

Pai-Megatron-Patch是什么
Pai-Megatron-Patch工具是阿里云机器学习平台PAI算法团队研发,基于阿里云智算服务PAI-灵骏平台的大模型最佳实践解决方案配套工具,旨在帮助大模型开发者快速上手灵骏产品,完成大语言模型(LLM)的高效分布式训练,有监督指令微调,模型离线推理验证等完整大模型开发链路。该项目提供了业界主流开源大模型基于Megatron-LM的训练&离线推理验证流程,方便用户快速上手大模型训练。
主要特性
- 多款热门大模型支持:llama,llama-2,codellama, 百川,通义千问,Falcon,GLM,Starcoder,Bloom,chatglm等
- 支持模型权重互转转换:在Huggingface,Megatron和Transformer Engine之间进行算子命名空间映射
- 支持Flash Attention 2.0和Transformer Engine模式下的FP8训练加速且确保收敛
- 丰富且简单易用的使用示例,支持大模型预训练,微调,评估和推理,强化学习全流程最佳实践
开源地址
https://github.com/alibaba/Pai-Megatron-Patch
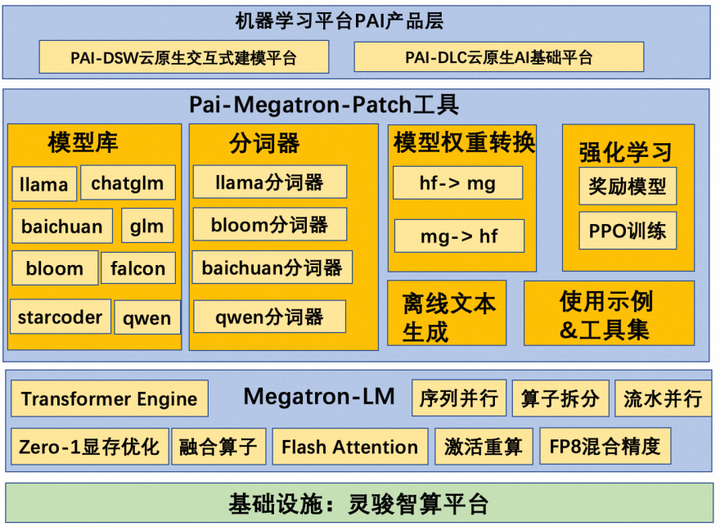
技术架构
Pai-Megatron-Patch的设计理念是不对Megatron-LM的源码进行侵入式修改,即不在Megatron-LM里面添加新的功能特性,将需要扩充完善的部分以patch补丁的方式呈现。在patch中构建LLM训练链路通过依赖Megatron-LM核心库的方法实现和Megatron-LM的解耦合。这样解耦合的好处就是Megatron-LM的升级不会影响用户的LLM最佳实践体验。
Pai-Megatron-Patch中包含模型库,分词器,模型转换,强化学习,离线文本生成以及使用示例和工具集等用于构建LLM训练的关键要素。在模型库中包含热门大模型的Megatron版本实现,例如baichuan,bloom,chatglm,falcon,galactica,glm,llama,qwen和starcoder,后续还会根据需要及时添加新的Megatron版大模型实现。同时patch还提供了huggingface模型权重和Megatron模型权重之间的双向转换。一方面是方便用户加载huggingface的权重在Megatron中继续预训练或者微调,另一方面是方便用户对训练好的Megatron模型使用huggingface的评估/推理流程对模型质量进行客观评估。在强化学习部分,patch提供了PPO训练流程等,方便用户使用SFT模型和RM模型进行强化学习。最后patch提供了大量的使用示例帮助用户快速开始大模型训练&离线推理。具体请参考阿里云灵骏产品的使用流程: 智算服务PAI灵骏大模型分布式训练方案
关键技术
模型权重转换
研发Megatron-Patch的初衷之一就是能将世界各地研发机构在Huggingface上放出的热门大模型使用Megatron引擎进行继续预训练或者继续微调。这就需要首先将Huggingface模型格式的ckpt转换成Megatron模型格式,才能正确加载进来,否则会出现pytorch加载模型失败。Megatron-Patch的一个核心可靠性保障特征就是在采用算子拆分,流水并行,序列并行,Zero显存优化,BF16混合精度,梯度检查点等训练加速技术确保模型训练吞吐速度平均提升1.5倍以上的同时,在评估任务模式下的单一样本前向loss值,预训练/微调任务模式下的loss曲线,离线文本生成任务模式下的生成效果这三个方面和Huggingface是对齐的,从而确保Megatron版模型的可靠性。
另一方面,Megatron版的transformer实现方式提供了一种让用户仅仅通过设置开关就能实现不同种类GPT模式的能力。比如llama模型打开如下开关即可
--swiglu
--use-rotary-position-embeddings
--no-position-embedding
--untie-embeddings-and-output-weights
--disable-bias-linear
如果想将llama模式变成baichuan模型,那么仅仅需要添加采用–use-alibi-mask开关,同时关闭Rotary Embeeding开关即可,具体配置如下所示:
--swiglu
--use-alibi-mask
--position-embedding-type none
--untie-embeddings-and-output-weights
--disable-bias-linear
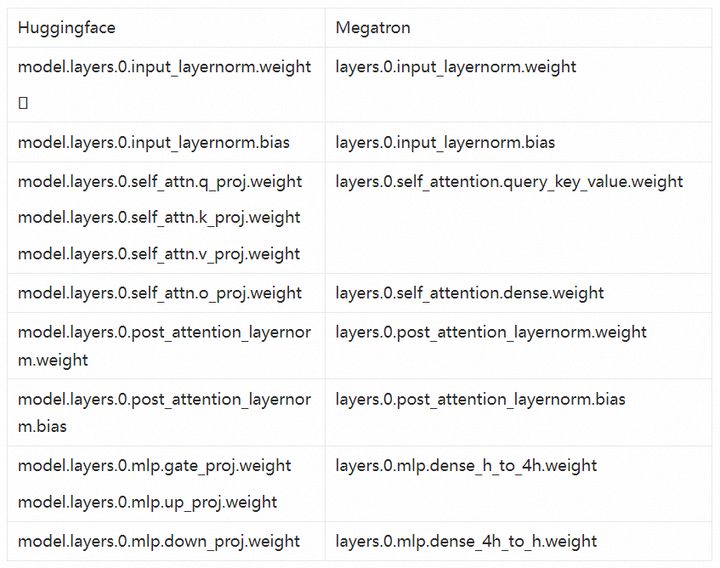
