


一、环境介绍
本文环境,以及本文所采用数据库为GreatSQL 8.0.32-24
$ cat /etc/system-release
Red Hat Enterprise Linux Server release 7.9 (Maipo)
$ uname -a
Linux gip 3.10.0-1160.el7.x86_64 #1 SMP Tue Aug 18 14:50:17 EDT 2020 x86_64 x86_64 x86_64 GNU/Linux
$ ldd --version
ldd (GNU libc) 2.17
在上篇[图文结合丨Prometheus+Grafana+GreatSQL性能监控系统搭建指南(上)]中介绍了如何搭建监控系统,本文将介绍如何使用Grafana平台以及AlertManager模块的告警功能
二、Grafana之邮件告警
这里我们以邮件告警并使用QQ邮箱为例
1.开启邮件服务
登录QQ邮箱后,点击设置->账号->开启POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务

我已经开启了,若没有开启可以开启一下,接着点击生成授权码,记得保存好授权码,接下来修改grafana邮箱配置
$ vim /usr/local/prometheus/grafana-10.1.1/conf/defaults.ini
使用/smtp找到邮件设置的区域,按下图示例修改

重启Grafana服务
$ systemctl restart grafana-server.service
接下来登录Grafana网页http://172.17.137.104:3000/,添加邮件告警
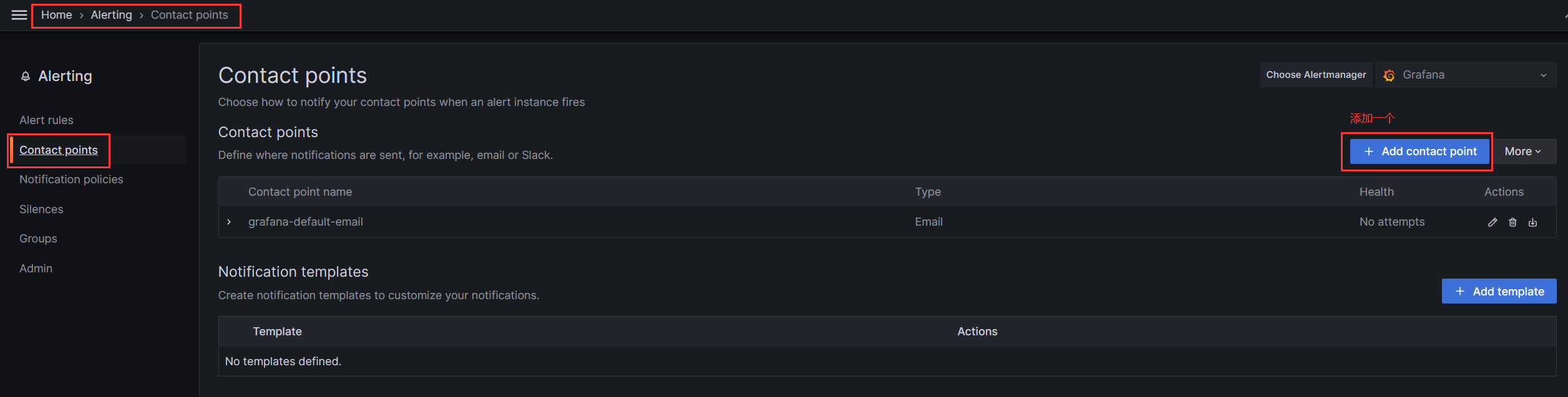
填写Name,Addresses等信息后点击Test测试下
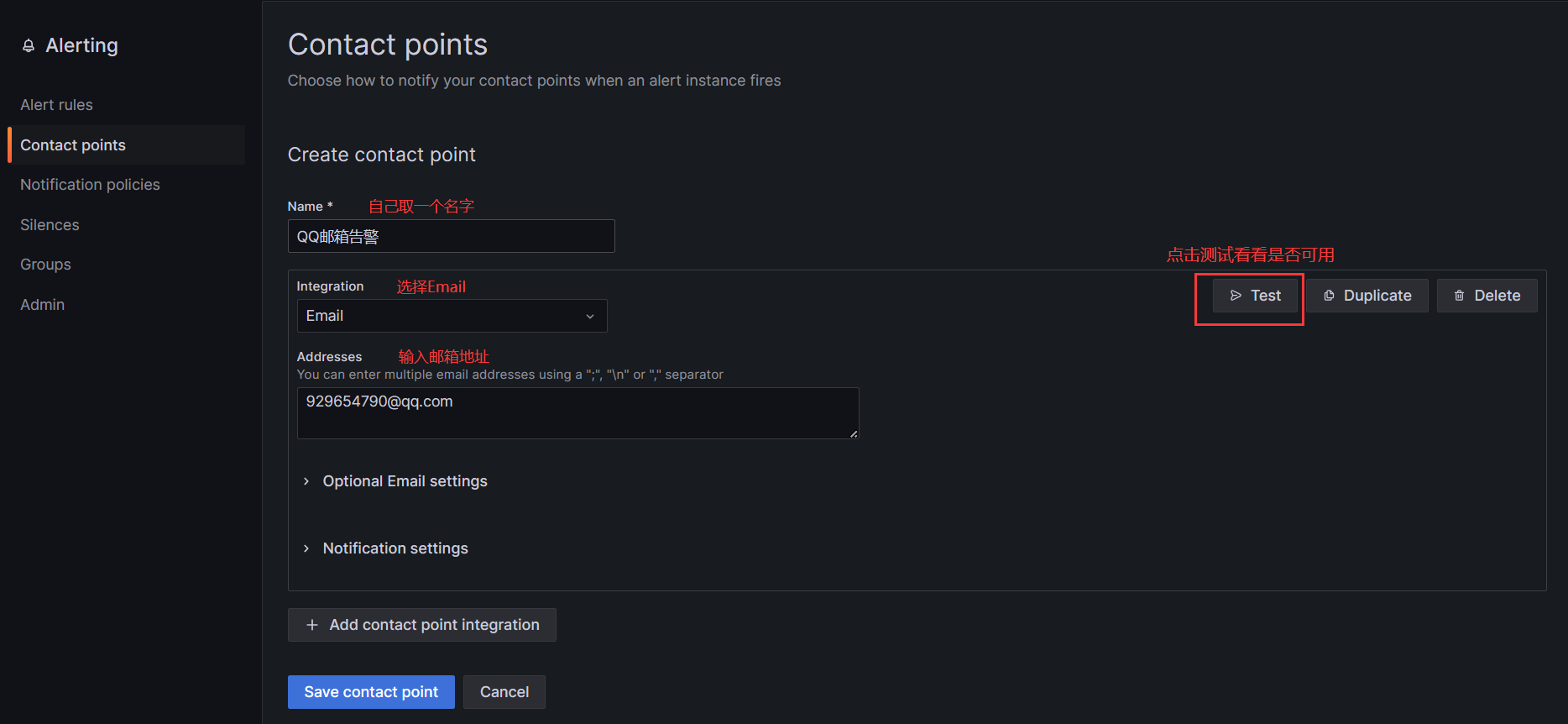
可以看到已经收到邮件,测试成功
2.添加告警规则
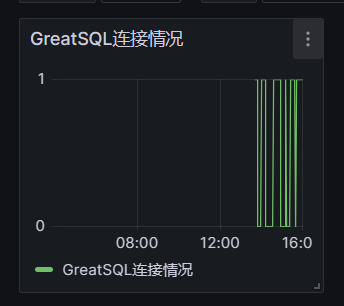
可以在Grafana中添加告警规则,例如我创建了一个GreatSQL连接情况,它监测是的mysql_up这个值,若为0则连接不上GreatSQL了
进入编辑面板,可以看到有一个Alert的告警选项,随后我们点击Create alert rule from this panel
这时候就会进入告警规则设置面板
首先我们来介绍下第一部分设置警报规则名称,就是设置告警的规则名字

