

文章目录
-
- 1. 如何何请求解析url
- 2. 如何获取标签里面的文本
- 3. 如何解析JSON格式
- 4. 如何添加常用的header
- 5. 如何合并两个div
- 6. 如何删除html dom的部分结构
- 7. 如何一次性获取所有div标签里的文本
- 8. python爬虫如何改变响应文本字符集编码
- 9. 如何进行字符集转码
- 11. response.text 和 respone.content的区别
- 12. 如何发送post请求访问页面
- 13. 如何获取 url 中的参数
1. 如何何请求解析url
- 要解析 Python 中 Request 返回的 HTML DOM,你可以使用解析库,如 BeautifulSoup 或 lxml,来处理 HTML 文档。下面是使用 Beautiful Soup 和 lxml 的示例代码:
- 首先,确保你已经安装了所需的库。对于 Beautiful Soup,你可以使用 pip install beautifulsoup4 进行安装。对于 lxml,你可以使用 pip install lxml 进行安装。
- 使用 Beautiful Soup 库:
- BeautifulSoup 是一个 Python 库,用于网络爬虫目的。它提供了一种方便和高效的方式来从 HTML 和 XML 文档中提取数据。使用 BeautifulSoup,你可以解析和遍历 HTML 结构,搜索特定元素,并从网页中提取相关数据。
- 该库支持不同的解析器,如内置的 Python 解析器、lxml 和 html5lib,允许你根据特定需求选择最适合的解析器。BeautifulSoup 的优势在于它能够处理格式混乱或损坏的 HTML 代码,使其成为处理复杂情况下的网络爬虫任务的强大工具。
import requests
from bs4 import BeautifulSoup
# 发送请求获取 HTML
response = requests.get(url)
html = response.text
# 创建 Beautiful Soup 对象
soup = BeautifulSoup(html, 'html.parser')
# 通过选择器选择 DOM 元素进行操作
element = soup.select('#my-element')
- 在上面的示例中,requests.get(url) 发送请求并获取HTML响应。然后,我们使用 response.text 获取响应的HTML内容,并将其传递给 Beautiful Soup 构造函数 BeautifulSoup(html, ‘html.parser’),创建一个 Beautiful Soup 对象 soup。
- 接下来,你可以使用 Beautiful Soup 提供的方法和选择器,如 select(),来选择 HTML DOM 中的特定元素。在上述示例中,我们通过选择器 #my-element 选择具有 id 为 my-element 的元素。
- 使用 lxml 库:
import requests
from lxml import etree
# 发送请求获取 HTML
response = requests.get(url)
html = response.text
# 创建 lxml HTML 解析器对象
parser = etree.HTMLParser()
# 解析 HTML
tree = etree.fromstring(html, parser)
# 通过XPath选择 DOM 元素进行操作
elements = tree.xpath('//div[@class="my-element"]')
- 在上面的示例中,我们首先使用 requests.get(url) 发送请求并获取HTML响应。然后,我们创建一个 lxml HTML 解析器对象 parser。
- 接下来,我们使用 etree.fromstring(html, parser) 解析 HTML,并得到一个表示 DOM 树的对象 tree。
