文章目录
- 1. TubeR: Tubelet Transformer for Video Action Detection
-
- 摘要和结论
- 引言:针对痛点和贡献
- 模型框架
-
- TubeR Encoder:
- TubeR Decoder:
- Task-Specific Heads:
- 2. Holistic Interaction Transformer Network for Action Detection
-
- 摘要和结论
- 引言:针对痛点和贡献
- 模型框架
- 实验
- 思考不足之处
- 3. VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
-
- 摘要和结论
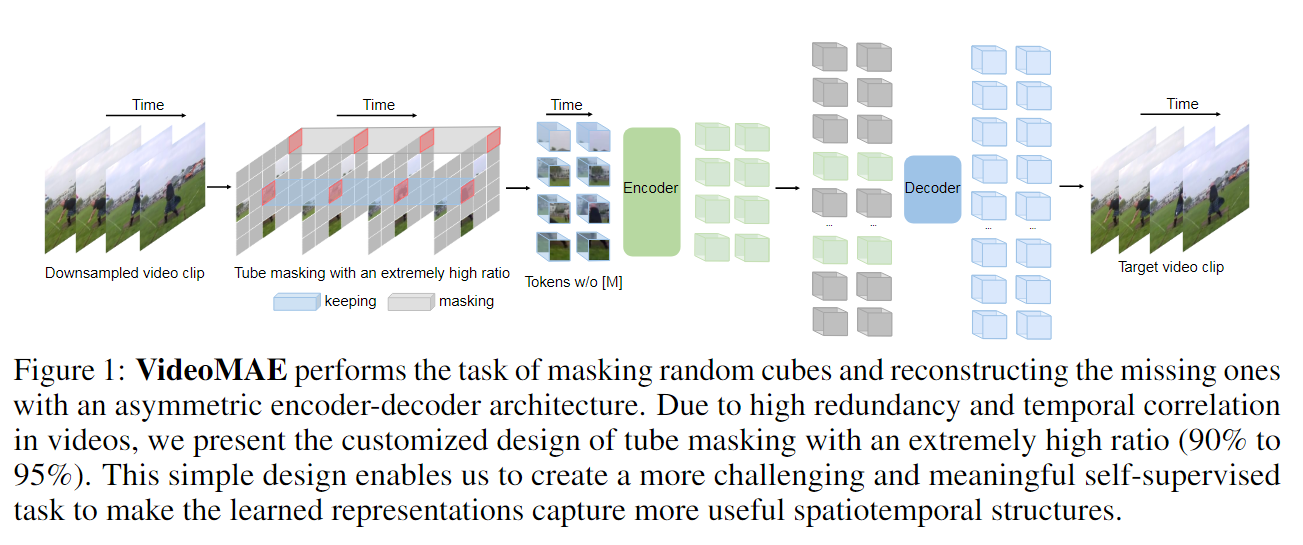
- 视频数据的特性
- 模型框架
1. TubeR: Tubelet Transformer for Video Action Detection
《TubeR: Tubelet Transformer for Video Action Detection》论文+代码分析
摘要和结论
1.提出了一种用于人体动作检测的Tubes Transformer的框架
2.基于tubelet-query和tubelet-attention能够生成任意位置和规模的Tubes
3.Classification Head能够聚合短期和长期的上下文信息
引言:针对痛点和贡献
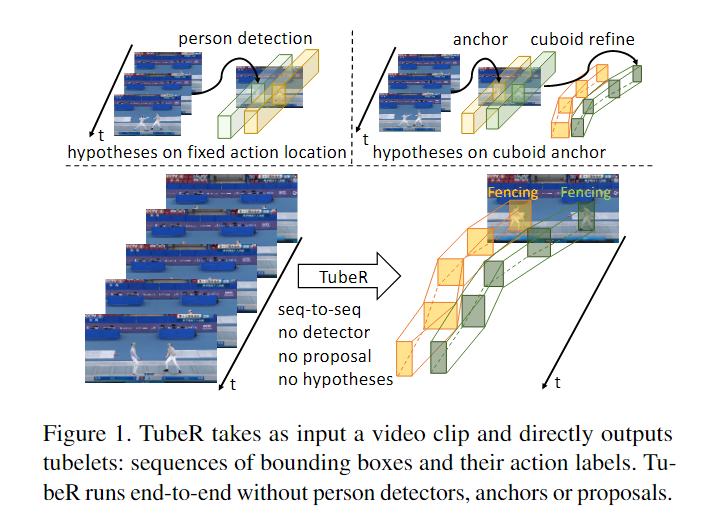
模型框架

