

一、订单系统概述
1.1 业务范围
服务业务线:快递、快运、中小件、大件、冷链、国际、B2B合同物流、CLPS、京喜、三入三出(采购入、退货入、调拨入、销售出、退供出、调拨出)等
1.2 订单中心价值
1、解耦(提升系统稳定性)
原系统:交易与生产耦合在一起,业务新增需求,涉及个上下游多个系统。ECLP、外单、运单、终端系统等。多条业务线的逻辑耦合在一起,单一业务条线的需求改动,涉及原系统中其他业务线的关联改造。
新系统:交易与生产运营解耦:交易相关的需求在订单的域内解决;生产侧的需求,在生产域内解决,减少上下游的相互影响。
业务条线接耦:不同业务线,业务流程不同,单一业务条线的需求改动,只在具体的流程中做迭代更新,不影响其他业务线。提升整个流程和业务的稳定性。
2、提升新业务接入速度
订单中心向前台提供可复用的标准能力,提升新业务的导入速度。
订单中心将原系统中的大应用,拆分、抽象为多个小的应用组合,并支持不同场景下按需编排业务流程。新业务通过对中台公共标准能力的复用,可快速接入订单中心,避免相同功能的重复建设。
3、提供全局化统一数据模型
原系统:订单分属于多个系统,外单、ECLP、大件系统,有多套数据库,业务语义不统一,不便于数据化建设。
新系统:订单中心统一定义订单的标准数据模型,让不同业务的数据,沉淀在同一系统,减少订单域相关功能的重复建设,避免资源浪费,打破部门壁垒。使得数据和流程可以集中得以管理和优化,为集团经营分析、预测京东未来的创新空间,提供订单域的标准数据。
二、架构介绍
2.1 整体架构设计
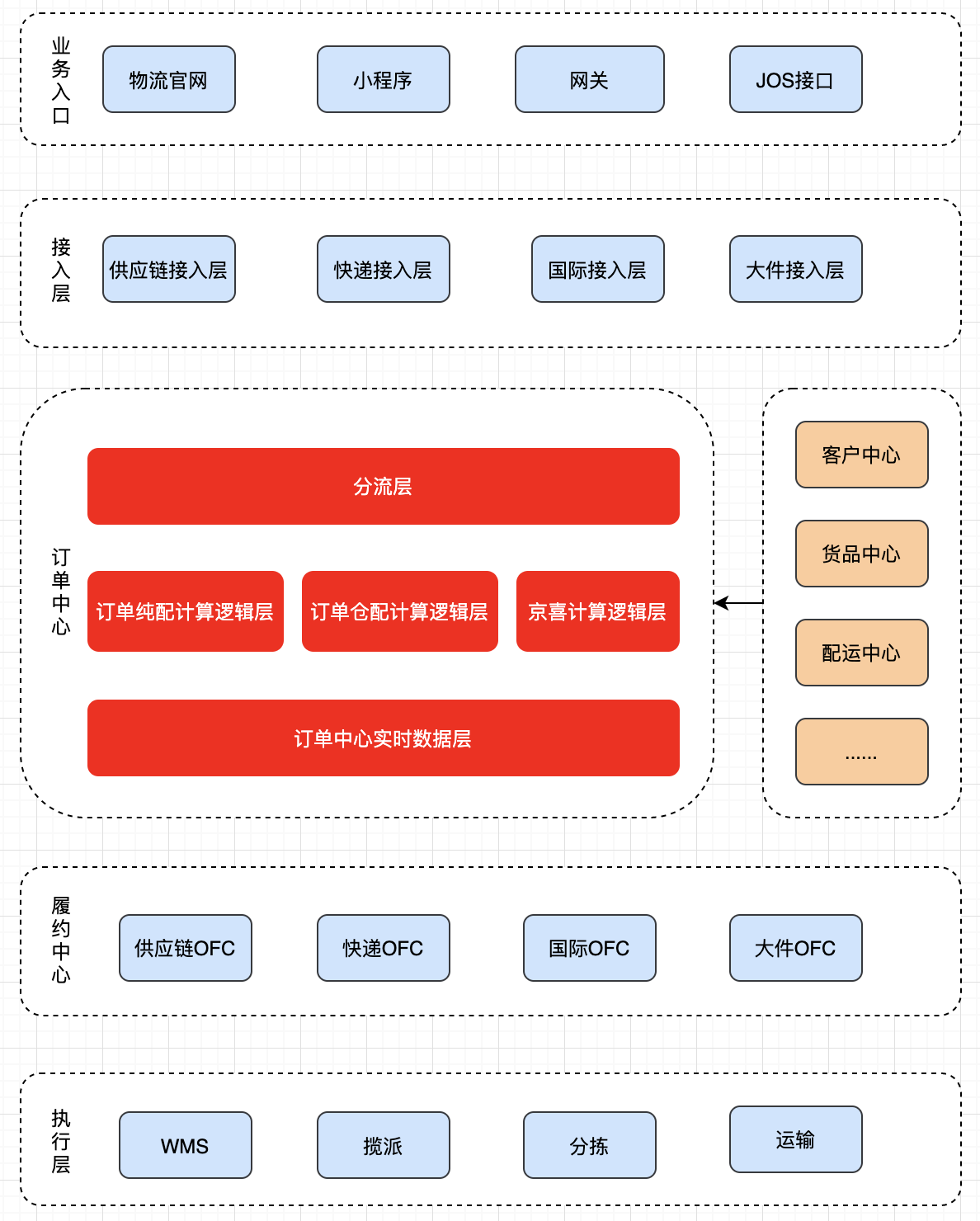
通过技术中台架构升级项目,将交易体系以新的接入-交易-履约-执行四层架构进行重新搭建。其中交易订单负责物流与客户之间产生物流服务契约的单据流量收口,同时承载向下游OFC(订单履约层)分发的职责。
2.2 实时数据层架构设计
2.2.1 系统交互图
系统交互如下:
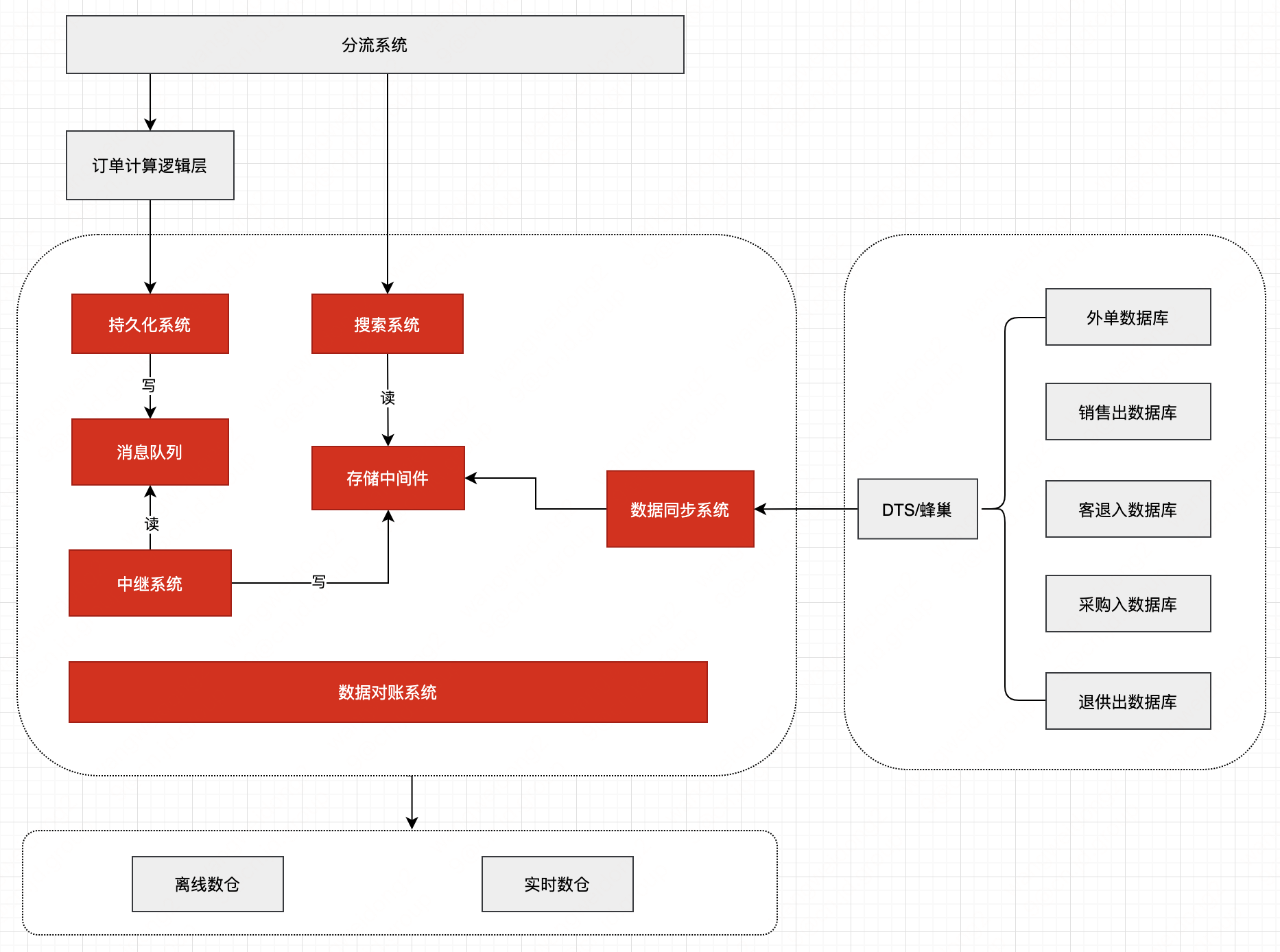