(第一部分)
第二个部分就是我们在外面展示的数据情况,在Expressions往下就是设置告警条件
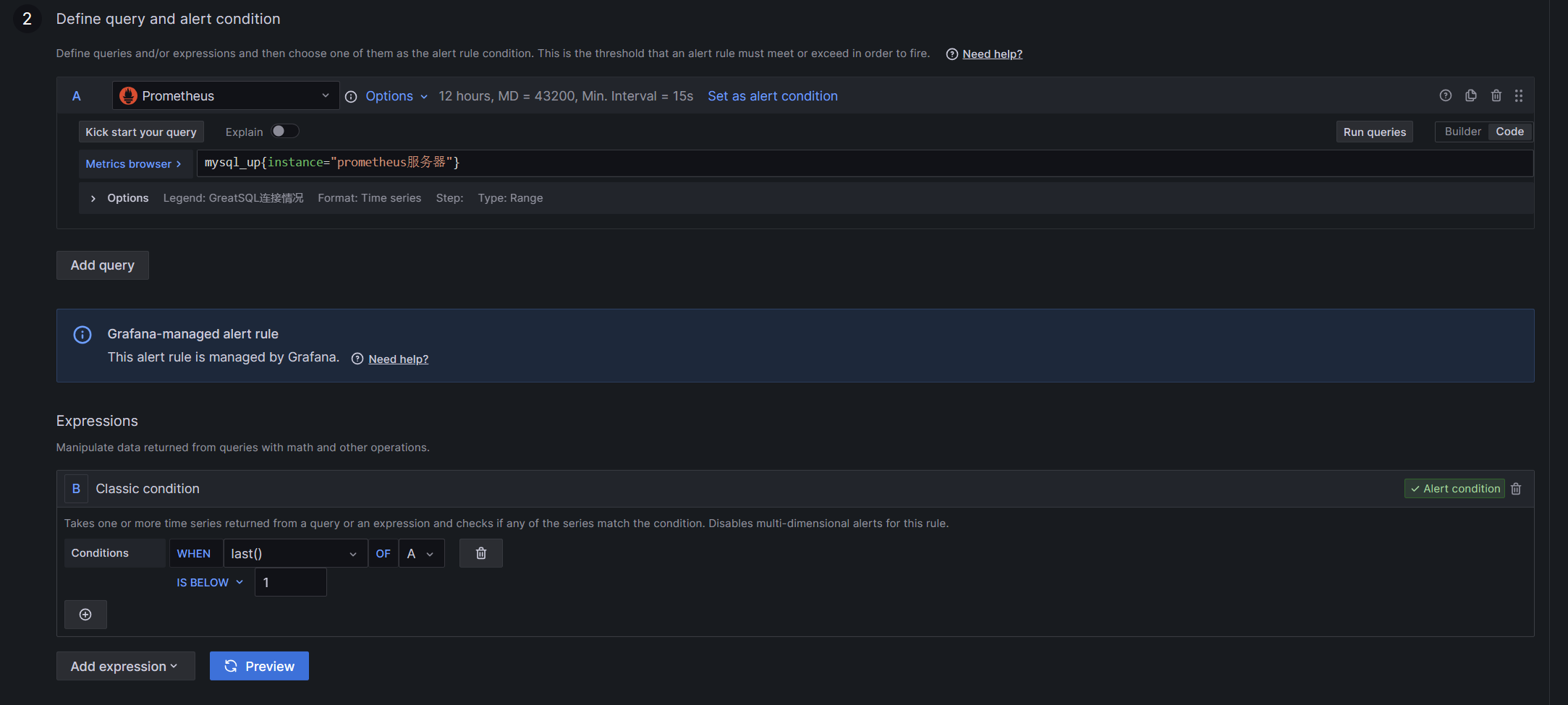
(第二部分)
第一项last()表示最新数据,还有很多其他选项如max()表示最大值,一般我们选择last()
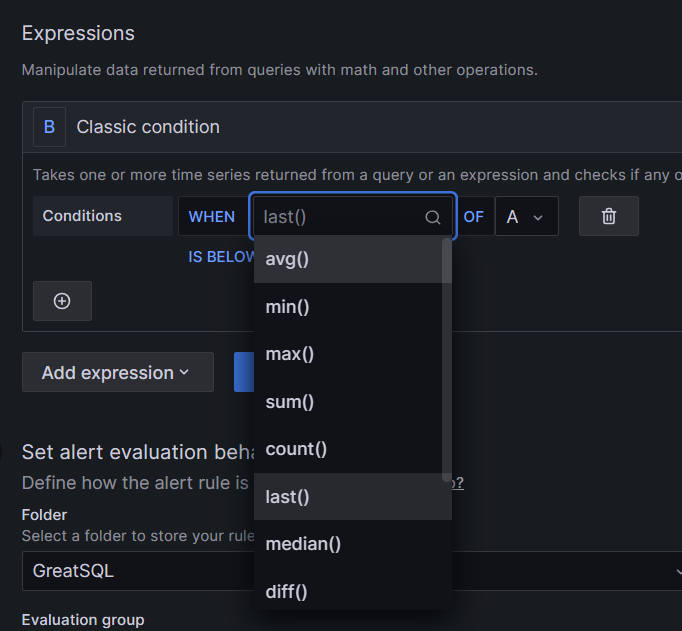
第二项就是表示我们来自哪个查询,因为我们只有一个所以选择A
第三项则标识我们要监控的值达到多少触发,触发判断是前面的选项,如图中的IS ABOVE则表示在这之上,还有其他几个选项如IS BELOW在这之下、IS OUTSIDE RANGE超出范围、IS WITHIN RANGE在范围内、HAS NO VALPUE无值。此处我们选择IS ABOVE,表达式综合就是:当mysql_up值小于1则触发。
第三部分是创建要储存规则的文件夹Folder以及评估的组Evaluation group同一组中的规则将在同一时间间隔内按顺序进行评估

