


在大数据时代,如何有效地管理和处理海量数据成为了企业面临的核心挑战。为此,拓数派推出了首款数据计算引擎 PieCloudDB Database,作为一款全新的云原生虚拟数仓,旨在提供更高效、更灵活的数据处理解决方案。
PieCloudDB 的设计理念源于对用户使用体验和查询效率的深度理解。在实现存算分离的同时,PieCloudDB 专门设计和打造了全新的存储引擎「简墨」等模块。针对云场景和分析型场景,PieCloudDB 还设计了高效的预聚集(Pre-Aggregate)特性。本文将详细介绍 PieCloudDB 如何运用预聚集技术优化数据处理流程,改善用户体验。
作为云原生虚拟数仓,PieCloudDB 充分借助云计算所提供的基础设施服务,包括大规模分布式集群、虚拟机、容器等。这些特性使得 PieCloudDB 能更好地适应动态的和不断变化的工作负载需求。同时,PieCloudDB 也积极拓展其自身的特性,实现高可用、易扩展和弹性伸缩,以满足企业不断增长的业务需求。
PieCloudDB 实现了一个重要创新功能:预聚集(Pre-Aggregate)。 该功能通过 PieCloudDB 的全新的存储引擎「简墨」(JANM),在数据插入时即时计算数据列的 Aggregate 信息,并将其预先保存以供后续使用。这种方法摒弃了在查询时进行复杂计算的传统方式,从而大大提升了查询速度。此外,由于聚合数据保存在文件中,可以实现快速访问并直接应用于查询。
PieCloudDB 会根据用户的查询自动生成带有 Pre-Aggregate 的计划,使得查询过程尽可能地快速且准确。 当需要聚合数据时,系统会检查预存储的聚合值,并直接读取符合条件的 Aggregate 数据。这样避免了查询过程中扫描整个数据集的需求,可以大幅提升查询速度。
对于部分满足条件的块,PieCloudDB 将会回归原来的处理方式计算 Aggregate 值。 这样既能利用已经预聚合的数据,又只需计算缺少的部分,从而降低计算成本并提高运算效率。
1 预聚集的原理
为了能够增加 Aggregate 的查询性能,PieCloudDB 采用了以「空间」换取「时间」的策略,在写入数据的时候,在存储层中将相关的 Aggregate 进行预先计算并保存,从而在查询的时候可以快速找到需要的 Aggregate 数据。
上面解决了 Aggregate 数据来源问题,下面将介绍如何拿到预先计算的 Aggregate 数据。为了能够实现正确获取下推的 Aggregate 数据,PieCloudDB 的优化器与执行器被进一步改造,增加了两个新的 Pre-Aggregate 计算节点。改造前后的计划树(plan tree) 的对比如下图所示:
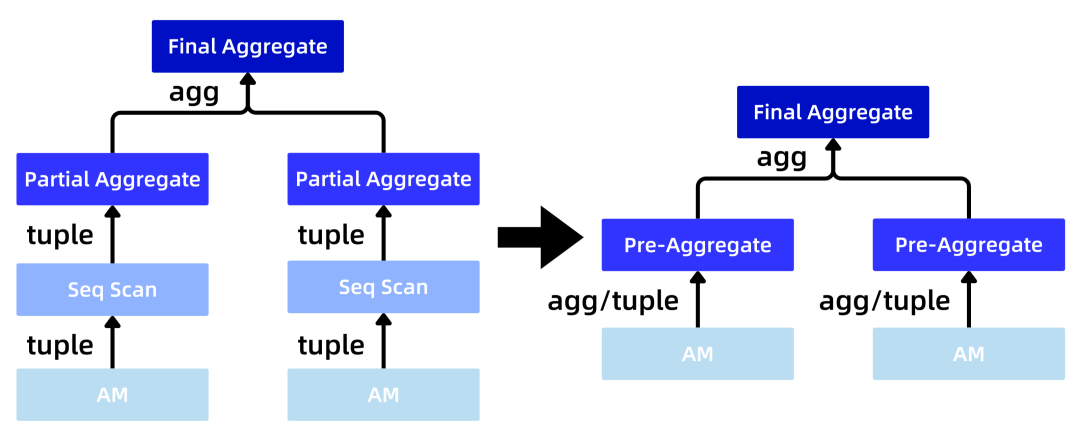
改造前后 plan tree 对比图
存储引擎「简墨」会在数据插入时,即时更新 Aggregate 信息。在上图中的 Pre-Aggregate 计算节点会从 AM(access method)中取出预先计算的 Aggregate 数据,如果没有找到合适的 Aggregate 数据,Pre-Aggregate 计算节点也会从 AM 中找出满足条件的 tuple 计算出对应的 Aggregate 数据,返回给上层计算节点使用。这样就解决了怎么正确找到下推的 Aggregate 数据的问题。