订单中心的标准接口在上层做了单据收口,同时我们在数据层也做了统一的收口。
将业务架构与数据解耦,分布式数据库、缓存、一致性等高可用、高性能设计从业务架构范畴剥离,使业务架构聚焦在业务自身。
持久化系统:用于支撑接单、订单修改、订单取消、订单删除等数据持久化。
搜索系统:提供订单详情查询、订单列表查询、订单状态流水查询、判断是否百川订单等服务。
中继系统:数据枢纽,通过消费消息队列将订单数据写入Elasticsearch、HBase、MySQL。
数据对账系统:用于对比多套存储中间件的数据是否一致,以保障数据最终一致性。
数据同步系统:将订单列表查询所需的查询条件和列表展示字段从老系统同步至订单中心,用于解决因切量过程中订单数据存在于新老系统中而分页困难的问题。
2.2.2 技术架构图
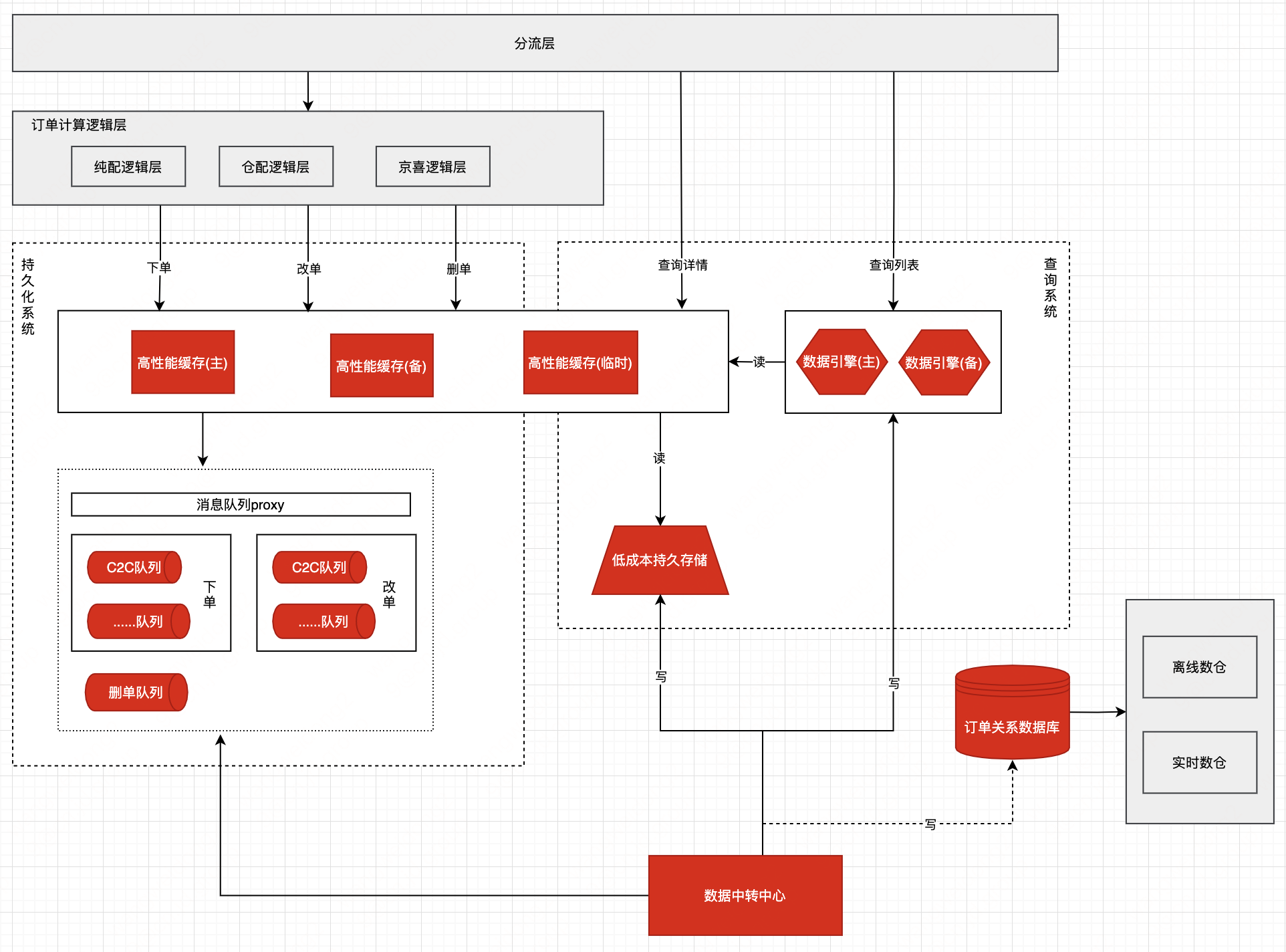
【读写分离架构】采用读写分离架构模式(CQRS),将订单读写流量分离,以提高查询性能和可扩展性,同时达到读、写解耦。
