


编者按:Transformers 是人工智能领域近年来最引人瞩目的技术之一,它为语言生成模型的发展做出了巨大的贡献。随着大语言模型(LLM)的兴起,公众对其背后的技术原理也越来越感兴趣。但是由于Transformers本身具有一定的复杂性,想要真正理解其中的原理并不容易。
今天,我们开始为大家带来了一系列以通俗易懂的语言解释Transformers的好文章。作者Chen Margalit希望通过本系列文章,用最简单的语言把Transformers的关键要点讲清楚,让不同机器学习掌握水平的读者都能受益。
本文是Transformers系列的第一篇。作者着重讲述 Transformers 的输入(input)部分。依次讲解了分词、词向量表示、位置编码等概念。这些看似简单的步骤,却是构建Transformers的基石。在讲解的过程中,作者多次使用通俗易懂的例子辅助解释,同时辅以代码、公式和图示,让读者在理解抽象概念的同时,也能对实际操作过程有具体的认知。
相信通过阅读本系列文章,不论是人工智能初学者还是有相关经验的从业人员,都能对Transformers的运作原理有一个直观且全面的了解。
以下是译文,enjoy!
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:https://medium.com/towards-data-science/transformers-part-1-2a2755a2af0e ; https://medium.com/towards-data-science/transformers-part-2-input-2a8c3a141c7d
作者 | Chen Margalit
编译 | 岳扬
Transformers这种深度学习架构,为人工智能的发展做出了杰出贡献。它在人工智能和整个技术领域都是一个重要的里程碑,但它也有一些复杂之处。目前已经有了很多关于Transformers的好资源了,为什么我还要再创作这个系列呢?原因有二:
- 我深谙自学之道,而且根据我的经验,阅读不同的人如何描述相同的观点,能够大大加深我们对这些知识的理解。
- 目前,我很少在阅读一篇文章时,认为这篇文章的解释已经足够简单。技术内容创作者往往总是将概念过度复杂化或没有充分的去解释。我们应该明白,没有什么是rocket science,甚至连rocket science都不是。只要对其的解释足够好,我们可以理解任何东西。 在本系列中,我将尝试对Transformers做出足够好的解释。
此外,作为一个凭借博客文章和开源代码走上职业道路的人,我认为我有义务回报社会。
该系列将尝试为那些几乎不了解人工智能的人和那些了解机器学习原理的人,都提供合理的指导。我打算怎么实现这一目标呢?首要的是要合理去解释Transformers。在我的职业生涯中,我阅读了近1000篇技术文章(就像这篇文章一样),我阅读时所面临的主要问题是作者(或许是潜意识地)假设你已经了解了很多相关的知识。在本系列中,我打算假设你阅读过的相关技术文章,比我为创作这篇文章而阅读的Transformers文章数量还要少。
此外,我将结合个人感觉和直观理解、数学公式、代码和可视化元素,使这个系列就像一个candy store(译者注:用来形容某事提供了多种吸引人的选择,就像一个糖果店一样,糖果店里有各种各样形状、口味的糖果供人选择)——适合各种人。考虑到这是一个复杂领域中的前沿概念,我愿意冒险地让你认为:“哇,这文章的进展太慢了,不要去解释这些显而易见的东西”。但同时读者产生这种想法的可能性就会大大降低:“我不知道他到底在说什么?”
