


引言
随着PolarDB分布式版的不断演进,功能不断完善,新的特性不断增多,整体架构扩大的同时带来了测试链路长,出现问题前难发现,出现问题后难排查等等问题。原有的测试框架已经难以支撑实际场景的复杂模拟测试。因此,我们实现了一个基于业务场景面向优化器索引选择的混沌查询实验室,本文之后简称为CEST(complex environment simulation test)。 CEST能够提供灵活生产各种数据的测试工具,包括有无倾斜,有无全局二级索引,大,小,宽,窄等等类型的表。为日后的扩展的测试框架提供了测试的数据保障。其次,CEST针对目前的优化器进行了评测,从而复现出目前业务场景存在的多种问题,主要包括索引错选和plan cache等问题。最后,CEST能够探测尚未在业务场景发现的设计隐患,从而在问题发生之前就将其消灭。
索引选择
在介绍CEST之前,本文先对PolarDB-X的索引选择策略进行简要的回顾: 以是否选择使用全局二级索引为例介绍索引选择策略。简单的来说,全局二级索引一般是一张有索引键,主键,覆盖索引键的表。由于其按索引键分区,如果索引和查询过滤条件配合得当,那么使用全局二级索引能够快速定位数据所在分区,减少扫描的分片数,从而达到优化查询速度的效果。而如果分区键定义不当,也很容易出现“烂索引”,对写入性能造成一定影响。我们在这篇文章中对比了各数据库的索引写入性能。如果选择使用全局二级索引,查询时也会带来一个额外的开销,即不在索引表中的数据需要和主表进行join后得到,这个开销我们称之为回表代价。
因此有无回表代价,回表代价是否比减少的开销要低成了我们是否选择全局二级索引的关键因素。一旦回表代价比较高而我们仍然选择了此索引,则认为这个选择是一次失败的索引选择策略。
回表代价在PolarDB-X查询引擎中用Net表示:

可以看到我们的索引选择策略在很大程度上依赖于估计出的回表行数,而回表行数的估计的准确性又依赖于基数估计精准度。因此,基数估计的准确度很大程度的影响了索引选择的效果。而事实上,许多基数估计算法都有着许多与实际场景不相符合的假设,比如说“各列独立不相关”。这就造成了在实际场景中基数估计很难估计准确,也直接影响到了索引选择的正确性。因此,本文介绍的测试器将着重测试优化器估计和索引选择的效果。
优化器误估&索引错选问题频发
我们根据PolarDB-X的用户反馈进行排查后发现优化器误估和索引错选的问题频繁发生,而且由于线上环境经常出现计算节点宕机,缓存清空等突发情形,导致运维人员排查问题比较吃力。本文认为产生这类问题的原因可以被归类于以下几点:
统计信息缺失:由于种种原因,某张表的统计信息丢失了。这意味着优化器在进行索引选择代价估算的时候不知道每个列的基数等信息。导致代价估算毫无根据,从而无法分辨出主表扫描和全局索引谁的代价更低,导致索引错选。
热点索引:PolarDB-X在计算节点会将常用的SQL模版的执行计划缓存下来。设想这样一个场景,一个查询语句的过滤条件是全局二级索引列上的一个冷值,如果从全局二级索引上扫描数据不仅能够快速定位数据所在分区,并且最终回表行数也非常少,因此优化器生成了一个扫描全局二级索引的执行计划并将其缓存了下来。但之后计算节点收到一个具有相同的查询模版而过滤条件值为热值的查询语句,因为缓存中有执行计划,优化器偷懒直接使用了扫描全局二级索引的执行计划,导致回表行数爆炸,产生了一个慢查询。
全局二级索引分区:全局二级索引的分区数,分区键设置不合理同样会导致索引错选。比如一个指定主表分区键为二级索引分区键的全局二级索引就是一个不好的索引,会导致索引错选问题。
上述几点是比较常见的原因,当然还有一些其他的原因,这里不一一列举。这类原因本文认为都只是索引错选的直接原因,而并非是根本原因。索引错选的根本原因在于普通的单元测试或集成测试没有对优化器索引选择的行为进行评估:
- 优化器执行过程中各种估计是否准确?
