

作者:车漾
前文回顾:
本系列将介绍如何基于 ACK Fluid 支持和优化混合云的数据访问场景,相关文章请参考:
-基于 ACK Fluid 的混合云优化数据访问(一):场景与架构
-基于 ACK Fluid 的混合云优化数据访问(二):搭建弹性计算实例与第三方存储的桥梁
-基于 ACK Fluid 的混合云优化数据访问(三):加速第三方存储的读访问,降本增效并行
在前一篇文章《加速第三方存储的读访问,降本增效并行》中,介绍如何加速第三方存储访问,实现更好的性能,更低的成本同时降低对专线稳定性的依赖。
还有一些客户的场景下,出于历史原因和容器存储接口开发维护的成本,并没有选择使用标准的 CSI 接口,而是使用非容器化的手段,比如自动化脚本。但是一旦拥抱云,就需要考虑如何和基于标准接口的云服务对接的问题。
而本文将重点介绍如何通过 ACK Fluid 实现第三方存储主机目录挂载 Kubernetes 化,更加标准并加速提效。
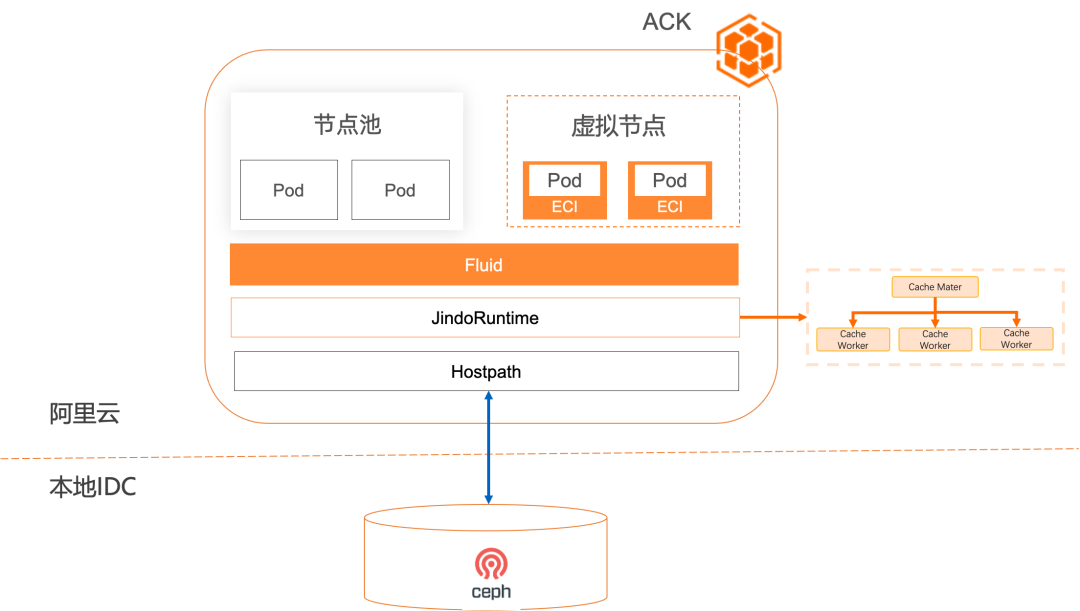
概述
有许多企业由于历史原因和技术云下存储选择没有支持 CSI 协议,只支持以主机目录的方式通过 ansible 等运维工具挂载,一方面存在与 Kubernetes 标准化平台的对接的挑战,另一方面也需要应对与上篇文章类似的性能和成本的问题:
- 缺少标准化,上云困难: 主机目录挂载的模式由于无法被 Kubernetes 感知和调度,很难被容器化工作负载使用和管理。
- 缺少数据隔离性: 由于整个目录都被挂载到主机上,并被所有的工作负载访问,导致数据全局可见。
- 数据访问在成本,性能和可用性上有何场景 2 相同的需求,因此不再赘述。
ACK Fluid 提供了基于 JindoRuntime 的 PV 主机目录通用加速能力 [ 1] ,直接支持主机目录挂载可以原生,简单,快速,安全的获得通过分布式缓存实现数据访问加速能力。
1. 将传统架构迁移到云原生适配架构: 将主机目录挂载模式变化为 Kubernetes 可以管理的 CSI 协议下的 PV 存储卷,方便通过标准化协议与公共云相结合。
2. 传统架构迁移低成本: 只需要实现主机目录挂载可以立即使用,无需额外开发;只需要在部署时刻将 Hostpath 协议转换成 PV 存储卷。
3. 数据可隔离: 通过 Fluid 的子数据集模式可以隔离不同用户对于线下存储不同目录的可见性。
4.可以提供和《加速第三方存储的读访问,降本增效并行》一样的性能,成本,自动化和无缓存数据落盘的优点。
总结: ACK Fluid 为云上计算访问第三方存储的主机目录挂载方式提供了开箱即用,高性能,低成本,自动化和无数据落盘的收益。
演示
1. 前提条件
- 已创建 ACK Pro 版集群,且集群版本为 1.18 及以上。具体操作,请参见创建 ACK Pro 版集群 [ 2] 。
- 已安装云原生 AI 套件并部署 ack-fluid 组件。重要: 若您已安装开源 Fluid,请卸载后再部署 ack-fluid 组件。
- 未安装云原生 AI 套件:安装时开启 Fluid 数据加速。具体操作,请参见安装云原生 AI 套件 [ 3] 。
- 已安装云原生 AI 套件:在容器服务管理控制台的云原生 AI 套件页面部署 ack-fluid。
- 已通过 kubectl 连接 ACK 集群。具体操作,请参见通过 kubectl 工具连接集群 [ 4] 。