- 最后,我们可以使用 XPath 表达式来选择 DOM 元素。在上述示例中,我们使用 XPath 表达式 //div[@class=“my-element”] 选择所有 class 属性为 “my-element” 的 div 元素。
- 无论是使用 Beautiful Soup 还是 lxml,都可以使用各自库提供的方法和属性来操作和提取选择的 DOM 元素。
2. 如何获取标签里面的文本
在Python中,你可以使用多种库和方法来获取HTML标签里面的文本。以下是几种常见的方法:
- 方式一:使用BeautifulSoup库:
from bs4 import BeautifulSoup
# 假设html为包含标签的HTML文档
soup = BeautifulSoup(html, 'html.parser')
# 获取所有标签内的文本
text = soup.get_text()
# 获取特定标签内的文本(例如p标签)
p_text = soup.find('p').get_text()
- 方式二:使用lxml库:
from lxml import etree
# 假设html为包含标签的HTML文档
tree = etree.HTML(html)
# 获取所有标签内的文本
text = tree.xpath('//text()')
# 获取特定标签内的文本(例如p标签)
p_text = tree.xpath('//p/text()')
- 方式三:使用正则表达式:
import re
# 假设html为包含标签的HTML文档
pattern = re.compile('<[^>]*>')
text = re.sub(pattern, '', html)
这些方法可以根据你的需求选择其中之一,它们都可以帮助你提取出HTML标签里面的文本内容。请注意,这些方法在处理复杂的HTML文档时可能会有一些限制,因此建议使用专门的HTML解析库(如BeautifulSoup、lxml)来处理HTML文档以获得更好的灵活性和准确性。
3. 如何解析JSON格式
- 要获取 JSON 数据中的 title 属性的值,你可以使用 Python 的 json 模块来解析 JSON 数据。在你的示例数据中,title 属性位于 data 字典中的 pageArticleList 列表中的每个元素中。
- 下面是一个示例代码,演示如何获取 title 属性的值:
import json
# 假设你已经获取到了 JSON 数据,将其存储在 json_data 变量中
json_data = '''
{
"status": 200,
"message": "success",
"datatype": "json",
"data": {
"pageArticleList": [
{
"indexnum": 0,
"periodid": 20200651,
"ordinate": "",
"pageid": 2020035375,
"pagenum": "6 科协动态",
"title": "聚焦“科技创新+先进制造” 构建社会化大科普工作格局"
}
]
}
}
'''
# 解析 JSON 数据
data = json.loads(json_data)
# 提取 title 属性的值
title = data["data"]["pageArticleList"][0]["title"]
# 输出 title 属性的值
print(title)
-
在上述示例中,我们将示例数据存储在 json_data 字符串中。然后,我们使用 json.loads() 函数将字符串解析为 JSON 数据,将其存储在 data 变量中。
-
然后,我们可以通过字典键的层级访问方式提取 title 属性的值。在这个示例中,我们使用 data[“data”][“pageArticleList”][0][“title”] 来获取 title 属性的值。
-
最后,我们将结果打印出来或根据需求进行其他处理。
-
或者是用get()获取具体属性的值
list = json.loads(res.text)
for i in list:
print(i.get('edition'))