- 索引选择策略是否能带来性能提升?
- 环境的抖动是否会带来优化器误估和索引错选问题?
挑战与目标
因此,我们实现了一个基于业务场景面向优化器索引选择的混沌查询测试器(CEST)。CEST能够模拟复杂的线上环境,如计算节点宕机,缓存清空,缓存打满,统计信息丢失等。同时,在复杂环境中生成类似于用户行为逻辑的数据和访问模式,从而对优化器的估计和索引选择策略进行评估。 在实现CEST的过程中,本文遇到了如下挑战: 如何使得CEST的数据与行为与业务逻辑相似?
- Zipf分布:数据分布采用Zipf分布模式,并配有不同的倾斜度。
- 混沌查询:在随机单点,Agg,Join查询的同时可能加入CN宕机,PlanCache清空等行为。
如何保证CEST的可复现性和可解释性?
- 可解释性:针对不同的优化器评估模式,设立了不同的指标。
- 可复现性:在实验室的日志中,包括了随机时使用的种子(seed)和问题SQL。
如何保证CEST的易用性和泛用性?
- 易用性:分为多种查询测试,建表测试->固定查询->随机查询->混沌查询,难度逐步增大。
- 泛用性:实验室默认生成了大/小/宽/窄/全类型等等多场景表,覆盖面广。
通过解决这些问题,CEST最终可以达到以下效果:
- 提供灵活生产各种表数据的测试工具
- 复现业务场景中索引错选的实际问题
- 探测尚未在业务场景发现的设计隐患
设计与实现
CEST运行在k8s集群中,整体架构如下图所示:
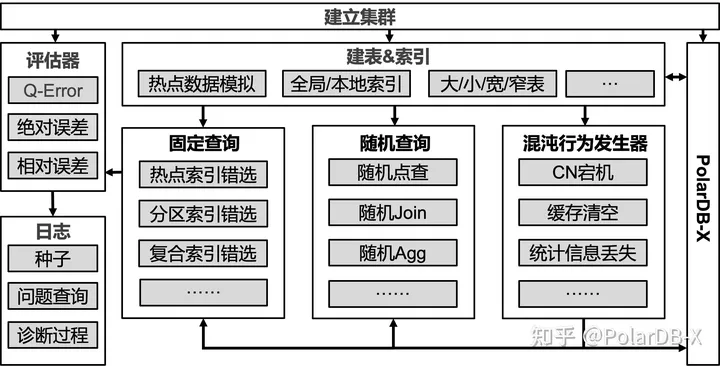
建立集群
目前集群由PolarDB-X(2CN+2DN) 和本项目的测试客户端组成。每次运行实验室时会检查是否已经存在集群,若有则直接使用它或者升级它(如果可以升级)再使用;否则拉取镜像后创建新的集群。
数据生成
本项目在数据生成时可为用户提供若干选项从而能够:
- rowNum:指定生成数据的行数
- colNum: 指定生成数据的列数,在生成列时,优先生成能够包含数字,字符串,时间等常用类型的列,其余列则从一个包含所有类型的列字典中随机挑选。
- uniqueRatio:指定特定列的独立比例。该选项一方面控制列与列之间的基数不相同,另一方面也控制着Zipf分布的数据生成时的字典长度。
- skew:指定特定列的数据倾斜程度。用于控制每个独特数据的重复率。
- partitionNum:指定表的分区数,默认为32
热点数据模拟具体包括:
1. 一个基类DataGenerator:调用其next可以得到Zipf分布选出字典长度范围内的一个idx,并根据idx给出字典内值,对于Zipf的字典初始化则交由各父类在创建时进行初始化。
2.针对每一种相似的类型,创建一个Generator:
- IntegerGenerator 整数数据生成器: BIT,TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT
- StringGenerator 字符串数据生成器:CHAR,BINARY,VARCHAR,VARBINARY,TEXT,BLOB
- TimeGenerator 时间数据生成器:YEAR,DATE,TIME,TIMESTAMP,DATE_TIME