(第三部分)
其中Pending period表示触发告警后延迟多长时间
第四部分用于添加注释Summary摘要对发生的事情和原因的简短总结,Description说明警报规则功能的说明,Runbook URL运行手册网址用于保存警报运行手册的网页

第五部分配置通知,用于添加自定义标签以更改通知的路由方式,如果没有设置匹配策略的话,则所有警报实例都由默认策略处理

点击右上角保存规则后,可以在页面中看到刚刚设定的告警规则

3.测试邮件告警
现在模拟GreatSQL宕机,看看会不会触发告警规则从而发送邮件报警
$ systemctl stop greatsql
因为我们设置的是1分钟,所以要1分钟以后才会再次检测GreatSQL的连接状况
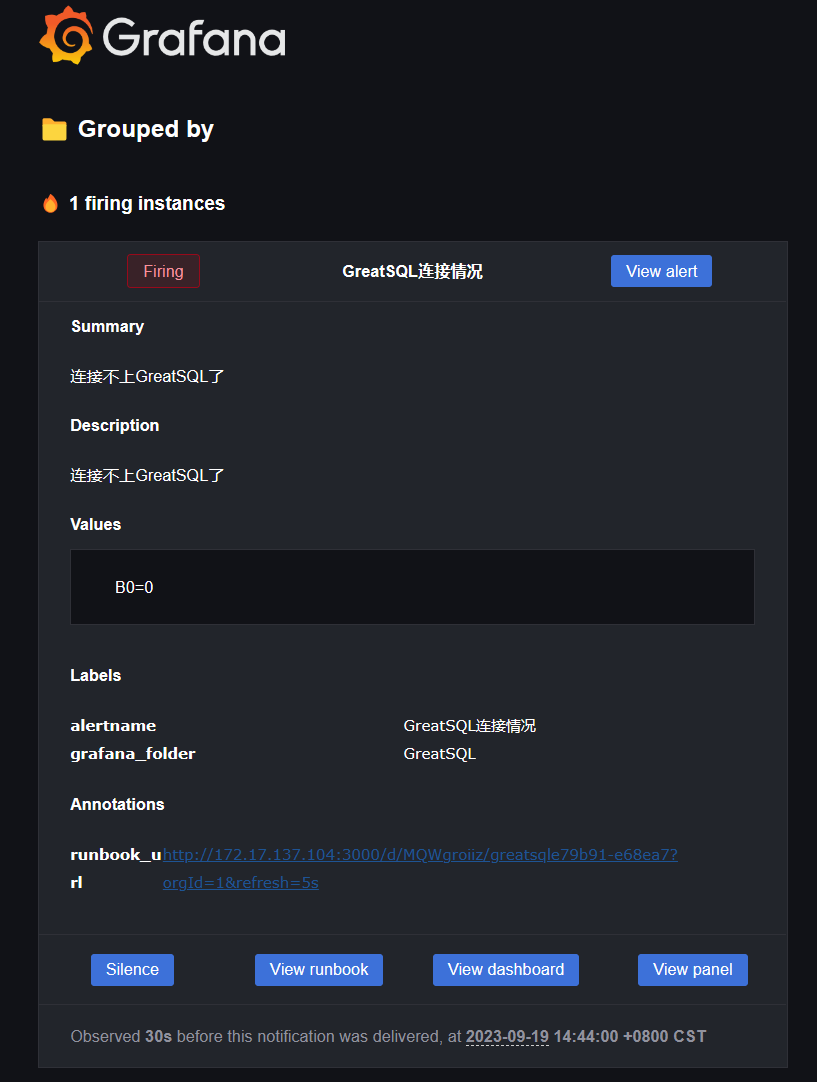
下图可以看到,已经检测到GreatSQL连接不上了,进入待定状态

过了设定的延迟时间,显示Firing表示已经发送邮件
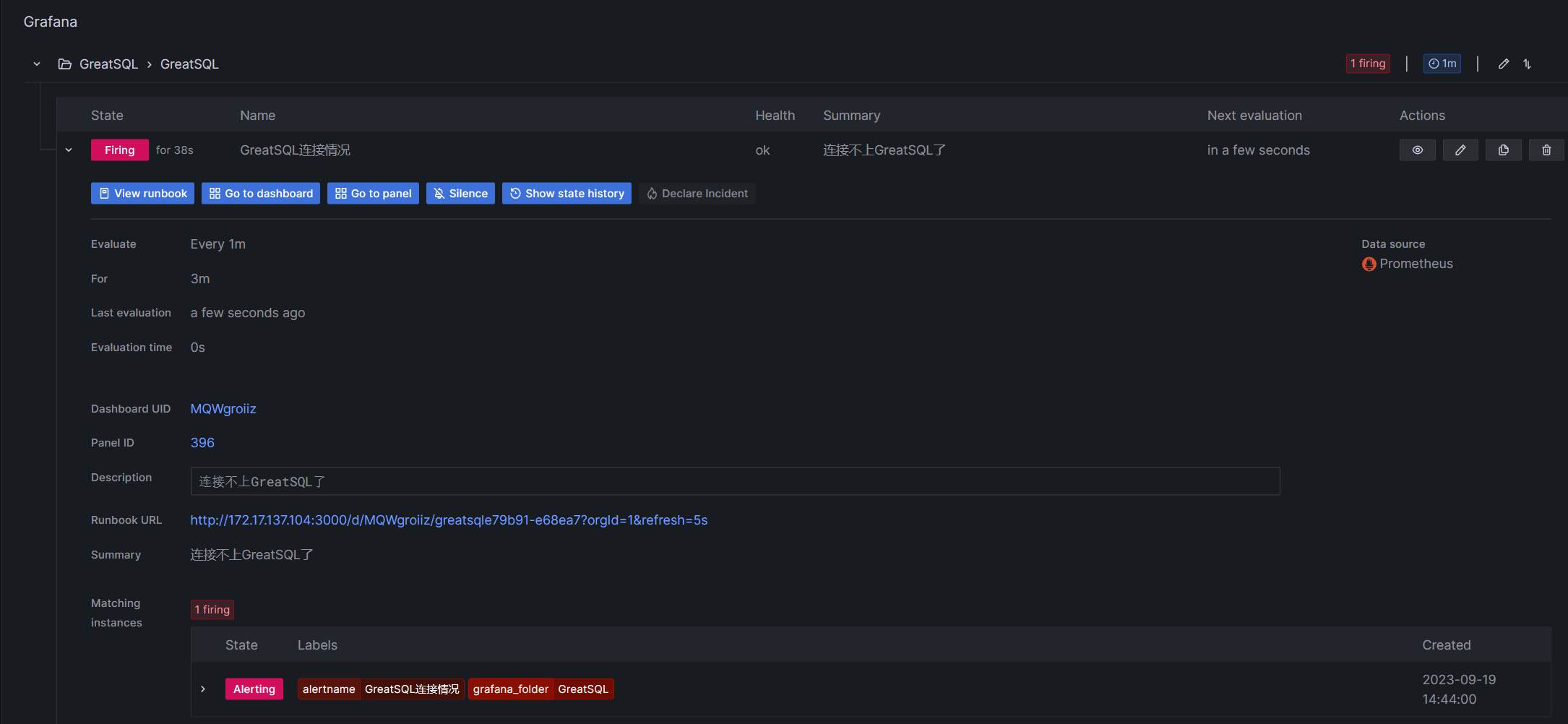
