


写在前面
外键是关系型数据库中非常便利的一种功能,它通过一个或多个列为两张表建立连接,从而允许跨表交叉引用相关数据。外键通过约束来保持数据的一致性,通过级联来同步数据在多表间的更新和删除。在关系数据库系统中,大多数表都遵循外键的概念。因此使用外键可以在一定程度上减轻业务代码中对数据一致性判断的工作量。 虽然外键的功能很便利,但有很多文章探讨过是否应该在MySQL等数据库中使用外键,因为外键在保证数据的一致性和引用合法性的同时,也增加了数据库需要承担的额外计算的开销。此外,在分布式场景中,没有办法在分区表上创建外键,也额外增加了业务从单机向分布式演进时的工作量。 PolarDB-X 作为分布式数据库,提供了外键这一功能,让你可以在分布式数据库中,通过外键对跨(库)表的数据建立连接,实现等同于单机数据库外键的数据一致性保证。同时,由于在分区表上检查和维护外键约束的实现比单机数据库更为复杂,不合理的外键使用可能会导致较大的性能开销,导致系统吞吐显著下降。 因此,外键功能会作为一项长期的实验性功能,建议你在对数据进行充分验证后谨慎使用。
具体功能
如果你对外键的语法已经充分了解,那么可以选择略过这一节,或者可以简略看看,可能会有所收获。
语法
创建外键的语法涉及到几类数据:
- 外键名(可省略,外键的名字)
- 外键索引名(可省略,外键索引名默认与外键名一致)
- 外键表和列
- 外键引用方式(可省略,外键在约束和级联时的行为)
其中必须要指定的是外键引用的表和列,引用的表也被称为父表,而外键所在的表被称为子表。列表示这两张表中发生引用关系的数据所在的列。通常父表中被引用的列是它的主键,但也可以在建立索引的任意列上创建外键。
-- 创建外键
[CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name, ...)
REFERENCES tbl_name (col_name,...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
reference_option:
RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT
-- 删除外键
ALTER TABLE tbl_name DROP FOREIGN KEY CONSTRAINT_symbol;
约束
当我们使用默认的外键类型 RESTRICT 时,在插入、更新或删除时会检查数据的一致性:
- 向子表插入数据或者更新数据时,外键字段值必须为父表中已经存在的值,否则会报错。
- 更新或删除父表中有外键约束的记录时,会报错。
例如,数据库中包含 student(id, name, content) 和 class(id, student_name) 两张表,并且 student.name 和 class.student_name 之间建立了外键,在执行如下所示的操作时都会触发数据库对外键的检查:
- 向 class 表中插入数据时,检查 name 是否在 student 表中存在;
- 更新 class 表中的数据时,检查 name 是否在 student 表中存在;
- 更新 student 表中的数据时,检查 class 中是否存在引用当前记录的外键;
- 删除 student 表中的数据时,检查 class 中是否存在引用当前记录的外键;
匹配方式:
MySQL中的外键约束支持三种匹配语法,分为 MATCH SIMPLE | MATCH FULL | MATCH PARTIAL,其中默认的匹配方式是 MATCH SIMPLE,MATCH PARTIAL 尚未实现。PolarDB-X支持默认的 MATCH SIMPLE 匹配方式,并暂时不支持修改匹配方式。 那么 MATCH SIMPLE 和 MATCH FULL 这两种匹配方式的区别是什么呢,区别是在对于 null 值一致性的处理。具体例子如下:
-- 插入一行数据 (1,1)
CREATE TABLE foo ( a int, b int,
PRIMARY KEY (a,b)
);
INSERT INTO foo (a,b) VALUES (1,1);
-- 创建两个不同匹配方式的外键