01 Transformers,值得你花时间去了解吗?
有什么值得大惊小怪的?它真的那么重要吗?因为它是世界上一些最先进的人工智能驱动技术工具(如 GPT 等)的基础,所以可能确实很重要。
尽管和历史上许多次科学突破一样,一些相关的思想在之前已经有人提出,但对这种架构的深入、完整的描述实际上是来自于 “Attention is all you need” 这篇论文,该论文说Transformers是一种 “简单的神经网络架构”。
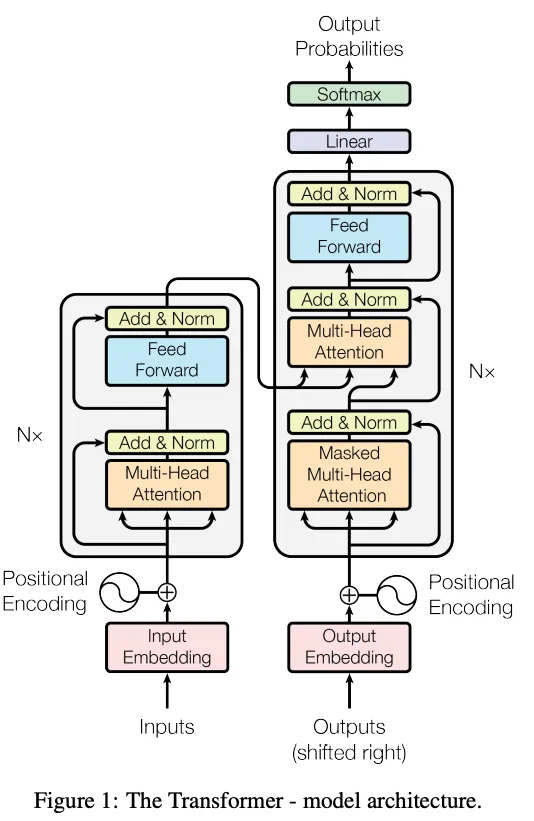
该架构图来自论文《Attention is all you need》[1]
如果你和大多数人相同,就不会认为这是一种简单的神经网络架构。因此,我的任务就是努力让你在读完这个系列后,心里想:这确实不简单,但我已经明白了。
那么,这张复杂的架构图,到底是怎么回事?
我们看到的这张图是一种深度学习架构,这就意味着其中的每一个方框都对应着一些代码片段,将这些代码片段组合在一起,就能完成一些人们现在还不知道它们如何完成的事情。
Transformers可以应用于许多不同的应用场景,但最著名的使用案例可能是automated chat(自动化聊天)——可以和它一起探讨各种各样的话题,就像在和一个真人交谈一样,它看起来也好像无所不知。在某种程度上类似于《黑客帝国》。
02 Inputs
龙从蛋中孵化,婴儿从腹中诞生,人工智能生成的文本从输入(inputs)开始。一切都必须从某个地方开始。
Transformers拥有什么样的输入取决于手头的任务。如果正在构建一个语言模型,一个能够生成相关文本的软件(Transformers架构在各种场景中都很有用),那么输入(inputs)就是文本。然而,计算机能够接受任何种类的输入(文本、图像、声音)并神奇地知道如何处理吗?实际上不行。
我相信你认识一些不擅长言辞但擅长处理数字的人,计算机类似于这样的人。它不能直接在 CPU/GPU(进行计算的地方)中处理文本,但它绝对可以处理数字!你很快就会发现,如何将这些文字表示为数字是Transformers中的关键因素。
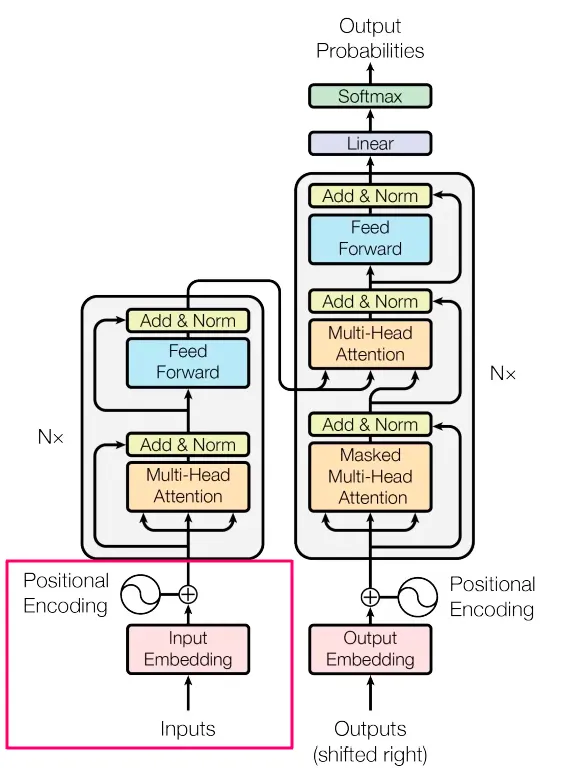
该图片来自 Vaswani, A. 等人论文《Attention Is All You Need》[2]
2.1 分词器
分词是将语料库(所有文本)转化为机器可以更好利用的较小部分的过程。 假设我们有一个包含 10,000 篇维基百科文章的数据集,我们对每个字符进行处理(分词)。对文本进行分词的方法有很多,让我们看看 OpenAI 的分词器[3]是如何处理以下文本的:
“Many words map to one token, but some don’t: indivisible.