可以看到QQ邮箱中已经收到了告警邮件
接着我们把GreatSQL再次启动起来
$ systemctl start greatsql
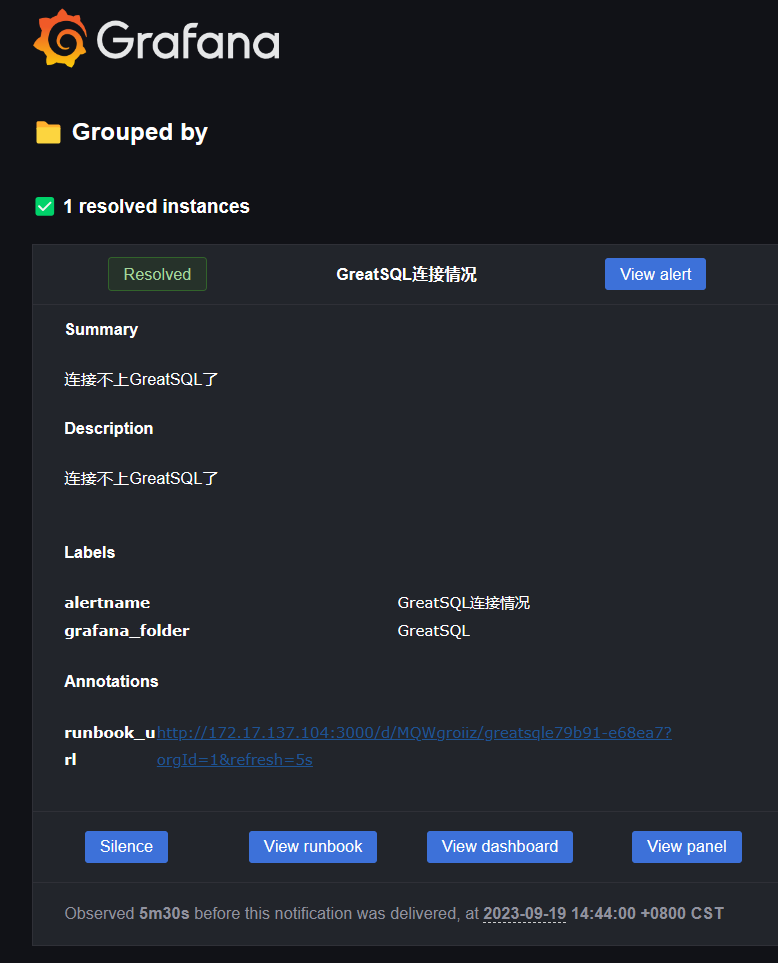
当你解决完成以后,还会收到一封已解决的邮件1 resolved instances
三、Grafana之钉钉告警
在之前的文章中已经提到了使用钉钉告警Prometheus+Grafana+钉钉部署一个单机的MySQL监控告警系统,但是使用的是Alertmanager是普米的告警模块,并不是Grafana,所以这里在介绍下如何用Grafana配置钉钉告警。
不过钉钉在2023年9月1日起,非内部群和内部群均不再支持创建自定义机器人,你需要登录钉钉开发者后台,申请开发者权限后,创建企业内部应用机器人,具体方法这边就不介绍了,需要的可以去钉钉上看详细介绍
按Prometheus+Grafana+钉钉部署一个单机的MySQL监控告警系统中的方法,先创建好钉钉机器人,接着到Grafana中添加Contact points联络点

