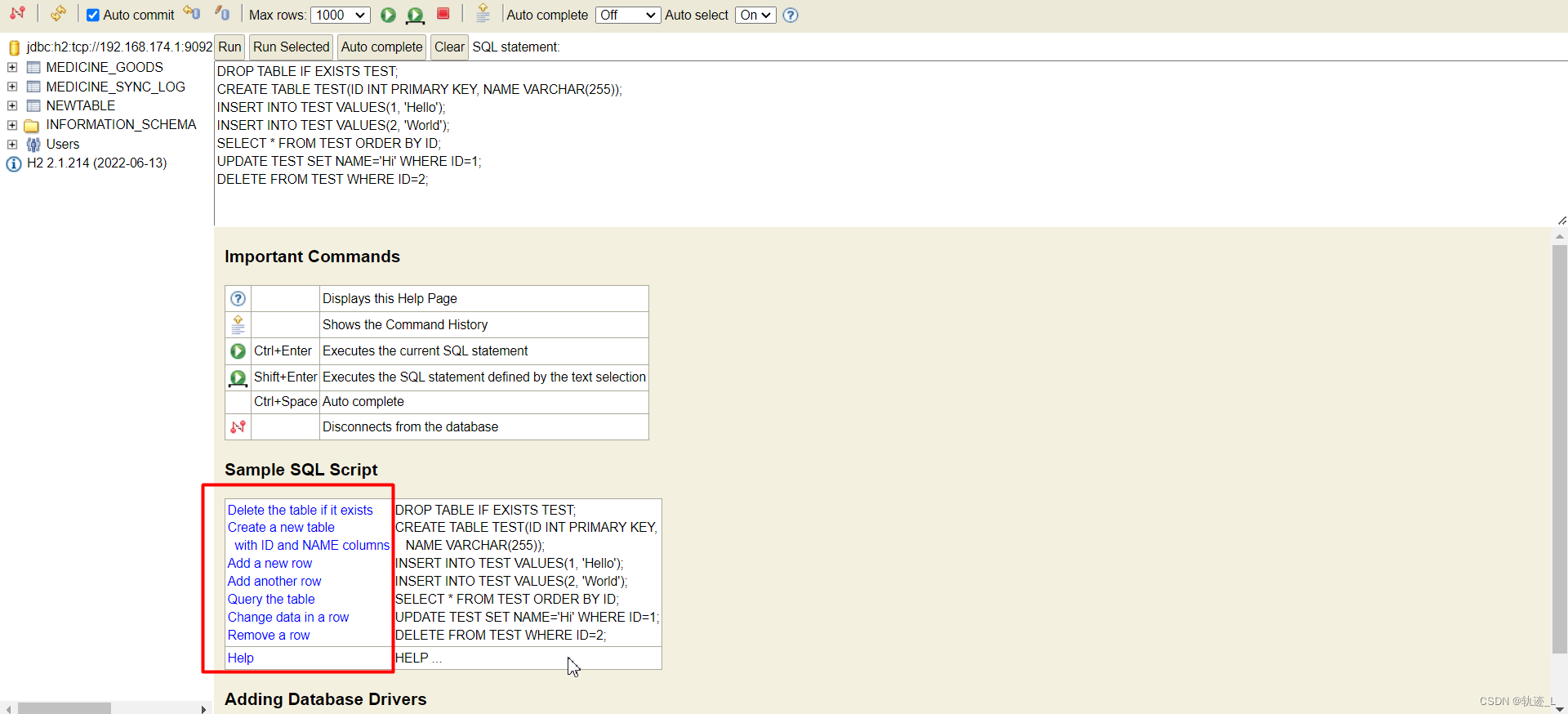
2.1.3 spring整合H2数据库
2.1.3.1 引入依赖文件
dependency>
groupId>com.h2databasegroupId>
artifactId>h2artifactId>
version>1.4.200version>
scope>runtimescope>
dependency>
对应yml文件如下:
server:
port: 8081
servlet:
context-path: /test
spring:
datasource:
#tcp配置
# url: jdbc:h2:tcp://127.0.0.1:9092/D:/db/medicine;MODE=MYSQL
# CASE_INSENSITIVE_IDENTIFIERS=TRUE;不进行区分大小写配置,可以看数据库需要选择配置
url: jdbc:h2:file:./db/medicine;MODE=MYSQL;
driver-class-name: org.h2.Driver
username: lijiaheng
password: 123123
schema: classpath:databaseCreation
h2:
console:
# 开启web控制台
enabled: true
# 访问路径url+/h2
path: /h2
settings:
web-allow-others: true
# mybatis-plus 配置
mybatis-plus:
mapper-locations: classpath*:/mapper/*.xml
#实体扫描,多个package用逗号或者分号分隔
typeAliasesPackage: com.test.eida.model
global-config:
#数据库相关配置
db-config:
#主键类型 AUTO:"数据库ID自增", INPUT:"用户输入ID", ID_WORKER:"全局唯一ID (数字类型唯一ID)", UUID:"全局唯一ID UUID";
id-type: AUTO
#字段策略 IGNORED:"忽略判断",NOT_NULL:"非 NULL 判断"),NOT_EMPTY:"非空判断"
field-strategy: NOT_NULL
#驼峰下划线转换
column-underline: false
logic-delete-value: -1