- 已创建需要访问存储系统对应的 PV 存储卷和 PVC 存储卷声明。在 Kubernetes 环境中,不同的存储系统有不同的存储卷创建方式,为保证存储系统与 Kubernetes 集群的连接稳定,请根据对应存储系统的官方文档进行准备。
2. 准备主机目录挂载点
本示例中通过 sshfs 模拟第三方存储通过 fluid 转化为数据卷声明,并且对其实现访问加速。
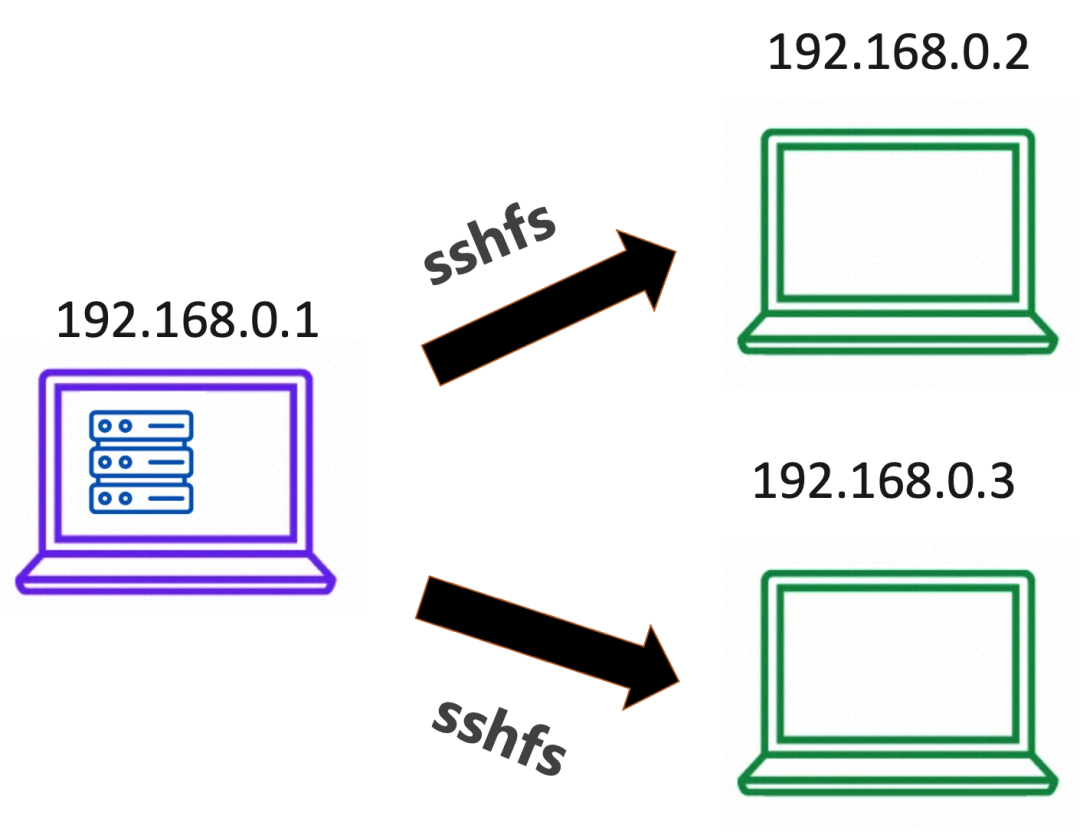
2.1 首先登录三台机器 192.168.0.1,192.168.0.2,192.168.0.3, 分别安装 sshfs 服务,在本例子中以 CentOS 为例,执行如下命令。
$ sudo yum install sshfs -y
2.2 登录 sshfs 服务器 192.168.0.1,执行如下命令,在 /mnt 目录下创建一个新的子目录作为主机目录挂载点,并且创建一个测试文件。
$ mkdir /mnt/demo-remote-fs
$ cd /mnt/demo-remote-fs
$ dd if=/dev/zero of=/mnt/demo-remote-fs/allzero-demo count=1024 bs=10M
2.3 执行如下命令,为 sshfs 的客户端 192.168.0.2 和 192.168.0.3 两个节点创建相应的主机目录。
$ mkdir /mnt/demo-remote-fs
$ sshfs 192.168.0.1:/mnt/demo-remote-fs /mnt/demo-remote-fs
$ ls /mnt/demo-remote-fs
2.4 执行如下命令,为 192.168.0.2 和 192.168.0.3 节点打标签。标签 demo-remote-fs=true 用于设置 JindoRuntime 的 Master 和 Worker 组件的节点调度约束条件。
$ kubectl label node 192.168.0.2 demo-remote-fs=true
$ kubectl label node 192.168.0.3 demo-remote-fs=true
2.5 选择 192.168.0.2 执行如下命令,访问数据,评估文件访问性能,拷贝 10G 文件的时间需要 1m5.889s。
$ ls -lh /mnt/demo-remote-fs/
total 10G
-rwxrwxr-x 1 root root 10G Aug 13 10:07 allzero-demo
$ time cat /mnt/demo-remote-fs/allzero-demo > /dev/null
real 1m5.889s
user 0m0.086s
sys 0m3.281s
3. 创建 Fluid Dataset 和 JindoRuntime
使用如下 YAML,创建 dataset.yaml 文件。
下方 dataset.yaml 配置文件中包含两个待创建的 Fluid 资源对象,分别是 Dataset 和 JindoRuntime。
- Dataset:所需挂载的主机目录信息。
- JindoRuntime:待启动的 JindoFS 分布式缓存系统配置,包括缓存系统 Worker 组件副本数,以及每个 Worker 组件最大可用的缓存容量等。
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: hostpath-demo-dataset
