


1 问题回顾
1.1 问题描述
在项目的性能测试中,相关的接口的随着并发数增加,接口的响应时间变长,接口吞吐不再增长,应用的CPU使用率较高。
1.2 分析思路
谁导致的CPU较高,阻塞接口TPS的增长?接口的响应时间的调用链分布是什么样的,有没有慢的点?
1)使用火焰图分析应用的CPU如下,其中log4j2日志占了40%左右CPU,初步怀疑是log4j2的问题。
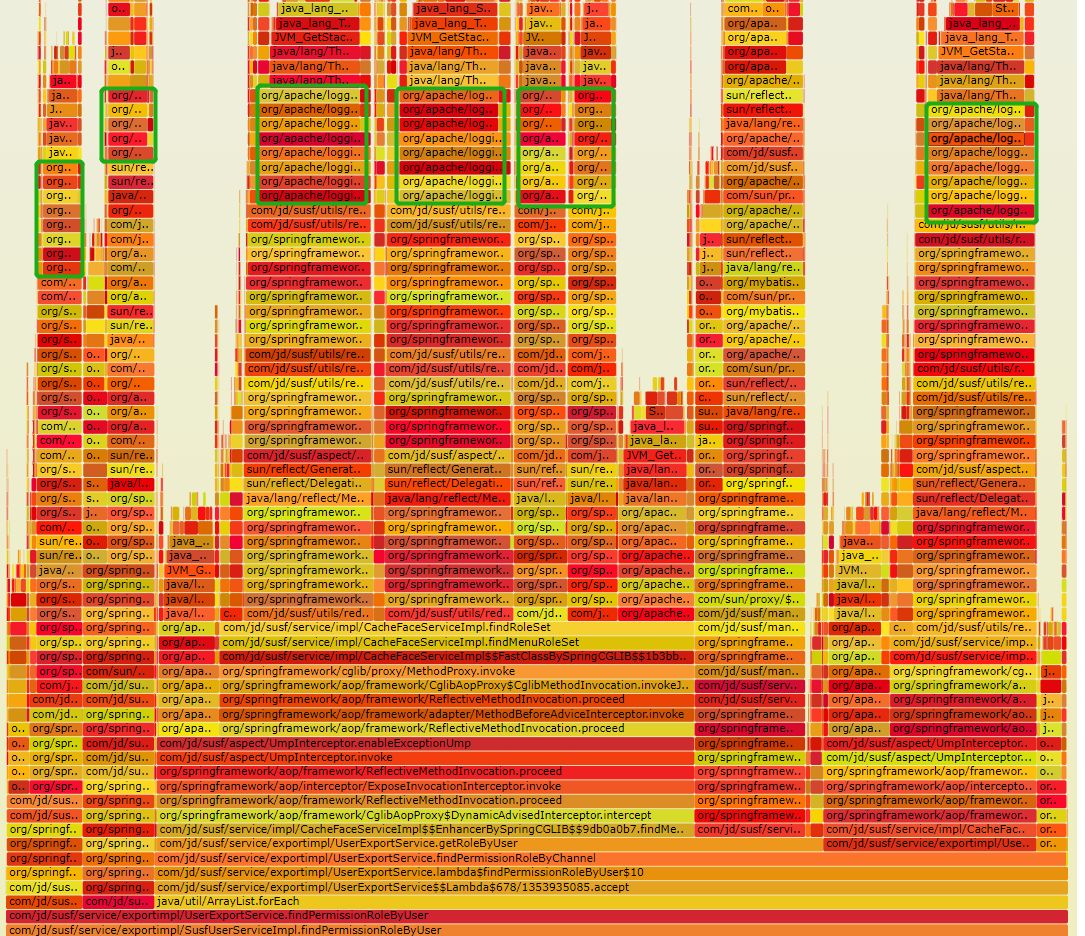
2)调用链的分析
通过pfinder查看调用链发现,接口总耗时78ms,没有明显慢的调用方法和慢sql等,先排除接口的本身的代码问题。
1.3 初步结论
log4j2的问题,需详细分析日志的相关配置log4j2.xml。
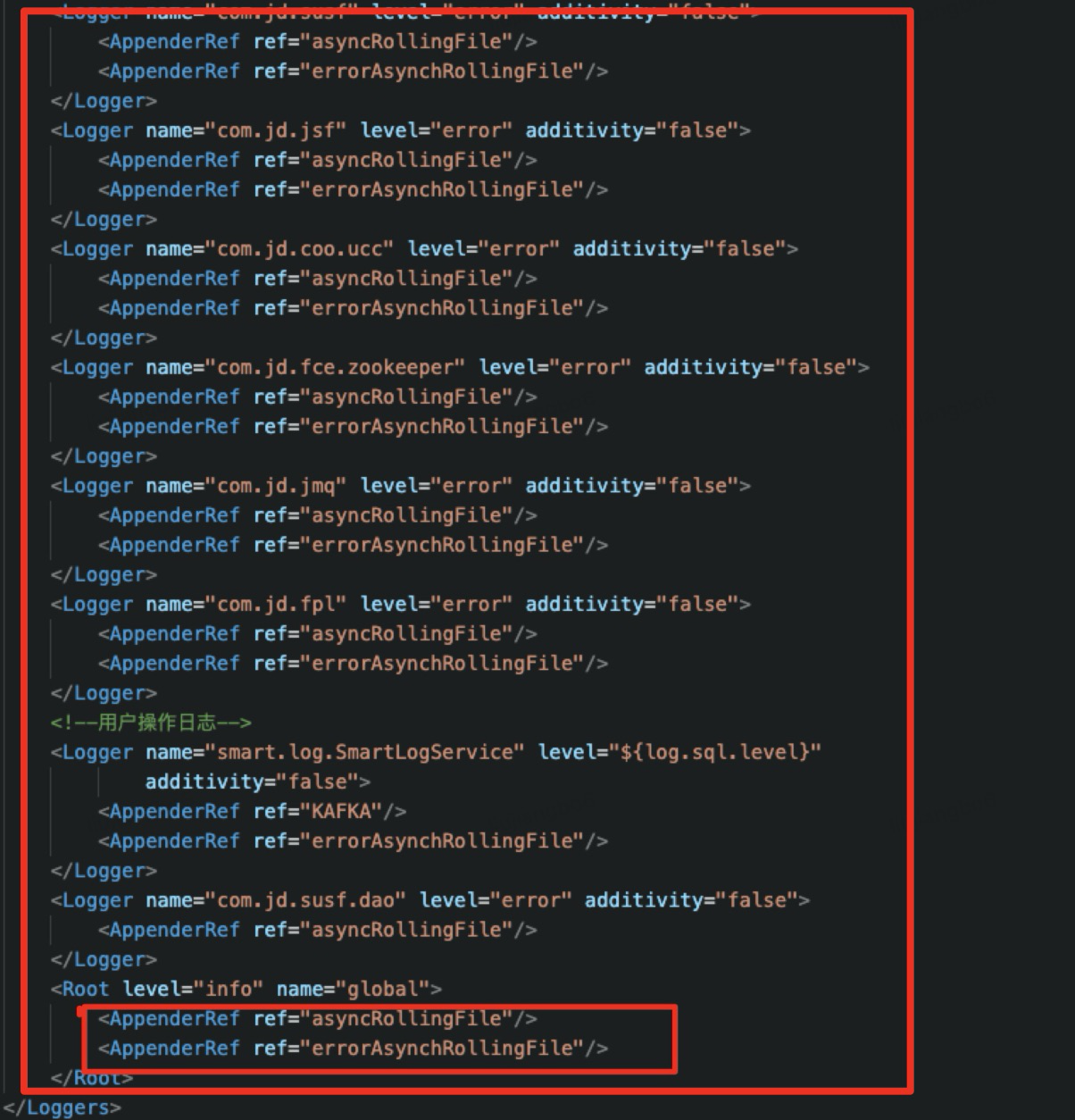
上面可以看到日志中Loggers节点下的节点以及节点都是打印的同步日志。同步日志是程序的业务逻辑和日志输出语句均在一个线程运行,当日志较多,在一定程度上阻塞了业务的运行效率。改成异步日志试一下:
改成异步日志配置:使用AsyncLogger
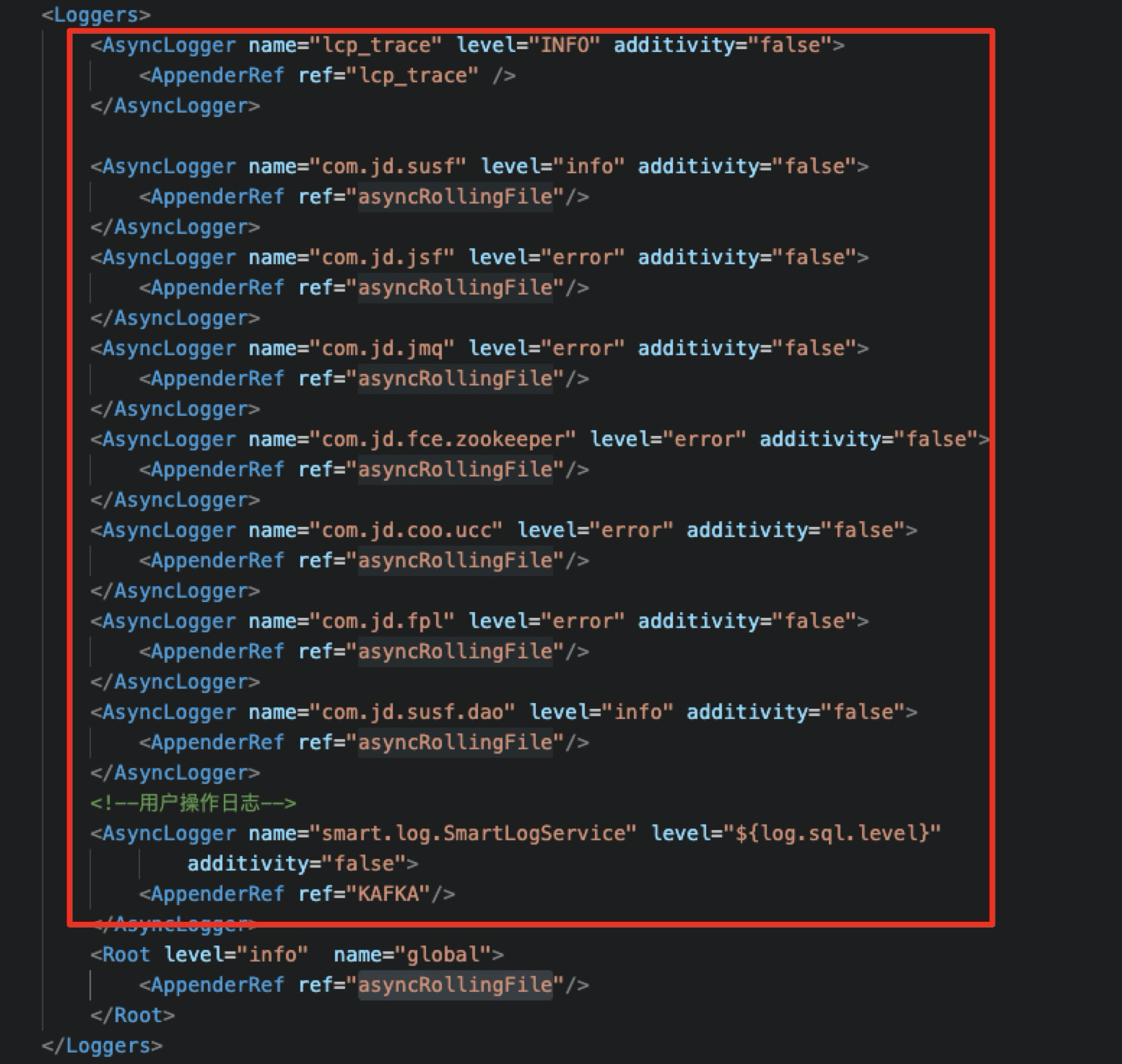
1.4 回归验证

同步日志改成异步日志后。同样10并发,接口的TP99由 51ms 降到 23ms,接口的吞吐TPS由 493提高到 1078,应用的CPU由 82%降到 57%。
完美end。问题解决了,但是log4j2的日志我们还是要详细研究学习一下。
1.5 结论
- log4j2使用异步日志将大幅提升性能,减少对应用本身的影响。
- 从根本上减少不必要日志的输出。
但是log4j2异步日志是怎么实现的和同步日志有什么区别?为什么异步日志的的效率更高?引发我去学习一下log4j2的相关知识,下面和大家分享一下:
2 log4j2日志
2.1 log4j2的优势
log4j2是log4j 1.x 的升级版,参考了logback的一些优秀的设计,并且修复了一些问题,因此带来了一些重大的提升,主要有:
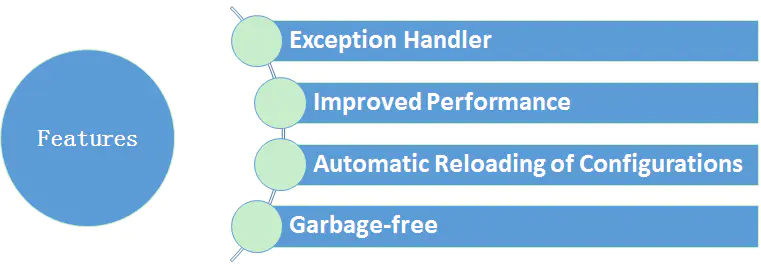
- 异常处理,在logback中,Appender中的异常不会被应用感知到,但是在log4j2中,提供了一些异常处理机制。
- 性能提升, log4j2相较于log4j 1和logback都具有很明显的性能提升,后面会有官方测试的数据。
- 自动重载配置,参考了logback的设计,当然会提供自动刷新参数配置,最实用的就是我们在生产上可以动态的修改日志的级别而不需要重启应用——那对监控来说,是非常敏感的。
- 无垃圾机制,log4j2在大部分情况下,都可以使用其设计的一套无垃圾机制,避免频繁的日志收集导致的jvm gc。
2.2 Log4J2日志分类
Log4j2中记录日志的方式有同步日志和异步日志两种方式,其中异步日志又可分为使用AsyncAppender和使用AsyncLogger两种方式。使用LOG4J2有三种日志模式,全异步日志,混合模式,同步日志,性能从高到底,线程越多效率越高,也可以避免日志卡死线程情况发生。

同步和异步日志的性能对比:
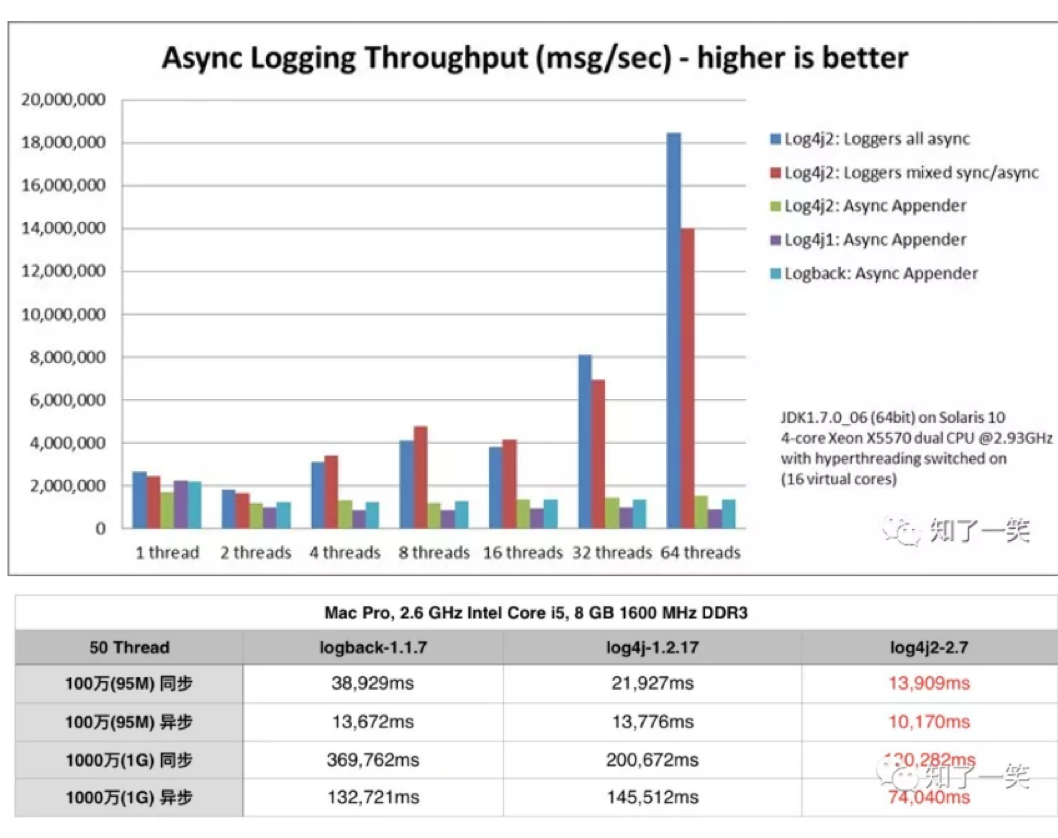
2.3 同步日志
使用log4j2的同步日志进行日志输出,日志输出语句与程序的业务逻辑语句将在同一个线程运行,即当输出日志时,必须等待日志输出语句执行完毕后,才能执行后面的业务逻辑语句。
2.4 异步日志