下面我们以llama-2为例,详解从huggingface到megatron的模型权重转换技术。下表总结了两者在不同module上的命名对应关系。在patch实现过程中,我们首先将HF格式的ckpt转换到一种内部格式,然后再把这种内部格式转换成对应的外部格式。这样做可以最大程度复用已有的转换逻辑来处理新模型。在转换为内部格式的过程中,
q_proj, k_proj, v_proj需要沿着第0维拼接在一起后赋值给内部变量query_key_value。
当用户在资源受限情况下需要按照TP>1来拆分权重的时候,这里需要注意的是针对MLP层的gate_proj和up_proj的操作。不能像qkv那样在转换成内部格式的时候进行merge再执行算子拆分。需要在拆分前加入如下针对MLP层的权重合并的代码逻辑才能确保正确收敛。
for i in range(tp_size):
params_dict = get_element_from_dict_by_path(output_state_dict[i],
"model.language_model.encoder")
dense_h_to_4h_1_name = 'mlp.dense_h_to_4h_1.weight'
dense_h_to_4h_1_layer_name = f"layers.{layer}.{dense_h_to_4h_1_name}"
dense_h_to_4h_1_weight = params_dict[dense_h_to_4h_1_layer_name]
dense_h_to_4h_2_name = 'mlp.dense_h_to_4h_2.weight'
dense_h_to_4h_2_layer_name = f"layers.{layer}.{dense_h_to_4h_2_name}"
dense_h_to_4h_2_weight = params_dict[dense_h_to_4h_2_layer_name]
dense_h_to_4h_name = 'mlp.dense_h_to_4h.weight'
dense_h_to_4h_layer_name = f"layers.{layer}.{dense_h_to_4h_name}"
params_dict[dense_h_to_4h_layer_name] = torch.cat(
[dense_h_to_4h_1_weight, dense_h_to_4h_2_weight], dim=0)
基于TE的FP8训练收敛
Transformer Engine(TE)是一个在英伟达GPUS上运行的针对Transformer模型的加速库,其中包括针对Hopper GPU的FP8混合精度,该精度可以在较低的显存利用率下提供更好的训练&推理速度。在TE内部封装了Flash Attention实现,同时TE还提供了一组高度优化后的算子用来构建Transformer模型。比如LayerNormLinear就是将LayerNorm和QKV-Proojection进行算子融合,LayerNormMLP就是将layernorm和mlp进行算子融合。如下图所示:
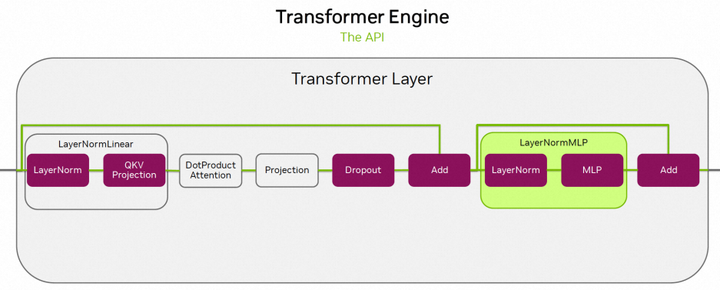
从Huggingface到TE模型的权重转换技术和之前是类似的,也需要事先找到两者之间的映射关系。从下表可以看出,TE中多了_extra_state是用来存fp8训练的scale和history的,这些在加载的时候会出现冲突,这时只要将load_state_dict函数的strict设置成False就可以了,比如load_state_dict(state_dict_, strict=False)。

在Megatron-Patch中使用示例中打开FP8混合精度训练开关也很容易,如下所示:
if [ $PR = fp16 ]; then
pr_options="
--fp16"
elif [ $PR = bf16 ]; then
pr_options="
--bf16"
elif [ $PR = fp8 ]; then
pr_options="
--bf16
--fp8-hybrid
--fp8-amax-compute-algo max
--fp8-amax-history-len 1024
--transformer-impl transformer_engine"
fi
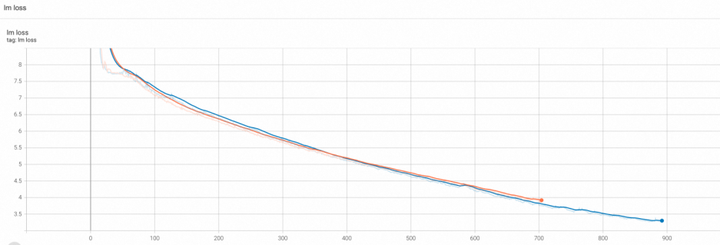
我们可以使用如下训练脚本run_pretrain_megatron_llama_enwiki.sh来测试打开FP8开关后的预训练收敛性。下图展示了llama-7B和llama-2-70B模型在打开和关闭FP8时的loss曲线对比,可以看出基本是重合的。
LLama-7B
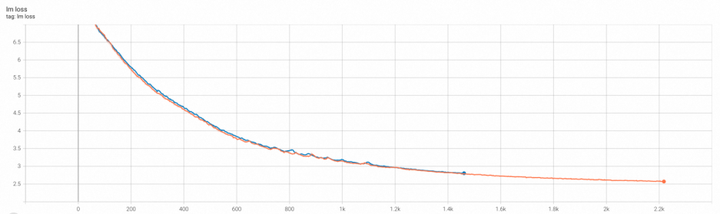