spec:
mounts:
- mountPoint: local:///mnt/demo-remote-fs
name: data
path: /
accessModes:
- ReadOnlyMany
---
apiVersion: data.fluid.io/v1alpha1
kind: JindoRuntime
metadata:
name: hostpath-demo-dataset
spec:
master:
nodeSelector:
demo-remote-fs: "true"
worker:
nodeSelector:
demo-remote-fs: "true"
fuse:
nodeSelector:
demo-remote-fs: "true"
replicas: 2
tieredstore:
levels:
- mediumtype: MEM
path: /dev/shm
quota: 10Gi
high: "0.99"
low: "0.99"
配置文件中资源对象的详细参数说明如下。

3.1 执行如下命令,创建 Dataset 和 JindoRuntime 资源对象。
$ kubectl create -f dataset.yaml
3.2 执行如下命令,查看 Dataset 的部署情况。
$ kubectl get dataset hostpath-demo-dataset
预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
hostpath-demo-dataset 10.00GiB 0.00B 20.00GiB 0.0% Bound 47s
3.3 Dataset 处于 Bound 状态,表明 JindoFS 缓存系统已在集群内正常启动,应用 Pod 可正常访问 Dataset 中定义的数据。
4. 创建 DataLoad 执行缓存预热
由于首次访问无法命中数据缓存,可能导致应用 Pod 的数据访问效率较低。Fluid 提供了 DataLoad 缓存预热操作提升首次数据访问的效率。
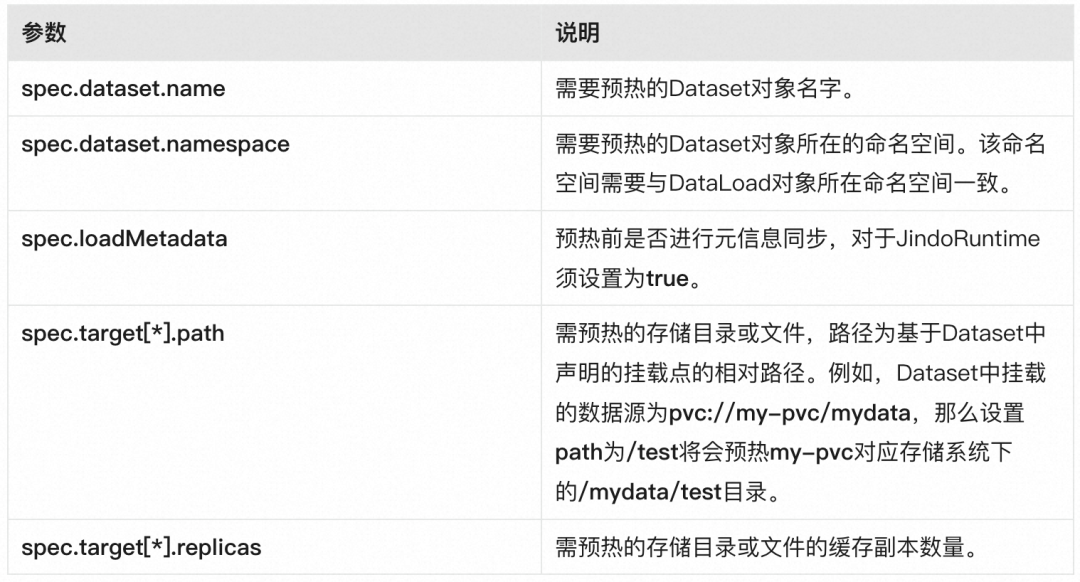
4.1 创建 dataload.yaml 文件,代码示例如下。
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: dataset-warmup
spec:
dataset:
name: hostpath-demo-dataset
namespace: default
loadMetadata: true
target:
- path: /
replicas: 1
上述资源对象的详细参数说明如下所示。
4.2 执行如下命令,创建 DataLoad 对象。
$ kubectl create -f dataload.yaml
4.3 执行如下命令,查看 DataLoad 状态。
$ kubectl get dataload dataset-warmup
预期输出:
NAME DATASET PHASE AGE DURATION
dataset-warmup hostpath-demo-dataset Complete 96s 1m2s
4.4 执行如下命令,查看数据缓存状态。
$ kubectl get dataset
