

4 自动重现和分析嵌入式软件中的Bug
4.1 引言
嵌入式软件的重要性逐年增加。ISO26262标准的最高安全级别要求十个9小时内无故障运行。然而,历史上的一些项目表明,即使进行了全面的测试,多年来仍有许多错误未被发现。航天飞机的控制计算机仅有50万行源代码,却经过了长达8年的测试,每行源代码耗资1000美元,即总耗资5亿美元。然而,在1990年最后一次发布时,预计每2000行代码中会遗留一个错误。这种错误可能在极少数情况下出现,而且可能只有在实际运行环境中测试嵌入式系统时才能发现。
静态分析在早期测试(如单元测试)中得到了有效利用。然而,对于复杂软件来说,对错误的静态分析已接近极限。大型软件的状态空间或控制流很难被完全探索。因此,这种分析在性能或精度上都存在缺陷。此外,语义错误具有很强的应用特异性,即使使用优化的静态分析工具,也无法检测到错误的行为。如果没有完整、正确的规范作为黄金参考,情况就会变得更加严重。
系统测试描述了在目标平台上部署和测试软件的过程。与只测试单个模块的单元测试或组件测试相比,系统测试是通过所有集成的软件和硬件模块来执行和测试软件。在系统测试之前,约有60%的错误未被发现。不过,根据软件开发流程模式的不同,系统测试可能只在开发流程的后期才进行。在系统测试期间,真实的传感器和设备被连接到嵌入式系统,以获得真实的输入。这样,传感器硬件与被测软件之间的不兼容性就能被检测出来。
研究表明,错误发现得越晚,需要修复的工作量就越大。一些研究表明,在开发过程中,错误修复成本呈指数增长。因此,与单元测试相比,在系统测试过程中发现的错误需要付出更多努力,这是由于密切的硬件交互和认证要求造成的。然而,一小部分错误(20%)需要 60-80% 的修复工作。当很大一部分复杂的错误在开发过程中很晚才被发现时,项目进度和项目期限就会受到负面影响。因此,产品往往无法及时投放市场。
造成错误修复工作量大的原因之一是错误难以重现。现场用户或操作测试期间的开发人员往往无法提供足够的信息来在实验室重现错误。不同的非确定性方面(如线程调度)可能使实验室中很难重现与运行期间观察到的相同的执行情况。根据社区的错误报告,开源桌面和服务器应用程序中约有17%的错误甚至无法重现。对于具有传感器驱动输入的嵌入式软件,这一比例可能更高。
当错误可以通过测试用例重现时,还需要额外的工作来分析错误。如果测试用例可用,在系统测试期间运行测试用例和修复错误大约需要8小时。Mozilla等开源项目每天会收到300份错误报告。在如此高的错误修复工作量下,要处理如此高的错误率是很困难的。动态验证可以帮助开发人员修复错误。然而,大多数动态分析工具都需要在运行期间对软件进行监控。这些监控工具通常只适用于特定的平台。
错误分为内存错误、并发错误和语义错误。经验研究表明,语义错误是最主要的根源。最常见的语义错误是实现不符合设计要求或行为与预期不符。我们需要自动定位语义错误根源的工具。内存错误并不难解决,因为有许多内存剖析工具可用。并发错误问题较多,尤其难以重现。每十个并发错误中就有一个无法重现。
我们自己开发的基于可移植调试器的错误重现和动态验证方法为嵌入式软件开发领域的技术现状做出了以下贡献:
- 通过使用调试器工具自动记录和重现错误,避免了在任何嵌入式平台上进行费力的人工错误重构。
- 通过强制随机线程切换来改进多线程错误检测。
- 通过对重现的错误进行自动根源分析,减少人工调试工作量。
- 通过使用低成本调试工具实施性能优化和分层分析,避免了昂贵的监控硬件。
- 通过在可扩展和易调整的模块中实施动态验证工具,降低了动态验证工具的移植成本。
我们的方法支持开发人员更快地检测和重建(主要是语义和并发)错误。通过实施自动根源分析,它还能帮助开发人员更快地修复错误。我们的工具可节省调试成本和硬件投资成本。它支持大多数嵌入式平台。它能帮助开发团队将软件产品更早地投放市场。
第4.2节简要介绍了正常的手动调试过程。第4.3节介绍了自动重现错误的方法,随后介绍了我们自己基于调试器的方法。第4.4节展示了如何使用调试器工具实现基于断言的验证。第4.5节介绍了在不使用断言的情况下分析错误根源的概念,以及使用廉价调试器接口加速监控实现的概念。
4.2 概述
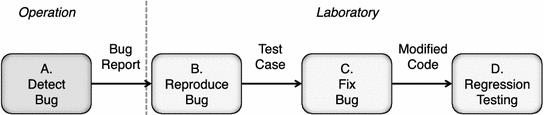
下图中的工作流程介绍了手动查找和修复错误的过程。首先要在系统测试环境中测试嵌入式系统和运行中的软件。例如,导航软件可在连接真实传感器的测试驱动器中执行。在执行过程中,对输入进行跟踪并记录到错误报告(A.)中。该错误报告将提交至错误报告库。在实验室中,开发人员会根据错误报告尝试手动重现错误 (B.)。如果错误可以重现,开发人员必须手动查找源代码中的故障根源 (C.)。修复错误后,可使用回归测试套件执行软件 (D.)。这样就可以确保在修复过程中不会增加新的错误。
手动调试概述:
4.3 基于调试器的错误重现
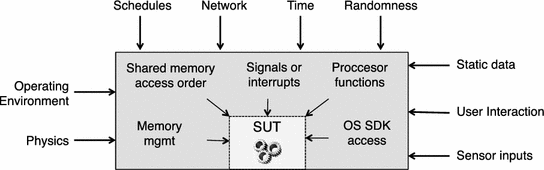
本节介绍自动支持错误再现的工具方法。为了重现错误,必须在运行过程中捕获传感器输入。在重放过程中,必须触发或注入相同的传感器输入(如来自GPS或触摸屏的输入),以实现相同的执行或指令序列。软件的正常执行是确定性的。当软件在相同输入的情况下运行时,会执行相同的指令。然而,这些输入是非确定的,在两次执行软件时并不完全相同。例如,在两次测试执行中很难在触摸屏上实现相同的动作。两次执行之间的微小差异就可能决定是否触发故障。图4.2显示了被测软件(SUT)的不同输入。非确定性输入具体如下:传感器是嵌入式软件最常见的输入源(如 GPS 传感器)。用户交互由人机界面设备(如触摸屏)触发。静态数据可从磁盘或闪存(如XML配置文件)中存储和读取。访问硬件中的时间或随机性功能可改变执行情况,从而使复制变得困难。网络交互可用于与嵌入式系统中的其他设备进行通信(如 CAN 总线)。操作环境可由操作系统来表示,该系统控制日程安排和内存管理。物理效应可能会导致硬件变化,这也是最难处理的分歧。从SUT的角度来看,非确定性的来源可分为: 操作系统 SDK 访问(如系统调用)、信号或中断、特定处理器功能、调度或共享内存访问顺序以及内存初始化和内存分配(如图4.2中SUT框周围的方框所示)。
图4.2嵌入式软件的输入类型
4.3.1 技术现状
本节介绍了当前最先进的错误自动重现方法。对所介绍的非确定性源引起的不同事件的跟踪和重放可在不同层面上实现。
图4.3:重放模块的不同层次