TubeR Encoder:

TubeR Decoder:
Tubelet query: 作者提出了一种通过学习一小组tubelet queries来代替手动设计3D anchors的方法,从而更好地表示tubelets的动态特性。其中,每个tubelet query包含了Tout个box query embeddings,用来预测tubelet在每个时间帧上的位置。
- Tubelet attention: 为了对 tubelet query 中的关系进行建模,提出了一个 tubelet-attention (TA) 模块,其中包含两个自注意力层。self-attention layer:识别动作受益于参与者之间或同一帧中的参与者和对象之间的交互。temporal self-attention layer:这一层是为了方便TubeR查询跟踪演员并生成聚焦于单个演员而非固定区域的动作tubelet。利用TubeR查询来跟踪演员并生成聚焦于单个演员的动作tubelet,并且通过tubelet attention模块生成tubelet查询特征。
-
Decoder: 包含一个 tubelet-attention 模块和一个交叉注意(CA)层,用于从 Fen 和 Fq 解码 tubelet 特定特征 Ftub。

Task-Specific Heads:
-
Context aware classification head:


我们从骨干特征中查询动作特定特征 Ftub,然后从一些上下文特征 Fcontext 中获取其他信息来增强 Ftub,得到最终的分类特征 Fc。
当我们将 Fcontext 设置为骨干特征 Fb 以利用短期上下文信息时,称其为短期上下文头。
短期上下文头采用了自注意力层和交叉注意力层来处理上下文信息和动作特征。 -
Action switch regression head:



2. Holistic Interaction Transformer Network for Action Detection
摘要和结论
- 提出了多模态的整体的交互的Transformer网络(multi-modal Holistic InteractionTransformer Network (HIT) ),它利用了大部分被忽视但关键的手和姿势信息,这些信息对大多数人类行为至关重要。
- 包含RGB流和姿态流的双模态框架。它们中的每一个都分别对人、对象和手的交互进行建模
- 在每个子网络中,引入了一个模态内聚合模块(IMA,Intra-Modality Aggregation module)来选择性地合并单个交互单元。然后使用注意力融合机制(AFM,Attentive Fusion Mechanism)将每个模态的结果特征粘合在一起。最后,我们从时间上下文中提取线索,以便使用缓存内存更好地对发生的动作进行分类。
引言:针对痛点和贡献
痛点:
-首先,这些方法只依赖于检测置信度高的对象,可能会忽略一些重要的对象,这些对象可能太小而无法被检测,或者是检测模型无法识别的新对象。例如,在图1中,演员正在与一些未被检测到的对象互动。
其次,这些模型很难检测与当前帧中不存在的对象相关的动作。例如,考虑动作“指向(一个对象)”,演员指向的对象可能不在当前帧中。
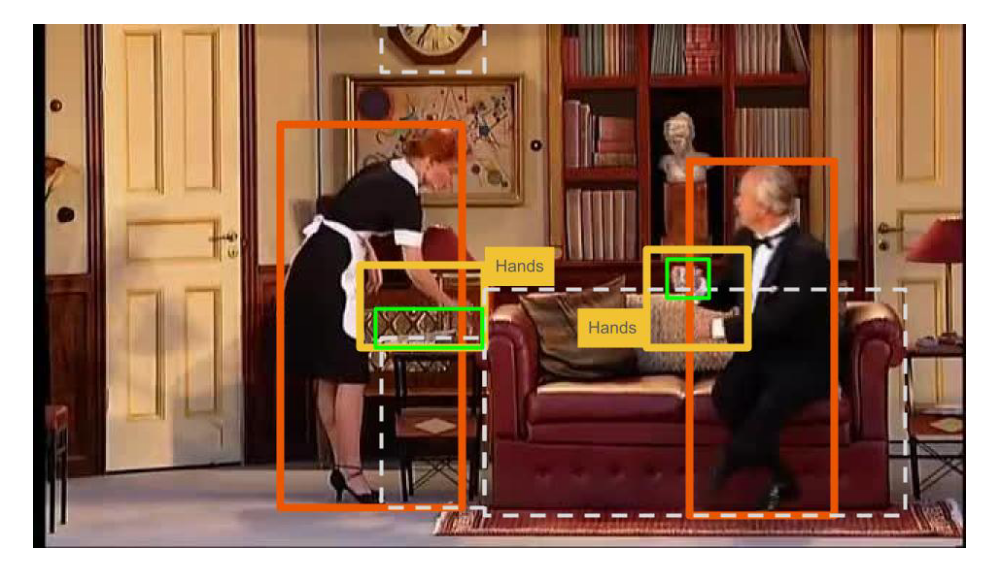
贡献:
- 我们提出了一种新颖的框架,结合了 RGB、姿势和手部特征来进行动作检测。combines RGB, pose and hand features
- 我们介绍了一种双模整体交互转换器(bi-modal Holistic Interaction Transformer,HIT)网络,它以直观和有意义的方式结合了不同类型的交互。
- 我们提出了一个注意力融合模块(AFM),它作为一个选择性过滤器,保留每个模态中信息最丰富的特征,以及一个模态内聚合器(IMA),用于学习模态内有用的动作表示。
模型框架
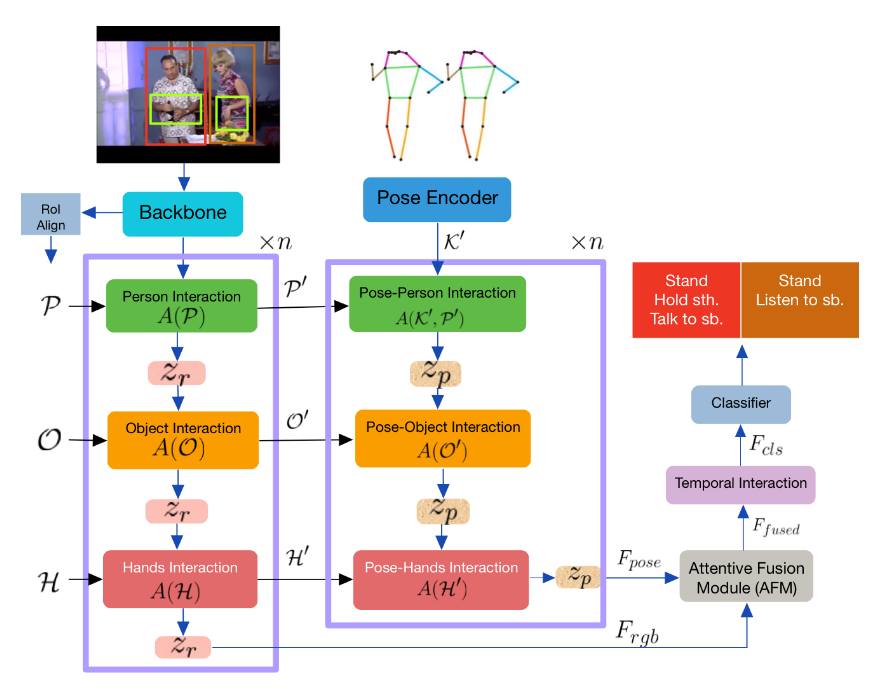
-
我们使用 Detectron [9] 进行人体姿势检测,并创建一个包围人手位置的边界框。遵循最先进的方法[40]、[32]、[28],我们使用 Faster-RCNN [31] 来计算对象边界框建议。视频特征提取器是一个 3D CNN 主干网络 [5],姿势编码器是受 [51] 启发的轻量级空间变换器。我们应用 ROIAlign [12] 来修剪视频特征并提取人、手和物体特征。
-
The RGB Branch:
RGB 分支包含三个主要组件,如图 2 所示。每个组件都执行一系列操作以了解有关目标人员的特定信息。
人物交互模块学习当前帧中人与人之间的交互(或者当帧仅包含一个主体时的自我交互)。
物体和手交互模块分别模拟人-物体和人-手交互。
每个交互单元的核心是交叉注意力计算,其中查询是目标人(或前一个单元的输出),键和值来自对象或手特征,具体取决于哪个模块我们现在处于(见图 3)。
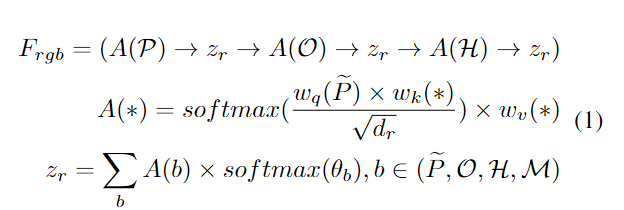
-
The Pose Branch:
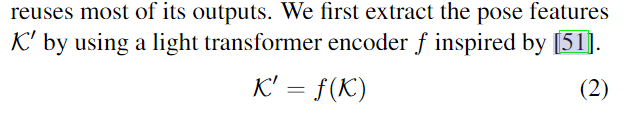