- RealNumGenerator 实数数据生成器:FLOAT, DECIMAL, DOUBLE
- GeometryGenerator 几何数据生成器:GEOMETRY,POINT,MULTIPOINT,GEOMETRYCOLLECTION,POLYON,MULTIPOLYGON,LINESTRING, MULTILINESTRING
3.每个generator在生成时将会根据类型的具体参数,初始化Zipf的字典,具体来说:
- 整数数据生成器:根据具体类型和是否带有unsigned标识决定字典的最大值
- 字符串数据生成器:根据具体类型和参数决定字符串长度,之后随机生成hex字符串
- 时间数据生成器:随机生成2022年01月01日到2023年01年01日的数据,对于TIME类型随机生成24小时的数据
- 实数数据生成器:根据具体类型决定字典的最大值,对DECIMAL则根据参数决定其最大值和精度
- 几何数据生成器:类似正数数据生成器,只是需要在结构上和SQL所需的样式进行对齐
4.本项目内置了若干张预设表:
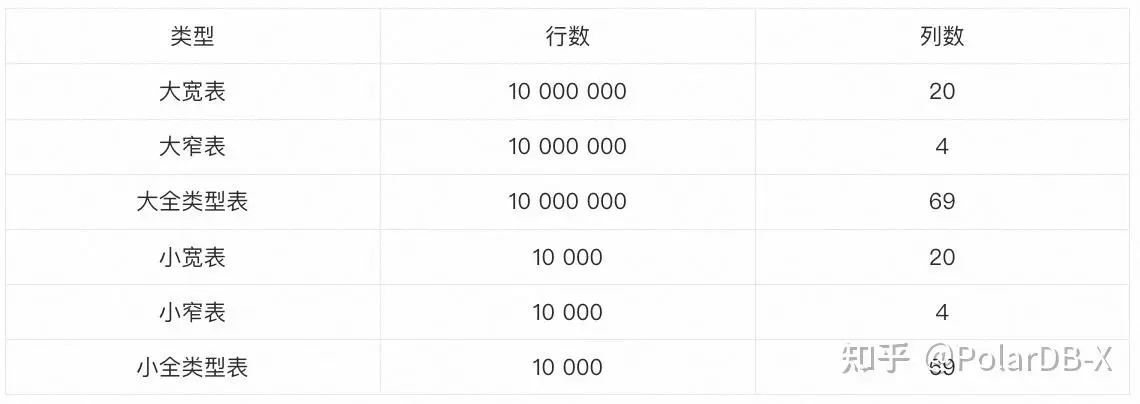
本项目对这些表预设了若干索引(包括全局二级索引,本地索引,复合索引,覆盖索引等等),这里以大全类型表为例:
GLOBAL INDEX /* c_int_32_idx_$226c */ `c_int_32_idx` (`c_int_32`)
PARTITION BY KEY(`c_int_32`,`id`)
PARTITIONS 32,
GLOBAL INDEX /* c_mediumint_24_idx_$1b0e */ `c_mediumint_24_idx` (`c_mediumint_24`) COVERING (`c_datetime`, `c_timestamp`)
PARTITION BY KEY(`c_mediumint_24`,`id`)
PARTITIONS 4,
GLOBAL INDEX /* c_varchar_idx_$7385 */ `c_varchar_idx` (`c_varchar`)
PARTITION BY KEY(`c_varchar`,`id`)
PARTITIONS 32,
LOCAL KEY `_local_c_varchar_idx` (`c_varchar`),
LOCAL KEY `_local_c_int_32_idx` (`c_int_32`),
LOCAL KEY `c_datetime_idx` (`c_datetime`),
LOCAL KEY `_local_c_mediumint_24_idx` (`c_mediumint_24`),
LOCAL KEY `c_char_c_date_idx` (`c_char`, `c_date`),
LOCAL KEY `c_smallint_16_c_smallint_16_copy_idx` (`c_smallint_16`, `c_smallint_16_copy`)
查询