logic-not-delete-value: 0
banner: false
2.1.4 数据库通过file模式实际保存数据的位置
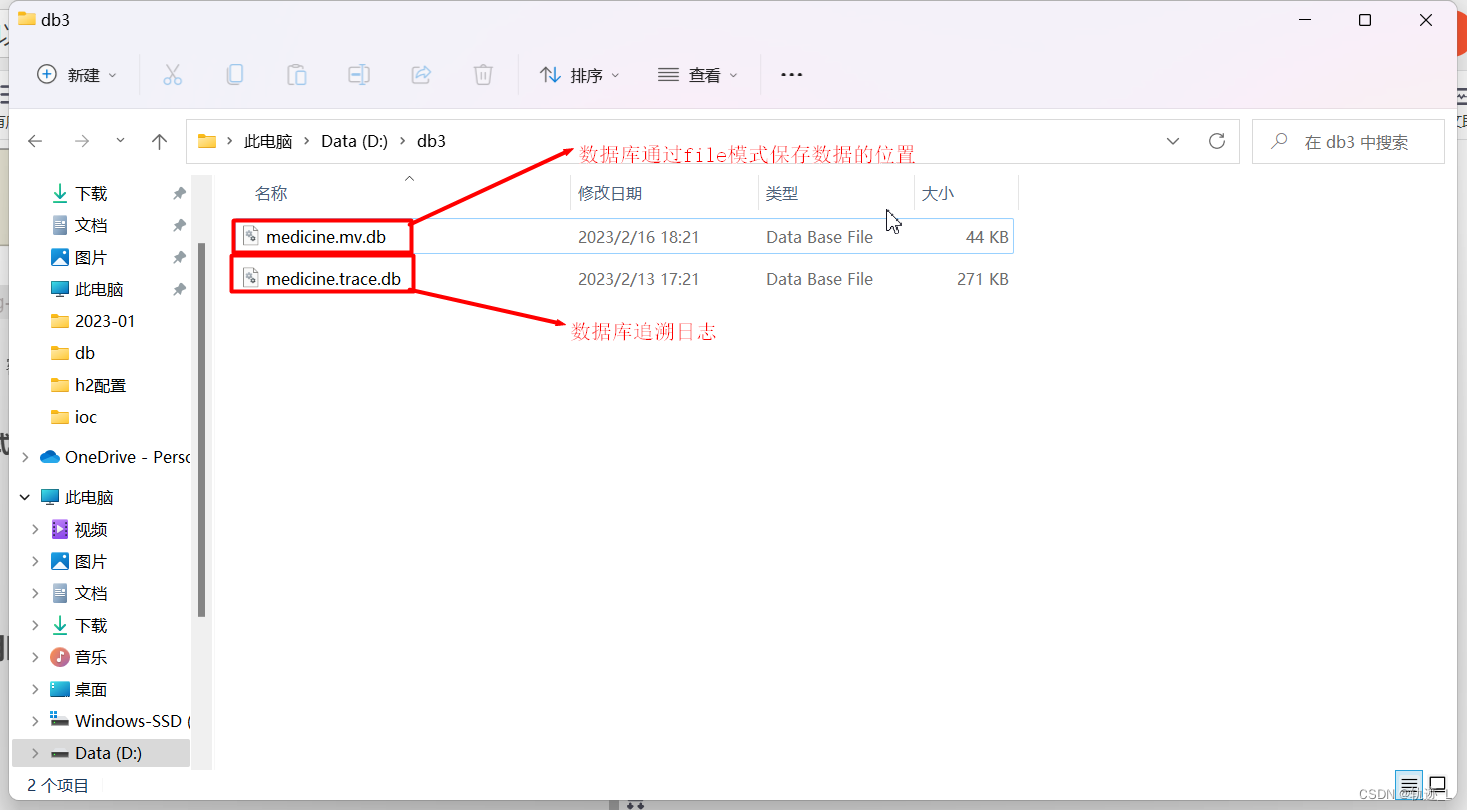
1.在指定本地路径后即可在当前指定的目录下构建medicine.mv.db文件,进行数据的保存。
2.medicine.trace.db此文件打开后可以看到通过file模式执行的sql信息和错误日志。
3.下文会详细介绍H2的配置
2.2 H2数据库操作
2.2.1 Mysql兼容模式
当需要不区分大小写的标识符时,将CASE_INSENSITIVE_IDENTIFIERS = TRUE附加到URL,创建数据库后不要更改DATABASE_TO_LOWER的值
示例:
jdbc:h2:~/test;MODE=MySQL;DATABASE_TO_LOWER=TRUE
- Creating indexes in the CREATE TABLE statement is allowed using
INDEX(…) or KEY(…). 创建表时允许使用 INDEX(…)或者 KEY(…)创建索引或者唯一键。create table test(id int primary key, name varchar(255), key idx_name(name)); - 将浮点数转换为整数时,小数 数字不被截断,但值被舍入。
- ON DUPLICATE KEY UPDATE在INSERT语句中是受支持的。
- INSERT IGNORE 部分支持,如果未指定 ON DUPLICATE KEY UPDATE,则可用于跳过具有重复键的行。
- 从CHAR值的右侧删除空格。
- REGEXP_REPLACE()使用进行反向引用。
- 日期时间值函数在命令中返回相同的值。0x文字被分析为二进制字符串文字。
- DISTINCT查询的ORDER BY子句中允许使用不相关的表达式。
- 部分支持某些特定于MySQL的ALTER TABLE命令。
- TRUNCATE TABLE重新启动生成列的下一个值。
- 如果手动指定标识列的值,则其序列将更新为在以下时间之后生成值插入。
- NULL值的工作原理与DEFAULT值一样,都是对标识列的赋值。
- 引用约束不需要被引用列上的现有主键或唯一约束 并且如果这样的约束不存在则自动创建唯一约束。
- 支持LIMIT / OFFSET子句。