CREATE TABLE bar_simple ( a int, b int,
FOREIGN KEY (a,b) REFERENCES foo (a,b) ON MATCH SIMPLE
);
CREATE TABLE bar_full ( a int, b int,
FOREIGN KEY (a,b) REFERENCES foo (a,b) ON MATCH FULL
);
-- 符合约束
INSERT INTO bar_simple (a,b) VALUES (1,1);
INSERT INTO bar_full (a,b) VALUES (1,1);
-- 符合约束
INSERT INTO bar_simple (a,b) VALUES (1,NULL);
-- 不符合约束
INSERT INTO bar_full (a,b) VALUES (1,NULL);
-- 特殊case,符合约束
INSERT INTO bar_simple (a,b) VALUES (42,NULL);
级联
级联操作的目的也是保持数据的一致性,以 CASCADE 为例:
- 更新父表字段的值,那么子表外键字段中相应的值也会同步更新。
- 删除父表字段值的记录,那么子表外键字段中相应值的记录也会同步删除。
例如,数据库中包含 student(id, name, content) 和 class(id, student_name) 两张表,并且 student.name 和 class.student_name 之间建立了外键,在执行如下所示的操作时会进行级联操作:
- 更新 student 表中的数据时,同步更新 class 中 student 有关的数据;
- 删除 student 表中的数据时,同步删除 class 中与 student 有关的数据;
级联一种有五种引用模式,具体的参数和用法如下表所示:
| 参数 | 用法 |
| ON DELETE NO ACTION / ON UPDATE NO ACTION |
默认参数; 在更新或删除父表字段时,如果字段有外键引用,则会语句会在执行更新或删除字段时失败。 |
| ON DELETE RESTRICT / ON UPDATE RESTRICT |
ON DELETE NO ACTION 和 ON UPDATE NO ACTION 的别名 |
| ON DELETE CASCADE / ON UPDATE CASCADE |
在更新或删除父表字段时,如果字段有外键引用,则会进行级联更新或删除,即引用该列的所有行将被更新或删除。 |
| ON DELETE SET NULL / ON UPDATE SET NULL |
在更新或删除父表字段时,如果字段有外键引用,则会被置为NULL,如果该列是NOT NULL,则会更新失败。 |
| ON DELETE SET DEFAULT / ON UPDATE SET DEFAULT |
暂不支持 |
开关
在某些场景下,你可以选择通过foreign_key_checks 这个参数暂时关闭外键功能,执行一些违反外键约束的操作后,再重新打开,比如先建立子表再建立父表、插入不符合外键约束条件的数据等。
分布式数据库中的外键
在分布式数据库中,外键除了基础的约束和级联功能,还会涉及到一些分布式系统中才会涉及到的特殊场景。下面几个例子会说明在哪些场景下分布式数据库中外键的行为会与单机明显不同。
下推行为
PolarDB-X分为计算层和存储层。非下推指外键的操作在计算层来处理;下推是指将外键的操作推送到存储层来处理,从而达到提前过滤数据、减少网络传输、并行计算等目的。
- 外键下推与否是由表的形态决定的,下推外键会提升性能。
- 当外键中涉及的表是分区表时,外键是不下推的,称为逻辑外键。逻辑外键会记录逻辑表之间的关系,这种关系很难同步到存储层的物理表中,拓扑需要通过计算层来计算。此外,单表与广播表之间的外键也是不下推的。
- 当表都为单表或广播表时,并且表处于同一表组(分片),外键是可下推的,称为物理外键。外键涉及的表都在同一个表组(分片)上,可以直接在存储层的物理表上建立外键。
- 外键是否下推会存储在元数据中,并且在某些特定场景下(扩缩容),会允许逻辑外键和物理外键同时存在。