LLama2-70B
大模型训练&推理
从github上获取Megatron模型训练工具PAI-Megatron-Patch(https://github.com/alibaba/Pai-Megatron-Patch)源代码并拷贝到工作目录/mnt/workspace/下。
模型格式转换
使用我们提供的模型转换脚本,将huggingface格式的模型文件转换为megatron格式:
cd /mnt/workspace/
mkdir llama2-ckpts
cd llama2-ckpts
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-ckpts/Llama-2-7b-hf.tgz
tar -zxf Llama-2-7b-hf.tgz
mv Llama-2-7b-hf llama2-7b-hf
cd /mnt/workspace/PAI-Megatron-Patch/toolkits/model_checkpoints_convertor/llama
sh model_convertor.sh
/root/Megatron-LM-23.04
/mnt/workspace/llama2-ckpts/llama2-7b-hf
/mnt/workspace/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1
1
1
llama-7b
0
false
继续预训练
中文继续预训练汉化指引
Step1: 获取需要扩充词表的模型(如llama-13b-hf)
Step2: 获取需要扩充的词表
- 使用sentence-piece代码库从自有文本语料中学习词表,得到randeng-sp.model文件
Step3: 词表扩充
- 扩充模型tokenizer:将randeng-sp.model中的词表添加到llama-13b-hf文件夹下tokenizer.model中
- 扩充模型词表对应的参数矩阵
- word_embedding、lm_head
- 新词向量可以使用原词向量均值作为初始化,比如“天气”=mean([“天”,“气”])
- 修改与词表大小相关的文件并保存,如config.json
运行继续预训练脚本 run_pretrain_megatron_llama.sh,需要传入的参数列表如下
ENV=$1 # 运行环境: dlc, dsw
MEGATRON_PATH=$2 # 设置开源Megatron的代码路径
MEGATRON_PATCH_PATH=$3 # 设置Megatron Patch的代码路径
MODEL_SIZE=$4 # 模型结构参数量级:7B, 13B
BATCH_SIZE=$5 # 每卡训练一次迭代样本数: 4, 8
GLOBAL_BATCH_SIZE=$6 # 全局batch size
LR=$7 # 学习率: 1e-5, 5e-5
MIN_LR=$8 # 最小学习率: 1e-6, 5e-6
SEQ_LEN=$9 # 序列长度
PAD_LEN=${10} # Padding长度:100
EXTRA_VOCAB_SIZE=${11} # 词表扩充大小
PR=${12} # 训练精度: fp16, bf16
TP=${13} # 模型并行度
PP=${14} # 流水并行度
AC=${15} # 激活检查点模式: sel, full
DO=${16} # 是否使用Megatron版Zero-1降显存优化器: true, false
FL=${17} # 是否使用Flash Attention: true, false
SP=${18} # 是否使用序列并行: true, false
SAVE_INTERVAL=${19} # 保存ckpt的间隔
DATASET_PATH=${20} # 训练数据集路径
PRETRAIN_CHECKPOINT_PATH=${21} # 预训练模型路径
TRAIN_TOKENS=${22} # 训练token数
WARMUP_TOKENS=${23} # 预热token数
OUTPUT_BASEPATH=${24} # 训练输出文件路径
注意设置正确的数据集挂载路径WORK_DIR以及运行环境ENV,运行示例如下所示:
export WORK_DIR=/mnt/workspace
cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2
bash run_pretrain_megatron_llama.sh
dlc
/root/Megatron-LM-23.04
${WORK_DIR}/PAI-Megatron-Patch
7B
1
16
1e-5
1e-6
2048
80
0
fp16
1
1
sel
true
false
false
100000