而使用异步日志进行输出时,日志输出语句与业务逻辑语句并不是在同一个线程中运行,而是有专门的线程用于进行日志输出操作,处理业务逻辑的主线程不用等待即可执行后续业务逻辑。
log4j2最大的特点就是异步日志,其性能的提升主要也是从异步日志中受益,我们来看看如何使用log4j2的异步日志
Log4j2中的异步日志实现方式有AsyncAppender和AsyncLogger两种。
其中:
- AsyncAppender采用了ArrayBlockingQueue来保存需要异步输出的日志事件;
- AsyncLogger则使用了Disruptor框架来实现高吞吐。
注意这是两种不同的实现方式,在设计和源码上都是不同的体现。
2.4.1 AsyncAppender
AsyncAppender是通过引用别的Appender来实现的,当有日志事件到达时,会开启另外一个线程来处理它们。需要注意的是,如果在Appender的时候出现异常,对应用来说是无法感知的。 AsyncAppender应该在它引用的Appender之后配置,默认使用 java.util.concurrent.ArrayBlockingQueue实现而不需要其它外部的类库。 当使用此Appender的时候,在多线程的环境下需要注意,阻塞队列容易受到锁争用的影响,这可能会对性能产生影响。
2.4.2 AsyncLogger
AsyncLogger才是log4j2 的重头戏,也是官方推荐的异步方式。它可以使得调用Logger.log返回的更快。Log4j2中的AsyncLogger的内部使用了Disruptor框架。
Disruptor简介
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,基于Disruptor开发的系统单线程能支撑每秒600万订单。