可以在硬件层面记录/重放软件的执行(第 4.3.1.1 节)。因此,需要添加额外的特殊硬件来支持跟踪和回放。另一种方法是模拟硬件。在仿真平台中,可以集成捕获模块。操作系统可控制软件和硬件,并可记录/重放事件(第 4.3.1.2 节)。可以修改操作系统并将其安装到目标平台上。有些操作系统支持集成新模块。此外,还可以修改软件以记录/重放应用层面的事件(第 4.3.1.3 节)。因此,可以在源代码或二进制代码层面修改应用程序。调试器工具在软件和操作系统之间提供了一个层级,因此可以记录/重放事件,如第 4.3.2 节和第 4.3.1.3 节所述。4.3.2 和 4.3.3 节中介绍的那样。以下各节将根据各个层面介绍不同的方法。
4.3.1.1 硬件级重放
我们研究了硬件级重放领域的三种方法:硬件支持重放、全电路重放和基于虚拟化的重放。大多数硬件支持的重放方法都考虑了多处理器平台。为了实现相似的执行,不同内核之间对共享内存的访问会被记录下来,并在重放过程中纳入相同的序列。共享内存访问的跟踪可通过附加硬件实现。与基于软件的方法相比,这种方法的优势在于基于硬件的功能开销低。全电路重放方法在FPGA综合电路中添加了调试工具。这样,就可以实时记录和重放FPGA电路的数据流。不过,只能实时捕获程序执行的一部分。其他方法实现了基于虚拟化的重放,对硬件进行模拟。此外,还有虚拟原型平台 Quick Emulator(QEMU)。不过,虚拟原型平台的基础开销较大,可能会影响与所连接传感器硬件的交互。
4.3.1.2 操作系统级重放
我们研究了操作系统级重放的三种不同方法:事件序列重放、同步事件重放和周期精确事件重放。为了重放相同的事件序列,一些方法使用操作系统 SDK 特定命令来跟踪底层事件,并在重放过程中触发相同的序列。RERAN使用 Android SDK的getevent和自带的sendevent函数在Android移动平台上进行跟踪和重放。RERAN无需修改即可记录和重放排名前100位的Android应用程序。记录和重放触摸屏上的复杂手势输入只需很低的开销(约 1%)。不过,操作系统中必须有支持事件跟踪和发送的功能。在多个内核上进行不同的调度或并行执行会导致另一种行为。并行执行需要同步事件,以实现对共享资源的相同访问顺序。SCRIBE是作为用于跟踪和注入的Linux内核模块实现的。它支持多处理器执行,并使用同步点实现并行访问的同步。利用这种同步,即使在多个内核上运行,系统调用也能在记录和重放过程中保持一致的顺序。然而,实时系统有严格的时间要求,需要对中断等事件进行精确的指令再现。RT-Replayer利用实时操作系统内核跟踪中断。为了进行重放,在发生中断的内存地址上使用陷阱指令(类似于调试器的断点)。因此,在重放过程中,软件会在陷阱处停止,并触发相同的中断功能。
4.3.1.3 应用程序级回放
为了跟踪和注入应用层事件,我们研究了三种不同的应用层回放方法:源代码工具化回放、二进制工具化回放和基于检查点的回放。使用源代码工具,可以修改源代码以跟踪控制流和变量赋值。Jalangi提出了一种方法,即在运行时对变量的每次赋值进行工具化,并将赋值写入跟踪文件。在重放过程中,会注入跟踪到的变量值。该方法是针对JavaScript提出的,但可移植到任何其他编程语言。Jalangi的缺点是:开销大、跟踪文件大,而且可能产生副作用。动态二进制代码工具在执行过程中修改源代码,例如记录。它可在运行时对加载的二进制代码进行动态检测,并注入额外的跟踪代码。工具化代码可以高度优化,执行代码只需较低的开销。PinPlay利用 Pin工具框架对二进制代码进行动态工具化。它考虑了本节导言中介绍的几种非确定性来源。不过Pin框架仅适用于特定指令集。检查点方法能高频捕捉当前进程状态。从检查点开始,所有非确定性事件(如系统调用)都会被捕获。检查点通常基于与平台相关的操作系统SDK操作。
4.3.2 理论与算法
上一节介绍了最先进的方法在不同系统级别记录和重放错误的方式。本节将介绍我们自己为调试器工具跟踪和重放错误的方法。它考虑了两种非确定性输入来源:传感器输入和线程调度。我们不考虑内存违规,因为这类错误可以通过许多可用的内存剖析工具轻松检测到。我们首先介绍传感器访问的记录/重放,然后介绍线程计划的记录/重放。
嵌入式软件经常在定时器或中断的触发下访问连接的设备。设备状态以特定频率被请求。例如,导航软件可能以10Hz的频率访问 GPS 传感器。图 4.4显示了如何通过定时器功能访问传感器。

可以通过在设备访问结束的位置(我们定义为接收)暂停软件执行来实现跟踪。读取的数据将写入日志文件。图 4.5 展示了这一概念。
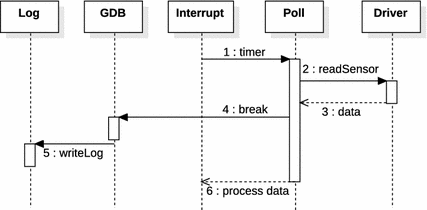
图 4.5 记录序列
在重放过程中,执行暂停在某个位置,在该位置中断开始访问设备(我们定义为请求)。跳过对传感器的访问,跳转到接收位置(定义为 Receive)。此时,将从日志文件中读取数据。这些数据被注入到执行过程中。这样,记录运行中的传感器数据就会被重放。这一概念可通过调试器工具实现,如第 4.3.3 节所述。4.3.3. 基于调试器的重放如图 4.6 中的序列图所示。
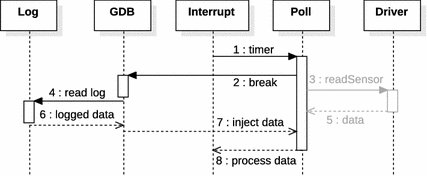
图 4.6 重放序列图
非确定性的其他来源可能是线程调度。线程计划的记录/重放基于线程事件和IO事件序列的重建。这样,在线程操作(如 sem_wait和sem_post时的活动线程就会受到监控。在重放过程中,会触发这些事件的相同调用序列。列表1和2显示了行人识别软件组件的两个线程的示例:Proc线程用于识别图片中的行人,GUI线程用于在检测到行人的图片中绘制矩形。如果交替执行这两个线程,不会出现故障。但是,当Proc线程执行两次时,有一幅图片没有绘制。此外,当Proc被执行两次时,semaphore的值为2,GUI线程也会被执行两次。因此,当前图片在第4行的 GUI 线程中被释放,下一次调用drawRec时会触发已释放的图片。这种情况在正常执行中极少发生,因为在线程 Proc(第 2 行)中对图像进行长时间的行人识别后,通常会触发线程切换到 GUI。
我们的方法实现了活动线程的序列化,并在线程操作时随机切换线程。因此,正常的线程调度器被锁定,任何时候都只有一个线程处于活动状态。这样,活动线程就不会被其他线程抢占。在我们的概念中,线程切换由我们的工具在线程事件(如 sem_wait、sem_post)时触发。脚本通过暂停相应函数并触发线程切换来监控线程事件。在每个线程事件中,我们的工具都会触发线程切换操作(见表 4.1)。
表 4.1 工具触发的线程切换操作列表
我们的工具会为每个semaphore sem设置计数器。每当出现sem_wait,算法都会检查语义符号是否大于零,因此是否可以通过,并减少语义符号计数器sem。如果semaphore计数器为零,则线程被注册为等待线程,并触发切换到另一(非等待)线程。当sem_post 发生时,post结束,并触发切换到随机线程。在重放过程中,与跟踪过程一样,通过为随机函数设置相同的种子,调用相同的随机线程切换。使用这种方法,线程切换总是由脚本触发。因此,脚本可以完全控制线程调度。
4.3.3 执行
调试器工具用于控制SUT的执行。GNU调试器是一种流行的调试工具,可用于不同的嵌入式平台。目前GDB主页列出了GDB支持的80 个主机平台。此外,不同的供应商还将其适配到其他平台。在正常使用过程中,GDB由开发人员手动控制,开发人员在控制台终端输入命令。表 4.2 列出了最常用的 GDB 命令。
表 4.2 线程事件操作

GDB 提供了外部 API。通过该API,可以使用Python编程语言控制调试器的执行和命令。清单3显示了一个可与GDB一起加载的简单 Python脚本。它开始加载要测试的程序(第2行),并在方法foo上设置断点(第3行)。脚本开始运行程序(第4行)。程序在调用 foo时暂停。脚本对foo的调用进行计数(第 6-8 行)。