${WORK_DIR}/llama2-datasets/wudao/wudao_llamabpe_text_document
${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1
100000000
10000
${WORK_DIR}/output_megatron_llama2/
有监督微调
在微调开始之前,请先进入https://github.com/alibaba/Pai-Megatron-Patch/blob/main/toolkits/pretrain_data_preprocessing/README.md 获取json文件。运行run_finetune_megatron_llama.sh脚本,需要传入的参数列表如下
ENV=$1 # 运行环境: dlc, dsw
MEGATRON_PATH=$2 # 设置开源Megatron的代码路径
MEGATRON_PATCH_PATH=$3 # 设置Megatron Patch的代码路径
MODEL_SIZE=$4 # 模型结构参数量级: 7B, 13B
BATCH_SIZE=$5 # 每卡训练一次迭代样本数: 4, 8
LR=$6 # 学习率: 1e-5, 5e-5
MIN_LR=$7 # 最小学习率: 1e-6, 5e-6
SEQ_LEN=$8 # 序列长度
PAD_LEN=$9 # Padding长度:100
EXTRA_VOCAB_SIZE=${10} # 词表扩充大小
PR=${11} # 训练精度: fp16, bf16
TP=${12} # 模型并行度
PP=${13} # 流水并行度
AC=${14} # 激活检查点模式: sel, full
DO=${15} # 是否使用Megatron版Zero-1降显存优化器: true, false
FL=${16} # 是否使用Flash Attention: true, false
SP=${17} # 是否使用序列并行: true, false
TRAIN_DATASET_PATH=${18} # 训练数据集路径
VALID_DATASET_PATH=${19} # 验证数据集路径
PRETRAIN_CHECKPOINT_PATH=${20} # 预训练模型路径
EPOCH=${21} # 训练迭代轮次
OUTPUT_BASEPATH=${22} # 训练输出文件路径
多节点运行示例如下所示:
export WORK_DIR=/mnt/workspace
cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2
sh run_finetune_megatron_llama.sh
dlc
/root/Megatron-LM-23.04
${WORK_DIR}/PAI-Megatron-Patch
7B
1
1e-5
1e-6
2048
80
0
fp16
1
1
sel
true
false
false
${WORK_DIR}/llama2-datasets/wudao_train.json
${WORK_DIR}/llama2-datasets/wudao_valid.json
${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1
2
${WORK_DIR}/output_megatron_llama2/
离线推理
模型训练完成后,可以进行离线推理,评估模型效果。根据上面的训练流程不同,我们提供了Megatron格式的推理链路。对于Megatron训练的模型,可以直接用Megatron框架进行推理。
ENV=$1 # 运行环境: dlc, dsw
MEGATRON_PATH=$2 # 设置开源Megatron的代码路径
MEGATRON_PATCH_PATH=$3 # 设置Megatron Patch的代码路径
CHECKPOINT_PATH=$4 # 模型微调阶段的模型保存路径
MODEL_SIZE=$5 # 模型结构参数量级: 1.1B, 1.7B, 7.1B
TP=$6 # 模型并行度
BS=$7 # 每卡推理一次迭代样本数: 1, 4, 8
SEQ_LEN=$8 # 序列长度: 256, 512, 1024
PAD_LEN=$9 # PAD长度:需要将文本拼接到的长度
EXTRA_VOCAB_SIZE=${10} # 模型转换时增加的token数量
PR=${11} # 推理采用的精度: fp16, bf16
TOP_K=${12} # 采样策略中选择排在前面的候选词数量(0-n): 0, 5, 10, 20
INPUT_SEQ_LEN=${13} # 输入序列长度: 512
OUTPUT_SEQ_LEN=${14} # 输出序列长度: 256