查询分为两类:固定查询和随机查询。 固定查询:固定查询是根据用户反馈的一些线上问题进行分析排查后得到的一些查询语句,其在CEST中得到了复现,我们希望每次运行CEST时都检查一遍,以确保这些问题被彻底修复。 固定查询又分为若干类,例如:
- 热点索引:数据访问存在较大倾斜时,索引选择策略可能发生错误。
- 分区索引:索引建立时分区不合理,如仍然使用主表主键做拆分,可能导致索引错选。
随机查询:随机查询是根据一些预先定义好的查询模版,结合数据生成器对其进行随机。随机查询的初衷是希望能够在用户发现问题前由研发同学首先发现,起到一个未雨绸缪的效果。 随机查询又分为若干类,例如:
- 随机单点查询:
- 挑选列:先随机列的个数,然后再随机具体列
- 挑选值:从值集合中使用和创建值相同的zipf分布进行随机挑选
- 挑选符号:目前是随机从 {,=,>=,
- 随机聚合查询:
- 随机从五个agg算子”count”, “sum”, “max”, “min”, “avg” 中选一个
- 随机挑选一个列做agg运算
- 随机挑选一个列做groupby
- 再随机加上where条件
以具体的一条随机聚合查询SQL为例,其随机过程如下图所示:

注意到,图中包含以下部分:
- 算子集:count,sum,max,min,avg
- 列集:根据表结构和算子要求生成
- 表集:来自具体用例的查询要求以及默认表集合
- 符号集:
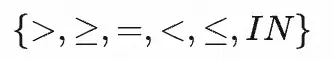
- 数据生成器:上文提到的若干的类型数据生成器,这里的数据可能在表中存在也可能不存在
混沌行为发生器
混沌行为发生器会在查询进行的过程中随机对PolarDB-X产生下列影响之一:
- 计算节点宕机:让若干个计算节点重启其自身。
- 缓存清空:之前缓存的执行计划丢失,必须重新走优化器产生
- 统计信息清空:包括各个列的基数估计结果丢失,这意味着索引选择策略可能完全失效
评估器
在测试过程中,主要关注优化器的各种估算行为是否准确,索引选择是否合理等(我们仅关注那些响应时延>100ms的SQL):
- 响应时间:如果开启/关闭索引选择的响应时间的绝对误差大于1s,或者相对误差超过2,则认为此sql的索引选择不合理,若记开启索引选择时的响应时间为T’,关闭索引选择时的响应时间为T,则误差计算如下:

- 扫描行数:优化器估算扫描行数的精准性决定了索引选择的合理性,使用q-error来评估此误差,现认为q-error大于10时的优化器估算不合理。若记开启优化器估计的行数为C’,真实扫描行数为C,则误差计算如下:
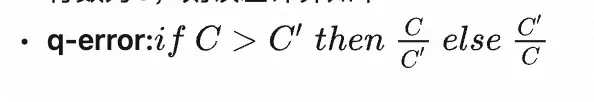
日志
在查询结果经过评估器评估后,其将被输出到日志中,日志中将详细描述评估器的评估过程和评估结果。若该查询是一个问题查询,评估器还会给出错误类型。 日志中还包含了一个种子(seed)。种子是唯一控制CEST中所有随机行为的参数。种子的一致确保了结果的可复现性。
实验结果
表生成工具测试
测试过程:生成一个小窄表观察,并且在不同的列中有不同的数据倾斜,数据分布采用zipf分布,观察其每列的数据分布情况。 实验结果绘制成了下面四张图。四张图展示了表各列中项的出现频次(经过排序后)。每张图的横轴表示一个个独立的项,而纵轴则表示该项的出现频次。