这样,调试器就由脚本逻辑控制了。其他调试器提供不同的 API 来控制被测软件的执行。即使调试器只提供终端命令接口,也可以通过脚本模拟这些终端命令,并对终端输出进行评估。我们基于调试器的方法就是利用这种调试器工具 API 来记录和重放事件。清单4显示了我们为 Navit 导航软件实现 GPS 传感器数据重放的方法。

在开始请求设备和结束访问设备的源代码行(第1-2行)中设置断点。在记录时,执行会在接收GPS数据的位置暂停。在这种情况下,将打印当前的GPS值(第7-8行)并将其写入日志文件(第9行)。对于重放,执行暂停在开始访问GPS的位置。使用跳转命令跳过访问(第12行),并注入日志中的数据(第13-14行)。如果使用断点进行基于调试器的记录太慢,可以使用printf语句或跟踪缓冲区来实现。
下一段将介绍如何控制被测程序以实现确定的线程调度。GDB为调试多线程程序提供了表4.3所列的命令。表4.3列出了用于调试多线程程序的命令,其中包括我们在实现过程中使用的三条命令。在每次断点暂停时,开发人员可以手动检查当前线程,也可以切换到线程列表中的其他线程。
表 4.3 处理多线程的 GDB 命令列表

清单5介绍了行人识别重放的实现(与第 4.3.4 节中介绍的游戏案例研究类似)。
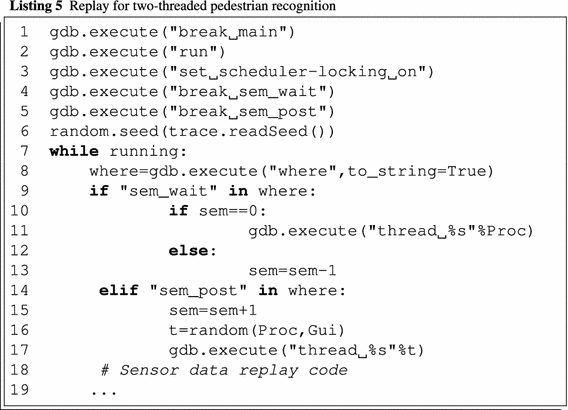
命令”set scheduler-locking on”可禁用当前线程调度器(第5行)。激活该选项后,任何时候都只能执行一个线程。可移植的非抢占式线程库也能达到类似效果。这样,线程的并行执行就被序列化了。为了实现所需的线程切换,我们的工具会在使用的线程操作处设置断点(见第4-5行)。每经过一个线程操作,我们的工具都会根据表4.1中的操作,用GDB的线程命令触发线程开关(清单5,第14-17行)。线程计划的控制与传感器重放集成在一起(清单5,第18行之后)。
与普通线程调度程序相比,在线程操作中使用随机切换可实现更好的线程交错覆盖率。这样,并发错误就能更快地显现出来。
4.3.4 实验
图4.7显示了我们在 X86 英特尔平台的Ubuntu Linux上执行单线程软件Navit时跟踪或记录传感器输入数据的测量结果。测量考虑了一条有1200个GPS坐标的路线。这些坐标由Mockup GPS服务器从文件中读取。测试GPS频率为50、33、20和10 Hz,同时以100Hz 捕获用户光标输入(例如从触摸屏)。正常执行(标记为”Normal”)和记录执行(标记为”Rec”)之间的开销几乎保持不变,因为在断点处暂停执行所用的时间被轮询定时器的调用所占用。这样,我们针对基于定时器软件的方法就能将开销降到最低。对于其他类型的软件,还需要对跟踪进行优化,例如将多个输入分组,一次只跟踪一组输入。
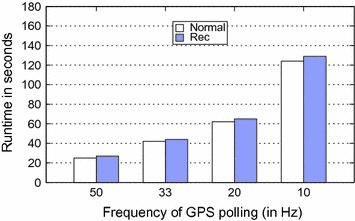
图 4.7 单线程 Navit 传感器输入记录的性能测量。
我们用两个使用 POSIX 线程实现的嵌入式软件示例测试了我们的确定性调度和记录方法。这些示例的性能测量结果如图4.8所示。第一个是基于 ASCII 码的飞行射击游戏。该游戏使用两个线程,一个用于绘制场景,另一个用于读取键盘信息。第二个例子是在车载摄像头的视频数据中识别行人(见第 4.3.2 节)。在每个例子中,我们都使用了两种场景进行测量,一种是短场景,另一种是长场景。我们对游戏进行了测量,直到用户在没有互动的情况下损失5或10条生命为止。我们使用一组60或165张图片作为输入,对行人识别进行了测量。我们的实验在配备ARM CPU和Linux操作系统的NVIDIA Tegra K1上执行了五次。

图 4.8 确定性调度和录制的性能测量结果
在记录游戏场景时,短场景平均需要调度377次线程切换,长场景平均需要调度642次线程切换。在行人识别示例中,平均需要安排186次(短)和475次(长)线程切换。录制行人软件平均需要1.22倍和1.36倍的开销。记录游戏的开销更高,平均为2.86倍和2.98倍,因为需要在更短的时间内触发更多的线程开关。
我们观察到,在两个案例研究中,短时间和长时间的开销都差不多。测量结果表明,只需极少的工作量就能实现高性能记录。每个记录和重放脚本的源代码不到50行。此外,行人识别示例表明,如果使用我们的工具强制进行随机切换,并发错误的检测速度会更快。因此,在我们的测试中,使用我们的方法在几秒钟内就能检测到示例错误,但在使用普通线程调度器进行10次图片输入时却不会触发该错误。为了测量性能,我们触发了两个线程的交替调用,以避免触发错误。
4.4 重放期间的动态验证
即使可以重现错误,也很难在重放过程中找到错误的根本原因。手动调试重放(如使用GDB)非常费力。源代码通常由其他开发人员实现。因此,很难理解是哪一系列操作(如方法调用)导致了故障。此外,也很难理解错误的操作序列是如何造成的。运行时验证领域的方法提供了在运行时通过将执行与正式规范进行比较来自动分析执行的概念。运行时验证测试在执行过程中是否保持了一组特定属性。观察执行情况的组件称为监控器。
4.4.1 技术现状
在线监控器方法是在运行过程中与执行并行运行监控器。在线监控器必须非常高效,因为正常执行不应受到干扰。不过,在线监控器可能会对执行过程中观察到的异常情况做出反应。出现异常时,可在运行过程中启动故障安全或恢复模式。日志监控器检查在软件长期运行过程中捕获的日志文件。跟踪文件是在运行过程中有效生成的。为了不影响正常执行,跟踪应精简或使用快速的附加硬件来实现。离线时,会对跟踪文件进行详细分析。可以检测出跟踪文件中的错误事件序列,指出故障或甚至故障的根本原因。有些方法结合了软件的记录/重放和动态分析 。但是,这些方法没有使用实现复杂断言的框架,也没有在嵌入式平台上进行测试。
表4.4列出了每种模式的优缺点。这两种方法不支持检查故障是否仍然发生(控制测试)。此外,这两种方法都不能细粒度应用(细粒度),因为它们会干扰与用户或其他系统的正常交互。我们的重放方法符合前两类要求(控制测试和细粒度)。不过,只有在表 4.4 中总结的在线模式下才能激活恢复功能。我们认为,长期跟踪和监控最好使用跟踪日志。
表 4.4 监控类型不同特性的比较

4.4.2 理论和工作流程
在重放过程中应用动态验证的概念是基于只跟踪软件的相关输入并离线重放的概念。在重放过程中,可以执行细粒度跟踪。监控或分析可检查这些跟踪是否存在异常。与正常运行相比,重放期间对高效跟踪和监控的要求较低。此外,生成的重放还可在错误修复后用作控制重放。我们认为,重放概念是系统测试的最佳选择,因为生成的控制重放可用作以后的回归测试用例。图 4.9 显示了自动化工具如何支持或取代不同的人工步骤。4.3.3节中介绍的随机调度概念优化了多线程错误(A.)的检测。4.3.3. 错误重放(B.)已实现自动化(见第 4.3 节),并可用作回归测试(D.)。重放(B.)过程中的自动分析支持手动错误修复(C.)。下文将介绍这些分析工具。