4. 如何添加常用的header
- 如果想在实际的代码中设置HTTP请求头,可以通过使用相应编程语言和HTTP库的功能来完成。下面是一个示例,显示如何使用Python的requests库添加常用的请求头:
import requests
url = "https://example.com"
headers = {
"User-Agent": "Mozilla/5.0",
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://example.com",
# 添加其他常用请求头...
}
response = requests.get(url,stream=True, headers=headers)
- 在上述示例中,我们创建了一个headers字典,并将常用的请求头键值对添加到字典中。然后,在发送请求时,通过传递headers参数将这些请求头添加到GET请求中。
请注意,实际使用时,可以根据需要自定义请求头部。常用的请求头包括 “User-Agent”(用户代理,用于识别客户端浏览器/设备)、“Accept-Language”(接受的语言)、“Referer”(来源页面)等。
5. 如何合并两个div
try:
html = ""
html>
body>
/body>
/html>
""
soup = BeautifulSoup(html, 'html.parser')
# 创建新的div标签
new_div = soup.new_tag('div')
temp_part1 = html_dom.find('div', 'detail-title')
new_div.append(temp_part1)
temp_part2 = html_dom.find("div", "detail-article")
new_div.append(temp_part2)
card = {"content": "", "htmlContent": ""}
html_dom=new_div
except:
return
6. 如何删除html dom的部分结构
- 要在 Python 中删除已获取的 DOM 结构的一部分,你可以使用 Beautiful Soup 库来解析和操作 HTML。下面是一个示例代码,演示如何删除 DOM 结构的一部分:
from bs4 import BeautifulSoup
# 假设你已经获取到了 DOM 结构,将其存储在 dom 变量中
dom = '''
<div class="container">
<h1>Hello, World!</h1>
<p>This is a paragraph.</p>
</div>
'''
# 创建 Beautiful Soup 对象
soup = BeautifulSoup(dom, 'html.parser')
# 找到要删除的部分
div_element = soup.find('div', class_='container')
div_element.extract()
# 输出修改后的 DOM 结构
print(soup.prettify())
- 在上述示例中,我们首先将 DOM 结构存储在 dom 变量中。然后,我们使用 Beautiful Soup 创建了一个解析对象 soup。
接下来,我们使用 find() 方法找到了要删除的部分,这里是。然后,我们使用 extract() 方法将该元素从 DOM 结构中删除。- 最后,我们使用 prettify() 方法将修改后的 DOM 结构输出,以便查看结果。
在实际应用中,需要根据要删除的部分的选择器和属性进行适当的调整。7. 如何一次性获取所有div标签里的文本
- 要一次性获取所有
标签里的文本,你可以使用BeautifulSoup库或lxml库进行解析。以下是使用这两个库的示例代码:
- 方式一:使用BeautifulSoup库:
from bs4 import BeautifulSoup # 假设html为包含标签的HTML文档 soup = BeautifulSoup(html, 'html.parser') # 查找所有div标签并获取其文本内容 div_texts = [div.get_text() for div in soup.find_all('div')]- 方式二:使用lxml库:
from lxml import etree # 假设html为包含标签的HTML文档 tree = etree.HTML(html) # 使用XPath查找所有div标签并获取其文本内容 div_texts = tree.xpath('//div//text()')- 使用这些代码,你可以一次性获取所有的