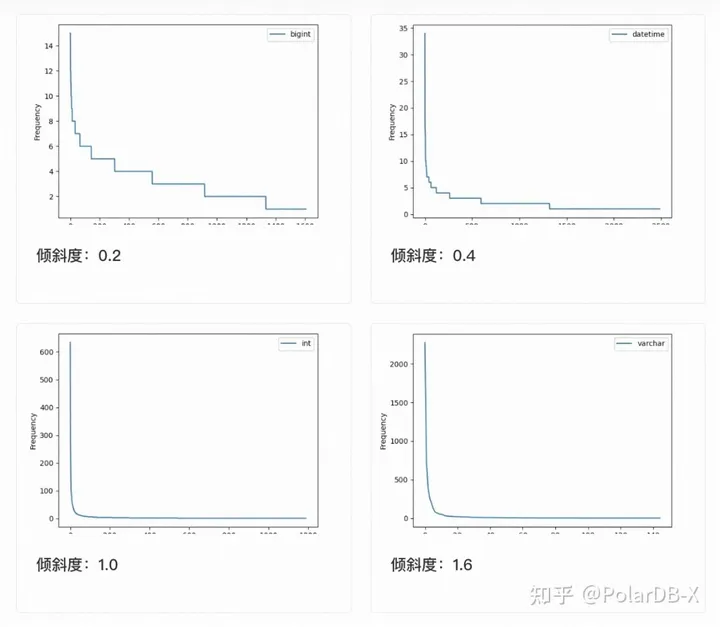
实验结果:
- 倾斜度-1.6:项的热度差最大为2000
- 倾斜度-1.0:项的热度差最大为600
- 倾斜度-0.4:项的热度差最大为35
- 倾斜度-0.2:项的热度差最大为15
结论:
- 数据分布为Zipf分布,且随着倾斜度降低而逐渐趋向均匀分布。
固定查询实验
固定查询是我们对线上暴露出来的问题进行分析,排查后复现在实验室的一类查询。这次实验的目的是为了验证CEST项目是否能够真的复现一些线上问题。 实验过程:在CEST中执行一些线上暴露的问题SQL,观察其是否超出设立的索引错选指标阈值。 实验结果如下表所示(AE表示绝对误差,RE表示相对误差):
| 原因 | 错选代价 |
| 本地索引热点 | AE=3001ms |
| 全局索引热点 | AE=29299ms |
| 全局索引和主表分区数不一 | RE=5.27 |
| 复合索引作为过滤条件 | RE=13.57 |
| In 查询过滤条件重复 | AE=3268ms |
| 全局索引分区键与主表一致 | AE= 3940ms |
我们以全局索引热点为例,分析其错选的原因。SQL如下所示:
# 查询1: varchar为冷 int为热,两列均有全局二级索引
select * from cest_full_table_big
where c_varchar = '019'
and c_int_32 = 1726763517;
# 响应时间:0.01s
# 查询2: int为冷 varchar为热
select * from cest_full_table_big
where c_varchar = '666cd17d'
and c_int_32 = 1507600269;
# 响应时间:2.29s
# 查询2(无缓存): int为冷 varchar为热
/*+TDDL:extra_cmd(enable_index_selection=false)*/
select * from cest_full_table_big
where c_varchar = '666cd17d'
and c_int_32 = 1507600269;
# 响应时间:0.01s
# 观察两次sql走的索引
explain select * from cest_full_table_big
where c_varchar = '019'
and c_int_32 = 1726763517;
# 显示使用VARCHAR全局二级索引
explain select * from cest_full_table_big
where c_varchar = '666cd17d'
and c_int_32 = 1507600269;
# 显示使用VARCHAR全局二级索引
执行SQL的过程中,不难发现两个问题:
- 无缓存的查询2比有缓存的查询2快了很多
- 观察两次explain的结果,发现执行计划索引相同,都是以VARCHAR为索引
