

编者按:嵌入(Embedding)是机器学习中一种将高维稀疏向量转换为低维稠密向量的技术。其通常用于处理自然语言、图像等高维离散数据。
嵌入能够有效地解决维度灾难问题,减少存储和计算成本,同时提高模型的表达能力。我们还可以通过得到的嵌入向量进行语义相似度计算、推荐系统、分类任务等多种应用。嵌入还可以用于处理非结构化数据,如文本、图像、音频等,帮助机器理解和处理人类的语言和其他感知信息。
IDP开启Embedding系列专栏,详细介绍Embedding的发展史、主要技术和应用。本文是《Embedding技术与应用系列》的第一篇,重点介绍Embedding技术的发展历程,并着重讲解Word2Vec的工作原理、具体实现等内容。
文章作者首先介绍了以往的编码表示方法的局限,指出它们在处理大规模语料时会产生维度灾难和计算复杂度高的问题。然后作者详细解释了Word2Vec模型的工作原理,并给出了具体的PyTorch实现代码。作者认为Word2Vec克服了传统方法的局限性,是一种优雅的大规模语料处理方案。
希望本文能给读者带来Embeddings技术发展脉络的系统性理解,对希望了解和使用Word2Vec技术的读者有重要参考价值。
以下是译文,enjoy!
作者 | Vicki Boykis
编译 | 岳扬
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
01 Embedding技术发展史
将内容表示为更低维的向量,使数据成为更紧凑的数字表达形式,并进行计算,这并非一种新的想法。自从人类进入信息爆炸时代以来,就一直在试图综合这些信息,以便我们可以基于这些信息做出决策。早期的方法有独热编码(one-hot encoding)、TF-IDF、词袋模型(bag-of-words)、LSA和LDA。
早期的这些方法都是基于计数的方法。它们主要计算一个词相对于其他词出现的次数,并以此为基础生成编码。LDA和LSA本质上是一种统计方法,但仍通过启发式方法来推断数据集的属性,而非构建模型。(译者注:意思是使用一些经验法则或规则来猜测数据集的某些属性,而非使用数学模型来描述数据集的属性。这种方法可能不是最准确或最优的,但可以在缺乏完整信息或数据集非常大的情况下提供一些有用的信息。与通过建立数学模型的方法相比,使用启发式方法可能更加快速和简单,但也可能会导致一些误差或不准确。)
基于预测的方法出现较晚,而是通过支持向量机(support vector machines)、Word2Vec、BERT和GPT系列模型来学习给定文本的属性,前文说的这些模型都使用了学习到的嵌入。
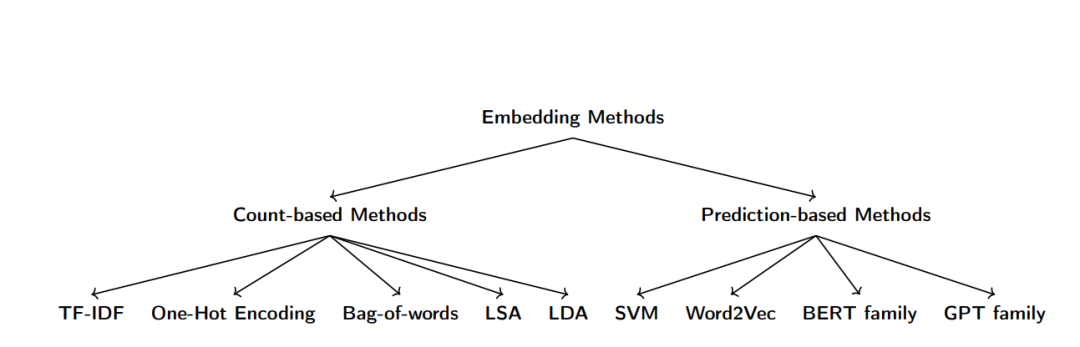
嵌入方法家族谱系图
02 早期方法的局限性
早期基于计数的方法,在处理大规模语料库时面临以下两大问题:
2.1 出现维度灾难
随着特征数的增加,数据集会变得非常稀疏。举例来说,如果一段文本语料由100万个独特的词汇组成,那么使用独热编码就会产生100万个特征向量,每个向量都会极为稀疏,因为大多数句子并不会包含其他句子的词汇。这会带来两方面的问题:
(1) 当特征数量线性增加时,进行计算会变得非常困难。
(2) 当特征数量巨大时,需要更多的数据才能准确可靠地描述这些特征,否则模型就无法良好表达数据,这就是所谓的“维度灾难”。
2.2 计算复杂度较高
以TF-IDF为例,它需要处理语料库中的所有词汇,所以时间复杂度随着词汇总数N和文档数量d的增长而线性增长,为O(Nd)。另外,TF-IDF会生成一个矩阵,如果有10万文档和5千个词汇,矩阵大小就为100,000 x 5,000,随着语料规模的增长,这个矩阵会变得十分难以处理。