Pre-Aggregate 是 OLAP 优化技术中 Zone Maps 的具体实现。即预先计算一批元组属性值的聚合并预先保存,数据库检查预计算的聚集信息决定是否要访问该 block。即上面所述的如果找到可用的 Aggregate 数据则直接返回,否则访问该 block 检索具体元组。
对于带条件的 Pre-Aggregate 来说,其效果取决于预先计算所涉及的数据范围。PieCloudDB 将预聚集范围缩小至块文件,针对每个块文件分别进行预计算存储,从而保证带条件的预聚集查询效果。
2 预聚集的使用演示
下面给出了如何开启 Preagg Block Scan 以及支持 Block Skipping 的 Preagg Bitmap Block Scan 的使用方式。最后给出了对应的性能对比图。
2.1 Preagg Block Scan 使用方式
-- 创建 t 表
create table t(a int, b int, c int);
-- 写入三行数据
insert into t values(1,2,3);
insert into t values(3,3,5);
insert into t values(4,4,6);
-- 开启 preagg,默认是开启的
set pdb_enable_preagg = on;
-- 执行如下的 query
explain (costs off) select sum(b), avg(c), count(*) from t;
QUERY PLAN
------------------------------------------------
Finalize Aggregate
-> Gather Motion 3:1 (slice1; segments: 3)
-> Pre-Aggregate Block Scan on t
Optimizer: Postgres query optimizer
(4 rows)
-- 开启后的执行结果
select sum(b), avg(c), count(*) from t;
sum | avg | count
-----+--------------------+-------
9 | 4.6666666666666667 | 3
(1 row)
-- 关闭 preagg
set pdb_enable_preagg = off;
-- 执行同一条 query
explain (costs off) select sum(b), avg(c), count(*) from t;
QUERY PLAN
------------------------------------------------
Aggregate
-> Gather Motion 3:1 (slice1; segments: 3)
-> Seq Scan on t
Optimizer: Postgres query optimizer
(4 rows)
-- 关闭后的执行结果
select sum(b), avg(c), count(*) from t;
sum | avg | count
-----+--------------------+-------
9 | 4.6666666666666667 | 3
(1 row)