首先分析问题2: 查询1选择VARCHAR全局二级索引非常合理,因为VARVCHAR的值为冷,从GSI返回主表的行数非常少,因此可以加快查询效率。查询2选择VARCHAR全局二级索引则不尽然,因为此时VARCHAR为热,从GSI返回主表行数就多得多了,从而导致高回表代价。更进一步的,查询2应该选择INT全局二级索引,提高过滤性的同时降低回表代价。 再结合问题1,我们大致就可以下结论了,原来是因为缓存中有查询1的模版和查询1的执行计划,认为该模版下所有的查询都应该走VARCHAR全局二级索引加速查询。查询2和查询1的模版相同,因此仍然沿用查询1的执行计划,从而导致索引错选,引发慢SQL问题。
另一类SQL错误是优化器误估。同样在CEST中执行一些线上暴露的问题SQL,观察其是否超出设立的优化器误估的指标阈值。实验结果如下表所示:
| 原因 | Q-Error |
| Join 使用OR作为过滤条件 | 421098.56 |
| JoinON连接类型不一 | 194925243 |
| Join 连接条件置后 | 21922.75 |
| 过滤条件相关性强 | 121652.63 |
可以发现优化器误估错误也比较严重。
随机查询实验
实验内容:发起随机单点,聚合查询各1000次,观察索引错选SQL占比。
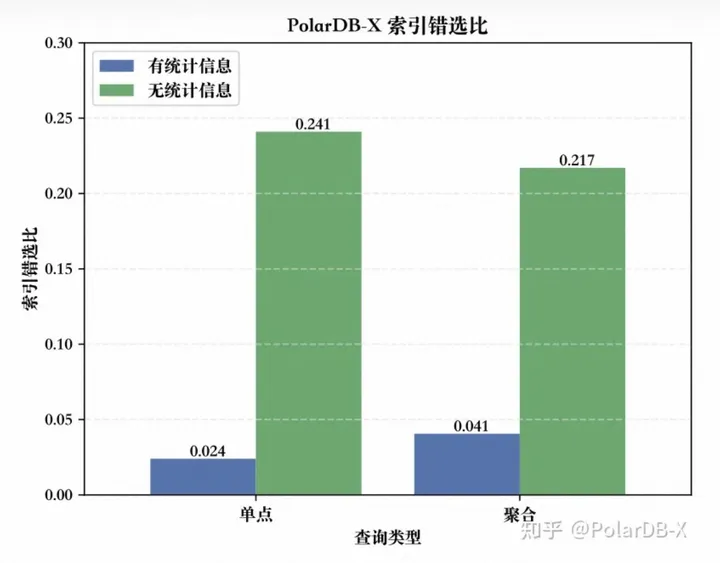
实验结果(在有无统计信息两种场景下):
- 点查:索引错选率分别为2.4%,24.1%;
- 聚合:索引错选率分别为4.1%,21.7%;
可以看出,实验室的随机SQL能够发现潜在的新索引错选问题,统计信息的缺失会大幅加剧索引错选。本次试验中发现的问题初步分为三类:计算/存储节点行为不一致,代价模型误估,统计信息不足。 通过几个例子对新发现的问题进行简要分析。如下,是一个简单的大小两表join的SQL。其链接条件和过滤条件都是全局二级索引列。
select count(*) from t_s as A inner join t_b as B on A.c_int_32 = B.c_int_32 where B.`c_int_32` >= '577509755';
该SQL的执行计划如下:
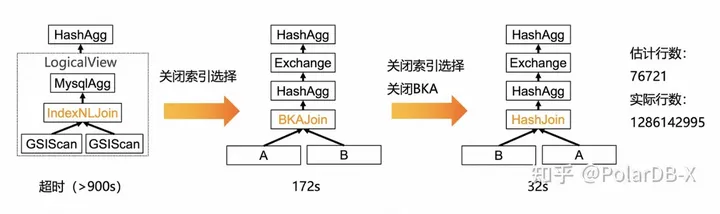
在默认情形下,优化器将Join下推到了存储节点的Mysql中,而Mysql则使用了INdexNLJoin算子,结果查询超时。之后,关闭索引选择,同样的查询,优化器选择使用BKAJoin对A,B两表进行Join,结果查询响应时间为172s,虽然没有超时,但仍然不是最好的执行计划。之后,我们再关闭BKAJoin,优化器选择使用HashJoin,查询时间降到了32s。
在一系列的操作之后,优化器才选择出了预期的执行计划,这背后发生了什么呢?首先,优化器生成第一个执行计划的原因是其认为Mysql-5.7支持HashJoin,从而其将Join下推到Mysql中进行。事实上,存储节点的Mysql-5.7不支持HashJoin,因此采用了NLJoin,从而查询超时。其次,为什么在关闭索引选择后,优化器没有使用HashJoin,反而生成了一个使用BKAJoin的执行计划呢?这是由于优化器错误的估计了Join的行数导致的。优化器估计Join的行数为76721,实际上却是128642995。若Join行数较少,选择BKAJoin确实不是一个坏的执行计划,然而实际行数却很多,就导致HashJoin才应该是最优执行计划。