Unicode characters like emojis may be split into many tokens containing the underlying bytes: 🤚🏾
Sequences of characters commonly found next to each other may be grouped together: 1234567890″
这就是进行分词后的结果:

图片由 OpenAI 提供,取自此处[3]
如您所见,有大约40个单词。在这40个单词中,生成了64个词元(token)。有时词元是整个单词,如“Many, words, map”,有时是单词的一部分,如“Unicode”。为什么要将整个单词分成较小的部分呢?为什么要分离句子?我们本可以让它们保持完整,反正最后它们都会被转换成数字。所以在计算机看来,词元(token)是 3 个字符长还是 30 个字符长又有什么区别呢?
词元有助于模型进行学习,因为文本就是我们的数据,词元就是数据的特征。对这些特征进行不同的工程设计会导致性能的变化。例如,在句子 “Get out!!!!!!!” 中,我们需要判断多个“!”是否与一个“!”不同,或者它是否具有相同的含义。从技术上讲,我们可以将这些句子作为一个整体保留下来,但试想一下,观察一群人与单独观察每个人,哪种情况下你能够获得更好的见解?
现在我们有了词元(token),我们可以构建一个查询字典(lookup dictionary),这样就可以摒弃单词,改用索引(数字)代替。例如,如果我们整个数据集是一个句子 “Where is god”。我们可以建立这样一个词汇表,它只是一个由单词和代表单词的单个数字组成的键值对。我们不必每次都使用整个单词,我们可以使用数字。例如:
{Where: 0, is: 1, god: 2}。每当我们遇到单词“is”,我们将其替换为1。如果想了解更多关于分词器的内容,你可以使用谷歌开发的分词器[4],或者尝试使用OpenAI的TikToken[5]进行更多实验。
2.2 Word to Vector
个人感觉和直观理解 Intuition
在将单词表示为数字的这个过程,我们取得了重大进展。下一步将是根据这些词元(tokens)生成数值形式的语义表征(numeric, semantic representations)。 为此,我们可以使用一种名为 Word2Vec[6] 的算法。该算法的具体细节目前还不是很重要,但其主要思想是,采用数字向量(可以简单想象为一个普通的数组),这个向量的大小可以任意设置(这篇论文[1]的作者使用了512个数字),而这个向量应当代表一个词的语义含义。想象一下,像 [-2, 4,-3.7, 41…-0.98] 这样的数组实际上代表了一个单词的语义。如果我们将这些数字向量绘制在二维图上,相似的词的位置会比不相似的词更加接近。
如图所示(取自此处[7]),”Baby “与 “Aww “和 “Asleep “相近,而 “Citizen”/”State”/”America’s “也有几分相近。
*二维词向量(也就是包含 2 个数字的数组)甚至不能准确地表示一个词的含义,如前所述,作者使用了 512 个数字作为向量的大小。由于我们无法绘制 512 维中的任何内容,因此我们使用一种叫做 PCA [8] 的方法将维度数量减少到 2,希望还能保留大部分的原始含义。 在本系列的后续部分,我们将深入探讨这种方法的原理。
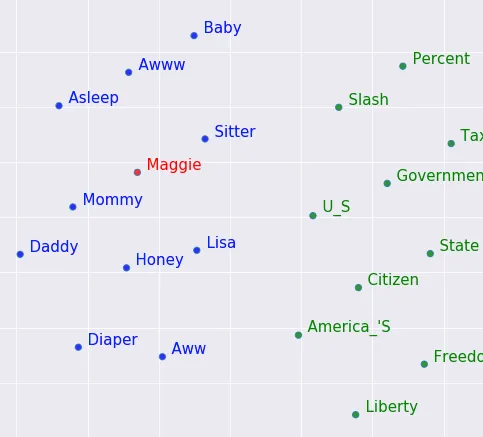
Word2Vec 2D 演示——图片由 Piere Mergret 提供,摘自此处[7]
这种方法确实有效!你可以训练一个模型,让其能够生成具有语义的数组。计算机不知道“baby”是一个会尖叫、让人失眠(超级可爱)的小人儿,但它知道通常会在“aww”附近更频繁地看到“baby”这个词,而不是“State”和“Government”这些词。我之后会再写一些文章,解释其中的实现原理,但在那之前,如果你有兴趣,这篇文章[7]也许还不错。