图4.9重放期间基于调试器的动态验证工作流程
A. 系统错误检测: 在实际操作中测试软件。在这些测试过程中,会捕捉到进入软件的事件。记录机制通过符号调试器实现,以避免工具化并实现平台兼容性。因此,调试器由脚本控制。开发人员决定哪些事件是相关的,必须捕获。因此,记录可以保持精简。为有效检测多线程错误,线程调度器由脚本控制,在任何线程事件中触发随机开关。
B. 自动重放和分析: 故障序列可在实验室中加载并确定性地重放。重放机制是通过便携式调试器工具实现的。软件通过调试界面在与运行期间相同的硬件上执行,以安排与原始运行期间相同的系统行为。在重放过程中,故障会根据确定性重放再次发生。手动调试完整的执行序列甚至是事件的多个处理路径非常耗时。因此,我们在重放过程中采用动态验证来自动检测潜在的异常情况。这些信息可以为故障提供提示。在运行过程中进行的在线分析会干扰正常执行,但在重放过程中不会造成弊端,因为重放的执行不需要与用户或外部组件进行交互。
C. 手动错误修复: 根据动态验证报告,开发人员可以手动修复故障。该步骤的结果是一个已打补丁的程序。
D. 回归重放: 修改后的程序可通过控制回放进行测试。使用记录的故障输入序列执行程序,观察故障行为是否再次发生。最后,错误重放可作为回归测试套件的测试用例存档。
4.4.3 在回放过程中执行断言
在上一节介绍的工作流程中,动态验证是在重放过程中应用的,用于检测错误原因。本节将展示如何使用断言来检测错误原因。这种断言可以通过调试器轻松实现。因此,在基于调试器的重放过程中,也可以使用调试器监控执行情况。下文将讨论行人识别软件的多线程重放(如第4.3节所述)。在软件重放过程中,可以使用基于断言的验证对事件序列进行分析。通过在相应的方法上设置断点来监控方法调用的顺序。在行人识别示例中,有三个相关事件:recogPed()、drawRec() 和 showImg()。在重放过程中,可以通过方法断点或观察点检查时间条件。图4.10中的自动机会检查加载和处理图像的正确顺序是否被调用。如果发生其他转换,则会检测到违反规范的情况。
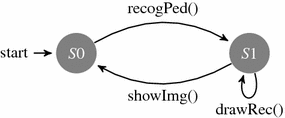
图 4.10 行人识别动作序列自动机
这种监控器可以在GDB Python脚本中轻松实现(见清单 6)。第1-3行根据条件设置断点和观察点。第6-14行检查达到的点和当前状态。

参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
4.4.4 实验
图 4.11显示了不同监控场景下的性能测量结果与多线程记录开销的比较。
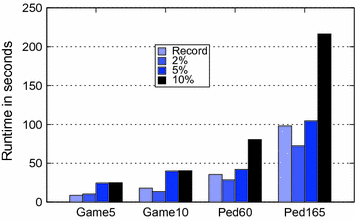
我们测量了使用GDB监控相应软件所有方法中的2%、5%和10%(代表在线监控或日志监控模式)时的运行时间。受监控的方法可与上一节中介绍的并行运行状态机进行比较。我们随机选取了一定比例(2%、5% 或 10%)的方法,并在这些方法上设置了断点。我们还测量了执行多线程记录方法(标记为 Record)的运行时间。我们使用了与第4.3节中相同的四种场景:”飞行”和”射击”。我们使用了与第4.3节中相同的四个场景:有5或10条生命的飞行射击游戏,以及有60或165张视频图片的行人识别。在所有场景中2%的监测方法比记录方法更快。5%的方法的监控速度慢于记录速度,尤其是在游戏场景中。在监控10%的方法时,录制场景的执行时间平均比运行时间快2.45 倍。不过,方法监控的性能主要取决于每个方法在执行过程中出现的频率。表4.5显示了记录场景和每个方法监控场景(2、5 和 10%)的 GDB 停顿次数。
表 4.5 记录和方法监控的GDB操作次数

暂停次数越多,记录或监控时间就越长。然而,与监控方案相比,记录方案的暂停次数较少,运行时开销比例却较高。造成这一结果的原因是,为实现记录,每次断点暂停都需要更多的GDB命令。此外,我们还测试了对15%的行人识别方法进行监控,但第一张图片的监控在10分钟后仍未完成。
4.5 根本原因分析
在上一节中,我们展示了如何通过将执行的操作与规范属性进行比较来检测错误的操作序列。错误序列触发了错误,导致程序崩溃。然而,在许多情况下,并不存在正确或完整的操作规范。通常就是这种情况,因为规范属性往往已经指出了潜在的故障,可以手动修复。在本节中,我们将考虑语义错误(在没有规范的软件中),即错误的根源在于数值处理或程序逻辑。我们将介绍一些概念,用于检测处理过程中错误或缺失的方法调用,并确定相应错误逻辑的根本原因。
4.5.1 技术现状
本节介绍了非崩溃错误定位和嵌入式软件监控领域的最新技术。
4.5.1.1 Delta调试
《程序为何会失败》一书介绍了软件故障定位的不同概念。书中介绍了几个动态分析概念,包括三角调试和异常检测。其中一些概念在我们的工作中也有类似的考虑,例如我们的delta计算方法。后来Burger和Zeller的工作开发了用于定位非崩溃错误的动态切片。他们采用了多个步骤,通过回溯执行过程中的错误来隔离故障位置。然而delta调试基于对程序的实验,以自动生成通过运行和失败运行,这在嵌入式环境下是困难的,且耗费运行时间。
4.5.1.2 非崩溃错误的动态验证
Zhang 等人提出了一种检测错误配置导致的非崩溃错误的方法。它剖析了失败配置和非失败配置的执行情况。许多嵌入式软件甚至不需要配置,错误可以在源代码中找到。Liu等人应用支持向量机对非崩溃错误的通过运行和失败运行进行分类。他们的方法在方法级别上生成行为图,以比较不同的运行。为了进行分类,需要大量的输入运行,而且只能检测到可疑的方法(而不是相关的源代码行)。Abreu使用基于频谱的覆盖率分析实现了嵌入式软件的故障定位。他们应用基于模型的诊断来改进分析结果。与Tarantula类似,他们将每个失败运行的执行语句覆盖率与通过运行的语句覆盖率进行比较。他们假定失败运行和通过运行的测试用例集都是可用的。然而,所有方法都需要一组失败运行,用于分类。在我们的系统测试用例中,没有大量的非失败运行和失败运行可用于分类。
4.5.1.3 监控嵌入式软件
为实现故障定位,必须对软件进行监控。Amiar等人使用特殊的跟踪硬件来监控嵌入式软件。他们在单个跟踪上应用基于频谱的覆盖分析。当检测到一个故障周期时,将其与之前的类似周期进行比较,以检测基于频谱的覆盖范围脱差。不过,它们假设有适用于特定嵌入式平台的跟踪硬件。这种硬件通常价格昂贵。有几种运行时验证方法使用 GNU 调试器 (GDB)的廉价调试器接口来实现平台兼容性,但它们没有提出在没有规范的情况下检测错误的概念。FLOMA使用概率采样对软件进行细粒度观察,但并不监控每一行源代码。它会随机决定是否监控特定的执行步骤。不过,概率采样可能会遗漏重要步骤,而且FLOMA需要对源代码进行工具化。Zuo等人提出了一种分层监控方法来加速监控。他们的方法利用软件来监控和分析方法调用序列。之后,只在源代码行级监控可疑部分。通过这种方法,可以加快监控速度。我们的方法扩展了这一方法,并将其应用于调试器工具。
4.5.2 理论和概念
我们对故障回放进行根本原因分析,自动检测出可能是故障根本原因的可疑源代码行。分析结果将形成一份报告,为开发人员提示错误在源代码中的位置。下面,我们将介绍一个基于故障重放和非故障重放的工作流程。我们将软件的执行分成几个部分(见第4.5.2.1节)。一个分区的多个执行过程存在重叠,可以进行比较。一个分区的每次执行称为一次运行。之后,必须检测重放中执行故障的运行(见第4.5.2.2节)。重放中的故障运行将与重放中类似且未被归类为故障运行的多个运行进行比较(见第4.5.2.3节)。为了将失败运行与类似运行进行比较,我们对源代码行进行了细粒度分析,目的是检测出存在错误的源代码行。我们展示了覆盖率分析和不变量生成分析的指标(见第 4.5.2.4节)。然而,使用廉价的调试器接口进行细粒度监控可能会非常缓慢。因此,我们在第 4.5.2.5 节中介绍了一种加速方法。4.5.2.5.我们用开源导航软件Navit中的一个非崩溃错误来举例说明我们自己的方法。如果Navit接收到的GPS传感器数据角度小于 -360,车辆指针将在短时间内无法绘制。例如,在繁忙的街道上寻找正确的十字路口时,这个错误可能会干扰驾驶员。这个错误不会产生异常。只是在图形用户界面中可以短暂观察到。这是由于处理了错误的传感器数据(传感器发送的角度值为
4.5.2.1 分区重放
异常检测领域的最新方法提供了通过比较被测软件的非失败运行和失败运行来检测根本原因的概念。然而,复杂嵌入式软件的执行可能包含执行不同功能的部分。对不同功能进行比较可能会导致许多误报,尤其是在只有一小部分参考运行时。在我们的方法中,我们将嵌入式软件的执行分成几个可比较的部分(执行类似的功能)。嵌入式软件通常会处理传感器数据以更新程序状态。每次执行时的处理过程通常非常相似。图 4.12举例说明了Navit的重放概念。Navit重放包含不同类型的处理,例如GPS处理、触摸屏输入处理或交通数据处理。