标签里的文本内容。请注意,这些方法返回的结果是一个列表,列表中的每个元素对应一个标签的文本内容。你可以根据需要进一步处理这些文本内容。
8. python爬虫如何改变响应文本字符集编码
-
在Python爬虫中,你可以通过以下几种方法来改变响应文本的字符集编码:
-
方式一:使用response.encoding属性:当使用requests库发送请求并获取到响应对象后,可以通过response.encoding属性来指定响应文本的字符集编码。根据响应中的内容,可以尝试不同的编码进行设置,例如UTF-8、GBK等。示例代码如下:
import requests response = requests.get('https://example.com') response.encoding = 'UTF-8' # 设置响应文本的字符集编码为UTF-8 print(response.text)apparent_encoding用于获取响应内容的推测字符集编码,是一个只读属性,它只返回推测的字符集编码,并不能用于设置或更改字符集编码。如果需要更改字符集编码,请使用response.encoding属性进行设置- 方式二:使用chardet库自动检测字符集编码:如果你不确定响应的字符集编码是什么,可以使用chardet库来自动检测响应文本的字符集编码。该库可以分析文本中的字符分布情况,并猜测出可能的字符集编码。示例代码如下:
import requests import chardet response = requests.get('https://example.com') encoding = chardet.detect(response.content)['encoding'] # 检测响应文本的字符集编码 response.encoding = encoding # 设置响应文本的字符集编码 print(response.text)- 方式三:使用Unicode编码:如果你无法确定响应文本的正确字符集编码,你可以将文本内容转换为Unicode编码,这样就不需要指定字符集编码了。示例代码如下:
import requests response = requests.get('https://example.com') text = response.content.decode('unicode-escape') print(text)- 以上是三种常见的方法来改变响应文本的字符集编码。根据具体情况选择最适合的方法来处理爬取的网页内容。记住,在处理字符集编码时,要注意处理异常情况,例如编码错误或无法识别字符集等。
9. 如何进行字符集转码
-
字符集转码是指将文本从一种字符集编码转换为另一种字符集编码的过程。在Python中,可以使用**encode()和decode()**方法进行字符集转码操作。
-
方式一: encode(encoding) 将文本从当前字符集编码转换为指定的编码。其中,encoding参数是目标编码格式的字符串表示。示例代码如下:
text = "你好" encoded_text = text.encode('utf-8') # 将文本从当前编码转换为UTF-8编码 print(encoded_text)- 方式二:decode(encoding) 将文本从指定的编码格式解码为当前字符集编码。其中,encoding参数是原始编码格式的字符串表示。示例代码如下:
encoded_text = b'xe4xbdxa0xe5xa5xbd' # UTF-8 编码的字节串 decoded_text = encoded_text.decode('utf-8') # 将字节串从UTF-8解码为Unicode文本 print(decoded_text)- 在进行字符集转码时,需要确保原始文本和目标编码相匹配。如果不确定原始字符集,可以先使用字符集检测工具(如chardet)来确定原始编码,然后再进行转码操作。
- 使用正确的字符集编码进行转码操作可以确保文本在不同环境中的正确显示和处理。
11. response.text 和 respone.content的区别
在许多编程语言的HTTP请求库中,比如Python的requests库,有两个常用的属性用于获取HTTP响应的内容:response.text和response.content。区别如下:
- response.text:
1. response.text返回的是一个字符串,表示HTTP响应的内容。
2. 这个字符串是根据HTTP响应的字符编码来解码的,默认使用UTF-8编码。
3. 如果响应中包含了其他编码的内容,那么可以通过指定response.encoding属性来手动指定相应的编码方式进行解码。- response.content:
1. response.content返回的是一个字节流,表示HTTP响应的内容。