这些 “数组” 相当重要,因此它们在专业的机器学习术语中也有属于自己的名字,那就是“嵌入”(Embeddings)。为什么叫嵌入?因为我们正在进行嵌入(很有创意),这是将术语从一种形式(单词)映射(翻译)到另一种形式(数组)的过程。这些括号内的内容也很重要。
从现在开始,我们将把“单词”称为“嵌入”,正如前面所解释的那样,嵌入是一个数组,用于保存任何它被要求表示的词的语义含义。
2.3 使用 Pytorch 创建嵌入
我们首先计算所拥有的唯一词元(token)的数量,为简单起见,假设为 2。嵌入层(embeddings layer)是 Transformer 架构的第一部分,创建嵌入层就像编写以下代码一样简单:
*备注——请不要将此段代码及其约定视为好的编码风格,写这段代码的目的是为了便于理解。
代码 Code
import torch.nn as nn
vocabulary_size = 2
num_dimensions_per_word = 2
embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)
print(embds.weight)
---------------------
output:
Parameter containing:
tensor([[-1.5218, -2.5683],
[-0.6769, -0.7848]], requires_grad=True)
现在,我们已经有了一个嵌入矩阵,在本例中,它是一个 2 乘 2 的矩阵,是由来自正态分布 N(0,1) 的随机数生成(例如,均值为 0、方差为 1 的分布)。
注意 requirements_grad=True,这是 Pytorch 中表示这 4 个数字是可学习权重的方式。它们可以并将在学习过程中进行自定义,以更好地表示模型接收到的数据。
在一个更实际的场景中,我们可以期望得到一个接近10,000×512的矩阵,用数字形式表示了整个数据集。
vocabulary_size = 10_000
num_dimensions_per_word = 512
embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)
print(embds)
---------------------
output:
Embedding(10000, 512)
*有一个有趣的事实(当然,我们也许还能想到更有趣的事):有时你可能会听说某个语言模型拥有数十亿个参数。而上面这个初始的、看起来不太疯狂的层就已经拥有 10,000 乘以 512 的参数量,也就是 500 万个参数。而 LLM (大语言模型)是一种相当复杂的东西,需要进行大量计算。
“参数”是一个比较 fancy (译者注:在这里,“fancy” 可能表示参数有一定的价值。)的词,用来指代那些数字(比如-1.525等),只不过它们是可以改变的,而且在训练过程中会发生变化。
这些数字就是机器正在学习的东西。之后给机器学习模型输入信息时,就会将输入信息与这些数字相乘,然后祈祷能输出一个好的计算结果。 你看,这些数字是不是非常重要。因为你对你父母来说很重要,所以你会拥有自己的名字,所以这些不是普通的数字,它们也有自己的名字:参数。
为什么上面的Embedding(10000, 512)这行代码使用 512 而不是 5 ?因为更大的数字意味着我们可以生成更准确的含义。太好了!那么使用 100万 如何?为什么不呢?因为更大的数字意味着要进行更多的计算、需要更多的计算资源、更昂贵的训练成本等等。经过长期的实验,人们发现 512 是个合适的中间值。
2.4 序列长度 Sequence Length