目前,包括Apache Strom、Log4j2在内的很多知名项目都应用了Disruptor来获取高性能。
Disruptor框架内部核心数据结构为RingBuffer,其为无锁环形队列。
Disruptor为什么这么快?
- lock-free-使用了CAS来实现线程安全
- 使用缓存行填充解决伪共享问题
异步日志可以有两种选择:全局异步和混合异步。
1)全局异步
全局异步就是,所有的日志都异步的记录,在配置文件上不用做任何改动,只需要在jvm启动的时候增加一个参数;这是最简单的配置,并提供最佳性能。
然后在src/java/resources目录添加log4j2.component.properties配置文件
设置异步日志系统属性
log4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
2)混合异步
混合异步就是,你可以在应用中同时使用同步日志和异步日志,这使得日志的配置方式更加灵活。因为Log4j文档中也说了,虽然Log4j2提供以一套异常处理机制,可以覆盖大部分的状态,但是还是会有一小部分的特殊情况是无法完全处理的,比如我们如果是记录审计日志,那么官方就推荐使用同步日志的方式,而对于其他的一些仅仅是记录一个程序日志的地方,使用异步日志将大幅提升性能,减少对应用本身的影响。混合异步的方式需要通过修改配置文件来实现,使用AsyncLogger标记配置。
第一步:pom中添加相关jar包
com.lmax
disruptor
3.4.2
第二步:log4j2.xml同步日志和异步日志(配置AsyncLogger)混合配置的例子如下:
log
test.log
2.5 使用异步日志的注意事项
在使用异步日志的时候需要注意一些事项,如下:
- 不要同时使用AsyncAppender和AsyncLogger,也就是在配置中不要在配置Appender的时候,使用Async标识的同时,又配置AsyncLogger,这不会报错,但是对于性能提升没有任何好处。
- 不要在开启了全局同步的情况下,仍然使用AsyncAppender和AsyncLogger。这和上一条是同一个意思,也就是说,如果使用异步日志,AsyncAppender、AsyncLogger和全局日志,不要同时出现。
- 如果不是十分必须,不管是同步异步,都设置immediateFlush为false,这会对性能提升有很大帮助。
- 如果不是确实需要,不要打印location信息,比如HTML的location,或者pattern模式里的%C or $class, %F or %file, %l or %location, %L or %line, %M or %method, 等,因为Log4j需要在打印日志的时候做一次栈的快照才能获取这些信息,这对于性能来说是个极大的损耗。
3 总结
在压测的中,对于问题的根因尽最大能力探索挖掘,不断沉淀总结实践经验。尤其是一些开源的组件使用,要详细学习了解使用规范以及最佳实践,必要时可以加入性能测试,确保满足我们质量和性能要求。
4 参考
- https://www.yisu.com/zixun/623058.html
- https://www.jianshu.com/p/9f0c67facbe2
- https://blog.csdn.net/thinkwon/article/details/101625124
- https://zhuanlan.zhihu.com/p/386990511
作者:京东物流 刘江波 吕怡浩
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