分区变更
问题:PolarDB-X中,表的类型与分区方式是可以进行变化的,那么当表类型在分区表、单表、广播表之间变化时,外键的下推行为也可能同时受到影响。比如A,B表之前均为同一个分片上的单表,之间建立了外键F,是物理外键。当A表的表类型变更为分区表后,外键F必须变更为逻辑外键才能在分布式数据库中实现其功能。 方案:表类型的变更我们称为Repartition,那么需要在 Repartition 这个任务的流程中增加删除和添加外键的子任务。在Repartition中,首先在原表被删除变动之前(因为不允许删除带有外键的父表)加入删除所有关联外键的子任务,并更新所有子表状态,此外,还需要清理物理表中跟随外键建立的相关索引;然后在新表建好后加入创建所有关联外键的子任务,这样新建的外键就会按新的父子表分区状态来更新好下推或非下推行为。
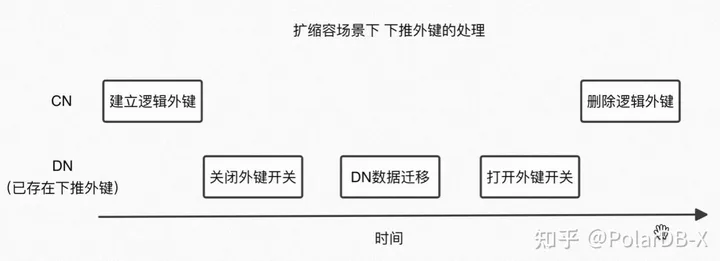
扩缩容与备份
问题:当根据业务需求对库表进行扩缩容、迁移、或进行物理/逻辑备份时,由于表的迁移是无序的,对于下推的物理外键,可能会形成先迁移子表,后迁移父表,或先迁移子表数据后迁移父表数据的情况,从而不满足外键约束,导致数据迁移失败。 方案:
- 在扩缩容前,首先在计算层上新建一份逻辑外键,然后通过 foreign_key_checks 开关关闭存储层上的外键检测。这样可以保证在扩缩容时,存储层上的外键约束不会影响数据的迁移,对于可能同时执行的级联或约束操作,会由计算上的逻辑外键来保证。
- 在扩缩容后,首先打开 foreign_key_checks 开关开启存储层上的外键检测,然后删除计算层上的冗余的逻辑外键,这样也不会在发生外键约束或级联操作时产生数据不一致的问题。
对于这个方案,还需要考虑的一个问题是 foreign_key_checks 开关的影响:
- 问题:foreign_key_checks 这个参数包含 session 和 global 两个级别,在对开启和关闭外键开关时,不能对用户其他的表/库/session产生影响。在开启和关闭 foreign_key_checks 时,怎么才能不影响到其他不在扩缩容的库表呢?
- 方案:在进行扩缩容的DDL引擎开始时,只改变DDL引擎相关任务所涉及的 session 中的 foreign_key_checks 变量,从而避免对用户 session 的影响,也不会影响其他的库表。
级联
问题:当外键涉及级联操作时,通常的想法是先去子表中查询是否存在需要级联的数据,如果存在,则构造相应的执行计划。由于需要先查询数据,再根据查询的数据决定是否进行外键的约束或级联,那么整个流程就会实现在执行器阶段,并通过查询出的数据构造物理计划,但在分布式数据库中会面临很多难以解决的问题,如:
- 当表带GSI(全局二级索引)时,级联不仅会更新主表,还会更新GSI的索引表,那么还需要手写更新索引表的物理计划。
- PolarDB-X支持 online schema change,当表状态发生变更时,比如在delete_only阶段,需要根据目标表的状态设计对应的物理计划。
- 当发生扩缩容时,需要对表的状态进行判断,并涉及到双写。
所以我们采用的方法是复用优化器的能力。
方案:在优化器中,当某个表中包含外键并且是级联操作时,会根据外键相关的信息,递归地生成所有子表中所有级联操作的AST,并交给优化器生成逻辑执行计划。这些逻辑执行计划我们称之为外键的子计划,它们存储在原有的执行计划中,并通过 唯一标识。当进入执行器阶段后,再构造 Select 物理计划并推到子表执行,如果子表中存在数据,则取出相应的外键子计划,和 Select 出的数据结合后执行。 需要注意的是,当某张表发生变化时,如被删除或修改,需要向上递归其所有的父表、父表的父表等,并更新它们存储在plan cache中的外键子计划。
PolarDB-X 中外键的实现
外键的实现可以分为 DDL 和 DML 两大部分,DDL 中关注的是外键的创建、修改、删除以及各种限制条件,DML关注的外键的约束和级联。
DDL
命名
[CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name, ...)