在训练模型时,我们会把大量单词组合在一起。这样做的计算效率更高,而且有助于模型在获得更多上下文时进行学习。如前文所述,每个单词都将由一个 512 维的向量(包含 512 个数字的列表)来表示,而且每次将输入传递给模型(又称前向传递(forward pass))时,我们会向模型发送一堆句子,而不仅仅是一句。举个例子,如果我们决定生成一个单词数量为50的序列。意味着我们需要在一个句子中提取 x 个单词,如果 x > 50,我们就将其拆分,只提取前 50 个单词,如果 x 为了解决这个问题,我们需要在句子中添加 padding,这是一种特殊的虚拟字符串。例如,如果我们需要一个 由 7 个单词组成的句子,并且现在这个句子为 “where is god”。就需要添加 4 个padding,因此输入到模型的内容将变成“Where is god ”。实际上,通常我们会添加至少2个额外的特殊 padding,这样模型就能知道句子的开始和结束位置,所以这个句子会变成类似于 “ Where is god ”的样子。
- 为什么所有的输入向量都必须拥有相同的大小?因为软件有 “expectations” ,而矩阵的 “expectations” 更为严格(译者注:“expectations”指对输入数据或操作有特定的期望,要求输入数据满足特定的某种规则或条件)。我们不能随心所欲地进行“数学”计算,必须要遵循某些规则,其中规则之一就是需要有足够的向量大小。
2.5 位置编码 Positional encodings
个人感觉和直观理解 Intuition
如前文所述,现在有了一种好方法来表示(和学习)vocabulary中的单词(译者注:vocabulary指代一个特定数据集或语料库中出现的不同单词的集合)。我们可以对单词的位置进行编码进一步改进这个方法。为什么说这个步骤很重要呢?看看下面这个例子:
-
The man played with my cat
-
The cat played with my man
我们可以使用完全相同的嵌入来表示这两个句子,但这两个句子的含义却不同。我们可能会认为这些数据的顺序并不重要。因为如果我们要计算某些东西的总和,顺序可能并不重要。但是在语言中,顺序通常很重要。这些嵌入虽然包含单词的语义,但没有确切的顺序含义。这些嵌入确实在某种程度上保持了原有的顺序,因为这些嵌入最初是根据某种语言逻辑创建的(“baby”出现更接近“sleep”,而不是“state”),但同一个词可以有多个含义,更重要的是,当它处于不同的语境中时,会有不同的含义。
将这些单词转化为没有顺序的文本是不够的,但是我们可以改进这一点。我们可以在嵌入中加入位置编码。 具体做法是为每个单词计算一个位置向量(position vector),然后将两个向量相加(求和)。位置编码向量(positional encoding vectors)的大小(size)必须相同,这样才能相加。位置编码通过两个函数来实现:偶数位置(如第 0 个单词、第 2 个单词、第 4 个单词、第 6 个单词等)用正弦函数计算,奇数位置(如第 1 个单词、第 3 个单词、第 5 个单词等)用余弦函数计算。
可视化元素 Visualization
通过观察这些函数(红色表示正弦函数,蓝色表示余弦函数),你也许可以想象为什么要特别选择这两个函数。这两个函数之间存在一定的对称性,就像一个单词与它前面的单词之间存在对称性一样,这种方法有助于模拟(表示)这些相关的位置。此外,它们的输出值在 -1 到 1 之间,数字大小非常稳定(不会变得超大或超小)。
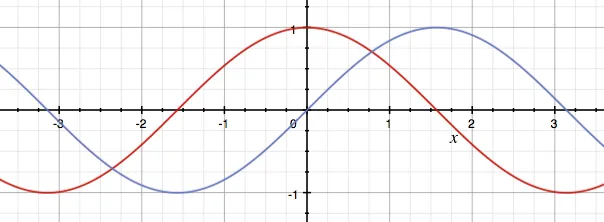
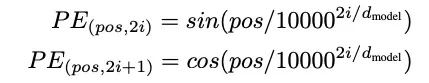
公式及图片来自 Vaswani, A. 等人的论文[2]
在上述公式中,第一行公式表示从 0 开始的偶数(i = 0),并接着表示偶数(21、22、2*3)。第二行以同样的方式表示奇数。
每个位置向量都是一个数值从 0 到 1 的number_of_dimensions(本例中为 512)维的向量。
Code
from math import sin, cos
max_seq_len = 50
number_of_model_dimensions = 512
positions_vector = np.zeros((max_seq_len, number_of_model_dimensions))
for position in range(max_seq_len):
for index in range(number_of_model_dimensions//2):