接下来填入Name、Integration下拉框中找到DingDingURL中填入钉钉机器人的Webhook:
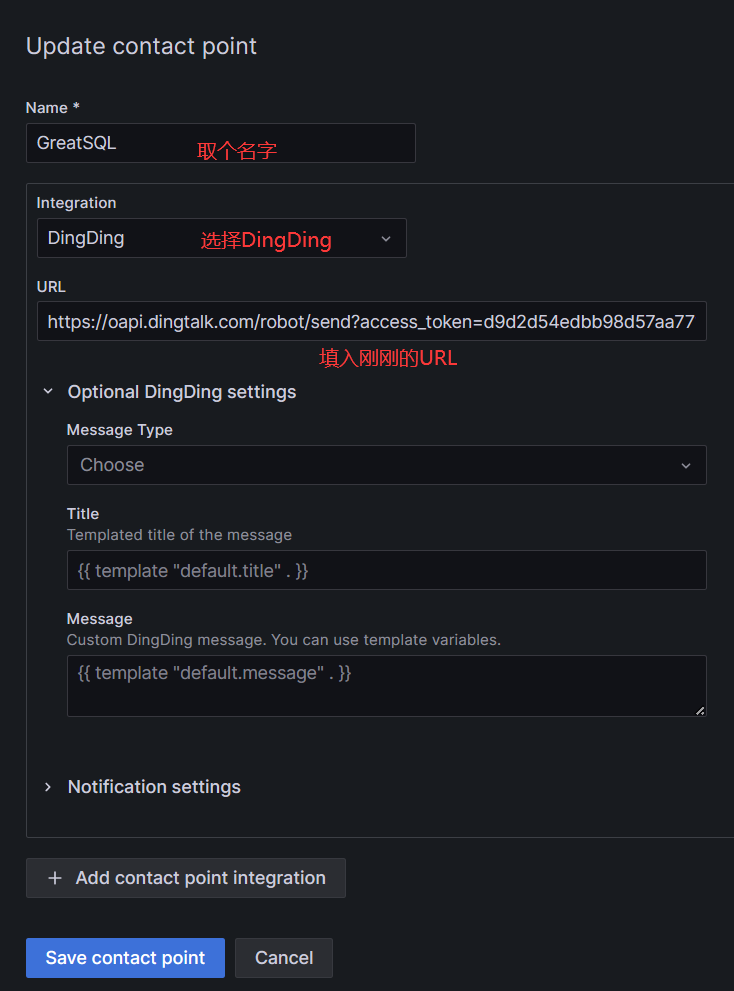
Message Type有两个选项,一个是卡片的模式,一个是链接的模式,以及Title标题和Message消息,接着点击Test测试一下,看看是否可以发送告警信息,这时候钉钉机器人就会发送告警测试,没问题就点击下方蓝色的Save contact point
如果要选择钉钉告警,可以在选项Notification policies中选择Edit
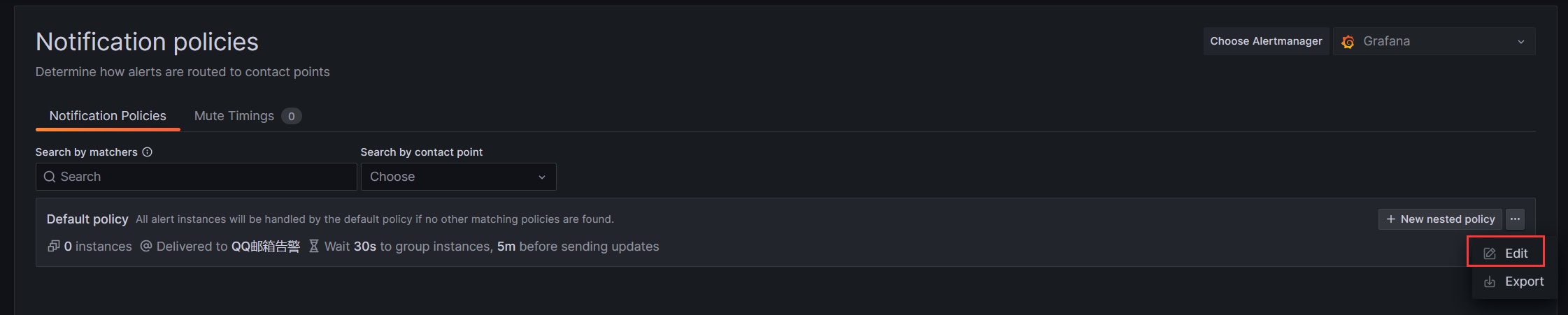
把Default contact point修改为钉钉告警的方式,修改好点击Update default policy
接下来测试下,我们把GreatSQL模拟关闭,看看是否会发送告警信息
$ systemctl stop greatsql