【缓存】使用分布式缓存Redis缓存热门订单数据以及与订单相关的信息提高并发和响应速度减少对HBase的访问,同时,通过主、备、临时3套高性能缓存以提升系统容灾能力。
【消息队列】使用消息队列JMQ实现异步处理订单提升系统吞吐量,同时流量削峰减轻直接请求ES、HBase、数据库的压力。将不同业务场景(如下单、回传)使用不同的Topic进行隔离,可以更好地管理和维护;将不同业务使用不同的Topic隔离,可以实现消息的并行处理和水平扩展,提高系统的吞吐量和性能。
【复杂查询】使用搜索引擎Elasticsearch解决订单复杂查询,先通过Elasticsearch获取订单号,然后根据订单号查询分布式缓存Redis+列式数据库HBase。
【低成本持久化存储】采用HBase列式数据库以支持海量数据规模的存储和极强的扩展能力。
【数据一致性】通过强事务、最终一致、幂等、补偿、分布式锁、版本号等实现
【多租户架构】系统中采用多租户数据模型,将租户的数据分离存储,以确保数据的隔离性和安全性。根据不同租户的需求动态扩展系统的容量和资源,可以支持系统的水平扩展。通过共享基础设施和资源,多租户架构实现了更高的资源利用率和降低成本。
2.3 设计优势
2.3.1 高可用
应用服务器、MySQL、Redis、HBase、JMQ等均跨机房部署;ES单机房部署,搭建ES主备双机房集群
隔离、限流、熔断、削峰、监控
2.3.2 高性能
高性能缓存
异步化
2.3.3 海量数据处理
分库分表
冷热分离
列式存储(HBase)
2.3.4 数据安全
敏感信息加密存储,Log、Redis、ES、MySQL、HBase等均采用加密存储,“谁存储谁加密,谁使用谁解密”。
三、订单数据模型
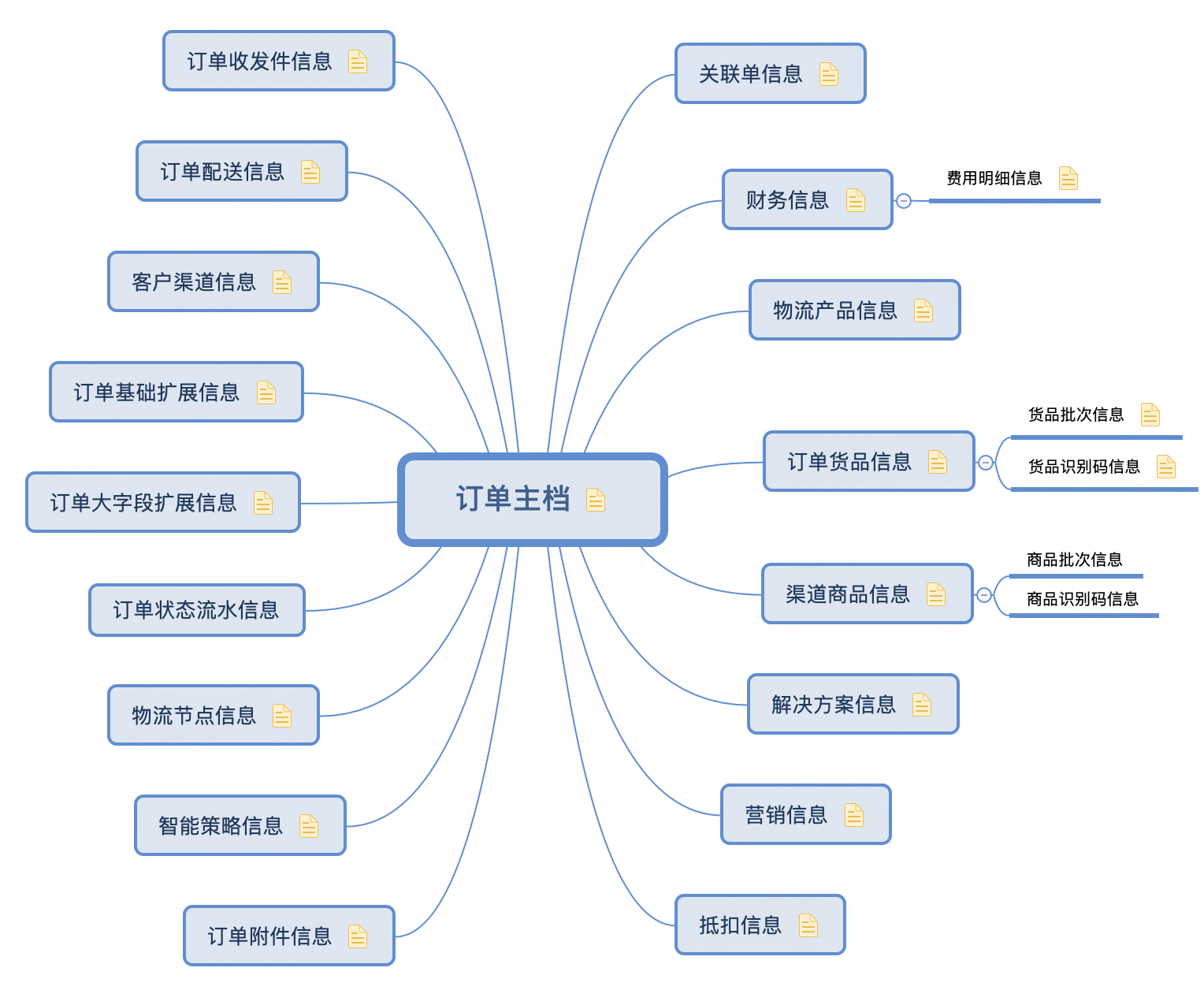
3.1 PDM模型
在订单模型设计上,基于统一业务属性、抽象通用模型、归纳共性实体的原则,将订单模型主要分成了订单的主档信息、订单的货品信息、订单的物流服务信息、订单的营销信息、订单的财务信息、订单的客户渠道信息、订单的收发货信息、订单的操作信息、订单的扩展信息等几类