从传感器硬件(在第 4.3 节中定义为接收点)读取数据后,即开始处理传感器数据。处理过程由以下元组表示:
Processing = (Start, Run, End)
Start和End表示执行过程中传递的源代码行数。Start是执行过程中系统开始处理传感器数据的位置。End是执行过程中传感器数据处理结束的位置。处理运行包括传感器数据处理过程中的所有操作Ops和方法调用M的列表:
Run = (M,Ops)
和
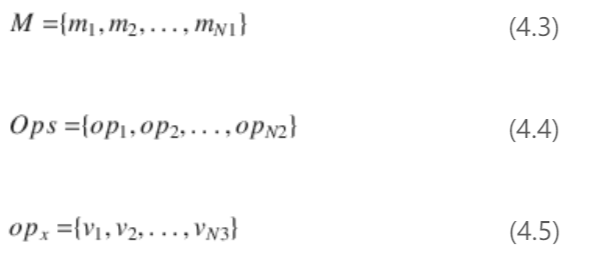
在我们的方法中,执行会在开始时中断。从这个断点开始,处理过程会在方法或源代码行级别上被观察到。
4.5.2.2 检测故障运行
软件分区的每次执行都被视为一次重放运行。在运行故障回放时,特定传感器处理的一次或多次运行会导致观察到的故障。我们提出了一个轻量级概念,用于检测回放中的故障运行。它将与非故障重放中的运行差异最大的运行分类为故障运行(如下所述)。重放的每个运行都可以与其他运行进行比较,因为会执行类似的操作和方法。运行中的差异可能指向故障。要检测故障运行,我们的方法需要进行两次重放。一个是导致故障的重放,另一个是不会导致故障的重放。出现故障的重放运行可与未出现故障的重放运行进行比较。可以通过检查一次运行覆盖了哪些源代码行或方法来比较两次运行。如第4.5.2.5节,在此阶段考虑方法的覆盖范围更为有效。
表 4.6 显示了示例矩阵(代表 Navit Bug),其中包含重放的每次运行的方法覆盖率(就像为跟踪提出的那样)。
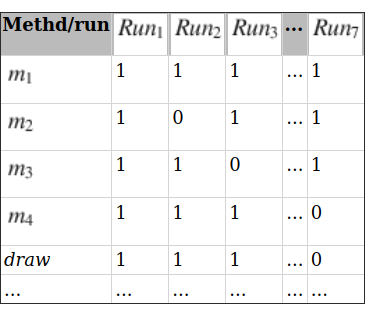
可调用方法在行中表示。运行用列表示。单元格中的值1表示该行中的方法由相应列中的运行执行。可以使用汉明距离(hamming distance)比较两个运行的差异,即计算两列运行在行中的差异。在我们的例子中:distance(Run1,Run7)=2,distance(Run2,Run7)=3, distance(Run3,Run7)=3。为了简单明了,我们考虑了一些伪方法m1-m4和绘制方法。
利用上述矩阵和汉明距离,通过比较故障重放中的每个运行和非故障重放中的每个运行来检测故障。故障重放中与非故障重放中所有运行不相似(或差异最大)的运行被视为故障运行。图4.13显示了故障重放中的运行7与非故障重放中的每个运行的比较情况。Run7与非失败运行的差异最大,因为缺少了对车辆指针的绘制方法的调用。每种方法的出现次数也可以与汉明距离相结合。这样,如果一个运行比另一个运行执行了更多的方法,那么两个运行中的一个方法就可以被归类为不同的方法。还可以考虑调用序列。不过,方法覆盖率的监控速度要快于源代码行覆盖率(见第4.5.4节)。此外,还可以将若干次运行归类为失败运行。例如,可以将与非失败重放的运行相比出现20%差异的运行归类为失败运行。不过,以下解释以一次失败运行为基础。注:如果多个运行排序的距离相同,则选择最近的运行(因为预计错误将出现在重放的末尾)。
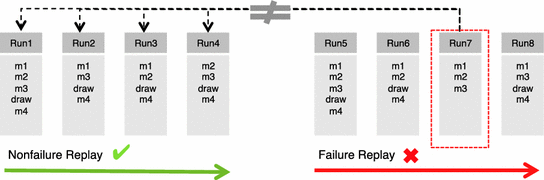
图 4.13 检测故障运行
在这里,故障重放中的运行7与非故障重放中的所有其他运行差别最大。这意味着Run5、Run6和Run8在非故障重放中都有相应的运行,其汉明距离小于 Run7 与非故障重放中各运行的汉明距离。
4.5.2.3 检测相似运行
在上一节中,我们介绍了检测故障运行的概念。通过将故障运行与无故障运行进行比较,可以检测出异常。因此,我们的方法会在故障回放中检测与故障运行相似但未被归类为故障运行的若干运行,即使用汉明距离检测与故障运行具有相似方法覆盖范围的运行。图4.14显示了失败重放。在本例中,与失败运行 Run7 最相似的运行是 Run5。这样,故障运行就会与其最相似的运行进行详细比较。这一概念基于近邻模型,该模型同样适用于跟踪硬件的日志文件。我们的方法是在发生故障运行的同一重放中检测类似运行,这些类似运行是在与故障运行相同的上下文(例如,考虑配置上下文)下执行的。
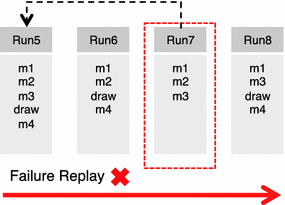
图 4.14 检测类似运行
在测试中,我们检测到三个运行与故障运行相似。我们将使用delta分析法对这些运行和故障运行进行详细比较。
4.5.2.4 Delta计算
对故障运行和类似运行进行详细比较,以检测可指向故障根源的Delta。将类似运行与故障重放中的故障运行进行比较时,可采用不同的指标来识别可疑源代码行。我们以Navit Bug为例,介绍Delta分析的概念和指标。
Navit bug基于GPS处理中的错误计算(伪代码见清单 7)。如果角度小于0,第2行中的角度值会加上360。但是,如果角度小于-360,则角度在第2行后保持负值,第5+6行被跳过,并且不会绘制车辆指针。在正确的执行过程中,应该对角度计算进行数学调制运算,以产生一个正值。第5行和参数变量lazy将在下一节中解释。
在我们的示例中,以下对vehicle_update方法的GPS输入序列触发了错误(…{42, 9, 40, 0},{42, 9, 55, 0},{42, 9, -370, 0},{42, 9, 70, 0})。这里第三输入端发送错误的角度数据,例如来自传感器设备的数据。