没问题,成功接收到了告警信息
四、Alertmanager之邮件告警
还记得我们上篇文章安装的Alertmanager吗,其实也具有告警功能。Prometheus 包含一个报警模块,就是我们的 AlertManager,Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等。在上篇中我们也往这里面添加了一些规则,忘记的可以在复读一次上篇,Alertmanager也可以钉钉告警,在Prometheus+Grafana+钉钉部署一个单机的MySQL监控告警系统有介绍,这里就来介绍下Alertmanager之邮件告警
Prometheus触发一条告警的过程
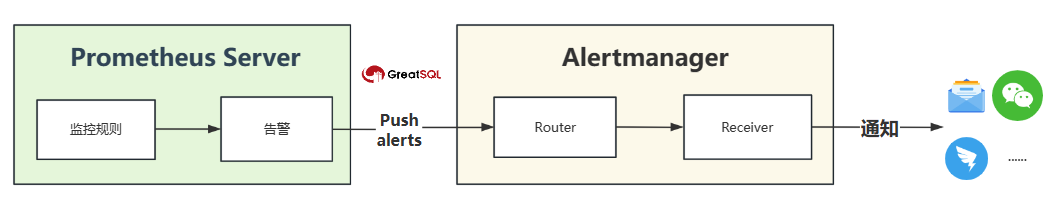
1.配置AlertManager
AlertManager 默认配置文件为 alertmanager.yml,路径为 /usr/local/prometheus/alertmanager-0.26.0.linux-amd64/alertmanager.yml那么,我们就来配置一下使用 Email 方式通知报警信息,这里以 QQ 邮箱为例,配置如下:
global:
resolve_timeout: 5m
smtp_from: '填写邮箱@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '填写邮箱@qq.com'
smtp_auth_password: '填写QQ邮箱授权码'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '填写邮箱@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
yml对缩进有要求,请仔细检查
对重点参数做详细介绍:
global
全局配置,主要配置告警方式,如邮件、webhook等。
-
resolve_timeout:超时,默认5min -
smtp_auth_password:切记QQ邮箱的授权码,非QQ账户登录密码 -
smtp_require_tls:是否使用tls,根据环境不同,来选择开启和关闭。如果提示报错email.loginAuth failed: 530 Must issue a STARTTLS command first,那么就需要设置为 true。着重说明一下,如果开启了 tls,提示报错starttls failed: x509: certificate signed by unknown authority,需要在 email_configs 下配置 insecure_skip_verify: true 来跳过 tls 验证。
route
用来设置报警的分发策略
-
group_by:用于分组聚合,对告警通知按标签(label)进行分组,将具有相同标签或相同告警名称(alertname)的告警通知聚合在一个组,然后作为一个通知发送。如果想完全禁用聚合,可以设置为group_by: […] -
group_wait:当一个新的告警组被创建时,需要等待’group_wait’后才发送初始通知。这样可以确保在发送等待前能聚合更多具有相同标签的告警,最后合并为一个通知发送。 -
group_interval:当第一次告警通知发出后,在新的评估周期内又收到了该分组最新的告警,则需等待’group_interval’时间后,开始发送为该组触发的新告警,可以简单理解为,group就相当于一个通道(channel)。 -
repeat_interval:告警通知成功发送后,若问题一直未恢复,需再次重复发送的间隔。 -
receiver:配置告警消息接收者,与下面配置的对应。例如常用的 email、wechat、slack、webhook 等消息通知方式。
receivers
配置报警信息接收者信息
-
to:接收警报的Email -
send_resolved:故障恢复后通知
inhibit_rules
抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)
配置完成后重启即可systemctl restart alertmanager.service
若启动失败可自行排查
journalctl -u alertmanager.service -f,注意检查缩进问题!
接下来就可以配置AlertManager的告警规则,这个我们也在上篇提到,并且也创建rules文件夹存放规则,所以按上篇方法做即可
2.测试邮件告警
接下来我们登录到http://172.17.137.104:9090/rulesPrometheus的Rules中查看,是不是有添加完成几个告警