2. 这个字节流是原始的二进制数据,没有进行任何编码解码操作。
3. response.content适用于处理二进制文件,比如图片、音视频文件等。简而言之,response.text适用于处理文本内容,会自动进行编码解码操作,而response.content适用于处理二进制内容,返回的是原始字节流。
使用哪个属性取决于你处理的内容类型和需求。如果你处理的是文本内容,比如HTML、JSON数据等,那么通常使用response.text。如果你处理的是二进制文件,比如图像或音视频文件,那么使用response.content更合适。
12. 如何发送post请求访问页面
解析一个请求主要关注以下几个方面
- 请求路径
- 请求参数(post请求是隐含参数,浏览器发送的是post请求)
- 请求头
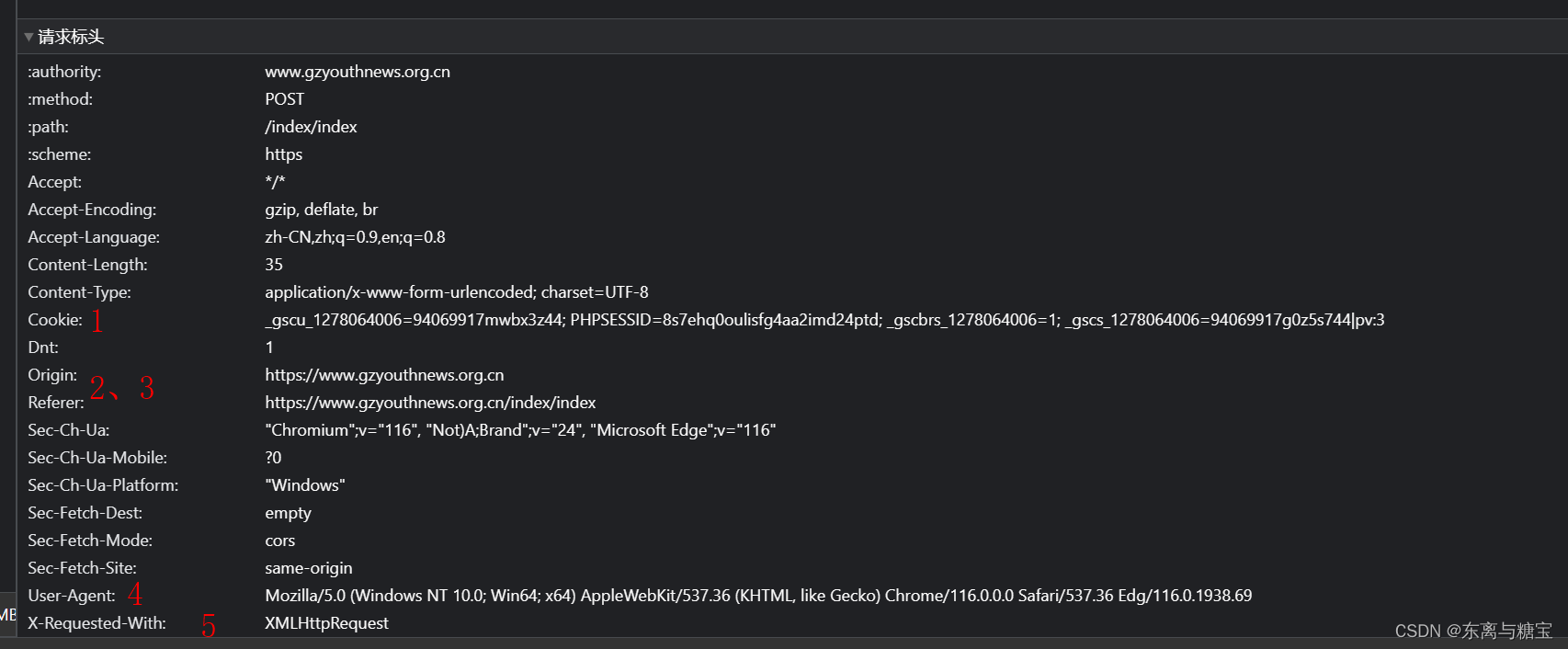
- 请求类型
以下是一个示例代码
import json import requests def main(): url = 'https://www.gzyouthnews.org.cn/index/index' header = { 'X-Requested-With':'XMLHttpRequest' } data={ 'act':'list', 'date':'2023-08-10', 'paper_id':1 } res = requests.post(url=url,headers=header,data=data) list = json.loads(res.text) for i in list: print(i.get('edition')) if __name__ == '__main__': main()13. 如何获取 url 中的参数
要从给定的 URL 中获取参数 page=100,你可以使用 URL 解析库来解析 URL,并提取出所需的参数。
以下是使用 Python 的 urllib.parse 模块解析 URL 参数的示例代码:from urllib.parse import urlparse, parse_qs url = "https://blog.csdn.net/phoenix/web/v1/comment/list/131760390?page=100&size=10&fold=unfold&commentId=" parsed_url = urlparse(url) query_params = parse_qs(parsed_url.query) page_value = query_params.get("page", [None])[0] print(page_value)在上述示例中,我们首先使用 urlparse 函数解析 URL,然后使用 parse_qs 函数解析查询参数部分。parse_qs 函数将查询参数解析为字典,其中键是参数名称,值是参数值的列表。
然后,我们使用 query_params.get(“page”, [None])[0] 从字典中获取名为 page 的参数值。这将返回参数的值,如果该参数不存在,则返回 None。
输出结果将是 100,这是从 URL https://blog.csdn.net/phoenix/web/v1/comment/list/131760390?page=100&size=10&fold=unfold&commentId= 中提取的 page 参数的值。
请注意,如果 URL 的参数值是字符串形式,你可能需要根据需要进行进一步的类型转换。
$(function() {
setTimeout(function () {
var mathcodeList = document.querySelectorAll(‘.htmledit_views img.mathcode’);
if (mathcodeList.length > 0) {
for (let i = 0; i < mathcodeList.length; i++) {
if (mathcodeList[i].naturalWidth === 0 || mathcodeList[i].naturalHeight === 0) {
var alt = mathcodeList[i].alt;
alt = '\(' + alt + '\)';
var curSpan = $('‘);
curSpan.text(alt);
$(mathcodeList[i]).before(curSpan);
$(mathcodeList[i]).remove();
}
}
MathJax.Hub.Queue([“Typeset”,MathJax.Hub]);
}
}, 1000)
}); -
阅读终点,创作起航,您可以撰写心得或摘录文章要点写篇博文。去创作