INPUT_FILE=${15} # 需要推理的文本文件: input.txt, 每行为一个样本
OUTPUT_FILE=${16} # 推理输出的文件: output.txt
# TOP_K和TOP_P必须有一个为0
TOP_P=${17} # 采样策略中选择排在前面的候选词百分比(0-1): 0, 0.85, 0.95
TEMPERATURE=${18} # 采样策略中温度惩罚: 1-n
REPETITION_PENALTY=${19} # 避免生成是产生大量重复,可以设置为(1-2)默认为1.2
- 此处提供一个离线推理输出的文件,推理的数据组织形式需要与微调时的保持一致。
- 测试样本:https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/pred_input.jsonl
- 注意:
- 模型保存的路径下缺少tokenizer依赖的文件,需要将微调前模型路径下所有json文件及tokenizer.model拷贝至保存模型的路径下(位于{OUTPUT_BASEPATH }/checkpoint),与latest_checkpointed_iteration.txt同级。
以下有监督微调过程保存模型的推理代码,需要将run_text_generation_megatron_llama.sh脚本中CUDA_VISIBLE_DEVICES参数设置为0;GPUS_PER_NODE参数设置为1;同时使用下列代码进行推理。此时使用单卡进行推理。注意:此处模型tp为1,可使用单卡推理;如果tp>1,则需使用相应卡数进行推理。
export WORK_DIR=/mnt/workspace
cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2
bash run_text_generation_megatron_llama.sh
dsw
/root/Megatron-LM-23.04
${WORK_DIR}/PAI-Megatron-Patch
../../../llama2-train
7B
1
1
1024
1024
0
fp16
10
512
512
${WORK_DIR}/pred_input.jsonl
${WORK_DIR}/llama2_pred.txt
0
1.0
1.2
大模型强化学习
一般来说,SFT微调过的模型在对话场景已经会有不错的表现了。如果想进一步提升模型效果,可以再加上RLHF训练。包括奖励模型(Reward Model)的训练和强化学习(PPO)的训练。这里展示了如何使用当前最常用的RLHF开源代码框架,DeepSpeed-Chat和trlx,来进行奖励函数训练(RM),以及强化学习优化(PPO)。
模型格式转换
如果基于huggingface格式的模型直接进行奖励模型训练(RM)和强化学习优化(PPO),可以跳过此步骤。
如果基于Megatron格式的模型,如PAI-Megatron-Patch训练好的SFT模型,进行RM和PPO训练,需要使用我们提供的模型转换脚本,先将Megatron格式的模型文件转换为huggingface格式。
LLaMA2模型转换:
cd PAI-Megatron-Patch/toolkits/model_checkpoints_convertor/gpt3_llama
bash model_convertor.sh
/path/to/Megatron-LM
/path/to/megatron_llama2_ckpt
/path/to/hf_llama2_ckpt
1
1
llama-7b
0
true
BLOOM模型转换:
cd PAI-Megatron-Patch/toolkits/model_checkpoints_convertor/bloom
bash model_convertor_huggingface_megatron.sh
/path/to/Megatron-LM
/path/to/megatron_bloom_ckpt
/path/to/hf_bloom_ckpt
1
1
true
DeepSpeed-Chat
下载安装开源社区DeepSpeed-Chat源代码:
cd PAI-Megatron-Patch/rlhf/deepspeed-chat
git clone https://github.com/microsoft/DeepSpeedExamples.git
cp -f rm_main.py DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/main.py
cp -f utils.py DeepSpeedExamples/applications/DeepSpeed-Chat/training/utils/utils.py