- 可以使用AUTO_INCREMENT子句。
- YEAR数据类型被视为SMALLINT数据类型。
- GROUP BY子句可以包含SELECT列表中表达式的从1开始的位置。
- 允许在数值和布尔值之间使用不安全的比较运算符。
- 默认情况下,MySQL中的文本比较不区分大小写,而H2中的文本比较区分大小写(与大多数其他数据库一样)。 H2确实支持不区分大小写的文本比较,但需要单独设置,使用设置忽略实例SET IGNORECASE TRUE 。这会影响使用=、LIKE、REGEXP进行的比较。
2.2.2 Mysql模式的使用
sql示例:
CREATE TABLE IF NOT EXISTS medicine_goods
(
id bigint auto_increment PRIMARY KEY COMMENT '主键',
GoodsName VARCHAR(100) DEFAULT NULL COMMENT '商品名称',
GoodsID VARCHAR(100) not NULL COMMENT '商品编码',
UNIQUE KEY UNIQUE_KEY_GOODSID (GoodsID)
);
COMMENT ON TABLE PUBLIC.MEDICINE_GOODS IS '药品表';
注意: 由于对于alter table支持的不够完善,建议创建时进行多次实验。
配置可以通过mybatis-plus进行相关开发。当然由于部分H2数据库语法mybatis-plus未能很好的适配映射,因此更推荐直接在xml中写相对复杂的sql语句。
2.3 H2数据库URL详细配置以及使用
| Topic | URL Format and Examples |
|---|---|
Embedded (local) connection 嵌入式本地连接 |
jdbc:h2:[file:][
] jdbc:h2:~/test jdbc:h2:file:/data/sample jdbc:h2:file:C:/data/sample (Windows only) |
In-memory (private) 内存连接方式 |
jdbc:h2:mem: |
In-memory (named) 内存连接方式(已命名) |
jdbc:h2:mem: jdbc:h2:mem:test_mem |
Server mode (remote connections) using TCP/IP 使用TCP/IP进行远程连接 |