东离与糖宝
关注
关注-



105
点赞 -


踩 -



108
收藏
觉得还不错?
一键收藏

-

打赏 -

107
评论 -
复制链接
专栏目录python网络爬虫学习笔记(1)09-20主要为大家详细介绍了python网络爬虫学习笔记的第一篇,具有一定的参考价值,感兴趣的小伙伴们可以参考一下最牛逼的Python爬虫学习笔记08-28最牛逼的Python爬虫学习笔记,非常不错的,强烈建议下载107 条评论
您还未登录,请先
登录
后发表或查看评论python爬虫学习笔记 4.7 (Request/Response)01-20python爬虫学习笔记 4.7 (Request/Response)
Request
Request 部分源码:
# 部分代码
class Request(object_ref):
def __init__(self, url, callback=None, method=’GET’, headers=None, body=None,
cookies=None, meta=None, encoding=’utf-8′, priority=0,
dont_filter=False, errback=None):最牛逼的Python爬虫学习笔记,学习过程中记录的笔记08-18第1段:爬虫原理与数据抓取
爬虫能做些什么通用爬虫
和聚焦爬虫URL的意义
(了解)关于HTTP和
HTTPS HTTP代理工具
Fidder HTTP的请求与响
应urlib2:Python的标准
模块案例:批量爬取页面
数据 URLError与
HTTPError 附录:响应状
态码详解Python 爬虫学习笔记之单线程爬虫01-20介绍
本篇文章主要介绍如何爬取麦子学院的课程信息(本爬虫仍是单线程爬虫),在开始介绍之前,先来看看结果示意图怎么样,是不是已经跃跃欲试了?首先让我们打开麦子学院的网址,然后找到麦子学院的全部课程信息,像下面这样
这个时候进行翻页,观看网址的变化,首先,第一页的网址是 http://www.maiziedu.com/course/list/, 第二页变成了 http://www.maiziedu.com/course/list/all-all/0-2/, 第三页变成了 http://www.maiziedu.com/course/list/all-all/0-3/ ,可以看到,每次翻一页,
python爬虫学习笔记(二)——解析内容01-20– 获取到网页数据后,我们发现我们想要的信息隐藏在一堆无用信息之中,此时便需要解析网页数据的内容
补充:在一些其他的教程中,发现也可以用urllib模块获取数据,urllib模块是python内置的一个http请求库,不需要额外的安装。只需要关注请求的链接,参数,提供了强大的解析。requests库则需格外安装,但是个人感觉requests使用更简洁方便
标签解析
Beautiful Soup库的安装(Beautiful Soup库是解析、遍历、维护“标签树”的功能库):
按WIN键+R键打开运行,输入cmd后回车进入命令提示符
pip install beautifulsoup4然而,
python 爬虫学习笔记03-09python 爬虫学习笔记python爬虫学习笔记-scrapy框架(1)01-29python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python …python爬虫学习笔记-scrapy框架(2)01-29python爬虫学习 scrapy框架 爬虫学习 scrapy python爬虫学习 scrapy框架 爬虫学习 scrapy python爬虫学习 scrapy框架 爬虫学习 scrapypython爬虫学习 scrapy框架 爬虫学习python爬虫学习 scrapy框架 爬虫学习python…python爬虫学习笔记 2.9 (使用bs4得案例)12-21python爬虫学习笔记 2.9 (使用bs4得案例)
python爬虫学习笔记 1.1(通用爬虫和聚焦爬虫)
python爬虫学习笔记 1.2 ( HTTP和HTTPS )
python爬虫学习笔记 1.3 str和bytes的区别
python爬虫学习笔记 1.4 (Request简单使用)request安装
python爬虫学习笔记 1.5 (Requests深入)
python爬虫学习笔记 1.6 (HTTP/HTTPS抓包工具-Fiddler)
python爬虫学习笔记 1.7 (urllib模块的基本使用)
python爬虫学习笔记 1.8 (urllib:get请求和post请求python爬虫学习笔记之Beautifulsoup模块用法详解09-17主要介绍了python爬虫学习笔记之Beautifulsoup模块用法,结合实例形式详细分析了python爬虫Beautifulsoup模块基本功能、原理、用法及操作注意事项,需要的朋友可以参考下市场调查中的信度和效度分析原理及python实现示例爱数据爱统计09-13