cd DeepSpeedExamples/applications/DeepSpeed-Chat/
pip install -r requirements.txt
基于LLaMA2模型训练奖励模型(RM):
cd training/step2_reward_model_finetuning/ && bash training_scripts/llama2/run_llama2_7b.sh
基于LLaMA2进行强化学习优化训练(PPO):
cd training/step3_rlhf_finetuning/ && bash training_scripts/llama2/run_llama2_7b_lora.sh
trlx
下载安装开源社区trlx源代码:
cd PAI-Megatron-Patch/rlhf/trlx
git clone https://github.com/CarperAI/trlx.git
cp trlx_bloom_rlhf.py trlx_bloom_rlhf_test.py trlx/examples/summarize_rlhf/
cp train_reward_model_bloom.py reward_model_bloom.py ds_config_bloom.json trlx/examples/summarize_rlhf/reward_model/
cp -f ds_config_trlx_gptj_summarize.json trlx/examples/summarize_rlhf/configs/
cd trlx
pip install -e .
基于BLOOM模型训练奖励模型(RM):
cd examples/summarize_rlhf/reward_model/ && deepspeed train_reward_model_bloom.py
基于GPT-J模型训练奖励模型(RM):
cd examples/summarize_rlhf/reward_model/ && deepspeed train_reward_model_gptj.py
基于BLOOM模型进行强化学习优化训练(PPO):
cd examples/summarize_rlhf/ && accelerate launch --config_file configs/default_accelerate_config.yaml trlx_bloom_rlhf.py
基于GPT-J模型进行强化学习优化训练(PPO):
cd examples/summarize_rlhf/ && accelerate launch --config_file configs/default_accelerate_config.yaml trlx_gptj_text_summarization.py
PPO单测
如果您想跳过 有监督微调(SFT)与 奖励模型训练(RM)两个步骤,只单独测试PPO模块的性能,可以运行如下指令单测PPO:
cd examples/summarize_rlhf/ && accelerate launch --config_file configs/default_accelerate_config.yaml trlx_bloom_rlhf_test.py
开源生态——构想和未来
在PAI-Megatron-Patch的开发过程中,我们围绕中文大模型训练加速落地沉淀了以下几个方面的内容:
- Huggingface的模型权重无损转换成Megatron或者Transformer Engine可读的模型权重。
- H800集群开启FP8混合精度训练确保收敛。
- LLM大模型在PAI灵骏智算平台上的最佳实践。
- 强化学习技术在PAI灵骏智算平台上的最佳实践。
后续在PAI-Megatron-Patch中还会陆续放出更多高质量的大模型和最佳实践。
参考文献
[1]. Attention Is All You Need
[2]. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
[3]. Reducing Activation Recomputation in Large Transformer Models
[4]. FP8 Formats for Deep Learning
[5]. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
[6]. LLaMA: Open and Efficient Foundation Language Models
[7]. Llama 2: Open Foundation and Fine-Tuned Chat Models
[8]. Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。