接下来来看一个问题更加严重的SQL
select count(*) from t_s as A inner join t_b as B on A.c_varchar = B.c_varchar where B.`c_int_32` >= '577509755';
该SQL执行计划如下:
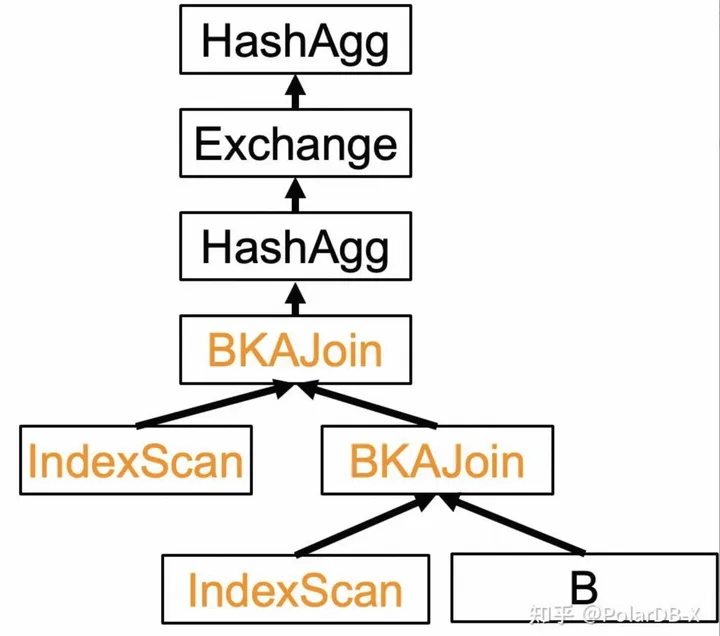
该执行计划非常特殊,是一个双重BKAJoin。首先,它将B表的GSI表和主表做了一个BKAJoin。之后,将结果和A表的GSI表再做一次BKAJoin。最后进行一个两阶段Agg。如果关闭索引选择,则执行计划变成一个普通的HashJoin。
在默认情况下,此执行计划将报错:impossible: sharding column not found. 经过分析,该报错是由于BKAJoin下发IN查询时需要尽量向有目标数据的分片发送。在此过程中需要用到某个分片列信息,此时未找到该列引发报错。
总结
本文介绍了一个基于业务场景面向优化器索引选择的混沌查询测试器(CEST),旨在解决优化器误估和索引错选问题。通过模拟复杂的线上环境,生成类似于用户行为逻辑的数据和访问模式,对优化器的估计和索引选择策略进行评估。本文介绍了CEST的挑战和目标,包括如何使得CEST的数据与行为与业务逻辑相似,如何保证CEST的可复现性和可解释性,以及如何保证CEST的易用性。之后,本文对CEST进行了一系列的实验,展示了其数据分布,固定查询和随机查询的实验效果,验证了其不仅可帮助复现线上问题,也能帮助提前暴露问题。 本文提出的方案为CEST的第一步,后续进一步的工作我们打算集中在:
- 数据生成模拟:目前生成的数据基于Zipf分布模式,配备有不同的倾斜度。虽然与大多用户访问模式类似,但仍然有可能无法复现部分比较特殊的问题。后续计划扩大表格的设计参数规模,并支持根据特定用户表模拟生成更多数据的功能。
- 混沌模拟行为:目前的混沌行为还不算特别多,后续工作可以加入网络抖动,磁盘空间不足,内存不足等的混沌行为。
- 问题算子定位:目前发现问题的手段比较直接—观察几个预定义指标:响应时间的误差和代价的估算误差。响应时间容易受到网络抖动的影响,代价估算则容易受到SQL复杂度的影响,都在一定程度上会引起误报警。后续除了观察更加丰富的指标之外,也可以智能地分析问题SQL的执行计划图,让报警日志将问题定位到算子级别。
- 强化索引选择评估器: 目前的索引选择的评估是通过开关索引选择功能,比较被选索引的性能差异来实现的。将来希望能全程打开索引选择, 通过如搜索可能的索引空间,比较这些索引性能的方式,准确评估出选择的索引是否符合预期。
相信未来的CEST可以做到数据行为与线上场景更加相似,查询环境更加多样化,问题定位排查更加智能化。
作者:子勉
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。