-
The Attentive Fusion Module (AFM):
RGB 和姿势流需要先组合成一组特征,然后再馈送到动作分类器。为此,我们提出了一个注意力融合模块,该模块应用两个特征集的通道级联,然后进行自我关注以进行特征细化。
然后,我们通过使用所使用的投影矩阵 θf 来减少输出特征的大小。我们的消融研究中的表 5a 验证了我们的融合机制与文献中使用的其他融合类型相比的优越性。
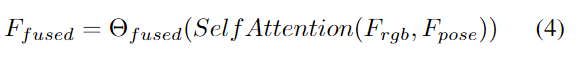
–Temporal Interaction Unit:

实验
Backbone: 我们采用 SlowFast 网络 [5] 作为我们的视频主干网。
Person and Object Detector: 我们从数据集中的每个视频中提取关键帧,并使用[16]中检测到的人物边界框进行推理。作为目标检测器,我们采用 Faster-RCNN [31] 和 ResNet-50-FPN [21, 47] 主干网络。
Keypoints Detection and Processing: 我们采用 Detectron [9] 的姿势模型。作者使用在 ImageNet 上预训练的 Resnet-50-FPN 主干网络进行对象检测。
思考不足之处
- 我们的框架依赖于使用的现成检测器和姿态估计器,并且不考虑它们的失败。 AVA数据集的大量帧拥挤且质量低。因此,检测器和姿态估计器的准确性可能会影响我们的方法。
- 通过分析 J-HMDB 数据集的结果,我们发现了两个主要原因。第一个涉及外观相似的类,例如“throw”和“catch”,它们在视觉上是相同的。
- 二是部分遮挡。请参阅补充材料以获取有关限制的更深入讨论。然而,在这种情况下,对象被遮挡。因此,该模型很难区分“高尔夫”和“摇摆棒球”。那么我们应该如何着手解决这些问题呢?就我们而言,我们尝试汇总尽可能多的信息。然而,拥有如此多的信息是昂贵的。这些问题的最佳答案是更好的时间支持,但这会引发另一个问题:我们如何定义“更好的时间支持”?虽然有些人可能主张更扩展的时间支持,但它会增加计算开销,同时不一定会转化为更高的检测精度。有些行动需要长期的支持,有些需要很少的支持,有些则不需要;因此,决定保留多少内存是具有挑战性的。而如果我们保留更长的内存跨度,那么对特征进行压缩的需求就会更加迫切,而大多数现有的压缩方法都是有损的。
3. VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
摘要和结论
VideoMAE的自监督视频预训练方法,其使用高比例的自定义视频管道遮罩video tube masking来进行视频重构,从而鼓励提取更有效的视频表示。
作者发现,高比例的遮罩仍然可以使VideoMAE表现良好,1)极高比例的掩蔽率(即 90% 到 95%)仍然对 VideoMAE 产生了良好的性能。时间冗余视频内容比图像具有更高的掩蔽率。
并且该方法可以在非常小的数据集上取得令人印象深刻的结果。
此外,作者还发现,数据质量比数据数量更重要,因为预训练数据集与目标数据集之间的领域转移是一个重要因素。
视频数据的特性
与图像数据相比,视频数据包含了更多的帧,也具有更加丰富的运动信息。


解决方法:



模型框架