2.2 Preagg Bitmap Block Scan 使用方式
create table t(a int, b int);
insert into t values(generate_series(1, 20), generate_series(100, 120));
insert into t values(generate_series(21, 60), generate_series(121, 160));
-- 开启 preagg,默认是开启的
set pdb_enable_preagg = on;
-- 下面是开启 Pre-Aggregate Bitmap Block Scan 的几个 guc
set enable_seqscan = off;
set enable_bitmapscan = on;
set enable_indexscan = on;
-- 执行如下的 query
explain (costs off) select max(a), sum(a) from t where a > 10 and a Gather Motion 3:1 (slice1; segments: 3)
-> Partial Aggregate
-> Pre-Aggregate Bitmap Block Scan on t
Recheck Cond: ((a > 10) AND (a Bitmap Index Scan on t
Index Cond: ((a > 10) AND (a 10 and a 10 and a Gather Motion 3:1 (slice1; segments: 3)
-> Partial Aggregate
-> Bitmap Heap Scan on t
Recheck Cond: ((a > 10) AND (a Bitmap Index Scan on t
Index Cond: ((a > 10) AND (a 10 and a 2.3 性能对比
测试表:
create table preaggdata (a int, b int);
测试语句:
explain analyze select sum(a), avg(a), count(*), max(b) from preaggdata;
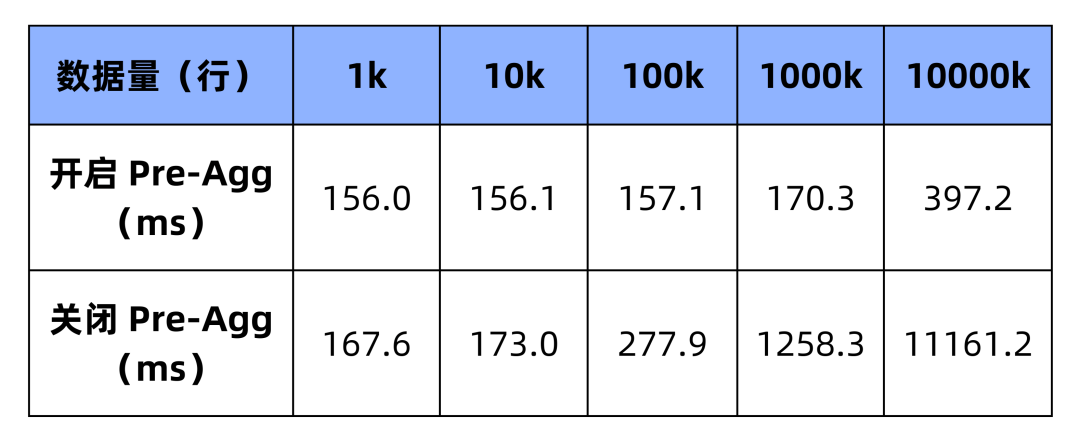
耗时对比图如下所示:
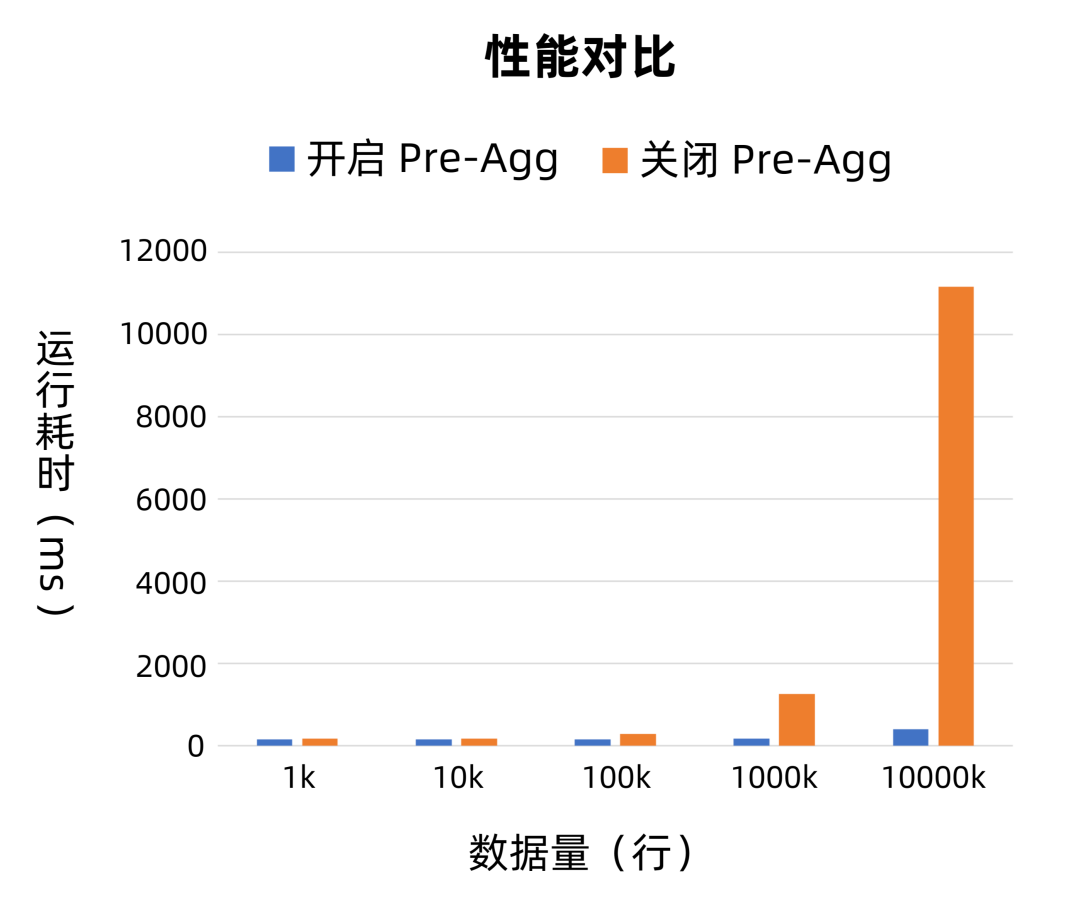
耗时对比图
从上面的测试数据和对比图可以看出,未开启 Pre-Agg 时,随着数据量的增大,耗时不断增大,且增加的速度也会越来越快;而开启 Pre-Agg 时,耗时是平稳的增长的,增长的速度也不快。当数据量达到 10000K 时,实现了近 28 倍的速度提升。
3 预聚集未来演变之路
目前, Pre-Aggregate 采用「空间」换「时间」的策略来提升性能效率。为了扩大 Pre-Aggregate 的应用范围,优化用户体验,我们将不断推动技术研发,扩大应用场景,并提供更加丰富、多元的功能。
无论是通过优化数据处理方式,拓展支持的函数类型,还是引进新的查询处理机制,我们都在锲而不舍地努力实现这一目标。相信很快,Pre-Aggregate 将能够为复杂的查询场景提供更高效、更精准的解决方案,从而逐步深化其在数据分析和处理领域的应用影响力。