我们采用故障定位度量来检测故障重放中此类错误的根本原因(在本例中,第2行中的错误计算)。我们用三个系数来定义这些指标,每个可执行源代码行都会生成这三个系数。这些系数用于计算满足特定源代码行op的特定特征的运行次数。这些特征定义了导致故障或未导致故障的运行次数。它们还定义了是否涵盖特定源代码行操作。

Tarantula、Jaccard 和 Occhiai 等人给出了常用的故障定位指标。这些指标定义如下:

Tarantula衡量失败运行主要执行哪些行。这些行被认为更有可能是失败的根本原因。如果许多非故障运行也执行了该行,则其可疑程度会降低。Jaccard 系数也是基于e_f,但当许多非失败运行执行了该行或许多失败运行未执行该行时,可疑排名会降低。Occhiai还对 $$e_p$ 和 n_f之间的差值进行了加权。因此,当许多非失败运行同时执行该行,而许多失败运行同时不执行该行时,排名就会降低。前面介绍的指标主要考虑的是哪些源代码行经常出现在失败运行中。然而,在嵌入式软件出现非崩溃错误时,错误的原因可能是缺少对操作系统 SDK 库的调用。此外,失败运行中遗漏的源代码行可能指向错误的条件逻辑评估。将失败运行中的遗漏代码与非失败运行中的遗漏代码进行比较,可以发现失败的原因。因此,我们认为有必要对失败运行中的缺失特征进行排序。AMPLE 指标(4.9)也考虑了失败运行中的缺失特征。
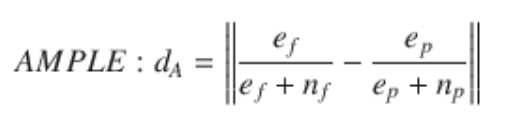
表 4.7显示了Navit错误示例(见清单 7)中三个相似运行RunSim和一个失败运行RunFail的不同度量结果。得出的系数越高,相应源代码行的可疑度就越高。我们发现,每个指标都将索引为2的操作列为可疑操作。然而,尽管AMPLE将另外指向错误条件情况的操作5和6列为可疑操作,但却未将其列为可疑操作。
表 4.7 按示例计算指标
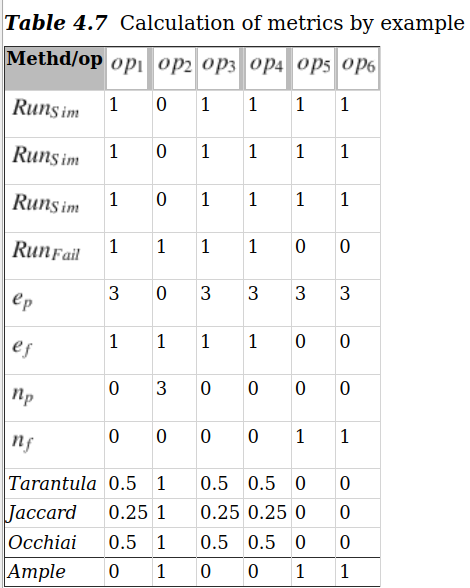
在大多数故障定位方法中,度量指标会产生一个源代码行列表,并根据其可疑程度进行排序。然而,要根据该列表对源代码进行人工评估是很困难的。在我们的使用案例中,我们的工具会在重放过程中在最可疑的源代码行上设置断点。开发人员可以在重放过程中逐步查看可疑行,并检查哪些行在失败运行和非失败运行中被执行。我们的工具只在AMPLE可疑度排名为1的源代码行上设置断点。此外,它还会在每一行可疑源代码上注明,该行是否在故障运行中被执行(但未在任何类似运行中执行),或是否在每个类似运行中被执行(但未在故障运行中执行)。还有一些方法提出了可疑度量的组合,例如将AMPLE和Occhiai结合起来。这样,机器学习算法就会生成不同指标的加权组合。研究表明,使用组合指标可以获得更好的指标结果。不过,这需要一个学习阶段,而在我们的使用案例中这是不可能的。
之前,我们展示了delta计算如何能够显示故障重放中的故障运行与重放中一些类似运行之间的覆盖率差异。然而,只有通过监控每一行源代码中的所有变量值,才能发现从错误的变量赋值开始传播的根本原因。
在我们的示例中,GPS 输入的另一个序列也可能触发错误:({42, 9, 340, 0},{42, 9, -355, 0},{42, 9, -370, 0},{42, 9, -355, 0})。当传感器发送小于0的数据并逐步切换到小于-360的角度时,就会出现这种序列。在此序列的重放过程中应用基于覆盖率的分析,无法检测到错误的源代码行(清单7中的第2行),因为第2行在每次运行中都会被执行。但是,如果监控每行源代码中的所有变量值,就可以检测到根本原因。
变量值中的异常情况可以使用不变量来检测。不变式是为每次运行存储的变量/值对的特征。非故障运行所持有的不变式可与故障运行所存储的不变式进行比较。因此,我们会自动为非失败运行和失败运行生成不变式。范围不变式检查在运行期间观察到的变量值的范围。在我们的 Navit例子中,公式 (4.10) 中的不变式存储在每次非失败运行中。该不变量可在失败运行中进行检查,因为在失败运行中该不变量被违反。在我们的实现中,我们为每一行通过的源代码生成不变式。
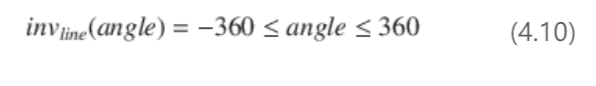
然而,由于参考运行较少,很难建立范围不变式。变量/值对之间的关系不变式检查两个数值变量之间的关系。变量关系通常在条件分支中进行检查。这种关系可能是变量角度总是大于特定源行中的变量懒惰值(4.11)。
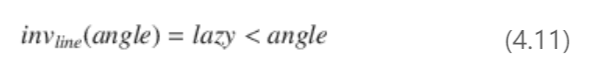
我们的分析将每个变量值与所有其他变量值进行比较,以检测变量之间的关系。在Navit示例中,调用vehicle_update方法时总是使用第四个变量lazy,它定义了绘制模式,在大多数情况下为0或1。将变量angle与变量lazy比较,可以发现在操作2之前,angle