这里说明一下 Prometheus Alert 告警状态有三种状态:Inactive、Pending、Firing
-
Inactive:非活动状态,表示正在监控,但是还未有任何警报触发。 -
Pending:表示这个警报必须被触发。由于警报可以被分组、压抑/抑制或静默/静音,所以等待验证,一旦所有的验证都通过,则将转到 Firing 状态。 -
Firing:将警报发送到 AlertManager,它将按照配置将警报的发送给所有接收者。一旦警报解除,则将状态转到 Inactive,如此循环。

接下来我们关闭GreatSQL,使得mysql_up = 0触发告警规则,看看是否会发送告警邮件
$ systemctl stop greatsql
停止服务后,alert 页面由绿色 Inactive 状态变成了黄色 Pending 状态继续等待变成红色 Firing状态,从而向 AlertManager 发送报警信息,此时 AlertManager 则按照配置规则向接受者发送邮件告警

黄色 Pending
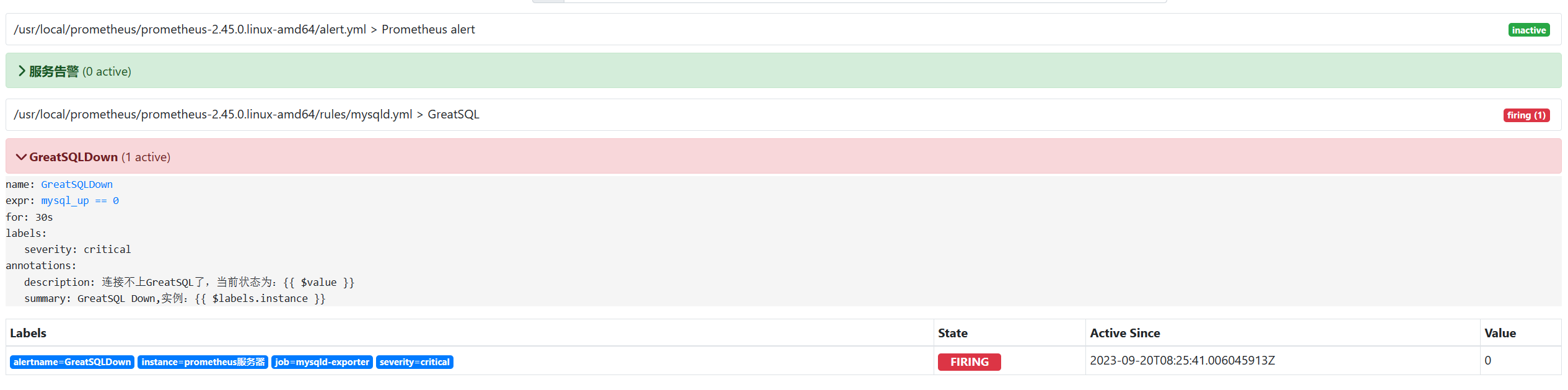
红色 Firing
然后我们就收到了告警邮件
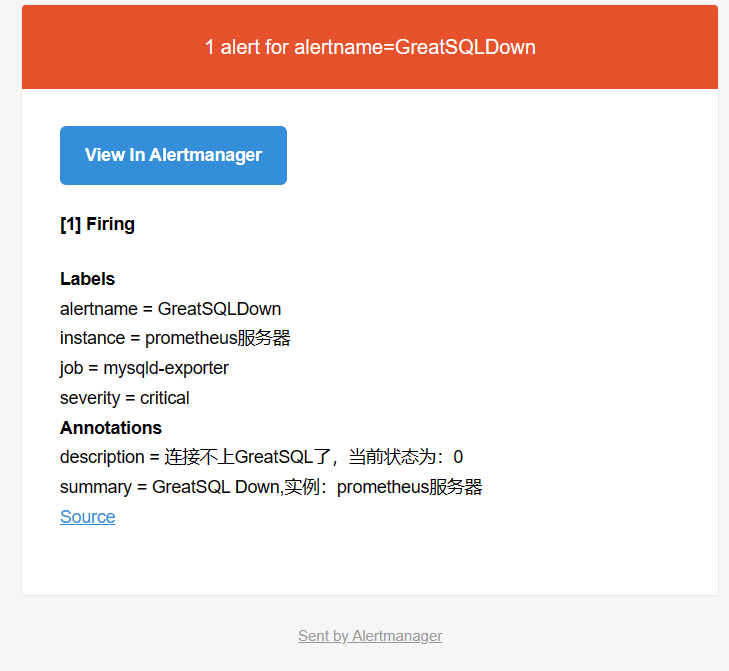
从上图可以看到,默认邮件模板 Title 及 Body 会将之前配置的 Labels 及 Annotations 信息均包含在内,而且每隔 5m 会自动发送,直到服务恢复正常,报警解除为止,同时会发送一封报警解除邮件。
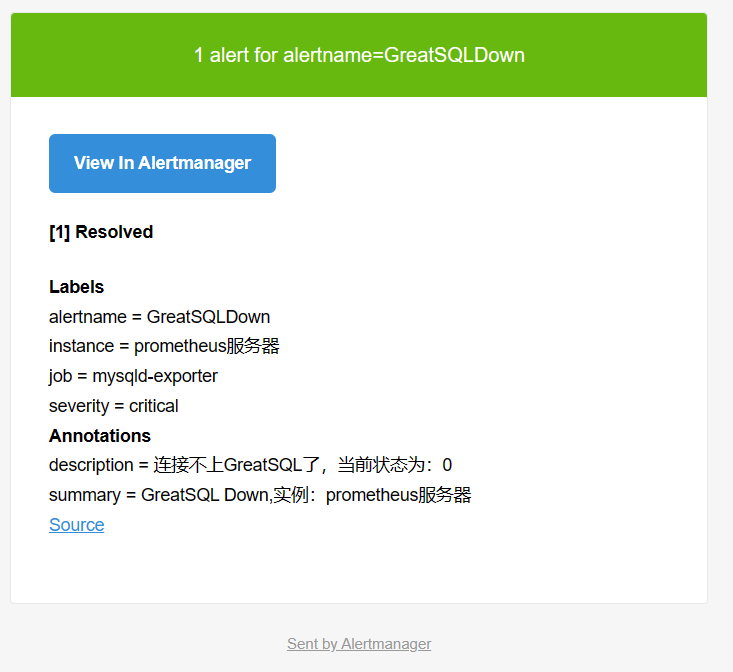
报警触发后,每隔 5m 会自动发送报警邮件(服务未恢复正常期间),是因为 alertmanager.yml 中 route -> repeat_interval: 5m 配置决定的
3.更改AlertManager邮件内容
此步骤非必要,想要邮件内容更优雅直观的可以参考
虽然所有核心的信息已经包含了,但是邮件格式内容可以更优雅直观一些,AlertManager也是支持修改自定义邮件模板配置的
我们需要新建一个模板文件,就叫做email.tmpl
$ vim /usr/local/prometheus/alertmanager-0.26.0.linux-amd64/email.tmp
写入以下内容
{{ define "email.from" }}填入邮箱@qq.com{{ end }}
{{ define "email.to" }}填入邮箱@qq.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
@告警通知
告警程序: prometheus_alert
告警级别: {{ .Labels.severity }} 级
告警类型: {{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
触发时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
@告警恢复