(译者注:此处为内容总结,全文请看《What are embeddings》3.4节 Limitations of traditional approaches)
03 Word2Vec
为了克服早期文本处理方法的局限性,并跟上文本语料库规模不断增长的步伐,2013年,Google的研究人员提出了一种优雅的解决方案,名为 Word2Vec[1]。
到目前为止,我们已经从简单的启发式方法,如独热编码(one-hot encoding),发展为机器学习方法(如 LSA 和 LDA),这些方法旨在学习数据集的模型特征。以前,就像最初的独热编码一样,所有的嵌入方法都将重点放置于稀疏向量。稀疏向量(sparse vector)能够说明两个单词之间存在关联,但并不能表明它们之间存在语义关系。例如,“狗追猫”和“猫追狗”在向量空间中的距离是相同的,尽管它们是完全不同的句子。
Word2Vec 是一个模型系列,有多种实现方法,每种方法都着眼于将整个输入数据集转换为向量表示,更重要的是,它们不仅关注单个单词的已有标签,还关注这些表示之间的关系。Word2Vec 有两种构建模型的方法——连续词袋模型(CBOW)和skipgrams模型,这两种方法都能生成密集的嵌入向量,但对问题的建模过程略有不同。无论是哪种方法,Word2Vec 模型的最终目标都是学习参数,最大限度地提高给定单词或单词组的准确预测概率[2]。
在训练skipgrams模型时,首先从初始训练语料(input corpus)中抽取一个单词,然后预测给定的一组单词围绕已抽取的单词的概率。对于”Hold fast to dreams for if dreams die, life is a broken-winged bird that cannot fly”这句话,模型处理这句话的中间步骤是学习、生成一组嵌入,这些嵌入是数据集中所有单词之间的距离,并以“fast”一词作为输入,预测整个短语中其他单词周围的概率,并给出了这些单词在此处的概率值。
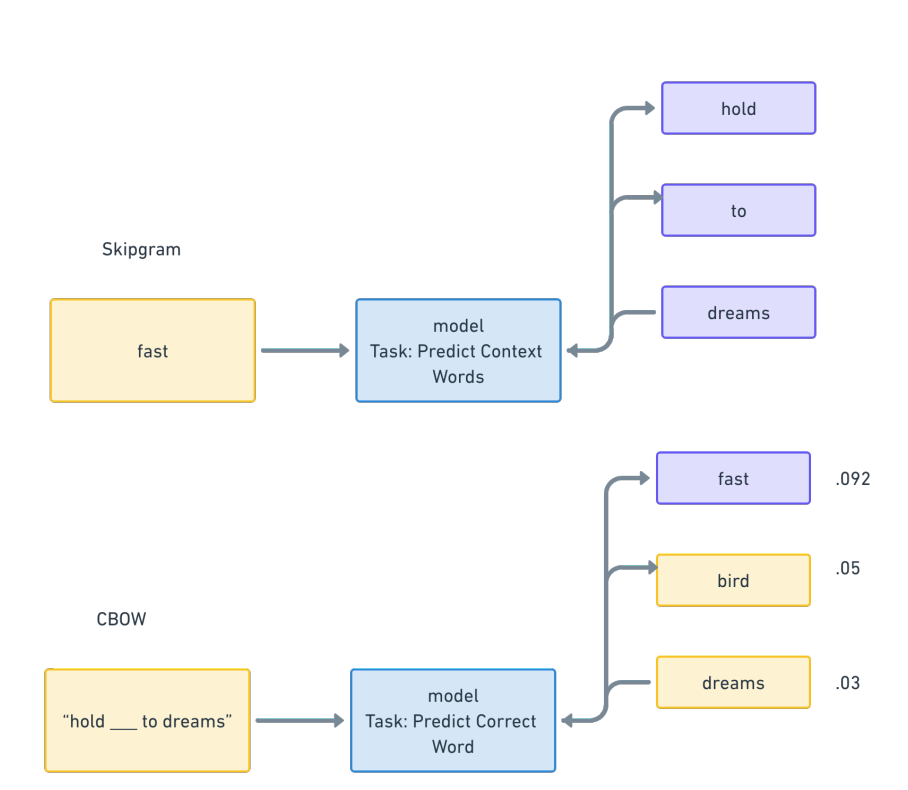 Word2Vec 架构图
Word2Vec 架构图
在训练CBOW时,我们的做法恰恰相反:从一个短语(被称为上下文窗口)中移除一个单词,然后训练一个模型来预测给定单词能够填充空白处的概率。 这个过程可以用下面的公式表示,我们的目标是最大化这个概率。 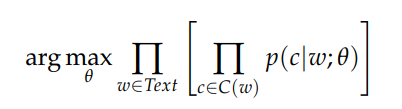
通过优化这两个参数(theta和Pi),我们可以最大化单词在句子中出现的概率,从而学习到适合训练语料的好的嵌入向量。
现在让我们来了解一下 CBOW 的详细实现过程,以便更好地理解其工作原理。这次,在代码部分,我们将从适用于较小数据集的 scikit-learn 转向更适用于神经网络操作的 PyTorch。在最高层是一列输入词,然后通过第二层(嵌入层)进行处理,最后是输出层(只是一个返回概率的线性模型)。
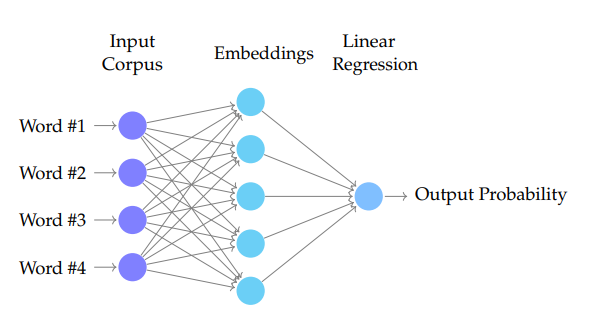
Word2Vec CBOW 神经网络架构
我们将在主流神经网络模型构建库PyTorch中实现这个架构的。实现 Word2Vec 的最佳方法是使用Gensim,尤其是在处理较小数据集的情况下,而且Gensim将各层抽象成内部类,这使得用户体验极佳。但由于我们才刚刚了解它们,我们希望更清楚地看到它们是如何工作的,而 PyTorch 虽然没有 Word2Vec 的原生实现,却能让我们更清楚地看到其内部工作原理。