jdbc:h2:tcp://[:]/[
] jdbc:h2:tcp://localhost/~/test jdbc:h2:tcp://dbserv:8084/~/sample jdbc:h2:tcp://localhost/mem:test |
Server mode (remote connections) using TLS 使用TLS远程加密连接 |
jdbc:h2:ssl://[:]/[
] jdbc:h2:ssl://localhost:8085/~/sample; |
Using encrypted files 使用加密文件 |
jdbc:h2:;CIPHER=AES jdbc:h2:ssl://localhost/~/test;CIPHER=AES jdbc:h2:file:~/secure;CIPHER=AES |
File locking methods 文件锁定 |
jdbc:h2:;FILE_LOCK={FILE|SOCKET|FS|NO} jdbc:h2:file:~/private;CIPHER=AES;FILE_LOCK=SOCKET |
Only open if it already exists 仅在存在时打开 |
jdbc:h2:;IFEXISTS=TRUE jdbc:h2:file:~/sample;IFEXISTS=TRUE |
Don’t close the database when the VM exits VM退出时不关闭数据库 |
jdbc:h2:;DB_CLOSE_ON_EXIT=FALSE |
Execute SQL on connection 连接时执行SQL |
jdbc:h2:;INIT=RUNSCRIPT FROM ‘~/create.sql’ jdbc:h2:file:~/sample;INIT=RUNSCRIPT FROM ‘~/create.sql’;RUNSCRIPT FROM ‘~/populate.sql’ |
User name and/or password 使用用户名或密码通过url登陆数据库 |
jdbc:h2:[;USER=][;PASSWORD=] jdbc:h2:file:~/sample;USER=sa;PASSWORD=123 |
Debug trace settings 调试跟踪 |
jdbc:h2:;TRACE_LEVEL_FILE= jdbc:h2:file:~/sample;TRACE_LEVEL_FILE=3 |