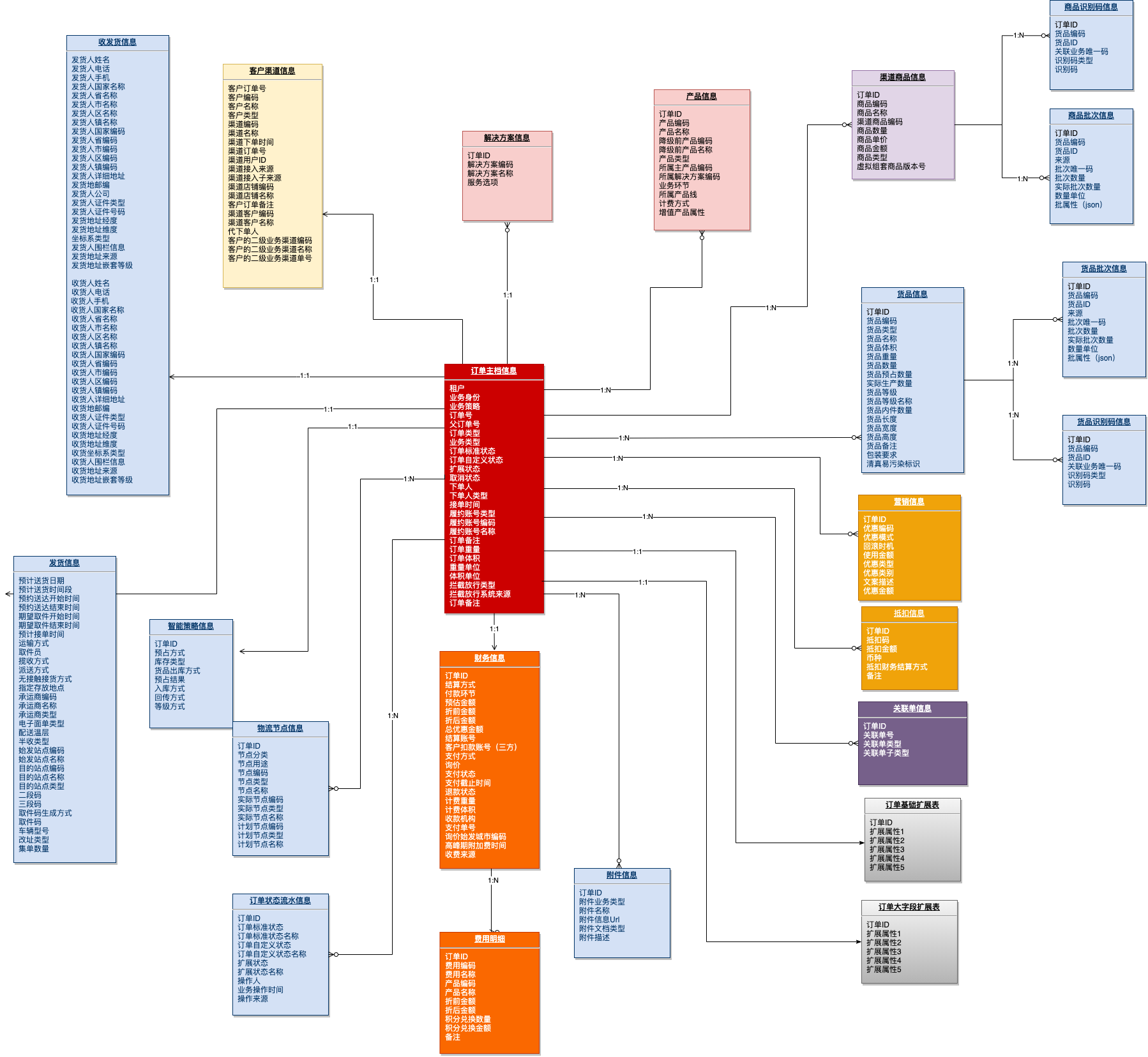
3.2 模型扩展性
3.2.1 标准模型扩展性设计
订单中存在几十上百个标识字段,若每次都采用新增字段形式,订单业务属性、数据模型会大量膨胀,腐蚀模型,同时开发效率较低,故采用KV形式承接和存储。将标识划分到各个业务域中,如订单标识、货品标识、营销标识等。
3.2.2 个性化业务模型扩展性
针对个性化业务,提供了一套可配置的数据库字段管理方案,通过开箱即用的一些设置,订单在提交、修改、查询时,可以根据业务身份+业务类型+业务字段找到不同的数据模型以及数据扩展编码,即找到存储到哪张表哪个字段。在每张表都预留N个扩展属性,同一个扩展属性,不同的业务身份+业务类型表示不同的含义,以此实现扩展存储。
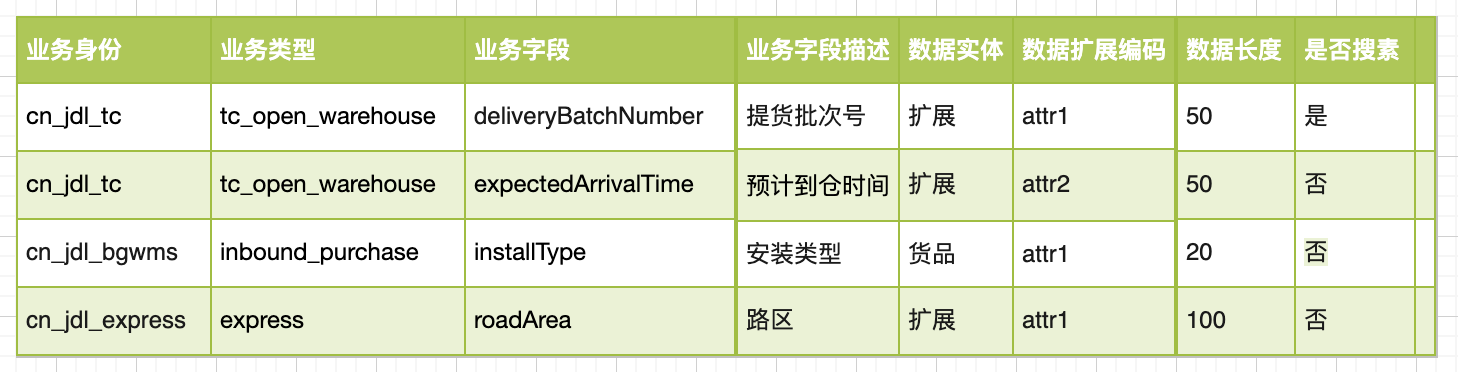
四、未来及挑战
4.1 订单个性化查询