告警程序: prometheus_alert
故障主机: {{ .Labels.instance }}
故障主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
告警时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }}
恢复时间: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- end }}
上边模板文件配置了 email.from、email.to、email.to.html 三种模板变量,可以在 alertmanager.yml 文件中直接配置引用。
这里 email.to.html 就是要发送的邮件内容,支持 Html 和 Text 格式,这里为了显示好看,采用 Html 格式简单显示信息。下边{{ range .Alerts }}是个循环语法,用于循环获取匹配的 Alerts 的信息,下边的告警信息跟上边默认邮件显示信息一样,只是提取了部分核心值来展示。然后,需要增加 alertmanager.yml 文件 templates 配置如下:
$ vim /usr/local/prometheus/alertmanager-0.26.0.linux-amd64/alertmanager.yml
global:
resolve_timeout: 5m
smtp_from: '填入邮箱@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '填入邮箱@qq.com'
smtp_auth_password: '填写QQ邮箱授权码'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates:
- '/usr/local/prometheus/alertmanager-0.26.0.linux-amd64/email.tmp'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '{{ template "email.to" . }}'
html: '{{ template "email.to.html" . }}'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
接着我们模拟GreatSQL宕机,使其触发告警规则,看看是否发送告警邮件

没问题已经成功收到了告警邮件
好啦,Prometheus+Grafana+GreatSQL性能监控系统搭建指南就到此结束,快动手搭建操作下吧~
Enjoy GreatSQL 🙂
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:

社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群:
QQ群:533341697
微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。