253
准则效度又称为效标效度,是根据已经得到确定的某种理论,选择一种指标或量表作为准则即效标,计算量表得分与准则间的相关系数,用于评估一个量表(或测量工具)与一个已被确定为准则的变量之间的关联程度,这种相关系数被称为准则效度系数。根据准则效度系数的大小判断所采用量表与准则之间的一致性程度,一致性程度越高,说明所采用量表的效度越高;该系数测量了量表中各项之间的相关性,通常在0到1之间,较高的值表示较高的内部一致性。区别效度是指利用相同的量表测量不同的概念或特征之间的相关程度,相关程度越低,区别效度越高。【Python】从入门到上头—网络请求模块urlib和reuests的应用场景(12)墩墩分墩09-13
228
– urllib的`request模块`可以非常方便地抓取URL内容,也就是发送一个`GET请求`到指定的页面,然后返回HTTP的响应:
– 如果安装了Anaconda(免费、易于安装的包管理器),requests就已经可用了。否则,需要在命令行下通过pip安装:【python】高级特性最新发布浮生九记09-19
43
本文记录python的高级特性。安装Python第三方库java1234的博客09-17
113
在Python的标准安装中,包含了一组自带的模块,这些模块被成为“标准库”。比如常用的math,random,datetime,os,json等等。pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名。输入你想要安装的第三方库名,可以指定版本,再加上清华的库镜像,然后点击安装。此外,还有很多的第三方模块,或者叫做库也行,叫包也行。安装第三方库,我们用pip命令。pandas库,数据分析领域。numpy库,科学计算领域。【python学习】函数式编程和高阶函数 map filter reduce lambda表达式 sorted 闭包 装饰器weixin_40293999的博客09-17
77
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数。高阶函数包括:map,reduce,filter, sorted匿名函数lambda。读入2个整数a和b,然后输出它们的和(python)qq_64037242的博客09-15
220
读入2个整数a和b,然后输出它们的和。Java面向对象编程weixin_64308540的博客09-15
795
目描述:二货小易有一个W*H的网格盒子,网格的行编号为0~W-1,网格的列编号为0~H-1。已知表达式int m[]={0,1,2,3,4,5,6};( (x1-x2) * (x1-x2) + (y1-y2) * (y1-y2) ) 的算术平方根。输入描述:每组数组包含网格长宽W,H,用空格分割.(1 ≤ W、H ≤ 1000)有六个元素6,5,4,3,2,1顺序入栈,问下列哪一个不是合法的出栈序列?C. 抽象类中可以没有抽象方法,最终类中可以没有最终方法。进阶:空间复杂度 O(1)时间复杂度 O(N)python爬虫之b站视频下载(python学习笔记)06-06好的,下面是用中文回复的python爬虫之b站视频下载(python学习笔记):Python爬虫是一种自动化获取网页数据的技术,可以用来下载B站视频。具体步骤如下:
1. 安装必要的Python库,如requests、bs4、lxml等。
2. 找到B站视频的URL地址,可以通过搜索、分类、排行榜等方式获取。
3. 使用requests库发送HTTP请求,获取视频页面的HTML源码。
4. 使用bs4库解析HTML源码,获取视频的真实下载地址。
5. 使用requests库下载视频,保存到本地。
需要注意的是,B站对于视频下载有一定的限制,需要登录账号才能下载高清视频。因此,在爬取B站视频时需要模拟登录,获取登录后的cookie信息。
以上就是python爬虫之b站视频下载的基本流程,希望对您有所帮助。
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交
window.csdn.csdnFooter.options = {
el: ‘.blog-footer-bottom’,
type: 2
}东离与糖宝