个性化查询需求增多,如模糊查询、根据查询条件实时聚合等需求,若ES索引都放在同一个集群中,会影响整体集群稳定性,但拆分后该业务数据无法与其他业务一块查询展示。
4.2 单元化架构
当前接单持久化TP99是47ms,在非跨机房情况下TP99是20ms,从数据来看,跨机房对性能影响很大。
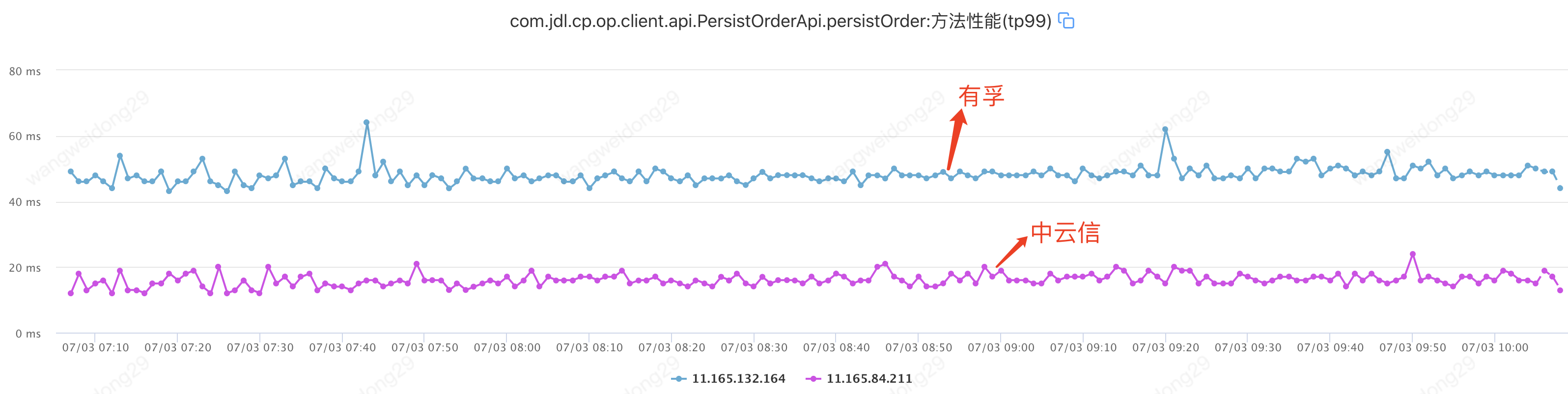
单元化,可以让同一个用户的相关请求,只在一个机房内完成所有业务「闭环」,不再出现「跨机房」访问。单元化的部署方式,可以让每个机房部署在任意地区,随时扩展新机房。通过单元化,持续加强订单平台的基座稳固。
4.3 硬件成本控制
订单日均单量不断上升,数据量越来越大,随之而来是硬件成本的增加,如何控制硬件成本增加,是当下及未来的一项挑战。我们计划通过数据归档、冷热温数据分层等方式来降低数据存储成本。
作者:京东物流 王卫东
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