要在 PyTorch 中建模实现CBOW,需要使用与处理机器学习中的任何问题相同的方法:
1.检查并清理输入数据。
2.构建模型的各层。(对于传统的机器学习模型,只有一层)
3.将输入数据馈送到模型中并跟踪损失曲线。
4.检索训练好的模型工件,并利用它对我们分析的新项目进行预测。
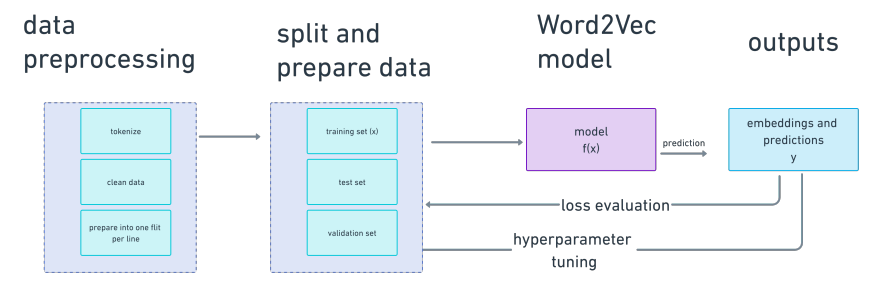
创建 Word2Vec 模型的步骤
先从输入数据开始。在本文中,语料库是我们收集到的所有flits。我们首先需要处理这些数据,作为模型的输入。

Word2Vec输入数据集
要为 PyTorch 准备输入数据,我们可以使用 DataLoader 或 Vocab 类,将文本拆分为token和进行分词,或者说为每个句子创建更小的单词级表示。对于文件中的每一行,我们都会通过将每一行拆分成单个单词,然后删除空格和标点符号,并将每个单词小写化,从而生成token。
这种处理流程在NLP中非常常见,花时间做好这一步至关重要,这样我们才能得到干净、正确的输入数据。该流程通常包括以下步骤[3]:
• 分词 – 通过拆分句子或单词转换为其组成字符
• 去除噪声 – 包括URL、标点符号和文本中与当前任务无关的其他内容
• 单词分割 – 将句子拆分成多个单词
• 纠正拼写错误
 处理输入词汇表并在PyTorch中从数据集构建一个Vocabulary对象[4]
处理输入词汇表并在PyTorch中从数据集构建一个Vocabulary对象[4]
现在已经成功创建了一个可以使用的输入词汇表对象,下一步是将每个单词创建为一个数字位置的独热编码,并将每个位置再映射回单词,这样就可以轻松地同时引用单词和向量。我们的目标是在查找和检索时能够来回映射。
这一步发生在嵌入层中。在 PyTorch 的嵌入层中,我们根据指定的矩阵大小和词汇表的大小初始化一个嵌入矩阵,该层将词汇表中的单词索引到词向量字典中,以便进行检索。嵌入层是一个查找表,可按索引将单词与相应的单词向量进行匹配。首先,我们创建一个独热编码的word to term字典。然后,我们创建每个单词到词向量的映射和每个词向量到每个单词的映射。这被称为双射(bijection)。这样,嵌入层就像一个独热编码矩阵,允许我们进行查找,实现词语和词向量之间的转换。这一层的查找值初始化为一组随机权重,然后我们将其传递给线性层。
嵌入类似于哈希映射(hash maps),也具有自己的性能特征(O(1)的检索和插入时间),这就是为什么嵌入层可以轻松扩展,而其他方法却做不到。在嵌入层中,Word2Vec中每个向量中的每个值都表示特定维度上的单词。更重要的是,与其他方法不同,该方法中每个向量的值都与输入数据集中的其他词语有直接关系。

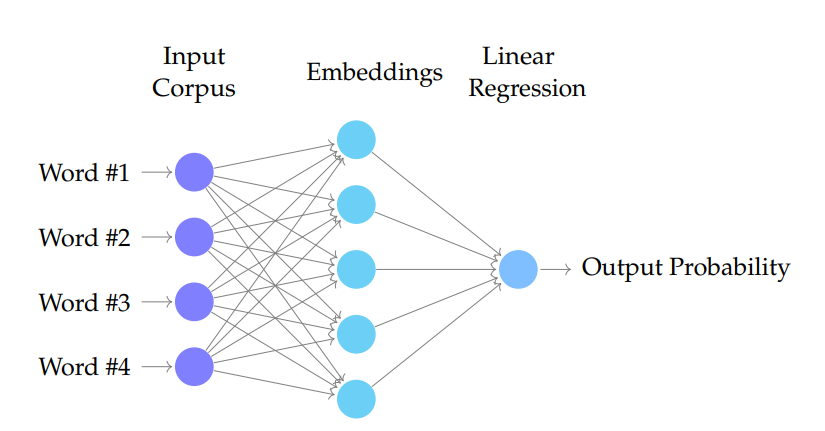
在 Pytorch 中实现 Word2Vec CBOW[4]
得到查找值(lookup values,译者认为此处应为词向量)之后,就可以处理所有单词了。对于CBOW这种方法,需要先选择一个滑动窗口,例如在本文这种情况下,即选择目标词前后两个词作为上下文窗口,然后尝试推断出实际的单词是什么。这就是所谓的上下文向量(context vector),在一些情况下,它也被称为注意力。例如,对于“No bird [blank] too high”这个短语,我们就会尝试预测答案是“soars(翱翔)”,也就是使用softmax概率来计算每个单词在给定上下文中出现的概率,并根据这些概率进行训练和推理。一旦有了上下文向量之后,我们就可以查看loss值(即真实单词与按概率排序的预测单词之间的差值),然后继续。