REFERENCES tbl_name (col_name,...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
PolarDB-X 中外键的命名遵循以下规则与Mysql保持一致:
- 如果在 CONSTRAINT 中指定了名称,则使用该名称。
- 如果 CONSTRAINT 语句未指定名称,会自动生成一个 CONSTRAINT 名称,并使用该名称。
- index_name 仅作为伴随外键创建的索引的名称,不代表外键名称。
- 外键名称必须在当前表中唯一。
限制
创建外键时需要满足以下条件:
- 仅支持在InnoDB引擎上创建外键。
- 外键中的列和引用的父表中的列必须是相同的数据类型,并具有相同的大小、精度、长度、字符集 (charset) 和排序规则 (collation)。
- 外键中的列不能引用自身。
- 外键中父表与子表的列个数必须一致,且必须存在。
- 不支持超过64个字符的外键名、索引名、表名、列名。
- 外键中的列和引用的父表中的列必须有相同的索引,并且索引中的列顺序必须与外键的列顺序一样,这样才能在执行外键约束检查时使用索引来避免全表扫描。
- 如果子表中没有对应的外键索引,则会自动创建一个索引,索引名可以指定或与外键名一致。
- 不支持在 BLOB 和 TEXT 类型的列上创建外键。
- 不允许引用方式为 SET NULL 的外键的引用列为NOT NULL(主键)。
- 不支持创建引用方式为 SET DEFUALT 的外键。
- 不支持在生成列 (Stored & Virtual) 上创建外键。
元信息
外键的系统表有 foreign_key 和 foreign_key_cols。foreign_key 负责记录外键表、行为相关信息,foreign_key_cols 负责记录列相关信息。 其中 foreign_key 中的 PUSH_DOWN 表示外键是否下推,允许物理外键与逻辑外键同时存在,逻辑外键优先级更高:
- 0b11 = logical & physical
- 0b10 = logical
- 0b01 = physical
create table if not exists `foreign_key` (
`ID` bigint unsigned not null auto_increment,
`SCHEMA_NAME` varchar(64) NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) NOT NULL DEFAULT '',
`INDEX_NAME` varchar(64) NOT NULL DEFAULT '',
`CONSTRAINT_NAME` varchar(64) NOT NULL DEFAULT '',
`REF_SCHEMA_NAME` varchar(64) NOT NULL DEFAULT '',
`REF_TABLE_NAME` varchar(64) NOT NULL DEFAULT '',
`REF_INDEX_NAME` varchar(64) NOT NULL DEFAULT '',
`N_COLS` int(11) unsigned NOT NULL DEFAULT '0',
`UPDATE_RULE` varchar(64) NOT NULL DEFAULT '',
`DELETE_RULE` varchar(64) NOT NULL DEFAULT '',
`PUSH_DOWN` int(11) unsigned NOT NULL DEFAULT '2',
primary key (`ID`),
unique key (`SCHEMA_NAME`, `TABLE_NAME`, `INDEX_NAME`)
) charset=utf8
create table if not exists `foreign_key_cols` (
`ID` bigint unsigned not null auto_increment,
`SCHEMA_NAME` varchar(64) NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) NOT NULL DEFAULT '',
`INDEX_NAME` varchar(64) NOT NULL DEFAULT '',
`FOR_COL_NAME`varchar(64) NOT NULL DEFAULT '',
`REF_COL_NAME` varchar(64) NOT NULL DEFAULT '',
`POS` int(11) unsigned NOT NULL DEFAULT '0',
primary key (`ID`),
key (`SCHEMA_NAME`, `TABLE_NAME`, `INDEX_NAME`)
) charset=utf8
对应到内存中外键的数据结构:
public class ForeignKeyData {
public String schema; // schema
public String tableName; // table name