theta = position / (10000 ** ((2*index)/number_of_model_dimensions))
positions_vector[position, 2*index ] = sin(theta)
positions_vector[position, 2*index + 1] = cos(theta)
print(positions_vector)
---------------------
output:
(50, 512)
如果我们打印第一个单词,我们可以看到我们只得到0和1这两个值,它们是可以互换的:(译者注:根据前文所述,译者猜测此处为填充的padding——)
print(positions_vector[0][:10])
---------------------
output:
array([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])
第二个单词中的数字就已经更加多样化了。
print(positions_vector[1][:10])
---------------------
output:
array([0.84147098, 0.54030231, 0.82185619, 0.56969501, 0.8019618 ,
0.59737533, 0.78188711, 0.62342004, 0.76172041, 0.64790587])
*代码灵感来自这里[9]。
我们已经看到,不同的位置会产生不同的表征(representations)。为了完成整个输入部分(下图中红色的正方形),我们将位置矩阵(position matrix)中的数字添加到输入的嵌入矩阵(input embeddings matrix)中。最终,我们会得到一个与嵌入相同大小的矩阵,只是这次的这些数字包含了语义+顺序。
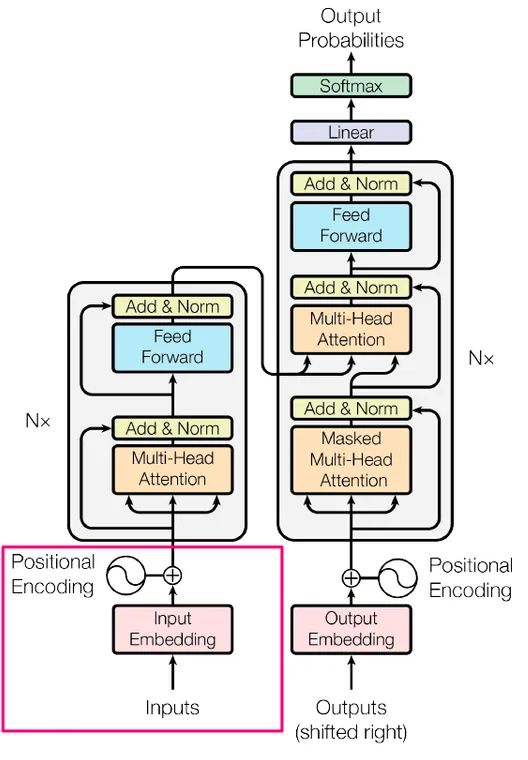
图片来自 Vaswani, A. 等人的论文[2]
2.6 总结 Summary
本小节讨论了 Transformer 的input部分(用红色矩形标记),介绍了模型如何获取输入。我们学习了如何将文本分解成特征(词元),将它们表示为一些数字(嵌入),以及了解了一种聪明的方式将位置编码添加到这些数字中。
下一小节将重点讨论编码器块的不同机制(第一个灰色矩形),其中的每个部分都是不同颜色的矩形(例如多头注意力机制(Multi head attention)、Add & Norm(译者注:“Add” 指的是将不同层的输出相加,而 “Norm” 指的是归一化,主要目标是解决深度神经网络中的梯度消失和梯度爆炸问题)等)。
END
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
参考资料
[1]https://arxiv.org/pdf/1706.03762.pdf
[2]https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
[3]https://platform.openai.com/tokenizer
[4]https://github.com/google/sentencepiece
[5]https://github.com/openai/tiktoken
[6]https://arxiv.org/abs/1301.3781
[7]https://www.kaggle.com/code/pierremegret/gensim-word2vec-tutorial
[8]https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
[9]https://machinelearningmastery.com/a-gentle-introduction-to-positional-encoding-in-transformer-models-part-1/