本文训练该模型的方法是通过上下文窗口。对于模型中的每个给定的单词,都要创建一个滑动窗口,其包括该单词和它的前后2个单词。
接着是使用ReLu激活函数激活线性层(linear layer),该函数会决定给定的权重是否重要。在这种情况下,ReLu激活函数会将我们初始化嵌入层的所有负值压缩为零,因为不可能有反向的单词关系,并通过学习单词关系模型的权重进行线性回归(linear regression)。然后,我们检查每个 batch 的 loss ,即真实单词与我们根据上下文窗口预测应该存在的单词之间的差异,并将损失函数最小化。
在每个 epoch 结束时或将数据输入到模型中进行处理的过程中,将权重传递或反向传播回线性层,然后再次根据概率更新每个单词的权重。这里的概率是通过softmax函数计算的,该函数将实数向量(vector of real numbers)转换为概率分布(probability distribution),即向量中的每个数字都代表一个单词的概率值,该值在0和1之间的区间内,所有单词的概率数值加起来等于1。反向传播到嵌入表(embeddings table)的距离应该会逐渐收敛,具体变化程度取决于模型对特定单词之间接近程度的理解。

PyTorch 中 Word2Vec CBOW 的实现[4]
当完成对训练集的迭代后,我们就训练完成了一个模型,该模型能够检索出给定单词是否是正确单词的概率,并且也能检索出词汇表的整个嵌入空间。换句话说,我们可以利用这个模型来预测单词,并且可以使用嵌入空间来比较单词之间的相似性。
下一期,我们将分享神经网络技术下的Embedding技术,敬请期待。
END
参考资料
[1]Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
[2]Yoav Goldberg and Omer Levy. word2vec explained: deriving mikolov et al.’s negative-sampling word-embedding method. arXiv preprint arXiv:1402.3722, 2014.
[3]Usman Naseem, Imran Razzak, Shah Khalid Khan, and Mukesh Prasad. A comprehensive survey on word representation models: From classical to state-of-the-art word representation language models. Transactions on Asian and Low-Resource Language Information Processing, 20(5):1–35, 2021.
[4]https://github.com/veekaybee/viberary/tree/main/word2vec
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://vickiboykis.com/what_are_embeddings/index.html
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