public String constraint; // CONSTRAINT identifier
public String indexName; // FOREIGN KEY identifier
public List columns; // child table columns
public String refSchema; // parent table schema
public String refTableName; // parent table name
public List refColumns; // parent table columns
public ReferenceOptionType onDelete; // delete options
public ReferenceOptionType onUpdate; // update options
public Long pushDown = 2L; // pushdown
}
你可以使用 SHOW FULL CREATE TABLE 语句查看外键的定义和下推行为:
mysql> show full create table t2 G
*************************** 1. row ***************************
Table: t2
Create Table: CREATE PARTITION TABLE `t2` (
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`_drds_implicit_id_` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`_drds_implicit_id_`),
CONSTRAINT `t2_ibfk_1` FOREIGN KEY (`a`) REFERENCES `t1` (`a`) ON DELETE RESTRICT ON UPDATE RESTRICT /* TYPE LOGICAL */
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4
PARTITION BY KEY(`_drds_implicit_id_`)
PARTITIONS 3
/* tablegroup = `tg1121` */
也可以从以下系统表中获取外键有关信息:
- INFORMATION_SCHEMA.TABLE_CONSTRAINTS
- INFORMATION_SCHEMA.KEY_COLUMN_USAGE
- INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS
- INFORMATION_SCHEMA.INNODB_SYS_FOREIGN
- INFORMATION_SCHEMA.INNODB_SYS_FOREIGN_COLS
DML
事务
级联更新或删除时默认开启事务,如果发生违反约束,所有的级联操作都会被事务自动回滚。 在已经开启了事务的情况下,如果开启了 auto_savepoint, 只会回滚当前语句(包含后续的级联);如果没有开启,则报错 ERR_TRANS_CONTINUE_AFTER_WRITE_FAIL,需要回滚整个事务。
约束
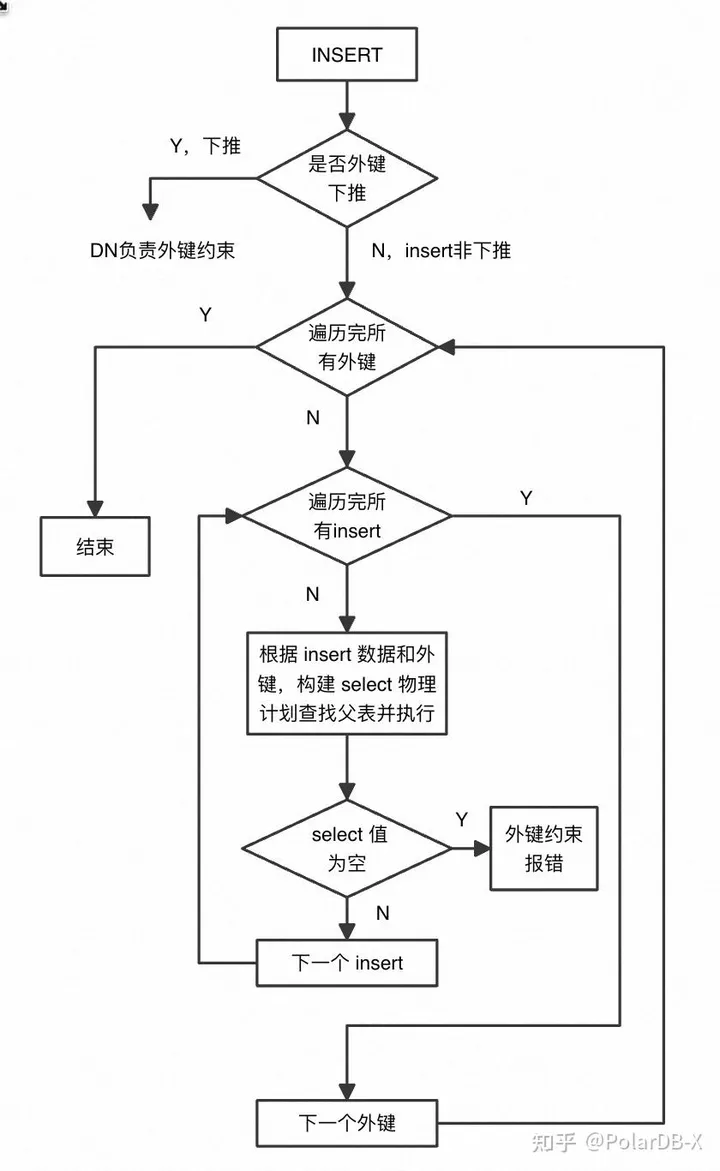
与约束有关的 DML 分为 Insert,Insert Ignore,Upsert,Replace 几类:
- Insert 约束:子表只能插入父表对应列中已经存在的数据,否则报错。若 batch insert 中有不符合约束的数据,则全部不能插入成功。
- Insert ingnore 约束:子表只能插入父表对应列中已经存在的数据,但违反约束不会报错。如果是 batch insert 中有不符合约束的数据,则满足约束的部分可以插入成功。
- Replace 约束:支持约束行为,暂不支持级联更新。
- Upsert 约束:暂不支持。
算法
以 Insert 为例,流程图如下:
级联
情况分析
下面列举几个级联的情况,以 ON DELETE CASCADE 为例,便于理解后续对级联的设计。
CASCADE 与 RESTRICT
当 CASCADE 与 RESTRICT 同时存在于引用关系中时,会造成删除失败。 由于级联,删除表a的数据后应删除表b中的数据,但由于更深层的级联中存在RESTRICT,所以失败报错,因此在执行级联时需要有回滚的能力。
CREATE TABLE a (
id INT PRIMARY KEY
);
INSERT INTO a VALUES (1);
CREATE TABLE b (
id INT PRIMARY KEY,
a_id INT,
FOREIGN KEY fk(`a_id`) REFERENCES a(`id`) ON DELETE CASCADE
);
INSERT INTO b VALUES (1,1);
CREATE TABLE c (
b_id INT,
FOREIGN KEY fk(`b_id`) REFERENCES b(`id`) ON DELETE RESTRICT
);