图4.15检测两个 Navit GPS 处理之间的不变量Delta
在图4.15中,故障运行中第3行和第4行的错误关系正好指向故障的根本原因。由此产生的分析报告包括通过比较故障运行与类似运行的覆盖范围而发现的异常。此外,报告还包括生成的关系不变式,这些关系不变式在故障运行和类似运行之间存在差异。
4.5.2.5 加速监控
许多方法使用特殊硬件来监控被测嵌入式软件。然而,这种硬件可能很昂贵,甚至无法用于新平台。因此,我们提出了一种如何优化监控以实现快速动态验证结果的方法。大多数开发人员已经使用增量方法手动调试软件。他们首先在方法上设置断点,开始检测方法调用序列中的异常。然后,他们检查可疑方法,并逐步完善检查。我们的工具通过自动应用这一概念,实现了对错误根源分析的加速监控。首先,我们定义了单级监控(SL)的基本概念。
单级监控-SL:在(处理)运行过程中,对每行已执行的源代码进行单步监控。它监控每个被监控源代码行的当前变量值。
上一节介绍的分析可应用于 SL 监控生成的跟踪。不过,运行单级监控可能会比较慢。软件方法的执行频率通常远低于源代码行。因此,监控方法通常比监控每一行源代码更快。
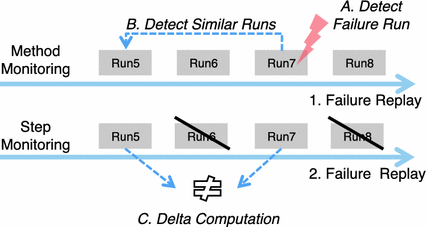
多层次监控 -ML:在第一次重放中,对方法调用进行监控。在此方法调用跟踪中可应用以下活动: 检测故障运行和检测类似运行。在第二次重放中,通过单步监控详细监控故障运行和类似运行。Delta计算可应用于生成的跟踪。这样,所有运行(尽管有故障)和类似运行都无需详细监控。
图 4.16举例说明了这一概念。图中显示了两个重放:一个用于方法级监控,另一个用于通过单步详细监控相关运行。在方法层面,首先将故障运行与非故障重放进行比较,从而检测到故障运行 (A.),如第 4.5.2.2节所述。图 4.16 中的故障运行是运行7。然后,在方法层 (B.) 上识别出与失败运行类似的运行,如第4.5.2.3节所述。里的相似运行是Run5。不过,我们的方法可以检测并处理多个类似运行。失败运行与类似运行(Run5和Run7)之间的区别是通过单步监控(与SL相同)和分析每一行源代码来实现的,如第4.5.2.4节所述。因此,在本示例中,不对 Run6 和 Run8 进行详细监控。
然而,每次方法通过时暂停也会导致较长的监控时间(如第4.5.4节所述),尤其是在高频率调用短方法时。因此,在下文中,我们提出了一种基于调试器的高效监控运行方法覆盖率的概念。
ML方法监控-MLMethd: 方法覆盖率监控只跟踪一次运行中每个已执行的方法。
算法1以伪代码的形式展示了 MLMethd 的概念。通过这种方式,方法覆盖率的监控是高效的,因为监控工具只需对每个方法跟踪一次。

然而,在检测到故障运行并计算出类似运行后,Delta计算步骤需要进行细粒度跟踪。对该轨迹的监控可能非常缓慢。逐步细化可以加快监控速度。MLMethd会产生一个可疑方法(relmethds)列表,这些方法会在失败运行或类似运行中执行。
ML 回溯监控-MLBack: 识别 relmethds 中方法的回溯。首先对这些回溯中出现的每个方法进行监控,而不介入被调用的方法(边步骤)。在类似运行或失败运行中执行的方法不会受到监控(无法进行比较)。MLBack 包括 MLMethd。
在 Navit 示例中,我们考虑了五种不同的方法:
- update:根据 GPS 输入数据更新当前车辆状态。
- route: 代表路线计算。
- vehi: 代表车辆绘制方法。
- set: 更改绘制模式。
- draw: 调用绘制车辆指针。
图 4.17 展示了 Navit bug 的 MLBack 概念。每条黑线(或实线)代表一个受监控的方法。每条红线(或虚线)代表一个未监控的方法。

图 4.17 多级回溯 (MLBack) 监控
首先,重放会监控方法覆盖范围,并检测到失败运行中的绘制方法未命中。根据方法监控,检测出与失败运行类似的几个运行。在MLBack 期间,在非失败运行中调用 draw 的回溯中出现的方法被收集到relmethds中。在第二次重放过程中relmethds中的方法会在相似运行和失败运行中受到监控,但不会步入被调用(或侧步)的方法。在步入这些方法的过程中,会对局部变量和方法参数变量的值进行监控。MLBack 的结果是包含异常suspectmethd 的方法列表。方法update和vehi.在不进入边步骤(此处为路由和设置)的情况下受到监控。这样,与我们考虑的错误无关但需要大量操作的路由计算就不会受到监控。此外,不监控绘制,因为它只出现在相似运行中,而不出现在故障运行中(无法比较)。在vehi中计算angle+=360后,可以检测到变量值的第一次异常。
定义ML步骤监控-MLStep: 此监控概念将可疑方法列表suspectmethd作为输入。这些方法会在额外的重放中受到监控,并被称为边步骤。在类似运行或失败运行中执行的方法仍不会受到监控。
在Navit示例中,执行了第三次重放以额外监控可疑方法中的边步骤(见图 4.18)。
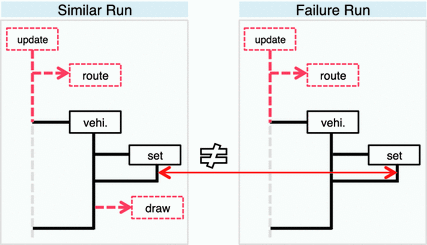
图 4.18 多级步骤 (MLStep) 监控
在这里,还通过侧步骤对方法车辆进行监控。这包括步入方法集(以及图 4.18 中未显示的一些其他方法)。在Navit的另一种实现中,方法集(或由 vehi.调用的另一个方法)可能包括 $$angle+=360$$ 的错误源代码行,之后角度和懒惰之间的错误关系会被检测到。
4.5.3 执行
本节介绍如何通过单步跳过每一行源代码来监控回放中的一组运行(单步监控)。在源代码层面,对运行中执行的每一行源代码的变量值进行监控。在第二次重放中,SL和ML都需要这种实现方式。我们将展示如何实现方法级监控(方法覆盖监控)。在方法层面,运行中已执行方法的覆盖率受到监控。此外,我们还展示了如何使用GDB Python脚本实现MLBack和MLStep。
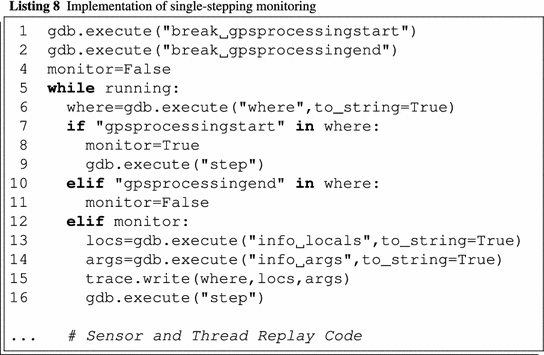
4.5.3.1 单步监控
清单8显示了Navit示例的单步监控实现(考虑到GPS处理)。第 1-2行在源代码中GPS处理开始和结束的位置设置断点。如果到达处理开始的位置(第7行),则激活监控(第8行)。如果激活了监控,则会通过打印局部变量和参数变量来监控处理过程中的每一步(第13-14行)。通过执行 GDB step命令(第16行)到达被测软件的下一行源代码。
4.5.3.2 方法覆盖监控
清单9显示了 Navit示例方法覆盖监控的实现(考虑到GPS处理)。第 1-2行在源代码中GPS处理开始和结束的位置设置断点。此外,在 Navit 软件的每个方法上都设置了断点(第5-6行);它们在执行开始时被禁用(第7行)。如果到达处理开始的位置(第10行),监控将被激活(第11行),此外,Navit 软件中每个方法的断点也会被启用(第12行)。如果只需监控已执行方法的覆盖范围,可在首次通过后禁用每个断点(第 18-19 行)。

4.5.3.3 方法回溯监控
清单10显示了Navit示例(考虑到 GPS 处理)中方法回溯监控的实现。第2-3行在先前方法监控和分析报告的relmethds中的所有方法上设置断点。使用GDB命令next(第14行)对这些方法进行步进,同时监控变量值,而不步进到被调用的方法(侧步)。MLStep的实现与此类似,但它监控的是MLBack分析所报告的方法。它使用GDB的命令步而不是命令下一步。