Ignore unknown settings 忽略未知设置 |
jdbc:h2:;IGNORE_UNKNOWN_SETTINGS=TRUE |
Custom file access mode 自定义文件访问模式 |
jdbc:h2:;ACCESS_MODE_DATA=rws |
Database in a zip file 压缩文件中的数据库 |
jdbc:h2:zip:!/ jdbc:h2:zip:~/db.zip!/test |
Compatibility mode 兼容模式 |
jdbc:h2:;MODE= jdbc:h2:~/test;MODE=MYSQL;DATABASE_TO_LOWER=TRUE |
Auto-reconnect 自动重新连接 |
jdbc:h2:;AUTO_RECONNECT=TRUE jdbc:h2:tcp://localhost/~/test;AUTO_RECONNECT=TRUE |
Automatic mixed mode 自动混合模式 |
jdbc:h2:;AUTO_SERVER=TRUE jdbc:h2:~/test;AUTO_SERVER=TRUE |
Page size 页面大小 |
jdbc:h2:;PAGE_SIZE=512 |
Changing other settings 更改其他设置 |
jdbc:h2:;=[;=…] jdbc:h2:file:~/sample;TRACE_LEVEL_SYSTEM_OUT=3 |
以上均可通过连接在官方文档中定位相关模式详情,在此不再一一赘述。
3. H2数据库开发使用时注意问题和细节
3.1 逆向工程细节和踩过的坑
3.1.1 mybatis-plus-generator
如果使用mybatis-plus-generator建议使用最新版本,3.4.0版本会因为执行唯一主键sql找不到对应表的Extra(mysql中有)字段,因此会生成不出来对应实体类属性,在拉取最新版本后可以看到查询语句已经修改。
3.4.0逆向工程代码H2查询主键sql:
select * from INFORMATION_SCHEMA.INDEXES WHERE TABLE_NAME = '%s'
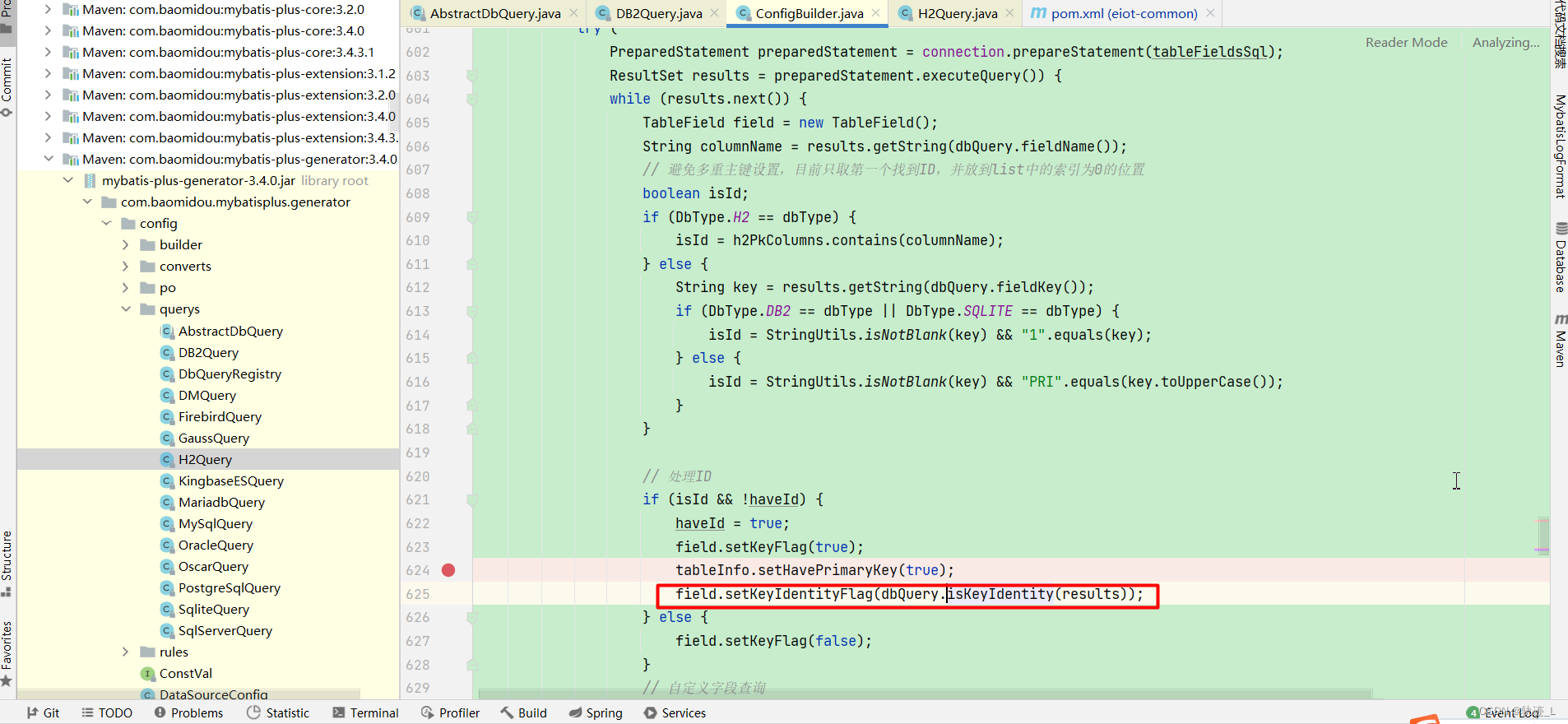
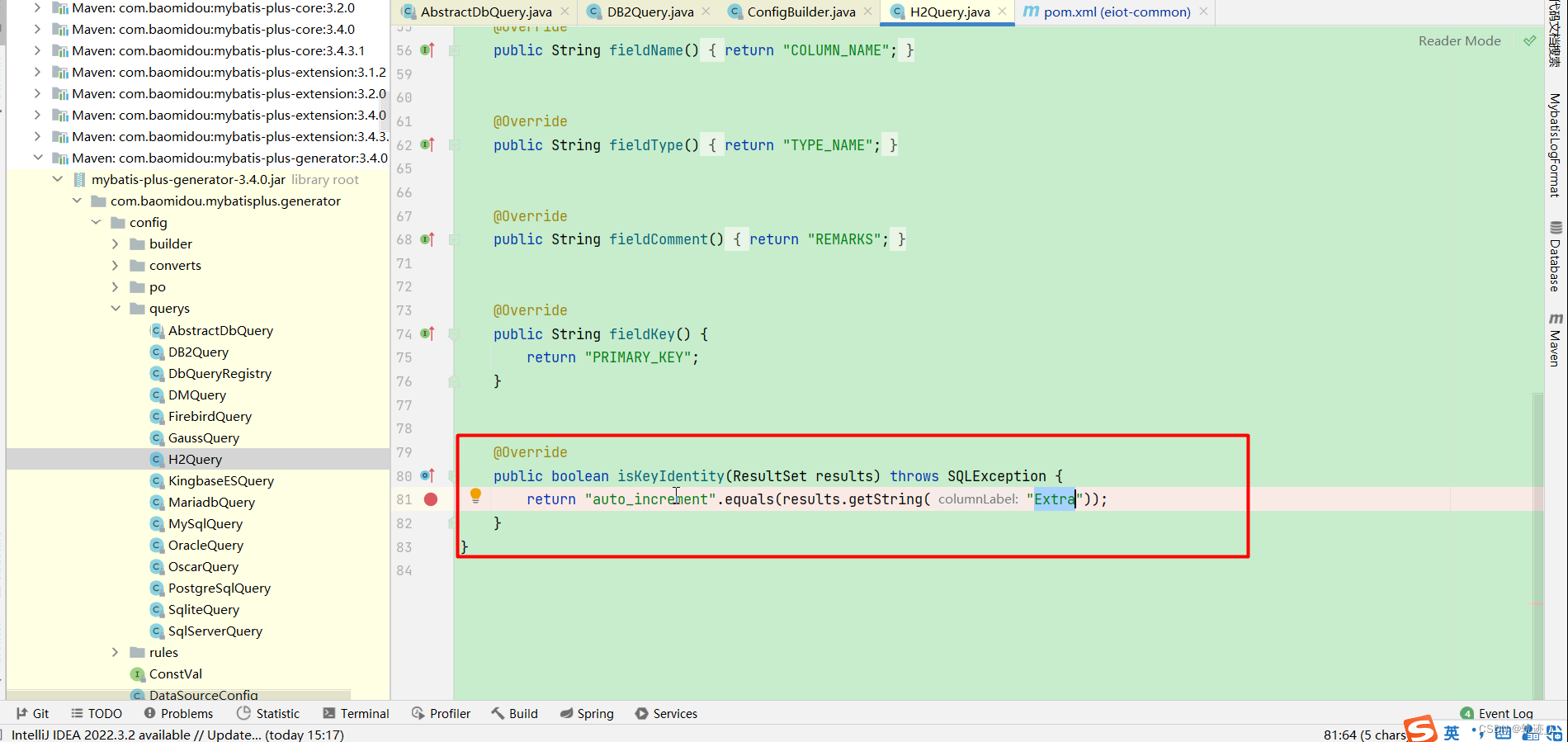