INSERT INTO c VALUES (1);
DELETE FROM a WHERE id = 1;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`test`.`c`, CONSTRAINT `c_ibfk_1` FOREIGN KEY (`b_id`) REFERENCES `b` (`id`) ON DELETE RESTRICT)
自循环引用
表中的一列作为外键引用另一列,当删除表中任意一行时,将会删除表中的所有数据。 在这种自引用场景下,我们没有办法事先判断会进行多少次级联,只有当获取需要删除行中所对应的被引用列的数据后,才能根据数据时候在外键列中存在,来判断是否进行下次级联操作。 需要限制级联次数(Mysql中为15次),PolarDB-X 也限制为15次,超出报错。
CREATE TABLE a (
id INT PRIMARY KEY,
other_id INT,
FOREIGN KEY fk(`other_id`) REFERENCES a (`id`) ON DELETE CASCADE
);
INSERT INTO a VALUES (1, NULL), (2, 1), (3, 2), (4, 3);
UPDATE a SET other_id = 4 WHERE id = 1;
SELECT * FROM a;
+----+----------+
| id | other_id |
+----+----------+
| 1 | 4 |
| 2 | 1 |
| 3 | 2 |
| 4 | 3 |
+----+----------+
(4 rows)
DELETE FROM a WHERE id = 1;
SELECT * FROM a;
+----+----------+
| id | other_id |
+----+----------+
+----+----------+
(0 rows)
#进行了三次级联删除
多重级联
在多重级联中,表与表之间会存在复杂的引用关系,并且这些引用关系可能会导致竞争 例如在下面这个引用关系中,b和c引用自a,d引用自c,e引用自b和d,那在进行级联时,b和d会形成竞争关系。
a
/
b c
| |
| d
/
e
CREATE TABLE race_a (
id STRING PRIMARY KEY
);
CREATE TABLE race_b (
id STRING PRIMARY KEY,
a_id STRING,
FOREIGN KEY fk(`a_id`) REFERENCES race_a(`id`) ON DELETE CASCADE
);
CREATE TABLE race_c (
id STRING PRIMARY KEY,
a_id STRING,
FOREIGN KEY fk(`a_id`) REFERENCES race_a(`id`) ON DELETE CASCADE
);
CREATE TABLE race_d (
id STRING PRIMARY KEY,
c_id STRING,
FOREIGN KEY fk(`c_id`) REFERENCES race_c(`id`) ON DELETE CASCADE
);
CREATE TABLE race_e (
id STRING PRIMARY KEY,
b_id STRING,
d_id STRING,
FOREIGN KEY fk(`b_id`) REFERENCES race_b(`id`) ON DELETE CASCADE,
FOREIGN KEY fk(`d_id`) REFERENCES race_d(`id`) ON DELETE CASCADE
);
INSERT INTO race_a (id) VALUES ('a1');
INSERT INTO race_b (id, a_id) VALUES ('b1', 'a1');
INSERT INTO race_c (id, a_id) VALUES ('c1', 'a1');
INSERT INTO race_d (id, c_id) VALUES ('d1', 'c1');
INSERT INTO race_e (id, b_id, d_id) VALUES ('e1', 'b1', 'd1');
SELECT * FROM race_a;
+----+
| id |
+----+
| a1 |
+----+
(1 row)
SELECT * FROM race_b;
+----+------+
| id | a_id |
+----+------+
| b1 | a1 |
+----+------+
(1 row)
SELECT * FROM race_c;
+----+------+
| id | a_id |
+----+------+
| c1 | a1 |
+----+------+
(1 row)
SELECT * FROM race_d;
+----+------+
| id | c_id |
+----+------+
| d1 | c1 |
+----+------+
(1 row)
SELECT * FROM race_e;