预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
hostpath-demo-dataset 10.00GiB 10.00GiB 20.00GiB 100.0% Bound 157m
DataLoad 缓存预热操作完成后,数据集的已缓存数据量 CACHED 已更新为整个数据集的大小,代表整个数据集已被缓存,缓存百分比 CACHED PERCENTAGE 为 100.0%。
5. 查看数据预热后的访问性能
5.1 使用如下 YAML,创建 pod.yaml 文件,并修改 YAML 文件中的 claimName 名称与本例子中已创建的 Dataset 名称相同。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
command:
- "bash"
- "-c"
- "sleep inf"
volumeMounts:
- mountPath: /data
name: data-vol
volumes:
- name: data-vol
persistentVolumeClaim:
claimName: hostpath-demo-dataset # 名称需要与Dataset相同。
5.2 执行如下命令,创建应用 Pod。
kubectl create -f pod.yaml
5.3 执行如下命令,登录 Pod 访问数据。
$ kubectl exec -it nginx bash
预期输出,可以拷贝 10G 文件的时间需要 0m8.629s,是 sshfs 直接远程拷贝耗时(1m5.889s)的 1/8:
root@nginx:/# ls -lh /data
total 10G
-rwxrwxr-x 1 root root 10G Aug 13 10:07 allzero-demo
root@nginx:/# time cat /data/allzero-demo > /dev/null
real 0m8.629s
user 0m0.031s
sys 0m3.594s
5.4 清理应用 Pod
$ kubectl delete po nginx
相关链接:
[1] PV 主机目录通用加速能力
https://help.aliyun.com/zh/ack/cloud-native-ai-suite/user-guide/accelerate-pv-storage-volume-data-access
[2] 创建 ACK Pro 版集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/create-an-ack-managed-cluster-2#task-skz-qwk-qfb
[3] 安装云原生 AI 套件
https://help.aliyun.com/zh/ack/cloud-native-ai-suite/user-guide/deploy-the-cloud-native-ai-suite#task-2038811
[4] 通过 kubectl 工具连接集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/obtain-the-kubeconfig-file-of-a-cluster-and-use-kubectl-to-connect-to-the-cluster#task-ubf-lhg-vdb