CSDN认证博客专家
CSDN认证企业博客
码龄2年

Java领域优质创作者- 66
- 原创
- 12
- 周排名
- 605
- 总排名
- 15万+
- 访问
-

- 等级
- 1万+
- 积分
- 9748
- 粉丝
- 7034
- 获赞
- 6511
- 评论
- 6257
- 收藏












 私信关注
私信关注

热门文章
-
Mybatis-Plus 实现增删改查 — Mybatis-Plus 快速入门保姆级教程(一)
21903 -
Spring概述与核心概念学习 — Spring入门(一)
15939 -
Mybatis-Plus 进阶开发 — Mybatis-Plus 入门教程(二)
10487 -
Spring注解开发 — Spring入门(六)
8916 -
Spring AOP — Spring入门(五)
7659
分类专栏
-

python
4篇
-

合作推广
6篇
-

代码随想录算法训练营
2篇
-

代码随想录
-

JAVA基础
2篇
-

纪念日
1篇
-

Nginx
1篇
-

SSM项目实例
12篇
-

Spring入门
8篇
-
HTTP
1篇
-

前后端软件安装与环境配置
2篇
-

MongoDB
4篇
-

mysql
2篇
-

Git
1篇
-

操作系统
4篇
-

Redis
3篇
-

SpringMVC
5篇
-

mybatis
3篇
-

mybatis-plus入门
2篇
-

SpringBoot
4篇

最新评论
您愿意向朋友推荐“博客详情页”吗?
-
强烈不推荐 -
不推荐 -
一般般 -
推荐 -
强烈推荐
提交
最新文章
- Python 超高频常见字符操作【建议收藏】
- 分布式文件系统的新兴力量:揭秘Alluxio的元数据管理机制【文末送书】
- 阿里后端开发:抽象建模经典案例【文末送书】
202309月
10篇08月
13篇07月
19篇06月
10篇05月
12篇04月
2篇目录
$(“a.flexible-btn”).click(function(){
$(this).parents(‘div.aside-box’).removeClass(‘flexible-box’);
$(this).parents(“p.text-center”).remove();
})
目录
分类专栏
-
python
4篇
-
合作推广
6篇
-
代码随想录算法训练营
2篇
-
代码随想录
-
JAVA基础
2篇
-
纪念日
1篇
-
Nginx
1篇
-
SSM项目实例
12篇
-
Spring入门
8篇
-
HTTP
1篇
-
前后端软件安装与环境配置
2篇
-
MongoDB
4篇
-
mysql
2篇
-
Git
1篇
-
操作系统
4篇
-
Redis
3篇
-
SpringMVC
5篇
-
mybatis
3篇
-
mybatis-plus入门
2篇
-
SpringBoot
4篇
目录
- 最后,我们使用 prettify() 方法将修改后的 DOM 结构输出,以便查看结果。

栗筝i:
支持博主优质博客!功能实现很有参考价值,文章写得专业、很到位,很细节,非常透彻!干货满满!永远支持博主!
沃和莱特:
这波python字符操作总结赞哇,支持 !
LinAlpaca:
优质好文,又学到了新东西,支持大佬
北 海:
优质好文,内容丰富,结构严谨,感谢大佬的分享,期待大佬持续输出好文
Satoru_Kaugo:
博主的文章细节很到位,兼顾实用性和可操作性,感谢博主的分享,期待博主持续带来更多好文,同时也希望可以来我博客指导我一番!