+----+------+------+
| id | b_id | d_id |
+----+------+------+
| e1 | b1 | d1 |
+----+------+------+
(1 row)
DELETE FROM race_a WHERE id = 'a1';
SELECT * FROM race_a;
+----+
| id |
+----+
+----+
(0 rows)
SELECT * FROM race_e;
+----+------+------+
| id | b_id | d_id |
+----+------+------+
+----+------+------+
(0 rows)
设计思路
在级联中,表与表的关系可以抽象为一张有向图,其中表是图中的节点,而外键则是图中的边。确定在级联过程中哪些表和其中的数据会受到影响,所需要实现的就是一个图遍历算法。
单步描述
在级联的遍历过程中,由于级联涉及到的情况众多,每一步都需要根据其特定情况进行操作,所以需要对单步中遇到的情况做一个说明:
- 在 DML 中会可能涉及到级联。
- 级联分为本位开头介绍的六种具体的不同操作。
下面以一个一个映射关系为例进行具体介绍:
'NA 'DC 'DS 'UC 'US
| / /
| / /
| / /
\|//
X
//|\
/ / |
/ / |
/ / |
NA DC DS UC US
上图中每个元素都代表一张表,下面的表引用自上面的表,并且表的名字代表了其与表X的映射关系,比如X引用自表'NA,并且引用关系是NO ACTION 或 RESTRICT,表DC引用自表X,并且引用关系是DELETE CASCADE。 下面为元素的具体含义:
-
NA, 'NA:NO ACTION或RESTRICT -
DC, 'DC:DELETE CASCADE -
DS, 'DS:DELETE SET NULL或DELETE SET DEFAULT -
UC, 'UC:UPDATE CASCADE -
US, 'US:UPDATE SET NULL或UPDATE SET DEFAULT
接下来为 INSERT, DELETE, UPDATE 具体分析:
INSERT
INSERT 时需要向前查找。 向表X中插入一行时,必须获取它引用的所有表。所以需要获取表'NA, 'DC, 'DS,'UC和'US中的数据,并且不需要继续向前查找,因为 INSERT 不会产生级联。 对于那些引用表X的表,INSERT与它们无关,不需要获取它们的相关数据。
DELETE
DELETE 时需要向后查找。 删除表X中的一行时,不需要获取它引用的表。 对于引用表X的表NA, DC, DS,UC和US,需要进行以下操作:
-
NA:获取数据,无其他操作。 -
DC:获取数据,继续进行 DELETE 操作。 -
DS:获取数据,继续进行 UPDATE 操作。 -
UC:获取数据,无其他操作。 -
US:获取数据,无其他操作。
UPDATE
更新表X的一行时,由于 UPDATE 是 DELETE + INSERT,所以与 INSERT 类似,也需要表X引用的所有表'NA, 'DC, 'DS,'UC和'US中的数据,并且不需要继续向前查找。 对于引用表X的表NA, DC, DS,UC和US,需要进行以下操作:
-
NA:获取数据,无其他操作。 -
DC:获取数据,无其他操作。 -
DS:获取数据,无其他操作。 -
UC:获取数据,继续进行 UPDATE 操作。 -
US:获取数据,继续进行 UPDATE 操作。
算法
正如遍历一张图一样,只要我们构建出图中顶点间的拓扑关系,就可以将级联关系遍历完成。
算法可以通过递归或队列迭代实现,过程入下:
- 进行外键约束的检查
- 遍历所有已知的映射关系,对于每个映射关系:
- 构建并执行 SELECT 物理执行计划,查找是否存在级联更新的数据。
- 基于上节中的说明为 DELETE/UPDATE 寻找对应的逻辑执行计划。
- 下发执行计划,获取会后续会影响的行,并根据行获得新的映射关系。
- 若映射关系不为空,递归继续执行 / 将新的映射关系加入队列,并将已经完成的映射关系删除。
Delete 级联的流程图:
- CASCADE 时构造的是delete执行计划,SET NULL 构造的是update执行计划。

Update 级联的流程图:
- 由于拓扑中可能同时包含物理与逻辑外键,若当前外键不下推,则 select 出数据后,执行 delete/update 逻辑计划;若当前外键下推,存储层会在各自分片行执行级联操作,计算层仍需要 select 出数据,但不需要执行当前的 delete/update 逻辑计划,这是为了确定是否需要进行后续的级联,

总结
在本文中,我们介绍了 PolarDB-X 中外键的设计和实现,首先介绍了外键的具体功能,然后列举了在分布式数据库中外键需要额外考虑的一些场景,最后通过 DDL 和 DML 两方面介绍了 PolarDB-X 中外键的具体实现。外键作为一项功能较多、细节丰富的特性,本文仍有很许多尚未讨论的问题,如果你有任何问题或建议,欢迎与我们讨论。
作者:琦华
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。