如果不用最新的直接修改把查询类H2Query中方法isKeyIdentity修改直接返回true即可解决问题,因为通过PRIMARY_KEY已经可以找到对应主键。
3.1.2 使用H2原生提供的数据库初始化方法
Execute SQL on connection 连接时执行SQL
jdbc:h2:;INIT=RUNSCRIPT FROM ‘~/create.sql’
jdbc:h2:file:~/sample;INIT=RUNSCRIPT FROM ‘~/create.sql’;RUNSCRIPT FROM ‘~/populate.sql’
在实际使用中放置于classpath目录下总是识别不到,无论配置相对路径和绝对路径都无法识别,包括修改最新的H2版本。通过搜索该问题
https://stackoverflow.com/questions/4490138/problem-with-init-runscript-and-relative-paths?noredirect=1&lq=1
发现原作者Thomas Mueller也未能复现,并且此问题未被解决,因此通过spring的扫描进行处理了数据脚本初始化的问题。
spring:
datasource:
#tcp配置
# url: jdbc:h2:tcp://127.0.0.1:9092/D:/db/medicine;MODE=MYSQL
# CASE_INSENSITIVE_IDENTIFIERS=TRUE;不进行区分大小写配置,可以看数据库需要选择配置
url: jdbc:h2:file:./db/medicine;MODE=MYSQL;
driver-class-name: org.h2.Driver
username: lijiaheng
password: 123123
schema: classpath:databaseCreation
4. 总结
在使用H2数据库过程中,发现有部分语法虽然兼容了Mysql但还有些不太一样,例如在创建唯一键的时候,或者使用alter table 时部分语法不支持,因此在使用过程中应当多进行实验,可以通过官网找到错误语法标签查看并进行修改。
当然还有很多的坑因为业务的简单未遇到,但是总的来说通过stackoverflow基本能解决大部分问题。在国内H2数据并不是大众化的数据,因此生态会差一些,这也是我想写这篇文章的初衷。
以上就是H2数据库配置及相关使用方式一站式介绍,欢迎大家多多点赞,收藏,分享~