4.5.4 实验
前面几节介绍了动态验证如何帮助开发人员分析错误的根源。在第 4.5.2.5 节中,我们介绍了加速监控这些分析的优化技术。我们在西门子测试套件的Replace工具中测试了多级监控 (ML) 概念。Replace程序有32个不同版本,并包含多个测试用例。我们测试了前 20 个版本中的 19 个,它们都包含一个错误(我们无法手动检测第 19 个版本中的错误)。为了生成可能的随机重放,我们实施了一个重放生成器,从西门子测试套件故障矩阵中的 5542 个测试用例中随机选择 99 个不会导致故障的测试用例。在重放的最后,我们添加了一个执行错误的失败运行作为运行 100。为了随机选择测试用例,我们使用了 Python 随机函数,每次生成的重放均使用 100 种子。我们生成了包含 200 个非失败运行的第二个重放,以模拟噪声(使用相同的种子 100)。我们将此重放作为非故障重放,用于第 4.5.2.2 节中介绍的故障运行检测。4.5.2.2. 对于 SL,我们监控了 100 次重放运行的执行情况,收集源代码行覆盖率以及局部变量和参数变量的数值。对于 ML,我们根据方法覆盖率检测失败运行。在此实施过程中,我们还使用了特定方法的出现次数来构建 hamming 词(如第 4.5.2.3 节所述,使用 threshold=5)。此外,还根据方法覆盖率确定了与失败运行最相似的三个运行。在第二次重放中,考虑到行覆盖率和变量关系,对故障运行和相似运行进行了监测和比较。我们发现,ML 监控比 SL 监控要快得多。图 4.19 显示了单级(SL)监控与多级(ML)监控 Replace 的运行时间对比(对于我们可以使用算法检测到相应错误的版本)。

图 4.19 对替换进行多层次分析的监控运行时间
对于一般评估,只包括监控运行时间,因为分析监控结果的运行时间取决于分析类型。ML包括方法级的第一次重放监控和行级的第二次重放监控。ML和SL监控了失败运行和三个最相似运行的delta计算的所有局部变量、参数和宏。我们发现,ML监控比SL监控快得多。对于Replace,监控速度提高了varnothing 9.5倍。表4.8 显示了SL和ML报告的可疑行数,以及不同Replace版本的失败运行与三个相似运行之间的汉明距离。
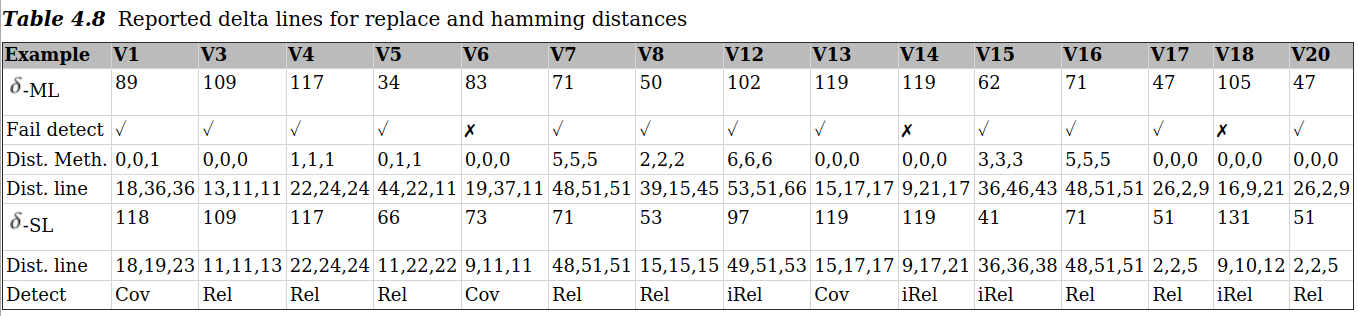
delta-ML/SL示报告的可疑行计数。Fail Detect(失败检测)显示是否能在方法层面上检测到失败运行。Dist. Meth. Detect显示是否通过覆盖率delta计算或变量关系delta计算检测到有问题的线路。在6个版本(3、4、7、13、14、16)中,ML和SL检测到的相似运行是相同的。在这些情况下,报告的可疑行也是相同的。在15次实验中,SL和ML检测到了该版本的所有错误,这些错误要么指向覆盖率Delta (Cov),要么指向变量关系Delta (Rel)。有四个错误报告间接指向了失败(第 12 版–关系三角中多次出现 MAXPAT;第15版和第18版–错误行中其他变量的关系差异;第14版–if-clause 封闭行中的关系差异)。我们用其他四个版本的Replace(2、9、10、11)测试了我们的工具,但在这些测试中,我们用ML和SL进行的delta分析无法检测到有错误的源代码行。在这里,错误主要是由if子句中访问数组(仅在寄存器中可用)的谓词引起的。Fail Detect一行显示的是可以在方法级别检测到失败运行的版本。在第4.5.2.2节中介绍的优化轻量级分类中,第6、14 和18版无法检测到失败运行。4.5.2.2节中介绍的优化的轻量级分类方法无法检测到第6、14 和18个版本的失败运行。因此,基于100次运行的故障重放和200次运行的非故障重放,63%的错误可以通过ML自动有效地定位。
在某些情况下,ML 的 delta 计算报告的误报率较低,这是因为 SL 检测到的相似运行恰好造成了更多的变量关系差异。总的来说,SL 和 ML 的报告质量差异主要取决于重放中不同运行的组成。注:SL 在失败的运行和重放中的每个运行之间进行Delta计算(cov+rel)会导致解析和比较监控结果的运行时间增加(Replace 在不监控三个运行的情况下进行Delta计算的运行时间为 $$varnothing $$ 13.7 s)。
不过,对于指令密集型计算而言,ML 监控仍然太慢。例如,对 Navit 方法级路由计算(高频率调用转换方法)的监控,在每次方法调用时暂停执行,速度会非常慢。我们在 NVIDIA Tegra K1 ARM 平台上测量了包括路由计算在内的 20 个 GPS 坐标处理的方法监控,结果显示需要 50 多小时。
图
4.20显示了我们使用 Navit 软件(MLBack 和 MLStep)的细化功能加速监控根源分析的实验。
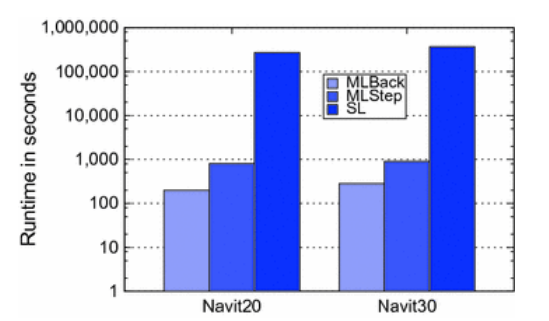
我们测量了包含20个GPS坐标的重放和包含30个GPS坐标的重放,这两个重放都包含前面章节中的Navit错误。在这些实验中,每种分析(MLBack、MLStep 和 SL)都检测到了错误的根源。这些测量包括 Navit GPS 处理的路由计算。
在20个GPS的情况下,MLBack比SL快1354倍。在20GPS情景下,MLStep比SL快334倍。对于30GPS方案,加速系数为:MLBack1292倍,MLStep405倍。加速度并没有随着序列的延长而增加,因为开始时的一些GPS处理(重新计算和重新绘制航线)需要更长的时间。Navit的测量结果表明,具有高监控开销的分析可以通过分层细化加速,从而实现可行的动态验证性能。
4.6 小结
本章介绍的方法展示了自动化工具如何支持人工调试过程。我们介绍了最先进的自动错误重现方法。然而,这些方法主要是针对特定平台开发的。因此,我们开发了基于调试器的方法,可移植到不同的嵌入式平台。它可以重现传感器输入,并实现随机线程调度,以高效定位并发错误。本章介绍了如何利用调试器工具实现断言,以定位并发错误的原因。随后,我们展示了如何在不需要规范或断言的情况下定位错误的根本原因。根源可追溯到导致错误的变量值变化。基于一个导航软件,我们演示了如何加速这些根源定位技术。这样,就可以优化慢速监控工具的应用,使其适用于实际情况。
所介绍的方法几乎不需要对其他调整。不过,实现的脚本都非常短(每个记录/重放或监控脚本都短于200LOC)。因此,该工具具有很强的可扩展软件进行性。此外,大多数嵌入式平台都支持GDB,我们的脚本实现也适用于大多数嵌入式平台。只需稍加修改,我们就能在ARM Linux上运行所有脚本,就像在X86Linux上一样。
